Коллеги, добрый день.
Мы чуть затянули с выпуском нашей очередной статьи. Но тем не менее она готова и я хочу представить статью нашего нового аналитика и автора — Алексея Павлова — avpavlov.
В этой статье мы рассмотрим наиболее важный аспект «жизнедеятельности» любого Security Operation Center – выявление и оперативный анализ возникающих угроз информационной безопасности. Мы расскажем, каким образом происходит настройка правил, а также выявление и регистрация инцидентов в нашем аутсорсинговом центре мониторинга и реагирования JSOC.
О том, как работает JSOC, мы говорили в наших предыдущих статьях:
JSOC: опыт молодого российского MSSP
JSOC: как измерить доступность Security Operation Center?
В них, в том числе, упоминалось, что ядром JSOC является SIEM-система HP ArcSight ESM. В этой статье мы сконцентрируемся на описании ее настроек и доработок, которые были реализованы для уменьшения количества false-positive-событий, оперативного подключения новых систем и СЗИ, а также увеличения скорости и повышения прозрачности процесса разбора потенциальных инцидентов для наших заказчиков.
Любая SIEM имеет «из коробки» набор предустановленных корреляционных правил, которые, сопоставляя события от источников, могут оповестить клиента о возникшей угрозе. Зачем же тогда нужна дорогостоящая настройка этой системы, а также ее поддержка силами интегратора и собственного аналитика?
Для ответа на этот вопрос необходимо рассказать, как устроен жизненный цикл событий, попадающих в JSOC из источников, каков путь от срабатывания правила до создания инцидента.
Первичная обработка событий происходит на коннекторах SIEM-системы. Обработка включает в себя фильтрацию, категоризацию, приоритизацию, агрегирование и нормализацию. Далее событие в формате CEF (Common Event Format) отправляется в ядро системы HP ArcSight, где происходят его корреляция и визуализация. Это стандартные механизмы работы с событием любой SIEM. В рамках JSOC мы доработали их, чтобы расширить возможности по мониторингу инцидентов и получению информации о конечных системах.
Одними из основных функций SIEM являются фильтрация и категоризация событий, которые происходят на коннекторах. В среднестатистической SIEM-системе нормальным потоком событий считается 6000–8000 EPS (Event per Second), при этом количество типов событий с 50–80 источников исчисляется тысячами. Для удобства обработки такого объема информации и были придуманы категории событий.
Отметим, что на оборудовании и в системах различных вендоров одинаковые события зачастую называются по-разному. Например, начало сессии в рамках подключения по протоколу TCP у Cisco имеет название «Built inbound TCP connection», у Juniper – «session created», а у Checkpoint это два события: в зависимости от успешности подключения – «accept» или «block». Во избежание модификации корреляционных правил «под нового вендора» при появлении устройств были введены категории событий, определяющие совершаемое действие.
Пример: событие с межсетевого экрана Juniper – «session start»
Category Significance: /Informational – тип сообщения – информационное
Category Device Type: Firewall – событие с фаервола
Category Behavior: /Access/Start – открытие сессии
Category Outcome: /Success – успешное
Таким образом, если нам необходимо отслеживать события успешного доступа со всех устройств в корреляционном правиле, мы просто указываем Category Behavior: /Access/Start, Category Device Type: Firewall, Category Outcome: /Success.
Помимо типовой категоризации в рамках JSOC, мы реализовали дополнительную, чтобы минимизировать возможные изменения в правилах, генерирующих инциденты. Эти правила работают для разных заказчиков, и изменение параметров под одного из них может привести к временной и\или полной неработоспособности решения для всех.
