
В нашем блоге на Хабре мы не только рассказываем о развитии своего продукта — биллинга для операторов связи «Гидра», но и публикуем материалы о работе с инфраструктурой и использовании технологий из опыта других компаний.
В Instagram развертывание backend-кода (основная программно-аппаратная часть, с которой работают клиенты) происходит от 30 до 50 раз в день, каждый раз, когда инженеры подтверждают изменение оригинала. И, по большей части, без участия человека — сложно в это поверить, особенно учитывая масштабы соцсети, но факт остается фактом.
Инженеры Instagram в своем техническом блоге рассказали о том, как создавали эту систему и налаживали ее безотказную работу. Мы представляем вашему вниманию главные мысли этой заметки.
Зачем все это нужно
У непрерывного развертывания есть несколько преимуществ:
- Непрерывное развертывание позволяет быстрее работать инженерам. Они не ограничены несколькими развертываниями за день в фиксированное время — вносить изменения по мере необходимости что экономит время.
- Непрерывное развертывание легче выявлять ошибки, которые вкрались в тот или иной коммит. Инженерам не приходится разом анализировать сотни изменений, чтобы найти причину новой ошибки, достаточно проанализировать два-три последних коммита. Метрики или данные, которые указывают на проблему, можно использовать для точного определения момента возникновения ошибки, а значит, сразу понятно, какие коммиты нужно проверить.
- Коммиты, содержащие ошибки можно быстро обнаружить и исправить, а значит код не превращается в кишащую «багами» массу, развернуть которую физически невозможно. Система всегда находится в таком состоянии, когда найти и поправить ошибку можно очень быстро.
Реализация
Успех итоговой реализации проекта во многом можно связать с итеративным подходом построения архитектуры. Система не создавалась отдельно с последующим переключением на нее, вместо этого инженеры Instagram развивали существующий процесс создания софта и работы с инфраструктурой до тех пор, пока не было реализовано непрерывное развертывание.
Что было раньше
До непрерывного развертывания, инженеры вносили изменения по мере их возникновения — если была реализована какая-то функция, которую хочется поскорее внедрить, то запускался процесс развертывания. При этом сначала развертывание происходило на тестовых серверах — на них «накатывались» обновления, затем изучались логи, и если все было хорошо, затем обновление разворачивалось уже на всю инфраструктур.
Всё это было реализовано в виде скрипта Fabric (библиотека и набор инструментов командной строки для развертывания и администрирования приложений на python), кроме того использовалась простейшая база данных и графический интерфейс “Sauron”, который хранил логи развертывания.
Тест с использованием «канареек»
Первым шагом было добавление теста с использованием «канареек» (групп конечных пользователей, которые могут не знать про участие в тесте), что изначально предполагало создание скриптов для автоматизации инжереных задач. Вместо запуска раздельного развертывания на одной машине, скрипт развертывается на машинах «канереек», записывает пользователськие логи, а затем запрашивает разрешение на дальнейшее развертывание. На следующем этапе осуществляется обработка собранных данных: скрипт анализирует HTTP-коды всех запросов и категоризирует их согласно заданному барьеру (например, менее 0,5% или как минимум 90%).
У инженеров Instagram был набор готовых тестов, однако, он запускался только сотрудниками ИТ-департамента на их рабочих машинах. А значит, рецензентам (тем, кто выполняет code review) при определение успешности или неуспешности теста приходилось верить коллегам на слово. Кроме того были неизвестны результаты теста при развертывании коммита на боевой системе.
Поэтому было решено установить систему интеграции Jenkins для запуска тестов новых изменений и создания отчетов для графического интерфейса Sauron. Этот инструмент был нужен для отслеживания последних успешно прошедших тесты коммитов — при необходимости, именно их система должна была предлагать вместо самого последнего коммита.
Для рефакторинга инженеры Facebook используют инструмент Phabricator и хорошо интегрирующуюся с ним систему Sandcastle. Их коллеги из Instagram также. воспользовались Sandcastle для запуска теста и получения отчетов.
