Приветствую всех читателей! Сегодня хотелось бы поговорить об основных принципах мониторинга бизнес-приложений, которые ежедневно используют многие компании по всему миру. Само понятие «бизнес-приложение» следует понимать как программный комплекс, который обеспечивает поддержку определенного бизнес-процесса компании.
Самый типичный пример архитектуры современного приложения — т.н. «трёхзвенка», т.е. веб-сервер, сервер приложений и сервер БД, следовательно, каждый из этих компонентов будет чуть менее чем полностью оказывает влияние на работу всего приложения. Если рассматривать именно такую конфигурацию, то со своего опыта могу сказать, что чаще всего возникает ситуация, которая в утрированном виде выглядит так:

Периоды недоступности или низкой производительности компонента проецируются на общую доступность приложения, которую ощущает на себе пользователь: т.е. даже при том, что нынешние прикладные системы могут обеспечивать свою доступность сильно за 90%, общая производительность всего бизнес-приложения может не дотягивать и до 90%. В реальном мире картинка выше может выглядеть как-то по-другому, но суть всегда одна — это непредсказуемость характера влияния мельчайших проблем с компонентами приложения на весь программный комплекс в целом. Ниже разбор что, как и почему, прошу под кат.
В любой компании возникают ситуации, когда определенные периоды недоступности одного из звеньев приложения в итоге выливаются в периоды низкой производительности либо полной недоступности пользовательского веб-интерфейса (читай, основного функционала приложения). Если ИТ-ландшафт компании сложный, то бывает весьма затруднительно разобраться, какой именно слой является источником проблемы и к кому обращаться за ее решением. Если вернуться к визуализации такой штуки, то это все можно изобразить следующим образом:

Получается ситуация lose-lose, т.е. проигрывают все. Пользователи чувствуют, что ИТ их не понимает, линейный руководитель для решения конкретной ситуации задействует ИТ и самого главного босса, который посылает лучи негодования ИТ-менеджеру. ИТ-менеджер в смешанных чувствах идет к своим администраторам, которые пытаются валить друг на друга, предоставляя результаты своих систем мониторинга (или работы самописных скриптов) и далее, далее, далее. В общем-то такая ситуация может длиться довольно долго, до тех пор пока проблема в лучшем случае самоустранится, либо все ИТ-администраторы придут к соглашению проводить диагностику каждый в своей системе и наконец найти корневую причину. По опыту коммуникаций с заказчиком могу сказать, что бывает еще такой сценарий, когда своими силами сделать ничего не удалось (в силу недостаточной экспертизы или других объективных причин), и заводится кейс у вендора соответствующего софта, что может растянуться уж совсем на неопределенный срок.
Есть еще момент, на котором остановлюсь подробнее. Любая прикладная система требует мониторинга, и не всегда в компании есть для этого нечто промышленное. В такой ситуации администратора в большинстве случаев выручит встроенный механизм мониторинга приклада, а в случае его отсутствия это может быть некий хорошо зарекомендовавший себя скрипт, запускаемый на регулярной основе. Отлично, что администратор использует удобные и понятные для него инструменты, а теперь допустим, что возник ахтунг планетарного масштаба (радикальное снижение производительности приложения или его полная недоступность). При этом механизм запуска скрипта решил какое-то время не исполняться и спокойно покурить в сторонке. В итоге размахивать перед ИТ-директором скриншотами, подтверждающими, что мониторинг всё-таки был, но вот скрипт выдал exception и scheduler споткнулся, может быть не лучшей идеей. Встроенный мониторинг хорош тем, что учитывает особенности приложения, но опять-таки владельцу приложения может быть не очень удобно собирать разнородную информацию со всех администраторов и отчитываться перед руководством о непрерывности бизнес-процесса, который поддерживает приложение. По моему мнению, администраторы прикладных систем не должны тратить свое драгоценное время на поддержку системы мониторинга, им стоит переложить этот функционал на специально обученных сотрудников внутри компании либо на внешнего подрядчика.
