Виртуальный. В отличие от большинства модных компьютерных словечек, это понятие обычно соответствует своему словарному определению в тех случаях, когда речь идёт об аппаратуре или программах. Словарь «Random House College Dictionary» определяет «virtual» как «проявляющий свойства и эффекты чего-либо, но не являющийся таковым на самом деле».Последние несколько лет в начале каждого семестра я даю студентам определения основных терминов, используемых в моём курсе: симуляция, эмуляция и виртуализация. И каждый раз я говорю, чтобы мои слова не принимали за стопроцентную правду. Дело в том, что в одних областях технического знания эти термины зачастую трактуются противоположно тому, что принято использовать в других. Нелёгкое это дело — давать определения.
ОригиналVirtual. Unlike most computer buzzwords, this one usually holds true to its dictionary definition when it refers to hardware or software. The Random House College Dictionary defines «virtual» as «being such in force or effect, though not actually or expressly such.» [4]
Видимо, эту проблему заметил не только я. В своей книге Software and System Development using Virtual Platforms, вышедшей в прошлом году, мои коллеги Jakob Engblom и Daniel Aarno в первой главе вводят понятия simulation и emulation и отмечают неоднозначность их толкования в областях разработки программного обеспечения и проектирования аппаратуры.
С беспорядком в толковании этих двух терминов я для себя разобрался и вроде бы смирился. Осталось ещё одно понятие, уже более десяти (на самом деле пятидесяти) лет не теряющее популярности — это «виртуализация». За время своего бытия в категории «buzzword» оно стало сочетаться со множеством других слов. Недавно я осознал, что термин «виртуальная машина» (ВМ) на самом деле используется для обозначения двух хоть и связанных, но различных сущностей. В этой статье я расскажу о двух классах: языковые и системные виртуальные машины. Я покажу сходства и различия между ними, их назначение, классификацию, общие и частные черты в их практической реализации.
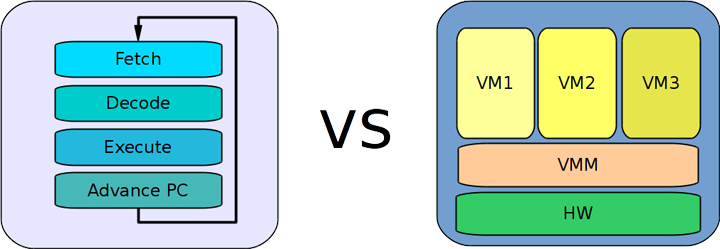
Если говорить широко, то виртуальная машина — это программа, задача которой состоит в реализации спецификаций определённого вычислительного устройства или класса устройств. В этом её главное отличие от «просто» физической машины, реализующей то же самое, но в аппаратуре. Всякая спецификация (архитектура компьютера) чаще всего включает в себя определение интерфейсов устройств и описание переходов между состояниями машины. Однако определение интерфейса, как известно, не должно налагать ограничений на способы его реализации.
Многие из нас, наверное, не замечают, как часто ежедневно они сталкиваются с обеими типами машин — виртуальными и реальными. Например, самый простой калькулятор имеет две реализации — как специализированное устройство и как программа:

И аппаратная машина слева, и виртуальная машина справа предоставляют один и тот же интерфейс — кнопки и экран, — и реализуют одни и те же функции — арифметические, логические, тригонометрические операции над числами, отображаемыми на экране.
Виртуальный калькулятор — это пример виртуальной машины — программной копии того, что изначально существовало только в виде аппаратуры, физической машины, вполне конкретной и осязаемой системы. К системным ВМ мы вернёмся чуть позже.
Языковые ВМ
Другой случай — это когда программа создаётся для чего-то «нереального» с самого начала, например, для языка программирования или среды исполнения (runtime environment). В этом случае такая языковая виртуальная машина будет способом реализации спецификации языка или среды.
Всегда ли нужна ВМ?
Ключевая фраза в предыдущем параграфе — способ реализации. Кроме ВМ, есть и другие способы.