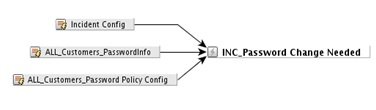
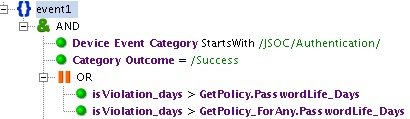
Рис. 1. Категоризация событий на примере правила «INC_Password Change Needed»
В качестве примера приведем правило «INC_Password Change Needed». Его основная задача – оповещать, если произошла аутентификация в системе под учетной записью с просроченным паролем. Период вычисляется по корпоративным правилам и разнится в зависимости от заказчика. В данном правиле используются категоризация JSOC «Device Event Category starts with /JSOC/Authentication/», которая включает в себя все события аутентификации с различных источников, и стандартная категоризация «HP Arcsight – Category Outcome =/Success» – успешное событие подключения.
Для обработки отдельных типов событий, попадающих в ядро системы, в JSOC введены специальные профилирующие и базовые правила. Профилирующие правила для самых разных активностей играют одну из важнейших ролей. Они формируют первичные данные, записываемые в active list и в дальнейшем используемые при расчетах средних, максимальных и флуктуационных показателей. К таким правилам относятся данные по аутентификации, доступу к ресурсам, ежедневному трафику, белым спискам IP-адресов для доступа к ключевым системам и др. После того как типовые профили активностей заполнены, мы можем создать правила, которые будут фиксировать отклонение от нормальной активности.
Базовые правила хотелось бы выделить отдельным пунктом. Добавление недостающей информации в события – имени пользователя в события с файерволов, информации о владельце учетной записи из кадровой системы, дополнительное описание хостов из CMDB – реализовано в JSOC для ускорения процесса разбора инцидентов и получения всей необходимой информации в одном событии.
Ярким примером использования базовых правил является «CISCO_VPN_User Session Started». Это правило позволяет связать IP-адрес сотрудника, подключающегося по VPN, с его именем пользователя (данная информация находится в разных событиях, приходящих с Cisco ASA).
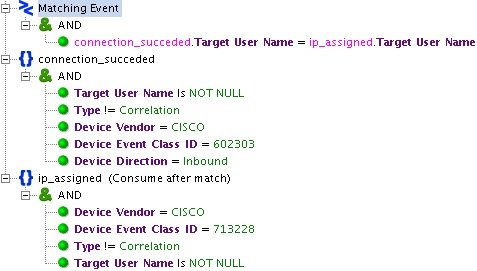
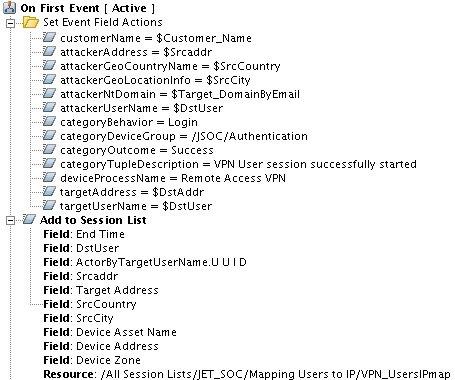
Рис. 2. Пример настроек базового правила
Существует несколько вариантов условий регистрации аномальных активностей:
Давайте разберем каждый вариант подробнее.
Самый простой способ использования корреляционных правил – срабатывание по возникновению единичного события с источника. Это прекрасно работает, если SIEM-система используется в связке с настроенными СЗИ.
При остановке критичной службы на отслеживаемом сервере происходит срабатывание правила «INC_Critical Service Stopped». Это событие может говорить о злонамеренных действиях пользователя или вредоносного ПО. Но большинство направленных атак на компанию, а также внутренних инцидентов невозможно идентифицировать по одиночному событию.
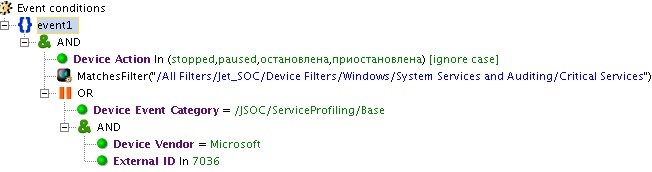
Рис. 3. Пример срабатывания правила на одиночное событие с источника
Второй способ – срабатывание корреляционных правил по нескольким последовательным событиям за период – идеально ложится в инфраструктурную безопасность.