Что же можно сделать для формирования ситуаций win-win? Чтобы у больших боссов не возникало дополнительных вопросов на тему «а что вы делаете, чтобы такого больше не повторилось», и вы, как человек от ИТ (или менеджер по доступности такого-то сервиса), лишний раз не беспокоились, следует иметь оперативную информацию о состоянии всех компонентов систем, участвующих в основном (и не очень) бизнесе компании. Желательно на большом LCD-телевизоре, желательно с большими понятными подписями, цветовой индикацией (а-ля красный-жёлтый-зелёный) и, где-то рядом, списком фамилий напротив названий сервисов. А еще было бы здорово кликнуть мышью по сервису (который окрасился, например, в красный) и узнать, на каком звене возникла проблема. Таким образом, мы пришли к идее единой (а она может быть и зонтичной) системы мониторинга, которая охватывает все части бизнес-приложения, используя стандартные модули мониторинга (конечно, всегда есть возможность наравне со стандартными средствами использовать кастомные скрипты, либо вообще другую оупенсорсную или промышленную систему мониторинга). Ниже пример так называемого heat map, т.е. карты сервисов:

Таким образом, у сотрудников ИТ-подразделения или менеджера бизнес-сервиса есть возможность буквально «держать руку на пульсе» и в любой момент времени иметь представление о том, где возникла проблема, и у кого можно узнать о сроках решения, чтобы отчитаться перед пользователями или руководством. Очень полезен такой мониторинг бывает, когда вы проводите регламентные работы на большом количестве приложений (или их компонент) и хотите убедиться, что всё успешно восстановилось после перезагрузки, ведь тратить остаток ночи (ну, ведь правда, такие работы чаще всего проводятся по ночам) на ручную проверку всего «зоопарка» было бы не совсем рационально.
Нынешний уровень промышленных систем мониторинга позволяет производить глубокий контроль и даже рассчитывать уровень доступности бизнес-приложения. Особенно важным это может быть, когда ИТ-департамент предоставляет бизнесу набор услуг (или сервисов), по которым заключено соглашение об уровне обслуживания (SLA). Система мониторинга позволит формировать отчеты с необходимой детализацией, позволит накапливать статистику и понимать, какие компоненты бизнес-приложения недостаточно производительны, и, в конце концов, позволит бизнесу хотя бы как-то понимать, насколько качественно предоставлен ИТ-сервис. Но наиболее полное представление о работе приложения вы будете иметь, если с определенной периодичностью на среднестатистической рабочей станции будете делать то, что делает пользователь. Об этом ниже.
Наконец, переходим к вопросу мониторинга бизнес-приложения с точки зрения пользователя, без этого вообще нынче никуда. Понятное дело, что конечные пользователи наиболее чувствительны к снижению производительности или недоступности приложения, и «видеть» их глазами было бы наиболее предпочтительным вариантом. Нанимать людей, которые будут, допустим, оформлять банковские проводки и сидеть с секундомером, замеряя время отклика веб-интерфейса того же Siebel, не самое лучшее занятие. Наиболее оптимальным вариантом в таком случае будет написание специального алгоритма (синтетической транзакции), который будет запускать браузер, производить авторизацию в приложении и перекидывать условную сумму в 1 рубль с одного счета на другой. Специально для дорогих читателей я написал браузерную транзакцию (есть еще транзакции с тяжёлыми клиентами) на примере одного известного интернет-магазина. По ней измеряется затраченное время на каждый шаг — первоначальная загрузка страницы в браузер, время на авторизацию пользователя, время на поиск товара и межстраничные редиректы и переходы – плюс проверяется успешное выполнение каждого шага и транзакции в целом.
Система позволяет контролировать, что загрузились конкретные изображения, также есть возможность распознавать текст со страницы (OCR-метод), сравнивать его с чем-нибудь или просто записывать, например, в БД. Можно получить тайминг транзакции, т.е. на каждом шаге запускается таймер, который измеряет время его выполнения и проверяет на успешность, чтобы владелец приложения мог понять, на каком шаге произошел сбой.
Получается, что если условный пользователь вам заявляет, что в вашем приложении все тормозит и глючит, вы сможете предоставить результаты таких транзакций и объяснить, что его случай уникальный и происходит в совершенном отрыве от реальности:) Если серьезно, то предоставление подобных графиков производительности поможем вам избавиться от ненужных активностей по поиску надуманных пользователем проблем.
