Все проблемы в области Computer Science могут быть решены введением дополнительного уровня косвенности. За исключением одной: слишком большого числа уровней косвенности.
All problems in computer science can be solved by another level of indirection, except for the problem of too many layers of indirection.
Программные интерпретаторы известны своей невысокой скоростью работы. В этой статье я расскажу, как их можно ускорить.
Я давно уже хотел поподробней остановиться на создании интерпретаторов. Прямо таки обещал, в том числе самому себе. Однако серьёзный подход требовал использования более-менее реалистичного кода для примеров, а также проведения измерений производительности, подтверждающих (а иногда и опровергающих) мои аргументы. Но наконец-то я готов представить почтенной публике результаты, причём даже чуть более интересные, чем собирался.
В данной статье будет описано семь способов построения программной ВМ для одной гостевой системы. От самых медленных мы проследуем к более быстрым, поочерёдно избавляясь от различных «неэффективностей» в коде, и в конце сравним их работу на примере одной программы.
Тех, кто не боится ассемблерных листингов, испещрённого макросами кода на Си, обильно удобренного адресной арифметикой, goto и даже longjmp, а также программ, использующих копипаст во имя скорости или даже создающих куски самих себя, прошу пожаловать под кат.

Интерпретаторы — класс программ, анализирующих написанный на некотором входном языке текст по одной фразе (выражению, утверждению, инструкции, другой смысловой единице) за раз и немедленно выполняющих предписанные этой фразой действия. Этим они отличаются, например, от трансляторов, в которых фазы разбора входного языка и исполнения действий разнесены во времени.
Это определение довольно общее, и под него попадают многие программы, в том числе реализующие виртуальные машины (ВМ). Последние можно разделить на два класса: языковые и системные.
Следует предупредить, что большинство идей, о которых я буду рассказывать, были найдены довольно давно [3, 4]. Более того, похожее сравнение скорости различных типов интерпретаторов (для очень примитивной ВМ) уже проводилось [2]. Есть даже русскоязычные книги советского времени [1] на эту тему.
1. Я позволю себе ограничиться хозяйской архитектурой Intel® 64. При этом измерения будут делаться только для одной машины. Я призываю всех читателей отчётливо понимать, что детали архитектуры и микроархитектуры (такие, как организация предсказателя переходов) напрямую влияют на скорость работы программ, в особенности интерпретаторов. Более того, может оказаться, что алгоритм A, работающий быстрее алгоритма B на архитектуре Z, будет проигрывать ему на системе Y.
2. Примеры кода были сделаны с расчётом на переносимость между системами. Они должны корректно обрабатываться популярными в настоящее время версиями компиляторов GCC и ICC на POSIX-системах. На немногочисленные «непортабильные» места я буду указывать отдельно.
3. Рассказ ориентирован на интерпретаторы, создаваемые для нужд симуляции центральных процессоров. Специфика данной предметной области влияет на структуру решения. Например, далее обращается внимание на нетривиальность фазы декодирования входного машинного языка, тогда как в известных мне работах эта задача считается тривиальной (решаемой с помощью оператора идентичности).
4. В этой статье ничего не будет сказано про разбор грамматики, то есть про ту часть интерпретации, необходимую для построения интерпретаторов языков высокого уровня. В книге Terrence Parr [5], создателя ANTLR — мощного фреймворка для создания лексеров, парсеров и генераторов, качественно и подробно раскрывается этот вопрос.
Итак, сперва описание того, что будем моделировать — спецификация виртуальной машины.
Архитектура исследуемой ВМ
Полный код примеров, а также Makefile для сборки и скрипт для тестирования производительности опубликованы здесь: github.com/grigory-rechistov/interpreters-comparison.
Далее я буду цитировать некоторые куски кода оттуда и отсылать читателя к конкретным именам файлов и функций.
Для нужд данной статьи я хотел использовать ВМ, достаточно простую, чтобы успеть написать и отладить несколько вариантов её реализации за приемлемое время, но при этом достаточно сложную, чтобы на ней проявлялись различные эффекты, присущие реальным проектам, и чтобы на ней можно было исполнять хотя бы минимально полезную программу, а не просто скучный псевдослучайный поток инструкций.
В целом эта ВМ вдохновлена языком Форт. По сравнению с ним она сильно упрощена и имеет только те инструкции, которые были необходимы для иллюстрации описываемых в статье идей. Самые важные, на мой взгляд, её упущения (упрощения) по сравнению с нормальным Фортом — отсутствие процедурного механизма и словаря.
Хочу отметить, что все описанные далее примеры могут быть напрямую адаптированы не только для стековых, но и регистровых ВМ.
- Ширина машинного слова — 32 бита. Все операнды и инструкции — это знаковые или беззнаковые 32-битные целые числа
- Три состояния процессора: Running — активное исполнение инструкций; Halted — останов после исполнение Halt, соответствует нормальному завершению программы; Break — останов после любой ненормальной, неподдерживаемой или вызвавшей нестандартное состояние инструкции, обозначает ошибку в программе. Другими словами, ВМ начинает работать в состоянии Running. Заканчивает она работу в состоянии Halted, если в процессе работы не произошло никаких непредвиденных событий и исполнение достигло инструкции Halt. Если произошло деление на ноль, выход за границы кода, переполнение или опустошение стека, или что-то ещё, что мне не захотелось поддерживать при реализации, она останавливается в режиме Break.
- Все регистры — неявные, а всего их два. PC — указатель текущей команды. SP — указатель вершины стека. В начале работы PC=0, SP=-1.
- Стек параметров глубиной 32 беззнаковых целых слова. SP указывает на текущий элемент, или же равен -1, если стек пуст.
- Программная память ёмкостью в 512 слов, доступная только на чтение. При выходе за границы [0; 511] процессор останавливается в состоянии Break.
- Инструкции могут иметь ноль или один явный операнд (imm). В первом случае они имеют длину в одно слово, во втором — два.
- Описание всех машинных инструкций. Коды операций, а также другие элементы архитектуры ВМ, описаны в файле common.h.
Описание набора инструкцийBreak = 0x0000 — перевести процессор в состояние Break. Так как неинициализированная программная память заполнена нулями, любой случайный переход «мимо кода» приводит к остановке.
Nop = 0x0001 — пустая команда, не изменяющая стек и SP.
Halt = 0x0002 — перевести процессор в состояние Halted.
Push = 0x0003 imm — поместить константу imm на вершину стека.
Print = 0x0004 — снять с вершины стека значение и распечатать его в десятичном виде.
JNE = 0x0005 imm — снять с вершины стека значение, и, если оно не равно нулю, прибавить imm к PC. imm при этом трактуется как число со знаком.
Swap = 0x0006 — переставить местами вершину стека и следующий за ний элемент.
Dup = 0x0007 — поместить на вершину стека копию самого верхнего элемента.
JE = 0x0008 imm — снять с вершины стека значение, и, если оно равно нулю, прибавить imm к PC. imm при этом трактуется как число со знаком.
Inc = 0x0009 — прибавить к вершине стека единицу.
Add = 0x000a — сложить два верхних элемента стека. Снять их со стека и поместить результат как вершину.
Sub = 0x000b — вычесть из верхнего элемента стека следующий за ним. Снять их со стека и поместить результат на вершину.
Mul = 0x000c — перемножить два верхних элемента стека. Снять их со стека и поместить результат как вершину.
Rand = 0x000d — поместить на вершину стека случайное число.
Dec = 0x000e — вычесть из вершины стека единицу.
Drop = 0x000f — снять с вершины стека число и «выбросить» его.
Over = 0x0010 — поместить на вершину стека копию элемента, являющегося вторым в стеке после вершины.
Mod = 0x0011 — поделить верхний элемент стека на следующий за ним. Снять их со стека и поместить остаток от деления на вершину.
Jump = 0x0012 imm — прибавить imm к PC. imm при этом трактуется как число со знаком.
Арифметические операции, приводящие к переполнению (кроме деления на ноль), не вызывают перехода в состояние Break и никак не сигнализируются.
Отмечу, что все инструкции, включая управляющие исполнением (т.е. Jump, JE, JNE), безусловно продвигают PC на свою длину в конце исполнения. Это следует учитывать при вычислении смещения адреса перехода. Т.е. прыжок считается от начала инструкции, следующей для текущей.
- Исполнение любой инструкции, не определённой в архитектуре явно, эквивалентно исполнению Break.
- Для нужд отладки процессор содержит 64-битный регистр steps, увеличивающийся на единицу после каждой исполненной инструкции ВМ. Программы позволяют задать предел числа шагов, после которого симуляция прерывается. По умолчанию он равен LLONG_MAX.
- После завершения симуляции программы выводят состояние процессора и стека на экран.
