Текущую ситуацию в области медиакодеков, можно описать буквально несколькими словами: простые решения себя исчерпали. С каждым годом материал для кодирования становится все сложнее, а требования к качеству результата – все выше. В этих условиях, когда лобовая атака уже не дает эффекта, особое значение приобретает оптимизация как кодирования, так и воспроизведения медиа под конкретные платформы с использованием их самых современных возможностей. Чего можно добиться такой оптимизацией, мы покажем на примере перспективного кодека Н.265. В качестве целевой платформы рассмотрим серверное решение Intel — процессор Xeon.
Краткое описание H.265/HEVC
Стандарт H.265/HEVC (High-Efficiency Video Coding — высокоэффективное кодирование видео) — это самый последний стандарт видеокодека, разработанный совместно Международным союзом электросвязи ITU-T и ISO/IEC. Цель этого стандарта — повысить эффективность сжатия и снизить потери данных. H.265/HEVC, по сравнению с предыдущим стандартом H.264/AVC, обладает вдвое более высокой степенью сжатия при равном субъективном качестве изображения. Технология HEVC позволяет поставщикам видео передавать высококачественные видеоматериалы с меньшей нагрузкой на сеть.Отметим основные функциональные новшества, примененные в Н.265:
- Особые возможности для произвольного доступа и сращивания цифровых потоков. В H.264/MPEG-4 AVC цифровой поток должен всегда начинаться с блока адресации IDR, а в HEVC поддерживается произвольный доступ.
- Изображение разделяется на единицы дерева кодирования (CTU), каждая из которых содержит блоки дерева кодирования (CTB) яркости и цветности. Во всех прежних стандартах кодирования видео использовался фиксированный размер массива для выборок яркости — 16×16. HEVC поддерживает блоки CTB разного размера, который выбирается в зависимости от потребностей кодировщика с точки зрения памяти и вычислительной мощности.
- Каждый блок кодирования (СВ) может быть рекурсивно разделен на блоки преобразования (ТВ). Разделение определяется остаточным квадродеревом. В отличие от прежних стандартов в HEVC один блок ТВ может охватывать несколько блоков предсказания (РВ) для перекрестных предсказываемых единиц кодирования (CU).
- Направленное предсказание с 33 различными направлениями ориентации для блоков преобразования (TB) размером от 4×4 до 32×32. Возможное направление предсказания — все 360 градусов. HEVC поддерживает различные методики кодирования предсказания интракадров.
H.265/HEVC налагает исключительно высокие требования по вычислительной мощности и на клиентские устройства, и на внутренние серверы транскодирования.
Проблемы производительности HEVC
Существующий проект HEVC Test Model (HM) реализует только основную функциональность стандарта; фактическая производительность по-прежнему далека от необходимой в реальной среде. Два основных недостатка этого проекта:- Отсутствие параллельной схемы.
- Неэффективная настройка векторизации.

Рисунок 1. Профиль проекта HM — параллельная работа потоков

Рисунок 2. Профиль проекта HM — ресурсоемкий код
Этот кодек HEVC потребляет, по сравнению с H.264, в 100 раз больше ресурсов ЦП на стороне сервера и в 10 раз больше — на стороне клиента.
Кодек H.265/HEVC привлек внимание множества компаний и организаций во всем мире, что повлекло оптимизацию его производительности и фактическую разработку. Существует несколько проектов с открытым исходным кодом.
- OpenHEVC (совместим с HM10.0, оптимизация декодера)
- x265 (совместим с HM, распараллеливание и векторизация)
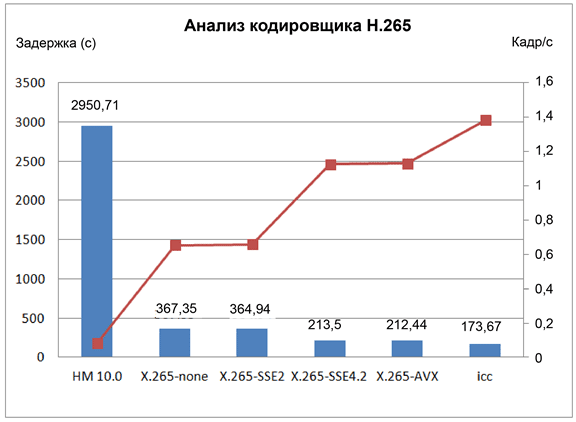
Для оценки производительности кодировщика x265 на платформе с процессорами Intel® Xeon® (E5-2680, 2,7 ГГц, 8*2 физических ядер, кодовое название — Sandy Bridge) мы запустили видео с разрешением 720p и частотой 24 кадра в секунду. Разработчики x265 проделали большую работу для оптимизации исходного стандарта с целью распараллеливания обработки задач и данных. Тем не менее, наш тест показал, что кодек может использовать лишь 6 ядер в системе с 32 логическими ядрами (с включенным SMT). Таким образом, кодек далеко не в полной мере использует ресурсы современных многоядерных платформ.