В сухом остатке мы имеем инструмент, который позволяет получать информацию о наличии проблемы на самой ранней стадии (даже до начала обращения пользователей в службу поддержки). Успешность/неуспешность выполнения транзакции (или ее доступность) система мониторинга может позволять привязывать к бизнес-сервису (если говорить о сервисно-ресурсной модели) и настраивать степень ее влияния на сервис в целом (т.н. вес связи). Ниже пример сервисно-ресурсной модели:

Для тех, кто хочет еще больше понимать своих пользователей, существуют системы мониторинга реальных транзакций. Еще более круто, еще более технологично. Выглядят такие системы следующим образом:
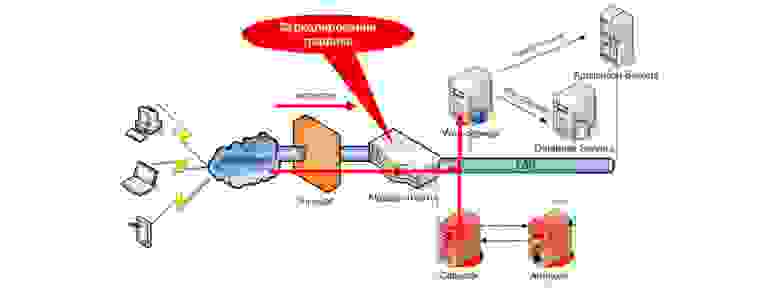
Т.е. весь HTTP/HTTPS трафик, который маршрутизирован на веб-сервер (ферму веб-серверов), зеркалируется на специальный коллектор (на схеме обозначен как Collector). Далее происходит его анализ и формирование заранее заданных представлений (иногда называются дашлетами от англ. dashlets). Такого рода мониторинг можно использовать, например, как механизм отладки веб-приложений для поиска низкопроизводительных компонент, либо определения алгоритмов перехода пользователя между страницами, определения географической локации пользователя, типа браузера и т.п. Ниже приведен пример дашборда анализатора сетевого трафика:

Обратите внимание на т.н. «стакан» в верхнем правом углу окна. Это заранее заданный алгоритм перехода пользователей между страницами, который подсчитывает, сколько пользователей переходят от одной страницы к другой именно в таком порядке, и сколько пользователей выходят из этой последовательности и на каком шаге. Строить графики и делать отчеты можно практически по любому параметру, который передается в HTTP заголовках (имя пользователя, его id и т.п.), т.е. система действительно гибкая и готова подстраиваться под потребности заказчика.
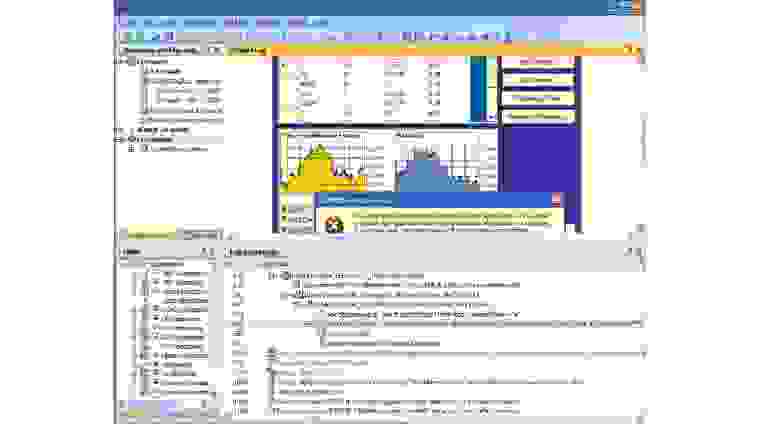
Наконец, переходим к глубокой диагностике бизнес-приложения (особенно актуально для заказных разработок). Такого рода анализ могут делать системы типа Application Diagnostics, диагностику можно производить как для JAVA, так и для .NET приложений. Специальный агент прицепляется к процессу, который выполняется на сервере и анализирует последовательность его действий. Например, на картинке ниже приведен пример такого анализа для .NET приложения, которое выдает exception, и мы можем видеть, что он возникает после запроса в БД.
Для отладки и мониторинга самописных приложений просто must have.
