
Многие торговые платформы для высокочастотного трейдинга часто работают на оборудовании с высокопроизводительными сетевыми адаптерами. Однако минусом таких систем является относительно высокая и непредсказуемая задержка — в итоге многие трейдеры обратили свой взгляд на гибридные архитектуры с аппаратным ускорением.
Эксперты компании Algo-Logic Systems Inc. Джон Локвуд (Jowhn W. Lockwood), Адвайт Гупте (Adwait Gupte) и Нишит Мехта (Nishit Mehta) опубликовали работу, в которой рассказали о том, как FPGA используются в онлайн-трейдинге для уменьшения задержек передачи данных. Мы представляем вашему вниманию основные моменты этой публикации.
Почему в деле HFT так важна скорость
Современные биржи транслируют финансовую информацию с помощью различных потоков данных. Трейдеры мониторят эти потоки, анализируют цены и спрос на конкретные финансовые инструменты (акции, фьючерсы, опционы и т.п.), чтобы понять, когда и какую сделку совершить — когда решение принято, на биржу отправляется приказ на покупку или продажу нужного инструмента.
По мере развития электронной торговли, все больше распространение получил и так называемый высокочастотный трейдинг (HFT, High frequency trading) — по разным оценкам уже в 2010 году на американских биржах более 70% сделок было осуществлено с помощью алгоритмов.
HFT-трейдеры пытаются эксплуатировать возникающие неэффективности рынка. Таким образом они не только зарабатывают деньги, но и делают финансовые рынки более эффективными. Однако из-за растущего числа высокочастотных торговцев, которые пытаются заработать на одних и тех же неэффективностях, действительно заработать на определенной возможности смогут лишь первые несколько трейдеров. А значит, им нужно опередить конкурентов.
Второй важной причиной является понятие проскальзывания — в случае высоколиквидных финансовых инструментов (например, акций) после отправки приказа, допустим, на покупку по заданной цене, сделка может пройти по менее выгодной, поскольку пока приказ дойдет до биржи, цена изменится. Соответственно, чем больше задержка от времени генерации приказа до момента его исполнения, тем больше может быть проскальзывание, и как следствие, недополученная прибыль трейдера.
В-третьих, существуют торговые стратегии, например абитраж задержек (latency arbitrage), суть которых сводится к тому, что трейдер должен иметь возможность получить рыночную информацию и отправлять приказы быстрее, чем другие игроки. В такой ситуации каждая выигранная миллисекунда может значительно улучшить производительность стратегии.
Разновидности HFT-платформ
В настоящий момент большинство трейдеров и брокеров создают свои HFT-системы с помощью популярных программных и аппаратных технологий. Это позволяет описывать алгоритмы с помощью знакомых многим высокоуровневых языков программирования (о том, какие из них используются в сфере финансов мы писали здесь), и в них можно довольно быстро внести изменения в случае необходимости.
Однако погоня за скоростью приводит к тому, что непредсказуемое время ответа программных систем становится препятствием на пути к успешной торговле. Рассмотрим существующие программные и аппаратные подходы к созданию HFT-систем.
Программные высокочастотные платформы
Существует довольно большое количество компаний, предлагающих софт для высокочастотного трейдинга (для Западных бирж это, например, Mantara, Ulink и QuantHouse). При их использовании большая часть задержек приходится на работу операционной системы, на которой запущен софт, а также сетевого стека. Чтобы с этим бороться, пользователи могут использовать высокопроизводительные сетевые карты (например, от Solarflare или Myricom), которые ускоряют определенные части сетевого стека.
«Кастомные» аппаратные HFT-платформы
Сравнительно высокие задержки программных торговых платформ заставили представителей отрасли искать альтернативные подходы к снижению задержек с помощью специального железа. Как правило вещи вроде ASIC не рассматриваются в HFT-торговле, поскольку им недостает гибкость для последующей реконфигурации или работы с новыми протоколами. GPU также не могут предложить значительное быстродействие. Подходящим инструментом для получения гибкости и достижения требуемого быстродействия стала технология FPGA (Field-Programmable Gate Arrays).
Использовать FPGA для ускорения финансовых приложений можно различными способами. Один из них называется Гибридными вычислениями и используется, к примеру, в моделях риск-менеджмента, вычисления цен опционов и моделирования портфолио — при его применении скорость работы системы может возрастать на три порядка.
Этот подход дополняет обычные многоядерные процессоры сопроцессорами на FPGA. Обычно связь с CPU осуществляется с помощью высокоскоростных коннекторов вроде FrontSide Bus (FSB), PCI Express или QPI. Сами торговые модули в таком случае пишутся на высокоуровневых языках программирования.
