В этой статье мы рассмотрим способы применения машинного обучения в сфере высокочастотного трейдинга (HFT) и анализа микроструктурных данных. Машинное обучение – это замечательный раздел информатики, использующий модели и методы из статистики, теории алгоритмов, теории вычислительной сложности, искусственного интеллекта, теории управления и огромного числа других дисциплин. Основным объектом исследования машинного обучения являются эффективные алгоритмы, позволяющие создать хорошие предсказательные модели на основании больших наборов данных – именно поэтому оно так хорошо подходит для решения задач высокочастотного трейдинга: заключения сделок и расчета показателя «альфа».
Поскольку такое явление как «высокочастотный трейдинг» возникло совсем недавно, работ, посвященных применению машинного обучения в этой сфере, существует немного. Однако мы рассмотрим три области его применимости:
- Оптимизация процесса заключения сделок с использованием обучения с подкреплением;
- Предсказание изменения цены на основании состояния биржевого стакана;
- Оптимизация процесса заключения сделок в дарк-пулах на основании исследования неполных данных.
Оптимизация процесса заключения сделок с использованием обучения с подкреплением
Давайте рассмотрим возможность использования машинного обучения для решения самой фундаментальной алгоритмической торговой проблемы – оптимизирования процесса заключения сделок. В простейшем случае проблема определяется пакетом акций, скажем, AAPL, их количеством V, а также временем или числом шагов T. Таким образом, мы должны купить определенное количество акций V за T шагов, минимизировав стоимость покупки.
Базовые алгоритмы расчета цены, средневзвешенной объемом, сопоставляют свое текущее состояние (v;t) с объемом акций, который должен быть приобретен к шагу t, основываясь на исторических показателях интересующего нас пакета акций (значения показателей могут варьироваться в зависимости от времени дня и времени года). Если показатель v говорит нам, что мы отстаем от расписания, то стоит начать торговать более агрессивно и чаще покупать акции по цене продавца. Если же мы опережаем график, то можно торговать более пассивно, ожидая улучшения цен. Подобные сравнения проводятся непрерывно или с определёнными интервалами, позволяя нам подстроиться под расписание и текущие условия на бирже.
Свое начало обучение с подкреплением берет глубоко в теории управления и является подразделом машинного обучения, разработанным специально для изучения динамических инструкций. Мы опустим технические подробности, однако опишем основные этапы:
- Определение состояния среды (обычно ограниченной), чьи элементы представляют собой изменяющиеся условия, в зависимости от которых выбирается порядок действий. В нашем случае среда имеет две переменные (v;t), а также другие компоненты и признаки, описывающие состояние биржевого стакана.
- Определение набора действий для каждого состояния. В нашем случае мы будем устанавливать лимит заказов для оставшегося объема акций (изменяющаяся цена).
- Определение модели воздействия, которое оказывают наши решения, в виде вероятности исполнения при определенных условиях, формирующейся на основании исторических данных.
- Определение функции стоимости, отражающей ожидаемый или средний доход при принятии определенного решения в заданный момент времени.
- Алгоритмы для изучения оптимальных правил – переход от состояний к действиям – минимизирующих эмпирическую стоимость акций (затраты на их покупку) на основании тренировочных данных.
- Проверка изученной последовательности действий путем оценки её производительности за пределами выборки.
Потенциал такого метода можно пронаблюдать на графиках (рисунок 1). На графике приведено сравнение производительностей одноразовой стратегии и алгоритмов, изученных с помощью обучения с подкреплением. Одноразовые стратегии в начале торгового периода закрепляют размер лимита заказов на определённой стоимости p для всего целевого объема V и не меняют его на протяжении всех T шагов. В конце торгового периода, если не был куплен весь объем V, рыночный приказ дается с условием достижения целевого объема. Чтобы нормализовать ценовые различия по всем пакетам акций, мы измеряем производительность путем оценки разницы между средней уплаченной суммой (за акцию) и средней точкой спреда в начале торгового периода – чем она меньше (чем выше средняя точка спреда), тем лучше.