На выходе мы можем иметь зонтичное решение, которое будет получать данные о работе приложения из всех описанных источников и, что самое главное, полную картину того, что происходит внутри приложения, и как это отражается на нашем (не побоюсь этого слова) любимом пользователе, ради которого всё и затевается. На рынке немало софтверных вендоров, которые имеют весь арсенал описанных решений, и выбрать для себя оптимальное решение, исходя из бюджета, потребностей, ожиданий и т.п., может быть не так уж и сложно. Б̀о́льшую часть оупенсорсных и промышленных решений можно собирать как пазл: т.е. если у вас уже есть сетевой или инфраструктурный мониторинг от одного вендора, вы с большой долей вероятности сможете дополнить его, например, синтетическим мониторингом от другого вендора.
На сегодняшний день ИТ стремится приблизиться к бизнесу настолько, насколько это возможно, и оказывать влияние на стратегию компании в целом, а инструменты, в которые может заглянуть руководитель ИТ (или выше) и понять, что деньги потрачены не зря, в целом очень востребованы рынком.
Я попытался дать поверхностное представление о различных методах мониторинга абстрактного бизнес-приложения, и если у вас возникли вопросы, то с радостью на них отвечу. Будет также интересно узнать, какими способами вы решаете задачи мониторинга, и с какими проблемами приходится сталкиваться, особенно с учетом влияния нынешних внешнеполитических факторов. Спасибо за внимание!
Автор статьи: Антон Касимов
Самый типичный пример архитектуры современного приложения — т.н. «трёхзвенка», т.е. веб-сервер, сервер приложений и сервер БД, следовательно, каждый из этих компонентов будет чуть менее чем полностью оказывает влияние на работу всего приложения. Если рассматривать именно такую конфигурацию, то со своего опыта могу сказать, что чаще всего возникает ситуация, которая в утрированном виде выглядит так:

Периоды недоступности или низкой производительности компонента проецируются на общую доступность приложения, которую ощущает на себе пользователь: т.е. даже при том, что нынешние прикладные системы могут обеспечивать свою доступность сильно за 90%, общая производительность всего бизнес-приложения может не дотягивать и до 90%. В реальном мире картинка выше может выглядеть как-то по-другому, но суть всегда одна — это непредсказуемость характера влияния мельчайших проблем с компонентами приложения на весь программный комплекс в целом. Ниже разбор что, как и почему, прошу под кат.
Сценарий, приближенный к реальному
В любой компании возникают ситуации, когда определенные периоды недоступности одного из звеньев приложения в итоге выливаются в периоды низкой производительности либо полной недоступности пользовательского веб-интерфейса (читай, основного функционала приложения). Если ИТ-ландшафт компании сложный, то бывает весьма затруднительно разобраться, какой именно слой является источником проблемы и к кому обращаться за ее решением. Если вернуться к визуализации такой штуки, то это все можно изобразить следующим образом:
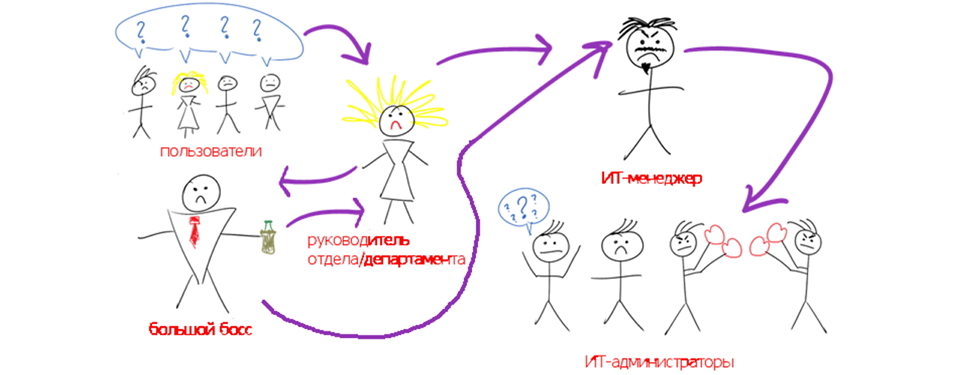
Получается ситуация lose-lose, т.е. проигрывают все. Пользователи чувствуют, что ИТ их не понимает, линейный руководитель для решения конкретной ситуации задействует ИТ и самого главного босса, который посылает лучи негодования ИТ-менеджеру. ИТ-менеджер в смешанных чувствах идет к своим администраторам, которые пытаются валить друг на друга, предоставляя результаты своих систем мониторинга (или работы самописных скриптов) и далее, далее, далее. В общем-то такая ситуация может длиться довольно долго, до тех пор пока проблема в лучшем случае самоустранится, либо все ИТ-администраторы придут к соглашению проводить диагностику каждый в своей системе и наконец найти корневую причину. По опыту коммуникаций с заказчиком могу сказать, что бывает еще такой сценарий, когда своими силами сделать ничего не удалось (в силу недостаточной экспертизы или других объективных причин), и заводится кейс у вендора соответствующего софта, что может растянуться уж совсем на неопределенный срок.
