
Доклад Андрея Сумина (хабрапрофиль) «Как не утонуть в мегабайтах JS-кода?» — очередной в серии расшифровок с Форума Технологий Mail.Ru 2011. Подробности о том, как работает система расшифровки докладов — см. в статье «Изнанка» Форума технологий Mail.Ru: Хай-тек в event-management. Там же, а также на сайте Форума (http://techforum.mail.ru) — ссылки на расшифровки других докладов.
(Скачать видеоверсию для мобильных устройств — iOS/Android H.264 480?368, размер 170 Mb, видеобитрейт 500 кбит/с, аудио — 64 кбит/с )
(Скачать видеоверсию большего разрешения H.264 624?480, размер 610 Mb, видеобитрейт 1500 кбит/с, аудио — 128 кбит)
(Скачать слайды презентации, 4.7Мб)
 Скажу сразу, в этом посте не будет даже упоминаний про последние, внедренные браузерами «фишки». Более того, первый раз эту тему я освещал в 2007 году. Я расскажу про некоторые приемы организации кода, которые вот уже 5 лет помогают мне и моим коллегам успешно разрабатывать проекты с большим количеством JS-кода.
Скажу сразу, в этом посте не будет даже упоминаний про последние, внедренные браузерами «фишки». Более того, первый раз эту тему я освещал в 2007 году. Я расскажу про некоторые приемы организации кода, которые вот уже 5 лет помогают мне и моим коллегам успешно разрабатывать проекты с большим количеством JS-кода.Давайте вернемся немного назад, примерно в 2002 год. Сайты тогда содержали мало JS-кода. По большей части, на Javascript делали небольшие «рюшечки», вроде смены фона по наведению мышкой. Структура проекта была проста и прозрачна.

С 2005 года мы видим стремительное развитие, и уже тогда в Рунете появляются вакансии с заголовком «javascript-программист». Проекты тоже стали немного сложнее.

Я common.js выделил не потому, что он такой важный, а потому, что он стал большим и неуправляемым. Если бы работал не один человек, а команда, каждый бы туда дописывал что-то свое, в конец файла. Поддержка проекта, конечно, усложнилась.

В итоге мы имеем путаницу, огромный файл и, самое страшное, на мой взгляд — нет code reuse.
Конкретно у меня было так: какие-то функции по эскейпингу строк, например, html, никто еще тогда не умел этого делать. Ты приходишь на проект или берешь проект другого человека, видишь функцию эскейпинга, пытаешься ее применить, она не работает. Либо баги, либо не то эскейпит все, что надо, либо лишнее эскейпит. Все заканчивалось тем (про тесты уж точно никто не знал), что я очень боялся поменять эту функцию, и просто рядом писал еще одну. Через какое-то время, думал, ну вот везде, где вспомнил, поменял на свою, и она точно лучше, быстрее, в ней нет багов, и, вроде бы, старую можно удалить. Но в последний момент рука дрогнет, ладно оставлю. Так и лежит этот код для следующих поколений.

Следующие шаги были очевидны: люди стали просто делить один большой файл по каким-то логическим частям. И хорошо, если по логическим — обычно выходило «как получится».

И будем откровенными — проблемы это, на самом деле, не решило. Размер остался, только раньше это был один файл, а теперь это папка. У нас появились новые проблемы — проблемы с подключением. Если мы бьем на несколько файлов, естественно, мы хотим, чтобы на страницах, где нужна какая-нибудь часть файлов, мы подключали только эту часть файлов. Эту проблему надо было как-то решать. И проблему с сопровождением подключения, потому что по факту получалось так: на всех страницах подключали все скрипты.
Следующий слайд очень важен и отражает самую главную мысль моего доклада.

