
С предыдущего разбора прошло много времени, но я не бросил затею. Сегодня предлагаю вашему вниманию доклад Романа nevoroman Неволина, посвящённый тому, какой выход есть у человека, если он, во-первых, data scientist, а во-вторых, почему-то любит .NET.
Вполне логично, что это выступление состоялось на DotNext в декабре 2016 года:
Слайды можно найти тут.
Традиционный дисклеймер: про .NET только разбираемый в статье доклад, а не сама статья.
В предыдущих разборах не было повода заострять на этом внимание, но Роман отдельно написал, что считает себя не очень опытным спикером, поэтому прокомментирую пару моментов.
Обратите внимание, что взгляд докладчика возвращается в зал очень быстро каждый раз, как ему приходится посмотреть куда-то в сторону. В рассказе встречается код на слайдах, демо и прочие вещи, которые требуют внимания спикера. Очень у многих, даже и вполне опытных людей, взгляд после этого надолго залипает на экране, а Роман отлично справляется, именно так и надо делать.
Ещё один примечательный момент наступил примерно на 3:45. Если человека поставили на подиум и велели там стоять, потому что туда камера нацелена, то он зачастую так и будет делать, даже если это неудобно. В данном случае докладчик поступил правильно: свой дискомфорт во время выступления нужно по возможности сразу исправить, а камера как-нибудь подстроится.
Живой и держащий контакт с аудиторией докладчик может позволить себе больше огрехов в содержании и слайдах и всё равно выступить хорошо. Конечно, провальный бред никаким контактом с аудиторией не спасти, но нормальному рассказу живость выступающего придаёт много очков убедительности.
В общих чертах смысл рассказа Романа таков: есть типовые инструменты, которые нужны data scientist'у, и до сих пор этот набор инструментов никак не ассоциировался с .NET. А между тем, в рамках платформы существует отличный язычок F#, в котором практически всё уже есть, берите и пользуйтесь.
Предположим, что целью выступления является популяризация F#. Поскольку это инструмент на стыке .NET и data science, то перспективно было бы пойти к тем, у кого data science, и продавать им .NET + F#. Трудно представить, как пересадить на .NET исследователя, у которого сейчас совершенно другой стек технологий, и разработчики, которые его окружают, .NET тоже не используют, но мне кажется, что рынок сбыта именно там. На конференции же по .NET людей, которые вдруг хлопнут себя по лбу и осознают, что F# подходит для решения их задач, вряд ли много.
Я глубоко убеждён, что история с сюжетом, хоть каким-то, в которую вплетены технические сведения, работает лучше, чем просто перечисление этих технических сведений. В докладе мы видим аспекты работы data scientist'а, подкреплённые маленькими задачками на F#. В таком подходе есть несколько проблем.
Во-первых, из всего этого никак не следует, что система в целом подходит для решения глобальных задач.
Во-вторых, каждую задачу, пусть они и маленькие, зрителям приходится осмысливать с нуля, предварительно выбрасывая из головы предыдущую. За время доклада мы столкнулись со следующими предметными областями:
Поскольку задача каждый раз полностью новая, условия её приходится объяснять с нуля, а часть ранее накопленной информации зрителям приходится из головы выгружать. Мне кажется, выигрышнее смотрелась бы одна большая сквозная история, в которой по ходу дела возникали бы задачи, на которых можно демонстрировать мощь F#. Так проще сложить в голове у зрителя целостную картину.
При этом реальная или похожая на реальную задача — лучше, чем явно вымышленная. Даже если это заказная разработка и все реальные задачи под NDA, довольно часто заказчик оказывается не против рассказа, так как ничего по-настоящему конфиденциального нам разглашать не надо. Попросив у заказчика разрешение, мы ничего не теряем.
Если у нас будет сквозная задача, это будет чуть проще для зрителей, но, возможно, потребует больше времени: надо будет сделать интро в предметную область, описать архитектуру решения (на которую ещё и сослаться больше одного раза), да и код, наверное, будет сложнее. Для того, чтобы это время найти, я предлагаю сократить демонстрации, о которых сейчас самое время сказать пару слов.