Бенчмарк
Для сравнения производительности нужна была программа, написанная для этой ВМ. Она должна была быть достаточно длинной, с нетривиальным потоком управления, не использовать чрезмерно ввод-вывод, т.е. быть вычислительно-сложной. И при этом быть достаточно простой, чтобы такой рассеянный человек, как я, смог бы отладить её в машинных кодах даже без нормально работающего симулятора. В результате получилось то, что я назвал Primes.
Primes выводит на экран все простые числа, содержащиеся на отрезке от 2 до 100000. Её код для ВМ содержится в массиве Primes[], одинаково объявленном во всех примерах.
Primes
const Instr_t Primes[PROGRAM_SIZE] = {
Instr_Push, 100000, // nmax (maximal number to test)
Instr_Push, 2, // nmax, c (minimal number to test)
/* back: */
Instr_Over, // nmax, c, nmax
Instr_Over, // nmax, c, nmax, c
Instr_Sub, // nmax, c, c-nmax
Instr_JE, +23, /* end */ // nmax, c
Instr_Push, 2, // nmax, c, divisor
/* back2: */
Instr_Over, // nmax, c, divisor, c
Instr_Over, // nmax, c, divisor, c, divisor
Instr_Swap, // nmax, c, divisor, divisor, c
Instr_Sub, // nmax, c, divisor, c-divisor
Instr_JE, +9, /* print_prime */ // nmax, c, divisor
Instr_Over, // nmax, c, divisor, c
Instr_Over, // nmax, c, divisor, c, divisor
Instr_Swap, // nmax, c, divisor, divisor, c
Instr_Mod, // nmax, c, divisor, c mod divisor
Instr_JE, +5, /* not_prime */ // nmax, c, divisor
Instr_Inc, // nmax, c, divisor+1
Instr_Jump, -15, /* back2 */ // nmax, c, divisor
/* print_prime: */
Instr_Over, // nmax, c, divisor, c
Instr_Print, // nmax, c, divisor
/* not_prime */
Instr_Drop, // nmax, c
Instr_Inc, // nmax, c+1
Instr_Jump, -28, /* back */ // nmax, c
/* end: */
Instr_Halt // nmax, c (== nmax)
};
В моих запусках она исполнялась от половины до трёх минут. Её алгоритм приблизительно (с поправкой на стековую архитектуру) соответствует программе, содержащейся в файле native.c.
main() из native.c
int main() {
for (int i = 2; i < 100000; i++) {
bool is_prime = true;
for (int divisor = 2; divisor < i; divisor++) {
if (i % divisor == 0) {
is_prime = false;
break;
}
}
if (is_prime)
printf("[%d]\n", i);
}
return 0;
}
Замечание об оптимизации
Один вводящий в заблуждение бенчмарк может помочь достичь того, что невозможно получить за годы хорошей инженерной работы.
A misleading benchmark test can accomplish in minutes what years of good engineering can never do.
dilbert.com/strip/2009-03-02
Я хочу ещё раз подчеркнуть один очень важный момент в оптимизации производительности приложений: никому нельзя верить. Особенно если кто-то говорит что-то вроде: «используй алгоритм X вместо твоего Y, потому что он всегда быстрее». Нельзя верить проспектам производителям аппаратуры, статьям создателей компиляторов, обещаниям авторов библиотек. Нельзя верить своему чутью — в вопросах поиска узких мест в производительности оно врёт ещё как. Верить можно только результатам измерений и профилировки, и то не всегда.
Тем менее можно верить мне. Действительно — программа Primes, которую я использую для сравнения производительности, смехотворно наивна: мало того, что она вряд ли создаёт сколь-нибудь существенную нагрузку на все подсистемы процессора, так ещё и алгоритм, использованный в ней, неоптимален! В самом деле, для больших N нет нужды проверять делимость N на N-1, достаточно проверить делители от 2 до √N̅. Она даже не использует все доступные инструкции, которые я так тщательно писал!
Да и ВМ, чего уж там, немного стоит. Объёмы ресурсов крошечные, даже 8-битные микроконтроллеры часто сложнее. Без механизмов вызова процедур и обработки исключений далеко не уедешь.
Но не стоит забывать, что весь этот материал служит лишь иллюстративной цели. Если бы симулятор был реалистично сложен, а бенчмарк-программа была бы реальных размеров, то немногие захотели бы читать их.
Замечание об оптимизации касается всего последующего материала данной статьи. На другом поколении хозяйских процессоров с другой версией компилятора вполне может оказаться, что самый медленный код этой статьи обгонит все остальные варианты. Я сам был удивлён, получив графики — некоторые результаты не соответствовали моим ожиданиям; более того, разные компиляторы вывели в лидеры разных участников. Но я опять забегаю вперёд.
Переключаемый (switched)
Первая схема построения интерпретатора является самой популярной — переключаемый интерпретатор (файл switched.c). Её код естественным образом выражает базовый цикл «считать код операции — распознать — исполнить — повторить». Так как это первая разбираемая схема, рассмотрим, как все фазы этого цикла выражаются в коде ВМ; в дальнейшем будем обращать внимание лишь на различия (никто же не хочет читать сотни строчек похожего кода).
Функция fetch() считывает «сырой код» операции, находящийся по адресу PC. Так как интерпретатор моделирует системную ВМ, необходимо быть готовым к выходу PC за границы памяти; за проверку отвечает fetch_checked().
код fetch() и fetch_checked()
static inline Instr_t fetch(const cpu_t *pcpu) {
assert(pcpu);
assert(pcpu->pc < PROGRAM_SIZE);
return pcpu->pmem[pcpu->pc];
};
static inline Instr_t fetch_checked(cpu_t *pcpu) {
if (!(pcpu->pc < PROGRAM_SIZE)) {
printf("PC out of bounds\n");
pcpu->state = Cpu_Break;
return Instr_Break;
}
return fetch(pcpu);
}
Функция decode() должна завершить начатое в fetch() — полностью определить характеристики команды. В нашем случае это её длина (1 или 2) и значение литерального операнда для тех инструкций, у которых он есть. Кроме того, по принятым соглашениям все неизвестные опкоды считаются эквивалентными Break. Всё это выясняется в результате работы одного оператора switch.
Особенность обработки «длинных» инструкций с операндом: они требуют дополнительного чтения памяти команд по адресу PC+1, который также необходимо проконтролировать на выход за границы.
код decode()
static inline decode_t decode(Instr_t raw_instr, const cpu_t *pcpu) {
assert(pcpu);
decode_t result = {0};
result.opcode = raw_instr;
switch (raw_instr) {
case Instr_Nop:
case Instr_Halt:
case Instr_Print:
case Instr_Swap:
case Instr_Dup:
case Instr_Inc:
case Instr_Add:
case Instr_Sub:
case Instr_Mul:
case Instr_Rand:
case Instr_Dec:
case Instr_Drop:
case Instr_Over:
case Instr_Mod:
result.length = 1;
break;
case Instr_Push:
case Instr_JNE:
case Instr_JE:
case Instr_Jump:
result.length = 2;
if (!(pcpu->pc+1 < PROGRAM_SIZE)) {
printf("PC+1 out of bounds\n");
pcpu->state = Cpu_Break;
break;
}
result.immediate = (int32_t)pcpu->pmem[pcpu->pc+1];
break;
case Instr_Break:
default: /* Undefined instructions equal to Break */
result.length = 1;
result.opcode = Instr_Break;
break;
}
return result;
}
Для более реалистичных архитектур процедура декодирования в программной ВМ несколько сложнее: придётся искать по дереву префиксов, то есть проходить через серию вложенных switch. Но я думаю, что общую идею передать удалось.
Наконец, исполнение — по коду операции, полученного из decode(), переходим на сервисную процедуру (service routine) — блок кода, ответственный за семантику конкретной гостевой инструкции. Ещё один switch, во всей его
код switch
uint32_t tmp1 = 0, tmp2 = 0;
/* Execute - a big switch */
switch(decoded.opcode) {
case Instr_Nop:
/* Do nothing */
break;
case Instr_Halt:
cpu.state = Cpu_Halted;
break;
case Instr_Push:
push(&cpu, decoded.immediate);
break;
case Instr_Print:
tmp1 = pop(&cpu); BAIL_ON_ERROR();
printf("[%d]\n", tmp1);
break;
case Instr_Swap:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1);
push(&cpu, tmp2);
break;
case Instr_Dup:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1);
push(&cpu, tmp1);
break;
case Instr_Over:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp2);
push(&cpu, tmp1);
push(&cpu, tmp2);
break;
case Instr_Inc:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1+1);
break;
case Instr_Add:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1 + tmp2);
break;
case Instr_Sub:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1 - tmp2);
break;
case Instr_Mod:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
if (tmp2 == 0) {
cpu.state = Cpu_Break;
break;
}
push(&cpu, tmp1 % tmp2);
break;
case Instr_Mul:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1 * tmp2);
break;
case Instr_Rand:
tmp1 = rand();
push(&cpu, tmp1);
break;
case Instr_Dec:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1-1);
break;
case Instr_Drop:
(void)pop(&cpu);
break;
case Instr_JE:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
if (tmp1 == 0)
cpu.pc += decoded.immediate;
break;
case Instr_JNE:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
if (tmp1 != 0)
cpu.pc += decoded.immediate;
break;
case Instr_Jump:
cpu.pc += decoded.immediate;
break;
case Instr_Break:
cpu.state = Cpu_Break;
break;
default:
assert("Unreachable" && false);
break;
}
Здесь и далее BAIL_ON_ERROR служит для перехвата возможных исключений, возникших в ходе выполнения отдельных команд:
#define BAIL_ON_ERROR() if (cpu.state != Cpu_Running) break;
К сожалению, это Си, и использовать нормальный try-catch не получится (однако погодите, ближе к концу статьи будет кое-что похожее на него).
