Если Вы последние 10 лет провели на удаленном острове, без интернета и в отрыве от цивилизации, то специально для Вас мы попытаемся еще раз рассказать про концепцию MapReduce. Введение будет небольшим, в объеме достаточном, для реализации концепции MapReduce в среде InterSystems Caché. Если же Вы не сильно далеко удалялись последние 10 лет, то сразу переходите ко 2ой части, где мы создаем основы инфраструктуры.

Давайте сразу определимся, я не являюсь большим поклонником MapReduce, о чем можно было догадаться по предыдущим моим статьям/переводам — Майкл Стоунбрейкер — "Hadoop на распутье" и "Утилиты командной строки могут быть в 235-раз быстрее вашего Hadoop кластера" [Если быть точнее, я не являюсь поклонником Java реализаций Hadoop MapReduce, но это уже личное]
В-любом случае, несмотря на все эти оговорки и недостатки, есть еще множество причин, которые заставляют вернуться к этой теме и попытаться реализовать MapReduce в другой среде и на другом языке. Все это мы озвучим позже, но до этого поговорим про BigData...
Когда Data большая, а когда маленькая?
Несколько лет назад все стали сходить с ума по BigData, никто правда не знал когда его маленькие данные становятся большими, и где тот предел, но все понимали что это модно, молодёжно и «так» надо делать. Время шло, кое-кто объявил, что BigData уже не buzzword (это довольно таки забавно, но Gartner реально убрал волевым решением BigData со своей кривой базвордов за 2016, обосновав это тем, что термин расщепился на другие). Вне зависимости от желания Gartner термин BigData еще среди нас, живее всех живых, и думаю самое время определиться с его пониманием.
Например, понимаем ли мы до конца, когда наши «не очень большие данные» превращаются в «БОЛЬШИЕ ДАННЫЕ»?
Наиболее конкретный (из разумных) ответов дал Дэвид Кантер, один из самых уважаемых экспертов по архитектуре процессоров в целом и x86 в частности1:
FWIW, когда я, работая в Интеле, перешел в аппаратную команду, работающую над «процессором следующего поколения» (don'task), то я начал с изучения материалов про архитектуру процессора Nehalem на сайте Дэвида Кантера, а не с внутренних доков HAS и MAS. Потому как у Дэвида было лучше, и понятнее.
Т.е. если у вас «всего пара терабайт» данных, то вы, скорее всего, сможете найти аппаратную конфигурацию серверной машины, достаточную для того, чтобы все данные поместились в памяти сервера (при достаточном, конечно, количестве денег и мотивации), и ваши данные еще не совсем Большие.
BigData начинаются когда такой подход с вертикальным масштабированием (нахождением «более лучшей» машины) перестают работать, т.к. с определенного размера данных вы уже не можете купить большей конфигурации, ни за какие (разумные) деньги. И надо начинать расти вширь.
Проще – лучше
Ок, определившись с какого размера у нас данные выросли до термина BigData, мы должны определиться с подходами, которые работают на больших данных. Одним из первых подходов, который начал массово применяться на больших данных был MapReduce. Существует множество альтернативных программных моделей, работающих с большими данными, которые могут даже оказаться лучше или гибче чем MapReduce, но тот, однозначно может считаться самым упрощенным, хотя может быть и не самым эффективным.
Более того, как только мы начинаем рассматривать какую-то программную платформу, или платформу баз данных, на предмет поддержки BigData, мы по умолчанию предполагаем, что MapReduce сценарий поддерживается на этой платформе внутренними или внешними утилитами.
Другими словами – без MapReduce ты не можешь утверждать, что твоя платформа поддерживает BigData!
ALARM – если вы все же были не на луне последние 10 лет, то можете смело проматывать рассказ про основы алгоритма MapReduce, скорее всего, вы уже в курсе. Для остальных мы попытаемся (еще раз) рассказать про то, с чего это все начиналось, и как этим всем можно воспользоваться в конце 2016 года. (Особенно на платформах, где MapReduce не поддерживается из коробки.)
