
Доклад «Tarantool: как обрабатывать 1,5 млрд запросов в сутки?» — очередной в серии расшифровок с Форума Технологий Mail.Ru 2011. Подробности о том, как работает система расшифровки докладов — см. в статье «Изнанка» Форума технологий Mail.Ru: Хай-тек в event-management. Там же, а также на сайте Форума (http://techforum.mail.ru) — ссылки на расшифровки других докладов.
(Скачать видеоверсию для мобильных устройств — iOS/Android H.264 480×368, размер 170 Mb, видеобитрейт 500 кбит/с, аудио — 64 кбит/с )
(Скачать видеоверсию большего разрешения H.264 624×480, размер 610 Mb, видеобитрейт 1500 кбит/с, аудио — 128 кбит)
(Скачать слайды презентации, 520К)
Представлять данного докладчика тяжело, потому что его все знают. Каждый из вас, я уверен, пользуется продуктами, к которым Костя приложил руку. Это, в первую очередь, MySQL. Костя на протяжении многих лет занимался разработкой этой популярной базы данных, которую используют если не 100%, то 90% российских сайтов точно. Сегодня Костя работает в компании Mail.Ru Group. Костя нам сегодня расскажет о том, что мы сделали, как это работает и главное — какую производительность это позволит получить на ваших сервисах.

Добрый день. Вас сегодня очень много. Cпасибо, что пришли! Меня уже представили, поэтому я бы только хотел добавить, что я в душе и по делу все-таки инженер. Я, скорее, не руковожу, а активно участвую в разработке Tarantool, поэтому, если вам это интересно, у вас сегодня есть возможность узнать про него абсолютно всё. Так или иначе, этот доклад, помимо философствования на тему будущего СУБД, о Tarantool. Поэтому я бы хотел понять тех людей, которые сегодня пришли сюда, понять, зачем вы это сделали.
Кто пришел на этот доклад, чтобы попробовать Tarantool, узнать о нем больше на этом форуме? Такие люди есть?
Здорово, потому что в целом Tarantool — это система, которая разрабатывается в Mail.Ru Group и наиболее активно используется именно в нашей компании, но имеет намного более широкую применимость. Это open-source система, которая хорошо, на мой взгляд, задокументирована, у нас есть коннекторы ко многим языкам программирования — Python, Ruby, Perl. Недавно, буквально два дня назад, один из участников комьюнити написал новый коннектор для Python. Поэтому я надеюсь, что результатом нашего сегодняшнего разговора будет то, что вы попробуете Tarantool. И, может быть, скажете, почему это отстой — мне будет приятно услышать и такой отзыв.

О чем я буду говорить? Так как тема доклада довольно амбициозная, я буду говорить о месте Tarantool в экосистеме СУБД: почему мы сейчас имеем такое количество различных решений для хранения данных, почему это количество адекватно. Дальше мы перейдем непосредственно к системе, к разбору того, что она может делать. Закончу я рассказом о своих планах, о планах команды, о том, какие фичи мы будем добавлять в продукт и т.д.

Вот есть такая картинка, я буквально за полчаса натаскал все эти логотипы. Кто из вас узнаёт больше половины этих логотипов? Меньшинство. Т.е. многие из вас знают MySQL, может быть Memcached, может быть PostgreSQL. Вот и все, собственно.
Сегодня мы слышали доклад о Hadoop и видели, что на самом деле все эти системы очень широко используются и очень популярны. И это всё open source системы. Мы видим, что мир системного программного обеспечения все больше движется в сторону open source. Единственная здесь не open source-система, разработанная бывшими программистами Yahoo, это Citrusleaf. Это достаточно богатая возможностями коммерческая система.
Если мы проанализируем этот слайд с точки зрения характеристик данных, для работы с которыми предназначены упомянутые системы, то мы найдём две размерности. Первая размерность — это количество данных. Мы видим — Cassandra, Hadoop, Voldemort — это системы, которые призваны управлять огромным объёмом данных. На другой стороне картинки мы видим системы, которые работают зачастую с не очень большим объёмом данных, но зато обеспечивают очень высокопроизводительный доступ к этим данным. Вторая размерность — это уровень структурированности данных. И это только две метрики, по которым мы можем сравнивать эти системы. На самом деле размерностей мира NoSQL гораздо больше. Почему вообще NoSQL-движение возникло и почему мы видим это богатство? На мой взгляд, в мире традиционных СУБД есть 3 основные нерешенные проблемы. Проблем можно найти 10, 20, но основные и действительно плохо решенные проблемы реляционных СУБД следующие:

