 В этой статье я хочу рассказать о том, как создатели симуляторов добиваются максимальной производительности моделей процессоров, при этом не жертвуя гибкостью и расширяемостью полного решения. Если кратко, то решение состоит в сосуществовании нескольких движков, наилучшие качества которых используются на различных этапах работы модели.
В этой статье я хочу рассказать о том, как создатели симуляторов добиваются максимальной производительности моделей процессоров, при этом не жертвуя гибкостью и расширяемостью полного решения. Если кратко, то решение состоит в сосуществовании нескольких движков, наилучшие качества которых используются на различных этапах работы модели.Содержимое данной заметки будет основываться на моём опыте разработки функциональных симуляторов, а также на публикациях и технических статьях, описывающих различные симуляторы и виртуальные машины: Wind River Simics, VMWare, Qemu, Bochs и другим. Слово «функциональный» в контексте данной статьи обозначает то, что точность моделей ограничена уровнем набора команд (instruction set architecture, ISA).
Интерпретация
«Интерпретатор» — некто (или нечто), совершающий перевод текста или речи с одного языка на другой «на лету». Смысл этого термина приблизительно сохраняется при его переносе в область вычислительной техники. Оригинальные реализации многих языков программирования: Basic, Unix Shell, Rexx, PHP и др. — были интерпретаторами. Характерная их черта — обработка за один раз одной строки программы, написанной на входном языке. Следующая строка будет преобразована (проинтерпретирована) только тогда, когда в этом возникнет необходимость. По этой причине термин «интерпретатор» обычно противопоставляется понятиям «транслятор» и «компилятор», которые обрабатывают более крупные блоки входного языка: процедуры, файлы, модули и т.п.
Цикл работы
Алгоритм работы симулятора, использующего интерпретацию — это бесконечный цикл (для простоты здесь я опускаю детали, связанные с обработкой прерываний, событиями в периферийных устройствах и т.п.), по структуре напоминающий работу конвейера настоящих процессоров.

О числе стадий в конвейере
Отмечу, что длины конвейеров настоящих процессоров бывают очень разными. У простых микроконтроллеров, например, PIC, может быть всего две стадии. У Intel Pentium 4 последних поколений число стадий доходило до 31. Есть и невообразимо монструозные продукты, например, Xelerated Xelerator X10q имеет 1040 (!) стадий конвейера.
За одну итерацию цикла симулятор исполняет одну инструкцию, последовательно исполняя следующие шаги.
- Fetch — чтение машинного кода из памяти.
- Decode — декодирование текущей функции, заключённой в инструкции, а также её аргументов — операндов.
- Execute — исполнение функции над аргументами.
- Writeback — запись результатов память.
- Advance PC — продвижения регистра-указателя инструкций (PC, program counter).
Рассмотрим каждый поподробнее.
Чтение инструкции из памяти
В реальных компьютерах оперативная память размещается достаточно далеко (во многих смыслах) от процессора. Код, как и данные хранится в ней. Требуется доставить порцию машинного кода для последующей обработки в процессор, что и делается на стадии Fetch. Как и в реальных микропроцессорах, имеющих перед памятью более быстрый кэш инструкций, модель может также использовать кэширование ранее прочитанных инструкций. И опять же, как и в реальных системах, чтение памяти вполне может завершиться возникновением исключения, которое необходимо будет просимулировать.
Декодирование
Задача декодера, как аппаратного, так и симулируемого — вычленить из последовательности байт, полученных из памяти, отдельную инструкцию и разобрать, что же она означает.
Написание модели декодера — не самая простая вещь. Создателю симулятора приходится иметь дело со многими особенностями гостевых архитектур (об одной из них, присущей IA-32, на Хабре недавно писал yulyugin). Само число инструкций, которые надо уметь различить, может быть велико.
Если написание симулятора начинается с чтения документации на ISA, то создание декодера в его составе — с просмотра таблиц инструкций, чтобы получить представление о масштабах бедствия. Приведу несколько примеров таблиц кодировок инструкций для различных архитектур. Все они взяты из официальных мануалов или сопутствующих материалов.