Всякий раз, когда мы берём в руки документацию на новый язык программирования, мы открываем описание «несуществующей» машины. Например, K&R Си — это во многих своих местах нарочно недосказанное описание среды для программ на Си. Большинство реализаций Си являются компиляторами (буду благодарен, если мне подскажут реализации, основанные на ВМ). Для Java описание среды и её границ более чёткое (у её авторов были иные цели и задачи, чем у создателей Си), однако и здесь не диктуется ни использование какой-то конкретной ВМ (на выбор машины от Sun/Oracle, IBM, Microsoft, Apple, GNU и даже Dalvik от Google), ни даже необходимость в ВМ (компилятор GNU GCJ).
Всякий раз, когда мы берём в руки документацию на новый язык программирования, мы открываем описание «несуществующей» машины. Например, K&R Си — это во многих своих местах нарочно недосказанное описание среды для программ на Си. Большинство реализаций Си являются компиляторами (буду благодарен, если мне подскажут реализации, основанные на ВМ). Для Java описание среды и её границ более чёткое (у её авторов были иные цели и задачи, чем у создателей Си), однако и здесь не диктуется ни использование какой-то конкретной ВМ (на выбор машины от Sun/Oracle, IBM, Microsoft, Apple, GNU и даже Dalvik от Google), ни даже необходимость в ВМ (компилятор GNU GCJ).
Языковые ВМ обычно проектируются для исполнения одного гостевого приложения (иногда многопоточного) в одной копии виртуальной среды. Другими словами, они не берут на себя типичные для многопользовательской/многозадачной операционной системы функции разграничения доступа к ресурсам. Задача языковой ВМ — предоставить программе окружение, напрямую не зависящее от деталей (и в какой-то мере ограничений) нижележащей физической системы, таких как используемые в последней процессоры, объёмы ОЗУ и дисков, наличие и особенности периферийных устройств и т.д.
Конечно же, и тут не обойтись без холивара про терминологию. К языковым ВМ (language VMs) я буду относить и то, что называется process virtual machine, и то, что именуется managed runtime environment (MRE).
Два семейства языковых ВМ
Языковая ВМ стоит на середине пути: от языков высокого уровня до машинных кодов того компьютера, на котором она исполняется. Поэтому при создании новой архитектуры языковой ВМ следует учитывать два фактора: удобство преобразования выбранных входных языков и скорость исполнения на конкретных аппаратных системах. От первого будет зависеть универсальность и расширяемость создаваемой среды, а от второго — верхняя граница скорости работы программ для этой ВМ.
Базовой единицей исполнения для ВМ является машинная инструкция. Каждая такая инструкция должна определять операцию, выполняемую над данными, а также местоположение самих данных. Естественно, что набор операций сильно зависит от конкретной ВМ и может варьироваться в широких пределах. «Железные» наборы инструкций в этом куда более ограничены [Я всё ещё жду процессор с аппаратными malloc() и free(), а лучше — с аппаратным сборщиком мусора].
С другой стороны, в подходах к организации обрабатываемых данных среди ВМ не так много разнообразия. Фактически есть две устоявшиеся концепции — хранить данные на стеке (стеках) и использовать выделенный набор регистров.
Стековые ВМ
Такие ВМ хранят все или почти все данные в одном или нескольких стеках. Для обращения к ним используется адресация относительного положения требуемой ячейки от текущей вершины стека. Если у операции есть результат, то он помещается в стек, становясь его новой вершиной. Кроме данных, в стеке могут храниться адреса, используемые при возврате из вызванных подпроцедур в вызывающие. Или же адреса могут быть в отдельном стеке.
Про стековые машины известно и написано много, и я не буду пытаться здесь описать всё, что знаю и чего не знаю. Выделю лишь некоторые ключевые факты.
Отмечу достоинства стековых языковых ВМ:
- Простота трансляции выражений из инфиксной нотации (выражения со скобочками:
a + b * (c / (d - f))) в стековое представление (обратную польскую запись). - Компактность кодировки инструкций. Большинство машинных команд не требуют явных аргументов, так как они работают с вершиной стека.