Наблюдательный читатель может удивиться — зачем используются два switch: в decode() и в main(), — ведь они вызываются один за другим и управляются одной и той же величиной, то есть могут быть объединены. Необходимость такого разделения станет понятна в следующей секции, где мы избавимся от необходимости постоянно вызывать decode().
Предварительное декодирование (pre-decoding)
Первое, от чего следует избавиться — это декодирование на каждом шаге симуляции (файл predecoded.c). В самом деле, содержимое программы не меняется в процессе работы, или меняется очень нечасто: при загрузке новых приложений или динамических библиотек, изредка самим приложением (JIT-программа, дописывающая свои куски). В нашей ВМ вообще нет возможности изменить программу в процессе выполнения, и этим надо воспользоваться.
код predecode_program()
static void predecode_program(const Instr_t *prog,
decode_t *dec, int len) {
assert(prog);
assert(dec);
/* The program is short, so we can decode it as a whole.
Otherwise, some sort of lazy decoding will be required */
for (int i=0; i < len; i++) {
dec[i] = decode_at_address(prog, i);
}
}
Поскольку в памяти программ этой ВМ всего 512 слов, нам доступна возможность декодировать её всю сразу и сохранить результат в массиве, индексированном значением PC. В реальных ВМ с объёмами гостевой памяти 2³²–2⁶⁴ байт этот трюк не прошёл бы. Пришлось бы использовать структуру а-ля кэш с вытеснением, который в ограниченном объёме хозяйской памяти хранил бы рабочее множество соответствий «PC → decode_t». При этом приходилось бы вносить новые записи в кэш декодированных инструкций при симуляции. Однако и в этом случае был бы выигрыш в скорости. При повторном исполнении недавно выполненных инструкций их не пришлось бы заново декодировать.
Ну а так — вызовем predecode_program() до исполнения:
Код с предварительным декодированием
decode_t decoded_cache[PROGRAM_SIZE];
predecode_program(cpu.pmem, decoded_cache, PROGRAM_SIZE);
while (cpu.state == Cpu_Running && cpu.steps < steplimit) {
if (!(cpu.pc < PROGRAM_SIZE)) {
printf("PC out of bounds\n");
cpu.state = Cpu_Break;
break;
}
decode_t decoded = decoded_cache[cpu.pc];
uint32_t tmp1 = 0, tmp2 = 0;
/* Execute - a big switch */
switch(decoded.opcode) {
case Instr_Nop:
/* Do nothing */
break;
case Instr_Halt:
cpu.state = Cpu_Halted;
break;
case Instr_Push:
push(&cpu, decoded.immediate);
break;
case Instr_Print:
tmp1 = pop(&cpu); BAIL_ON_ERROR();
printf("[%d]\n", tmp1);
break;
case Instr_Swap:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1);
push(&cpu, tmp2);
break;
case Instr_Dup:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1);
push(&cpu, tmp1);
break;
case Instr_Over:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp2);
push(&cpu, tmp1);
push(&cpu, tmp2);
break;
case Instr_Inc:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1+1);
break;
case Instr_Add:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1 + tmp2);
break;
case Instr_Sub:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1 - tmp2);
break;
case Instr_Mod:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
if (tmp2 == 0) {
cpu.state = Cpu_Break;
break;
}
push(&cpu, tmp1 % tmp2);
break;
case Instr_Mul:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1 * tmp2);
break;
case Instr_Rand:
tmp1 = rand();
push(&cpu, tmp1);
break;
case Instr_Dec:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1-1);
break;
case Instr_Drop:
(void)pop(&cpu);
break;
case Instr_JE:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
if (tmp1 == 0)
cpu.pc += decoded.immediate;
break;
case Instr_JNE:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
if (tmp1 != 0)
cpu.pc += decoded.immediate;
break;
case Instr_Jump:
cpu.pc += decoded.immediate;
break;
case Instr_Break:
cpu.state = Cpu_Break;
break;
default:
assert("Unreachable" && false);
break;
}
cpu.pc += decoded.length; /* Advance PC */
cpu.steps++;
}
Два замечания.
1. Предварительное декодирование приводит к тому, что на этапе исполнения команд не выполняется фаза Fetch. При этом возникает риск некорректной симуляции архитектурных эффектов, с ней связанных, таких как срабатывание аппаратных точек останова. Эта проблема решаема аккуратным слежением за введённым кэшем.
2. В отличие от системных ВМ, в языковых ВМ, которые обычно имеют очень простую структуру команд, фазы fetch и decode тривиальны. Поэтому для них подобное кэширование неприменимо.
Насколько избавление от декодирования ускорило симуляцию? Позволю себе сохранить интригу до конца статьи, где будут сравниваться все варианты интерпретаторов. А пока что попробуем понять, как дальше ускорить наш интерпретатор.
Как я уже писал, интуиция в этом случае — плохой помощник. Обратимся к беспристрастным инструментам: используем Intel® VTune Amplifier XE 2015 Update 4 для проведения «General Exploration» для predecoded. В обзорном отчёте красным выделены проблемные, с точки зрения анализатора, аспекты работы программы:
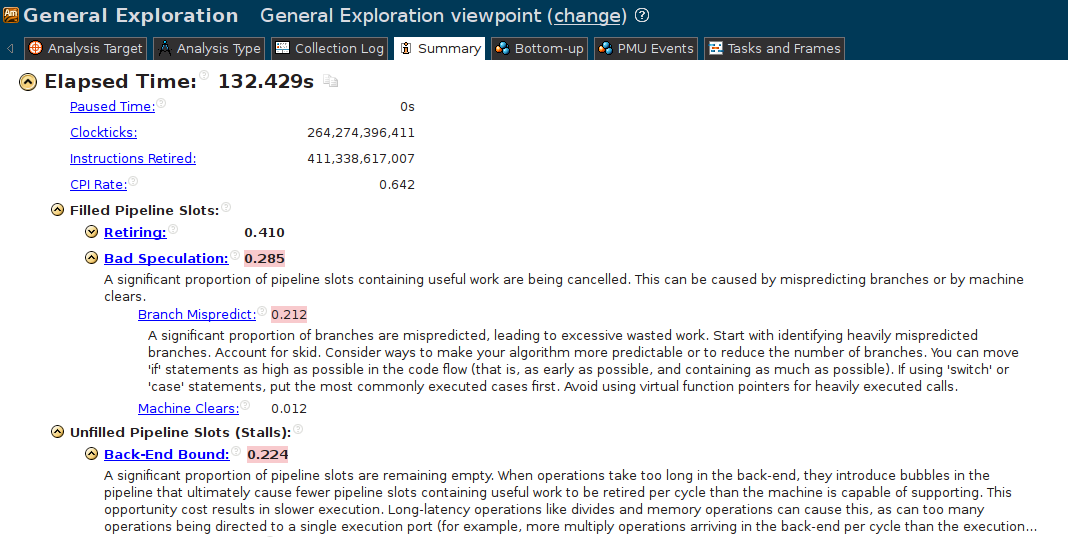
«Bad speculation»??? Какой-такой спекулянт? Непонятно. «Branch Mispredict» — уже яснее. Какой-то условный или непрямой переход в нашей программе постоянно вызывает ошибку предсказателя переходов. При этом событии вместо полезной работы процессор вынужден опустошить конвейер и начать выполнение другой инструкции. При этом возникает простой в пару десятков тактов.
Но откуда в такой простой программе такая проблема? Начинаем спускаться ниже. Кликаю на «Branch Mispredict», открывается вид Bottom-up, в котором показывается главный подозреваемый — main().