Часто было замечено, что самый простой подход к решению задачи позволяет получить наилучше результаты, и остаётся жить в продукте на продолжительное время. Вне от оригинального плана авторов. Даже если, в итоге, он не оказывается самым эффективным, но в силу того, что сообщество уже его широко узнало, и все изучили, и он просто достаточно хорош и решает задачи. Примерно такой эффект и наблюдается с моделью MapReduce – будучи очень простым в основе своей, он по-прежнему широко используется даже после того, как оригинальные авторы декларировали его смерть.
Масштабирование в Caché
Исторически InterSystems Caché имел достаточно инструментов в своём арсенале, как для вертикального, так и горизонтального масштабирования. Как мы все знаем (грустный смайл) Caché это не только сервер баз данных, но и сервер приложений, который может использовать ECP (Enterprise Cache Protocol) для горизонтального масштабирования и высокой доступности.
Особенность ECP протокола – будучи сильно оптимизированным протоколом для когерентности доступа к одним и тем же данным на разных узлах кластера, сильно упирается в производительность write daemon на центральном узле сервера БД. ECP позволяет добавить дополнительные счетные узлы с ядрами процессоров, если нагрузка на write-daemon не очень высокая, но этот протокол не поможет отмасштабировать ваше приложение горизонтально, если каждый из вовлеченных узлов порождает большую активность на запись. Дисковая подсистема на сервере БД по-прежнему будет узким местом.
На самом деле, при работе с большими данными современные приложения предполагают использование другого, или даже ортогонального озвученном выше, подхода. Масштабировать приложение горизонтально надо с использованием дисковой подсистемы на каждом из узлов кластера. В отличие от ECP, где данные приносятся на удаленный узел, мы наоборот, приносим код, размер которого предполагается малым, к данным на каждом узле, размер которых предполагается очень большим (как минимум относительно размера данных). Похожий тип партиционирования, именуемый шардингом, в будущем будет реализован в SQL движке Caché в одном из будущих продуктов. Но даже сегодня, на имеющихся в платформе средствах, мы можем реализовать нечто простое, что позволило бы нам спроектировать горизонтально масштабируемую систему, с применением современных, «модных, молодежных» подходов. Например, с применением MapReduce…
Google MapReduce
Оригинальная реализация MapReduce была написана в Google на Си++, но так получилось, что широкое распространение парадигмы началось в индустрии только с реализации MapReduce от Apache, которая на Java. В-любом случае, вне зависимости от языка реализации, идея остается одной и той же, будь та реализована на C++, Java, Go, или Caché ObjectScript, как в нашем случае.
[Хотя, для Caché ObjectScript реализации мы воспользуемся парой трюков, доступных только при операциях с многомерными массивами, известными как глобалы. Просто, потому что можем]
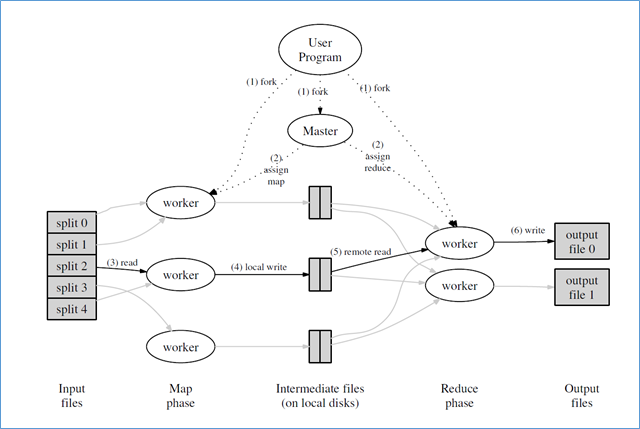
Рисунок 1. Исполнениевсреде MapReduce изстатьи "MapReduce: Simplified Data Processing on Large Clusters", OSDI-2004
Давайте пройдемся по стадиям алгоритма MapReduce, нарисованного в картинке выше:
На входе у нас есть набор «файлов», или потенциально бесконечный поток данных, который мы можем разбить (партиционировать) на несколько независимых кусков данных;
Также имеем набор параллельных исполнителей (локальных внутри узла или может быть удаленных, на других узлах кластера) которые мы можем назначить как обработчиков входных кусков данных (стадия «отображение» /« map »)
Эти параллельные обработчики читают входной поток данных и выводят в выходной поток пару(ы) «ключ-значение». Выходной поток может быть записан в выходные файлы или куда-то еще (например, в кластерную файловую систему Google GFS, Apache HDFS, или в какое другое «волшебное место» реплицирующее данные на несколько узлов кластера);
- На следующей стадии, именуемой «свертка» / « reduce » у нас имеется другой набор обработчиков, которые занимаются (сюрприз) … сверткой. Они читают, для заданного ключа, всю коллекцию данных, и выводят результирующие данные как очередные «ключ-значения». Выходной поток этой стадии, аналогично предыдущей стадии, записывается в волшебные кластерные файловые системы или их аналоги.