Первая проблема, проблема горизонтального масштабирования, состоит в том, что вторичные ключи, сложные запросы, хранимые процедуры достаточно плохо масштабируются на кластер из десятков или сотен компьютеров, т.е. вы не можете просто добавлять узлы, как, допустим, на предыдущем докладе вы слышали, что в Hadoop можно просто добавлять новые узлы. В принципе, проблема решаема. Есть достаточное количество масштабируемых SQL систем, которые, однако, очень дороги — NonStop SQL, Teradata. Они используются, например, в банковском секторе. То есть существуют SQL-системы, которые хорошо масштабируются горизонтально, но пока что эти решения не open source.
Вторая проблема реляционных СУБД: они рассчитаны на то, что сначала вы определяете свою схему данных, а затем вы можете писать ad-hoc запросы к данным. Т.е. вы можете написать произвольный SELECT, произвольный JOIN и т.д. Часто бывает наоборот. Схема данных очень динамично меняется, а вот запросы более или менее фиксированы — они меняются вместе со схемой данных, но и только.
Ну и в конечном счете проблема № 3 — это производительность. Это как цена за бензин, т.е если она 20 лет назад была одна и двигатели были
И, несмотря на то, что проблемы традиционных СУБД в целом понятны, изучены, и признаны сообществом учёных и практиков, мир NoSQL ответил не просто новыми решениями этих проблем, а началом с чистого листа, взрывом идей и часто там, где, собственно, взрывать ничего не нужно. Например, в такой области, как модели данных. Т.е. мир NoSQL отбросил знаменитую модель Эдгара Кодда и предложил такие парадигмы, как, например, Column Storage — хранение, ориентированное на столбцы, Key-Value Storage, JSON и XML форматы.
Также заново рассматриваются и на практике применяются разные модели консистентности данных. Здесь мы можем вспомнить ранее упомяную сегодня CAP-теорему, определяющую соотношение консистентности, доступности данных и устойчивости кластера СУБД к разбиению, то есть делению на несвязанные сегменты. Как многие пытаются интерпретировать эту теорему, прикладному программисту необходимо выбрать два свойства модели данных из трех. Например, мы можем выбрать консистентность данных на каждом узле, и eventual consistency между узлами, когда в конечном счёте все узлы окажутся консистентны между собой.
Также активно предлагаются новые языки доступа к данным, например, но это уже скорее примеры из истории, Object Query Language, XQL, NQL др. Десять лет тому назад были очень популярны XML СУБД, но где они сейчас?
Ну и, наконец, мы наблюдаем постоянную эволюцию алгоритмов хранения данных, что всегда очень важно, и создание огромного количества новых методов масштабирования, таких, как констистентное хеширование, мастер-мастер репликация и т.д.
Каково же будущее мира СУБД, к чему приведёт движение NoSQL? На мой взгляд, мир решений для хранения данных расширится, и прикладные инженеры будут вынуждены знать, что существуют NoSQL-хранилища, существуют реляционные хранилища и существуют распределенные кластеры типа Hadoop. Таким образом, из всего многообразия продуктов в будущем образуются три ниши, три базовых кластера решений, одно из которых — реляционные СУБД, которые, естественно, останутся ещё надолго.
К чему же приведут многочисленные эксперименты с моделями данных? Взять, например, парадигму Redis’а, также известного как data structures server, получит ли данный подход распространение? На мой взгляд, модели данных также вынуждены будут стабилизироваться вокруг двух принципиальных подходов: подхода, подразумевающего наличие абстракции модели от представления, и здесь лучшей абстракции, чем реляционная модель, до сих пор не предложено, и непосредственно модели представления данных.
На этом я хотел бы завершить обзор мира современных СУБД. Прогноз — неблагодарное дело, но для того чтобы дать представление о месте Tarantool в мире NoSQL СУБД, я решил дать какую-то общую картину.
Tarantool — это высокопроизводительное хранилище, которое хранит все данные в оперативной памяти. Часто поначалу слышишь такое возражение — «но это же очень дорого». Но, если сравнивать оперативную память с флеш-памятью, то окажется что RAM дешевле, чем Flash.
Tarantool — это персистентное хранилище. Данные хранятся в оперативной памяти, но все изменения данных атомарны, т.е. всё, что в Tarantool записано, записано на диск.
Здесь я бы хотел немного отвлечься и привести пример из прошлого. Если мы вспомним историю MySQL, то изначально все начиналось с того, что сообществу пользователей MySQL не были нужны транзакции, не обязательна была надёжность и атомарность хранения данных. Вспоминается MySQL
На основе опыта MySQL у меня сформировалось убеждение, что транзакции обязательны для любой современной промышленной системы хранения данных. Это фундаменталый параметр, определяющий остальные параметры архитектуры системы, и поэтому Tarantool уже сейчас поддерживает атомарные операции и в данный момент мы разрабатываем полноценную поддержку транзакций. В следующей версии она уже у нас будет.
В области языка доступа к данным решение Tarantool — это язык SQL, хотя есть поддержка и других языков программирования.
Однако следует понимать, что с точки зрения модели данных, Tarantool — key-value storage, т.е. наш основной сценарий доступа к данным — это получить значение по ключу. Таким образом, реализован далеко не весь функционал SQL.
В дополнение к простым INSERT/UPDATE/SELECT/DELETE запросам, мы поддерживаем хранимые процедуры на Lua, которые позволяют очень гибко определять, какие сценарии доступа к данным у вас есть. Наличие хранимых процедур позволяет превратить Tarantool из сервера данных в сервер бизнес-логики, т.к. появляется возможность программировать произвольный формат хранения данных, произвольные инварианты консистентности данных, произвольные запросы.
Вопрос из зала:
За счет чего поддерживается персистентность данных?
Мы используем логирование, т.е. все записи логируются на диск. Сейчас я об этом расскажу, но сначала — о модели данных.
Наша модель данных не является изобретением. Я бы ее охарактеризовал как упрощенную реляционную модель. Базовым элементом хранения является кортеж. Кортеж имеет любую размерность, это просто произвольно длинный список полей, ассоциированный с уникальным ключом. Каждый кортеж принадлежит какому-то пространству (space). По полям кортежа можно определять индексы. Если проводить аналогии с реляционными СУБД, то «пространство» соответствует таблице, а «поля» соответствуют столбцам. Мы поддерживаем два типа данных — целые числа и строки — и два типа индексов: хеши и двоичные деревья.
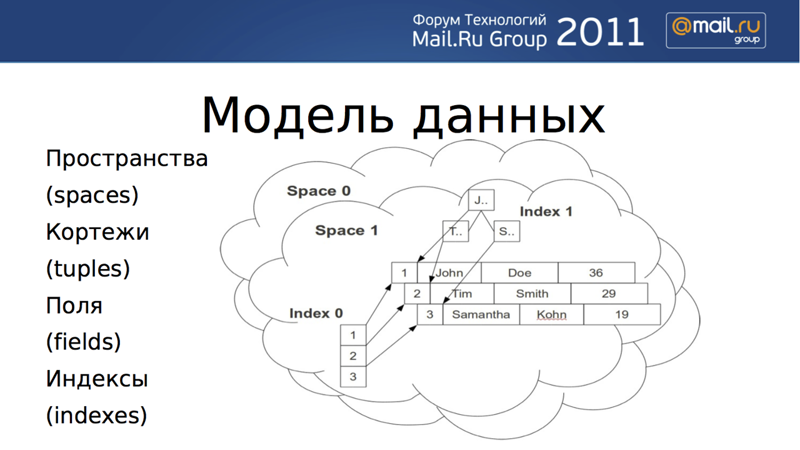
Индексы могут быть как простые, так и составные, и для поиска может использоваться любой индекс. Однако, в каждом пространстве должен быть задан простой первичный ключ, по которому должен осуществляться доступ при вставке, обновлении или удалении. Можно осуществлять доступ по составному вторичному ключу, например, по полям 3 и 5, или по полям 7, 9, 11.


