Эта статья — краткий пересказ невероятно интересного доклада Скотта Майерса для тех, у кого нет 70 минут на весь доклад, но есть 7 минут на основные тезисы.
Некоторые люди, которые не пишут на С++, а лишь слышали об этом языке, задаются вопросом: «Почему вообще кто-то пишет на C++?». Но есть люди, которые используют С++ каждый день, и вот эти люди задаются вопросом: «А действительно, почему я пишу на этом языке?».
 Но ведь действительно, должна быть какая-то причина, по которой люди пишут программы на С++. Давайте вернемся в начало 90-ых, когда проходила стандартизация С++. Была предложена масса идей. Предложений было столько и они были настолько разные, что мне запомнилась цитата Джима Вальдо, который тогда работал в комитете по стандартизации: «Каждый, предлагающий добавить что-то в С++ должен приложить к заявке свою почку. Тогда никто не предложит больше двух идей, а к выбору этих двух он подойдёт невероятно ответственно.»
Но ведь действительно, должна быть какая-то причина, по которой люди пишут программы на С++. Давайте вернемся в начало 90-ых, когда проходила стандартизация С++. Была предложена масса идей. Предложений было столько и они были настолько разные, что мне запомнилась цитата Джима Вальдо, который тогда работал в комитете по стандартизации: «Каждый, предлагающий добавить что-то в С++ должен приложить к заявке свою почку. Тогда никто не предложит больше двух идей, а к выбору этих двух он подойдёт невероятно ответственно.»
Язык, который был бы получен в результате принятия всех предложений, выходил слишком сложным и тогда Бьёрн Страуструп сказал «А помните Ваза?». Никто, кроме людей из Швеции, не понял о чём речь. Ваза был огромным боевым кораблём, построенным в Швеции в 1625 году. Основным принципом постройки корабля было «А почему бы нам не добавить сюда ещё и вот такую фичу?». Многие из идей исходили непосредственно от короля, в частности он лично утверждал размеры корабля. Также на Ваза по указаниям свыше требовалось нацепить огромное количество элементов украшения, резьбы, большое количество пушек и т.д. А королю ведь не откажешь. Итог был закономерным — из-за ошибок в конструировании Ваза затонул в первом же рейсе, едва выйдя из бухты.
Давайте посмотрим на С++. Является ли он настолько же «нагруженным» фичами? На первый взгляд — без сомнения:
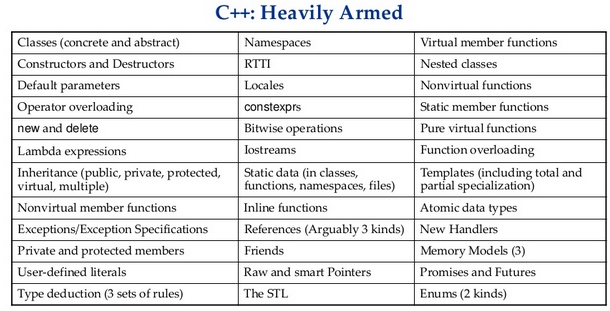
Давайте посмотрим вот на это:
Вроде бы всё ясно — это функция f, которой передаётся х. Так? Не факт. Это может быть функция, а может быть указатель на функцию, а может быть ссылка на функцию. Ещё это может быть объект, в классе которого перегружен оператор скобок. Или объект, который неявно может быть сконвертирован в что-то из вышеуказанного. Или одна из перегруженных функций. Или шаблон. Или несколько из вышеуказанных вещей одновременно.
Я начинаю понимать, почему люди считают С++ сложным. Кажется, что всё вышеуказанное спроектировано совершенно неверно. Слишком сложно.
Но подождите. Давайте измерим пару вещей. Например, количество вакансий для программистов на разных языках, количество кода на них в открытых источниках, количество поисковых запросов к поисковикам и т.д. И если мы посмотрим на статистику, в течении последних 25 лет С++ находится на 2-4 месте по популярности в мире.
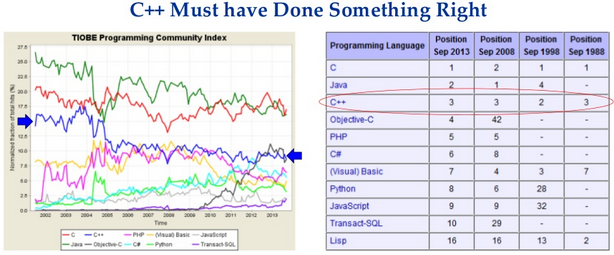
С++ на втором месте по количеству кода в opensource (12%) и этот процент растёт год от года.