Вход под одной учетной записью на рабочую станцию и дальнейший вход в целевую систему под другой (или такой же сценарий с VPN и информационной системой) говорит о возможней краже данных учетных записей. Подобная потенциальная угроза встречается часто, особенно в повседневной работе администраторов (domain: a.andronov, Database: oracle_admin), и вызывает большое количество ложных срабатываний, поэтому требуются создание «белых списков» и дополнительное профилирование.

Рис. 4. Пример срабатывания правила на последовательность событий с нескольких источников
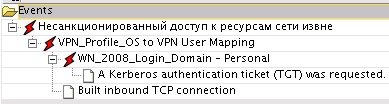
Рис. 5. Пример сопоставления событий по инциденту «несанкционированный доступ к ресурсам извне»
Третий способ настройки правил отлично подходит для выявления различных сканирований, брутфорса, эпидемий, а также DDoS.
Большое количество неуспешных попыток входа в систему может говорить о брутфорс-атаке. Правило «BF_INC_SSH_Dictionary Attack» настроено на отслеживание 20 неуспешных попыток логина на Unix-системы.
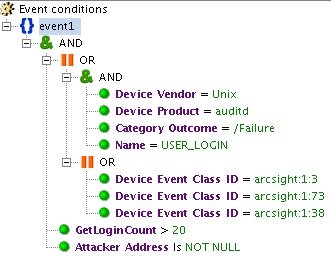
Рис. 6. Пример срабатывания правила на определенное количество событий одного типа
Наиболее сложный, в то же время эффективный и универсальный способ регистрации аномальных активностей – использование профилей.
В качестве примера можно привести корреляционное правило «INC_AV_Virus Anomaly Activity», которое отслеживает превышение среднего показателя срабатываний антивируса (вычисляется на основании профиля) за определенный период.
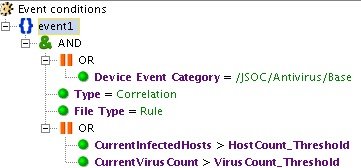
Рис. 7. Пример срабатывания правила по превышению среднего показателя
Развивая JSOC, мы извлекли определенные уроки, ставшие основой для нижеследующих рекомендаций по созданию корреляционных правил:
При этом хочется отметить: как бы хорошо ни была настроена SIEM-система, False Positive события будут присутствовать всегда. Если их нет, значит, SIEM мертв. Именно поэтому важно наличие квалифицированных инженеров мониторинга, способных выявить реальный инцидент. Специалист должен обладать набором знаний по информационной безопасности, профилям возможных атак и знать конечные системы для анализа событий.
В качестве заключительного слова хотелось бы подвести итог по рекомендациям при организации собственного SOC в компании:
Мы чуть затянули с выпуском нашей очередной статьи. Но тем не менее она готова и я хочу представить статью нашего нового аналитика и автора — Алексея Павлова — avpavlov.
В этой статье мы рассмотрим наиболее важный аспект «жизнедеятельности» любого Security Operation Center – выявление и оперативный анализ возникающих угроз информационной безопасности. Мы расскажем, каким образом происходит настройка правил, а также выявление и регистрация инцидентов в нашем аутсорсинговом центре мониторинга и реагирования JSOC.
О том, как работает JSOC, мы говорили в наших предыдущих статьях:
JSOC: опыт молодого российского MSSP
JSOC: как измерить доступность Security Operation Center?
В них, в том числе, упоминалось, что ядром JSOC является SIEM-система HP ArcSight ESM. В этой статье мы сконцентрируемся на описании ее настроек и доработок, которые были реализованы для уменьшения количества false-positive-событий, оперативного подключения новых систем и СЗИ, а также увеличения скорости и повышения прозрачности процесса разбора потенциальных инцидентов для наших заказчиков.
