Постановка задач машинного обучения математически очень проста. Любая задача классификации, регрессии или кластеризации – это по сути обычная оптимизационная задача с ограничениями. Несмотря на это, существующее многообразие алгоритмов и методов их решения делает профессию аналитика данных одной из наиболее творческих IT-профессий. Чтобы решение задачи не превратилось в бесконечный поиск «золотого» решения, а было прогнозируемым процессом, необходимо придерживаться довольно четкой последовательности действий. Эту последовательность действий описывают такие методологии, как CRISP-DM.
Методология анализа данных CRISP-DM упоминается во многих постах на Хабре, но я не смог найти ее подробных русскоязычных описаний и решил своей статьей восполнить этот пробел. В основе моего материала – оригинальное описание и адаптированное описание от IBM. Обзорную лекцию о преимуществах использования CRISP-DM можно посмотреть, например, здесь.

* Crisp (англ.) — хрустящий картофель, чипсы
Я работаю в компании CleverDATA (входит в группу ЛАНИТ) на позиции дата-сайентиста с 2015 года. Мы занимаемся проектами в области больших данных и машинного обучения, преимущественно в сфере data-driven маркетинга (то есть маркетинга, построенного на «глубоком» анализе клиентских данных). Также развиваем платформу управления данными 1DMP и биржу данных 1DMC. Наши типичные проекты по машинному обучению – это разработка и внедрение предиктивных (прогнозирующих) и прескриптивных (рекомендующих наилучшее действие) моделей для оптимизации ключевых бизнес-показателей заказчика. В ряде подобных проектов мы использовали методологию CRISP-DM.
CRoss Industry Standard Process for Data Mining (CRISP-DM) – стандарт, описывающий общие процессы и подходы к аналитике данных, используемые в промышленных data-mining проектах независимо от конкретной задачи и индустрии.
На известном аналитическом портале kdnuggets.org периодически публикуется опрос (например, здесь), согласно которому среди методологий анализа данных первое место по популярности регулярно занимает именно CRISP-DM, дальше с большим отрывом идет SEMMA и реже всего используется KDD Process.
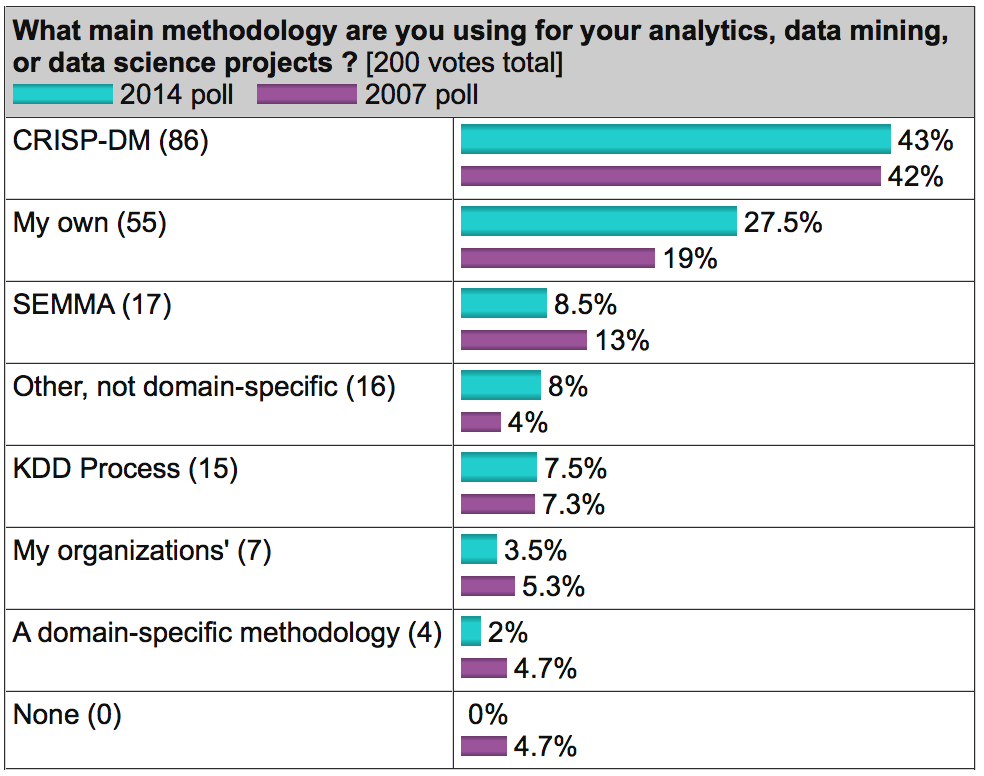 Источник: kdnuggets.com
Источник: kdnuggets.com
В целом, эти три методологии очень похожи друг на друга (здесь сложно придумать что-то принципиально новое). Однако CRISP-DM заслужила популярность как наиболее полная и детальная. По сравнению с ней KDD является более общей и теоретической, а SEMMA – это просто организация функций по целевому предназначению в инструменте SAS Enterprise Miner и затрагивает исключительно технические аспекты моделирования, никак не касаясь бизнес-постановки задачи.
Методология разработана в 1996 году по инициативе трех компаний (нынешние DaimlerChrysler, SPSS и Teradata) и далее дорабатывалась при участии 200 компаний различных индустрий, имеющих опыт data-mining проектов. Все эти компании использовали разные аналитические инструменты, но процесс у всех был построен очень похоже.
Методология активно продвигается компанией IBM. Например, она интегрирована в продукт IBM SPSS Modeler (бывший SPSS Clementine).
Важное свойство методологии – уделение внимания бизнес-целям компании. Это позволяет руководству воспринимать проекты по анализу данных не как «песочницу» для экспериментов, а как полноценный элемент бизнес-процессов компании.
Вторая особенность — это довольно детальное документирование каждого шага. По мнению авторов, хорошо задокументированный процесс позволяет менеджменту лучше понимать суть проекта, а аналитикам – больше влиять на принятие решений.
Согласно CRISP-DM, аналитический проект состоит из шести основных этапов, выполняемых последовательно:
Методология не жесткая. Она допускает вариацию в зависимости от конкретного проекта – можно возвращаться к предыдущим шагам, можно какие-то шаги пропускать, если для решаемой задачи они не важны:
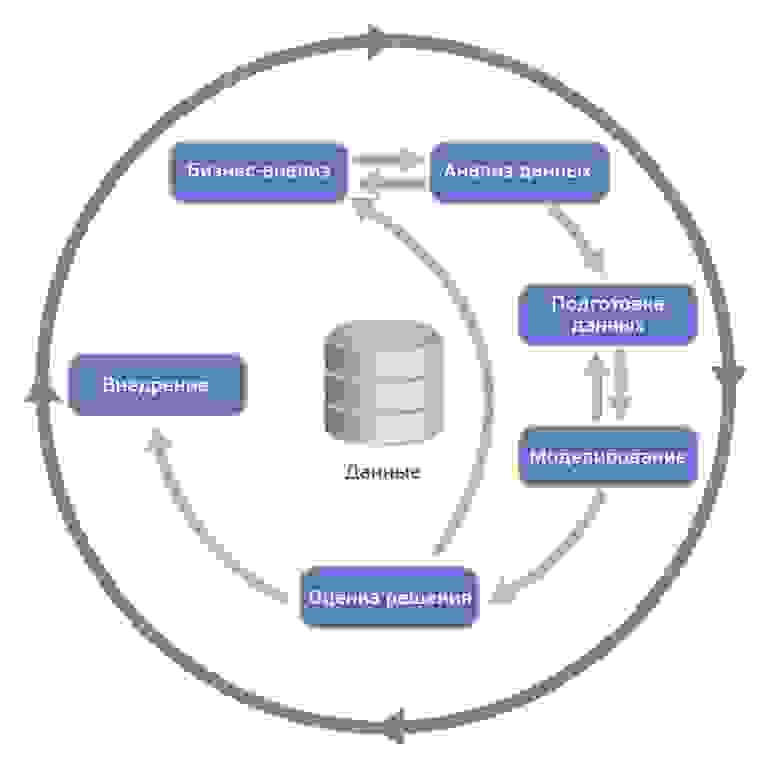 Источник Wikipedia
Источник Wikipedia
Каждый из этих этапов в свою очередь делится на задачи. На выходе каждой задачи должен получаться определенный результат. Задачи следующие:
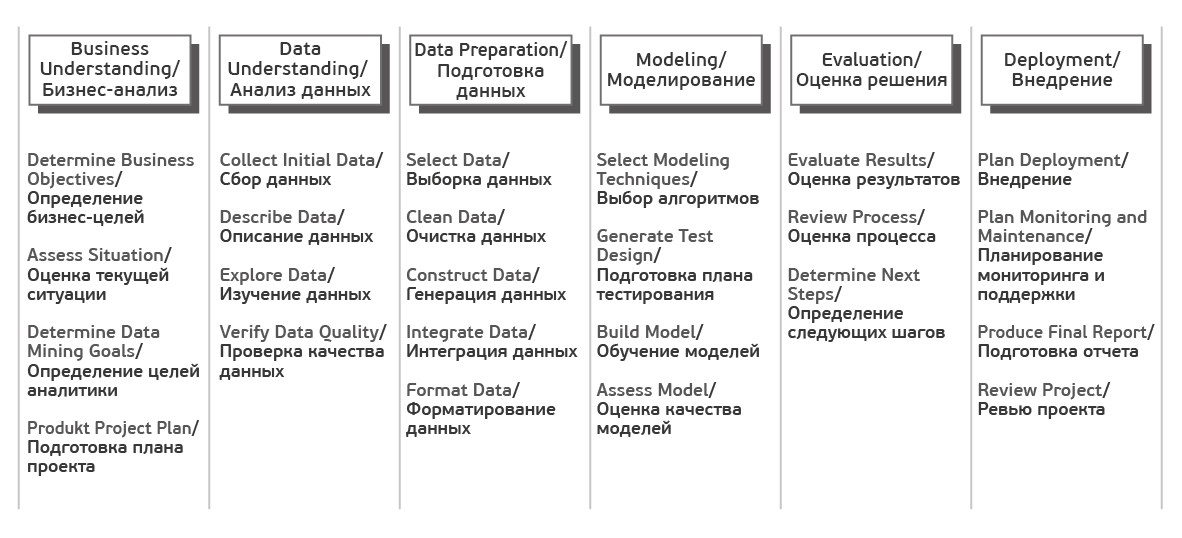
Источник Crisp_DM Documentation
В описании шагов я сознательно не буду углубляться в математику и алгоритмы, поскольку в статье фокус делается именно на процесс. Предполагаю, что читатель знаком с основами машинного обучения, но на всякий случай в следующем параграфе приводится описание базовых терминов.
Также обращу внимание, что методология одинаково применима как для внутренних проектов, так и для ситуаций, когда проект делается консультантами.
Как правило, основным результатом аналитического проекта является математическая модель. Что такое модель?
Пусть у бизнеса есть некая интересующая его величина — y (например, вероятность оттока клиента). А также есть данные — x (например, обращения клиента в техподдержку), от которых может зависеть y. Бизнес хочет понимать, как именно y зависит от x, чтобы в дальнейшем через настройку x он мог влиять на y. Таким образом, задача проекта — найти функцию f, которая лучше всего моделирует исследуемую зависимость y = f(x).
Под моделью мы будем понимать формулу f(x) либо программу, реализующую эту формулу. Любая модель описывается, во-первых, своим алгоритмом обучения (это может быть регрессия, дерево решений, градиентный бустинг и прочее), а во-вторых, набором своих параметров (которые у каждого алгоритма свои). Обучение модели – процесс поиска таких параметров, при которых модель лучше всего аппроксимирует наблюдаемые данные.
Обучающая выборка – таблица, содержащая пары x и y. Строки в этой таблице называются кейсами, а столбцы – атрибутами. Атрибуты, обладающие достаточной предсказательной способностью, будем называть предикторами. В случае с обучением «без учителя» (например, в задачах кластеризации), обучающая выборка состоит только из x. Скоринг – это применение найденной функции f(x) к новым данным, по которым y пока неизвестен. Например, в задаче кредитного скоринга сначала моделируется вероятность несвоевременной оплаты долга клиентом, а затем разработанная модель применяется к новым заявителям для оценки их кредитоспособности.

