В рамках корпоративного блога хотелось бы запустить цикл статей о нашем молодом (но, тем не менее, очень ярком) начинании в сфере информационной безопасности – JSOC (Jet Security Operation Center) − коммерческом центре по мониторингу и реагированию на инциденты. В статьях я постараюсь поменьше заниматься саморекламой и большее внимание уделить практике: нашему опыту и принципами построения услуги. Тем не менее, это мой первый «хабро-опыт», и потому не судите строго.
Рассказывать, зачем вообще крупной российской компании нужен SOC, не очень хочется (уж слишком много различных статей и исследований по этому поводу написано). А вот статистика – совсем другое дело, и о ней грех не вспомнить. Так, например:
Если же добавить к этому еще 3−4 новостных заголовка по соответствующей теме, то абсолютно логичной и понятной становится идея о том, что за безопасностью необходимо следить, а инциденты ИБ − выявлять и анализировать.
Что советуют по этому вопросу эксперты безопасности? Конечно же сделать SIEM-решение ядром существующего или строящегося SOC. Это позволит решить сразу несколько задач:
Существует несколько уровней зрелости SOC − SOMM (Security Operations Maturity Model):
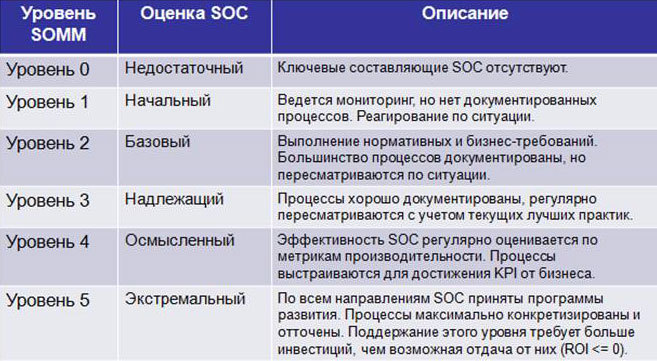
Рис. 1 – Уровни SOMM
К сожалению, большинство компаний, сделав первый шаг на пути к собственному центру мониторинга инцидентов, на нем и останавливаются. По оценкам HP, 24 % SOC в мире не дотягивают до 1 уровня, и только 30 % SOC соответствуют базовому (2) уровню. Статистика распределения уровней SOMM в зависимости от сферы бизнеса компаний, собранная в 13 странах мира (включая Канаду, США, Китай, Великобританию, Германию, ЮАР и др.) такова:
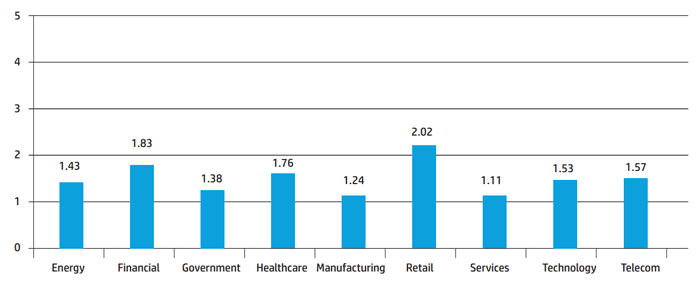
Рис. 2 – Распределение уровней SOMM по сферам бизнеса
При этом по пути внедрения масштабного SIEM-решения прошли практически все крупные российские компании. Удалось ли им построить эффективные SOC`и? К сожалению, чаще всего нет: на сегодняшний день нам известен опыт всего четырех успешных запусков SOC в России.
И, как правило, приступая к построению собственного SOC, все сталкиваются с тремя гранями одной проблемы.
Во-первых, с количественной нехваткой персонала по самым различным причинам: от кадрового голода и отсутствия профильных вузов до сложности обретения требуемых компетенций. Де-факто в рамках подразделения it-security сегодня работает по 4−5 человек, осуществляющих весь цикл работ по обеспечению безопасности компании (от администрирования средств защиты до регулярного анализа рисков и разработки стратегии развития тематики в компании). Естественно, при такой загрузке уделить должное время задачам SOC практически невозможно.
Второй момент связан с невозможностью построения эффективного процесса мониторинга с внутренними SLA. Помимо необходимости выделения персонала запуск SOC, обычно, влечет за собой создание в подразделении it-security полноценной дежурной смены, работающей в рамках расширенного рабочего дня или круглосуточно. А это − от 2 до 5 новых штатных единиц. При этом выделение персонала напрямую связано с необходимостью постоянного контроля кадровой текучки (крайне редко ИБ-специалисты готовы работать в ночной смене), выстраивания процессов и внутренних контролей качества выполняемых работ.