Нельзя сказать, что в стековой ВМ совсем не может быть выделенных регистров. Как минимум две ячейки иметь приходится: одну для указателя текущей команды, а другую — для указателя на вершину стека. Однако они не всегда доступны для прямой манипуляции в программе, т.е. не каждая машина делает их архитектурно видимыми.
Поскольку речь сейчас только о программных системах, я не буду углубляться в особенности аппаратных стековых машин, с их сильными и слабыми сторонами, такими как обработка прерываний, скорость доступов к памяти, взаимодействие с различными узлами процессора, возможности к параллелизации и т.д. Рекомендую хорошую статью на Википедии в качестве отправной точки.
Примеры
Я не утаю правду, сказав, что за всё время всевозможных языковых виртуальных машин было создано очень много. Пытаться описать их все — безнадёжная затея. Поэтому я далее упомяну лишь некоторые из них в качестве примеров.
Исторические важные примеры стековых языковых ВМ
SECD — абстрактная машина, появившаяся в 1960-х годах и повлиявшая на развитие функциональных языков, в том числе LISP.
P-code — язык виртуальной машины, в который транслировал программы первый компилятор Паскаля университета Калифорнии. Благодаря переносимости p-code и подхода с «самораскруткой» (bootstrapping) компилятора имелась возможность достаточно быстро получить работающий компилятор Паскаля на новых ЭВМ, что во времена отсутствия стандартов на окружение (никаких тебе POSIX в 70-х) и огромного числа несовместимых между собой архитектур ЭВМ было важным фактором для завоевания языком популярности.
Forth — вообще-то Forth нельзя назвать только языковой ВМ. Для кого-то это процедурный язык высокого уровня, для кого-то объектно-ориентированный язык, кому-то — функциональный, кому-то — машинный, а кому-то и вовсе философия проектирования систем (Thinking Forth). Однако именно Форт приходит мне на ум, когда кто-то произносит слова «программирование» и «стек» в одном предложении.
Актуальные языковые ВМ
Java VM — байткод для всем известного «compile once, run everywhere» языка Java (а также для Scala, Clojure и др.) выполняется на стековой ВМ. Сам стек хранит скалярные данные выполняющихся методов, аргументы инструкций, в том числе ссылки на объекты и массивы, которые хранятся в отдельной области-куче.
Common Intermediate Language от Microsoft — основание .NET-фреймворка. В него транслируются C#, F#, VB.NET и множество других менее популярных языков высокого уровня. Байткод выполняется на стековой ВМ. Структура как среды выполнения, так и байткода CIL существенно отличается от JVM; в [1] приводится их сравнение, в том числе показываются их сходства между собой и отличия от обычных аппаратных наборов инструкций.
Таким образом, две самые популярные среды времени исполнения используют стековые языковые ВМ. Возможно, у читателя возник вопрос: если код из байткода чаще всего в конце концов транслируется в настоящий машинный код хозяйской системы, архитектура которой содержит регистры, а не только стек (кто читает эти строки с дисплея машины со стековой машинной архитектурой — поднимите руки!), то почему две самых популярных языковых ВМ используют стековое представление? В [1] приводится следующий довод: «...a stack is amenable to platform independence (the host platform can have any number of registers in its ISA)» — «стек облегчает обеспечение платформонезависимости (хозяйская платформа может иметь любое количество регистров в своём наборе команд)».
Регистровые ВМ
Альтернативный подход к хранению обрабатываемых данных состоит в использовании выделенного набора ячеек памяти с фиксированными именами-номерами — регистрами. Инструкции в основном оперируют с данными на регистрах, при необходимости загружая отсутствующие значения из памяти или выгружая ненужные в память.
В некоторых регистровых архитектурах стек тоже обычно имеется в наличии. Однако он не играет центральной роли в работе ВМ, а используется для поддержки процедурного механизма (и в таком случае не обязательно является напрямую доступным программам).