Рисунок 1 – Производительность одноразового метода на тестовом наборе (черный левый столбик) и производительность обучения с подкреплением (серый и белый столбики) на пакетах акций AMZN, NVDA и QCOM. На оси x указаны целевой объем акций и период; целевой объем разделен на I уровней, а период разделен на T дискретных шагов, равномерно распределенных во времени
Пока что мы практически не использовали микроструктурную информацию и не производили реконструкцию биржевого стакана – мы лишь определяли стоимость покупки и оценивали её влияние на стакан котировок. Машинное обучение позволяет повысить производительность, если передать алгоритму больше информации. Какие переменные, связанные с биржевым стаканом, мы можем использовать? Вот несколько из них:
- Бид-аск спред – это величина, отражающая разницу между ценой покупателя (бид) и ценой продавца (аск) в текущих биржевых стаканах;
- Дисбаланс бид/аск объемов – это величина, равняющаяся числу покупаемых акций за вычетом продаваемых акций в текущих биржевых стаканах;
- Объем транзакций – это величина, описывающая количество купленных акций за последние 15 секунд, минус число акций, проданных за это же время;
- Стоимость исполнения рыночного приказа в текущий момент – это цена, которую мы платим за покупку оставшейся доли акций путем выставления рыночного ордера.
Мы провели серию аналогичных экспериментов в нашем исходном состоянии (v;t), используя признаки биржевого стакана, описанные выше. Полученные результаты сведены в таблицу 1.
Таблица 1 – Снижение издержек обращения, при добавлении новых признаков
| Признаки | Снижение издержек обращения |
|---|---|
| Бид-аск спред | 7,97% |
| Дисбаланс бид/аск объемов |
0,13% |
| Объем транзакций |
2,81% |
| Стоимость исполнения рыночного ордера в текущий момент |
4,26% |
| Все признаки сразу | 12,85% |
Три из четырех признаков привели к значительным улучшениям; дисбаланс бид/аск объемов оказал наименьшее влияние. Последняя строка таблицы отражает повышение производительности при использовании всех признаков одновременно – это практически 13%.
Предсказание изменения цены на основании состояния биржевого стакана
Стоит отметить, что в предыдущем разделе мы не учли множество признаков, напрямую затрагивающих недавние направленные движения цен исполнения, которые могут оказаться очень важными. Поэтому в следующих экспериментах нами были использованы:
- Бид-аск спред – использовался в предыдущем пункте;
- Цена – это признак, отражающий недавние направленные движения цен исполнения;
- Умная цена – это среднее между ценой предложения и ценой спроса, взвешенное согласно величине, обратной их объему;
- Торговый показатель – это признак, показывающий, насколько часто покупатели и продавцы «пересекали спред»;
- Дисбаланс бид/аск объемов – использовался в предыдущем пункте;
- Объем транзакций – использовался в предыдущем пункте.
В первой серии экспериментов рассматривался короткий десятисекундный временной промежуток. Важно отметить, что, покупка или продажа по средней цене предполагает, что одно из двух действий всегда оказывается выгодным: покупка, а затем продажа, если средняя цена выросла, и наоборот, если цена упала. В реальных условиях такой подход не работает, потому опишем методологию следующим образом:
- Для каждого из 19 наименований проводилась реструктуризация биржевого стакана на основе исторических данных;
- Для каждой торговой возможности оценивалось текущее состояние биржевого стакана и доходность обоих действий (покупка-продажа или продажа-покупка). Результаты записывались в таблицу симулятора биржевого стакана, где вычислялось перемещение средней точки;
- Для каждого наименования в качестве тренировочных данных использовались показатели 2008 года. Производилось вычисление функции, определяющей, какое из действий для данного состояния ~x ведет к наибольшему росту производительности;
- Тестирование изученных принципов для каждого наименования проводилось с использованием набора данных 2009 года. К каждому состоянию ~x применялось соответствующее действие, выученное алгоритмом, после чего рассчитывалась производительность.
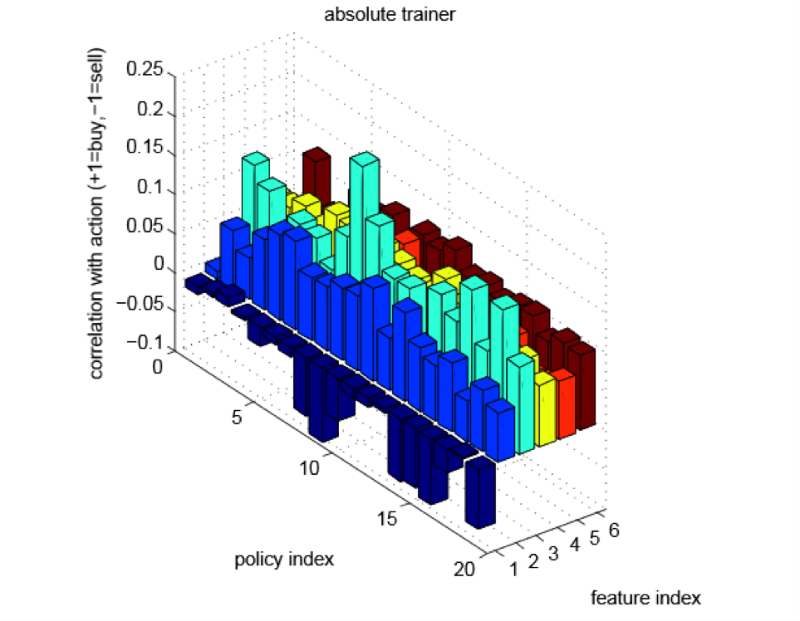
На рисунке 2 для каждого из 19 правил и каждого из шести признаков отводится столбик, показывающий зависимость между ценностью признака и изученным действием. Мы условились, что значение +1 обозначает покупку-продажу, а -1 – продажу-покупку. Как и в прошлом разделе, мы видим, что численные значения корреляции сильно зависят от выбранного наименования.