Для ARM [3], 32-битные инструкции.
Таблица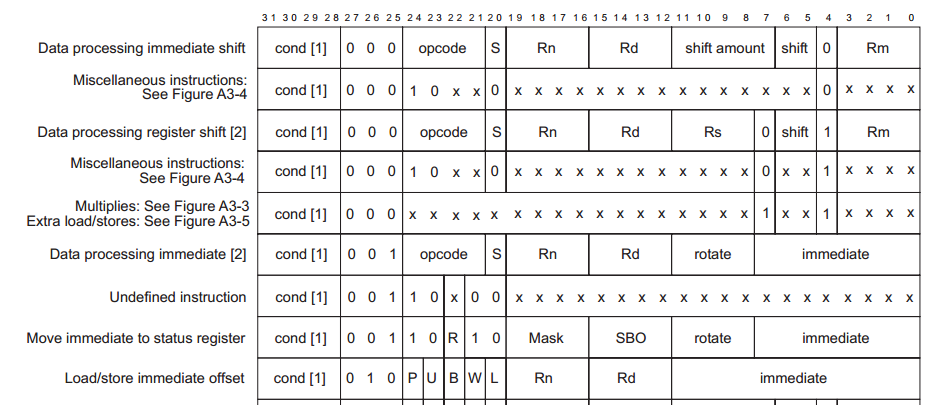

Для PowerPC 3.0 [4]
Таблица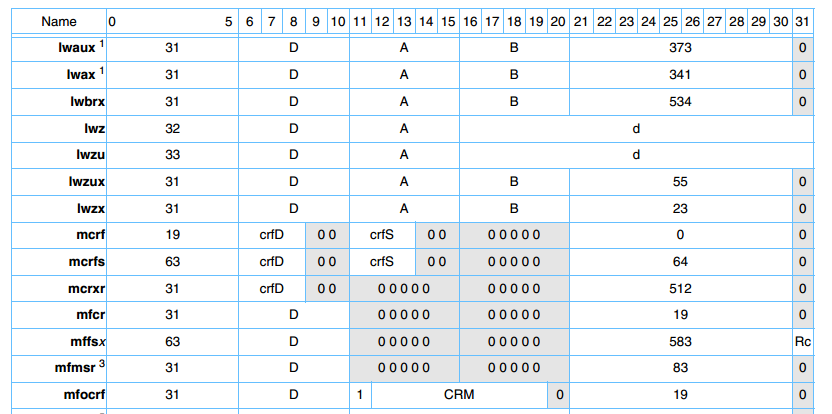

Для Itanium 2.3 [2]. Мне всегда нравилась задорная цветастость этого руководства!
Таблица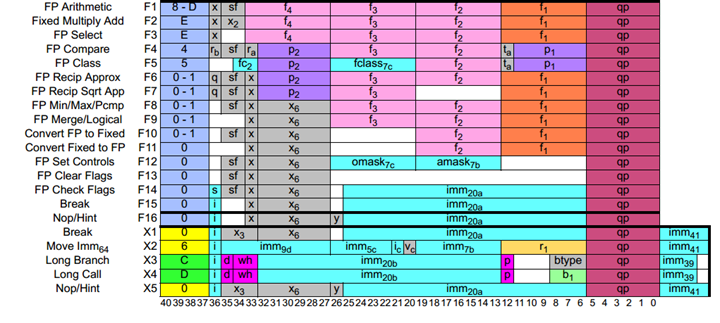

Для IA-32 [5]. Диаграмма, показывающая все поля, использующиеся после введения префикса EVEX.