На мой взгляд, демонстрация органично смотрится в руках фронтендера. Правда же, вот так тормозит, а вот эдак — уже нет. Тут получаются красивые 3d эффекты, а вон там не получаются. С помощью демонстрации можно сразу связать код и эффекты, которые он производит. Но даже это можно делать с помощью заранее записанного скринкаста.
Вживую демонстрировать серверное приложение совсем незачем, проще показать результат его работы на слайде. Аудитория и без демонстраций склонна верить докладчику, если он в целом выглядит разумно и говорит правдоподобные вещи.
Отдельно хочу покритиковать демо с линейной регрессией проката велосипедов (начинается на 27:20). Тем, кто не знаком с линейной регрессией, оно ничего не даёт, потому что код появляется и пропадает быстро, при этом всё время возникают ссылки на относящуюся к делу математику. Тут Роман говорит как раз не вполне правдоподобные вещи, и от этого следить становится совсем трудно. Если нам не нравится ошибка, которую мы получили в каком-то машинном обучении (относится ли этот термин к линейной регрессии — предмет отдельного философского спора), то скормить в обучение все имеющиеся данные — плохая идея. Мне в первую очередь приходит в голову мысль о переобучении, а вовсе не о том, что датасет какой-то фейковый и в нём нет естественного шума. То есть тут рассказать математически аккуратно не получилось, да ещё и мельтешение между приложениями.
По итогам доклада я готов поверить, что в F# есть всё, что надо, так что похоже, повторять это в отдельно слайде-резюме не надо. За скобками остались ограничения и производительность, но нельзя же говорить обо всём.