Источник
На первом шаге нам нужно определиться с целями и скоупом проекта.
Первым делом знакомимся с заказчиком и пытаемся понять, что же он на самом деле хочет (или рассказываем ему). На следующие вопросы хорошо бы получить ответ.

Источник
Когда вместе с заказчиком разобрались, что мы хотим, нужно оценить, что мы можем предложить с учетом текущих реалий.
Оцениваем, хватает ли ресурсов для проекта.
Нужно описать вероятные риски проекта, а также определить план действий по их уменьшению.
Типичные риски следующие.
Важно, чтобы заказчик и исполнитель говорили на одном языке, поэтому перед началом проекта лучше составить глоссарий и договориться об используемой в рамках проекта терминологии. Так, если мы делаем модель оттока для телекома, необходимо сразу договориться, что именно мы будем считать оттоком – например, отсутствие значительных начислений по счету в течение 4 недель подряд.
Далее стоит (хотя бы грубо) оценить ROI. В machine-learning проектах обоснованную оценку окупаемости часто можно получить только по завершению проекта (либо пилотного моделирования), но понимание потенциальной выгоды может стать хорошим драйвером для всех.
После того, как задача поставлена в бизнес-терминах, необходимо описать ее в технических терминах. В частности, отвечаем на следующие вопросы.
Как только получены ответы на все основные вопросы и ясна цель проекта, время составить план проекта. План должен содержать оценку всех шести фаз внедрения.
Начинаем реализацию проекта и для начала смотрим на данные. На этом шаге никакого моделирования нет, используется только описательная аналитика.
Цель шага – понять слабые и сильные стороны предоставленных данных, определить их достаточность, предложить идеи, как их использовать, и лучше понять процессы заказчика. Для этого мы строим графики, делаем выборки и рассчитываем статистики.

Источник
Для начала нужно понимать, какими данными располагает заказчик. Данные могут быть:
Необходимо проанализировать все источники, доступ к которым предоставляет заказчик. Если собственных данных недостаточно, возможно, стоит закупить сторонние или организовать сбор новых данных.
Далее смотрим на доступные нам данные.
С помощью графиков и таблиц исследуем данные, чтобы сформулировать гипотезы относительно того, как эти данные помогут решить задачу.
В мини-отчете фиксируем, что интересного нашли в данных, а также список атрибутов, которые потенциально полезны.
Важно еще до моделирования оценить качество данных, так как любые несоответствия могут повлиять на ход проекта. Какие могут быть сложности с данными?

