
КДПВ: одна из попыток Intel создать демотиватор :)
Почти 10 лет назад Intel сообщил о закрытии проектов Tejas и Jayhawk – продолжателей архитектуры NetBurst (Pentium 4) в направлении увеличения тактовой частоты. Это событие фактически ознаменовало переход в эпоху многоядерных процессоров. Давайте попробуем разобраться чем это было обусловлено, и какие принесло результаты.
Для того, чтобы понять причины и масштабы случившегося с этим переходом, предлагаю взглянуть на следующий график. Здесь показано число транзисторов, тактовая частота, энергопотребление и степень параллелизма на уровне инструкций (ILP).
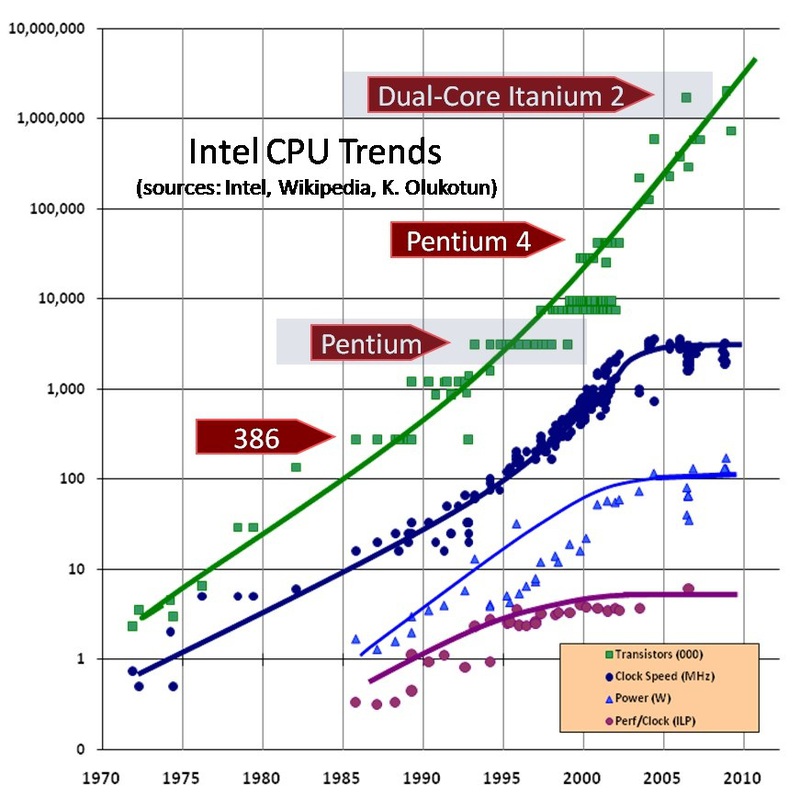
Удвоение числа транзисторов каждые несколько лет, известное как закон Мура – не единственная закономерность. Можно заметить, что до 2000го года тактовая частота и потребляемая мощность росли согласно аналогичным законам. Выполнение закона Мура на протяжении десятилетий было возможно потому, что размеры транзисторов всё уменьшались и уменьшались, следуя еще одному закону, известному как закон Деннарда (Dennard's scaling). Согласно этому закону, в идеальных условиях такое уменьшение транзисторов при неизменной площади процессора не требовало роста энергопотребления.
В итоге, если первый процессор 8086 при частоте 8MHz потреблял менее 2W, то Pentium 3, работающий на частоте 1GHz, потреблял уже 33W. То есть энергопотребление увеличилось в 17 раз, а тактовая частота за то же время возросла в 125 раз. Заметим, что производительность за это время выросла гораздо сильнее, т.к. сравнение частот не учитывает таких вещей как появление L1/L2 кэша и out-of-order исполнения, а также развитие суперскалярной архитектуры и конвейеризации. Это время можно по праву называть золотым веком: масштабирование техпроцесса (уменьшение размера транзисторов) оказалось идеей, обеспечившей устойчивый рост производительности на несколько десятилетий.
Сочетание технологических и архитектурных достижений привело к тому, что закон Мура выполнялся до середины 2000х, где и наступил перелом. На 90nm затвор транзистора становится слишком тонким, чтобы предотвратить ток утечки, а энергопотребление уже и так достигло всех мыслимых пределов. Энергопотребление до 100W и системы охлаждения весом до полукилограмма у меня ассоциируются скорее со сварочным аппаратом, да с чем угодно, но только не со сложным вычислительным прибором.
Intel и другие компании смогли несколько продвинуться вперед в вопросах роста производительности и снижения энергопотребления благодаря инновационным решениям, таким, как использование оксида гафния, переход на Tri-Gate транзисторы и т.п. Но каждое такое улучшение было лишь одноразовым, и не могло даже близко сравниться с тем, чего удавалось добиться просто уменьшая транзисторы. Если с 2007 по 2011 год тактовая частота процессоров увеличилась на 33%, то с 1994 по 1998 эта цифра составляла 300%.
Поворот в сторону Multicore
Последние 8 лет Intel и AMD фокусируют свои усилия на многоядерных процессорах, как решении для увеличения производительности. Но есть ряд причин считать, что это направление себя практически исчерпало. В первую очередь – увеличение числа ядер никогда не дает идеального увеличения производительности. Производительность любой параллельной программы ограничена частью кода, не поддающейся распараллеливанию. Это ограничение известно как закон Амдала и иллюстрируется следующим графиком.

Также не следует забывать о таких причинах, как, например, трудность эффективной загрузки большого числа ядер, которые также ухудшают картину.