Ну и третьим пунктом нельзя не упомянуть необходимость не только обрабатывать возникающие инциденты, но и постоянно «тюнить» и подстраивать систему под изменяющуюся инфраструктуру или возникающие угрозы безопасности. А это, вне зависимости от выбранного инструмента, весьма трудоемкая задача для аналитика, требующая постоянно держать руку на пульсе. А наличие в штате человека, занимающегося чистой аналитикой и развитием SOC – большая роскошь (даже для крупной компании).
Оценка существующей на рынке потребности в создании SOC`ов вкупе с описанными нюансами привели нас сначала к идее, а потом и к фактическому построению собственного коммерческого SOC.
Естественно, запуская SOC, мы в первую очередь столкнулись с вопросом: «Какое SIEM-решение сделать ядром своей системы»? Отвечая на него, мы сформировали список требований к создаваемой системе. В частности она должна:
Свой выбор мы остановили на флагманском продукте в классе SIEM – HP ArcSight (и, несмотря на различные сложности в жизни системы, о своем выборе мы ни разу не пожалели). Технологически JSOC − уже давно не только HP ArcSight. SIEM`овское ядро постепенно обрастало различными полезными фичами: мониторинг трафика, ips\ids, vulnerability assessment и т.д. Одновременно с этим мы накопили большое количество скриптов, аддонов и собственных разработок, интегрировались с собственным Security Intelligence решением (JiVS), которое является:
В итоге мы сформировали такие профили защиты/направления выявления инцидентов у компаний-заказчиков, как:
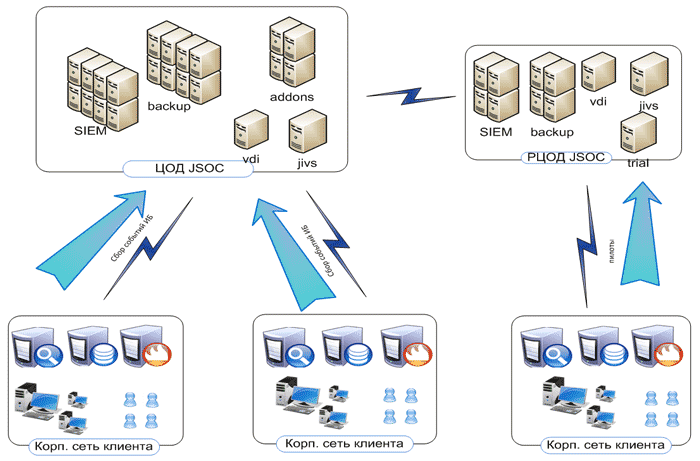
Рис. 3 – Инфраструктура сервиса JSOC
После выбора основной технологической платформы необходимо было решить задачи по созданию инфраструктуры и определить площадку размещения. Опыт наших западных коллег показывает, что целевая доступность архитектуры должна составлять не менее 99,5 % (причем с максимальной катаклизмоустойчивостью). При этом принципиальным оставался и вопрос географии: collocation возможен только в границах РФ, что исключило для нас возможность использования популярных западных провайдеров. Сюда же наложились естественные вопросы обеспечения ИБ инфраструктуры на всех уровнях доступа, и выбора у нас, по большому счету, не осталось: мы обратились к команде нашего ВЦОДа. В рамках большого колокейшена для нашего JSOC специально выделили фрагмент, где мы смогли развернуть свою архитектуру, одновременно ужесточив уже существующие в рамках ВЦОД профили безопасности. ИТ-инфраструктура развернута в Tier 3 дата-центре нашей компании, и ее показатели доступности составляют 99,8%. В результате мы смогли выйти на целевые показатели доступности нашего сервиса и получили существенную свободу действий в работе и адаптации системы под себя.