Источник
Подготовка данных – это традиционно наиболее затратный по времени этап machine learning проекта (в описании говорится о 50-70% времени проекта, по нашему опыту может быть еще больше). Цель этапа – подготовить обучающую выборку для использования в моделировании.
Для начала нужно отобрать данные, которые мы будем использовать для обучения модели.
Отбираются как атрибуты, так и кейсы.
Например, если мы делаем продуктовые рекомендации посетителям сайта, мы ограничиваемся анализом только зарегистрированных пользователей.
При выборе данных аналитик отвечает на следующие вопросы.
Когда отобрали потенциально интересные данные, проверяем их качество.
На выходе получается 3 списка атрибутов – качественные атрибуты, исправленные атрибуты и забракованные.
Часто генерация признаков (feature engineering) – это наиболее важный этап в подготовке данных: грамотно составленный признак может существенно улучшить качество модели.
К генерации данных можно отнести:
Хорошо, когда данные берутся из корпоративного хранилища (КХД) или заранее подготовленной витрины. Однако часто данные необходимо загружать из нескольких источников и для подготовки обучающей выборки требуется их интеграция. Под интеграцией понимается как «горизонтальное» соединение (Merge), так и «вертикальное» объединение (Append), а также агрегация данных. На выходе, как правило, имеем единую аналитическую таблицу, пригодную для поставки в аналитическое ПО в качестве обучающей выборки.
Наконец, нужно привести данные к формату, пригодному для моделирования (только для тех алгоритмов, которые работают с определенным форматом данных). Так, если речь идет об анализе временного ряда – к примеру, прогнозируем ежемесячные продажи торговой сети – возможно, его нужно предварительно отсортировать.
На четвертом шаге наконец-то начинается самое интересное — обучение моделей. Как правило, оно выполняется итерационно – мы пробуем различные модели, сравниваем их качество, делаем перебор гиперпараметров и выбираем лучшую комбинацию. Это наиболее приятный этап проекта.
Необходимо определиться, какие модели будем использовать (благо, их множество). Выбор модели зависит от решаемой задачи, типов атрибутов и требований по сложности (например, если модель будет дальше внедряться в Excel, то RandomForest и XGBoost явно не подойдут). При выборе следует обратить внимание на следующее.
Далее надо решить, на чем мы будем обучать, а на чем тестировать нашу модель.
Традиционный подход – это разделение выборки на 3 части (обучение, валидацию и тест) в примерной пропорции 60/20/20. В этом случае обучающая выборка используется для подгонки параметров модели, а валидация и тест для получения очищенной от эффекта переобучения оценки ее качества. Более сложные стратегии предполагают использование различных вариантов кросс-валидации.
Здесь же прикидываем, как будем делать оптимизацию гиперпараметров моделей – сколько будет итераций по каждому алгоритму, будем ли делать grid-search или random-search.
Запускаем цикл обучения и после каждой итерации фиксируем результат. На выходе получаем несколько обученных моделей.
Кроме того, для каждой обученной модели фиксируем следующее.

Источник
После того, как был сформирован пул моделей, нужно их еще раз детально проанализировать и выбрать модели-победители. На выходе неплохо иметь список моделей, отсортированный по объективному и/или субъективному критерию.
Задачи шага:
Если критерий успеха не достигнут, то можно либо улучшать текущую модель, либо пробовать новую.
Прежде чем переходить к внедрению нужно убедиться, что:

Источник
Результатом предыдущего шага является построенная математическая модель (model), а также найденные закономерности (findings). На пятом шаге мы оцениваем результаты проекта.
Если на предыдущем этапе мы оценивали результаты моделирования с технической точки зрения, то здесь мы оцениваем результаты с точки зрения достижения бизнес-целей.
Адресуем следующие вопросы:
Стоит собратьсяза кружкой пива за столом, проанализировать ход проекта и сформулировать его сильные и слабые стороны. Для этого нужно пройтись по всем шагам:
Далее нужно либо внедрять модель, если она устраивает заказчика, либо, если виден потенциал для улучшения, попытаться еще ее улучшить.
Если на данном этапе у нас несколько удовлетворяющих моделей, то отбираем те, которые будем дальше внедрять.

Источник
Перед началом проекта с заказчиком всегда оговаривается способ поставки модели. В одном случае это может быть просто проскоренная база клиентов, в другом – SQL-формула, в третьем – полностью проработанное аналитическое решение, интегрированное в информационную систему.
На данном шаге осуществляется внедрение модели (если проект предполагает этап внедрения). Причем под внедрением может пониматься как физическое добавление функционала, так и инициирование изменений в бизнес-процессах компании.
Наконец собрали в кучу все полученные результаты. Что теперь?
Очень часто в проект включаются работы по поддержке решения. Вот что оговаривается.
По окончании проекта, как правило, пишется отчет о результатах моделирования, в который добавляются результаты по каждому шагу, начиная от первичного анализа данных и заканчивая внедрением модели. В этот отчет также можно включить рекомендации по дальнейшему развитию модели.
Написанный отчет презентуется заказчику и всем заинтересованным лицам. В отсутствие ТЗ этот отчет является главным документом проекта. Также важно поговорить с задействованными в проекте сотрудниками (как со стороны заказчика, так и со стороны исполнителя) и собрать их мнение о проекте.
Важно понимать, что методология не является универсальным рецептом. Это просто попытка формально описать последовательность действий, которую в той или иной степени выполняет любой аналитик, занимающийся анализом данных.
У нас в CleverDATA следование методологии на дата-майнинговых проектах не является жестким требованием, но, как правило, при составлении плана проекта наша детализация довольно точно укладывается в данную последовательность шагов.
Методология применима к совершенно разным задачам. Мы следовали ей в ряде маркетинговых проектов, в том числе, когда предсказывали вероятность отклика клиента торговой сети на рекламное предложение, делали модель оценки кредитоспособности заемщика для коммерческого банка и разрабатывали сервис рекомендаций товаров для интернет-магазина.