Есть еще момент, на котором остановлюсь подробнее. Любая прикладная система требует мониторинга, и не всегда в компании есть для этого нечто промышленное. В такой ситуации администратора в большинстве случаев выручит встроенный механизм мониторинга приклада, а в случае его отсутствия это может быть некий хорошо зарекомендовавший себя скрипт, запускаемый на регулярной основе. Отлично, что администратор использует удобные и понятные для него инструменты, а теперь допустим, что возник ахтунг планетарного масштаба (радикальное снижение производительности приложения или его полная недоступность). При этом механизм запуска скрипта решил какое-то время не исполняться и спокойно покурить в сторонке. В итоге размахивать перед ИТ-директором скриншотами, подтверждающими, что мониторинг всё-таки был, но вот скрипт выдал exception и scheduler споткнулся, может быть не лучшей идеей. Встроенный мониторинг хорош тем, что учитывает особенности приложения, но опять-таки владельцу приложения может быть не очень удобно собирать разнородную информацию со всех администраторов и отчитываться перед руководством о непрерывности бизнес-процесса, который поддерживает приложение. По моему мнению, администраторы прикладных систем не должны тратить свое драгоценное время на поддержку системы мониторинга, им стоит переложить этот функционал на специально обученных сотрудников внутри компании либо на внешнего подрядчика.
Как научиться понимать приложение
Что же можно сделать для формирования ситуаций win-win? Чтобы у больших боссов не возникало дополнительных вопросов на тему «а что вы делаете, чтобы такого больше не повторилось», и вы, как человек от ИТ (или менеджер по доступности такого-то сервиса), лишний раз не беспокоились, следует иметь оперативную информацию о состоянии всех компонентов систем, участвующих в основном (и не очень) бизнесе компании. Желательно на большом LCD-телевизоре, желательно с большими понятными подписями, цветовой индикацией (а-ля красный-жёлтый-зелёный) и, где-то рядом, списком фамилий напротив названий сервисов. А еще было бы здорово кликнуть мышью по сервису (который окрасился, например, в красный) и узнать, на каком звене возникла проблема. Таким образом, мы пришли к идее единой (а она может быть и зонтичной) системы мониторинга, которая охватывает все части бизнес-приложения, используя стандартные модули мониторинга (конечно, всегда есть возможность наравне со стандартными средствами использовать кастомные скрипты, либо вообще другую оупенсорсную или промышленную систему мониторинга). Ниже пример так называемого heat map, т.е. карты сервисов:
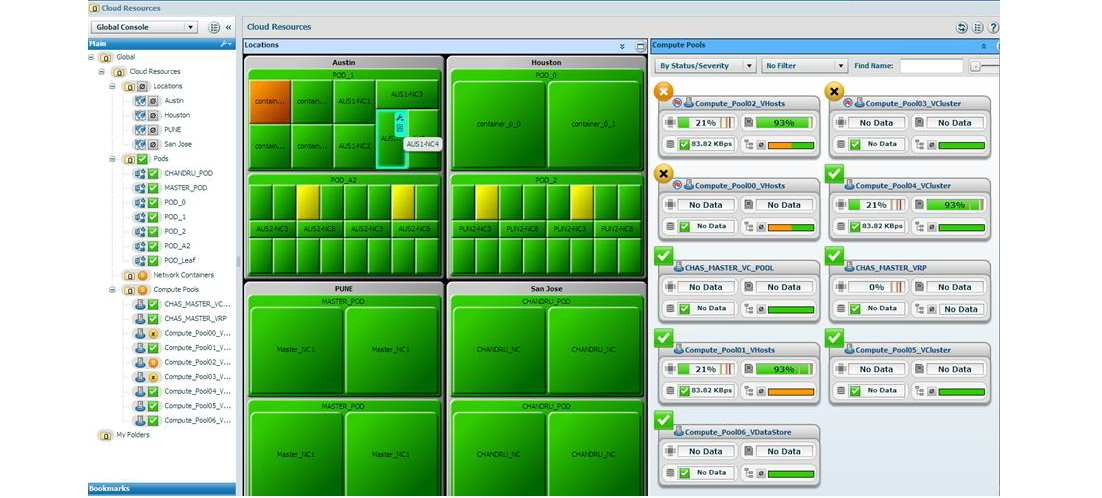
Таким образом, у сотрудников ИТ-подразделения или менеджера бизнес-сервиса есть возможность буквально «держать руку на пульсе» и в любой момент времени иметь представление о том, где возникла проблема, и у кого можно узнать о сроках решения, чтобы отчитаться перед пользователями или руководством. Очень полезен такой мониторинг бывает, когда вы проводите регламентные работы на большом количестве приложений (или их компонент) и хотите убедиться, что всё успешно восстановилось после перезагрузки, ведь тратить остаток ночи (ну, ведь правда, такие работы чаще всего проводятся по ночам) на ручную проверку всего «зоопарка» было бы не совсем рационально.
