 Возможно, я скажу банальную вещь, но прошедший год был хорошим годом для С++!
Возможно, я скажу банальную вещь, но прошедший год был хорошим годом для С++!Просто факты:
- Вышла Visual Studio 2015 с отличной поддержкой возможностей С++14/17 и даже нескольких экспериментальных вещей
- Вышел долгожданный GCC 5.0
- С++ набрал серьёзную популярность. Где-то с июля — третье место в Tiobe Ranking
- На конференции CppCon 2015 было сделано несколько важных анонсов
А теперь об этом и другом немного подробнее
Статус поддержки С++11
Компиляторы Clang, GCC и Intel Compiler имеют полную поддержку C++11.
В Visual Studio не хватает двух вещей: Expression SFINAE — N2634 и C99 preprocessor — N1653
Статус поддержки С++14
Clang и GCC полностью поддерживают C++14. А в общем дела обстоят так:
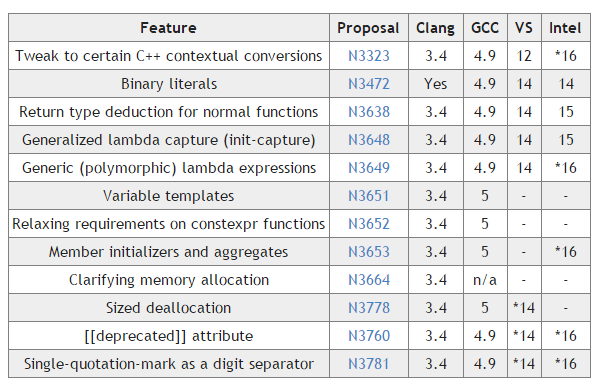
Изменения с прошлого года отмечены звёздочкой (*)
В Visual Studio 2015 компилятор С++ стал заметно ближе к полному соответствию стандарту, были реализованы Sized deallocation, атрибут [[deprecated]] и поддержка одинарной кавычки в качестве разделителя разрядов в числах.
Хороший прогресс показал и компилятор Intel — они добавили поддержку обобщённых лямбда-функций, инициализацию членов класса (включая агрегатную), плюс всё те же аттрибут [[deprecated]] и поддержку одинарной кавычки в качестве разделителя разрядов в числах.
Статус поддержки С++17
Очевидно, большинство из нас ждёт этого грандиозного события, которое должно уже вот-вот произойти: стандартизации С++17! Да, компиляторам нужно ещё поработать над поддержкой С++11/14, но большинство фич уже реализованы или находятся на последних этапах реализации. Команды разработчиков всех основных компиляторов уже активно экспериментируют с некоторыми новыми фичами будущего стандарта С++17.
Но что включает в себя С++17?
Для полного понимания предмета лучше всего будет прочитать "Мысли по поводу С++17" от Страуструпа. Он выделил три основных приоритета:
- Улучшить поддержку масштабирования для больших проектов
- Добавить поддержку высокоуровневого параллелизма
- Сделать ядро языка проще, улучшить STL
Кроме того, С++17 запланирован быть мажорным релизом языка, т.е. кроме мелких апдейтов мы получим и нечто более крупное:
- Модули — n4465, n4466
- Контракты — n4415
- ASIO для работы с сетью — n4478
- SIMD-векторизация — n4454
- Улучшенные futures — n3857, n3865
- Корутины — N4402, n4398
- Транзакционная память — n4302
- Параллельные алгоритмы — n4409
- Концепты — n3701, n4361
- Концепты в стандартной библиотеке — n4263
- Ranges — n4128, n4382
- Унифицированный синтаксис вызова — n4474
- Оператор точка — n4477
- array_view и string_view — n4480
- Массивы в стеке — n4294
- optional — n4480 — optional
- Свертка выражений — N4295
- __has_include в условиях препроцессора — P0061R1
- Файловая система — n4099
- Множество более мелких изменений
Вот отличный обзор всех потенциальных возможностей С++17.
Те фичи, которые не успеют войти в С++17, войдут в следующий стандарт С++20, который планируется как минорный. С++20 отполирует С++17, как С++14 отполировал С++11.
Core Guidelines
На конференции CppCon в ключевой презентации Бьёрн Страуструп сделал важный анонс: Core Guidelines!
Полная версия гайдлайнов находится на GitHub, вот выдержка из вступления:
«С++ Core Guidelines являются результатом совместной работы группы авторов под руководством Бьёрна Страуструпа, как, собственно, и сам язык С++. В разработку этих рекомендаций вложено много человеко-лет труда людей из множества организаций. Дизайн данных гайдлайнов предполагает их общее применение и широкое распространение, что однако, не исключает ваше право скопировать и изменить их под нужды вашей организации.