Автоматизация
Перед началом проекта по автоматизации развертывания инженерам Instagram пришлось проделать кое-какую подготовительную работу. В частности, для каждого нового развертывания был добавлен статус (запущено, готово, ошибка) и реализованы оповещения, которые появлялись в случае, если предыдущее развертывание не имело статуса «готово». В графический интерфейс была добавлена кнопка для прерывания развертывания. Кроме того, было реализовано отслеживание всех изменени. В итоге, если раньше Sauron знал лишь о последнем удачно прошедшем тесте, то теперь все изменения боевой системы записывались, и был известен статус каждого из них.
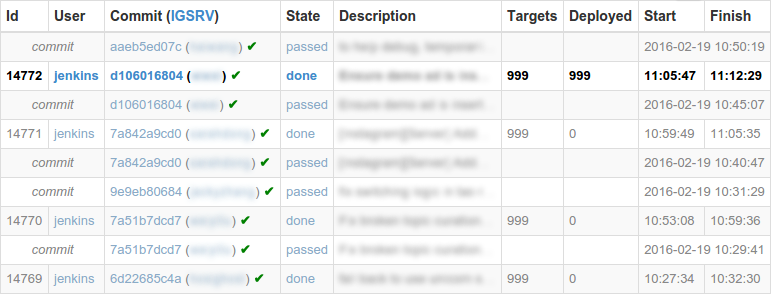
Затем была проделана работа по автоматизации оставшихся решений, которые должен был принимать человек. Первым из них был выбор коммита, который должен быть развернут. Изначальный алгоритм всегда выбирал коммиты, которые удачно прошли тест, и выбирал как можно меньшее их количество — это число никогда не превышало трех. Если все коммиты прошли тест успешно, то каждый раз выбиралось новое изменение, кроме того могло быть не более двух последовательных изменений, не прошедших тестирование. Вторым было решение об успехе или провале прохождения развертывания. Если оно не прошло более чем на одном проценте хостов, то такое развертывание считалось не выполненным.
В такой конфигурации в процессе развертывания человеку приходилось несколько раз отвечать «да» в системном диалоге (прием коммита, запуск канареечного теста, старт полного развертывания) — это действие можно было автоматизировать. Послеэтого Jenkins научился запускать скрипт полного развертывания — конечно, на первом этапе эта его возможность использовалась только под присмотром инженеров.
Проблемы
При реализации непрерывного развертывания в Instagram до его текущего состояния не все шло гладко. Было несколько неполадок, над которыми инженерам пришлось поработать.
Ошибки тестирования
Прежде всего, часто бывало так, что в коммитах содержались ошибки, приводившие к сбоям тестов — а значит они не работали и для всех последующих коммитов. А это, в свою очередь, означало, что в таком случае ничего не могло быть развернуто. Чтобы исправить ошибку, нужно было сначала заметить неполадки, откатить проблемный коммит, подождать прохождения тестов для последнего успешного коммита, а затем вручную развернуть входящие в коммит изменения, прежде чем процесс сможет продолжиться в автоматическом режиме.
Все это сводило на нет главное преимущество непрерывного развертывания — развертывание малого количества коммитов за раз. Проблема заключалось в ненадежности и малой скорости отработки тестов. Чтобы сократить время их выполнения с 12-15 минут до 5 инженерам Instagram пришлось заняться оптимизацией производительности и исправлением ошибок в тестовой инфраструктуре, которые приводили к ее ненадежности.
Накопление очереди изменений
Несмотря на внедренные улучшения, все еще регулярно образовывалась очередь изменений, ждущих развертывания после ошибки. Основной причиной являлись ошибки, выявленные в ходе канареечных тестов (как положительные, так и ложноположительные), но возникали и другие неисправности. После исправления проблемы, система автоматизации выбирала по одному коммиту для развертывания — чтобы развернуть их все, нужно было время, за которое в очередь могли попасть и новые изменения.
Обычно в такой ситуации дежурный инженер мог вмешаться и развернуть всю очередь сразу — но это, опять же, нивелировло одно из главных достоинств непрерывного развертывания.
Для исправления этого недостатка был реализован алгоритм обработки очереди в логике выбора изменений, что позволило автоматически развертывать множество изменений при наличии очереди. Алгоритм основан на установке временного интервала, через который будет развертываться каждое изменение (30 минут). Для каждого изменения в очереди рассчитывается оставшийся интервал времени, число развертываний, которые можно провести в этот интервал, и число изменений, которые должны быть развернуты за раз. Выбирается максимальное отношение изменений к развертыванию, но оно ограничивается тремя. Это позволило инженерам Instagram проводить столько развертываний, сколько возможно при обеспечении развертывания каждого коммита за приемлемое время.
