В данной статье хотел бы рассказать про набор полезных дополнений к Visual Studio, которые могут в значительной мере облегчить разработку баз данных на основе MS SQL Server.
Основными преимуществами использования SSDT я бы выделил следующее:
Безусловно на этом плюсы использования SSDT не заканчиваются, но остальное не так сильно впечатляет, как то, что упомянуто выше. Если вас интересует, как воспользоваться этими и другими преимуществами — прошу под кат.
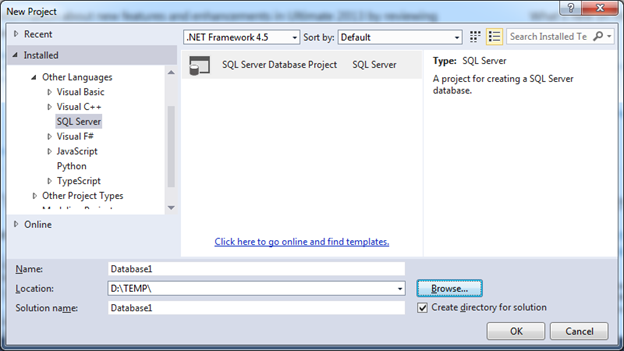
Всё необходимое для установки можно найти на странице загрузки в Data Developer Center. Выбрав необходимую версию вы сможете без труда установить инструменты на свой компьютер и описывать это не вижу смысла. После установки в окне создания нового проекта у вас появится новый тип проекта:
Создав новый проект вы увидите следующее:
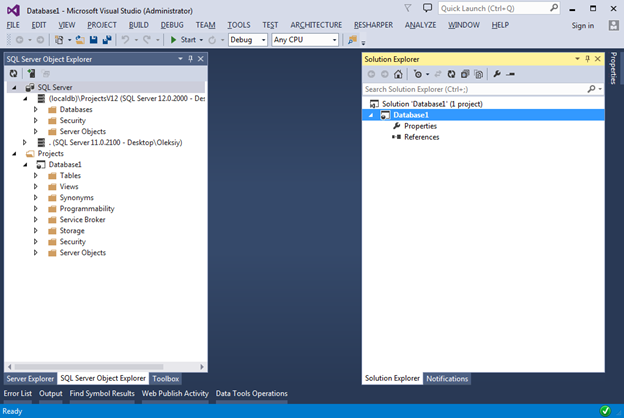
На панели SQL Server Object Explorer (меню View -> SQL Server Object Explorer) мы видим нечто очень похожее на Object Explorer в SQL Server Management Studio, из которого убрано всё, что не имеет большого смысла на этапе разработки базы данных.
Подключившись к существующей базе, можно производить разработку базы данных в так называемом Connected режиме. Это мало чем отличается от классического подхода используемого в SQL Server Management Studio и в данной статье рассматриваться не будет.
Этот режим разработки нам наиболее интересен, т.к. именно он позволяет получить основные преимущества использования SSDT.
В основе работы лежит очень простая идея – позволить разработчикам хранить все скрипты создания объектов БД (tables, views, store procedures и т. д.) в проекте специального типа в составе имеющегося или нового решения (solution). На основе скриптов, Visual Studio может сгенерировать DACPAC файл, который по сути является zip архив со всеми t-sql скриптами. Имея DACPAC файл можно будет произвести публикацию (publish) на требуемом экземпляре базы данных, путём сравнения схемы описанной в DACPAC и схемы в целевой базе данных. В ходе публикации, специальные механизмы производят сравнения, в результате чего автоматически создаются миграционные скрипты для применения изменений без потери данных.
Для того что увидеть это в действии, предлагаю посмотреть следующие примеры.
Начнём с возможности импорта. Вызываем контекстное меню проекта и видим 3 возможных варианта:

Мы выберем вариант “Database…” и импортируем локальную базу. Она содержит одну таблицу и одну хранимую процедуру. В SQL Server Object Explorer исходная база выглядит следующим образом:
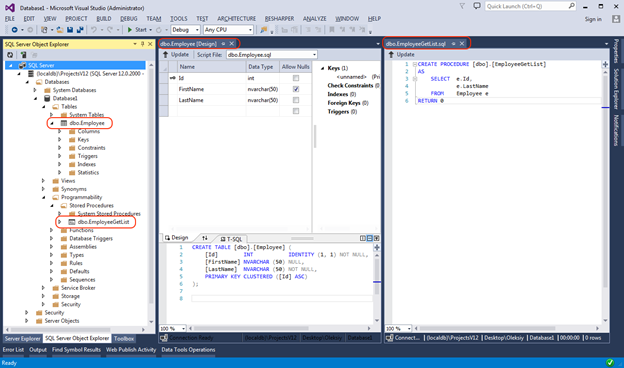
После завершения импорта мы увидим крайне похожую картину, с тем единственным различием, что структура базы будет представлена в Solution Explorer в качестве *.sql файлов.