Любая SIEM имеет «из коробки» набор предустановленных корреляционных правил, которые, сопоставляя события от источников, могут оповестить клиента о возникшей угрозе. Зачем же тогда нужна дорогостоящая настройка этой системы, а также ее поддержка силами интегратора и собственного аналитика?
Для ответа на этот вопрос необходимо рассказать, как устроен жизненный цикл событий, попадающих в JSOC из источников, каков путь от срабатывания правила до создания инцидента.
Первичная обработка событий происходит на коннекторах SIEM-системы. Обработка включает в себя фильтрацию, категоризацию, приоритизацию, агрегирование и нормализацию. Далее событие в формате CEF (Common Event Format) отправляется в ядро системы HP ArcSight, где происходят его корреляция и визуализация. Это стандартные механизмы работы с событием любой SIEM. В рамках JSOC мы доработали их, чтобы расширить возможности по мониторингу инцидентов и получению информации о конечных системах.
Фильтрация и категоризация
Одними из основных функций SIEM являются фильтрация и категоризация событий, которые происходят на коннекторах. В среднестатистической SIEM-системе нормальным потоком событий считается 6000–8000 EPS (Event per Second), при этом количество типов событий с 50–80 источников исчисляется тысячами. Для удобства обработки такого объема информации и были придуманы категории событий.
Отметим, что на оборудовании и в системах различных вендоров одинаковые события зачастую называются по-разному. Например, начало сессии в рамках подключения по протоколу TCP у Cisco имеет название «Built inbound TCP connection», у Juniper – «session created», а у Checkpoint это два события: в зависимости от успешности подключения – «accept» или «block». Во избежание модификации корреляционных правил «под нового вендора» при появлении устройств были введены категории событий, определяющие совершаемое действие.
Пример: событие с межсетевого экрана Juniper – «session start»
Category Significance: /Informational – тип сообщения – информационное
Category Device Type: Firewall – событие с фаервола
Category Behavior: /Access/Start – открытие сессии
Category Outcome: /Success – успешное
Таким образом, если нам необходимо отслеживать события успешного доступа со всех устройств в корреляционном правиле, мы просто указываем Category Behavior: /Access/Start, Category Device Type: Firewall, Category Outcome: /Success.
Помимо типовой категоризации в рамках JSOC, мы реализовали дополнительную, чтобы минимизировать возможные изменения в правилах, генерирующих инциденты. Эти правила работают для разных заказчиков, и изменение параметров под одного из них может привести к временной и\или полной неработоспособности решения для всех.

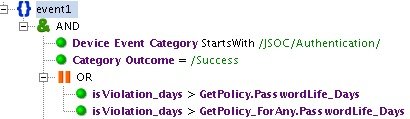
Рис. 1. Категоризация событий на примере правила «INC_Password Change Needed»
В качестве примера приведем правило «INC_Password Change Needed». Его основная задача – оповещать, если произошла аутентификация в системе под учетной записью с просроченным паролем. Период вычисляется по корпоративным правилам и разнится в зависимости от заказчика. В данном правиле используются категоризация JSOC «Device Event Category starts with /JSOC/Authentication/», которая включает в себя все события аутентификации с различных источников, и стандартная категоризация «HP Arcsight – Category Outcome =/Success» – успешное событие подключения.
Базовые и профилирующие правила
Для обработки отдельных типов событий, попадающих в ядро системы, в JSOC введены специальные профилирующие и базовые правила. Профилирующие правила для самых разных активностей играют одну из важнейших ролей. Они формируют первичные данные, записываемые в active list и в дальнейшем используемые при расчетах средних, максимальных и флуктуационных показателей. К таким правилам относятся данные по аутентификации, доступу к ресурсам, ежедневному трафику, белым спискам IP-адресов для доступа к ключевым системам и др. После того как типовые профили активностей заполнены, мы можем создать правила, которые будут фиксировать отклонение от нормальной активности.