Заметим, что MapReduce подход – пакетный по своей природе. Он не очень хорошо обрабатывает бесконечные потоки входных данных, в силу пакетной реализации, и будет ожидать завершения работы на каждой из его стадий («отображение» или «свертка»), перед тем как продвинуться дальше в конвейере. Этим он отличается от более современных поточных алгоритмов, используемых, например, в Apache Kafka, которые по своему дизайну нацелены на обработку «бесконечных» входных потоков.
Знающие люди пропустили данный раздел, а незнающие, думаю, по-прежнему смущены. Давайте рассмотрим классический пример word-count (подсчет слов в потоке данных), который по традиции используется при объяснении реализации MapReduce на разных языках программирования, и в разных средах.
Итак, допустим, нам надо подсчитать количество слов во входной коллекции (достаточно большой) файлов. Для ясности определимся, что словом будем считать последовательность символом между пробельными символами, т.е. цифры, знаки пунктуации также посчитаются частью слова, это, конечно, не очень хорошо, но в рамках простого примера это нас не волнует.
Будучи Си++ разработчиком в глубинах своей души, для меня алгоритм становится ясен, когда я вижу пример на Си++. Если «Вы — не такой», то не расстраивайтесь, скоро мы его покажем в упрощенном виде.
#include "mapreduce/mapreduce.h"
// User's map function
class WordCounter : public Mapper {
public:
virtual void Map(const MapInput& input) {
const string& text = input.value();
const int n = text.size();
for (int i = 0; i < n; ) {
// Skip past leading whitespace
while ((i < n) && isspace(text[i]))
i++;
// Find word end
int start = i;
while ((i < n) && !isspace(text[i]))
i++;
if (start < i)
Emit(text.substr(start,i-start),"1");
}
}
};
REGISTER_MAPPER(WordCounter);
// User's reduce function
class Adder : public Reducer {
virtual void Reduce(ReduceInput* input) {
// Iterate over all entries with the
// same key and add the values
int64 value = 0;
while (!input->done()) {
value += StringToInt(input->value());
input->NextValue();
}
// Emit sum for input->key()
Emit(IntToString(value));
}
};
REGISTER_REDUCER(Adder);
int main(int argc, char** argv) {
ParseCommandLineFlags(argc, argv);
MapReduceSpecification spec;
// Store list of input files into "spec"
for (int i = 1; i < argc; i++) {
MapReduceInput* input = spec.add_input();
input->set_format("text");
input->set_filepattern(argv[i]);
input->set_mapper_class("WordCounter");
}
// Specify the output files:
// /gfs/test/freq-00000-of-00100
// /gfs/test/freq-00001-of-00100
// ...
MapReduceOutput* out = spec.output();
out->set_filebase("/gfs/test/freq");
out->set_num_tasks(100);
out->set_format("text");
out->set_reducer_class("Adder");
// Optional: do partial sums within map
// tasks to save network bandwidth
out->set_combiner_class("Adder");
// Tuning parameters: use at most 2000
// machines and 100 MB of memory per task
spec.set_machines(2000);
spec.set_map_megabytes(100);
spec.set_reduce_megabytes(100);
// Now run it
MapReduceResult result;
if (!MapReduce(spec, &result)) abort();
// Done: 'result' structure contains info
// about counters, time taken, number of
// machines used, etc.
return 0;
}
Программа, приведенная выше, вызывается со списком файлов, которые надо обработать, переданным через стандартные argc/argv.