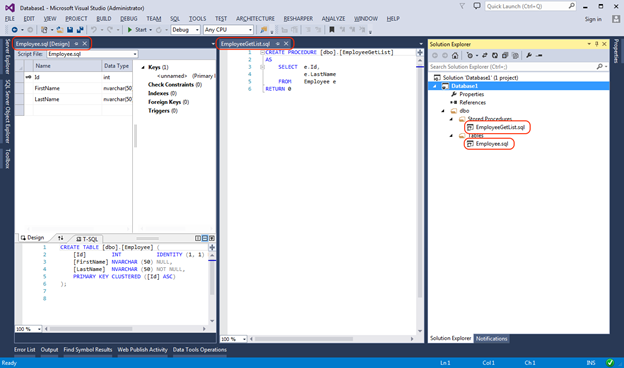
Так же мы всегда можем добавить новые элементы воспользовавшись диалоговым окном Add New Item, в котором перечислены все возможные объекты базы данных:
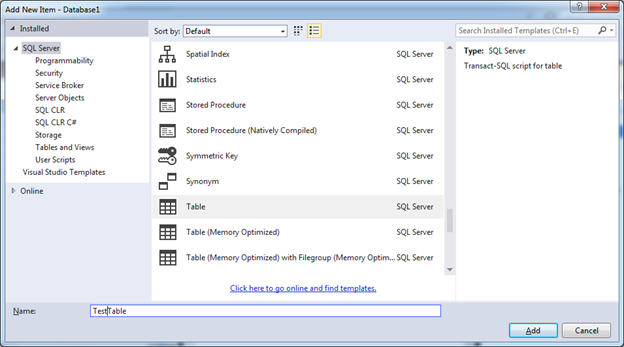
Добавим таблицу TestTable. Новый файл-скрипт TestTable.sql будет добавлен в корень проекта и для удобства мы его перенесём в папку Tables.

Для создания схемы таблицы мы можем использовать как панель дизайнера, так и панель T-SQL. Все изменения сделанные на одной панели будут сразу же отображены в другой.
Так же мы можем изменять существующие скрипты. Visual Studio для этого предоставляет удобный и любимый всеми IntelliSense. Так как мы не подключены к физической базе данных, Visual Studio для корректной работы IntelliSence парсит все скрипты в проекте, что позволяет ей мгновенно отражать последние изменения сделанные в схеме базы данных.
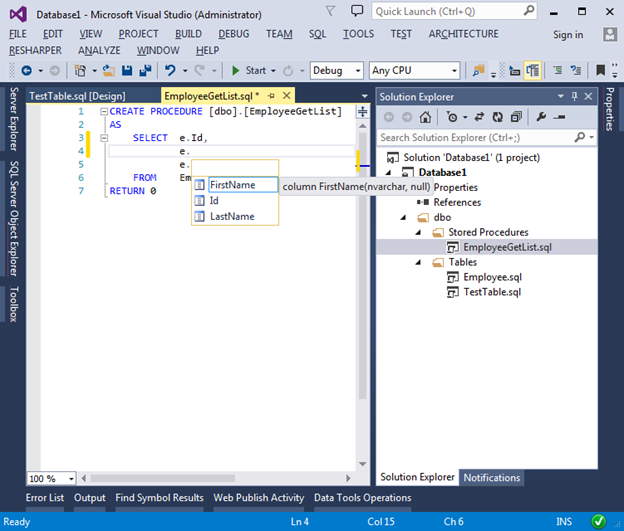
Хочу обратить внимание на то, что мы не должны заботиться об инкрементных изменениях нашей базы. Вместо этого мы всегда создаём скрипты так, как если бы объекты создавались заново. При публикации DACPAC пакета миграционные скрипты будут сгенерированы автоматически, путём сравнения DACPAC файла и схемы в целевой базе (target Database).
Как уже упоминалось, DACPAC содержит не только схему и данные, но ещё и ряд полезных настроек, для просмотра/редактирования которых мы можем воспользоваться окном свойств нашего проекта.
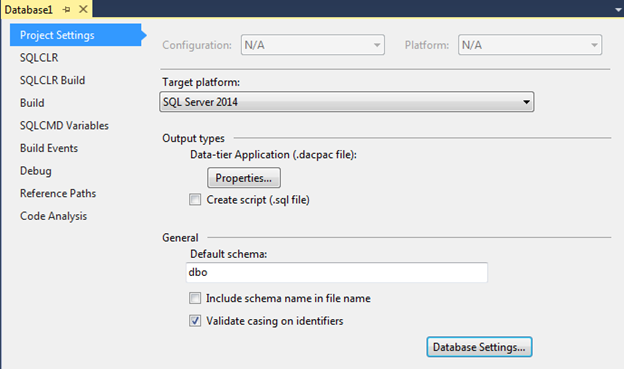
Свойство Target platform позволяет выставить версию базы данных, для которой будут валидироваться скрипты в проекте. Минимальная поддерживаемая версия MS SQL Server 2005. Если например задать версию базы 2005 и попробовать создать колонку типа Geography, то при компиляции мы получим следующее сообщение:

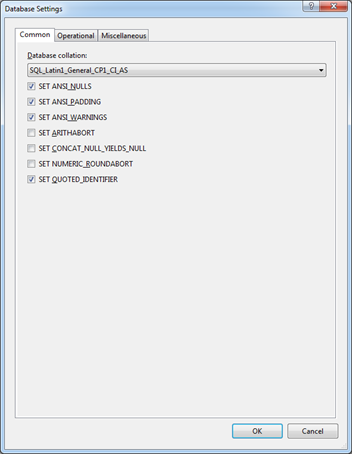
На закладке Project Settings, мы можем задать настройки базы данных, нажав на кнопку Database Settings. Нажав на неё мы увидим диалог с настройками, аналогичные тем, что мы привыкли видеть в SQL Server Management Studio:
Так же хочется упомянуть закладку SQLCMD Variables, на которой мы можем задавать различные переменные для дальнейшего их использования в наших скриптах.