Нынешний уровень промышленных систем мониторинга позволяет производить глубокий контроль и даже рассчитывать уровень доступности бизнес-приложения. Особенно важным это может быть, когда ИТ-департамент предоставляет бизнесу набор услуг (или сервисов), по которым заключено соглашение об уровне обслуживания (SLA). Система мониторинга позволит формировать отчеты с необходимой детализацией, позволит накапливать статистику и понимать, какие компоненты бизнес-приложения недостаточно производительны, и, в конце концов, позволит бизнесу хотя бы как-то понимать, насколько качественно предоставлен ИТ-сервис. Но наиболее полное представление о работе приложения вы будете иметь, если с определенной периодичностью на среднестатистической рабочей станции будете делать то, что делает пользователь. Об этом ниже.
Как научиться понимать пользователя
Наконец, переходим к вопросу мониторинга бизнес-приложения с точки зрения пользователя, без этого вообще нынче никуда. Понятное дело, что конечные пользователи наиболее чувствительны к снижению производительности или недоступности приложения, и «видеть» их глазами было бы наиболее предпочтительным вариантом. Нанимать людей, которые будут, допустим, оформлять банковские проводки и сидеть с секундомером, замеряя время отклика веб-интерфейса того же Siebel, не самое лучшее занятие. Наиболее оптимальным вариантом в таком случае будет написание специального алгоритма (синтетической транзакции), который будет запускать браузер, производить авторизацию в приложении и перекидывать условную сумму в 1 рубль с одного счета на другой. Специально для дорогих читателей я написал браузерную транзакцию (есть еще транзакции с тяжёлыми клиентами) на примере одного известного интернет-магазина. По ней измеряется затраченное время на каждый шаг — первоначальная загрузка страницы в браузер, время на авторизацию пользователя, время на поиск товара и межстраничные редиректы и переходы – плюс проверяется успешное выполнение каждого шага и транзакции в целом.
Система позволяет контролировать, что загрузились конкретные изображения, также есть возможность распознавать текст со страницы (OCR-метод), сравнивать его с чем-нибудь или просто записывать, например, в БД. Можно получить тайминг транзакции, т.е. на каждом шаге запускается таймер, который измеряет время его выполнения и проверяет на успешность, чтобы владелец приложения мог понять, на каком шаге произошел сбой.
Получается, что если условный пользователь вам заявляет, что в вашем приложении все тормозит и глючит, вы сможете предоставить результаты таких транзакций и объяснить, что его случай уникальный и происходит в совершенном отрыве от реальности:) Если серьезно, то предоставление подобных графиков производительности поможем вам избавиться от ненужных активностей по поиску надуманных пользователем проблем.