Опять же, мы не являемся какими-то идеологами в области языка доступа к данным — наш клиент реализует SQL-доступ, а в области коннекторов из других языков программирования мы придерживаемся соглашений из мира традиционных СУБД. Вот как это выглядит на PHP:
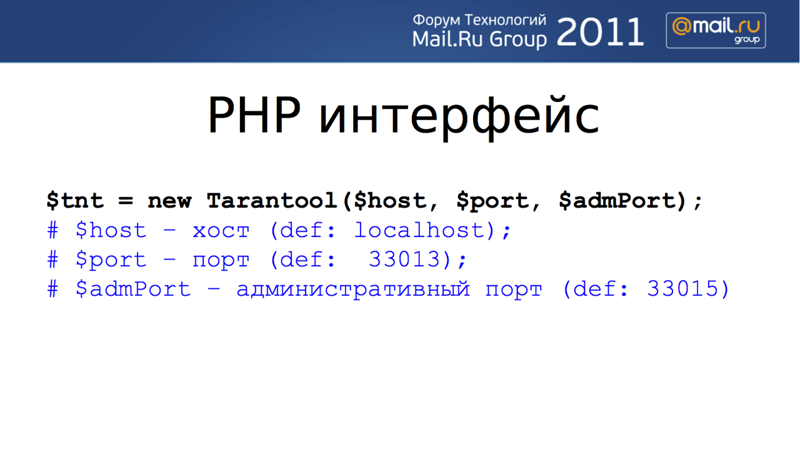
Для начала работы необходимо установить соединение с базой. Для выполнения запроса необходимо опредлить, к какому пространству кортежей идёт обращение. На данном этапе все пространства и все объекты в Tarantool пронумерованы, доступ осуществляется по номеру объекта. Есть номер индекса, номер пространства и так далее. На следущем слайде мы видим, как после установления соединения осуществляется вставка кортежа, потом доступ к кортежу осуществляется по первичному ключу, данные же возвращаются, в случае PHP, в виде простого массива. Можно также по ключу обновить кортеж в нужном пространстве.