Нда, понятней не стало. Попробуем поискать строчку программы. Кликаем на main(), открывается вид на исходник программы (заблаговременно собранной с символьной информацией). Открываем оба вида — Source и Assembly, и внимательно смотрим на столбцы «Branch Mispredict». Признаться, не сразу мне удалось найти то, что надо, хоть я и знал, где и что искать.
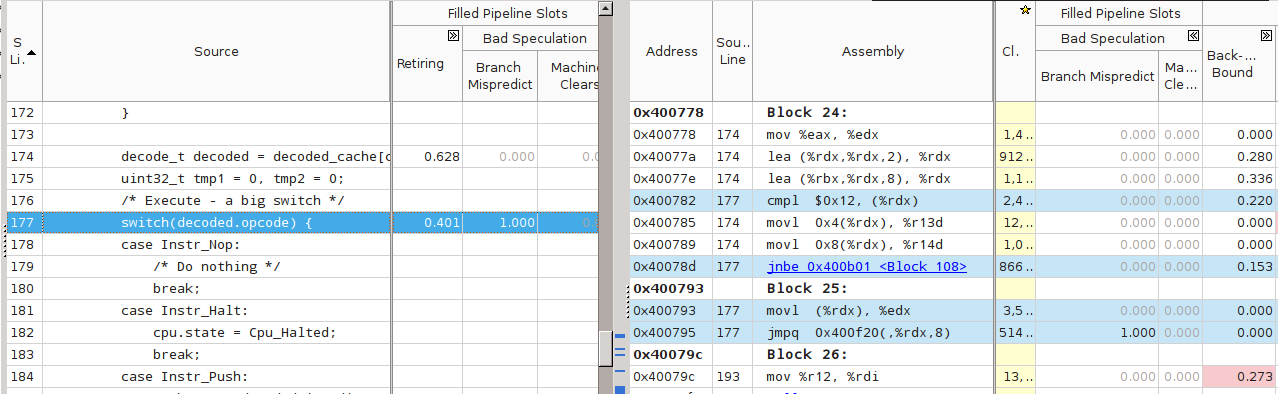
На этом скриншоте голубым подсвечены строки исходного кода и соответствующего ему кода машинного. Вот это да — наш главный switch и соответствующая ему команда «jmpq 0x400f20(,%rdx,8)» имеют стопроцентно (1.000) неправильные предсказания! Как так? Причина — в ограничениях аппаратуры по предсказанию таких переходов.
Предсказатель адресов косвенных переходов (branch target predictor) пытается предсказать, куда произойдёт переход в текущем исполнении jmp, основываясь на ограниченном наборе исторических данных, таких как адрес самой инструкции и история переходов с неё. В нашем случае история переходов — это история исполнения команд гостя внутри ВМ. Однако для Primes она совершенно хаотическая — после push может идти как ещё один push, так и over, после over могут идти over, sub, swap; число итераций внутреннего цикла велико и всё время изменяется и т.д.
Условные переходы
Очень хороший практический пример, иллюстрирующий аналогичное влияние предсказателя условных переходов на скорость работы программы, имеется на Stackoverflow: предварительная сортировка случайного массива ускоряет алгоритм фильтрации на нём.
Пенальти от неправильного предсказания адреса перехода тем вероятнее, чем больше число инструкций имеется в ВМ — по этой причине я отказался от идеи использовать BF-машину в качестве подопытной: всего 8 инструкций могли оказаться недостаточными.
Шитый (threaded)
«СЕПУЛЬКИ — важный элемент цивилизации ардритов с планеты Энтеропия. См. СЕПУЛЬКАРИИ».
Я последовал этому совету и прочёл:
«СЕПУЛЬКАРИИ — устройства для сепуления».
Я поискал «Сепуление»; там значилось:
«СЕПУЛЕНИЕ — занятие ардритов с планеты Энтеропия. См. СЕПУЛЬКИ».
Станислав Лем. «Звёздные дневники Ийона Тихого. Путешествие четырнадцатое.»
С причиной низкой производительности разобрались. Начнём её устранять. Необходимо помочь предсказателю переходов. При этом, конечно, неплохо бы знать, как он работает, в деталях. За неимением (или нежеланием обращаться к) деталям используем общие соображения. Вспомним, что предсказатель использует адрес самой инструкции для ассоциации с ней истории переходов. Вот бы удалось «размазать» единственный jmp по нескольким местам; с каждым из них будет связана своя локальная история, которая, можно надеяться, будет менее хаотичной для совершения адекватных предсказаний.
Именно это я попытался сделать в файлах threaded.c и threaded-cached.c (вариант, включающий также предварительное декодирование).
Суть решения: после исполнения текущей сервисной процедуры не возвращаться в общую точку (switch), а переходить сразу на сервисную процедуру следующей инструкции.
Плохая новость №1 — для перехода по метке придётся использовать оператор goto. Да, да, знаю, goto это плохо, мкей, я и сам писал об этом. Ради скорости — во все тяжкие. В коде ВМ это будет спрятано в макроcе DISPATCH:
Код DISPATCH
#define DISPATCH() do {\
goto *service_routines[decoded.opcode]; \
} while(0);
Плохая новость №2: придётся использовать нестандартное (отсутствующее в стандарте Си) расширение языка GCC — оператор взятия адреса метки &&:
Определение массива меток service_routines:
const void* service_routines[] = {
&&sr_Break, &&sr_Nop, &&sr_Halt, &&sr_Push, &&sr_Print,
&&sr_Jne, &&sr_Swap, &&sr_Dup, &&sr_Je, &&sr_Inc,
&&sr_Add, &&sr_Sub, &&sr_Mul, &&sr_Rand, &&sr_Dec,
&&sr_Drop, &&sr_Over, &&sr_Mod, &&sr_Jump, NULL
};
Данный нестандартный оператор поддерживается компиляторами GCC и ICC для языка Си (но, насколько мне известно, не для C++).
В результате главный «цикл» (который на самом деле не делает ни одной итерации) интерпретатора выглядит вот так:
Код main() из threaded-cached.c
decode_t decoded = {0};
DISPATCH();
do {
sr_Nop:
/* Do nothing */
ADVANCE_PC();
DISPATCH();
sr_Halt:
cpu.state = Cpu_Halted;
ADVANCE_PC();
/* No need to dispatch after Halt */
sr_Push:
push(&cpu, decoded.immediate);
ADVANCE_PC();
DISPATCH();
sr_Print:
tmp1 = pop(&cpu); BAIL_ON_ERROR();
printf("[%d]\n", tmp1);
ADVANCE_PC();
DISPATCH();
sr_Swap:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1);
push(&cpu, tmp2);
ADVANCE_PC();
DISPATCH();
sr_Dup:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1);
push(&cpu, tmp1);
ADVANCE_PC();
DISPATCH();
sr_Over:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp2);
push(&cpu, tmp1);
push(&cpu, tmp2);
ADVANCE_PC();
DISPATCH();
sr_Inc:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1+1);
ADVANCE_PC();
DISPATCH();
sr_Add:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1 + tmp2);
ADVANCE_PC();
DISPATCH();
sr_Sub:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1 - tmp2);
ADVANCE_PC();
DISPATCH();
sr_Mod:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
if (tmp2 == 0) {
cpu.state = Cpu_Break;
break;
}
push(&cpu, tmp1 % tmp2);
ADVANCE_PC();
DISPATCH();
sr_Mul:
tmp1 = pop(&cpu);
tmp2 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1 * tmp2);
ADVANCE_PC();
DISPATCH();
sr_Rand:
tmp1 = rand();
push(&cpu, tmp1);
ADVANCE_PC();
DISPATCH();
sr_Dec:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
push(&cpu, tmp1-1);
ADVANCE_PC();
DISPATCH();
sr_Drop:
(void)pop(&cpu);
ADVANCE_PC();
DISPATCH();
sr_Je:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
if (tmp1 == 0)
cpu.pc += decoded.immediate;
ADVANCE_PC();
DISPATCH();
sr_Jne:
tmp1 = pop(&cpu);
BAIL_ON_ERROR();
if (tmp1 != 0)
cpu.pc += decoded.immediate;
ADVANCE_PC();
DISPATCH();
sr_Jump:
cpu.pc += decoded.immediate;
ADVANCE_PC();
DISPATCH();
sr_Break:
cpu.state = Cpu_Break;
ADVANCE_PC();
/* No need to dispatch after Break */
} while(cpu.state == Cpu_Running);
Симуляция начинается с первого DISPATCH и затем происходит как чехарда прыжков между сервисными процедурами. Число хозяйских инструкций косвенных переходов в коде выросло, и каждый их них теперь имеет ассоциированную историю для пары гостевых инструкций. Вероятность неудачного предсказания при этом падает (в [4] утверждается, что с 100% до 50%).
Данная техника имеет название шитый код, по-английски — threaded code; учтите, что современный термин «thread — поток» появился значительно позже и не имеет отношения к рассматриваемой теме.