Таблица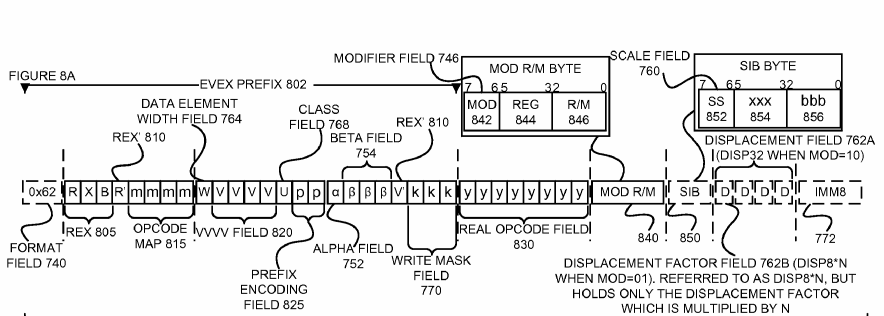

Жуткая схема, но мне она помогла понять, что вообще происходит в AVX3.
Естественно, что унылой ручной работе по вбиванию содержимого таблиц в код часто предпочитают автоматизацию — генерацию кода по описанию, сделанном на специализированном языке. Для сложных архитектур, или же в случаях, когда необходимо иметь общий фреймворк для создания симуляторов множества различных систем, затраты на создание такого языка и инструментов его трансляции окупаются.
Исполнение
Исполнение (execute) состоит из непосредственной симуляции функции уже декодированной инструкции. Это может быть вычисление результата арифметической или логической операции, чтение или запись в память, изменение текущего режима процессора или передача контроля управления при ветвлении или вызове процедуры.
Каждой распознанной инструкции должна соответствовать сервисная процедура (service routine). В самой простой схеме интерпретатора её выбор производится по коду операции инструкции (опкоду) с помощью конструкции множественного выбора — переключателя — используемого языка программирования. В языке Си это оператор switch. Данная схема получила название «переключаемая» (switched):
switch (opcode) {
case OPERATION1: do_op1(arg1, arg2); break;
case OPERATION2: do_op2(arg1, arg2); break;
case OPERATION3: do_op3(arg1, arg2); break;
...
default: do_undefined; break;
}
Существует несколько альтернатив переключаемой схеме интерпретации, характеризующихся большей скоростью работы [10], однако о них я напишу в другой раз.
Как и создание декодера вручную, написание сервисных процедур может оказаться утомительным занятием, особенно если они похожи друг на друга. Например, в системе команд могут быть семейства инструкций, имеющих одинаковый смысл, но различающихся по ширине обрабатываемого вектора и элементов, а также положением обрабатываемых данных (в регистре или в памяти). Руки сами тянутся к методам обобщённого программирования. Или же хочется написать генератор кода, что возьмёт на себя рутину.
Опять же, сервисные процедуры должны быть синхронизованны с декодером: при правке набора команд надо не забывать про добавление/удаление семантики для их симуляции. Поэтому самым разумным оказывается иметь такое совмещённое описание, чтобы из него автоматически производить и декодер, и процедуры, и (до кучи) дизассемблер.
Запись в память
Работа с симулируемой памятью, даже если рассматривать её только с точностью, достаточной для функциональной модели, тоже нетривиальна. Здесь надо учитывать многое: гостевую схему преобразования виртуальных адресов в физические, отношение гостевой системы к выравниванию данных, порядок байт в машинном слове (endianness), попадание доступа в отображённое на память устройство (memory mapped input/output), разрешения страницы на чтение/запись/исполнение, опциональную сегментацию (уфф!)…
Запись или чтение памяти может привести к исключению, которое, как и в случае fetch, необходимо корректно просимулировать.
Продвижение PC
PC (program counter) — регистр, хранящий адрес текущей инструкции. В разных системах и книгах он зовётся по-разному: IP/EIP/RIP, pc, IP… Для «линейных» операций его надо просто продвинуть на длину только что обработанной инструкции. Но для команд ветвления, вызова процедур, программных прерываний он будет меняться более сложным образом, соответствующим их семантике.