Слайды вполне достойные, поэтому бо́льшая часть моих комментариев — мелкие улучшения. Главное, что хорошо, — на слайдах есть то, что нужно именно показывать, и нет лишнего текста. То есть слайды выполняют именно ту роль, которую должны выполнять в идеальном мире: роль иллюстраций к речи докладчика.
Но улучшить, конечно, всегда есть что.
Значительная часть кода появляется на экране во время демонстраций, но и на слайдах его тоже немало. К коду у меня есть несколько предложений.
На слайдах 22-25 последовательно появляются классы, которые нужно реализовать, чтобы сделать обёртку вокруг вызова API Stackoverflow. С одной стороны, хочу сделать акцент на слове последовательно: это правильно, все сколько-нибудь сложные объекты лучше открывать зрителю по частям. Но можно сделать этот процесс чище. Посмотрите, в итоге всё приходит к трём дополнительным классам:
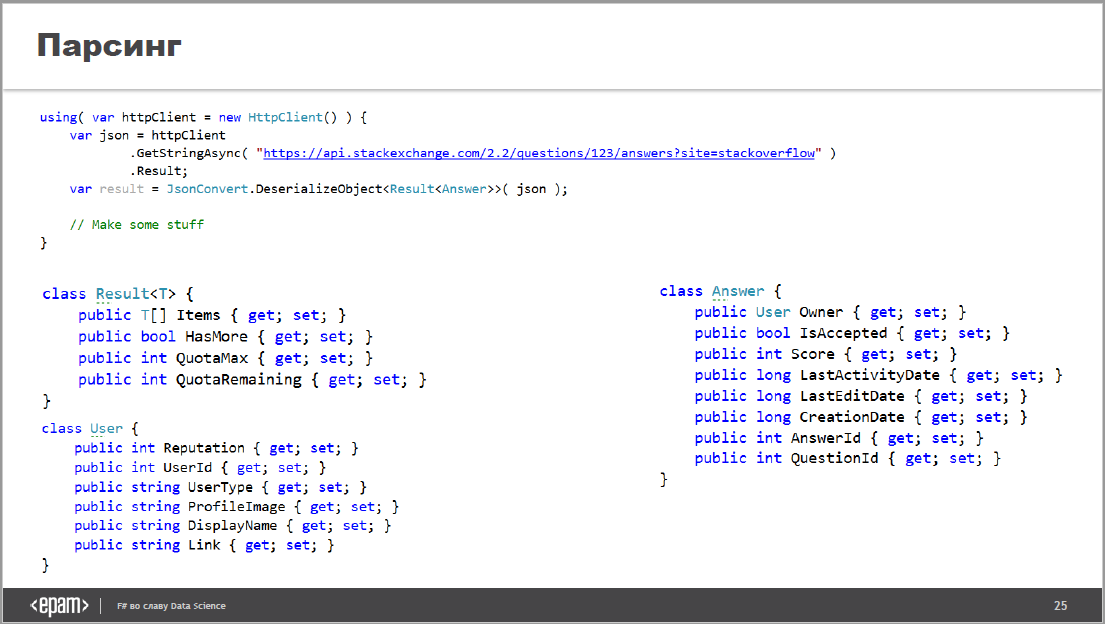
Вы на этом слайде видите сразу, почему эти три дополнительных класса понадобились? Нужно некоторое время, правда? Поэтому я предлагаю подсветить только то, на что следует смотреть:
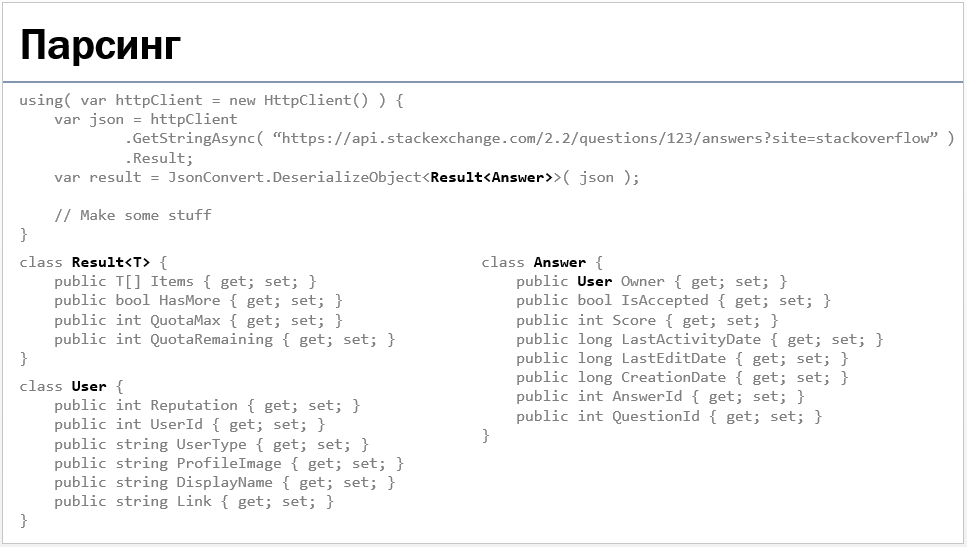
Мне кажется, так гораздо понятнее, кто из них кого за собой тянет. При последовательном открытии кусков кода подсветку уже отработанных участков, конечно, можно убирать.
Слайд 51, на котором кода довольно много, появляется в докладе на 20:33 и показывается две секунды с комментарием «не суть». Мне кажется, лучше его просто убрать. Не нужно показывать людям ничего такого, на что им не стоит смотреть.