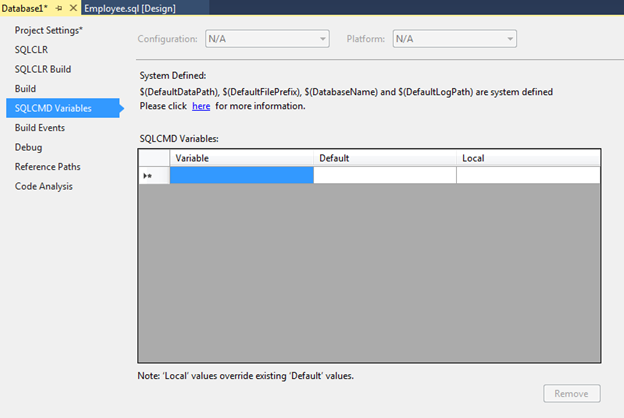
После того, как все настройки заданы и *.sql скрипты добавлены/обновлены мы можем применить изменения к целевой базе (target database). Для этого идём в меню Build->Publish или же выбираем аналогичный пункт в контекстном меню проекта.
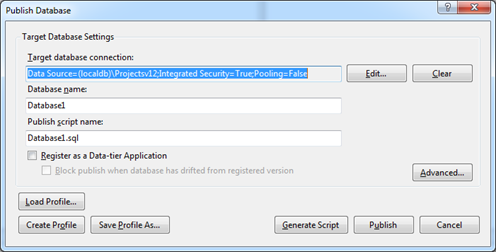
В появившемся диалоговом окне задаём строку подключения к базе назначения (target database) и если необходимо — дополнительные настройки, нажав на кнопку Advanced:
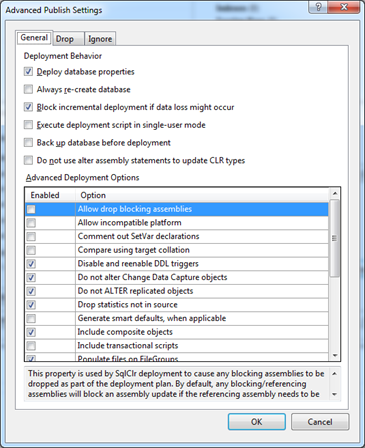
Большинство настроек понятны без дополнительного описания, поэтому не будем на них останавливаться подробно, но рекомендую с ними ознакомиться, что бы в случае невозможности успешно «запаблишить» проект, вы знали в чём может быть проблема.
Если требуется производить публикацию в целевую базу данных более одного раза, то настройки можно сохранить в publish профиль, нажав на кнопку Create Profile. Это добавит в наш проект файл с расширением *.publish.xml и в дальнейшем мы сможем произвести публикацию без необходимости вводить настройки ещё раз. Если же какой-то из профилей публикации должен быть использован по умолчанию, то можно в контекстном меню файла публикации выбрать пункт Set As Default Publish Profile. Этот профиль будет автоматически загружаться в диалог Publish.
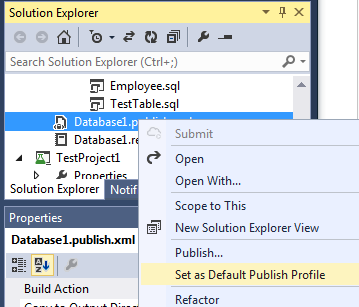
Все необходимые изменения, можно применить сразу, нажав на кнопку Publish. А можно отложить на потом, сгенерировав соответствующий миграционный скрип (кнопка Generate Script) — он будет содержать все необходимые инструкции для приведения базы назначения к требуемому состоянию.
Если же у нас нет доступа к базе данных, то мы можем передать результаты нашего труда в виде DACPAC файла, который создаётся путём компиляции проекта и находится в ../bin/Debug/Database1.dacpac. Отдав файл, например, администратору базы данных, тот в свою очередь сможет воспользоваться любым удобным способом для применения изменений в целевой базе.
Способы публикации DACPAC (publishing):
В нашем проекте создадим папку DataSeeding (имя не имеет значения) и в неё добавим новый скрипт.