Промежуточный итог
Интерпретатор — практически всегда первый тип модели, создаваемый для новой архитектуры процессора. По этой причине их существует великое множество, и перечисление более-менее известных заняло бы много места. Здесь приведу лишь пару примеров: Bochs [6], Zsim [7]. Хочу также порекомендовать FAQ Марата Файзуллина.
Двоичная трансляция
Главное достоинство моделей, основанных на интерпретации — их простота. Главный недостаток — низкая скорость работы.
Как и в случае с языками высокого уровня, для ускорения можно использовать технику, исторически называвшуюся трансляцией, но сейчас чаще именуемую компиляцией. Так, название языка Fortran — это сокращение от FORmula TRANslator.
Вместо того, чтобы тратить время на разбор и исполнение каждой инструкции каждый раз, когда она встречается, можно просто перевести достаточно длинный блок гостевого кода в эквивалентный по смыслу блок машинного хозяйской системы. Затем, при симуляции, достаточно передать управление на него, и он будет исполняться «без замедления». Это идея работает потому, что на практике код, однажды исполненный, скорее всего будет вскоре будет исполнен снова — ведь большую часть времени программы проводят в циклах относительно небольшого размера.
В контексте симуляции данная техника получила название «двоичная трансляция» (ДТ), или «бинарная трансляция» (binary translation). Понятие это очень близко к «компиляции времени исполнения» (just in time compilation, JIT).
Ниже я опишу одну из простых используемых на практике схем.
Капсулы и блоки трансляции
На вход процесса трансляции подаётся группа машинных команд, находящихся рядом (например, на одной странице) и/или исполняющихся последовательно (трасса). Они декодирутся. Затем каждая гостевая инструкция ассоциируется с блоком хозяйского кода, называемого капсулой. Несколько капсул собираются в более крупные образования, именуемые блоками трансляции. Каждый из них может иметь одну или более точек входа, а также несколько мест, из которых управление может его покинуть.

То, что в настоящей аппаратуре делается «железом», в симуляторе должна делать программа. Поэтому длина капсулы в среднем превышает одну инструкцию, которую она призвана представлять.
Может ли капсула быть короче?
Инструкции, которые при функциональной симуляции не вызывают видимых архитектурных эффектов, могут быть представлены пустой капсулой в ноль команд, особенно если блок трансляции перед исполнением подвергается оптимизациям. Примеры: варианты инструкции NOP (no-operation), инструкции предзагрузки данных (prefetch), барьеры (fence).
Читатели, знакомые с организацией компиляторов, почувствуют сходство происходящего в ДТ с компиляцией. Они будут правы: в ДТ можно выделить работу фронтенда, фаз оптимизации и кодогенерации в бэкенде. Хочу подчеркнуть отличия ДТ от компиляции с языков высокого яровня.
Проблема обнаружения кода
В машинном коде содержится меньше информации о программе, её структурах, чем в её исходном коде. Вытекающую из этого задачу обнаружения кода (code discovery) можно разделить на несколько подзадач.
- В оперативной памяти данные (переменные, массивы, константы, строки и т.д.) и код программ, их обрабатывающий, хранятся вместе. Никаких границ между ними не обозначено. Двоичная трансляция блоков данных (рассматриваемых как код!) бесполезна: управление на них никогда не будет передано, — и даже вредна: затрачиваемое на это время уходит впустую.
- В архитектурах, допускающих переменную длину инструкций, очень важен адрес, с которого начинается их декодирование. Сдвиг даже на один байт приводит к полной смене смысла последовательности.
- Результат декодирования зависит от режима процессора. Например, для архитектуры ARM есть фактически два набора инструкций — полный 32 битный и урезанный 16-битный Thumb, переход между которыми происходит с помощью команды BX .
Частный случай этой задачи — пересчёт относительных смещений для адресов перехода инструкций ветвления. На рисунке ниже приведён пример, в котором исходный блок кода заканчивается переходом на шесть байт назад. В сгенерированном коде граница инструкций, на которую следует перейти, находится в другом месте.