Хорошим примером того, как использование бОльшего числа ядер приводит к меньшей производительности, мог бы стать AMD Bulldozer. Этот микропроцессор был спроектирован с расчетом на то, что разделяемый кэш и логика позволят сэкономить площадь кристалла и в итоге разместить больше ядер. Но в итоге получилось так, что при использовании всех ядер, энергопотребление чипа вынуждает сильно снизить тактовую частоту, а медленный разделяемый кэш еще сильнее снижает производительность. Несмотря на то, что в целом это был неплохой процессор, увеличение числа ядер даже близко не дало ожидаемой производительности. И AMD не единственные, кто столкнулись с этой проблемой.
Еще одна причина, почему добавление новых ядер не сильно помогает решить проблему – оптимизация приложений. Существует не так много задач, которые как, например, обработка банковских транзакций, можно без особого труда распараллелить практически на любое число ядер.
Некоторые ученые (с аргументацией разной степени убедительности) считают, что задачи реального мира, как и железо, обладают естественным параллелизмом, и остается только создать параллельную модель вычислений и архитектуру. Но большинство известных алгоритмов, используемых для практических задач, последовательные по своей сути. Их распараллеливание не всегда возможно, затратно и не дает желаемых высоких результатов. Особенно это заметно, если взглянуть на компьютерные игры. Разработчики игр хоть и делают прогресс в направлении загрузки работой многоядерных процессоров, но двигаются они в этом направлении очень неспешно. Есть не так много игр, которые, как последние части Battlefield могут загрузить все ядра работой. И, как правило, такие игры создавались с самого начала с возможностью использования многоядерности как основной целью.
(Признаюсь, я не могу проверить информацию про Battlefield. У меня нет ни самой игры, ни компьютера, на котором в нее можно было бы играть. :) )
Можно сказать, что сейчас для Intel или AMD добавление новых ядер – более простая задача, нежели их использование для разработчиков программ.

Появление и ограничения Manycore
Конец эпохи масштабирования техпроцесса привел к тому, что большое количество компаний занялись разработкой специализированных процессорных ядер. Если ранее, в эпоху бурного роста производительности, процессорные архитектуры общего назначения практически вытеснили с рынка специализированные сопроцессоры и платы расширения, то с замедлением роста производительности специализированные решения начали постепенно отвоёвывать назад свои позиции.
Несмотря на заявления ряда компаний, специализированные manycore чипы никоим образом не нарушают закон Мура и не являются исключением из реалий полупроводниковой индустрии. Ограничения энергопотребления и параллелизма для них актуальны так же, как и для любых других процессоров. Что они предлагают – это выбор в пользу менее универсальной, более специализированной архитектуры, способной показывать лучшую производительность на узком круге задач. Также такие решения менее обременены ограничениями на энергопотребление – предел для Intel'овских CPU – 140W, а старшие модели видеокарт от Nvidia находятся в районе 250W.
Архитектура MIC (Many Integrated Cores) от Intel – отчасти это попытка воспользоваться преимуществами отдельного интерфейса к памяти и создать гигантскую ультра-параллельную числодробилку. AMD же тем временем направляет свои усилия на менее требовательные к производительности задачи, разрабатывая архитектуру GCN (Graphics Core Next). Несмотря на то, в какой сегмент рынка метят подобные решения, все они по своей сути предлагают специализированные сопроцессоры для ряда задач, одна из которых – графика.
К сожалению, такой подход не решит проблемы. Интеграция специализированных блоков в процессорный кристалл или их размещение на платах расширения позволяет повысить производительность на ватт потребляемой мощности. Но тот факт, что размеры транзисторов уменьшались и уменьшаются, в то время, как их энергопотребление и тактовая частота – нет, привел к появлению нового понятия – тёмный кремний (dark silicon). Этот термин используется для обозначения бОльшей части микропроцессора, которая не может быть задействована, оставаясь в рамках допустимого энергопотребления.
Исследования в области будущего многоядерных устройств показывают, что независимо от того, как устроен микропроцессор и какова его топология, увеличение числа ядер серьезно ограничено энергопотреблением. Учитывая низкий прирост производительности, добавление новых ядер не дает достаточных преимуществ, чтобы обосновать необходимость и окупить дальнейшее совершенствование техпроцесса. А если взглянуть на масштабы проблемы и то, как давно она требует решения, то становится понятно, что радикального или даже инкрементального решения этой проблемы ожидать со стороны типовых академических или промышленных исследований не приходится.
Необходимо найти новую идею как использовать огромное число транзисторов, которое обеспечивает закон Мура. Иначе рухнет экономическая составляющая разработки нового техпроцесса, а закон Мура перестанет выполняться еще до того, как достигнет своего технологического предела.
В течение нескольких следующих лет мы, вероятно, всё же увидим 14nm и 10nm чипы. Скорее всего, 6-8 ядер станет обычным делом для любого пользователя компьютера, четырехъядерные процессоры проникнут практически всюду, и мы увидим еще более тесную интеграцию CPU и GPU.
Но неясно, что произойдет дальше. Каждое следующее улучшение производительности выглядит крайне незначительным по сравнению с ростом, имевшим место в прошлые десятилетия. Из-за роста токов утечки закон Деннарда перестал выполняться, а новой технологии, способной обеспечить столь же устойчивый рост производительности не наблюдается.
В следующих частях, я расскажу о том, как разработчики пытаются решить эту проблему, об их краткосрочных и более отдаленных планах.