Соответственно, что-то в этом языке сделано правильно. Почему-то он плывёт. Давайте разбираться почему.
Мы можем взять код на С — и использовать его в С++. Мы можем взять редактор, IDE, линкер, дебаггер от С — и использовать их для С++ сразу или с минимальными изменениями. Мы можем взять программиста на С, сказать ему «ты уже знаешь часть фич С++, посмотри на ООП, STL и ещё пару вещей — и ты сможешь писать на С++». Эта вещь была невероятно важной в 90-ых и начале 2000-ых. Да и сегодня код на С — самый распространённый в мире.
Что бы вы назвали самой важной фичей языка? (Реплики из зала: «фигурные скобки», «шаблоны»). Нет. Это деструкторы. Деструкторы сделали возможным RAII. Деструкторы упростили сложность используемых в программировании концепций на порядок. В деструкторе мы можем освободить память, мьютекс, закрыть файл или сетевое соединение. Деструкторы спасают нас от веток условий, от ненужных goto.
На Марсе есть небольшой такой кратер, который получился от того, что в эту планету бодро врезался сделанный на Земле исследовательский аппарат, который вообще-то разбиваться был не должен. Но разбился. Разбился потому, что в одном из кусков его кода программист решил использовать метрическую систему мер, а в другом куске кода, другой программист — классическую английскую. И вот как-то оказалось, что килограмм не равен фунту.
Шаблоны в С++ дали нам возможность писать абстрактный код, алгоритмы, функции и классы, которые на этапе компиляции могут надёжно и однозначно быть специфицированы какими-то определёнными типами. Это огромный шаг вперёд. И никаких затрат на рантайме!
Мы можем перегрузить функции, методы, операторы. Мы можем сделать код проще и выразительнее. Перегрузка оператора скобок стала основой для лямбд в стандарте С++11, а лямбды очень полезны.
С++ проектировался как язык, удобный не столько для прикладных программистов, сколько для разработчиков библиотек. Мысль была в том, что когда появится много хороших библиотек — с их помощью будет удобно писать действительно хорошие приложения. Сейчас можно сказать, что библиотек для С++ у нас действительно много, так что затея себя оправдала.
Процедурное программирование? Ок. Объектно-ориентированное программирование? Ок. Метапрограммирование на шаблонах? Ок. «Опасное программирование» с указателями и ассемблерными вставками? Ок. Смешанные концепции? Тоже ок. Даже функциональное программирование в какой-то мере уже становится возможным с приходом последних стандартов С++.
Возможно, С++ не лучший язык всех времён и народов, но на данный момент он лучший язык для того, что я называю «программированием с препятствиями». Препятствием может быть неизвестная предметная область, высокие требования по быстродействию или потребляемой памяти, необходимость общаться со странным чужим кодом или аппаратными устройствами, неопределённость задач и т.д. Выбрав С++ в ситуации с наличием вышеуказанных (или других) препятствий — у вас самые высокие шансы не запороть проект в какой-то момент просто потому, что на выбранном языке решить задачу невозможно.
Один из базовых принципов языка. То, что может быть просчитано на этапе компиляции — там и просчитывается. Неиспользуемый код — не вызывается. Программа отрабатывает только те инструкции, которые вы написали, именно в том порядке, в каком вы заставили её это делать. Никаких закулисных игр. Такие вещи особенно важны в системном программировании.
Еще одно свойство совместимости с С. Программа на С++ не так далеко ушла от ассемблера. В большинстве случаев можно понять в какой набор ассемблерных инструкций развернётся код на С++. Как результат — можно писать эффективные программы под любые платформы. Более того, под некоторые платформы только на С/С++ писать и можно.
Код на С++, написанный в начале 90-ых на первых версиях стандарта С++ можно просто взять и скомпилировать современным компилятором, поддерживающим С++14. И он скомпилируется. Ну, с большой вероятностью. И будет делать то, что должен. Опять таки, с очень большой вероятностью. Есть пару мест, которые могут сломаться, но их мало и они общеизвестны. Таким образом мы говорим компании: инвестируя сегодня в код на С++ вы можете быть спокойны — и через 10 и через 20 лет ваш код будет работать, а значит ваши деньги не пропадут.