В сухом остатке мы имеем инструмент, который позволяет получать информацию о наличии проблемы на самой ранней стадии (даже до начала обращения пользователей в службу поддержки). Успешность/неуспешность выполнения транзакции (или ее доступность) система мониторинга может позволять привязывать к бизнес-сервису (если говорить о сервисно-ресурсной модели) и настраивать степень ее влияния на сервис в целом (т.н. вес связи). Ниже пример сервисно-ресурсной модели:

Для тех, кто хочет еще больше понимать своих пользователей, существуют системы мониторинга реальных транзакций. Еще более круто, еще более технологично. Выглядят такие системы следующим образом:
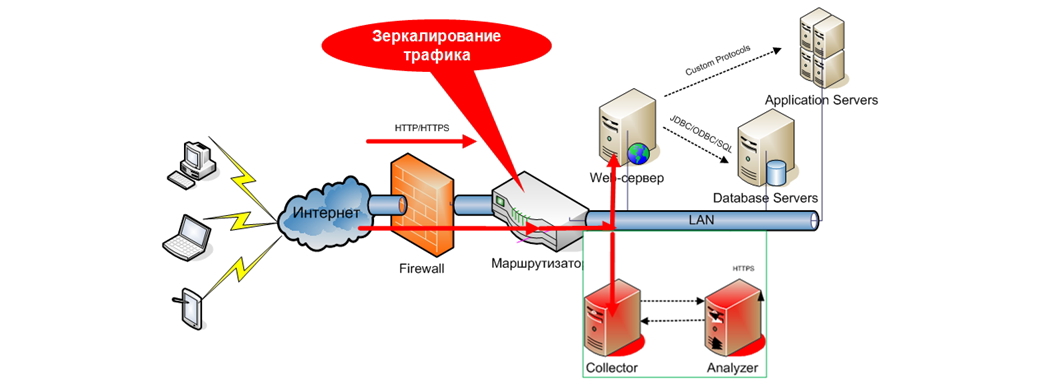
Т.е. весь HTTP/HTTPS трафик, который маршрутизирован на веб-сервер (ферму веб-серверов), зеркалируется на специальный коллектор (на схеме обозначен как Collector). Далее происходит его анализ и формирование заранее заданных представлений (иногда называются дашлетами от англ. dashlets). Такого рода мониторинг можно использовать, например, как механизм отладки веб-приложений для поиска низкопроизводительных компонент, либо определения алгоритмов перехода пользователя между страницами, определения географической локации пользователя, типа браузера и т.п. Ниже приведен пример дашборда анализатора сетевого трафика:
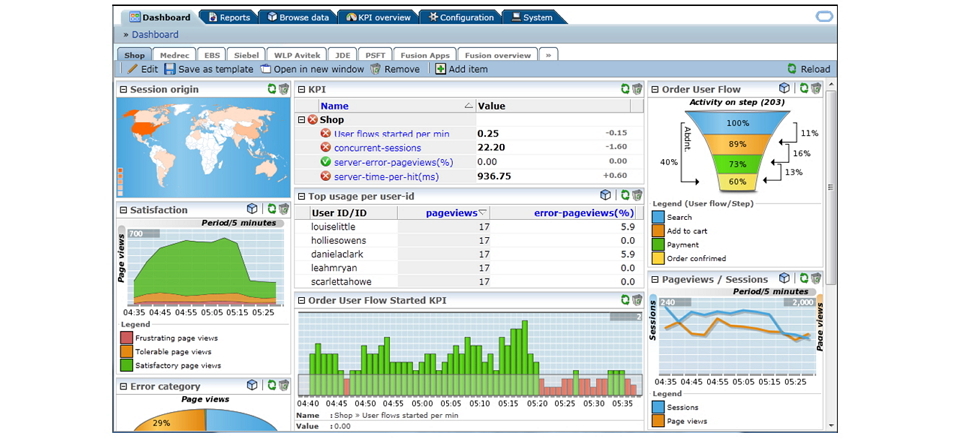
Обратите внимание на т.н. «стакан» в верхнем правом углу окна. Это заранее заданный алгоритм перехода пользователей между страницами, который подсчитывает, сколько пользователей переходят от одной страницы к другой именно в таком порядке, и сколько пользователей выходят из этой последовательности и на каком шаге. Строить графики и делать отчеты можно практически по любому параметру, который передается в HTTP заголовках (имя пользователя, его id и т.п.), т.е. система действительно гибкая и готова подстраиваться под потребности заказчика.