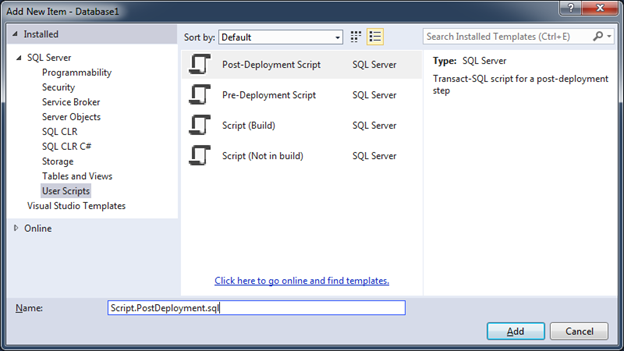
По сути все типы в разделе User Script являются обычными *.sql скриптами и отличаются лишь значением свойства “Build Action” у вновь созданного файла.
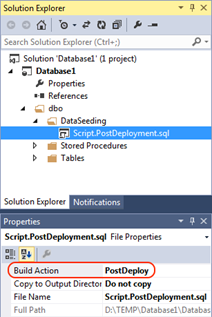
Логика из файла PostDeployment.sql будет выполнена после применения всех изменений схемы базы данных. В случае создания PreDeployment.sql — логика выполнится перед применением изменений схемы.
Значение свойства Build Action для файлов созданных через шаблон Script (Not in Build) будет установлено в «None». Они полезные для удобного структурирования команд в отдельных файлах, которые вызываются из Pre или Post Deployment скриптов.
Файлы созданные через шаблон Script имеют значение Build Action равное «Build», и их содержимое добавляется к результирующему скрипту, который выполняется при publish’e DACPAC файла в момент изменения схемы базы.
В виду того, что в проекте может быть только один Post Deployment script и его размер может быстро вырасти, рекомендуется логику вставки данных выносить в отдельные скрипты. Именно поэтому мы добавим файл типа Script (Not in Build), а в Post Deployment script добавим ссылку на него. Вот как это будет выглядеть:
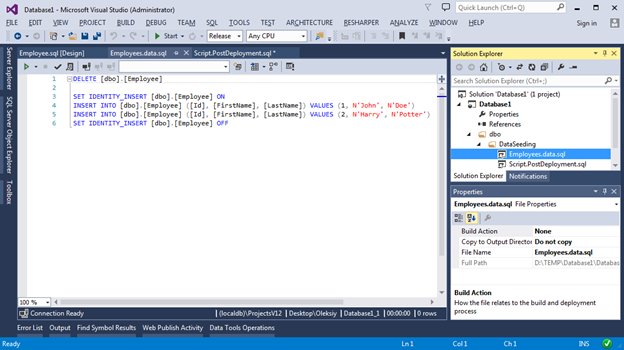
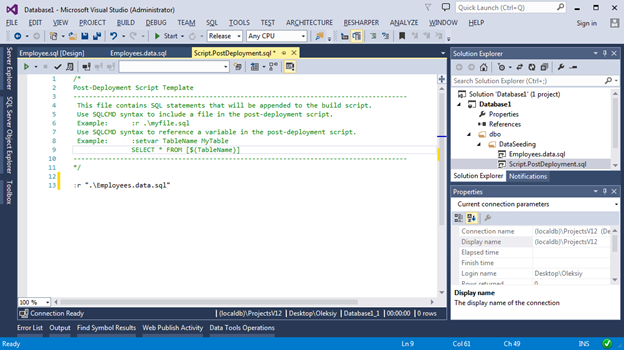
Теперь при публикации нашего проекта, в базе всегда будут вставлены 2 записи в таблицу Employees.
На ряду с возможностью создания Database проекта, установка SSDT добавляет ряд полезных инструментов, доступных из меню Tools.
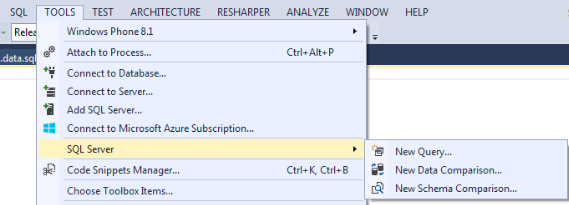
Думаю, что из названия и так понятно, что каждый из пунктов делает. Как пример, покажу удобный графический инструмент сравнения схем. В качестве источника и целевого объекта можно выбрать один из трех вариантов:
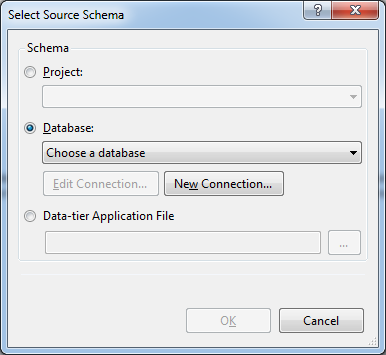
Мы сравним наш проект с локальной базой данных. Результат сравнения будет выглядеть следующим образом:
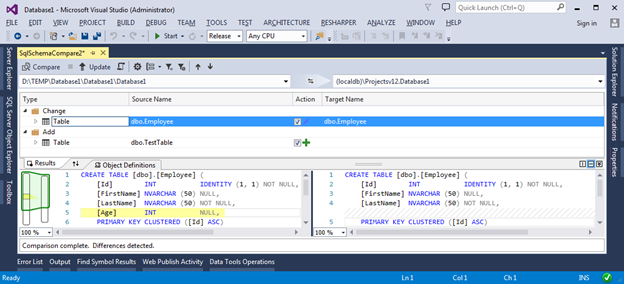
В результирующем окне мы можем применить различные способы группировки (по схеме, по типу объектов и по требуемому действию) для более удобного просмотра предлагаемых изменений и выбрать те объекты, которые требуется обновить. Для того, что бы применить миграционный скрипт необходимо нажать кнопку Update – это приведёт Target DB к состоянию нашего проекта.