Данная оптимизация и в наше время используется во вполне популярных проектах. Процитирую пост Utter_step habrahabr.ru/post/261575 от 1 июля сего года:
Vamsi Parasa из команды оптимизации серверных скриптовых языков Intel предложил патч <...>, переводящий блок switch, отвечающий за обработку Python-байткода, на использование computed goto, как это уже сделано в Python 3. Как объяснял Eli Bendersky, в таком огромном switch-блоке, как в блоке разбора байткода в CPython (состоящем из более чем 2000(!) строк), это даёт ускорение порядка 15-20%. Это происходит по двум причинам: computed goto, в отличие от switch-case, не производит граничных проверок, необходимых для оператора switch по стандарту C99, и, что, возможно, более важно, CPU может лучше прогнозировать ветвления в таких ситуациях <...>
Однако при измерении скорости интерпретатора, получаемого из threaded.c с флагами компиляции по умолчанию (программа threaded-notune), я получил неожиданный результат. Скорость работы программы оказалась на 10%–20% ниже switched. Анализ в VTune показал, что причина тормозов всё та же — 100% Branch Mispredict на одном из косвенных переходов внутри DISPATCH:
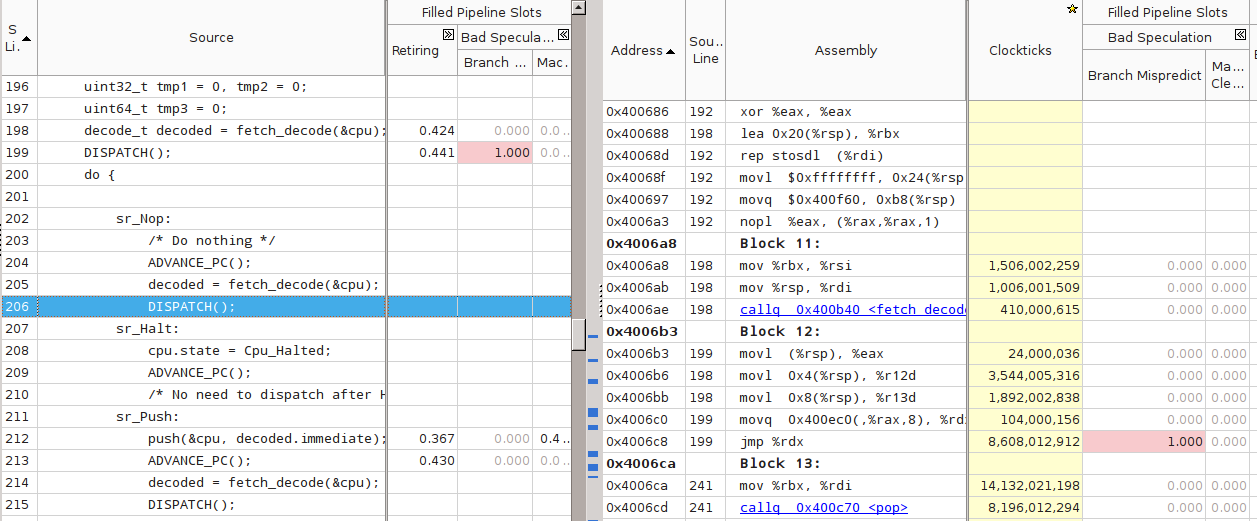
Однако что-то здесь не так — для всех остальных DISPATCH вообще нет никакой статистики. Более того, VTune не показывает для них ассемблерный код. Проверка дизассемблированием с помощью objdump подтвердила подозрения — во всём теле main() был только один косвенный переход, связанный c переходом на сервисные процедуры:
$ objdump -d threaded-notune| grep 'jmpq\s*\*%rdx' 4006c8: ff e2 jmpq *%rdx 400ae7: ff e2 jmpq *%rdx
(Второй jmpq по адресу 400ae7 — из функции register_tm_clones, — не относится к делу). Что же получается — компилятор GCC в результате процесса оптимизации услужливо схлопнул все DISPATCH в один, фактически заново построив переключаемый интерпретатор!
Компилятор — заклятый друг
Тут началась моя борьба с компилятором. Я потратил достаточно много времени, чтобы заставить GCC генерировать код с независимыми косвенными переходами для каждой сервисной процедуры.
- Проверил разные уровни оптимизации. Правильный код получался только при -Og, уровни оптимизаций с -O1 по -O3 схлопывали DISPATCH.
- Пытался заменить goto на ассемблерную вставку и тем самым спрятать от компилятора сам факт перехода по метке:
#define DISPATCH() \ __asm__ __volatile__("mov (%0, %1, 8), %%rcx\n" \ "jmpq *%%rcx\n" \ :: "r"(&service_routines), "r"((uint64_t)decoded.opcode): "%rcx");
В этом случае компилятор всё равно объединял похожие блоки кода. При этом все метки (sr_Add, sr_Nop и т.д.) стали указывать в одно и то же место, и все значения в массиве service_routines стали одинаковыми. Программа перестала корректно работать. - Попробовал вывести заполнение массива service_routines из-под контроля компилятора, чтобы он не смог передвигать метки: сделал содержимое неопределённым и лишь потом заполнял массив. Игры с неопределённым поведением не могли закончиться хорошо. На этот раз GCC законно посчитал весь код после первого DISPATCH недостижимым и полностью удалил его!
Если ничто другое не помогает, прочтите, наконец, инструкцию.
Аксиома Кана
Итак, грубая сила не помогла. Пришлось всё-таки читать документацию и пытаться понять, какая оптимизация мешает моему замыслу. На третьем экране списка опций оптимизаций я увидел следующее:
Please note the warning under -fgcse about invoking -O2 on programs that use computed gotos.
<...>
Note: When compiling a program using computed gotos, a GCC extension, you may get better run-time performance if you disable the global common subexpression elimination pass by adding -fno-gcse to the command line.
Попалась! Это оптимизация -fgcse превращала код threaded в ассемблерное спагетти. Похоже, что с подобной проблемой сталкивались и другие, см. например, комментарий к посту «Fast interpreter using gcc's computed goto»:
I have the same problem as Philip. With G++ the compiler seems to go though incredible contortions to preserve a single indirect jump. Even going so far as to combine jumps from separate jump tables — with a series of direct jumps. This seems utterly bewildering behaviour as it specially breaks the performance gain having a jmp \*%eax for each interpreter leg.
После выяснения вопроса с -fno-gcse генерируемый код стал больше похож на то, что требовалось:
Поиск косвенных переходов в threaded c помощью objdump
$ objdump -d threaded| grep 'jmpq\s*\*%rdx' 4006c8: ff e2 jmpq *%rdx 40070d: ff e2 jmpq *%rdx 40084e: ff e2 jmpq *%rdx 4008bd: ff e2 jmpq *%rdx 40093d: ff e2 jmpq *%rdx 4009b1: ff e2 jmpq *%rdx 400a3b: ff e2 jmpq *%rdx 400aa2: ff e2 jmpq *%rdx 400b15: ff e2 jmpq *%rdx 400b89: ff e2 jmpq *%rdx 400c0b: ff e2 jmpq *%rdx 400c80: ff e2 jmpq *%rdx 400cd8: ff e2 jmpq *%rdx 400d3f: ff e2 jmpq *%rdx 400d90: ff e2 jmpq *%rdx 400dea: ff e2 jmpq *%rdx 400e44: ff e2 jmpq *%rdx 400e8c: ff e2 jmpq *%rdx 400f97: ff e2 jmpq *%rdx
Ещё раз о том, за счёт чего должно возникнуть ускорение. С помощью реорганизации кода мы развязали один узел в исполнении всех симулируемых инструкций, заменив его на более мелкие узлы локальных переходов между парами инструкций. Наверное, эту идею можно развить и дальше — помочь предсказателю переходов правильно запоминать историю исполнения троек, четвёрок и т.д. за счёт соответствующего «разбухания» кода. Например, иметь по две копии всех сервисных процедур, и внутри DISPATCH выбирать только одну из них, в зависимости от кода предыдущей инструкции и её адреса, или какого-то другого критерия. Однако оставлю это в качестве упражнения заинтересовавшимся исследователям.
После выключения неудачной оптимизации скорость threaded стала получше. Насколько — описано в конце статьи. А сейчас перейдём к следующему типу интерпретатора.