Каждый раз, когда мы показываем динамику какого-то процесса или последовательные приближения к решению, лучше изменять на картинке только то, к чему мы хотим привлечь внимание. Всю прочую информацию, пока она сохраняет релевантность, лучше оставлять на месте. Роман в большинстве мест делает именно так, но на слайдах 36-38 я предлагаю перерисовать диаграммы:
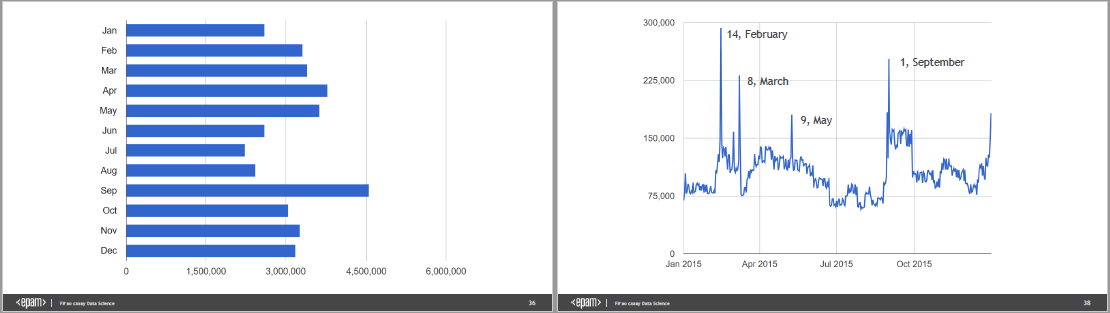
Что здесь можно улучшить? Во-первых, время — это такая штука, которая в сознании большинства людей течёт слева направо, поэтому именно для данных, изменяющихся по времени, горизонтальные столбики лучше не использовать, в отличие от почти любого другого случая. Кроме того, если повернуть диаграмму со слайда 36, на неё можно наложить график со слайдов 37 и 38, и у зрителя для контраста останется предыдущая версия попытки решения задачи. Конечно, ситуация, которую показывает Роман, довольно простая, поэтому здесь она понятна и безо всех этих ухищрений, но в каком-нибудь более сложном случае это сохранит зрителям много сил.
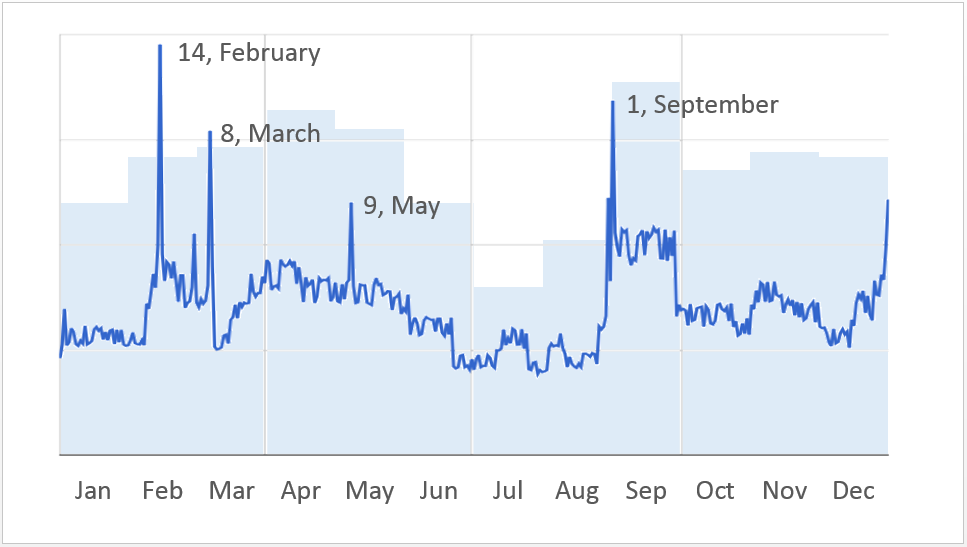
Чтобы не мучиться с двумя шкалами, вертикальную ось лучше совсем убрать, оставив только качественное сравнение. Я понимаю, что настоящий data scientist во время реальной работы так делать не будет, но здесь нам надо только передать идею. Исходников от графика я у докладчика не попросил, а то бы и сетку убрал.
Side note: интересно, что день святого Валентина круче, чем 8 марта. Впрочем, может быть, в соседнем ларьке всё иначе.
Честно скажу, замеченные небрежности не бросаются в глаза, но раз уж попались, не промолчу. Во-первых, в нескольких местах объекты на слайде смещаются без явной на то необходимости. Проблема тут в том, что, если объект не поменялся, но подвинулся, глаз всё равно фиксирует изменение, и разум уже не уверен, поменялся объект или нет. А поскольку предыдущий объект из поля зрения уже ушёл, то сознательным усилием их тоже не сравнить. Поэтому неизменные объекты самопроизвольно прыгать по слайду не должны.