Одной из специфических причин возникновения очереди было замедление развертывания из-за возросшего размера инфраструктуры сервиса. К примеру, однажды инженеры обнаружили, что ядро было полностью загружено SSH-агентом, осуществлявшим SSH-аутентификацию соединений, и скриптом Fabric. Для решения этой проблемы агент был заменен на распределенную SSH-систему от Facebook.
Памятка по развертыванию от инженеров Instagram
Что нужно знать, чтобы осуществить подобный проект? Инженеры Instagram выделили несколько основных принципов, которые следует использовать для создания столь же эффективно работающих систем автоматического развертывания.
- Тесты. Набор тестов должен быть быстрым. Охват тестов также должен быть обширным, однако здесь не обязательно пытаться объять необъятное. Тесты должны часто запускаться: при оценке кода, перед применением изменений (в идеале блокируя реализацию при ошибке), после реализации изменений.
- Тесты с использованием «канареек». Необходим автоматизированный тест с использованием «канареек» для предотвращения развертывания действительно плохих коммитов на всей инфраструктуре. Опять же, перфекционизм здесь не обязателен, даже простого набора статистических метрик и пороговых значений будет достаточно.
- Автоматизация обычного сценария. Не надо автоматизировать все, достаточно лишь стандартных и простых ситуаций. Если происходит что-то необычное, следует остановить автоматическое исполнение, чтобы в ситуацию могли вмешаться люди.
- Людям должно быть удобно. Одним из самых больших препятствий, возникающих в ходе подобных проектов по автоматизации, является тот факт, что люди перестают понимать, что происходит в текущий момент времени, и лишаются возможности контроля. Для решения этой проблемы, система должна обеспечивать хорошее понимание того, что сделано, что делается, и (в идеале) будет сделано на следующем шаге. Так же необходим хорошо работающий механизм экстренной остановки автоматического развертывания.
- Стоит ждать плохих развертываний. Не стоит надеяться на то, что все развертывания будут проходить без проблем. Ошибок не избежать, но это нормально. Главное уметь быстро находить проблемы и «откатывать» изменения до работающей версии.
По мнению инженеров Instagram, реализовать подобный проект под силам ИТ-департаментам многих компаний. Система постоянного развертывания не обязательно должна быть сложной. Стоит начать с чего-то простого, сфокусировавшись на изложенных принципах, улучшая систему шаг за шагом.
Что инженеры Instagram планируют делать дальше
Сейчас система автоматического развертывания в Instagram работает без особенных нареканий, но еще остаются некоторые моменты, которые нужно будет улучшить.
- Поддержание скорости работы. Instagram быстро развивается, и частота внесения изменений также увеличивается. Инженерам необходимо поддерживать высокую скорость развертывания для сохранения малого количества реализуемых за раз изменений.
- Добавить больше «канареек». С ростом объёма вносимых изменений, растет и число ошибок на хостах канареек, а с очередью ожидающих изменений взаимодействуют все больше разработчиков. Инженерам требуется на раннем этапе «отлавливать» больше плохих коммитов и блокировать их развертывание — для этого осуществляется постоянная модификация процесса канареечного тестирования, в частности, его результаты проверяются с помощью «боевого» трафика.
- Повышение качества обнаружения ошибок. Кроме того, инженерная команда Instagram планирует снизить влияние плохих коммитов, которые не были обнаружены с помощью канареечного тестирования. Вместо тестирования на одной машине и разворачивания на всем парке машин, планируется добавить промежуточные этапы (кластеры и регионы), на каждом из которых все метриеи будут проверяться перед дальнейшим развертыванием.
Другие технические статьи от «Латеры»:
- Автоматизируем учет адресов и привязок в IPoE-сетях
- Работа с MySQL: как масштабировать хранилище данных в 20 раз за три недели
- DoS своими силами: К чему приводит бесконтрольный рост таблиц в базе данных
- Архитектура open source-приложений: Как работает nginx
- Как повысить отказоустойчивость биллинга: Опыт «Гидры»