Языку С++ часто пеняют тем, что код на нём — сложный. Вернее было бы сказать, что на С++ действительно можно (при желании) написать сложный код. И ещё о коде на С++ можно сложно говорить. Давайте взглянем на вот это:
О Боже мой! Да здесь же есть пространства имён, потоки, шаблон (неявно специфицированный), объект класса (унаследованного от другого класса) и перегрузка операторов. Кошмар! Но взгляните на код выше ещё раз. Вы правда не понимаете, что там написано? Вы правда задумываетесь о всех этих страшных терминах, которые я упоминал, когда читаете этот код? Нет. Сложность прячется от вас, вы её не замечаете.
Люди, которые решают писать на С++, живут не в танке. Зачастую они знают парочку других языков — скриптовых, управляемых, функциональных. Там, где можно сэкономить себе время и силы — они на них и пишут. Но иногда оказывается, что выбора нет — проблема слишком сложна, требования слишком высоки, риски запредельны. И тогда на сцену выходит С++. Сложный, но мощный инструмент для сложных, но масштабных задач. Это, к стати, одна из причин, почему программирование на С++ и код на С++ считаются сложными — средний уровень решаемых на этом языке задач является более высоким. Наивно ждать решения сверх-сложной задачи простым минималистичным кодом.
Да, на С++ очень просто выстрелить себе в ногу. Даже множеством разных способов. Но для некоторых людей это плюс. Возможность выстрелить себе в ногу предполагает возможность стрелять вообще куда-угодно, как-угодно и сколько-угодно. Да, результаты могут быть ужасными. Но и мощь устрашающа.
Нам говорят, что в стандарте языка С++ в 1990-ом году было 400 страниц, в 1998 — 700, а в 2011 стало 1300. «Язык становится сложнее» — нам говорят. Нет, не становится. Да, мы вводим новые понятия и фичи, но большинство их них призваны не усложнить, а упростить код. Вспомните, как вам приходилось бегать итераторами по векторам — и вот в С++11 у нас есть range-based for и auto. Мы можем написать одну строку кода там, где раньше было 5. Лямбда-функции дали возможность исключить из кода целые сущности — лишние классы и методы, которые по факту были не нужны. Да, разработчикам стандарта приходится обдумывать и писать существенно больше текста. Но конечному программисту становится только легче.
Некоторые люди, которые не пишут на С++, а лишь слышали об этом языке, задаются вопросом: «Почему вообще кто-то пишет на C++?». Но есть люди, которые используют С++ каждый день, и вот эти люди задаются вопросом: «А действительно, почему я пишу на этом языке?».
 Но ведь действительно, должна быть какая-то причина, по которой люди пишут программы на С++. Давайте вернемся в начало 90-ых, когда проходила стандартизация С++. Была предложена масса идей. Предложений было столько и они были настолько разные, что мне запомнилась цитата Джима Вальдо, который тогда работал в комитете по стандартизации: «Каждый, предлагающий добавить что-то в С++ должен приложить к заявке свою почку. Тогда никто не предложит больше двух идей, а к выбору этих двух он подойдёт невероятно ответственно.»
Но ведь действительно, должна быть какая-то причина, по которой люди пишут программы на С++. Давайте вернемся в начало 90-ых, когда проходила стандартизация С++. Была предложена масса идей. Предложений было столько и они были настолько разные, что мне запомнилась цитата Джима Вальдо, который тогда работал в комитете по стандартизации: «Каждый, предлагающий добавить что-то в С++ должен приложить к заявке свою почку. Тогда никто не предложит больше двух идей, а к выбору этих двух он подойдёт невероятно ответственно.»Язык, который был бы получен в результате принятия всех предложений, выходил слишком сложным и тогда Бьёрн Страуструп сказал «А помните Ваза?». Никто, кроме людей из Швеции, не понял о чём речь. Ваза был огромным боевым кораблём, построенным в Швеции в 1625 году. Основным принципом постройки корабля было «А почему бы нам не добавить сюда ещё и вот такую фичу?». Многие из идей исходили непосредственно от короля, в частности он лично утверждал размеры корабля. Также на Ваза по указаниям свыше требовалось нацепить огромное количество элементов украшения, резьбы, большое количество пушек и т.д. А королю ведь не откажешь. Итог был закономерным — из-за ошибок в конструировании Ваза затонул в первом же рейсе, едва выйдя из бухты.