Наконец, переходим к глубокой диагностике бизнес-приложения (особенно актуально для заказных разработок). Такого рода анализ могут делать системы типа Application Diagnostics, диагностику можно производить как для JAVA, так и для .NET приложений. Специальный агент прицепляется к процессу, который выполняется на сервере и анализирует последовательность его действий. Например, на картинке ниже приведен пример такого анализа для .NET приложения, которое выдает exception, и мы можем видеть, что он возникает после запроса в БД.
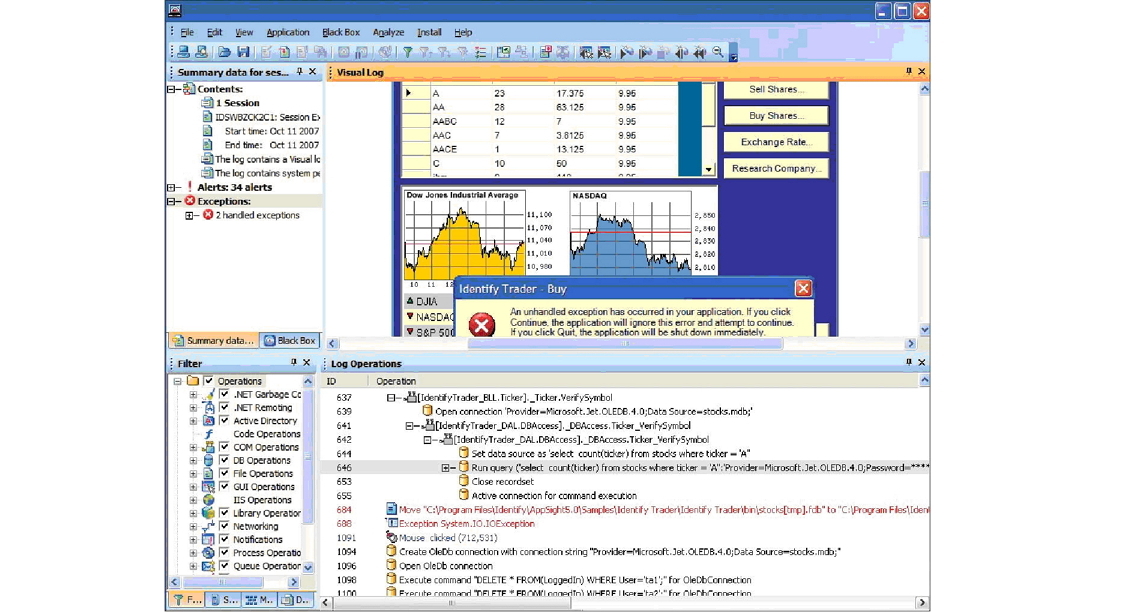
Для отладки и мониторинга самописных приложений просто must have.
А что же на выходе
На выходе мы можем иметь зонтичное решение, которое будет получать данные о работе приложения из всех описанных источников и, что самое главное, полную картину того, что происходит внутри приложения, и как это отражается на нашем (не побоюсь этого слова) любимом пользователе, ради которого всё и затевается. На рынке немало софтверных вендоров, которые имеют весь арсенал описанных решений, и выбрать для себя оптимальное решение, исходя из бюджета, потребностей, ожиданий и т.п., может быть не так уж и сложно. Б̀о́льшую часть оупенсорсных и промышленных решений можно собирать как пазл: т.е. если у вас уже есть сетевой или инфраструктурный мониторинг от одного вендора, вы с большой долей вероятности сможете дополнить его, например, синтетическим мониторингом от другого вендора.
На сегодняшний день ИТ стремится приблизиться к бизнесу настолько, насколько это возможно, и оказывать влияние на стратегию компании в целом, а инструменты, в которые может заглянуть руководитель ИТ (или выше) и понять, что деньги потрачены не зря, в целом очень востребованы рынком.
Я попытался дать поверхностное представление о различных методах мониторинга абстрактного бизнес-приложения, и если у вас возникли вопросы, то с радостью на них отвечу. Будет также интересно узнать, какими способами вы решаете задачи мониторинга, и с какими проблемами приходится сталкиваться, особенно с учетом влияния нынешних внешнеполитических факторов. Спасибо за внимание!
Автор статьи: Антон Касимов