Целью разработки данных инструкций является помочь людям использовать современный С++ эффективно. Под „современным С++“ мы подразумеваем С++11 и С++14 (а вскоре и С++17). Мы поможем представить вам как ваш код, который вы начнёте писать сегодня, будет выглядеть через 5 (или 10) лет.»
Поскольку язык становится богаче, современнеее (но в то же время и проще) будет очень полезно иметь такой справочник. Некоторые хорошо известные правила заменены новыми подходами — например, RAII. Переход на них не так прост, особенно, если вы поддерживаете старую кодовую базу и хотите добавить что-нибудь современное в свой код. Core Guidelines разрабатываются коллективно, а значит, должны стать достаточно практичным инструментом.
Речь Бьёрна Страуструпа:
Дополнение к ней от Херба Саттера:
Стандартизация С++
В прошлом году прошли две встречи комитета по стандартизации С++: Кона в Октябре и Ленекса в Апреле.
Пару слов о весенней встрече:
И об осенней:
Намечены следующие встречи комитета по стандартизации в 2016-ом году: во Флориде в феврале и в Финляндии в июне (на этой встрече планируется голосование за стандарт С++17).
Новости мира компиляторов
Visual Studio
- Поддержка С++11/14/17 в VS 2015 RTM
- MSDN о С++11/14/17
- Ссылка на последнюю версию поддерживаемого стандарта
- Поддержка constexpr в Visual Studio (http://blogs.msdn.com/b/vcblog/archive/2015/06/02/constexpr-complete-for-vs-2015-rtm-c-11-compiler-c-17-stl.aspx)
- Омоложение компилятора С++ от Microsoft
- Экспериментальная поддержка:
GCC
- Лайт-концепты добавлены в основную ветку GCC
- Вышел GCC 5.0 (список изменений)
- Текущая поддержка стандартов С++1y/C++14 в GCC
Clang
- Текущий статус поддержки новых стандартов
- Теперь Clang можно использовать в Visual Studio для компиляции под несколько платформ. А сам Clang можно использовать под Windows.
Intel compiler
- Вышла версия 16 (презентация, видео)
- Текущий статус поддержки С++11
- Текущий статус поддержки С++14
Конференции
В прошлом году прошло две важных конференции: CppCon и MettingCpp
CppCon
MeetingCpp
Первый доклад:
и второй:
Заключение
Как мы видим, комитет по стандартизации С++ прилагает серьёзные усилия по работе над стандартом С++17. К концу года мы можем рассчитывать на принятие черновика этого стандарта. Разработчики чувствуют новую атмосферу перемен и это отражается в рейтингах популярности языка (в Tiobe Rank С++ набрал 8%). Термин «ренессанс С++» уже не миф…
Что ещё лучше — у нас есть множество экспериментальных фич в компиляторах. Мы уже можем экспериментировать с модулями, концептами, корутинами… Это, конечно, пока не безопасно и не может быть применено в продакшн-коде, но в плане обучения и тестирования очень интересно. Кроме того, это даёт возможность получить некоторый фидбек, который может повлиять на финальную спецификацию всех этих вещей.
Команда разработчиков VisualStudio становится намного более открытой, это заметно начиная с VS2015. Вы не только можете создавать мультиплатформенные приложения, но и весьма оперативно получать обновления с новыми интересными фичами.
Все компиляторы поддерживают С++11/14 на достаточно хорошем уровне, так что больше нет оправданий не переходить на использование этих стандартов. С помощью Core Guidelines данная задача становится ещё проще.
Грустные новости
Буквально пару часов назад Скотт Майерс опубликовал статью-прощание с миром С++. Обсуждение на reddit
А что вы думаете?
- Что вам запомнилось из события около С++ в 2015-ом году?
- Что я пропустил?
Ну и опросничек.
Only registered users can participate in poll. Log in, please.
Какие фичи вы бы хотели непременно увидеть в С++17
70.29% Модули291
18.36% Контракты76
40.1% ASIO для поддержки сети166
19.57% SIMD-векторизация81
20.29% Улучшенные futures84
34.06% Корутины141
21.5% Транзакционная память89
43.96% Параллельные алгоритмы182
22.71% Концепты94
19.81% Концепты в стандартной библиотеке82
26.81% Ranges111
17.87% Унифицированный формат вызова74
17.63% Оператор точка73
12.8% array_view и string_view53
16.67% Массивы в стеке69
22.22% Optional92
11.59% Свертка выражений48
52.66% Файловая система218
7.49% другое31
414 users voted. 266 users abstained.