Давайте посмотрим на С++. Является ли он настолько же «нагруженным» фичами? На первый взгляд — без сомнения:
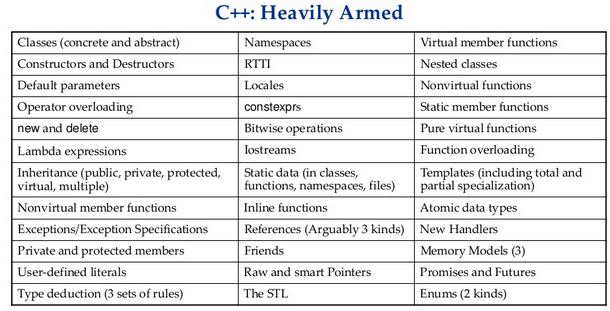
Давайте посмотрим вот на это:
f(x);
Вроде бы всё ясно — это функция f, которой передаётся х. Так? Не факт. Это может быть функция, а может быть указатель на функцию, а может быть ссылка на функцию. Ещё это может быть объект, в классе которого перегружен оператор скобок. Или объект, который неявно может быть сконвертирован в что-то из вышеуказанного. Или одна из перегруженных функций. Или шаблон. Или несколько из вышеуказанных вещей одновременно.
Я начинаю понимать, почему люди считают С++ сложным. Кажется, что всё вышеуказанное спроектировано совершенно неверно. Слишком сложно.
Но подождите. Давайте измерим пару вещей. Например, количество вакансий для программистов на разных языках, количество кода на них в открытых источниках, количество поисковых запросов к поисковикам и т.д. И если мы посмотрим на статистику, в течении последних 25 лет С++ находится на 2-4 месте по популярности в мире.
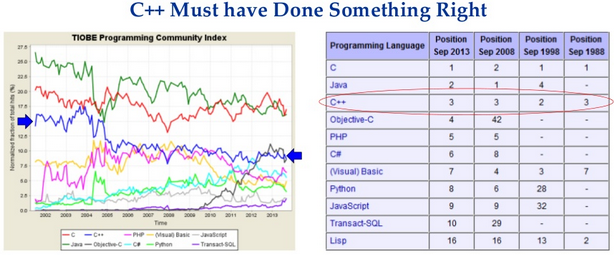
С++ на втором месте по количеству кода в opensource (12%) и этот процент растёт год от года.

Соответственно, что-то в этом языке сделано правильно. Почему-то он плывёт. Давайте разбираться почему.
Совместимость с С
Мы можем взять код на С — и использовать его в С++. Мы можем взять редактор, IDE, линкер, дебаггер от С — и использовать их для С++ сразу или с минимальными изменениями. Мы можем взять программиста на С, сказать ему «ты уже знаешь часть фич С++, посмотри на ООП, STL и ещё пару вещей — и ты сможешь писать на С++». Эта вещь была невероятно важной в 90-ых и начале 2000-ых. Да и сегодня код на С — самый распространённый в мире.
Самая важная фича языка
Что бы вы назвали самой важной фичей языка? (Реплики из зала: «фигурные скобки», «шаблоны»). Нет. Это деструкторы. Деструкторы сделали возможным RAII. Деструкторы упростили сложность используемых в программировании концепций на порядок. В деструкторе мы можем освободить память, мьютекс, закрыть файл или сетевое соединение. Деструкторы спасают нас от веток условий, от ненужных goto.
Шаблоны
На Марсе есть небольшой такой кратер, который получился от того, что в эту планету бодро врезался сделанный на Земле исследовательский аппарат, который вообще-то разбиваться был не должен. Но разбился. Разбился потому, что в одном из кусков его кода программист решил использовать метрическую систему мер, а в другом куске кода, другой программист — классическую английскую. И вот как-то оказалось, что килограмм не равен фунту.
Шаблоны в С++ дали нам возможность писать абстрактный код, алгоритмы, функции и классы, которые на этапе компиляции могут надёжно и однозначно быть специфицированы какими-то определёнными типами. Это огромный шаг вперёд. И никаких затрат на рантайме!
Перегрузка
Мы можем перегрузить функции, методы, операторы. Мы можем сделать код проще и выразительнее. Перегрузка оператора скобок стала основой для лямбд в стандарте С++11, а лямбды очень полезны.
Язык для библиотек
С++ проектировался как язык, удобный не столько для прикладных программистов, сколько для разработчиков библиотек. Мысль была в том, что когда появится много хороших библиотек — с их помощью будет удобно писать действительно хорошие приложения. Сейчас можно сказать, что библиотек для С++ у нас действительно много, так что затея себя оправдала.
Мультипарадигменность
Процедурное программирование? Ок. Объектно-ориентированное программирование? Ок. Метапрограммирование на шаблонах? Ок. «Опасное программирование» с указателями и ассемблерными вставками? Ок. Смешанные концепции? Тоже ок. Даже функциональное программирование в какой-то мере уже становится возможным с приходом последних стандартов С++.