Источник
По задумке авторов, после каждого шага должен писаться некий отчет. Однако на практике это не очень реалистично. Как и у всех, у нас бывают проекты, когда заказчик ставит очень сжатые сроки и необходимо быстро получить результат. Понятно, что в таких условиях нет смысла тратить время на детальное документирование каждого шага. Всю промежуточную информацию, если она нужна, мы в таких случаях фиксируем карандашом «на салфетке». Это позволяет максимально быстро заняться реализацией модели и уложиться в сроки.
На практике многие вещи делаются куда менее формально, чем требует методология. Мы, например, обычно не тратим время на выбор и согласование используемых моделей, а тестируем сразу все доступные алгоритмы (конечно, если ресурсы позволяют). Аналогично поступаем с атрибутами – готовим сразу несколько вариантов каждого атрибута, чтобы можно было опробовать максимальное количество вариантов. Нерелевантные атрибуты при таком подходе отсеиваются автоматически с помощью алгоритмов feature selection – автоматическом определении предсказательной способности атрибутов.
Полагаю, формализм методологии объясняется тем, что она писалась еще в 90-е, когда не было такого количества вычислительнных мощностей и важно было грамотно спланировать каждое действие. Сейчас доступность и дешевизна «железа» упрощает многие вещи.
Всегда есть соблазн «пробежать» первые два этапа и перейти сразу к реализации. Практика показывает, что это не всегда оправдано.
На этапе постановки бизнес-целей (business understanding) важно как можно детальнее проговорить с заказчиком предлагаемое решение и убедиться, что ваши с ним ожидания совпадают. Бывает так, что бизнес рассчитывает получить в результате некоего «волшебного» робота, который сходу решит все его проблемы и мгновенно увеличит вдвое выручку. Поэтому, чтобы ни у кого не было разочарований по итогам проекта, всегда стоит четко проговаривать, какой именно результат получит заказчик и что он даст бизнесу.
Кроме того, не всегда заказчик может дать правильную оценку точности модели. В качестве примера: предположим, мы анализируем отклик на рекламную кампанию в интернете. Знаем, что по ссылке переходят примерно 10% клиентов. Разработанная нами модель отбирает 1000 наиболее склонных к отклику клиентов, и мы видим, что среди них переходит по ссылке каждый четвертый – получаем точность (precision) в 25%. Модель показывает неплохой результат (в 2.5 раза лучше «случайной» модели), но для заказчика точность в 25% слишком мала (он ждет цифр в районе 80-90%). И наоборот, совершенно бессмысленная модель, которая относит всех в один класс, покажет точность (accuracy), равную 90%, и формально будет удовлетворять заявленному критерию успеха. Т.е. важно вместе с заказчиком выбирать правильную меру качества модели и правильно ее интерпретировать.
Этап исследования (data understanding) важен тем, что позволяет и нам, и заказчику лучше понять его данные. У нас были примеры, когда после презентации результатов шага мы параллельно с основным проектом договаривались о новых, так как заказчик видел потенциал в найденных на этом этапе закономерностях.
В качестве другого примера приведу один из наших проектов, когда мы положились на диалог с заказчиком, ограничились поверхностным изучением данных и на этапе моделирования обнаружили, что часть данных оказалась неприменима из-за многочисленных пропусков. Поэтому всегда стоит заранее изучить данные, с которыми предстоит работать.
Наконец, хочу отметить, что, несмотря на свою полноту, методология все-таки достаточно общая. Она ничего не говорит о выборе конкретных алгоритмов и не дает готовых решений. Возможно, это и хорошо, так как всегда остается пространство для творческого поиска, ведь, повторюсь, сегодня профессия data scientist по-прежнему остается одной из наиболее творческих в IT-сфере.
Методология анализа данных CRISP-DM упоминается во многих постах на Хабре, но я не смог найти ее подробных русскоязычных описаний и решил своей статьей восполнить этот пробел. В основе моего материала – оригинальное описание и адаптированное описание от IBM. Обзорную лекцию о преимуществах использования CRISP-DM можно посмотреть, например, здесь.