Рисунок 3. Нагрузка на ЦП в проекте X.265
Рисунок 4. Проект X.265 с настройкой Intel® SIMD
В проекте x265 также были использованы инструкции Intel® SIMD (автогенерация компилятором), что обеспечило повышение производительности более чем на 70%. Вместе с дальнейшей оптимизацией компиляторными опциями, компилятор Intel обеспечивает удвоение производительности на платформе IA. Тем не менее, производительность кодировщика по-прежнему существенно ниже, чем требуется для кодировщика реального времени, особенно для видео высокой четкости с разрешением 1080p.
Ниже мы покажем результаты, достигнутые китайской компанией Strongene при поддержке специалистов компании Intel на пути оптимизации созданного ей кодека H.265/HEVC под различные платформы Intel.
Оптимизация HEVC под платформу Intel® Xeon™
Основную часть самых ресурсоемких функций по обработке видео и изображений составляют интенсивные вычисления блочных данных. Для их оптимизации можно использовать инструкции векторизации Intel® SIMD. В кодировщике в составе кодека Strongene, согласно данным профилирования, с помощью инструкций Intel SSE можно провести ручную векторизацию всех наиболее ресурсоемких функций, таких как кадровая интерполяция низкой сложности с компенсацией движения; целочисленное преобразование без транспозиции; преобразование Адамара; вычисление сумм абсолютных разностей (SAD)/квадратов разности (SSD) с наименьшим избыточным использованием памяти. Мы включили инструкции Intel SSE в виде интринсик-функций, как показано на рис. 5.
Рисунок 5. Пример включения инструкций Intel® SIMD/SSE в кодеке Stongene
Разработчики Strongene переписали все ресурсоемкие функции, чтобы добиться наибольшего прироста производительности кодировщика. На рис. 6 показаны наши данные профилирования в сценарии кодирования видео стандарта 1080p с помощью HEVC. Видно, что 60% ресурсоемких функций обрабатываются инструкциями Intel SIMD.

Рисунок 6. Результаты профилирования функций кодирования Strogene
Инструкции Intel AVX2 с вычислением 256-разрядных целочисленных значений обладают вдвое более высокой производительностью по сравнению с прежним кодом Intel SSE, работающим со 128-разрядными значениями. Набор инструкций Intel AVX2 поддерживается платформой
Intel Xeon (Haswell), выпуск которой начат в 2014 году. Для оценки производительности встроенных функций Intel AVX2 мы используем распространенное вычисление сумм абсолютных разностей для блока 64*64.
Таблица 1. Результаты реализации Intel® SSE и Intel® AVX2
| Циклы ЦП | Исходный код | Intel® SSE | Intel® AVX2 |
|---|---|---|---|
| Запуск 1 | 98877 | 977 | 679 |
| Запуск 2 | 98463 | 1092 | 690 |
| Запуск 3 | 98152 | 978 | 679 |
| Запуск 4 | 98003 | 943 | 679 |
| Запуск 5 | 98118 | 954 | 678 |
| Среднее | 98322,6 | 988,8 | 681 |
| Ускорение | 1,00 | 99,44 | 144,38 |
Как видно из таблицы 1, применение инструкций Intel SSE и Intel AVX2 обеспечивает повышение производительности в 100 раз, при этом код Intel AVX2 дополнительно выигрывает еще 40% по сравнению с Intel SSE.
Как мы видели ранее, в большинстве существующих реализаций используются не все ядра многоядерных платформ. Опираясь на последнюю многоядерную архитектуру Intel Xeon с параллельной зависимостью между алгоритмами на основе CTB, разработчики Strongene предлагают заменить исходные методы OWF и WPP параллельной структурой IFW, а затем разработать трехуровневую схему управления потоками, чтобы гарантировать полное использование структурой IFW всех ядер ЦП для ускорения кодирования HEVC.

Рисунок 7. Параллельная работа потоков и использование ЦП в кодировщике Strongene
За счет применения новой параллельной структуры WHP и полной реализации инструкций Intel SIMD соответственно на уровне задач и уровне данных разработчикам кодировщика Strongene удалось добиться весьма значительного повышения производительности на процессорах x86 для видео с разрешением 1080p, используя вычислительные ресурсы всех ядер, как показано на рис. 8.
Дальнейшая настройка с использованием SMT/HT
Также представляет интерес зависимость производительности кодека от включения в системе широко распространенной на всех платформах с архитектурой Intel одновременной многопоточности (SMT), также называемой технологией гипертрединга (HT).Таблица 2. Скорость кодирования Strongene HEVC на платформе Intel® Xeon®

Как видно из таблицы (показано желтым цветом) на платформе Ivy Bridge (процессор Intel Xeon E5-2697 v2 для отключенного SMT кодирование видео HEVC с разрешением 1080p осуществляется в реальном времени!
Добившись огромнейшего увеличения производительности, мы продолжили изучение возможностей кодирования Strongene HEVC на платформе Ivy Bridge, уделяя внимание скорости потока и вопросам качества.
Таблица 3. Сравнение производительности кодеков H.264 и H.265

В таблице 3 видно, что кодек H.265/HEVC снижает объем данных на 50% при сохранении прежнего качества видеоизображения.
H.265/HEVC, по всей видимости, станет наиболее популярным стандартом видео в ближайшее десятилетие. Во множестве приложений и продуктов мультимедиа в настоящее время реализуется поддержка HEVC. В этом документе мы реализовали основанное на ЦП полнофункциональное решение HEVC реального времени на платформах Intel с новыми технологиями IA. Наше оптимизированное решение на базе процессоров Intel развернуто в компании Xunlei, занимающейся предоставлением услуг видео через Интернет, и будет способствовать повсеместному внедрению и распространению технологии H.265/HEVC.