На начальном этапе запуска услуги команда JSOC состояла из 3 человек: двух инженеров мониторинга, закрывающих временной интервал с 8 до 22 часов, и одного аналитика/администратора, который занимался развитием правил. SLA по услуге, обозначенный клиентам, тоже был достаточно мягким: время реакции на обнаруженный инцидент – до 30 минут, время на разбор, подготовку аналитической справки и информирование клиента – до 2 часов. Но, по прошествии первых месяцев работы, мы сделали несколько очень существенных выводов:
На практике все эти выводы вылились в создание в рамках Центра информационной безопасности компании «Инфосистемы Джет» отдельного структурного подразделения, ориентированного на трехуровневую модель обеспечения каждой из задач: как мониторинга и разбора инцидентов, так и администрирования средств защиты. Сейчас подразделение насчитывает уже более 30 человек, имеет сформировавшуюся структуру (см. Рис. 4) и включает в себя:

Рис. 4 – Организационная структура JSOC
Данная организационная структура позволила нам выйти на следующие целевые показатели SLA:
На текущий момент мы обслуживаем уже 12 клиентов и решаем стоящие перед нами задачи по обеспечению их информационной безопасности. Именно таковы итоги первых полутора лет работы JSOC.
Надеюсь, данный материал не показался вам излишне маркетинговым. В дальнейших статьях мы планируем осветить такие темы, как:
To be continued… ;) dryukov
SOC − предпосылки
Рассказывать, зачем вообще крупной российской компании нужен SOC, не очень хочется (уж слишком много различных статей и исследований по этому поводу написано). А вот статистика – совсем другое дело, и о ней грех не вспомнить. Так, например:
- в компании численностью от 1 до 5 тыс. человек в течение года фиксируется:
- 90 млн. событий ИБ;
- 16 865 событий с подозрением на инцидент;
- 109 реальных инцидентов ИБ ;
- общий объем потерь от инцидентов ИБ в 2013 году составил $ 25 млрд. ;
- в крупной компании используется не менее 15 разнородных средств защиты, не более чем в 7 из них проводится активный анализ журналов для выявления инцидентов .
Если же добавить к этому еще 3−4 новостных заголовка по соответствующей теме, то абсолютно логичной и понятной становится идея о том, что за безопасностью необходимо следить, а инциденты ИБ − выявлять и анализировать.
Что советуют по этому вопросу эксперты безопасности? Конечно же сделать SIEM-решение ядром существующего или строящегося SOC. Это позволит решить сразу несколько задач:
- замкнуть инциденты, фиксируемые другими системами самостоятельно, в рамках одного единого ядра инцидент-менеджмента;
- получить удобный инструмент для поиска необходимых событий, расследования инцидентов, хранения собранных данных;
- выявлять статистические отклонения и медленно развивающиеся инциденты за счет анализа больших интервалов и объемов информации с конкретных средств защиты;
- сопоставлять и коррелировать данные из разных систем, и, как следствие, строить сложные цепочки сценариев по обнаружению инцидентов, «обогащать» информацию в логах одних систем данными из других.
Немного общей методологии
Существует несколько уровней зрелости SOC − SOMM (Security Operations Maturity Model):

Рис. 1 – Уровни SOMM
К сожалению, большинство компаний, сделав первый шаг на пути к собственному центру мониторинга инцидентов, на нем и останавливаются. По оценкам HP, 24 % SOC в мире не дотягивают до 1 уровня, и только 30 % SOC соответствуют базовому (2) уровню. Статистика распределения уровней SOMM в зависимости от сферы бизнеса компаний, собранная в 13 странах мира (включая Канаду, США, Китай, Великобританию, Германию, ЮАР и др.) такова:
Рис. 2 – Распределение уровней SOMM по сферам бизнеса
SOC in-house: проблематика
При этом по пути внедрения масштабного SIEM-решения прошли практически все крупные российские компании. Удалось ли им построить эффективные SOC`и? К сожалению, чаще всего нет: на сегодняшний день нам известен опыт всего четырех успешных запусков SOC в России.
И, как правило, приступая к построению собственного SOC, все сталкиваются с тремя гранями одной проблемы.
Во-первых, с количественной нехваткой персонала по самым различным причинам: от кадрового голода и отсутствия профильных вузов до сложности обретения требуемых компетенций. Де-факто в рамках подразделения it-security сегодня работает по 4−5 человек, осуществляющих весь цикл работ по обеспечению безопасности компании (от администрирования средств защиты до регулярного анализа рисков и разработки стратегии развития тематики в компании). Естественно, при такой загрузке уделить должное время задачам SOC практически невозможно.