Рисунок 2 – Корреляция между значениями признаков и изученными мерами. Здесь 1 – бид-аск спред, 2 – цена, 3 – «умная» цена, 4 – торговый показатель, 5 – дисбаланс бид/аск объемов, 6 – объем транзакций
На изображении видно, что мы изучили стратегии, основанные на моменте: для каждого из признаков, имеющих информацию о направленности (цена, «умная» цена, торговый показатель, дисбаланс бид/аск объемов и объем транзакций), высокие значения соответствуют большей частоте покупки в изученных правилах.
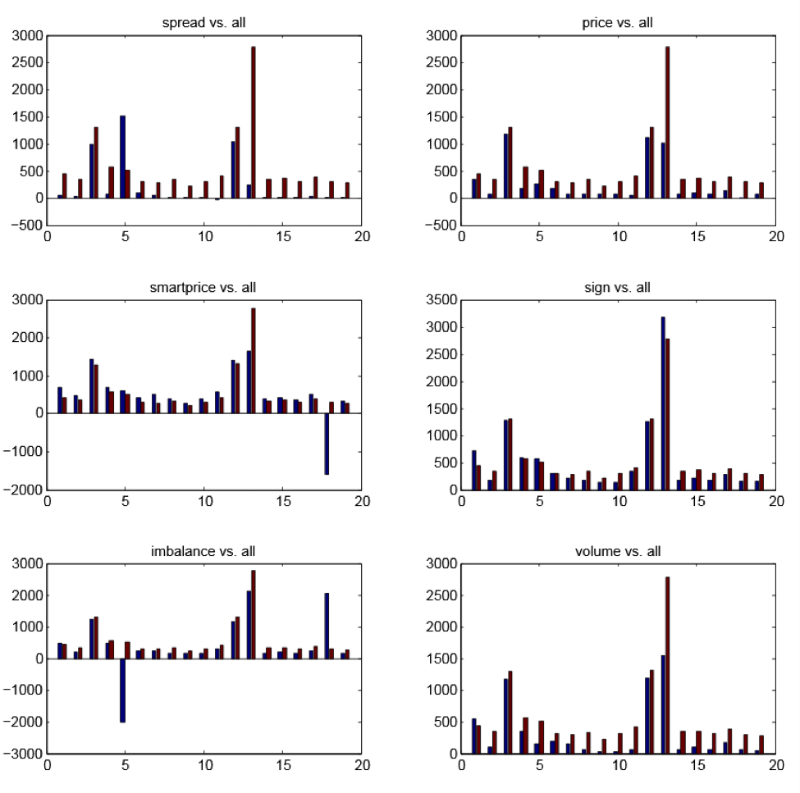
Рисунок 3 – графики для каждого из шести признаков
На рисунке 3 показаны графики для каждого из шести признаков. Красные столбики везде одинаковые и показывают доходность тестового набора правил, выученных для каждого из 19 наименований, где были использованы все 6 признаков. Синие столбики показывают доходность тестового набора правил, выученных для каждого из 19 наименований, но с использованием лишь одного признака. Отсюда можно сделать выводы:
- Выгоднее всего использовать сразу 6 признаков;
- «Умная» цена делает наибольший вклад в доходность. Часто случается так, что её использование приводит к лучшему результату, чем при использовании всех шести признаков;
- Спред – самый бесполезный признак, но для отдельных наименований оказывается самым выгодным.