Другой способ применения программируемой логики для ускорения — это использование так называемых Smart NIC. Обычно под этим понимается комбинация высокоскоростных сетевых интерфейсов, PCI-интерфейсов хоста, памяти и FPGA. Здесь FPGA выступает в роли NIC-контроллера, выполняя роль моста между хост-компьютеров и сетью и позволяя интегрировать программную логику напрямую на пути следования данных. Таким образом, Smart NIC может работать как торговая платформа под управлением CPU хост-машины.
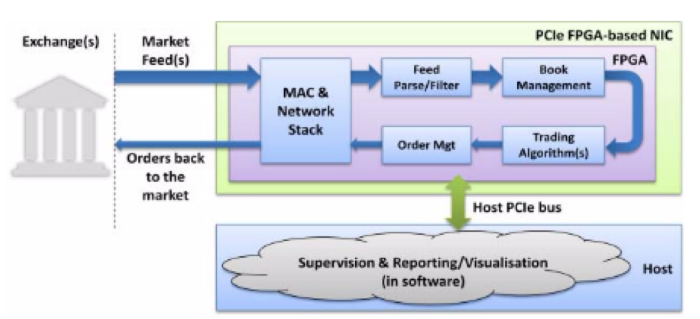
Плюсы и минусы FPGA для высокоскоростной торговли
С помощью современных FPGA можно реализовывать любые аспекты HFT-приложений. Входящие рыночные данные могут целиком обрабатываться на FPGA без необходимости их отправки к и от процессору. На рисунке ниже представлено сравнение FPGA-платформы с обычной программной платформой:
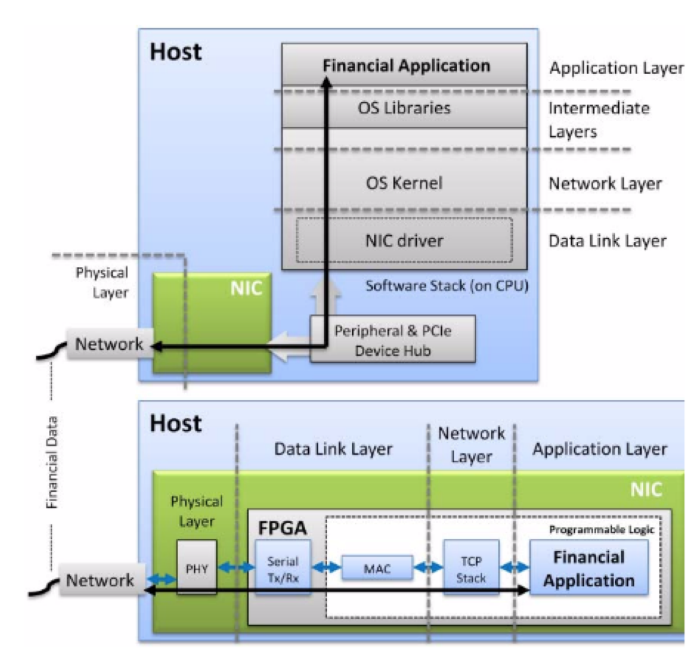
В последнем случае для получения сетевого трафика нужен сетевой адаптер. Нужная его часть затем передается процессору, который «прерывается» для обработки приложения. После ее завершения данные отправляются обратно на сетевой адаптер и передаются по сети. В данной ситуации подход, подразумевающий прерывания, а также наличие непредсказуемых задержек при PCIe-трансферах и кешировании, увеличивает сетевую задержку и затрудняет ее прогнозирование.
Напротив, в случае FPGA, входящие сетевые данные «скармливаются» напрямую кастомтизированной, высокооптимизированной системе через железные блоки MAC и PHY. Более того, фактически, нужная информация может быть извлечена еще до полного получения пакета. Таким образом, использование FPGA позволяет добиться значительного снижения общей задержки.

Минусы использования FPGA
Использование FPGA имеет и свои недостатки в сравнении с традиционными подходами разработки торговых систем. Корнем проблем является более высокая сложность потока разработки под FPGA. Значительная часть разработчиков финансовых систем и трейдеров не знакомы с этой технологией и им недостает знаний и экспертизы для осуществления аппаратно-ориентированной разработки.
Во-вторых, разработка и тестирования новых аппаратных решений из-за более низкого уровня абстракции — более сложный и длительный процесс по сравнению с обычным написанием торгового робота. Все это проиллюстрировано на рисунке ниже:

Чтобы избежать этого, в некоторых FPGA-based HFT-платформах есть специальные высокоуровневые среды, что позволяет создавать торговые системы без необходимости использования языков описания аппаратных средств (HDL, hardware description languages).
Как это работает: Библиотека Algo-Logic
Библиотека низкой задержки от Algo-Logic — это шлюзовой инструмет, который совместим со стандартными FPGA-платформами. Этот инструмент обрабатывает финансовые протоколы, используемые биржами в США, Европе и других странах, извлекая информацию из пакетов во время их прохождения через FPGA. Компоненты библиотеки используются для построения торговых приложений, работающих на высоких скоростях.