Особенности регистровых ВМ проще всего увидеть, сравнивая их со стековыми.
- Их машинные инструкции длиннее, так как в них приходится кодировать операнды. В стековых ВМ операнды задаются неявно.
- При работе ВМ происходит меньшее число обращений к памяти. Стековые ВМ вынуждены постоянно перекладывать данные на стеке, так как время жизни последних невелико (чаще всего операция «съедает» входные значения с вершины стека и замещает их своим результатом). Значение, помещённое в регистр, живёт до момента его перезаписи. Например, это позволяет избавиться от постоянного вычисления или подгрузки из памяти значений для цикловых инвариантов — они просто размещаются в регистрах.
- Необходимость использования алгоритмов распределения регистров при трансляции с языков высокого уровня. Для нетривиальных программ всегда будет возникать ситуация нехватки регистров (их число ограничено) для размещения всех используемых при вычислении данных. При этом как-то надо следить, на каком регистре что находится в каждый момент времени. Тогда как в случае стековых ВМ вершина стека одна, и она всегда «доступна». Эти обстоятельства могут значительно усложнять логику работы инструментов для регистровой ВМ.
Интереснейший вопрос заключается в том, какой тип ВМ — стековый или регистровый — исполняет программы быстрее. Однозначного ответа к настоящему моменту нет; данные одних исследователей доказывают преимущество первого вида, тогда как остальные утверждают обратное. Интересный эксперимент описан в [3] — авторы статьи используют для исполнения регистровую ВМ, код для которой получается с помощью оптимизирующей трансляции из Java байткода, и сравнивают производительность.
Примеры
Parrot VM —
Dalvik от Google — регистровая ВМ, служащая для исполнения приложений, написанных на Java. Интересно, что байткод стековой JVM (*.class) преобразуется в байткод регистровой ВМ (*.dex). В настоящее время Dalvik отходит на второй план в Android, уступая место ART — механизму прямой компиляции в машинный код хозяйской системы.
LLVM bitcode — одно из представлений исходной программы, используемое при трансляции программ с помощью инструментов на основе LLVM, и по совместительству входной язык ВМ, использующий трёхоперандный формат инструкций с регистрами. Необычным в этой ВМ является то, что инструкции выражены в т.н. SSA (single static assignment) форме, т.е. они используют потенциально неограниченное число виртуальных регистров. Распределение регистров ВМ на физические происходит позже в процессе трансляции в машинный код или интерпретации.
MIX и MMIX — виртуальные машины, используемые (или планируемые к использованию в будущих изданиях) Д. Кнутом в своей серии книг «Искусство программирования» для иллюстрации реализации алгоритмов. MIX выполнена в духе 1960-х: выделенный регистр-аккумулятор, 6-битные байты, двоично-десятичный формат чисел, отсутствие стека и склонность к задействованию самомодифицирующегося кода. MMIX — это уже вменяемый RISC с щедрым числом (256) и шириной (64 бит) регистров.
Об иллюстрации алгоритмов машинным кодом
Лично мне очень сложно понять «алгоритмы», написанные на MIX, в и без того сложной книге несомненно уважаемого мной автора. Мне почему-то кажется, что использование языков более высокого уровня значительно облегчило бы восприятие.
Экзотические ВМ
Остерегайтесь смоляной ямы Тьюринга, в которой всё возможно, но ничто из интересного не достижимо.