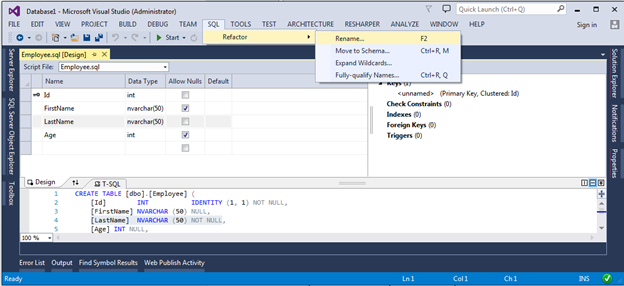
Это моя любимая фича. Для примера, покажем как переименовать колонку LastName в таблице Employees. Для этого открываем скрипт создания таблицы, в редакторе таблицы выделяем колонку LastName и в меню SQL -> Refactor выбираем пункт Rename:
Задаём новое имя:
Просматриваем последствия переименования и применяем предложенные изменения:
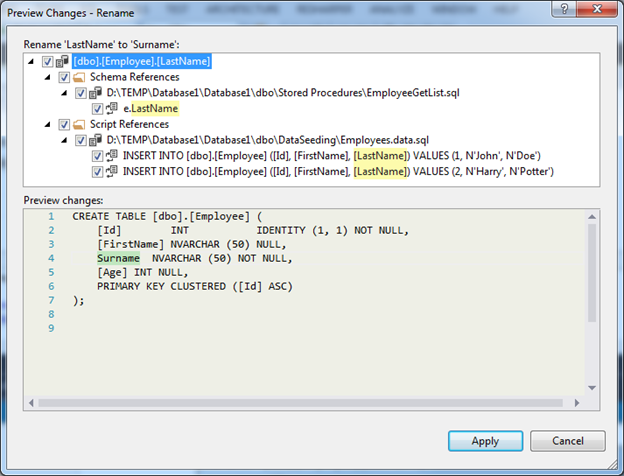
В результате все скрипты будут изменены и после первого рефакторинга в проект будет добавлен специальный файл *.refactoring. В нём будут сохраняться все изменения схемы в историческом порядке в формате XML документа. Эти данные будут полезны при генерации миграционного скрипта и позволят более правильно мигрировать схему и данные.

Создадим наш первый юнит тест. Для этого вызовем контекстное меню для хранимой процедуры, которую мы хотим протестировать:
В появившемся диалоговом окне у нас будет возможность выбрать дополнительные объекты (если они есть) и задать тип и имя тестового проекта и имя класса, содержащего код юнит теста:

Создав проект нам будет предложено выбрать базу данных на которой будут запускаться тесты, а также некоторые настройки проекта:
После успешного создания у нас откроется графический редактор юнит теста, в нижней части которого будут представлены различные проверки для тестируемого объекта. В нашем случае это хранимая процедура EmployeeGetList.
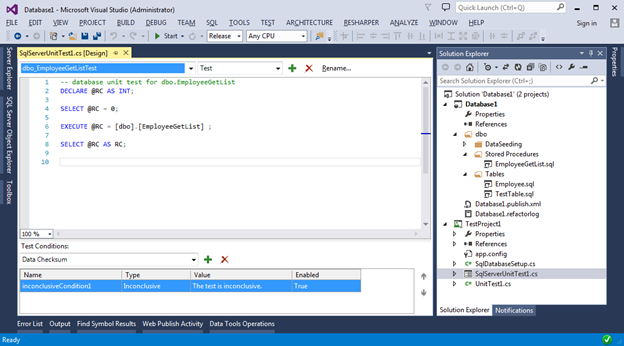
Наша задача сводится к тому, что бы написать необходимый Sql скрипт и задать требуемые условия проверки, которые будут произведены после выполнения кода скрипта. Проверки могут быть разные: время исполнения, количество возращённых строк, Checksum возвращённых данных и т.п. Полный список проверок можно найти в выпадающем меню под текстом скрипта и над таблицей проверок. Для каждой проверки можно задать ряд настроек через стандартную панель Properties. Для её вызова необходимо в контекстном меню конкретной проверки выбрать пункт Properties.