Идея следующая. Да, у нас много JavaScript, да он как-то разбит, да нам надо подключать часть его на страницах по каким-то правилам. Пусть результирующий HTML, который получился в результате отработки всей нашей логики, и будет конфигом того, что нужно подключить.
Поясню. У нас есть тег div, включающий какой-нибудь законченный блок — допустим, это будет список папок, т. е. в этом диве лежит список папок. Первый шаг, мы помечаем с помощью класса — этот див является компонентом. Это означает, что js-движок будет искать его по этой отметке. Вторая строчка — onclick, там указан return, и какой-то хеш. В этом хеше находится описание того, что это за компонент.
В результате нам надо найти компонент в DOM-дереве. Определить, что это за компонент (в моем случае информация о типе находится в onclick). Подключить js-файлы, чтобы все это заработало.
Первая задача решается, по крайней мере в современных браузерах, очень легко. CSS-селекторы работают много где нативно, а там, где не нативно, у вас есть в распоряжении соответствующие библиотеки.
Теперь самая интересная часть, то что записано в onclick. Там можно зашить любую информацию, которая вам нужна для инициализации. В моем случае это тип компонента, по содержимому хеша я понимаю, что это компонент по работе с папками. Достать его очень легко.

Таким образом, мы получаем сразу хеш с входными данными для компонента.

Require — эта та самая функция — то сердце, которое заставит работать всю нашу схему. Естественно, она на каком-то продакшн решении сильно сложнее, но идеи это не меняет.

Вот этот require записан в какой-то библиотеке, в каком-то компоненте, т.е., в каком-то javaScript-файле, который отвечает за функционал. Javascript-файл с ее помощью говорит ядру, что для моей работы нужен file1 и file2. Это передается первым аргументом, а вторым аргументом ядро вызывает функцию которая выполнится после того, как оно загрузит обе либы.
Очень важный момент. В function написано loaded(file). Естественно, идея уже давно не нова, естественно, есть реализации, помимо той, которую я описываю. Но в некоторых реализациях есть одно отличие, они пытаются понять, что функционал загружен по каким-то метаданным. Допустим, срабатывание события onload у script или чего-либо подобного. Я принципиально не стал этого делать: тот код, который находится в javascript, вызвав метод loaded, сам точно скажет, что я готов. И не потому, что там что-то загрузилось, не потому, что кто-то думает, что я загрузился. Да, я загрузился, я точно получил то, что мне нужно, я точно готов. Если я по цепочке вызову, кому я нужен дальше, то об этом можно смело сказать и ничего не бояться.

Вот как это выглядит на небольшой связке. Папкам нужны библиотеки по работе с датами.
В библиотеке по работе с датами нужны строки, чтобы красиво выводить, например, какая-нибудь реализация printf есть в strings. А strings самодостаточны, им ничего не нужно. И у нас получается цепочка require. В folders.js мы просим dates, по мере загрузки dates у нас вызывается функция, в которой сами folders говорят ядру, что у меня dates есть, ничего не надо, я готова к работе. У дат тоже самое со strings. А strings ничего не нужно, когда они загрузились, они говорят в конце — все, мы загрузились, давай работать дальше.
Мы рассмотрели полный набор задач для того, чтобы наш пример заработал.

Первым делом из DOM-дерева мы вычленяем все компоненты, которые нужны. Вторым этапом определяем, что это за компонент, в хеше у нас это будет компонент по работе, давайте скажем, что это компонент по работе со списком писем. Дальше функция require, вот там есть первым аргументом getFileName(type). По строке ядро может понять настоящий путь к файлу, чтобы прописать тегу script в src. Соответственно, в нашем случае вот это будет folders.js. Script folders загрузится. Он скажет в require, что мне нужны dates, dates скажут, что мне нужны strings. Сгенерируются 3 тега script, в обратном порядке сработают loaded и в результате у нас функция, в которой написано — window[type].init(), выполнится и компонент начнет инициализироваться.
Но отдыхать еще рано, мы получили еще одну проблему. У нас есть загрузка компонентов довольно изолированных, и представим такую ситуацию — вроде бы все хорошо. К разработчику приходит менеджер и говорит: «я хочу, чтобы ты сделал календарь».
Разработчик говорит, вот будет у меня отдельный div, будет у меня отдельный файл. У меня есть библиотека по работе со строками, которая покрыта тестами с датами, дата, которая покрыта тестами, и я за 2 дня делаю календарь. Показывает менеджеру, он счастлив, показывает коллегам в других проектах. Они приходят опять к вам.
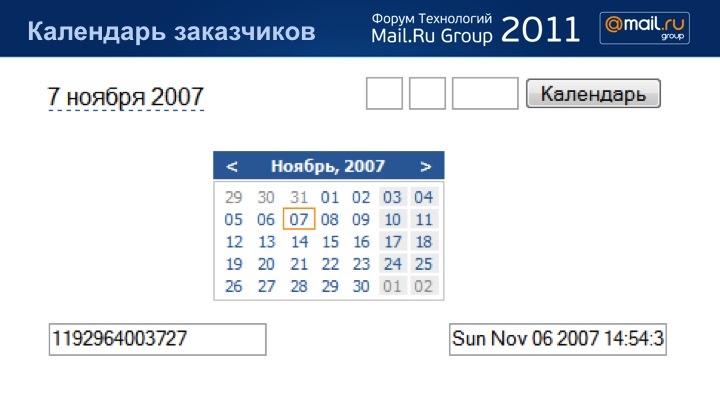
Вроде бы, тот же самый календарь, но вот количество интерфейсов, которые хотят разные люди к этой вашей прекрасной вылизанной штуке, слегка удручает.