ОригиналBeware of the Turing tar-pit in which everything is possible but nothing of interest is easy. Alan Perlis, «Epigrams on Programming»
Наконец, третий подход к построению ВМ заключается в нарушении всех правил и создании архитектуры, непохожей ни на что «стандартное». С одной стороны, это очень увлекательно: придумать новую концепцию там, где всё уже вроде бы придумано. С другой стороны, польза от таких систем ограничена, часто из-за их (нарочной) экстремальной непрактичности.
printf() как виртуальная машина — не совсем экзотика, просто хочу показать знакомую многим вещь под новым углом. Ведь если присмотреться, то строка спецификации, идущая первым аргументом у стандартных функций семейства
printf языка Си — это программа, инструкциями которой являются символы, а данными — оставшиеся аргументы функции. Большинство инструкций этой ВМ просто выводят один символ, совпадающий с кодом самой инструкции; но вот инструкция % имеет гораздо более сложную семантику, зависящую от следующих за ней символов. Неудивительно, что некоторые уязвимости в ПО основаны на передаче специально подобранной строки для интерпретации её в printf и исполнения неавторизованного кода.OISC. Самый увлекательный и загадочный (для меня) класс языков экзотического типа — это OISC (one instruction set computer) — системы, содержащие ровно одну машинную инструкцию и при этом не являющиеся совсем тривиальными. Некоторые из них эквивалентны машине Тьюринга, т.е. на них могут быть запрограммированы достаточно сложные алгоритмы. Самая известная из OISC — subleq (subtract and branch unless positive).
Следует отметить, что OISC зачастую скрывается во вполне привычном наборе машинных инструкций; например, MOV в PDP-11 или #PF/#DF в составе Intel ® IA-32; последнюю машину можно назвать zero instruction set computer, потому что формально исполнения инструкций IA-32 при обработке исключений не происходит.
Dis — ВМ для распределённой ОС Inferno, созданной в Bell Labs людьми, стоявшими у истоков ОС Plan 9. Эта машина имеет адресацию «память-память», что довольно необычно по современным меркам (последний раз в аппаратуре такое было в Motorola 68000), и отсутствие архитектурно видимых регистров. Я не могу придумать преимуществ такого подхода ни перед регистровыми, ни перед стековыми системами; скорее, он собирает в себе все их недостатки.
Способы исполнения
После определения типа ВМ и деталей архитектуры наступает время создания программы, реализующей функциональность ВМ. После выбора языка программирования и прочих мелочей надо определиться с тем, каким образом будут обрабатываться инструкции. А способа есть минимум три:

Интерпретация — основная и первоначальная техника как для языковых, так и для системных ВМ. Базовый принцип её я описывал в предыдущих своих статьях. Вопрос построения максимально эффективного интерпретатора не так прост, как кажется, и имеет большую практическую ценность из-за широкой популярности и распространённости динамических языков, использующих интерпретацию на различных этапах своей работы. И далеко не всегда достаточно написать
switch (...) {case ... case ... case ...}. Я планирую поподробнее описать проблемы, приводящие к низкой скорости работы для такого наивного подхода, и существующие решения в одной из последующих своих статей.Динамическая трансляция — техника, в общем случае превосходящая интерпретацию как по скорости, так и по сложности реализации. Она основана на том факте, что код, исполняющийся внутри ВМ, образует циклы, и входящие в них инструкции при каждой интерпретации будут совершать одинаковые действия. Если блоки кода ВМ перед исполнением транслировать в эквивалентные секции машинного кода физической системы, то можно сэкономить на декодировании и интерпретации. Чем больше итераций будет проводиться в цикле, тем значительнее будет эффект от использования трансляции. Я описал один из способов построения простого шаблонного транслятора в предыдущей статье.
Статическая трансляция — в случае, когда весь код, подлежащий исполнению, известен заранее (то есть в процессе работы ВМ подгрузки новых блоков с инструкциями не ожидается), то возможно использовать классическую компиляцию — однократно преобразовать машинные инструкции исходной ВМ в машинные инструкции физической системы, при этом опционально применяя разнообразные оптимизации.
Заинтересовавшимся вопросами проектирования и реализации языковых ВМ я могу посоветовать книгу [2], автор которой описывает теорию и приводит практические примеры реализации стековых, регистровых ВМ, а также «экзотического» варианта ВМ для событийно-ориентированной системы.