* Crisp (англ.) — хрустящий картофель, чипсы
Я работаю в компании CleverDATA (входит в группу ЛАНИТ) на позиции дата-сайентиста с 2015 года. Мы занимаемся проектами в области больших данных и машинного обучения, преимущественно в сфере data-driven маркетинга (то есть маркетинга, построенного на «глубоком» анализе клиентских данных). Также развиваем платформу управления данными 1DMP и биржу данных 1DMC. Наши типичные проекты по машинному обучению – это разработка и внедрение предиктивных (прогнозирующих) и прескриптивных (рекомендующих наилучшее действие) моделей для оптимизации ключевых бизнес-показателей заказчика. В ряде подобных проектов мы использовали методологию CRISP-DM.
CRoss Industry Standard Process for Data Mining (CRISP-DM) – стандарт, описывающий общие процессы и подходы к аналитике данных, используемые в промышленных data-mining проектах независимо от конкретной задачи и индустрии.
На известном аналитическом портале kdnuggets.org периодически публикуется опрос (например, здесь), согласно которому среди методологий анализа данных первое место по популярности регулярно занимает именно CRISP-DM, дальше с большим отрывом идет SEMMA и реже всего используется KDD Process.
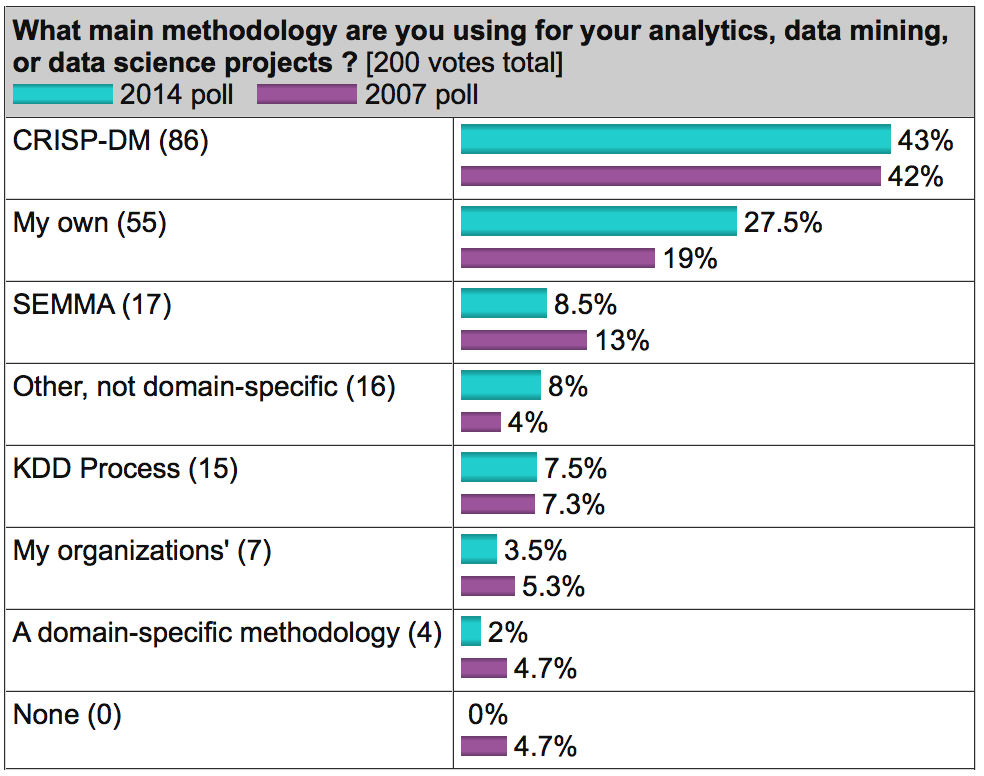
В целом, эти три методологии очень похожи друг на друга (здесь сложно придумать что-то принципиально новое). Однако CRISP-DM заслужила популярность как наиболее полная и детальная. По сравнению с ней KDD является более общей и теоретической, а SEMMA – это просто организация функций по целевому предназначению в инструменте SAS Enterprise Miner и затрагивает исключительно технические аспекты моделирования, никак не касаясь бизнес-постановки задачи.
О методологии
Методология разработана в 1996 году по инициативе трех компаний (нынешние DaimlerChrysler, SPSS и Teradata) и далее дорабатывалась при участии 200 компаний различных индустрий, имеющих опыт data-mining проектов. Все эти компании использовали разные аналитические инструменты, но процесс у всех был построен очень похоже.
Методология активно продвигается компанией IBM. Например, она интегрирована в продукт IBM SPSS Modeler (бывший SPSS Clementine).
Важное свойство методологии – уделение внимания бизнес-целям компании. Это позволяет руководству воспринимать проекты по анализу данных не как «песочницу» для экспериментов, а как полноценный элемент бизнес-процессов компании.
Вторая особенность — это довольно детальное документирование каждого шага. По мнению авторов, хорошо задокументированный процесс позволяет менеджменту лучше понимать суть проекта, а аналитикам – больше влиять на принятие решений.
Согласно CRISP-DM, аналитический проект состоит из шести основных этапов, выполняемых последовательно:
- Бизнес-анализ (Business understanding)
- Анализ данных (Data understanding)
- Подготовка данных (Data preparation)
- Моделирование (Modeling)
- Оценка результата (Evaluation)
- Внедрение (Deployment)
Методология не жесткая. Она допускает вариацию в зависимости от конкретного проекта – можно возвращаться к предыдущим шагам, можно какие-то шаги пропускать, если для решаемой задачи они не важны:
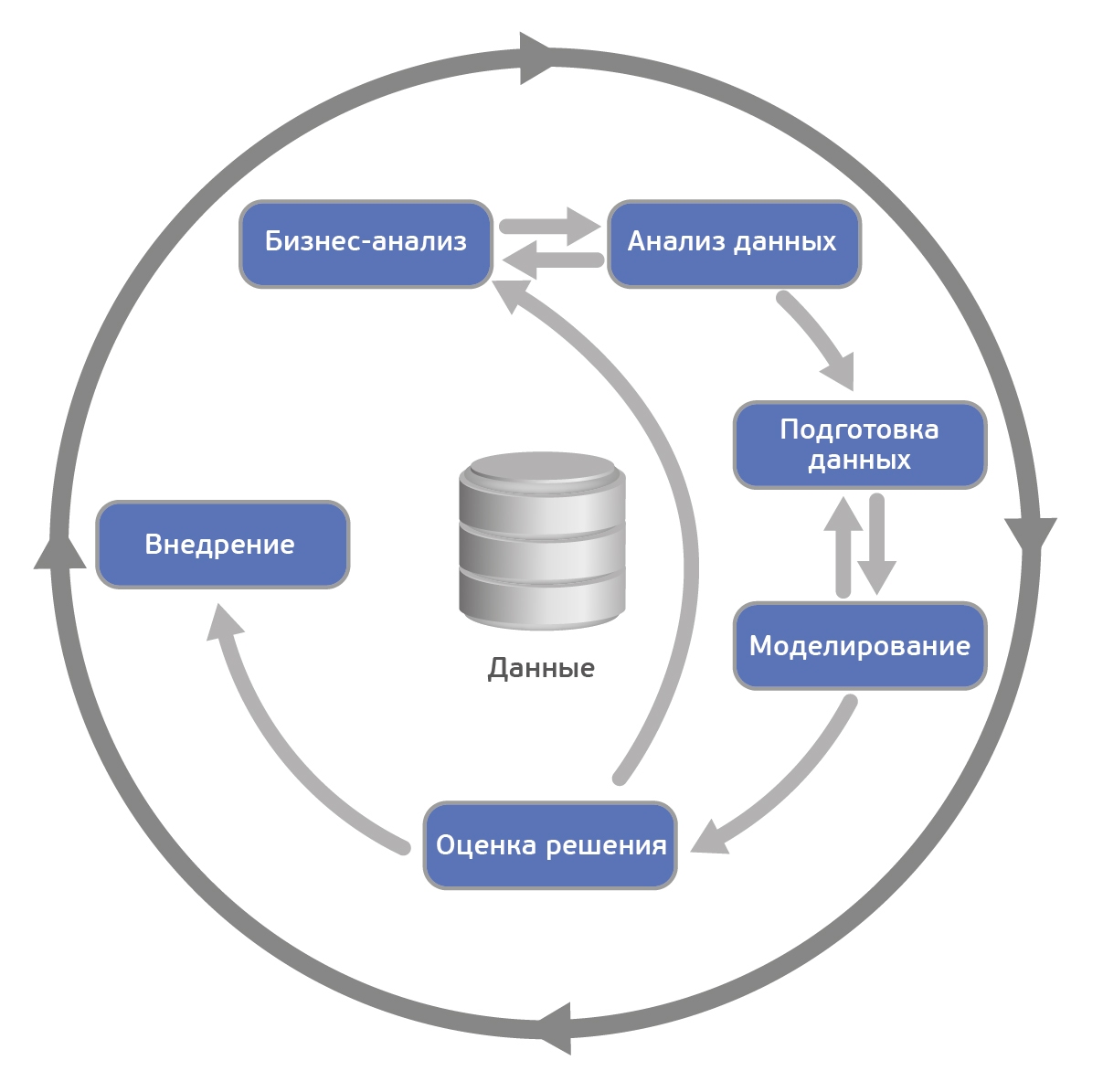
Каждый из этих этапов в свою очередь делится на задачи. На выходе каждой задачи должен получаться определенный результат. Задачи следующие:
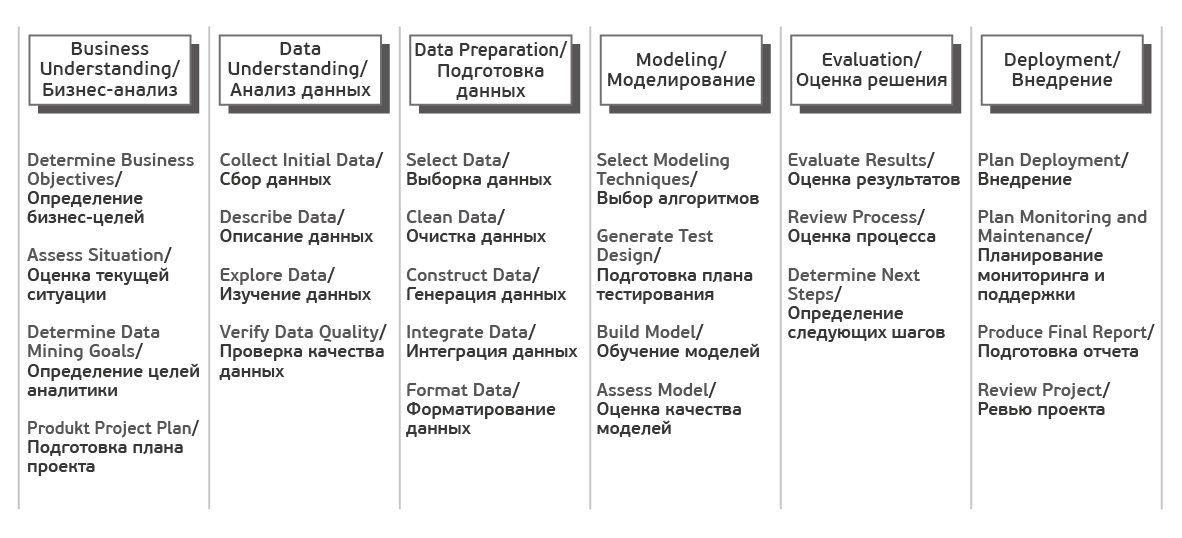
Источник Crisp_DM Documentation
В описании шагов я сознательно не буду углубляться в математику и алгоритмы, поскольку в статье фокус делается именно на процесс. Предполагаю, что читатель знаком с основами машинного обучения, но на всякий случай в следующем параграфе приводится описание базовых терминов.
Также обращу внимание, что методология одинаково применима как для внутренних проектов, так и для ситуаций, когда проект делается консультантами.
Несколько базовых понятий машинного обучения
Как правило, основным результатом аналитического проекта является математическая модель. Что такое модель?
Пусть у бизнеса есть некая интересующая его величина — y (например, вероятность оттока клиента). А также есть данные — x (например, обращения клиента в техподдержку), от которых может зависеть y. Бизнес хочет понимать, как именно y зависит от x, чтобы в дальнейшем через настройку x он мог влиять на y. Таким образом, задача проекта — найти функцию f, которая лучше всего моделирует исследуемую зависимость y = f(x).
Под моделью мы будем понимать формулу f(x) либо программу, реализующую эту формулу. Любая модель описывается, во-первых, своим алгоритмом обучения (это может быть регрессия, дерево решений, градиентный бустинг и прочее), а во-вторых, набором своих параметров (которые у каждого алгоритма свои). Обучение модели – процесс поиска таких параметров, при которых модель лучше всего аппроксимирует наблюдаемые данные.
Обучающая выборка – таблица, содержащая пары x и y. Строки в этой таблице называются кейсами, а столбцы – атрибутами. Атрибуты, обладающие достаточной предсказательной способностью, будем называть предикторами. В случае с обучением «без учителя» (например, в задачах кластеризации), обучающая выборка состоит только из x. Скоринг – это применение найденной функции f(x) к новым данным, по которым y пока неизвестен. Например, в задаче кредитного скоринга сначала моделируется вероятность несвоевременной оплаты долга клиентом, а затем разработанная модель применяется к новым заявителям для оценки их кредитоспособности.
Пошаговое описание методологии