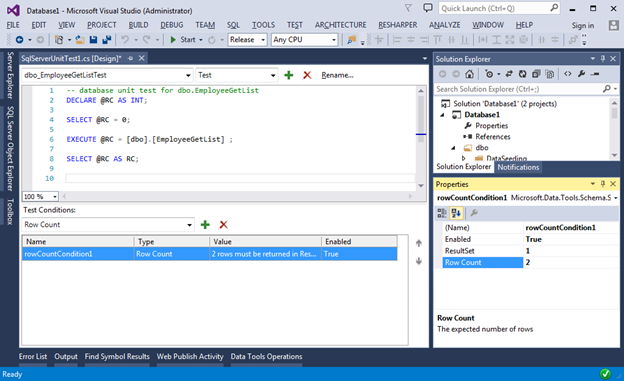
Например, вот так будет выглядеть проверка возвращаемого количества строк:
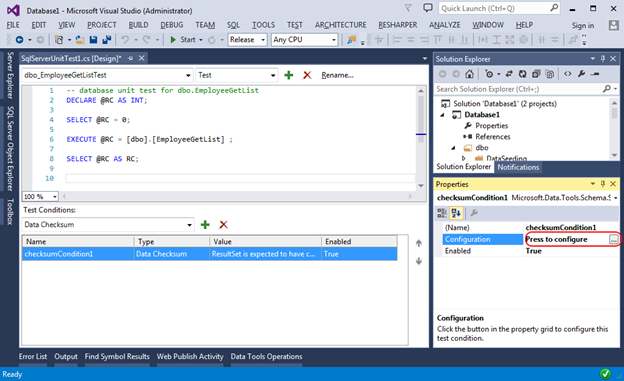
А вот так можно проверить Checksum:
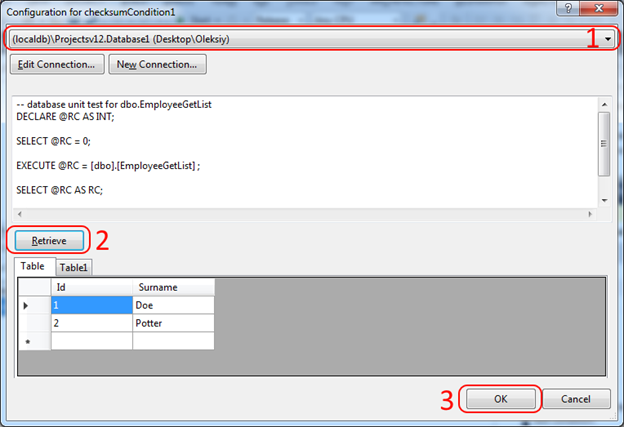
По сути эта проверка выполняет наш скрипт (получает 2 строки из таблицы Employees) и на полученных данных находит Checksum. Наша задача на этапе создания теста, найти эталонные данные, на них посчитать Checksum и в дальнейшем с этим значением будет производиться сверка полученного результата. Иными словами, это удобный способ убедиться, что результат хранимой процедуры не меняется. Для получения контрольного значения Checksum, необходимо воспользоваться кнопкой в окне Properties, которая позволит выбрать эталонную базу и получить эталонное значение Cheсksum:
Надеюсь этот краткий обзор позволил получить общее представление, что такое SSDT и как они могут быть полезны в вашем проекте. Безусловно тут не были рассмотрены все детали. Но вам, как разработчику это и не нужно. Вы должны просто иметь общее представление списка возможностей, а дальнейшее их использование надеюсь будет интуитивно понятным, т.к. разработчики SSDT хорошо потрудились и снабдили инструменты огромным количеством помощников (wizards) и контекстных подсказок.
Основными преимуществами использования SSDT я бы выделил следующее:
- возможность простого изменения (refactoring) схемы базы (можно переименовать колонку таблицы и все Views, Functions и Stored Procedures ссылающиеся на неё автоматически будут исправлены для отражения изменений)
- создание юнит тестов для базы данных
- хранение структуры базы данных в Source Control
- сравнение схемы/данных c возможностью генерации скрипта для приведения схемы/данных к требуемому состоянию
Безусловно на этом плюсы использования SSDT не заканчиваются, но остальное не так сильно впечатляет, как то, что упомянуто выше. Если вас интересует, как воспользоваться этими и другими преимуществами — прошу под кат.
Установка и первое знакомство
Всё необходимое для установки можно найти на странице загрузки в Data Developer Center. Выбрав необходимую версию вы сможете без труда установить инструменты на свой компьютер и описывать это не вижу смысла. После установки в окне создания нового проекта у вас появится новый тип проекта:
Создав новый проект вы увидите следующее:
На панели SQL Server Object Explorer (меню View -> SQL Server Object Explorer) мы видим нечто очень похожее на Object Explorer в SQL Server Management Studio, из которого убрано всё, что не имеет большого смысла на этапе разработки базы данных.
Подключившись к существующей базе, можно производить разработку базы данных в так называемом Connected режиме. Это мало чем отличается от классического подхода используемого в SQL Server Management Studio и в данной статье рассматриваться не будет.
Disconnected режим
Этот режим разработки нам наиболее интересен, т.к. именно он позволяет получить основные преимущества использования SSDT.
В основе работы лежит очень простая идея – позволить разработчикам хранить все скрипты создания объектов БД (tables, views, store procedures и т. д.) в проекте специального типа в составе имеющегося или нового решения (solution). На основе скриптов, Visual Studio может сгенерировать DACPAC файл, который по сути является zip архив со всеми t-sql скриптами. Имея DACPAC файл можно будет произвести публикацию (publish) на требуемом экземпляре базы данных, путём сравнения схемы описанной в DACPAC и схемы в целевой базе данных. В ходе публикации, специальные механизмы производят сравнения, в результате чего автоматически создаются миграционные скрипты для применения изменений без потери данных.