Системные ВМ
Системные виртуальные машины, как правило, создаются по спецификациям, для которых уже существуют «железные» реализации. Это привносит свои особенности в процесс создания таких ВМ. Архитектура настоящей аппаратуры ограничена сильнее чисто программной, «умозрительной» ВМ: влияют требования на производительность, энергопотребление, физические размеры кристалла, способного вместить реализацию, совместимости с внешними устройствами и т.д.
Часто целью создания системной ВМ является запуск внутри неё немодифицированных (пренебрегаем паравиртуализацией для простоты) операционных систем, предоставляющих многозадачность и контролируемый доступ к системным ресурсам гостевым пользовательским приложениям. В отличие от языковых ВМ, рассчитанных на работу одиночного процесса, системная ВМ должна предоставлять достаточно полное окружение из большого числа моделей периферийных устройств, симуляцию работы с картами физической памяти, корректную обработку прерываний и исключений, монотонное и равномерное течение виртуального времени и т.д.
В отличие от создателей языковых ВМ, которые часто имеют довольно большую свободу при выборе деталей машинного языка, программисты, реализующие системные ВМ, связаны необходимостью чётко следовать спецификациям на аппаратуру, которые обычно нелегко изменить. Значительные усилия приходится тратить на эффективную поддержку идиосинкразий (или попросту костылей) выбранного машинного языка. После длительной эволюции и многочисленных расширений некоторые архитектуры и вовсе выглядят как сплошной забор из костылей… но я отвлёкся. В любом случае, при создании системной ВМ больше внимания достаётся вопросам создания корректной и быстрой программы, чем хлопотам о входном машинном языке.
Классификация системных ВМ

Системные ВМ в первую очередь классифицируются по тому, какой тип гостевого процессора моделируется. Классификаций процессоров существует много, и они довольно подробно описаны в различных источниках, поэтому здесь лишь кратко резюмирую самые общие вещи. По архитектуре набора команд ЦПУ бывают CISC — сложные инструкции, делающие сразу много вещей сразу, включая загрузку данных из памяти, и RISC — максимально простые инструкции, в которых доступ к памяти и операции над данными в регистрах явно разделены; несколько особняком стоят VLIW, в которых несколько разных операций объединяются в одно машинное слово. Также можно классифицировать наборы команд по признаку вариативности длины инструкции: системы с переменной длиной команд и системы с фиксированной длиной. По правде сказать, по-настоящему постоянная длина инструкций встречается редко — всегда или что-то не влезает в машинное слово (например, 32-битные литералы в ARC и 64-битные в IA-64), или же создатели пытаются сэкономить, назначая для часто используемых инструкций последовательности покороче (16-битные команды ARCompact или ARM Thumb).
При создании системной ВМ важным классификационным признаком является наличие/отсутствие отношений «родства» между архитектурами хозяйской и гостевой систем. По степени родства моделируемая и моделирующая системы могут быть: полностью разнородными (например, Zilog Z80 и PowerPC), похожими (Intel IA-32 и Intel 64, или Intel 8086 и Intel IA-32) или же совпадающими (X и X, где X — ваша любимая архитектура).
В случае, когда гость и хозяин различны, задача системной ВМ состоит в обеспечении возможности запуска приложений, написанных и скомпилированных для «чужой» архитектуры, на хозяйской системе без необходимости их перекомпиляции или какой-либо ещё модификации. В идеале программная прослойка ВМ может быть вообще невидимой для конечного пользователя. Она обязана работать корректно, достаточно быстро и не требовать дополнительной конфигурации.
Такой подход может помочь компаниям перевести пользователей с их любимыми программами со своей старой архитектуры на новую (конечно же, превосходную во всём, но несовместимую со старой), или же переманить пользователей систем конкурента на собственную. Системная ВМ при этом должна устранить цикл: новая архитектура — нет приложений — нет пользователей — нет разработчиков — нет популярности — нет приложений.
Примеров такому применению ВМ масса. Приведу некоторые известные мне.
- Компания Digital: Digital FX!32 для запуска приложений IA-32 на Alpha, VEST — для запуска программ VAX на Alpha, mx — Ultrix MIPS на Alpha.