Процедурный (subroutined)
Но что это я всё про goto и прочие гадости. Пора вспомнить про нормальный и общепринятый способ организации программ — процедурный механизм (файл subroutined.c). Оформим код каждой сервисной процедуры в виде функции типа service_routine_t:
typedef void (*service_routine_t)(cpu_t *pcpu, decode_t* pdecode);
Пример сервисной процедуры:
void sr_Dec(cpu_t *pcpu, decode_t *pdecoded) {
uint32_t tmp1 = pop(pcpu);
BAIL_ON_ERROR();
push(pcpu, tmp1-1);
}
Инициализация массива service_routines[] теперь использует стандартный оператор взятия адреса функции:
Массив service_routines
service_routine_t service_routines[] = {
&sr_Break, &sr_Nop, &sr_Halt, &sr_Push, &sr_Print,
&sr_Jne, &sr_Swap, &sr_Dup, &sr_Je, &sr_Inc,
&sr_Add, &sr_Sub, &sr_Mul, &sr_Rand, &sr_Dec,
&sr_Drop, &sr_Over, &sr_Mod, &sr_Jump
};
Сам главный цикл интерпретации теперь выглядит гораздо более компактно. На каждой его итерации исполняется функция по адресу, соответствующему опкоду операции.
main() для subroutined
while (cpu.state == Cpu_Running && cpu.steps < steplimit) {
decode_t decoded = fetch_decode(&cpu);
if (cpu.state != Cpu_Running) break;
service_routines[decoded.opcode](&cpu, &decoded); /* Call the SR */
cpu.pc += decoded.length; /* Advance PC */
cpu.steps++;
}
Однако анализ в VTune показывает всю ту же проблему — плохое предсказание для переходов для единственного косвенного перехода при вызове функции:

Пока что непонятно, будет ли subroutined работать быстрее switched. Конечно, можно применить предварительное декодирование — оставлю это в качестве упражнения. Мы же попытаемся на основе subroutined сделать сшитый интерпретатор. При этом «тот, кто нам мешает — тот нам поможет!». Я говорю о компиляторе.
Процедурный с хвостовой рекурсией (tailrecursive)
Ноги, крылья… Главное — хвост!
Прошу читателей обратить внимание на код файла tailrecursive.c. По сравнению с subroutined.c в нём произошли следующие изменения.
Каждая сервисная процедура теперь заканчивается вызовом fetch_decode() для следующей за ней инструкции и макросом DISPATCH():
void sr_Dec(cpu_t *pcpu, decode_t *pdecoded) {
uint32_t tmp1 = pop(pcpu);
BAIL_ON_ERROR();
push(pcpu, tmp1-1);
ADVANCE_PC();
*pdecoded = fetch_decode(pcpu);
DISPATCH();
}
Код макроса DISPATCH:
#define DISPATCH() service_routines[pdecoded->opcode](pcpu, pdecoded);
То есть каждая процедура в конце вызывают процедуру, эмулирующую следующую инструкцию, и затем завершается. Код main(), в котором вроде бы должен происходить цикл интерпретации, выглядит не менее странно:
decode_t decoded = fetch_decode(&cpu); service_routines[decoded.opcode](&cpu, &decoded);
И всё. То есть просто вызывается сервисная процедура для первой гостевой инструкции. Она же, как мы видели, в конце своей работы вызывает процедуру для следующей инструкции, та — для третьей…
Но постойте, как это может работать?! Ведь, углубляясь в симуляцию, мы получим растущий стек вызовов, который вмиг переполнится, и программа упадёт. Однако этого не происходит.
Причина в том, что переход в вызываемую процедуру происходит перед самым выходом из вызывающей — так называемый хвостовой вызов. При этом никакого контекста для вызывающей процедуры хранить не требуется — она фактически завершилась. Поэтому и на стеке сохранять ничего не обязательно. Достаточно умный компилятор заменит финальный call на jmp, при этом стек вызовов не увеличится.
В GCC за такую оптимизацию отвечает флаг -foptimize-sibling-calls (включенный, начиная с -O1). Если её выключить (программа tailrecursive-noopt), то симуляция работает, но быстро падает. У меня она не добежала до 90000 инструкции:
$ ./tailrecursive-noopt 90000 > /dev/null Segmentation fault (core dumped)
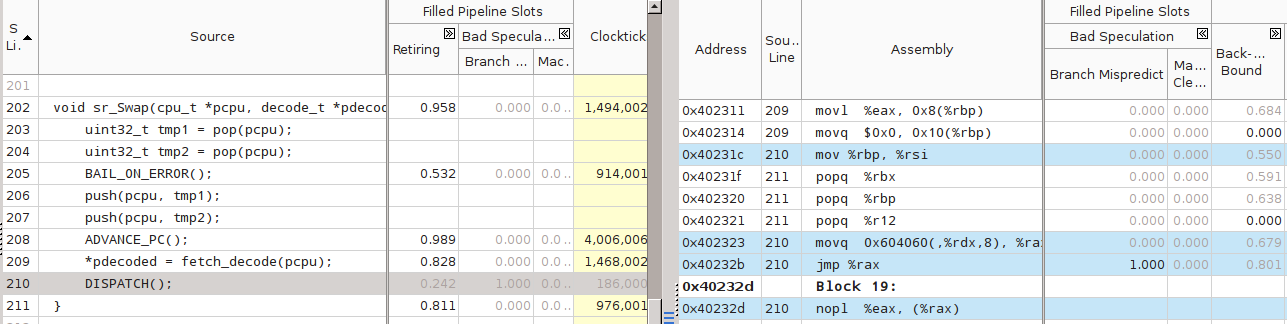
Анализ tailrecursive в VTune показал следующее. Во-первых, верхние места в списке «горячего» кода заняли fetch(_decode) и decode:

Видимо, дальнейшим шагом должна быть оптимизация (избавление от) декодирования.
Во-вторых, компилятор действительно оптимизировал хвостовые вызовы, заменив call на jmpq. Например, вот код функции sr_Swap(), вызывающей множество Branch Mispredict:
Рудиментарный двоичный транслятор (binary translation)
Для тех отважных читателей, что добрались до этого места, я подготовил ещё одну реализацию ВМ (файл translated.c). Формально эта программа не относится к классу интерпретаторов: в ней присутствует генерация машинного кода, соответствующего входной гостевой программе (трансляция). Однако, как мы увидим, translated недалеко ушла от интерпретаторов. Так, в ней тоже присутствует фаза предварительного декодирования, а исполнение, как и в шитом коде, прыгает от одной сервисной процедуры к другой.
Есть и важное отличие. Весь приведённый ранее код — это Си, и он может быть скомпилирован и запущен на любой POSIX-платформе.
На чём тестировались примеры
Ну, может быть, с незначительными правками под особенности конкретной платформы. В конце концов, я тестировал его всего на двух системах: Ubuntu 12.04 и Windows 8.1 (Cygwin). Все интерпретаторы работают. А вот translated под Cygwin мне пока что запустить не удалось — вызов mprotect() возвращает «Invalid argument».
translated же явно завязан на хозяйскую архитектуру Intel 64 (x86_64, AMD64, x64...), и не заработает ни на какой другой. Потребуется существенная модификация функции translate_program() и ещё нескольких мест.
Этот транслятор «рудиментарный», так как его автор поленился сделать капсулы по-человечески. Он служит лишь иллюстративным целям. Я описал два способа построения двоичных трансляторов в этой статье.
Разберём самые важные места в коде программы.
Проверка платформы
#ifndef __x86_64__ /* The program generates machine code, only specific platforms are supported */ #error This program is designed to compile only on Intel64/AMD64 platform. #error Sorry. #endif
Как я уже сказал, программа заработает только на Intel 64. В противном случае препроцессор выдаст ошибку ещё на стадии компиляции.
Прибиваем гвоздями pcpu к R15
/* Global pointer to be accessible from generated code.
Uses GNU extension to statically occupy host R15 register. */
register cpu_t * pcpu asm("r15");
Для ускорения доступа к самой часто используемой структуре cpu_t, хранящей архитектурное состояние моделируемого процессора, статически выделяется хозяйский регистр R15. Для этого используется нестандартное GNU-расширение, и поэтому программа компилируется с флагом -std=gnu11 (смотри Makefile), тогда как все остальные — с флагом -std=c11.
Область для генерированного кода
char gen_code[JIT_CODE_SIZE] __attribute__ ((section (".text#")))
__attribute__ ((aligned(4096)));
Массив gen_code получил два атрибута. Во-первых, адрес его начала должен быть выровнен на размер страницы. Во-вторых, я размещаю его в секции кода (.text), а не в секции данных (.data), где вообще-то место нормальным переменным. Поскольку мы будем в него писать код, лучше, чтобы он был поближе к остальному коду программы. Однако писать в gen_code пока что нельзя — секция .text по умолчанию защищена от записи.