Второй момент связан с невозможностью построения эффективного процесса мониторинга с внутренними SLA. Помимо необходимости выделения персонала запуск SOC, обычно, влечет за собой создание в подразделении it-security полноценной дежурной смены, работающей в рамках расширенного рабочего дня или круглосуточно. А это − от 2 до 5 новых штатных единиц. При этом выделение персонала напрямую связано с необходимостью постоянного контроля кадровой текучки (крайне редко ИБ-специалисты готовы работать в ночной смене), выстраивания процессов и внутренних контролей качества выполняемых работ.
Ну и третьим пунктом нельзя не упомянуть необходимость не только обрабатывать возникающие инциденты, но и постоянно «тюнить» и подстраивать систему под изменяющуюся инфраструктуру или возникающие угрозы безопасности. А это, вне зависимости от выбранного инструмента, весьма трудоемкая задача для аналитика, требующая постоянно держать руку на пульсе. А наличие в штате человека, занимающегося чистой аналитикой и развитием SOC – большая роскошь (даже для крупной компании).
Оценка существующей на рынке потребности в создании SOC`ов вкупе с описанными нюансами привели нас сначала к идее, а потом и к фактическому построению собственного коммерческого SOC.
Выбор платформы
Естественно, запуская SOC, мы в первую очередь столкнулись с вопросом: «Какое SIEM-решение сделать ядром своей системы»? Отвечая на него, мы сформировали список требований к создаваемой системе. В частности она должна:
- позволять физически и логически разделять аккумулируемые данные по разным resource pool (в нашим случае − по разным заказчикам) с возможностью разделения полномочий по доступу;
- позволять строить максимально сложные цепочки и взаимосвязи между событиями, использовать различные справочники и события для дополнения инцидента важной информацией. При этом нам скорее был нужен framework для построения своей логики выявления инцидентов, чем уже написанные правила и сценарии;
- иметь возможность написания и разработки интеграционных шин как в сторону систем-источников (и здесь ключевое значение приобретает максимальная гибкость в написании коннекторов к целевым системам\справочникам), так и api для связки с внешними инцидент-менеджментами, системами отчетности и визуализации;
- позволять кастомизировать внутренние ресурсы под меняющиеся задачи SOC. В частности, создание внутреннего профиля мониторинга источников, ведение и кастомизация своего инцидент-менеджмента и т.д. (кстати, данные изыскания станут предметом отдельной статьи).
Свой выбор мы остановили на флагманском продукте в классе SIEM – HP ArcSight (и, несмотря на различные сложности в жизни системы, о своем выборе мы ни разу не пожалели). Технологически JSOC − уже давно не только HP ArcSight. SIEM`овское ядро постепенно обрастало различными полезными фичами: мониторинг трафика, ips\ids, vulnerability assessment и т.д. Одновременно с этим мы накопили большое количество скриптов, аддонов и собственных разработок, интегрировались с собственным Security Intelligence решением (JiVS), которое является:
- инструментом высокоуровневого поиска аномалий у клиента и отслеживания общих трендов в активностях и инцидентах;
- системой контроля и визуализации нашего выполнения SLA перед заказчиком;
- эффективным визуальным dashboard и системой отчетности для бизнес-руководства заказчика.
В итоге мы сформировали такие профили защиты/направления выявления инцидентов у компаний-заказчиков, как:
- атаки на внешние веб-ресурсы компании;
- несанкционированный доступ к системам и приложениям;
- комплексное обеспечение безопасности бизнес-приложений;
- активности вирусного и вредоносного ПО в сети компании, включая эвристическое выявление zero-day вирусов;
- нарушение политик использования удаленного доступа в сеть компании;
- нелегитимные действия пользователей при обращении в интернет и работе с внешними устройствами;
- аномалии в аутентификации и использовании учетных записей;
- и другие категории инцидентов в зависимости от инфраструктуры компании, ее внутренних политик ИБ и используемых средств защиты.
Инфраструктура
Рис. 3 – Инфраструктура сервиса JSOC
После выбора основной технологической платформы необходимо было решить задачи по созданию инфраструктуры и определить площадку размещения. Опыт наших западных коллег показывает, что целевая доступность архитектуры должна составлять не менее 99,5 % (причем с максимальной катаклизмоустойчивостью). При этом принципиальным оставался и вопрос географии: collocation возможен только в границах РФ, что исключило для нас возможность использования популярных западных провайдеров. Сюда же наложились естественные вопросы обеспечения ИБ инфраструктуры на всех уровнях доступа, и выбора у нас, по большому счету, не осталось: мы обратились к команде нашего ВЦОДа. В рамках большого колокейшена для нашего JSOC специально выделили фрагмент, где мы смогли развернуть свою архитектуру, одновременно ужесточив уже существующие в рамках ВЦОД профили безопасности. ИТ-инфраструктура развернута в Tier 3 дата-центре нашей компании, и ее показатели доступности составляют 99,8%. В результате мы смогли выйти на целевые показатели доступности нашего сервиса и получили существенную свободу действий в работе и адаптации системы под себя.