В случае выборки кортежей мы выбираем номер ключа, по которому делается запрос — либо это первичный ключ с номером 0, либо другие ключи.

Дав общий обзор функциональности, я бы хотел перейти к тому, чем мы отличаемся от других NoSQL систем, с которыми вы уже наверняка работали.
Начну с производительности. В целом, так как это хранилище данных в оперативной памяти, то производительность изначально существенно выше чем у традиционных СУБД, таких как, например, MySQL. Мы используем асинхронный ввод-вывод и асинхронную поддержку множества соединений. Мы легко держим 10000 активных соединений. Наша производительность на одной машине, несмотря на то, что мы пишем все изменения в write ahead log, т.е. логируем все изменения на диск, доходит до 100 000 UPDATE-ов и INSERT-ов в секунду. Для запросов на чтение на этой машине мы добивались производительности в 260 000 SELECT-ов в секунду. Это не такие уж и суперцифры: они сравнимы с производительностью Memcache или Redis.

А какой лейтенси? Сколько составляет задержка на ответ?
Вопрос очень хороший.
Бенчмарк, на который ссылается слайд, делался в 10 потоков и каждый поток посылал по 10 запросов за один раз. Бенчмарк был построен таким образом, что сторона клиента пакетно принимала несколько запросов и параллельно отправляла ответы. Как только сервер отправлял пакет, клиент это пакет вычитывал. Почему мы выбрали именно такую схему измерения производительности? Потому что у нас в распоряжении было всего две машины, тогда как для того, чтобы Tarantool нагрузить нужен все-таки кластер, сотня машин и более. При таком подходе к измерению производительности, latency, конечно, выше того, что можно наблюдать на реальной нагрузке. В действительности, время выполнения одного запроса запроса очень сильно зависит от того, модифицирует он данные или нет. У SELECT’а latency минимальная: сервер просто читает данные из памяти по ключу и отправляет клиенту, никаких локов нет.
Вообще говоря, Tarantool — lock-free система, доступ ко всем данным, на уровне структур данных и кэшей, осуществляется последовательно, тогда как на уровне сети, конечно же, поддерживается параллельная обработка множества соединений. Для реализации этого подхода мы используем так называемые coroutines, также известные как «лёгкие» или «зелёные» потоки.
Если же запрос меняет данные, то изменения необходимо запротоколировать на диске. Для реализации пакетной записи используется алгоритм, который в серьёзных СУБД часто называют «group commit», то есть одновременная запись на диск нескольких накопившихся изменений. Проще всего это представить как поезд, соединяющий две станции — frontend и backend. Все запросы, которые нужно запротоколировать на диск, скапливаются на «перроне» процесса, ответственного за работу с сетью (frontend). Затем все эти запросы «погружаются в поезд», то есть буферизуются и записываются на диск. Как только одна группа запросов записана на диск, «поезд» возвращается за следующей группой запросов. Таким образом, задержка при выполнении INSERT/UPDATE/DELETE запроса зависит от того, в какой момент вы оказались на «перроне». Максимум на современном оборудовании это 0.01 секунды, время записи произвольного блока на произвольный цилиндр жёсткого диска.
Какую файловую систему вы используете?
Мы используем любую файловую систему. Если у вас на этом конкретном, к примеру, Linux, работает ZFS — пожалуйста. В данном случае мы используем POSIX API для работы с файлами. Единственный не-POSIX вызов, который мы используем — это вызов fallocate(), который, по-моему, поддерживается на JFS, XFS и EXT4.
Зачем мы используем fallocate()? Это связано с тем, как устроена современная файловая система. Это нужно более подробно рассказать, давайте я позже это сделаю.
Более конкретный вопрос относительно клиентов — как мы получаем доступ одновременно 1000 GETов одного и того же ключа с одного места, с одного клиента. Можем ли мы это дело как-то проксировать? Не посылать 1000 запросов на…