Самомодифицирующися код
Исполняемый код программ и обрабатываемые ими данные располагаются в одной физической памяти. Поэтому возможно в процессе исполнения изменять машинный код. Это используется, например, операционными системами для загрузки в память приложений и динамических библиотек, полиморфными вирусами для сокрытия своего присутствия. Назовём такую ситуацию самомодифицирующийся код (self-modifying code, SMC). В случае двоичной трансляции это означает, что блоки трансляции могут устаревать — делаться некорректными, если гостевой код, из которого они были получены, изменился.
Бывало ли у вас такое?
Пишешь код, делаешь изменение, запускаешь приложение, чтобы увидеть, как изменение повлияло на исполнение, а эффекта нет. Бросаешься разбираться, всё переберёшь, а оказывается, что забыл перекомпилировать приложение. Произошла рассинхронизация исходного кода и его трансляции в машинный.
При симуляции приходится отслеживать все записи в память и помечать затронутые при этом блоки как устаревшие, требующие повторной трансляции. Операция эта занимает некоторое время, поэтому скорость модели на участках программ с SMC будет низкой: исполнение генерированного кода будет часто прерываться на ретрансляцию.

Ограниченность оптимизаций
После сборки блока трансляции из капсул может оказаться, что его можно дополнительно преобразовать. При этом новый блок будет работать быстрее. Это аналогично применению фаз оптимизаций в компиляторах. Но, если есть вероятность того, что результат исполнения блока после трансформации будет отличаться от исходного, то от неё придётся отказаться. Так как в машинном коде часто содержится меньше информации об алгоритме, чем её содержалось в коде исходном, то и спектр оптимизаций в ДТ меньше, чем у компиляции.
Для проведения ряда преобразований необходимо иметь промежуточное представление для блоков трансляции, позволяющее анализировать графы управления и данных, как это делается в компиляторах. Описанная мною выше схема ДТ с капсулами недостаточно гибка для этого.
Промежуточный итог
Более подробно о техниках двоичной трансляции, применяемых для нужд симуляции, можно прочитать в серии постов на Intel Developer Zone:
Часть 1
Часть 2
Часть 3
Пара ссылок на известные мне симуляторы, в которых двоичный транслятор является основным движком для симуляции: SoftSDV [8], оригинальная реализация Qemu [9].
Прямое исполнение и аппаратная поддержка
Важным на практике случаем ДТ является ситуация, когда архитектуры гостя и хозяина совпадают (или почти совпадают). При этом возникает возможность значительно упростить трансляцию — в некоторых случаях она сводится к копированию гостевого кода как хозяйского или даже исполнению его «на месте», без дублирования. Подобные режимы симуляции имеют общее название «прямое исполнение» (direct execution, DEX).
Общая идея
Казалось бы, если программа уже выражена в машинном языке хозяйской системы, достаточно передать управление на её начало. Дальше аппаратура сама с максимальной скоростью будет исполнять инструкции.
Почему это не работает
Конечно же, это не будет работать. Гостевое приложение не должно иметь возможность определить факт того, что оно исполняется внутри симулятора, и тем более влиять на его работу, например, вызвав исключение. Опишу лишь часть осложнений, которые делают наивную схему DEX несостоятельной.
- Доступы к памяти. Адресное пространство гостя занимает лишь часть памяти симулятора. Данные и код симулируемой системы не обязательно будут находиться по тем же адресам, по которым они располагались в реальности.
- Возврат управления. Как можно «заставить» симулируемое приложение отдать управление обратно симулятору?
- Привилегированные инструкции. Симулятор работает в непривилегированном режиме пользовательского приложения, а гостевой код может содержать инструкции системных режимов. Попытка их исполнения приведёт к аварийному завершению симулятора.
Существуют программы двоичной инструментации, позволяющие «незаметно» для гостевого приложения подменять машинный код выбранных инструкций, например, Pin от Intel или DynamoRIO от Hewlett-Packard. Таким образом, можно построить симулятор, просматривающий гостевой код и заменяющий его «опасные» участки перед передачей ему управления. Можно сказать, что инструментация — это вариант ДТ, в котором почти все капсулы совпадают с исходными инструкциями, и только «трудные» команды преобразуются.