Источник
1. Бизнес-анализ (Business Understanding)
На первом шаге нам нужно определиться с целями и скоупом проекта.
Цель проекта (Business objectives)
Первым делом знакомимся с заказчиком и пытаемся понять, что же он на самом деле хочет (или рассказываем ему). На следующие вопросы хорошо бы получить ответ.
- Организационная структура: кто участвует в проекте со стороны заказчика, кто выделяет деньги под проект, кто принимает ключевые решения, кто будет основным пользователем? Собираем контакты.
- Какова бизнес-цель проекта?
Например, уменьшение оттока клиентов.
- Существуют ли какие-то уже разработанные решения? Если существуют, то какие и чем именно текущее решение не устраивает?
1.2 Текущая ситуация (Assessing current solution)

Источник
Когда вместе с заказчиком разобрались, что мы хотим, нужно оценить, что мы можем предложить с учетом текущих реалий.
Оцениваем, хватает ли ресурсов для проекта.
- Есть ли доступное железо или его необходимо закупать?
- Где и как хранятся данные, будет ли предоставлен доступ в эти системы, нужно ли дополнительно докупать/собирать внешние данные?
- Сможет ли заказчик выделить своих экспертов для консультаций на данный проект?
Нужно описать вероятные риски проекта, а также определить план действий по их уменьшению.
Типичные риски следующие.
- Не уложиться в сроки.
- Финансовые риски (например, если спонсор потеряет заинтересованность в проекте).
- Малое количество или плохое качество данных, которые не позволят получить эффективную модель.
- Данные качественные, но закономерности в принципе отсутствуют и, как следствие, полученные результаты не интересны заказчику.
Важно, чтобы заказчик и исполнитель говорили на одном языке, поэтому перед началом проекта лучше составить глоссарий и договориться об используемой в рамках проекта терминологии. Так, если мы делаем модель оттока для телекома, необходимо сразу договориться, что именно мы будем считать оттоком – например, отсутствие значительных начислений по счету в течение 4 недель подряд.
Далее стоит (хотя бы грубо) оценить ROI. В machine-learning проектах обоснованную оценку окупаемости часто можно получить только по завершению проекта (либо пилотного моделирования), но понимание потенциальной выгоды может стать хорошим драйвером для всех.
1.3 Решаемые задачи с точки зрения аналитики (Data Mining goals)
После того, как задача поставлена в бизнес-терминах, необходимо описать ее в технических терминах. В частности, отвечаем на следующие вопросы.
- Какую метрику мы будем использовать для оценки результата моделирования (а выбрать есть из чего: Accuracy, RMSE, AUC, Precision, Recall, F-мера, R2, Lift, Logloss и т.д.)?
- Каков критерий успешности модели (например, считаем AUC равный 0.65 — минимальным порогом, 0.75 — оптимальным)?
- Если объективный критерий качества использовать не будем, то как будут оцениваться результаты?
1.4 План проекта (Project Plan)
Как только получены ответы на все основные вопросы и ясна цель проекта, время составить план проекта. План должен содержать оценку всех шести фаз внедрения.
2. Анализ данных (Data Understanding)
Начинаем реализацию проекта и для начала смотрим на данные. На этом шаге никакого моделирования нет, используется только описательная аналитика.
Цель шага – понять слабые и сильные стороны предоставленных данных, определить их достаточность, предложить идеи, как их использовать, и лучше понять процессы заказчика. Для этого мы строим графики, делаем выборки и рассчитываем статистики.
2.1 Сбор данных (Data collection)

Источник
Для начала нужно понимать, какими данными располагает заказчик. Данные могут быть:
- собственные (1st party data),
- сторонние данные (3rd party),
- «потенциальные» данные (для получения которых необходимо организовать сбор).
Необходимо проанализировать все источники, доступ к которым предоставляет заказчик. Если собственных данных недостаточно, возможно, стоит закупить сторонние или организовать сбор новых данных.
2.2 Описание данных (Data description)
Далее смотрим на доступные нам данные.
- Необходимо описать данные во всех источниках (таблица, ключ, количество строк, количество столбцов, объем на диске).
- Если объем слишком велик для используемого ПО, создаем сэмпл данных.
- Считаем ключевые статистики по атрибутам (минимум, максимум, разброс, кардинальность и т.д.).
2.3 Исследование данных (Data exploration)
С помощью графиков и таблиц исследуем данные, чтобы сформулировать гипотезы относительно того, как эти данные помогут решить задачу.
В мини-отчете фиксируем, что интересного нашли в данных, а также список атрибутов, которые потенциально полезны.
2.4 Качество данных (Data quality)
Важно еще до моделирования оценить качество данных, так как любые несоответствия могут повлиять на ход проекта. Какие могут быть сложности с данными?
- Пропущенные значения.
К примеру, мы делаем модель классификации клиентов банка по их продуктовым предпочтениям, но, поскольку анкеты заполняют только клиенты-заемщики, атрибут «уровень з/п» у клиентов-вкладчиков не заполнен.
- Ошибки данных (опечатки)
- Неконсистентная кодировка значений (например «M» и «male» в разных системах)
3. Подготовка данных (Data Preparation)