Как устроен сам GET и можно ли это проксировать? У Tarantool есть протокол работы с клиентом. К примеру, в Memcache поддерживается текстовый и бинарный протокол. У нас сделано похожим образом. В основном используется бинарный протокол, в котором GET — это одна из команд. Код команды занимает 4 байта в заголовке пакета с запросом, весь заголовок занимает 12 байт. Вторые четыре байта заголовка содержат Request ID. Request ID — это средство для маркировки, уникальной идентификации конкретного запроса. В ответе на запрос сервер возвращает переданный ему request id. Это позволяет проксировать запросы достаточно просто, и в Mail.Ru Group это активно используется. Прокси принимает запросы с десятка, с сотни машин, направляет их в Tarantool, потом по request-id определяет с какой машины пришел запрос и отправляет ответ Tarantool’а на эту машину.
Как вы настраиваете ваш commit, чтобы не положить файловую систему?
Вы правы, мы боролись с этой проблемой довольно долго. Как часто лог файл синхронизируется с диском можно настроить в конфигурационном файле. У нас не совсем group commit, я бы более подробно рассказал об этом в конце. Наша рекомендация для параметра wal_fsync_delay — 0.01 секунды. При поиске наиболее оптимального значения самые большие палки в колеса ставит буфер файловой системы, которым управляет Linux. Эта проблема известна не только для Tarantool, но также и для MySQL. Если вы, например, почитаете про тюнинг буфера файловой системы на NUMA-архитектуре для нормальной работы MySQL, вы узнаете много интересного. Наша задача — упростить алгоритм операционныой системы по синхронизации этого буфера. Пэтому, в дата-центрах Mail.Ru мы ставим значение wal_fsync_delay в 0.01 секунды, то есть пропорционально скорости вращения диска.
Есть ли поддержка хранимых процедур в Tarantool?
Да, есть. Буду позже об этом подробно рассказывать.
Какая схема, чтобы подружить Tarantool с MySQL?
Это очень большой вопрос. Есть некий архитектурный паттерн, определяющий какие данные предпочтительно хранить в Tarantool, а какие в MySQL, который используется в Mail.Ru Group, я про него с удовольствием расскажу. В целом у нас нет репликации в MySQL, но данные из одной системы в другую перегнать достаточно просто.
Далее хочу вернуться к слайдам по производительности. Я хотел бы показать вам реальную картину производительности. Здесь мы видим два графика, это GETы, сотни тысяч запросов в секунду, здесь доходит до 700 тысяч запросов в секунду. По горизонтальной оси мы видим как изменяется производительность в зависимости от длины кортежа. Видно, что производительность сервера постепенно падает до сотни тысяч запросов.
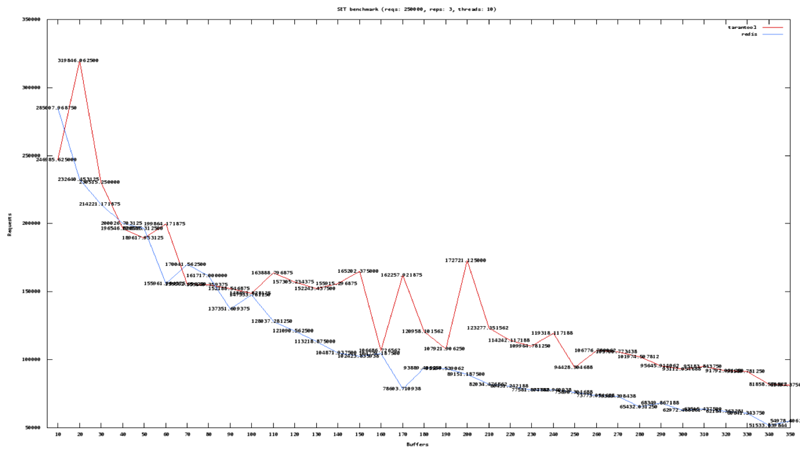
Для SET’ов можно наблюдать похожую картину. На этой, достаточно мощной машины (Intel Core I7, быстрый диск на 7200 оборотов в минуту), мы имеем 300 000 сетов и до 700 000 гетов.
На самом деле, у нас далеко не идеальная система дискового вывода. И график на следующем слайде демонстрирует наши новые патчи в версии 1.5 в сравнении с версией 1.4. Мы активно оптимизируем UPDATE’s. На этом бенчмарке мы измеряем производительность одного из патчей, который позволил удвоить производительность UPDATE’ов. Этот патч ещё не в мастере.
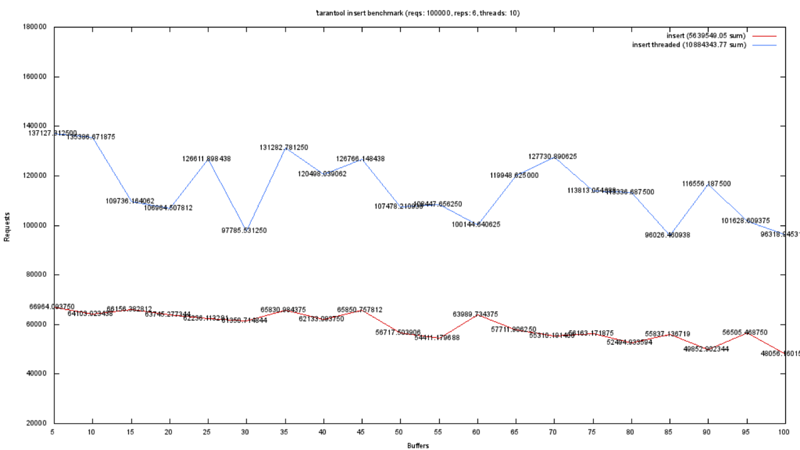
Таким образом, я надеюсь, я смог продемонстрировать, что производительность простых запросов достаточно высокая. Чтобы рассказать чем Tarantool отличается от других достаточно распространенных систем Key-Value, я бы хотел показать как использовать Trantool в более сложных сцецнариях, так как это наше уникальное преимущество.
Простейший такой сценарий это auto-increment. На PHP, если вы работаете с любой NoSQL СУБД или с Tarantool, есть более-мене стандартный способ реализовать авто-инкремент. Вы делаете UPDATE, который возвращает кортеж, и вы используете то, что вам вернул сервер в качестве нового значения счётчика. Таким образом, у вас обычно используются два пространства. В одном пространствве вы храните автои-нкремент, а в другое вы, собственно, вставляете ваши объекты. Добавление нового объекта осуществляется за два запроса к серверу.