Аппаратная поддержка
Некоторые микропроцессоры позволяют поддержать прямое исполнение гостевого кода в «песочнице», на аппаратном уровне выполняя работу по перехвату опасных операций. Этот подход лучше двоичной инструментации как по надёжности, так и по скорости работы. Аппаратно поддерживаемое DEX — это виртуализация, использованная для нужд симуляции.
Я постарался осветить классические условия эффективной виртуализации и состояние дел в современных системах в моём посте «Аппаратная виртуализация. Теория, реальность и поддержка в архитектурах процессоров».
Ограничения
Виртуализация является самым быстрым из рассмотренных движков симуляции. Одновременно она в каком-то смысле самая негибкая, так как сильно завязана на возможности аппаратуры.
- Аппаратно поддерживаемое прямое исполнение невозможно, если архитектуры гостя или хозяина не совпадают. Код ARM на IA-32 или программа для MIPS на PowerPC волшебным образом не побежит.
- Не все режимы процессора могут поддерживаться внутри гостя. Например, древний 16-битный реальный режим IA-32 затруднительно исполнять с помощью VMX, если нет возможностей т.н. Unrestricted Guest.
- Высокая стоимость входа и выхода в гостевой режим может убить выигрыш в скорости.
- Сложнее наблюдать и управлять работой гостевых приложений. Становится затруднительно ставить точки останова, с точностью до инструкции выполнять пошаговое исполнение, изменять семантику отдельных инструкций и т.д.
- Симулятор требует наличия модуля ядра/драйвера ОС, который будет осуществлять переключение между режимами. Написание, отладка этого модуля требует специфический знаний и инструментов.
Промежуточный итог
Довольно большое число симуляторов используют аппаратную поддержку виртуализации Intel VT-x для своих нужд. Можно упомянуть Wind River Simics, Oracle VirtualBox, Qemu и продукты VMWare.
Собираем всё вместе
Итак, имеются как минимум три подхода: интерпретация, двоичная трансляция и прямое исполнение, — которые можно использовать для создания программных моделей. Резюмирую их сильные и слабые стороны.
- Лёгкость реализации в коде. Самый простой в написании — интерпретатор. При этом сложно сказать, что труднее написать: ДТ или DEX — это зависит от свойств хозяйской системы.
- Переносимость между хозяйскими архитектурами. Интерпретатор берёт первое место: если он правильно написан, его код будет переносим. ДТ не сильно отстаёт при условии, что его генератор кода можно перенацелить (retarget) на другую систему. DEX не работает при существенных различиях в архитектурах, т.к. завязан на конкретную аппаратуру.
- Простота добавления функциональности, например новых инструкций ЦПУ. Вновь интерпретатор лидирует с отрывом. ДТ требует больше усилий: необходимо писать капсулы. DEX не позволяет выйти за границы хозяйской аппаратуры; новые инструкции не будут распознаны.
- Скорость работы. Тут интерпретатор в целом сильно проигрывает двум остальным движкам. ДТ обычно также уступает DEX. Однако вспомним, что слабая сторона ДТ — это SMC, а у DEX — это частые выходы из виртуализации, например, на привилегированных инструкциях.
Вывод неутешителен. Одновременно двум главным условиям — скорость и универсальность — не удовлетворяет ни одна схема. Более того, на разных этапах работы одного и того же сценария симуляции предпочтительной может оказаться любая схема.
Что же делать? Переключать передачу в зависимости от режима движения! Использовать все три, включая каждую из них, когда она наиболее выгодна!
Можно сформулировать некоторые рекомендации, определяющие условия переключения между режимами. Скорее, это даже эвристики.
- Если быстрый режим недоступен, переходить на более медленный. Например, не все инструкции могут поддерживаться ДТ или DEX.
- Переключаться с быстрой модели на медленную, если быстрая перестала быть таковой. Если детектрован SMC, то режим ДТ лучше временно отключить.