При переключении между слайдами 22 и 23 заметно, что скачет верхний блок кода, хотя он не изменился. То же происходит с нижним блоком кода между слайдами 30 и 31. Даже понятно, как это получается: поскольку вручную делать подсветку на слайде лень, удобнее скопировать код из IDE в виде скриншота. Дальше на одном из слайдов картинка случайно двигается или ресайзится, а автор этого не замечает. Лучше отказаться от подсветки синтаксиса, но зато иметь код в виде текста: его проще выравнивать.
Ещё одна забавная вещь обнаружилась в продажах цветочного ларька, на которые мы уже смотрели выше. Год на слайдах 33-35 и 37-38 не совпадает:
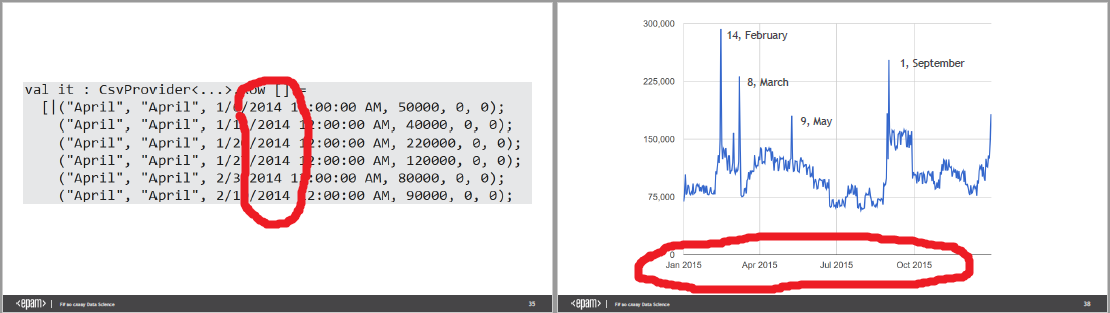
Это может иметь много валидных объяснений, но осадочек остаётся.
Если вы хотите получить обратную связь по своему выступлению, то я с радостью вам её предоставлю.
В среду, 7 июня, примерно в семь вечера в Москве мы проводим совместное мероприятие с Кириллом Анастасиным. У нас скопился приличный список типовых ошибок, которые спикеры часто допускают до выхода на сцену: при выборе темы и во время подготовки. Если вы начинаете выступать, приходите: будет полезно.
Вполне логично, что это выступление состоялось на DotNext в декабре 2016 года:
Слайды можно найти тут.
Традиционный дисклеймер: про .NET только разбираемый в статье доклад, а не сама статья.
Поведение докладчика
В предыдущих разборах не было повода заострять на этом внимание, но Роман отдельно написал, что считает себя не очень опытным спикером, поэтому прокомментирую пару моментов.
Обратите внимание, что взгляд докладчика возвращается в зал очень быстро каждый раз, как ему приходится посмотреть куда-то в сторону. В рассказе встречается код на слайдах, демо и прочие вещи, которые требуют внимания спикера. Очень у многих, даже и вполне опытных людей, взгляд после этого надолго залипает на экране, а Роман отлично справляется, именно так и надо делать.
Ещё один примечательный момент наступил примерно на 3:45. Если человека поставили на подиум и велели там стоять, потому что туда камера нацелена, то он зачастую так и будет делать, даже если это неудобно. В данном случае докладчик поступил правильно: свой дискомфорт во время выступления нужно по возможности сразу исправить, а камера как-нибудь подстроится.
Живой и держащий контакт с аудиторией докладчик может позволить себе больше огрехов в содержании и слайдах и всё равно выступить хорошо. Конечно, провальный бред никаким контактом с аудиторией не спасти, но нормальному рассказу живость выступающего придаёт много очков убедительности.