Лучший язык для «программирования с препятствиями»
Возможно, С++ не лучший язык всех времён и народов, но на данный момент он лучший язык для того, что я называю «программированием с препятствиями». Препятствием может быть неизвестная предметная область, высокие требования по быстродействию или потребляемой памяти, необходимость общаться со странным чужим кодом или аппаратными устройствами, неопределённость задач и т.д. Выбрав С++ в ситуации с наличием вышеуказанных (или других) препятствий — у вас самые высокие шансы не запороть проект в какой-то момент просто потому, что на выбранном языке решить задачу невозможно.
Вы не платите за то, что не используете
Один из базовых принципов языка. То, что может быть просчитано на этапе компиляции — там и просчитывается. Неиспользуемый код — не вызывается. Программа отрабатывает только те инструкции, которые вы написали, именно в том порядке, в каком вы заставили её это делать. Никаких закулисных игр. Такие вещи особенно важны в системном программировании.
«Платформенно-независимый ассемблер»
Еще одно свойство совместимости с С. Программа на С++ не так далеко ушла от ассемблера. В большинстве случаев можно понять в какой набор ассемблерных инструкций развернётся код на С++. Как результат — можно писать эффективные программы под любые платформы. Более того, под некоторые платформы только на С/С++ писать и можно.
Обратная совместимость
Код на С++, написанный в начале 90-ых на первых версиях стандарта С++ можно просто взять и скомпилировать современным компилятором, поддерживающим С++14. И он скомпилируется. Ну, с большой вероятностью. И будет делать то, что должен. Опять таки, с очень большой вероятностью. Есть пару мест, которые могут сломаться, но их мало и они общеизвестны. Таким образом мы говорим компании: инвестируя сегодня в код на С++ вы можете быть спокойны — и через 10 и через 20 лет ваш код будет работать, а значит ваши деньги не пропадут.
Сложность, которую можно спрятать
Языку С++ часто пеняют тем, что код на нём — сложный. Вернее было бы сказать, что на С++ действительно можно (при желании) написать сложный код. И ещё о коде на С++ можно сложно говорить. Давайте взглянем на вот это:
std::cout << x;
О Боже мой! Да здесь же есть пространства имён, потоки, шаблон (неявно специфицированный), объект класса (унаследованного от другого класса) и перегрузка операторов. Кошмар! Но взгляните на код выше ещё раз. Вы правда не понимаете, что там написано? Вы правда задумываетесь о всех этих страшных терминах, которые я упоминал, когда читаете этот код? Нет. Сложность прячется от вас, вы её не замечаете.
Язык для тех, у кого нет другого выбора
Люди, которые решают писать на С++, живут не в танке. Зачастую они знают парочку других языков — скриптовых, управляемых, функциональных. Там, где можно сэкономить себе время и силы — они на них и пишут. Но иногда оказывается, что выбора нет — проблема слишком сложна, требования слишком высоки, риски запредельны. И тогда на сцену выходит С++. Сложный, но мощный инструмент для сложных, но масштабных задач. Это, к стати, одна из причин, почему программирование на С++ и код на С++ считаются сложными — средний уровень решаемых на этом языке задач является более высоким. Наивно ждать решения сверх-сложной задачи простым минималистичным кодом.
Язык для тех, кто любит сложности
Да, на С++ очень просто выстрелить себе в ногу. Даже множеством разных способов. Но для некоторых людей это плюс. Возможность выстрелить себе в ногу предполагает возможность стрелять вообще куда-угодно, как-угодно и сколько-угодно. Да, результаты могут быть ужасными. Но и мощь устрашающа.
Стандарт становится больше и… проще
Нам говорят, что в стандарте языка С++ в 1990-ом году было 400 страниц, в 1998 — 700, а в 2011 стало 1300. «Язык становится сложнее» — нам говорят. Нет, не становится. Да, мы вводим новые понятия и фичи, но большинство их них призваны не усложнить, а упростить код. Вспомните, как вам приходилось бегать итераторами по векторам — и вот в С++11 у нас есть range-based for и auto. Мы можем написать одну строку кода там, где раньше было 5. Лямбда-функции дали возможность исключить из кода целые сущности — лишние классы и методы, которые по факту были не нужны. Да, разработчикам стандарта приходится обдумывать и писать существенно больше текста. Но конечному программисту становится только легче.