Источник
Подготовка данных – это традиционно наиболее затратный по времени этап machine learning проекта (в описании говорится о 50-70% времени проекта, по нашему опыту может быть еще больше). Цель этапа – подготовить обучающую выборку для использования в моделировании.
3.1 Отбор данных (Data Selection)
Для начала нужно отобрать данные, которые мы будем использовать для обучения модели.
Отбираются как атрибуты, так и кейсы.
Например, если мы делаем продуктовые рекомендации посетителям сайта, мы ограничиваемся анализом только зарегистрированных пользователей.
При выборе данных аналитик отвечает на следующие вопросы.
- Какова потенциальная релевантность атрибута решаемой задаче?
Так, электронная почта или номер телефона клиента как предикторы для прогнозирования явно бесполезны. А вот домен почты (mail.ru, gmail.com) или код оператора в теории уже могут обладать предсказательной способностью.
- Достаточно ли качественный атрибут для использования в модели?
Если видим, что большая часть значений атрибута пуста, то атрибут, скорее всего, бесполезен.
- Стоит ли включать коррелирующие друг с другом атрибуты?
- Есть ли ограничения на использование атрибутов?
Например, политика компании может запрещать использование атрибутов с персональной информацией в качестве предикторов.
3.2 Очистка данных (Data Cleaning)
Когда отобрали потенциально интересные данные, проверяем их качество.
- Пропущенные значения => нужно либо их заполнить, либо удалить из рассмотрения
- Ошибки в данных => попробовать исправить вручную либо удалить из рассмотрения
- Несоответствующая кодировка => привести к единой кодировке
На выходе получается 3 списка атрибутов – качественные атрибуты, исправленные атрибуты и забракованные.
3.3 Генерация данных (Constructing new data)
Часто генерация признаков (feature engineering) – это наиболее важный этап в подготовке данных: грамотно составленный признак может существенно улучшить качество модели.
К генерации данных можно отнести:
- агрегацию атрибутов (расчет sum, avg, min, max, var и т.д.),
- генерацию кейсов (например, oversampling или алгоритм SMOTE),
- конвертацию типов данных для использования в разных моделях (например, SVM традиционно работает с интервальными данными, а CHAID с номинальными),
- нормализацию атрибутов (feature scaling),
- заполнение пропущенных данных (missing data imputation).
3.4 Интеграция данных (Integrating data)
Хорошо, когда данные берутся из корпоративного хранилища (КХД) или заранее подготовленной витрины. Однако часто данные необходимо загружать из нескольких источников и для подготовки обучающей выборки требуется их интеграция. Под интеграцией понимается как «горизонтальное» соединение (Merge), так и «вертикальное» объединение (Append), а также агрегация данных. На выходе, как правило, имеем единую аналитическую таблицу, пригодную для поставки в аналитическое ПО в качестве обучающей выборки.
3.5 Форматирование данных (Formatting Data)
Наконец, нужно привести данные к формату, пригодному для моделирования (только для тех алгоритмов, которые работают с определенным форматом данных). Так, если речь идет об анализе временного ряда – к примеру, прогнозируем ежемесячные продажи торговой сети – возможно, его нужно предварительно отсортировать.
4. Моделирование (Modeling)
На четвертом шаге наконец-то начинается самое интересное — обучение моделей. Как правило, оно выполняется итерационно – мы пробуем различные модели, сравниваем их качество, делаем перебор гиперпараметров и выбираем лучшую комбинацию. Это наиболее приятный этап проекта.
4.1 Выбор алгоритмов (Selecting the modeling technique)
Необходимо определиться, какие модели будем использовать (благо, их множество). Выбор модели зависит от решаемой задачи, типов атрибутов и требований по сложности (например, если модель будет дальше внедряться в Excel, то RandomForest и XGBoost явно не подойдут). При выборе следует обратить внимание на следующее.
- Достаточно ли данных, поскольку сложные модели как правило требуют большей выборки?
- Сможет ли модель обработать пропуски данных (какие-то реализации алгоритмов умеют работать с пропусками, какие-то нет)?
- Сможет ли модель работать с имеющимися типами данных или необходима конвертация?
4.2 Планирование тестирования (Generating a test design)
Далее надо решить, на чем мы будем обучать, а на чем тестировать нашу модель.
Традиционный подход – это разделение выборки на 3 части (обучение, валидацию и тест) в примерной пропорции 60/20/20. В этом случае обучающая выборка используется для подгонки параметров модели, а валидация и тест для получения очищенной от эффекта переобучения оценки ее качества. Более сложные стратегии предполагают использование различных вариантов кросс-валидации.
Здесь же прикидываем, как будем делать оптимизацию гиперпараметров моделей – сколько будет итераций по каждому алгоритму, будем ли делать grid-search или random-search.
4.3 Обучение моделей (Building the models)
Запускаем цикл обучения и после каждой итерации фиксируем результат. На выходе получаем несколько обученных моделей.
Кроме того, для каждой обученной модели фиксируем следующее.
- Показывает ли модель какие-то интересные закономерности?
Например, что точность предсказания на 99% объясняется всего одним атрибутом.
- Какова скорость обучения/применения модели?
Если модель обучается 2 дня, возможно, стоит поискать более эффективный алгоритм или уменьшить обучающую выборку.
- Были ли проблемы с качеством данных?
Например, в тестовую выборку попали кейсы с пропущенными значениями, и из-за этого не вся выборка проскорилась.
4.4 Оценка результатов (Assessing the model)

Источник
После того, как был сформирован пул моделей, нужно их еще раз детально проанализировать и выбрать модели-победители. На выходе неплохо иметь список моделей, отсортированный по объективному и/или субъективному критерию.
Задачи шага:
- провести технический анализ качества модели (ROC, Gain, Lift и т.д.),
- оценить, готова ли модель к внедрению в КХД (или куда нужно),
- достигаются ли заданные критерии качества,
- оценить результаты с точки зрения достижения бизнес-целей. Это можно обсудить с аналитиками заказчика.
Если критерий успеха не достигнут, то можно либо улучшать текущую модель, либо пробовать новую.
Прежде чем переходить к внедрению нужно убедиться, что:
- результат моделирования понятен (модель, атрибуты, точность)
- результат моделирования логичен
Например, мы прогнозируем отток клиентов и получили ROC AUC, равный 95%. Слишком хороший результат – повод проверить модель еще раз.
- мы попробовали все доступные модели
- инфраструктура готова к внедрению модели
Заказчик: «Давайте внедрять! Только у нас места нет в витрине…».
5. Оценка результата (Evaluation)

Источник
Результатом предыдущего шага является построенная математическая модель (model), а также найденные закономерности (findings). На пятом шаге мы оцениваем результаты проекта.
5.1 Оценка результатов моделирования (Evaluating the results)
Если на предыдущем этапе мы оценивали результаты моделирования с технической точки зрения, то здесь мы оцениваем результаты с точки зрения достижения бизнес-целей.
Адресуем следующие вопросы:
- Формулировка результата в бизнес-терминах. Бизнесу гораздо легче общаться в терминах $ и ROI, чем в абстрактных Lift или R2
Классический пример диалога
Аналитик: Наша модель показывает десятикратный lift!
Бизнес: Я не впечатлён…
Аналитик: Вы заработаете дополнительных 100K$ в год!
Бизнес: С этого надо было начинать! Поподробнее, пожалуйста... - В целом насколько хорошо полученные результаты решают бизнес-задачу?
- Найдена ли какая-то новая ценная информация, которую стоит выделить отдельно?
К примеру, компания-ритейлер фокусировала свои маркетинговые усилия на сегменте «активная молодежь», но, занявшись прогнозированием вероятности отклика, с удивлением обнаружила, что их целевой сегмент совсем другой – «обеспеченные дамы 40+».
5.2 Разбор полетов (Review the process)
Стоит собраться
- Можно ли было какие-то шаги сделать более эффективными?
Например, из-за неповоротливости IT-отдела заказчика целый месяц ушел на согласование доступов. Не гуд!
- Какие были допущены ошибки и как их избежать в будущем?
На этапе планирования недооценили сложность выгрузки данных из источников и в результате не уложились в сроки.
- Были ли не сработавшие гипотезы? Если да, стоит ли их повторять?
Аналитик: «А давайте теперь попробуем сверточную нейронную сеть… Всё становится лучше с нейросетями!»
- Были ли неожиданности при реализации шагов? Как их предусмотреть в будущем?
Заказчик: «Ok. А мы думали, что обучающая выборка для разработки модели не нужна…»
5.3 Принятие решения (Determining the next steps)
Далее нужно либо внедрять модель, если она устраивает заказчика, либо, если виден потенциал для улучшения, попытаться еще ее улучшить.
Если на данном этапе у нас несколько удовлетворяющих моделей, то отбираем те, которые будем дальше внедрять.
6. Внедрение (Deployment)