Сюжет
В общих чертах смысл рассказа Романа таков: есть типовые инструменты, которые нужны data scientist'у, и до сих пор этот набор инструментов никак не ассоциировался с .NET. А между тем, в рамках платформы существует отличный язычок F#, в котором практически всё уже есть, берите и пользуйтесь.
Целевая аудитория
Предположим, что целью выступления является популяризация F#. Поскольку это инструмент на стыке .NET и data science, то перспективно было бы пойти к тем, у кого data science, и продавать им .NET + F#. Трудно представить, как пересадить на .NET исследователя, у которого сейчас совершенно другой стек технологий, и разработчики, которые его окружают, .NET тоже не используют, но мне кажется, что рынок сбыта именно там. На конференции же по .NET людей, которые вдруг хлопнут себя по лбу и осознают, что F# подходит для решения их задач, вряд ли много.
Перечисление vs. история
Я глубоко убеждён, что история с сюжетом, хоть каким-то, в которую вплетены технические сведения, работает лучше, чем просто перечисление этих технических сведений. В докладе мы видим аспекты работы data scientist'а, подкреплённые маленькими задачками на F#. В таком подходе есть несколько проблем.
Во-первых, из всего этого никак не следует, что система в целом подходит для решения глобальных задач.
Во-вторых, каждую задачу, пусть они и маленькие, зрителям приходится осмысливать с нуля, предварительно выбрасывая из головы предыдущую. За время доклада мы столкнулись со следующими предметными областями:
- Распределение разработчиков по странам
- Продажи цветов
- Рецепты на контактные линзы
- Макроэкономические показатели стран третьего мира
- Прокат велосипедов + линейная регрессия
- Анализ курсов акций
Поскольку задача каждый раз полностью новая, условия её приходится объяснять с нуля, а часть ранее накопленной информации зрителям приходится из головы выгружать. Мне кажется, выигрышнее смотрелась бы одна большая сквозная история, в которой по ходу дела возникали бы задачи, на которых можно демонстрировать мощь F#. Так проще сложить в голове у зрителя целостную картину.
При этом реальная или похожая на реальную задача — лучше, чем явно вымышленная. Даже если это заказная разработка и все реальные задачи под NDA, довольно часто заказчик оказывается не против рассказа, так как ничего по-настоящему конфиденциального нам разглашать не надо. Попросив у заказчика разрешение, мы ничего не теряем.
Живая музыка
Если у нас будет сквозная задача, это будет чуть проще для зрителей, но, возможно, потребует больше времени: надо будет сделать интро в предметную область, описать архитектуру решения (на которую ещё и сослаться больше одного раза), да и код, наверное, будет сложнее. Для того, чтобы это время найти, я предлагаю сократить демонстрации, о которых сейчас самое время сказать пару слов.
На мой взгляд, демонстрация органично смотрится в руках фронтендера. Правда же, вот так тормозит, а вот эдак — уже нет. Тут получаются красивые 3d эффекты, а вон там не получаются. С помощью демонстрации можно сразу связать код и эффекты, которые он производит. Но даже это можно делать с помощью заранее записанного скринкаста.
Вживую демонстрировать серверное приложение совсем незачем, проще показать результат его работы на слайде. Аудитория и без демонстраций склонна верить докладчику, если он в целом выглядит разумно и говорит правдоподобные вещи.
Отдельно хочу покритиковать демо с линейной регрессией проката велосипедов (начинается на 27:20). Тем, кто не знаком с линейной регрессией, оно ничего не даёт, потому что код появляется и пропадает быстро, при этом всё время возникают ссылки на относящуюся к делу математику. Тут Роман говорит как раз не вполне правдоподобные вещи, и от этого следить становится совсем трудно. Если нам не нравится ошибка, которую мы получили в каком-то машинном обучении (относится ли этот термин к линейной регрессии — предмет отдельного философского спора), то скормить в обучение все имеющиеся данные — плохая идея. Мне в первую очередь приходит в голову мысль о переобучении, а вовсе не о том, что датасет какой-то фейковый и в нём нет естественного шума. То есть тут рассказать математически аккуратно не получилось, да ещё и мельтешение между приложениями.