Вход и выход из сгенерированного кода
static void enter_generated_code(void* addr) {
__asm__ __volatile__ ( "jmp *%0"::"r"(addr):);
}
static void exit_generated_code() {
longjmp(return_buf, 1);
}
Вход в транслированный код происходит простым прыжком на начало требуемого блока внутри массива gen_code. Выход сделан через longjmp() — определённый в стандарте Си механизм нелокального goto (как будто обычного goto было мало). Эта штука позволяет выпрыгнуть из функции в любую другую из цепочки вызвавших её, в место, помеченное с помощью setjmp() c тем же значением аргумента (return_buf).
Данный механизм довольно полезен при написании двоичного транслятора, так как упрощает логику обработки исключительных ситуаций. exit_generated_code() вызывается всюду в коде, где необходимо сигнализировать о переходе в состояния Halted/Break, а также при нелинейном изменении PC. Признаться, я, похоже, хватил лишнего — разбросал longjmp по всему коду.
Код сервисных процедур
void sr_Drop() {
(void)pop(pcpu);
ADVANCE_PC(1);
}
void sr_Je(int32_t immediate) {
uint32_t tmp1 = pop(pcpu);
if (tmp1 == 0)
pcpu->pc += immediate;
ADVANCE_PC(2);
if (tmp1 == 0) /* Non-sequential PC change */
exit_generated_code();
}
Процедуры для инструкций ВМ, не имеющих операнда (например, Drop), оперируют только глобально определённым pcpu. Процедуры для инструкций с операндом (например, Je) получают его в первом аргументе. Если сгенерированный код будет вызывать их, то он должен соблюдать ABI хозяйской системы. В случае System V ABI (используемого в Linux) первый аргумент — это регистр RDI.
Код translate_program()
static void translate_program(const Instr_t *prog,
char *out_code, void **entrypoints, int len) {
assert(prog);
assert(out_code);
assert(entrypoints);
/* An IA-32 instruction "MOV RDI, imm32" is used to pass a parameter
to a function invoked by a following CALL. */
#ifdef __CYGWIN__ /* Win64 ABI, use RCX instead of RDI */
const char mov_template_code[]= {0x48, 0xc7, 0xc1, 0x00, 0x00, 0x00, 0x00};
#else
const char mov_template_code[]= {0x48, 0xc7, 0xc7, 0x00, 0x00, 0x00, 0x00};
#endif
const int mov_template_size = sizeof(mov_template_code);
/* An IA-32 instruction "CALL rel32" is used as a trampoline to invoke
service routines. A template for it is "call .+0x00000005" */
const char call_template_code[] = { 0xe8, 0x00, 0x00, 0x00, 0x00 };
const int call_template_size = sizeof(call_template_code);
int i = 0; /* Address of current guest instruction */
char* cur = out_code; /* Where to put new code */
/* The program is short, so we can translate it as a whole.
Otherwise, some sort of lazy decoding will be required */
while (i < len) {
decode_t decoded = decode_at_address(prog, i);
entrypoints[i] = (void*) cur;
if (decoded.length == 2) { /* Guest instruction has an immediate */
assert(cur + mov_template_size - out_code < JIT_CODE_SIZE);
memcpy(cur, mov_template_code, mov_template_size);
/* Patch template with correct immediate value */
memcpy(cur + 3, &decoded.immediate, 4);
cur += mov_template_size;
}
assert(cur + call_template_size - out_code < JIT_CODE_SIZE);
memcpy(cur, call_template_code, call_template_size);
intptr_t offset = (intptr_t)service_routines[decoded.opcode]
- (intptr_t)cur - call_template_size;
if (offset != (intptr_t)(int32_t)offset) {
fprintf(stderr, "Offset to service routine for opcode %d"
" does not fit in 32 bits. Cannot generate code for it, sorry",
decoded.opcode);
exit(2);
}
uint32_t offset32 = (uint32_t)offset;
/* Patch template with correct offset */
memcpy(cur + 1, &offset, 4);
i += decoded.length;
cur += call_template_size;
}
}
Самый сложный блок программы требует подробного рассмотрения. В результате работы этой функции по содержимому гостевой программы prog длиной len должны быть заполнены два массива: out_code — хозяйским гостевым кодом, симулирующим последовательность инструкций из prog, и массив указателей entrypoints на начала индивидуальных капсул внутри out_code.
Каждая гостевая инструкция декодируется, после чего транслируется в одну или две хозяйских инструкции. Для гостевых инструкций без операндов это «call rel32», для инструкций с операндом — пара «mov imm, %rdi; call rel32». RDI здесь, потому что вызываемые процедуры ожидают увидеть в нём свой аргумент.
rel32 — это 32-битное смещение адреса вызываемой функции по отношению к текущей инструкции. Для каждой новой инструкции CALL оно разное, поэтому оно каждый раз высчитывается (offset32) относительно текущего положения.
Почему я использовал здесь относительные адреса, а не абсолютные? Потому что хозяйская система использует 64-битные адреса, и для передачи 64 бит в CALL потребовалась бы ещё одна инструкция и ещё один регистр. Из-за этого gen_code размещён в секции кода — чтобы все смещения умещались в 32 бита. Ведь секция данных может быть помещена очень далеко от кода.
Заметьте, что как код шаблонов (mov_template_code и call_template_code), так и последующие манипуляции с ними (вызовы memcpy()) зависят способа кодирования хозяйских инструкций. При портировании translated на другую архитектуру их придётся исправить в первую очередь.
Результат трансляции программы Primes, полученный с помощью GDB в момент окончания работы translate_program():
Хозяйский код для Primes
(gdb) disassemble gen_code, gen_code+4096 Dump of assembler code from 0x403000 to 0x404000: 0x0000000000403000 <gen_code+0>: mov $0x186a0,%rdi 0x0000000000403007 <gen_code+7>: callq 0x4020c0 <sr_Push> 0x000000000040300c <gen_code+12>: mov $0x2,%rdi 0x0000000000403013 <gen_code+19>: callq 0x4020c0 <sr_Push> 0x0000000000403018 <gen_code+24>: callq 0x4029a0 <sr_Over> 0x000000000040301d <gen_code+29>: callq 0x4029a0 <sr_Over> 0x0000000000403022 <gen_code+34>: callq 0x402720 <sr_Sub> 0x0000000000403027 <gen_code+39>: mov $0x17,%rdi 0x000000000040302e <gen_code+46>: callq 0x4021a0 <sr_Je> 0x0000000000403033 <gen_code+51>: mov $0x2,%rdi 0x000000000040303a <gen_code+58>: callq 0x4020c0 <sr_Push> 0x000000000040303f <gen_code+63>: callq 0x4029a0 <sr_Over> 0x0000000000403044 <gen_code+68>: callq 0x4029a0 <sr_Over> 0x0000000000403049 <gen_code+73>: callq 0x4027e0 <sr_Swap> 0x000000000040304e <gen_code+78>: callq 0x402720 <sr_Sub> 0x0000000000403053 <gen_code+83>: mov $0x9,%rdi 0x000000000040305a <gen_code+90>: callq 0x4021a0 <sr_Je> 0x000000000040305f <gen_code+95>: callq 0x4029a0 <sr_Over> 0x0000000000403064 <gen_code+100>: callq 0x4029a0 <sr_Over> 0x0000000000403069 <gen_code+105>: callq 0x4027e0 <sr_Swap> 0x000000000040306e <gen_code+110>: callq 0x4028c0 <sr_Mod> 0x0000000000403073 <gen_code+115>: mov $0x5,%rdi 0x000000000040307a <gen_code+122>: callq 0x4021a0 <sr_Je> 0x000000000040307f <gen_code+127>: callq 0x402300 <sr_Inc> 0x0000000000403084 <gen_code+132>: mov $0xfffffffffffffff1,%rdi 0x000000000040308b <gen_code+139>: callq 0x402080 <sr_Jump> 0x0000000000403090 <gen_code+144>: callq 0x4029a0 <sr_Over> 0x0000000000403095 <gen_code+149>: callq 0x402460 <sr_Print> 0x000000000040309a <gen_code+154>: callq 0x4022a0 <sr_Drop> 0x000000000040309f <gen_code+159>: callq 0x402300 <sr_Inc> 0x00000000004030a4 <gen_code+164>: mov $0xffffffffffffffe4,%rdi 0x00000000004030ab <gen_code+171>: callq 0x402080 <sr_Jump> 0x00000000004030b0 <gen_code+176>: callq 0x402060 <sr_Halt> 0x00000000004030b5 <gen_code+181>: callq 0x4020a0 <sr_Break> 0x00000000004030ba <gen_code+186>: callq 0x4020a0 <sr_Break> 0x00000000004030bf <gen_code+191>: callq 0x4020a0 <sr_Break> 0x00000000004030c4 <gen_code+196>: callq 0x4020a0 <sr_Break> 0x00000000004030c9 <gen_code+201>: callq 0x4020a0 <sr_Break> 0x00000000004030ce <gen_code+206>: callq 0x4020a0 <sr_Break> <...>
Ещё раз отмечу: на момент начала работы translated этого кода не существовало.