Теперь давайте рассмотрим как это можно сделать с использованием хранимых процедур в Tarantool, в рамках одного запроса к серверу. Хранимая процедура со следующего слайда принимает номер пространства, в которое нужно сделать ставку, получает в этом пространстве максимум первичного ключа — т.е. используя хранимую процедуру мы обращаемся к объекту индекса в space 0. Получив максимум, мы вставили значение с номером на единицу больше. Все просто, причем все это работает атомарно — вот эта хранимая процедура гарантировано не будет прервана и выполнится достаточно быстро, так как здесь только одно обращение к серверу.

Но это самый простой паттерн, так сказать, для затравки. Давайте посмотрим, как на Tarantool сделать круговой буфер.
В хранимой процедуре на следующем слайде мы используем схему «один круговой буффер = один tuple (кортеж)». Т.к. у кортежа размерность произвольная, мы можем добавлять и удалять поля после его создания. Для хранения кругового буфера будем использовать следующую структуру кортежа: поле № 0 — идентификатор, поле № 1 — вершина буфера, т.е. самый новый элемент. В поле номер № 2 хранится индекс самого старого элемента, соответственно, вставка представляет из себя нахождение самого старого элемента, замена его, и обновление всех индексов. Получается, что у нас смещается индекс самого старого элемента и индекс самого нового элемента. Собственно, в этой хранимой процедуре мы это и делаем. Мы получаем номер top и bottom, формируем UPDATE запрос, в данном случае box.update() — это хранимая процедура, которая вызывает callback в сервере. Для того, чтобы в UPDATE указать, что именно нужно изменить, используется микроязык, похожий на printf(). Обновить три поля в тапле, например, записывается как =p=p=p, что означает ’=’ (присвоить) в поле с индексом 1 ’p’ (данные из переменной) top, ’=’ (присвоить) в поле с индексом 2 ’p’ (данные из переменной) bottom, и ’=’ (присвоить) в поле с индексом top данные из переменной val.

Такой символический способ формирования UPDATE, хотя и компактный, но, возможно, не самый легкий в восприятии вариант, мы также его сейчас меняем. Таким образом, у нас три присваивания полей в кортежи. Все эти присваивания выполняются атомарно.