Источник
Перед началом проекта с заказчиком всегда оговаривается способ поставки модели. В одном случае это может быть просто проскоренная база клиентов, в другом – SQL-формула, в третьем – полностью проработанное аналитическое решение, интегрированное в информационную систему.
На данном шаге осуществляется внедрение модели (если проект предполагает этап внедрения). Причем под внедрением может пониматься как физическое добавление функционала, так и инициирование изменений в бизнес-процессах компании.
6.1 Планирование развертывания (Planning Deployment)
Наконец собрали в кучу все полученные результаты. Что теперь?
- Важно зафиксировать, что именно и в каком виде мы будем внедрять, а также подготовить технический план внедрения (пароли, явки и прочее)
- Продумать, как с внедряемой моделью будут работать пользователи
Например, на экране сотрудника колл-центра показываем склонность клиента к подключению дополнительных услуг.
- Определить принцип мониторинга решения. Если нужно, подготовиться к опытно-промышленной эксплуатации.
Например, договариваемся об использовании модели в течение года и тюнинге модели раз в 3 месяца.
6.2 Настройка мониторинга модели (Planning Monitoring)
Очень часто в проект включаются работы по поддержке решения. Вот что оговаривается.
- Какие показатели качества модели будут отслеживаться?
В своих банковских проектах мы часто используем популярный в банках показатель population stability index PSI.
- Как понимаем, что модель устарела?
Например, если PSI больше 0.15, либо просто договариваемся о регулярном пересчете раз в 3 месяца.
- Если модель устарела, достаточно ли будет ее переобучить или нужно организовывать новый проект?
При существенных изменениях в бизнес-процессах тюнинга модели недостаточно, нужен полный цикл переобучения – с добавлением новых атрибутов, отбором предикторов и.т.д.
6.3 Отчет по результатам моделирования (Final Report)
По окончании проекта, как правило, пишется отчет о результатах моделирования, в который добавляются результаты по каждому шагу, начиная от первичного анализа данных и заканчивая внедрением модели. В этот отчет также можно включить рекомендации по дальнейшему развитию модели.
Написанный отчет презентуется заказчику и всем заинтересованным лицам. В отсутствие ТЗ этот отчет является главным документом проекта. Также важно поговорить с задействованными в проекте сотрудниками (как со стороны заказчика, так и со стороны исполнителя) и собрать их мнение о проекте.
Как насчет практики?
Важно понимать, что методология не является универсальным рецептом. Это просто попытка формально описать последовательность действий, которую в той или иной степени выполняет любой аналитик, занимающийся анализом данных.
У нас в CleverDATA следование методологии на дата-майнинговых проектах не является жестким требованием, но, как правило, при составлении плана проекта наша детализация довольно точно укладывается в данную последовательность шагов.
Методология применима к совершенно разным задачам. Мы следовали ей в ряде маркетинговых проектов, в том числе, когда предсказывали вероятность отклика клиента торговой сети на рекламное предложение, делали модель оценки кредитоспособности заемщика для коммерческого банка и разрабатывали сервис рекомендаций товаров для интернет-магазина.
Сто и один отчет

Источник
По задумке авторов, после каждого шага должен писаться некий отчет. Однако на практике это не очень реалистично. Как и у всех, у нас бывают проекты, когда заказчик ставит очень сжатые сроки и необходимо быстро получить результат. Понятно, что в таких условиях нет смысла тратить время на детальное документирование каждого шага. Всю промежуточную информацию, если она нужна, мы в таких случаях фиксируем карандашом «на салфетке». Это позволяет максимально быстро заняться реализацией модели и уложиться в сроки.
На практике многие вещи делаются куда менее формально, чем требует методология. Мы, например, обычно не тратим время на выбор и согласование используемых моделей, а тестируем сразу все доступные алгоритмы (конечно, если ресурсы позволяют). Аналогично поступаем с атрибутами – готовим сразу несколько вариантов каждого атрибута, чтобы можно было опробовать максимальное количество вариантов. Нерелевантные атрибуты при таком подходе отсеиваются автоматически с помощью алгоритмов feature selection – автоматическом определении предсказательной способности атрибутов.
Полагаю, формализм методологии объясняется тем, что она писалась еще в 90-е, когда не было такого количества вычислительнных мощностей и важно было грамотно спланировать каждое действие. Сейчас доступность и дешевизна «железа» упрощает многие вещи.
О важности планирования
Всегда есть соблазн «пробежать» первые два этапа и перейти сразу к реализации. Практика показывает, что это не всегда оправдано.
На этапе постановки бизнес-целей (business understanding) важно как можно детальнее проговорить с заказчиком предлагаемое решение и убедиться, что ваши с ним ожидания совпадают. Бывает так, что бизнес рассчитывает получить в результате некоего «волшебного» робота, который сходу решит все его проблемы и мгновенно увеличит вдвое выручку. Поэтому, чтобы ни у кого не было разочарований по итогам проекта, всегда стоит четко проговаривать, какой именно результат получит заказчик и что он даст бизнесу.
Кроме того, не всегда заказчик может дать правильную оценку точности модели. В качестве примера: предположим, мы анализируем отклик на рекламную кампанию в интернете. Знаем, что по ссылке переходят примерно 10% клиентов. Разработанная нами модель отбирает 1000 наиболее склонных к отклику клиентов, и мы видим, что среди них переходит по ссылке каждый четвертый – получаем точность (precision) в 25%. Модель показывает неплохой результат (в 2.5 раза лучше «случайной» модели), но для заказчика точность в 25% слишком мала (он ждет цифр в районе 80-90%). И наоборот, совершенно бессмысленная модель, которая относит всех в один класс, покажет точность (accuracy), равную 90%, и формально будет удовлетворять заявленному критерию успеха. Т.е. важно вместе с заказчиком выбирать правильную меру качества модели и правильно ее интерпретировать.
Этап исследования (data understanding) важен тем, что позволяет и нам, и заказчику лучше понять его данные. У нас были примеры, когда после презентации результатов шага мы параллельно с основным проектом договаривались о новых, так как заказчик видел потенциал в найденных на этом этапе закономерностях.
В качестве другого примера приведу один из наших проектов, когда мы положились на диалог с заказчиком, ограничились поверхностным изучением данных и на этапе моделирования обнаружили, что часть данных оказалась неприменима из-за многочисленных пропусков. Поэтому всегда стоит заранее изучить данные, с которыми предстоит работать.
Наконец, хочу отметить, что, несмотря на свою полноту, методология все-таки достаточно общая. Она ничего не говорит о выборе конкретных алгоритмов и не дает готовых решений. Возможно, это и хорошо, так как всегда остается пространство для творческого поиска, ведь, повторюсь, сегодня профессия data scientist по-прежнему остается одной из наиболее творческих в IT-сфере.

{kind=link}