- Откладывать трансляцию порции кода до тех пор, пока не станет ясно, что этот код — «горячий». Зачем тратить время на генерацию блока, который будет исполнен лишь несколько раз?
- Не использовать DEX, если есть высокая вероятность скорого выхода по исключению.
- Необходимо предоставлять пользователю возможность следить за текущей скоростью моделирования с разбиением по режимам. Ведь эвристики ограничены в своей прозорливости. Часто только человек может определить меры, необходимые для её ускорения.
Платой за скорость и гибкость является необходимость поддерживать фактически три независимых модели. Вылавливать в них ошибки, устранять «мелкие» различия в поведении, натыкаться на странности реализаций виртуализации разных поколений аппаратуры. В общем, пытаться обуздать трёхглавого Змея Горыныча.

Иван Билибин. Змей Горыныч. 1912.
Заключение
Заинтересовавшихся в вопросах внутреннего устройства программных моделей компьютеров я хочу отослать к учебнику [1]. Электронный вариант второго издания, а также «бета-версия» третьего доступна на сайте курса «Основы программного моделирования».
В этой заметке ни слова не было сказано об ещё одном способе повышения скорости моделирования — параллельном исполнении. Об проблемах, связанных с построением таких симуляторов, и их решениях рассказывается в другой серии постов на Intel Developer Zone: 0, 1, 2, 3.
Задний ход
Взглянув на помещённую в начале статьи картинку ручки-переключателя скоростей, я вдруг подумал: «Хм, а что насчёт заднего хода?» В терминах симуляции это означает, что течение виртуального времени, а также все протекающие в ней процессы, обращаются вспять. Самое интересное, что это осуществимо. Однако это тема для отдельного поста, который я планирую когда-нибудь подготовить.
Литература
[1] Основы программного моделирования ЭВМ: Учебное пособие / Речистов Г.С., Юлюгин Е.А., Иванов А.А., Шишпор П.Л., Щелкунов Н.Н., Гаврилов Д.А. — 2-е изд., испр. и доп. — Издательство МФТИ, 2013.
[2] Intel Corporation. Intel® Itanium® Architecture Software Developer’s Manual Rev. 2.3
[3] ARM Limited. ARM Architecture Reference Manual — 2005
[4] IBM Corporation. PowerPC® Microprocessor Family: The Programming Environments Manual for 64-bit Microprocessors. Version 3.0
[5] J.C.S. Adrian et al. Systems, Apparatuses, and Methods for Blending Two Source Operands into a Single Destination Using a Writemask. US Patent Application Publication. № 2012/0254588 A1
[6] D. Mihoka, S. Shwartsman. Virtualization Without Direct Execution or Jitting: Designing a Portable Virtual Machine Infrastructure bochs.sourceforge.net
[7] Yair Lifshitz, Robert Cohn, Inbal Livni, Omer Tabach, Mark Charney, Kim Hazelwood. Zsim: A Fast Architectural Simulator for ISA Design-Space Exploration www.cs.virginia.edu/kim/docs/wish11zsim.pdf
[8] SoftSDV: A Presilicon Software Development Environment for the IA-64 Architecture / Richard Uhlig, Roman Fishtein, Oren Gershon, Israel Hirsh, Hong Wang // Intel Technology Journal. — 1999. —№ 14. — ISSN: 1535-766X. — noggin.intel.com/content /softsdv-a-pre-silicon-software-development-environment-for-the-ia-64-architecture/
[9] Fabrice Bellard. QEMU, a Fast and Portable Dynamic Translator // FREENIX Track: 2005 USENIX Annual Technical Conference. — 2005. — www.usenix.org/publications/library/proceedings/usenix05/tech/freenix/full_papers/bellard/bellard.pdf
[10] James E.Smith, Ravi Nair. Virtual machines — Versatile Platforms for Systems and Processes. — Elsevier, 2005. — ISBN: 978-1-55860-910-5.