Наиболее популярный вопрос, который мне задают и на который я все с большим трудом нахожу в себе силы отвечать, это почему мы используем в качестве языка хранимых процедур Lua. В Видимо, многим Lua изучать не хочется. Вот был бы Javascript…
Попробую ещё раз на этот вопрос ответить. Пожалуй, LuaJIT — это самый быстрый just-in-time compiler, который сейчас есть у open source сообщества. И именно это определило наш выбор — минимальные издержки на поддержку хранимых процедур. Язык Lua очень простой, достаточно интересный, поэтому я не думаю, что у кого-то возникнут проблемы с его изучением. Кроме того, на GitHub есть открытая библиотека хранимых процедур для Tarantool, которые часто можно просто взять и подправить под свои нужды.
По тому, что я рассказал, по круговым буферам, по авто-инкрементам — есть вопросы?
Вот здесь, по-моему, происходит какая-то блокировка. Потому что на первый взгляд, может быть гонка при параллельном обновлении, 2 запроса и 2 одинаковых max+1.
Спасибо, что внимательно смотрите. Я об этом говорил, попытаюсь проговорить еще раз. У Tarantool нет никаких локов. Что здесь реально происходит? Выполнение хранимой процедуры не прерывается обработкой запроса от другого клиента, пока не сформируется кортеж, содержащий информацию для обновления WALа. 1 экземпляр Tarantool использует 1 процессор. Внутри экземпляра, мы используем легковесные fiber’ы, легковесные coroutines для реализации многозадачности и асинхронный ввод-вывод для того, чтобы выполнение не прерывалось на ожидание ввода-вывода. Весь код сервера работает на одном процессоре в контексте одного процесса, одного потока; используется кооперативная многозадачность для обработки всех запросов, и результаты по производительности, которые я вам показывал, на порядок превосходящие multi-threaded системы, мы получаем используя всего один процессор. Каким образом мы масштабируемся? Вы ставите больше nodes, экземпляров Tarantool. Обычно на одну машину ставится
Что еще в целом у нас есть сложного и интересного? Расскажу на примере реалий Mail.Ru Group.
Часто возникает задача не только хранить какие-то данные, хранить сложные структуры данных, но и реализовывать интеллектуальную систему удаления устаревших данных. Легковесные потоки, о которых я упоминал ранее, можно создавать, убивать, приостанавливать из хранимых процедур. Т.е. вы можете написать свою хранимую процедуру, которая будет в фоновом режиме обходить одно из ваших пространств кортежей и удалять из него старые кортежи. Вы можете не только реализовать — хотя у нас есть поддержка Memcache, Memcache-протокола и Memcache expiry — устаревание кортежей, вы в целом можете написать полностью свою стратегию устаревания, если вы, как и я, любитель Lua. Примерно таким образом реализовано хранение сессий на Почте Mail.Ru. Для хранения сессий используется 4 машинки, на каждой машинке работает по 2 экземпляра Tarantool’а. 2 машинки выступают как реплики, 2 машинки работают в роли мастеров. На этих машинках мы храним те 60 или 100 миллионов активных сессий, которые открыты в Mail.Ru для пользователей.
Тут, опять же, нужно понимать, что если сравнивать Tarantool и реляционную систему, то Tarantool в целом более компактен, потому что он не требует нормализации данных, потому что данные оптимизированы для хранения в памяти, а не на диске. В результате, достаточно сложные структуры сохраняются в одном кортеже. Например, все атрибуты сессии, которых могут быть десятки и сотни, сохранятся в одном кортеже. В реляционной СУБД потребовалось бы на каждую пару ключ-значение заводить либо отдельную строку в таблице, либо создавать таблицу с 400 столбцами, многие из которых оказались бы пустыми. Это не только и не столько бесполезная трата места на диске, но и неоптимальное использование оперативной памяти для кэширования данных. В Tarantool на все сессии уходит около 120 Гигабайт на всех машинах, и это полезные данные, а не искусственные ключи или плата за нормализацию. Описанный кластер из двух машин, по 2 экземпляра сервера на каждой машине, в сумме обрабатывает около 60 тысяч запросов в секунду. Так как это production конфигурация, мы не доходим до значений в тестах производительности, ведь нам еще нужно гарантировать время ответа. Загрузка ЦПУ, того единственного ЦПУ который использует каждый экземпляр, не превышает 20%.
У нас есть проблема хранения сессий. Сейчас мы используем для этого MongoDB. В Mongo есть проблема, мы не можем восстановить данные на момент падения из журналов. Мы используем предыдущий бэкап, который у нас есть. Поэтому есть погрешности, потери и т.п.
А почему вы не можете с Mongo восстановить? Mongo — персистентная система, тоже c Write Ahead Log’ом, что конкретно не получается?
Вот, наверно мы еще не научились.
Я думаю научитесь, но с Tarantool у вас не будет такой проблемы. В Tarantool есть система создания snapshot’ов, похожая на бэкапы в других СУБД. Вы можете в любой момент, мы обычно это делаем раз в сутки, создавать компактную копию всех ваших данных. Для создания снапшота используется техника copy-on-write, похожий подход принят в Redis. Но наш главный инструмент для поддержки сохранности данных это Write Ahead Log. Если вы упали, то всегда есть возможность запуститься с использованием файлов Write Ahead Log’а. Хотя все зависит от вашей конфигурации, обычно теряются данные не более чем за 0.01 сек.
А вот например в MySQL есть бинлог, который можно просмотреть, просто журнал, что происходило. Есть ли в Tarantool бинлог?
Это очень интересный вопрос. Чем Tarantool, например, отличается от MуSQL? У MуSQL есть хранилище, в котором есть свой Write Ahead Log, и есть бинлог, т.е. MуSQL на каждый запрос пишет данные в два места. У Tarantool его Write Ahead Log — это его же бинлог. Наша репликация устроена очень просто: мы берем наш Write Ahead Log и посылаем его на реплику. Таким образом, да, вы можете посмотреть и увидеть, что произошло за последнее время. Каждая запись в Write Ahead Log имеет порядковый номер (log sequence number, LSN), соответственно, вы всегда можете посмотреть, насколько реплика отличается от мастера, просто сравнив текущий максимальный порядковый номер на реплике и на мастере.
Мы сейчас используем бинлог для выяснения таких ситуаций — например, человек говорит: месяц назад я написал здесь 5, почему у меня сейчас здесь 8. И, просмотрев бинлог за это время, мы можем точно сказать когда, кто, что там изменил. Здесь есть ли у вас тоже такая функция?
Да, вы можете хранить эту информацию. Просто бинлоги могут быть очень большими, поэтому мы также используем снапшоты. Как только вы взяли снапшот, все бинлоги записанные до момента взятия снапшота можно удалить.