Дальше у вас вот какие варианты: можно заниматься очень долгим проектированием, делать абстракции, делать абстракции над абстракциями, но поверьте мне, когда через три месяца, а если вы блестящий программист, то через полгода, на ваше место придет другой программист работать, он удивится.

Все мы люди, все мы понимаем, что всё учесть невозможно, поэтому есть не новый паттерн, очень давно используется в программировании. Более того, с самого начала, с появления JavaScript’а, который вовсю используется в браузерах, – это события. Вы делаете календарь, делаете его системным, делаете его неприкосновенным, но делаете к нему событийное API.

Это очень легко масштабируется, это очень легко покрывается тестами, и программисту, который пришел записать свою штучку, очень легко и не трогать ваш код.
Казалось бы все, теперь уже точно все замечательно. У нас есть конфиг в html, у нас есть загрузка компонентов, по запросам, по тому html который есть. У нас есть интерфейс для общения компонентов друг с другом. Но возникла еще одна проблема.
Если вы знаете сегодня, то завтра вы точно не знаете порядок инициализации компонентов. Представьте себе такую ситуацию: встретился календарь. Он начал загружаться, загрузился, проинициализировался. После инициализации кинул событие, что я сейчас на дате выставлю 7 ноября. Все он это уже сделал, только после этого по DOM встречается маленький компонент, который должен написать 7 ноября. Он вешается на событие, а событие уже произошло. Его уже нет.
Решение оказалось из раздела серверного программирования, мне его подсказали. Оно существует очень давно и называется — очереди.

Мы к методу dispatch добавляемеще один аргумент, я выделил его красным,. Это размер очереди. Календарь при своей инициализации делает dispatch, раз уж у нас есть объект callback. Он ему говорит, что размер очереди таких событий один, т.е. если кто-то подписывается на подобное событие и еще ничего не получал, то по стеку first in first out он получит события. Длина очереди будет равна как раз размеру цифры, указанной на последнем аргументе. И он, соответственно, все эти события получает.
Что касается mail.ru, я тут не год работаю, а всего лишь 4 месяца, я думал, что я сейчас приду с длинным плащом, и всем тут покажу, как надо жить. И в первый же день, когда увидел исходники JavaScript mail.ru понял, что они написали практически то же самое. Местами даже до букв.

Данный текст основан на докладе Сумина Андрея на Форуме технологий Mail.Ru 2011, проходившем 16 ноября в центре Инфопространство. Подробности о технологии создания текстов докладов по видеозаписям см. здесь: «Изнанка» Форума технологий Mail.Ru: Хай-тек в event-management. Видеоверсии прочих докладов (включая версии для мобильных устройств) доступны на сайте Форума — techforum.mail.ru. Текстовые варианты докладов будут публиковаться здесь и на сайте Форума каждую неделю или немного пореже в похожем формате. Пожалуйста, сообщайте в «личку» об опечатках в тексте.