Машинное обучение и «умные системы» маршрутизации заявок в дарк-пулах
Методология машинного обучения применима и к только-только зародившимся областям, которые имеют менее богатые объемы данных и новые, неизученные механизмы. Давайте посмотрим на применение машинного обучения для решения проблемы маршрутизации заявок в дарк-пулах.
Дарк-пулы изначально рассматривались как места для сделок, где наибольшее значение имеет ликвидность. При достаточной ликвидности можно с легкостью платить «текущую цену».
Мы предполагаем, что нам доступно n отдельных дарк-пулов. Эти пулы способны предоставить различные профили ликвидности для определённого пакета акций – например, в одном пуле лучше быстро выполнять маленькие заказы, а другой приносит большую доходность от выполнения крупных заказов.
Будем считать, что – это вероятностное распределение, описывающее область значений с неотрицательными целыми числами. Мы предполагаем, что при подтверждении заказа на акций для пула i, на основании выбирается случайная величина. представляет собой акции, доступные на другой стороне рынка (акции, доступные для покупки при условии, что мы продаем, либо для продажи при условии, что мы покупаем) в момент подтверждения ордера. Проблема маршрутизации заявок в дарк-пулах может быть формализована следующим образом: у нас есть заданный объем акций V, которые мы хотим купить; как нам разделить V на подмножества для n дарк-пулов так, чтобы, при этом максимизировав количество покупаемых акций?
Рисунок 4 показывает, как выглядит реальное распределение ликвидности. Здесь показаны подмножества и данные, используемые для проведения операций купли-продажи акций DELL в американском дарк-пуле.
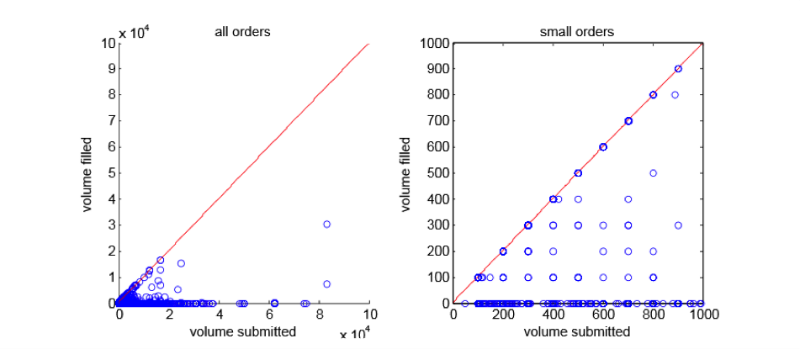
Рисунок 4 – Распределение ликвидности для акций DELL
Проблема обучения умной системы маршрутизации заявок возникает потому, что у нас недостаточно знаний о распределении вероятностей – мы должны изучать приближения на основании наших собственных данных о заявках. Детали алгоритма останутся за пределами данной статьи, но, если описать их в общих чертах, то:
- Алгоритм принимает определённое приближение для каждого неизвестного распределения ликвидности. До начала работы алгоритма, все аппроксимации принимают значения по умолчанию.
- Мы используем приближение Каплана-Мейера, оценивающее похожесть закрытых данных.
- Для каждого V алгоритм считает распределение приближений истинным и выбирает размещения согласно жадному алгоритму, примененному к приближениям Pi.
С получением свежих рабочих данных можно обновить приближенные распределения и повторить процесс для следующего целевого объема акций.

Рисунок 5 – Кривые производительности нашего алгоритма обучения (красный) и простого адаптивного эвристического алгоритма (синий). Черным отмечено равномерное размещение, а зеленым идеальное
Некоторые экспериментальные оценки производительности алгоритма представлены на рисунке 5. Здесь изображены симуляции с использованием неполных рабочих данных для дарк-пулов США. Каждый график показывает изменение производительности нашего алгоритма обучения.
Заключение
В этой статье мы познакомили вас с возможностями машинного обучения в сфере высокочастотного трейдинга и микроструктуры рынка, а также препятствиями, стоящими на его пути. Мы не верим в то, что машинное обучение стоит использовать по принципу «черного ящика» или искать с его помощью какие-либо «удивительные» трейдинговые стратегии.
В каждом из рассмотренных кейсов результат обучения не выдал результатов, радикально отличающихся от общих представлений о рассматриваемых проблемах с точки зрения экономики и теории рынков – смысл использования машинного обучения заключался в количественной оптимизации этих качественных стратегий. Если применять этот подход аккуратно и к месту, он может стать мощным и хорошо масштабируемым инструментом, эффективно работающим с огромным количеством существующих в настоящее время данных о микроструктуре рынка.