- Компания IBM: PowerVM Lx86 для запуска IA-32 на процессорах POWER.
- Apple использовала системные ВМ дважды: при переходе с Motorola 680x0 на PowerPC в 1996 году; Apple Rosetta для перевода с PowerPC на IA-32 в 2006 году.
- Российская компания МЦСТ разработала ПО для обеспечения запуска операционных систем и программ IA-32 на процессорах «Эльбрус».
- Компания Intel создала программный IA-32 Execution Layer для запуска IA-32 приложений на Intel Itanium.
- Подсистема NTVDM (NT virtual DOS machine) в 32-битных версиях Microsoft Windows использовалась для исполнения DOS-приложений, ожидающих увидеть процессор 8086 в реальном режиме под управлением MS-DOS.
- И ещё раз Intel: для запуска приложений для Android, скомпилированных для архитектуры ARM, на телефонах от с Intel Atom, также была создана программная прослойка, невидимая для пользователя.
Конечно же, этот список можно продолжить.
В случаях совпадения архитектур систем гостя и хозяина системные ВМ также находят применение. Запуск гостевой ОС внутри ВМ под управлением монитора позволяет контролировать потребление ею ресурсов, исполнять одновременно с другими системами, замораживать, восстанавливать из образов, клонировать, мигрировать с одного места на другое и вообще выполнять разные фокусы, которые затруднительно провернуть с ОС, запущенной напрямую на железе.
Для создателей ВМ критично важным становится свойство «виртуализуемости» набора команд. От того, удовлетворяет ли выбранная архитектура машинных команд достаточным условиям Голдберга-Попека, зависит, насколько просто будет реализовать монитор виртуальных машин для неё, а также насколько серьёзное замедление (по отношению к работе на «голом» железе) он будет вносить. Intel IA-32/Intel 64 до появления расширений Intel VT-x принадлежала к первой категории сложно-виртуализуемых систем, но в настоящее писать эффективные мониторы для неё «легко» (если это слово применимо к разработке модулей ядра для набора команд с почти полувековой эволюцией).
Способы исполнения
С точки зрения программной реализации системные ВМ имеют много общего с языковыми. Это неудивительно — базовая единица исполнения в обоих случаях — машинная инструкция.
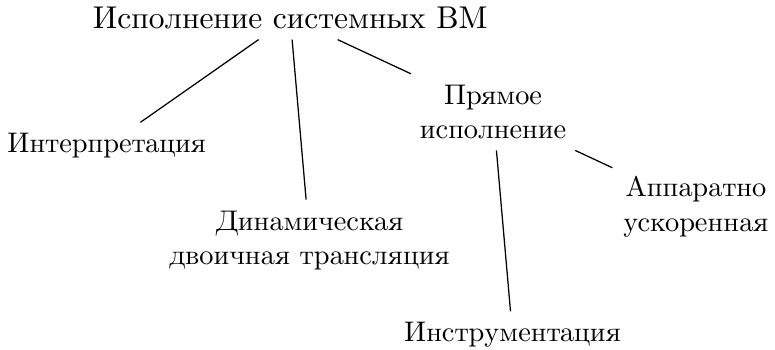
Интерпретация — и снова это слово! В случае, когда нужно сделать максимально легко портируемую системную ВМ без особой оглядки на скорость, интерпретатор будет естественным первым выбором. Bochs — наверное, самый известный из открытых проектов такого типа. Подчеркну вновь отсутствие порядка в терминологии — на официальной странице Bochs представлен как «PC emulator», а не симулятор или виртуальная машина.
Динамическая трансляция — как было описано ранее, группа технологий, обещающих более высокую скорость работы. А вот статическая трансляция, применимая для языковых ВМ, не очень удобна для создания ВМ системных — в полноплатформенных моделях крайне редко весь код доступен и известен заранее, до начала симуляции. К чисто динамическим трансляторам относится ранее упомянутый IA-32 Execution Layer.