Компоненты библиотеки делятся на две категориии — инфраструктурные компоненты (интерфейсы для сети, внешней памяти и ПО хоста) и модули обработки финансовой информации (протоколы, процессы парсинга и т.п.) На рисунке ниже представлено более детальное описание этих блоков:
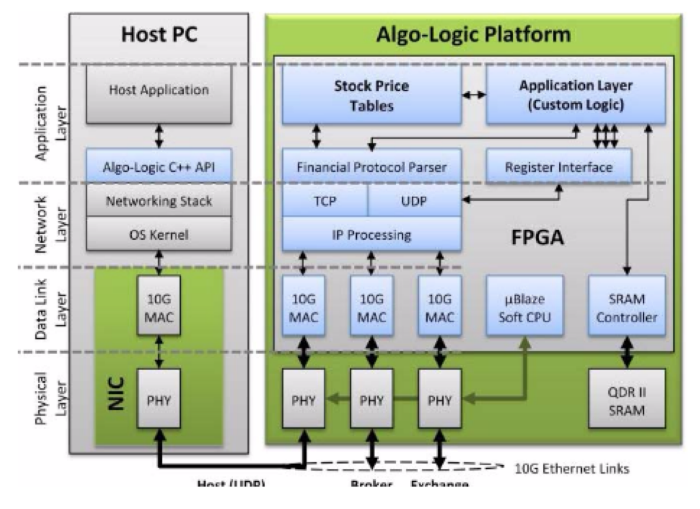
Инфраструктурные компоненты
Все инфраструктурные компоненты использует стандартизированный интерфейс с 64-битным машинным словом. Контроллер SRAM обеспечивает низкую задержку и высокопроизводительное хранение для небольших объёмов данных.
Модуль интерфейса регистров контролирует и мониторит статус регистров, в которые пишет и читает софт, работающий на хост-машине. Он содержит регистры различных типов, включая работающие только на запись конфигурационные регистры, работающие на чтение регистры статусы и т.п. Конфигурационные и статусные данные передаются и получаются по UDP. Доступ к интерфейсу регистров можно получить через C++ API на хосте или через веб-GUI.
Компоненты обработки финансовой информации
В библиотеке Algo-Logic есть IP-блоки, разработанный для обработки сообщений уровня приложений для высокочастотной торговли. Эти сообщения содержат приказы и отчеты о выполнении ордеров, пересылаемые между клиентами, брокерами и биржами. Среди этих компонентов:
Парсер финансовых протоколов — получает данные от уровня обработки TCP/IP и определяет границы сообщения. Затем парсер извлекает отдельные поля и устанавливает флаг, когда значения каждого поля валидируется. Это позволяет добиться снижения задержки при извлечении. Сейчас в этой конкретной библиотеке есть парсеры для протоколв FIX, OUCH, XPRS, AcaDIirect, Native Trading gateway, которые используются на различных биржах от NASDAQ до London Stock Exchange.
Рассмотрим работу парсера на примере протокола OUCH (NASDAQ). Полученное сообщение передается парсерсу, который извлекает поля и устанавливает нужные флаги. Например, извлекается поле типа сообщения (“O” или “Enter Order”) и 14-байтовый токен приказа. Индикатор покупки или продажи это “T” (Sell Short), число акций — 1002, биржевой тикер финансового инструмента — FFHL. В оставшихся полях указана желаемая цена сделки, а также информация о том, что приказ нельзя перемещать на другой рынок.

Парсинг рыночных данных и хранение данных о цене «на чипе» — финансовым приложениям нужно обязательно знать цену акций, которая используется в приказах. Чтобы отслеживать цены, рыночные данные направляются на карточку с помощью UDP/IP датаграмм. Затем FPGA извлекает обновления цены и хранит эти данные для каждой акции. Цены всех 8000 акций, торгуемых на американских биржах помещаются в чиповую память FPGA.
Заключение
Стремясь сократить возможные задержки при торговле и обработке финансовой информации, брокеры, трейдеры и сами биржи, осваивают работу с новыми технологиями, которые позволят строить высокоэффективные платформы.
Одной из таких технологий является FPGA, однако важно помнить о том, что этот инструмент не является серебряной пулей — помимо преимуществ в скорости, при его использовании есть и сложности в сфере разработки и поддержания системы.
Тем не менее, этот инструмент предоставляет хорошие возможности для повышения скорости работы финансовых приложений. И здесь важно, чтобы вся используемая трейдером инфраструктура отвечала требованиям по минимизации задержек — клиенты ITinvest для этого, к примеру, могут использовать технологию прямого подключения и размещать свое оборудование в стойках ITinvest в зоне колокации Московской биржи с шириной канала 10 гб/с.