Выводы
По итогам доклада я готов поверить, что в F# есть всё, что надо, так что похоже, повторять это в отдельно слайде-резюме не надо. За скобками остались ограничения и производительность, но нельзя же говорить обо всём.
Слайды
Слайды вполне достойные, поэтому бо́льшая часть моих комментариев — мелкие улучшения. Главное, что хорошо, — на слайдах есть то, что нужно именно показывать, и нет лишнего текста. То есть слайды выполняют именно ту роль, которую должны выполнять в идеальном мире: роль иллюстраций к речи докладчика.
Но улучшить, конечно, всегда есть что.
Код
Значительная часть кода появляется на экране во время демонстраций, но и на слайдах его тоже немало. К коду у меня есть несколько предложений.
На слайдах 22-25 последовательно появляются классы, которые нужно реализовать, чтобы сделать обёртку вокруг вызова API Stackoverflow. С одной стороны, хочу сделать акцент на слове последовательно: это правильно, все сколько-нибудь сложные объекты лучше открывать зрителю по частям. Но можно сделать этот процесс чище. Посмотрите, в итоге всё приходит к трём дополнительным классам:

Вы на этом слайде видите сразу, почему эти три дополнительных класса понадобились? Нужно некоторое время, правда? Поэтому я предлагаю подсветить только то, на что следует смотреть:

Мне кажется, так гораздо понятнее, кто из них кого за собой тянет. При последовательном открытии кусков кода подсветку уже отработанных участков, конечно, можно убирать.
Слайд 51, на котором кода довольно много, появляется в докладе на 20:33 и показывается две секунды с комментарием «не суть». Мне кажется, лучше его просто убрать. Не нужно показывать людям ничего такого, на что им не стоит смотреть.
Сохранение контекста
Каждый раз, когда мы показываем динамику какого-то процесса или последовательные приближения к решению, лучше изменять на картинке только то, к чему мы хотим привлечь внимание. Всю прочую информацию, пока она сохраняет релевантность, лучше оставлять на месте. Роман в большинстве мест делает именно так, но на слайдах 36-38 я предлагаю перерисовать диаграммы:
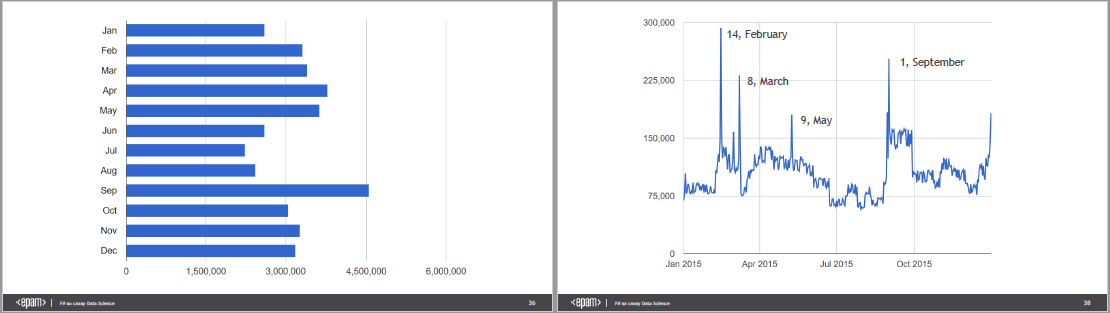
Что здесь можно улучшить? Во-первых, время — это такая штука, которая в сознании большинства людей течёт слева направо, поэтому именно для данных, изменяющихся по времени, горизонтальные столбики лучше не использовать, в отличие от почти любого другого случая. Кроме того, если повернуть диаграмму со слайда 36, на неё можно наложить график со слайдов 37 и 38, и у зрителя для контраста останется предыдущая версия попытки решения задачи. Конечно, ситуация, которую показывает Роман, довольно простая, поэтому здесь она понятна и безо всех этих ухищрений, но в каком-нибудь более сложном случае это сохранит зрителям много сил.