Базовые правила хотелось бы выделить отдельным пунктом. Добавление недостающей информации в события – имени пользователя в события с файерволов, информации о владельце учетной записи из кадровой системы, дополнительное описание хостов из CMDB – реализовано в JSOC для ускорения процесса разбора инцидентов и получения всей необходимой информации в одном событии.
Ярким примером использования базовых правил является «CISCO_VPN_User Session Started». Это правило позволяет связать IP-адрес сотрудника, подключающегося по VPN, с его именем пользователя (данная информация находится в разных событиях, приходящих с Cisco ASA).
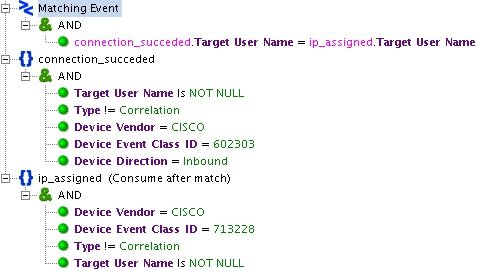
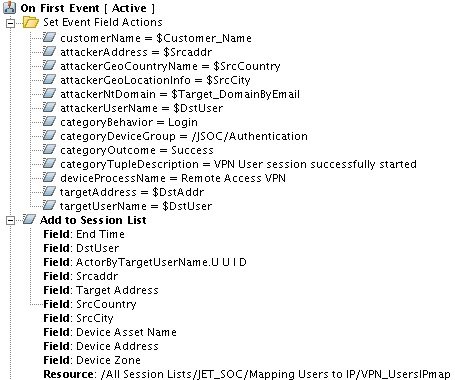
Рис. 2. Пример настроек базового правила
Создание и настройка корреляционных правил
Существует несколько вариантов условий регистрации аномальных активностей:
- По определенному событию с источника
- По нескольким последовательным событиям с источников за определенный период;
- По достижению порогового количества событий одного типа за определенный период;
- По отклонению каких-либо показателей от эталонного (либо среднего) значения.
Давайте разберем каждый вариант подробнее.
Самый простой способ использования корреляционных правил – срабатывание по возникновению единичного события с источника. Это прекрасно работает, если SIEM-система используется в связке с настроенными СЗИ.
При остановке критичной службы на отслеживаемом сервере происходит срабатывание правила «INC_Critical Service Stopped». Это событие может говорить о злонамеренных действиях пользователя или вредоносного ПО. Но большинство направленных атак на компанию, а также внутренних инцидентов невозможно идентифицировать по одиночному событию.
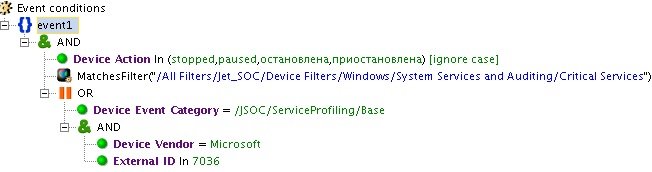
Рис. 3. Пример срабатывания правила на одиночное событие с источника
Второй способ – срабатывание корреляционных правил по нескольким последовательным событиям за период – идеально ложится в инфраструктурную безопасность.
Вход под одной учетной записью на рабочую станцию и дальнейший вход в целевую систему под другой (или такой же сценарий с VPN и информационной системой) говорит о возможней краже данных учетных записей. Подобная потенциальная угроза встречается часто, особенно в повседневной работе администраторов (domain: a.andronov, Database: oracle_admin), и вызывает большое количество ложных срабатываний, поэтому требуются создание «белых списков» и дополнительное профилирование.

Рис. 4. Пример срабатывания правила на последовательность событий с нескольких источников
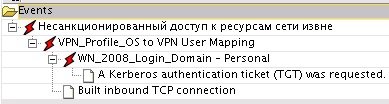
Рис. 5. Пример сопоставления событий по инциденту «несанкционированный доступ к ресурсам извне»
Третий способ настройки правил отлично подходит для выявления различных сканирований, брутфорса, эпидемий, а также DDoS.