Команда
На начальном этапе запуска услуги команда JSOC состояла из 3 человек: двух инженеров мониторинга, закрывающих временной интервал с 8 до 22 часов, и одного аналитика/администратора, который занимался развитием правил. SLA по услуге, обозначенный клиентам, тоже был достаточно мягким: время реакции на обнаруженный инцидент – до 30 минут, время на разбор, подготовку аналитической справки и информирование клиента – до 2 часов. Но, по прошествии первых месяцев работы, мы сделали несколько очень существенных выводов:
- Смена мониторинга должна обязательно работать в режиме 24*7. Несмотря на существенно меньший объем инцидентов в вечерние и ночные часы, самые важные и критичные события (старт DDoS-атак, завершающие фазы медленных атак на проникновение через внешний периметр, злонамеренные действия контрагентов и т.п.) происходят все же именно в ночное время и к моменту старта утренней смены уже теряют свою актуальность.
- Время разбора критичного инцидента не должно превышать 30 минут. В противном случае шансы на его предотвращение или существенную минимизацию ущерба катастрофически падают.
- Для обеспечения требуемого времени разбора под каждый инцидент должен быть подготовлен полноценный инструментарий для его расследования: active channels с отфильтрованными целевыми событиями для разбора, тренды, демонстрирующие статистические изменения в подозрительных активностях и целевые аналитические отчеты, позволяющие быстро анализировать активности и принимать оперативные решения.
- Команда администрирования средств защиты наших клиентов должна быть отделена от группы мониторинга и выявления инцидентов. В противном случае риск влияния человеческого фактора в цепочке «выполнил изменения конфигурации – зафиксировал по факту инцидент – отметил ложным срабатыванием» мог существенно сказаться на качестве нашей услуги.
На практике все эти выводы вылились в создание в рамках Центра информационной безопасности компании «Инфосистемы Джет» отдельного структурного подразделения, ориентированного на трехуровневую модель обеспечения каждой из задач: как мониторинга и разбора инцидентов, так и администрирования средств защиты. Сейчас подразделение насчитывает уже более 30 человек, имеет сформировавшуюся структуру (см. Рис. 4) и включает в себя:
- 2 дежурные смены, которые работают 24*7: одна занимается мониторингом и разбором инцидентов, другая – администрированием системы;
- выделенную команду развития, отвлеченную от эксплуатационных активностей в рамках наших клиентов, и позволяющую нам сохранять актуальность услуги и профиля мониторинга угроз.
Рис. 4 – Организационная структура JSOC
Данная организационная структура позволила нам выйти на следующие целевые показатели SLA:
| Параметры Jet Security Operation Center | Базовый | Расширенный | Премиум | |
|---|---|---|---|---|
| Время обслуживания | 8*5 | 24*7 | 24*7 | |
| Время обнаружения инцидента (мин) | Критичные инциденты | 15-30 | 10-20 | 5-10 |
| Прочие инциденты | до 60 | до 60 | до 45 | |
| Время базовой диагностики и информирования заказчика (мин) | Критичные инциденты | 45 | 30 | 20 |
| Прочие инциденты | до 120 | до 120 | до 90 | |
| Время выдачи рекомендаций по противодействию | Критичные инциденты | до 2 ч | до 1,5 ч | до 45 мин |
| Прочие инциденты | до 8 ч | до 6 ч | до 4 ч | |
На текущий момент мы обслуживаем уже 12 клиентов и решаем стоящие перед нами задачи по обеспечению их информационной безопасности. Именно таковы итоги первых полутора лет работы JSOC.
Надеюсь, данный материал не показался вам излишне маркетинговым. В дальнейших статьях мы планируем осветить такие темы, как:
- Доступность SOC: что это такое, из чего она складывается и как ее измерить;
- Как далек путь от корреляционного правила в SIEM до работающего сценария выявления инцидента;
- Организационные вопросы: чему учить и не учить специалистов SOC;
- Немного практики по разбору инцидентов.
To be continued… ;) dryukov