Для того что увидеть это в действии, предлагаю посмотреть следующие примеры.
Начнём с возможности импорта. Вызываем контекстное меню проекта и видим 3 возможных варианта:
- Script (*.sql) – добавляет один или несколько *.sql файлов из заданного расположения в структуру проекта;
- Data-tier Application (*.dacpac) – добавляет *.sql файлы, а так же различные настройки базы данных из специального DACPAC файла, описанного выше; может содержать не только схему базы, но так же данные и различные настройки базы;
- Database… — аналогичен предыдущему варианту, но источником данных служит существующая база
Мы выберем вариант “Database…” и импортируем локальную базу. Она содержит одну таблицу и одну хранимую процедуру. В SQL Server Object Explorer исходная база выглядит следующим образом:
После завершения импорта мы увидим крайне похожую картину, с тем единственным различием, что структура базы будет представлена в Solution Explorer в качестве *.sql файлов.
Так же мы всегда можем добавить новые элементы воспользовавшись диалоговым окном Add New Item, в котором перечислены все возможные объекты базы данных:
Добавим таблицу TestTable. Новый файл-скрипт TestTable.sql будет добавлен в корень проекта и для удобства мы его перенесём в папку Tables.
Для создания схемы таблицы мы можем использовать как панель дизайнера, так и панель T-SQL. Все изменения сделанные на одной панели будут сразу же отображены в другой.
Так же мы можем изменять существующие скрипты. Visual Studio для этого предоставляет удобный и любимый всеми IntelliSense. Так как мы не подключены к физической базе данных, Visual Studio для корректной работы IntelliSence парсит все скрипты в проекте, что позволяет ей мгновенно отражать последние изменения сделанные в схеме базы данных.
Хочу обратить внимание на то, что мы не должны заботиться об инкрементных изменениях нашей базы. Вместо этого мы всегда создаём скрипты так, как если бы объекты создавались заново. При публикации DACPAC пакета миграционные скрипты будут сгенерированы автоматически, путём сравнения DACPAC файла и схемы в целевой базе (target Database).
Как уже упоминалось, DACPAC содержит не только схему и данные, но ещё и ряд полезных настроек, для просмотра/редактирования которых мы можем воспользоваться окном свойств нашего проекта.
Свойство Target platform позволяет выставить версию базы данных, для которой будут валидироваться скрипты в проекте. Минимальная поддерживаемая версия MS SQL Server 2005. Если например задать версию базы 2005 и попробовать создать колонку типа Geography, то при компиляции мы получим следующее сообщение:
На закладке Project Settings, мы можем задать настройки базы данных, нажав на кнопку Database Settings. Нажав на неё мы увидим диалог с настройками, аналогичные тем, что мы привыкли видеть в SQL Server Management Studio:
Так же хочется упомянуть закладку SQLCMD Variables, на которой мы можем задавать различные переменные для дальнейшего их использования в наших скриптах.
Публикация DACPAC файла (publishing)
После того, как все настройки заданы и *.sql скрипты добавлены/обновлены мы можем применить изменения к целевой базе (target database). Для этого идём в меню Build->Publish или же выбираем аналогичный пункт в контекстном меню проекта.
В появившемся диалоговом окне задаём строку подключения к базе назначения (target database) и если необходимо — дополнительные настройки, нажав на кнопку Advanced:
Большинство настроек понятны без дополнительного описания, поэтому не будем на них останавливаться подробно, но рекомендую с ними ознакомиться, что бы в случае невозможности успешно «запаблишить» проект, вы знали в чём может быть проблема.
Если требуется производить публикацию в целевую базу данных более одного раза, то настройки можно сохранить в publish профиль, нажав на кнопку Create Profile. Это добавит в наш проект файл с расширением *.publish.xml и в дальнейшем мы сможем произвести публикацию без необходимости вводить настройки ещё раз. Если же какой-то из профилей публикации должен быть использован по умолчанию, то можно в контекстном меню файла публикации выбрать пункт Set As Default Publish Profile. Этот профиль будет автоматически загружаться в диалог Publish.
Все необходимые изменения, можно применить сразу, нажав на кнопку Publish. А можно отложить на потом, сгенерировав соответствующий миграционный скрип (кнопка Generate Script) — он будет содержать все необходимые инструкции для приведения базы назначения к требуемому состоянию.
Если же у нас нет доступа к базе данных, то мы можем передать результаты нашего труда в виде DACPAC файла, который создаётся путём компиляции проекта и находится в ../bin/Debug/Database1.dacpac. Отдав файл, например, администратору базы данных, тот в свою очередь сможет воспользоваться любым удобным способом для применения изменений в целевой базе.