Конечно, вместо того, чтобы без конца их вызывать, правильнее было бы подставить тела самих сервисных процедур в out_code. При этом было бы сэкономлено время на входах и выходах в функции. Но пришлось бы что-то делать с прологами-эпилогами процедур, т.е. учиться инлайнить код за спиной у компилятора. Я оставлю это упражнение читателям, желающим поглубже разобраться с вопросами кодогенерации.
Наконец, изучим происходящее в main():
main() внутри translate
/* Code section is protected from writes by default, un-protect it */
if (mprotect(gen_code, JIT_CODE_SIZE, PROT_READ | PROT_WRITE | PROT_EXEC)) {
perror("mprotect");
exit(2);
}
/* Pre-populate resulting code buffer with INT3 (machine code 0xCC).
This will help to catch jumps to wrong locations */
memset(gen_code, 0xcc, JIT_CODE_SIZE);
void* entrypoints[PROGRAM_SIZE] = {0}; /* a map of guest PCs to capsules */
translate_program(cpu.pmem, gen_code, entrypoints, PROGRAM_SIZE);
setjmp(return_buf); /* Will get here from generated code. */
while (cpu.state == Cpu_Running && cpu.steps < steplimit) {
if (cpu.pc > PROGRAM_SIZE) {
cpu.state = Cpu_Break;
break;
}
enter_generated_code(entrypoints[cpu.pc]); /* Will not return */
}
Во-первых, обязательно необходимо разрешить запись в gen_code. Это делается с помощью системного вызова mprotect(). Затем на всякий случай заполним gen_code целиком однобайтовой инструкцией INT3 — 0xcc. Если при исполнении сгенерированного кода что-то пойдёт не так, и управление передадут на незаполненный участок массива, сразу произойдёт прерывание, что облегчит отладку.
Затем транслируем программу и устанавливаем точку возврата с помощью setjmp(). Именно сюда, на начало цикла while(), будет возвращаться исполнение.
Цикл while каждый раз будет передавать управление, используя в качестве адреса значения из отображения entrypoints для текущего PC. Возможно, возник вопрос — а зачем вообще выходить из gen_code до окончания работы сгенерированного кода?
Обратите своё внимание ещё раз на листинг gen_code выше. В нём нет ни одной инструкции ветвления — все MOV и CALL исполнятся последовательно. Однако в исходной программе были циклы!
Трансляция гостевых инструкций переходов — это сложный момент: смещения адресов гостевого кода в общем случае нелинейным образом связаны со смещениями между капсулами кода хозяйского. Я обошёл эту сложность, используя следующий трюк. Все сервисные процедуры, изменившие PC нелинейным образом (т.е. Jump, JE, JNE), обязаны вызывать exit_generated_code(). И уже внешний код, используя сохранённые значения в entrypoints, заново зайдёт в гостевой код по правильному адресу. Для остальных, «обычных» сервисных процедур, longjmp не нужен — они просто проваливаются на следующую по коду процедуру.
У меня есть идея, как обойтись без longjmp внутри процедур для JNE, JE и Jump. Можно узнать следующую точку входа из entrypoints сразу внутри процедуры, и поместить дополнительное значение адреса возврата RIP на стеке так, чтобы при выходе из текущей процедуры оказаться не в вызывавшей её функции, а сразу в нужной процедуре! Ещё одно упражнение для пытливого читателя — реализовать эту идею.
Узкие места изменились. Теперь VTune обозначил главной проблемой «Front End Bound»:

В верх списка попали сервисные процедуры, что можно в некоторой мере считать успехом:

Отмечу, что для динамически создаваемого кода VTune ожидаемо не может ассоциировать символьную информацию. Однако этот инструмент предоставляет JIT Profiling API, позволяющий отметить вход и выход в регионы генерированного кода. translated его не использует, но для серьёзной профилировки он явно пригодился бы.
Кто кого — измерения
Для тестовых прогонов использовался старый, но всё ещё бойкий ноутбук Lenovo Thinkpad X220i.
- ОС: Ubuntu 12.04.5 LTS, Linux версии 3.2.0-75-generic x86_64
- Процессор: Intel® Core(TM) i3-2310M CPU @ 2.10GHz
- 4 Гбайт ОЗУ
Компиляторы:
- GCC 4.8.1-2ubuntu1~12.04
- ICC 15.0.3 20150407
Сравниваемые варианты программ.
- switched — переключаемый интерпретатор.
- threaded — шитый интерпретатор.
- predecoded — переключаемый интерпретатор с предварительным декодированием.
- subroutined — процедурный интерпретатор.
- threaded-cached — шитый с предварительным декодированием интерпретатор.
- tailrecursive — процедурный интерпретатор с оптимизированными хвостовыми вызовами.
- translated — двоичный транслятор.
- native — реализация алгоритма Primes на Си. Не совсем честно сравнивать статичную программу с реализациями ВМ, способной исполнить произвольный код. Тем не менее, в сравнении native участвует, чтобы показать потенциал к возможному ускорению.
Проведение экспериментов автоматизировалось с помощью скрипта measure.sh. Для каждого варианта измерялось время исполнения пяти прогонов программы и высчитывалось среднее значение.
Для GCC:

predecoded работает лишь чуть быстрее switched. По непонятным мне причинам простой threaded так и остался медленнее switched. А вот сочетание предварительного декодирования с шитым кодом, threaded-cached, дало заметный прирост. Удивительно хорошо показали себя процедурный интерпретатор subroutined и процедурный с хвостовыми оптимизациями tailrecursive. Ожидаемо было и то, что translated обошёл все интерпретаторы.
Для ICC:

Эти результаты ещё более странные. Абсолютно худший результат показал threaded, несмотря на все мои старания. predecoded же, наоборот, настолько быстр, что у меня возникли сомнения в корректности его исполнения. Однако дополнительные проверки и повторные измерения не обнаружили проблем. threaded-cached обошёл по скорости процедурные варианты, почти сравнявшись с translated, который, в свою очередь, не самый быстрый.
Отмечу, что ICC не понял мои попытки помочь с генерацией кода для шитых вариантов, т.к. не все опции GCC он понимает:
icc -std=c11 -O2 -Wextra -Werror -gdwarf-3 -fno-gcse -fno-thread-jumps -fno-cse-follow-jumps -fno-crossjumping -fno-cse-skip-blocks -fomit-frame-pointer threaded-cached.c -o threaded-cached icc: command line warning #10006: ignoring unknown option '-fno-gcse' icc: command line warning #10006: ignoring unknown option '-fno-thread-jumps' icc: command line warning #10006: ignoring unknown option '-fno-cse-follow-jumps' icc: command line warning #10006: ignoring unknown option '-fno-crossjumping' icc: command line warning #10006: ignoring unknown option '-fno-cse-skip-blocks'
Конечно, очень интересно было бы изучить причины аномалий, обнаруженных на сборках ICC. Но статья и без этого разбухла до неприличных размеров, так что позволю себе отложить этот анализ на следующий раз.
Заключение
Как и ожидалось, различные техники построения интерпретаторов различаются по скорости. Однако нельзя заранее, только из структуры кода ВМ, сделать выводы о том, какой из вариантов будет быстрее на практике. Более того, различные техники можно комбинировать, но возникающие при этом эффекты не суммируются: посмотрите, как изменялась производительность при использовании только предварительного декодирования или шитого кода, и какой эффект получился от их совместного использования.
Немалую, и не всегда положительную, роль при этом играет компилятор. В зависимости от применённых им оптимизаций очень простая схема интерпретации может показать себя хорошо, а вот супернавороченная оказаться в хвосте списка.
Статья написана, совесть моя перед самим собой чиста, пора и в отпуск. Спасибо за внимание!
Литература
- Баранов С. Н., Ноздрунов Н. Р. Язык Форт и его реализации. 1988 Издательство «Машиностроение» 2.1. Шитый код и его разновидности www.netlib.narod.ru/library/book0001/ch02_01.htm
- M. Anton Ertl. 2007. Speed of various interpreter dispatch techniques V2 www.complang.tuwien.ac.at/forth/threading
- James E. Smith and Ravi Nair. Virtual machines – Versatile Platforms for Systems and Processes. Elsevier, 2005. ISBN 978-1-55860-910-5.
- M. Anton Ertl and David Gregg. The structure and performance of efficient interpreters // Journal of Instruction-Level Parallelism 5 (2003), pp. 1–25. www.jilp.org/vol5/v5paper12.pdf
- Terrence Parr. Language Implementation Patterns — The Pragmatic Bookshelf, 2010. ISBN-10: 1-934356-45-X ISBN-13: 978-1-934356-45-6