Чтобы не мучиться с двумя шкалами, вертикальную ось лучше совсем убрать, оставив только качественное сравнение. Я понимаю, что настоящий data scientist во время реальной работы так делать не будет, но здесь нам надо только передать идею. Исходников от графика я у докладчика не попросил, а то бы и сетку убрал.
Side note: интересно, что день святого Валентина круче, чем 8 марта. Впрочем, может быть, в соседнем ларьке всё иначе.
Небрежность
Честно скажу, замеченные небрежности не бросаются в глаза, но раз уж попались, не промолчу. Во-первых, в нескольких местах объекты на слайде смещаются без явной на то необходимости. Проблема тут в том, что, если объект не поменялся, но подвинулся, глаз всё равно фиксирует изменение, и разум уже не уверен, поменялся объект или нет. А поскольку предыдущий объект из поля зрения уже ушёл, то сознательным усилием их тоже не сравнить. Поэтому неизменные объекты самопроизвольно прыгать по слайду не должны.
При переключении между слайдами 22 и 23 заметно, что скачет верхний блок кода, хотя он не изменился. То же происходит с нижним блоком кода между слайдами 30 и 31. Даже понятно, как это получается: поскольку вручную делать подсветку на слайде лень, удобнее скопировать код из IDE в виде скриншота. Дальше на одном из слайдов картинка случайно двигается или ресайзится, а автор этого не замечает. Лучше отказаться от подсветки синтаксиса, но зато иметь код в виде текста: его проще выравнивать.
Ещё одна забавная вещь обнаружилась в продажах цветочного ларька, на которые мы уже смотрели выше. Год на слайдах 33-35 и 37-38 не совпадает:
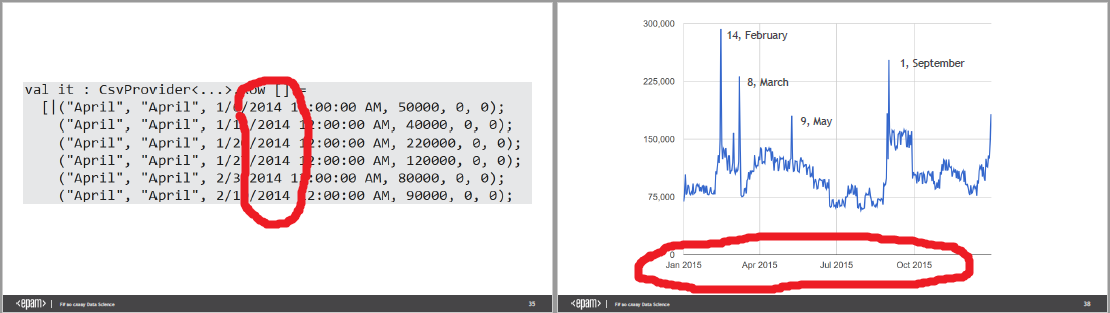
Это может иметь много валидных объяснений, но осадочек остаётся.
Регулярные разборы
Если вы хотите получить обратную связь по своему выступлению, то я с радостью вам её предоставлю.
Что для этого нужно?
Всё это нужно отправить хабраюзеру p0b0rchy, то есть мне. Обещаю, что отзыв будет конструктивным и вежливым, а также осветит и положительные моменты, а не только то, что надо улучшать.
- Ссылка на видеозапись выступления.
- Ссылка на слайды.
- Заявка от автора. Без согласия самого докладчика ничего разбирать не будем.
Всё это нужно отправить хабраюзеру p0b0rchy, то есть мне. Обещаю, что отзыв будет конструктивным и вежливым, а также осветит и положительные моменты, а не только то, что надо улучшать.
Минутка беззастенчивой саморекламы
В среду, 7 июня, примерно в семь вечера в Москве мы проводим совместное мероприятие с Кириллом Анастасиным. У нас скопился приличный список типовых ошибок, которые спикеры часто допускают до выхода на сцену: при выборе темы и во время подготовки. Если вы начинаете выступать, приходите: будет полезно.