Способы публикации DACPAC (publishing):
- Бесплатная редакция Visual Studio с установленными SSDT (в частности для publish используются клиентские инструменты, входящие в состав DAC Framework, устанавливаемые вместе с SSDT)
- MS SQL Server Management Studio + DAC Framework
- Консольная утилита SqlPackage.exe
- Windows PowerShell (пример)
- Data-tier Application Framework (DACFx) позволяющий поставить DACPAC файл, путём вызова методов из C# программы (документация и пример)
Data Seeding
В нашем проекте создадим папку DataSeeding (имя не имеет значения) и в неё добавим новый скрипт.
По сути все типы в разделе User Script являются обычными *.sql скриптами и отличаются лишь значением свойства “Build Action” у вновь созданного файла.
Логика из файла PostDeployment.sql будет выполнена после применения всех изменений схемы базы данных. В случае создания PreDeployment.sql — логика выполнится перед применением изменений схемы.
Значение свойства Build Action для файлов созданных через шаблон Script (Not in Build) будет установлено в «None». Они полезные для удобного структурирования команд в отдельных файлах, которые вызываются из Pre или Post Deployment скриптов.
Файлы созданные через шаблон Script имеют значение Build Action равное «Build», и их содержимое добавляется к результирующему скрипту, который выполняется при publish’e DACPAC файла в момент изменения схемы базы.
В виду того, что в проекте может быть только один Post Deployment script и его размер может быстро вырасти, рекомендуется логику вставки данных выносить в отдельные скрипты. Именно поэтому мы добавим файл типа Script (Not in Build), а в Post Deployment script добавим ссылку на него. Вот как это будет выглядеть:
Теперь при публикации нашего проекта, в базе всегда будут вставлены 2 записи в таблицу Employees.
Tools -> SQL Server
На ряду с возможностью создания Database проекта, установка SSDT добавляет ряд полезных инструментов, доступных из меню Tools.
Думаю, что из названия и так понятно, что каждый из пунктов делает. Как пример, покажу удобный графический инструмент сравнения схем. В качестве источника и целевого объекта можно выбрать один из трех вариантов:
Мы сравним наш проект с локальной базой данных. Результат сравнения будет выглядеть следующим образом:
В результирующем окне мы можем применить различные способы группировки (по схеме, по типу объектов и по требуемому действию) для более удобного просмотра предлагаемых изменений и выбрать те объекты, которые требуется обновить. Для того, что бы применить миграционный скрипт необходимо нажать кнопку Update – это приведёт Target DB к состоянию нашего проекта.
Refactoring
Это моя любимая фича. Для примера, покажем как переименовать колонку LastName в таблице Employees. Для этого открываем скрипт создания таблицы, в редакторе таблицы выделяем колонку LastName и в меню SQL -> Refactor выбираем пункт Rename:
Задаём новое имя:
Просматриваем последствия переименования и применяем предложенные изменения:
В результате все скрипты будут изменены и после первого рефакторинга в проект будет добавлен специальный файл *.refactoring. В нём будут сохраняться все изменения схемы в историческом порядке в формате XML документа. Эти данные будут полезны при генерации миграционного скрипта и позволят более правильно мигрировать схему и данные.
Unit testing
Создадим наш первый юнит тест. Для этого вызовем контекстное меню для хранимой процедуры, которую мы хотим протестировать:
В появившемся диалоговом окне у нас будет возможность выбрать дополнительные объекты (если они есть) и задать тип и имя тестового проекта и имя класса, содержащего код юнит теста:
Создав проект нам будет предложено выбрать базу данных на которой будут запускаться тесты, а также некоторые настройки проекта:
После успешного создания у нас откроется графический редактор юнит теста, в нижней части которого будут представлены различные проверки для тестируемого объекта. В нашем случае это хранимая процедура EmployeeGetList.
Наша задача сводится к тому, что бы написать необходимый Sql скрипт и задать требуемые условия проверки, которые будут произведены после выполнения кода скрипта. Проверки могут быть разные: время исполнения, количество возращённых строк, Checksum возвращённых данных и т.п. Полный список проверок можно найти в выпадающем меню под текстом скрипта и над таблицей проверок. Для каждой проверки можно задать ряд настроек через стандартную панель Properties. Для её вызова необходимо в контекстном меню конкретной проверки выбрать пункт Properties.
Например, вот так будет выглядеть проверка возвращаемого количества строк:
А вот так можно проверить Checksum:
По сути эта проверка выполняет наш скрипт (получает 2 строки из таблицы Employees) и на полученных данных находит Checksum. Наша задача на этапе создания теста, найти эталонные данные, на них посчитать Checksum и в дальнейшем с этим значением будет производиться сверка полученного результата. Иными словами, это удобный способ убедиться, что результат хранимой процедуры не меняется. Для получения контрольного значения Checksum, необходимо воспользоваться кнопкой в окне Properties, которая позволит выбрать эталонную базу и получить эталонное значение Cheсksum:
Заключение
Надеюсь этот краткий обзор позволил получить общее представление, что такое SSDT и как они могут быть полезны в вашем проекте. Безусловно тут не были рассмотрены все детали. Но вам, как разработчику это и не нужно. Вы должны просто иметь общее представление списка возможностей, а дальнейшее их использование надеюсь будет интуитивно понятным, т.к. разработчики SSDT хорошо потрудились и снабдили инструменты огромным количеством помощников (wizards) и контекстных подсказок.