Большое количество неуспешных попыток входа в систему может говорить о брутфорс-атаке. Правило «BF_INC_SSH_Dictionary Attack» настроено на отслеживание 20 неуспешных попыток логина на Unix-системы.
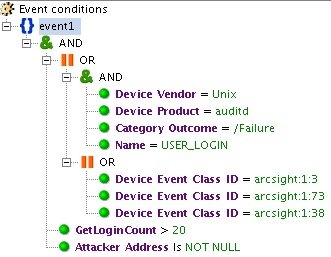
Рис. 6. Пример срабатывания правила на определенное количество событий одного типа
Наиболее сложный, в то же время эффективный и универсальный способ регистрации аномальных активностей – использование профилей.
В качестве примера можно привести корреляционное правило «INC_AV_Virus Anomaly Activity», которое отслеживает превышение среднего показателя срабатываний антивируса (вычисляется на основании профиля) за определенный период.
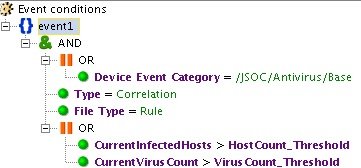
Рис. 7. Пример срабатывания правила по превышению среднего показателя
Развивая JSOC, мы извлекли определенные уроки, ставшие основой для нижеследующих рекомендаций по созданию корреляционных правил:
- Необходимо использовать профилирование. Для одного клиента может быть абсолютно нормальным использование ТОР на хосте, а для другого это прямой путь к увольнению сотрудника. У одних VPN-доступ имеют только доверенные администраторы, которые могут работать со всей инфраструктурой, у других доступ есть у половины сотрудников, но работают они только со своей станцией. Но при этом подавляющее большинство сотрудников компании работают по одному и тому же сценарию ежедневно, его легко профилировать, следовательно, и аномалии просто регистрировать. Поэтому в JSOC мы используем единые правила, но параметры, списки, фильтры в них индивидуальны для каждого клиента;
- Сложные правила не работают: если нагромоздить десяток условий срабатывания правил, чтобы минимизировать количество False Positive, то шанс их срабатывания низок, а риск пропустить что-то важное – высок;
- SIEM должна решать только свои задачи. Не нужно пытаться сбросить на нее всё, если для этих целей существуют специализированные решения. Например, требуется настроить правило, которое должно сработать в случае попытки внешнего IP-адреса совершить более 1000 подключений к внешнему ресурсу за 1 минуту. Гораздо проще настроить это правило на IPS, который для этого и предназначен, не загружая SIEM лишней работой.
При этом хочется отметить: как бы хорошо ни была настроена SIEM-система, False Positive события будут присутствовать всегда. Если их нет, значит, SIEM мертв. Именно поэтому важно наличие квалифицированных инженеров мониторинга, способных выявить реальный инцидент. Специалист должен обладать набором знаний по информационной безопасности, профилям возможных атак и знать конечные системы для анализа событий.
Заключение
В качестве заключительного слова хотелось бы подвести итог по рекомендациям при организации собственного SOC в компании:
- Важнейшим звеном SOC является SIEM-система, о вопросах ее выбора говорилось в первой статье цикла, но наиболее важным моментом является ее настройка под требования бизнеса и особенности инфраструктуры;
- Создание корреляционных правил для обнаружения различных сценариев атак и деятельности злоумышленников – это огромный пласт работ, которые никогда не заканчиваются в связи с постоянным развитием угроз. Именно поэтому необходимо наличие собственного квалифицированного аналитика;
- Первая линия инженеров мониторинга должна формироваться на базе отдела информационной безопасности. Специалист должен уметь отличать False Positive срабатывания от реальных инцидентов и проводить базовый разбор событий. Для этого необходимы навыки в сфере ИБ и понимание возможных векторов атак.