Аппаратная поддержка — для архитектур, поддерживающих виртуализацию аппаратно, это наиболее эффективный метод. Однако он и самый «капризный», ведь он работает только при совпадении архитектур гостя и хозяина. Часто даже относительно небольшие различия между наборами расширений выбранных систем могут сделать нецелесообразными попытки создания ВМ такого типа. Большинство современных коммерческих гипервизоров для IA-32 активно полагаются на наличие VT-x в своей работе.
Заинтересовавшимся вопросами проектирования и реализации системных ВМ я хочу посоветовать книгу [1]. Незаинтересовавшимся тоже рискну её посоветовать — в ней доступно объясняются многие важные особенности компьютерной архитектуры, она написана довольно понятным языком.
Что появилось раньше — виртуальная память или виртуальная машина?
Хочу поделиться удивительным для меня фактом. В те далёкие времена, когда ещё шли дебаты о том, стоит ли включать аппаратную поддержку страничной виртуальной памяти в коммерческие ЭВМ или же ей место лишь в немногиз экспериментальных или узкоспециализированных системах, аппаратные виртуальные машины уже вовсю использовались для разработки программ. Более того, они даже «продавались» для консолидации задач нескольких независимых потребителей машинного времени на одной физической системе. В [4], книге об основах работы в операционных системах для мэйнфреймов, есть примечательный параграф:
Другими словами, системные виртуальные машины старше виртуальной памяти!
IBM разработала операционную систему VM (Virtual Machine) в 1964. Как и любая ОС, VM контролировала ресурсы компьютера. Она также предоставляла новую возможность, никогда не существовавшую раньше в других ОС: иллюзию для каждого пользователя, что в его распоряжении есть целый компьютер, полностью для его нужд. IBM создала VM задолго до появления идеи персонального компьютера, и в то время возможность иметь хотя бы симуляцию компьютера целиком и полностью для себя самого было Большим Делом. Если двадцать человек подключились к системе с VM одновременно, она создаёт для каждого из них иллюзию, что они используют двадцать различных независимых компьютеров.
ОригиналIBM developed VM («Virtual Machine») in 1964. Like any operating system, VM controlled the computer's resources. It also added a feature that had never existed before: the illusion, for each of its users, that they had a whole computer to themselves. (Because IBM developed VM well before the invention of the PC, having even a simulation of your own computer was a Big Deal.) If twenty people use a VM system at once, it gives them the illusion that they are using twenty different computers.
Другими словами, системные виртуальные машины старше виртуальной памяти!
Итоги
В данной статье я постарался описать два класса программных систем, называемых виртуальными машинами, показать различия и сходства между ними, известные вариациии используемых архитектур и их программных реализаций. Суммарно классификация ВМ выглядит следующим образом:

Языковые виртуальные машины в первую очередь различаются по организации доступа к данным. Системные ВМ в первую очередь характеризуются особенностями аппаратной архитектуры реализуемого гостя. Очень часто реализуемый на практике сценарий подразумевает совпадение архитектур хозяина и гостя. При этом самым важным свойством с точки зрения проектировщика монитора ВМ является удовлетворение условиям эффективной виртуализуемости.
Спасибо за внимание!
Литература
- James E. Smith, Ravi Nair, Virtual Machines: Versatile Platforms For Systems And Processes — Morgan Kaufmann — 2005. ISBN 1-55860-910-5
- Craig, Iain D. Virtual Machines — Springer — 2006. ISBN 1-85233-969-1
- Yunhe Shi, Kevin Casey, M. Anton Ertl, and David Gregg. Virtual Machine Showdown: Stack Versus Registers — USENIX — 2008. www.usenix.org/events/vee05/full_papers/p153-yunhe.pdf
- Bob DuCharme. Fake Your Way Through Minis and Mainframes (formerly, «The Operating System Hand-book») — Part 5: VM/CMS — 2001. www.snee.com/bob/opsys/part5vmcms.pdf