Последний паттерн, о котором я хотел бы рассказать — это то, что мы сейчас внедряем в Моем Мире.
На слайде вы видите цифры, такие как 6, 83, 1, 21, 8 и т.д. Это так называемые уведомления: «Вашу фотографию оценили 44 пользователя, 83 человека хотели бы добавить ваз в друзья». Как устроена система уведомлений? С каждым пользователем ассоциируется некий тип уведомлений: фотки, уведомления о сообщении, friend-requests и т.д. Всего у нас сейчас таких типов 5. Для каждого типа уведомления мы поддерживаем кольцевой буфер последних уведомлений. Если вам прислали 30 friend-requests, мы в этом кольцевом буфере храним последние 20, т.к. длина кольцевого буфера равна 20. И так для каждого типа уведомления.
Для хранения кольцевых буферов используется Tarantool. То есть с каждым пользователем ассоциируется 5 буферов для каждого типа уведомления. Есть 2 базовые операции, первая — это «Добавить уведомление для пользователя». Tarantool проверяет, что для данного конкретного пользователя это уведомление еще не было добавлено. Все это мы храним в одной структуре данных, компактно, в одном пространстве, все кольцевые буферы для данного пользователя хранятся в одном кортеже данного пользователя. Вот скажите мне, какая SQL-система дает вам такую возможность? Я такой не знаю.
Вторая команда работы с кольцевыми буферами — «Прочитать уведомление». Допустим, пользователь зашел на свою страничку, нажал на кнопку уведомлений, прочитал их. Счётчик непрочитанных обновлений должен быть обнулён.
Вся логика по добавлению, чтению и подсчёту непрочитанных уведомлений выполняется на сервере.
Процедура notification_push() автоматически проверяет уникальность уведомления. Она принимает три параметра — user_id, тип уведомления и собственно идентификатор уведомления. Идентификатор уведомления может вполне быть первичным ключом к объекту уведомления в MySQL, то есть вам уже не нужно на топовую страницу выводить сам текст уведомления, вы можете хранить его в MySQL, разгрузив тем самым вашу основную СУБД от множества мелких запросов.
При чтении уведомлений возвращается список notification id из кольцевого буфера и обнуляются счетчики непрочитанных уведомлений. На следующем слайде вы видите пример описанной хранимой процедуры.
Код процедур для работы с уведомлениями также доступен на GitHub.
Давайте подробнее рассмотрим как работает notification_push(). Для добавления уведомления мы вычисляем новое значение unread count, создаем команду для UPDATE кольцевого буфера и выполняем эту команду. Добавление уведомления выполняется атомарно.

В заключение я бы хотел немного рассказать о масштабировании. На данном этапе, Tarantool — это, надеемся, качественная реализация одного узла в кластере. Мы очень активно смотрим в сторону масштабирования, и с точки зрения поддерживания мастер и мастер-репликации, синхронной репликации, консистентного хеширования, но хочу сказать, что схем масштабирования существует бесконечное множество. Мы в целом не собираемся реализовывать одну из них и объяснять всему миру, что это самая правильная, что мы выбрали две самые важные буквы в CAP-теореме.

Tarantool, в первую очередь, будет хорошим бэкэндом для Voldemort, для Riak, мы будем писать свои системы для масштабирования, это уже есть в ближайших планах. Предупреждая ваши вопросы о том, как мы работаем на 100 машинах — вы видите, что на Mail.Ru, в таком большом проекте, сейчас используется по 4, по 6 машин, т.е. проблема не самая острая. Мы движемся в эту сторону, но единой системы масштабирования не будет.
Наши планы, в первую очередь, это автоматизация управления кластером экземпляров сервера, поддержка трансакций, мастер-мастер-репликация, тригеры на репликацию. У нас огромное количество планов: пробуйте продукт и скажите нам как их поменять. Спасибо.

Данный текст является стенограммой доклада Осипова Константина на Форуме технологий Mail.Ru 2011, проходившем 16 ноября в центре Инфопространство. Подробности о технологии создания текстов докладов по видеозаписям см. здесь: «Изнанка» Форума технологий Mail.Ru: Хай-тек в event-management. Видеоверсии прочих докладов (включая версии для мобильных устройств) доступны на сайте Форума — techforum.mail.ru. Текстовые варианты докладов будут публиковаться здесь и на сайте Форума каждую неделю или немного пореже в похожем формате. Пожалуйста, сообщайте в «личку» об опечатках в тексте.