Объект MapReduceInput инстанциируется как обертка для доступа к каждому файлу из входного списка и планируется на исполнение классом WordCount для обработки его данных;
MapReduceOutput инстанциируется с перенаправлением выходных данных в кластерную файловую систему GoogleGFS (обратите внимание на /gfs/test/*)
Классы Reducer (свёртщик, хмм) и Combiner (комбинатор) реализуются Си++ классом Adder, текст которого приводится в этой же программе;
Функция Map в классе Mapper, реализованная в нашем случае в классе WordCouner, получает данные через обобщенный интерфейс MapInput. Нашем случае этот интерфейс будет поставлять данные из файлов. Класс, реализующий данный интерфейс, должен реализовать метод value(), поставляющий следующую строку как string, и длину входных данных в методе size();
В рамках решения нашего задания, подсчета количества слов в файле, мы будем игнорировать пробельные символы и считать все остальное, между пробелами как отдельное слово (вне зависимости от знаков пунктуации). Найденное слово пишем в выходной «поток» через вызов функции Emit(word, "1");
Функция Reduce в классе реализации интерфейса Reducer (в нашем случае это Adder) получает свои входные данные через другой обобщенный интерфейс ReduceInput. Данная функция будет вызвана для определенного ключа (слова из файла, в нашем случае) из пары «ключ-значение», записанных на предыдущей стадии Map. Эта функция будет вызвана для обработки коллекции значений, советующих данному ключу (в нашем случае для последовательности «1»). В рамках нашего задания, ответственность функции Reducer — подсчитать количество таких единиц на входе и выдача суммарного числа в выходной канал.
- Если у нас построен кластер из нескольких узлов, или просто запускается множество обработчиков в рамках алгоритма MapReduce, то ответственностью «мастера» будет разбить поток выдаваемых пар «ключ-значение» на соответствующие коллекции, и перенаправление этих коллекций на вход Reduce обработчикам.
Детали реализации такого мастер узла будут сильно зависеть от протокола реализации используемой технологии кластеризации, т.ч. мы опустим подробный рассказ об этом за скобками текущего повествования. В нашем случае, для Caché ObjectScript, для некоторых рассматриваемых алгоритмов (как текущий WordCount) мастер может быть реализован тривиально, в силу использования глобалов и их природы, как отсортированных, но разреженных массивов. О чем подробнее позже.
- В общем случае, часто необходимо завести несколько шагов Reduce, например, для случаев, когда невозможно обработать полную коллекцию значений за один заход. И тогда появляется дополнительная(ые) стадия(ии) Combiner, которые будут дополнительно агрегировать результаты данных с предыдущих стадий Reduce.
Если, после такого подробного описания Си++ реализации, вам по-прежнему непонятно что такое MapReduce, то давайте попробуем изобразить этот алгоритм на нескольких строках одного известного скриптового языка:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));Как в этом упрощенном примере видим, ответственностью функции map будет выдать последовательность пар <ключ, значение>. Эти пары перемешиваются и сортируются в мастере, и результирующие коллекции значений, для заданного ключа, отсылаются на вход функций reduce (свертка), которые, в свою очередь, ответственны за генерацию выходной пары <ключ, значение>. В нашем случае это будет <слово, счетчик>
В классической реализации MapReduce трансформация коллекции пар <ключ, значение> в раздельные коллекции <ключ, значени(я)> является самой время- и ресурсоёмкой операцией. В случае же Caché реализации, как из-за природы реализации хранилищ btree*, так и связующего протокола ECP, сортировка и агрегация на мастере становятся не такой большой задачей, реализуемой почти на автомате, почти «забесплатно». Об этом мы расскажем при случае в следующих статьях.
Пожалуй, этого достаточно для вводной части – мы еще не затронули собственно Caché ObjectScript реализации, хотя и дали достаточно информации для начала реализации MapReduce на любом языке. К нашей реализации MapReduce мы вернемся в следующей статье. Оставайтесь на линии!
