
Обзор архитектур подготовки данных больших поисковых систем
В прошлый раз мы с вами вспомнили, как стартовал в 2010 году Go.Mail.Ru, и каким Поиск был до этого. В этом посте мы попробуем нарисовать общую картину — остановимся на том, как работают другие, но сначала расскажем о поисковой дистрибуции.
Как распространяются поисковые системы
Как вы и просили, мы решили подробнее остановиться на основах дистрибуционных стратегий самых популярных поисковых систем.
Бытует мнение, что интернет-поиск – один из тех сервисов, которые большинство пользователей выбирает самостоятельно, и победить в этой битве должен сильнейший. Эта позиция нам крайне симпатична – именно ради этого мы постоянно совершенствуем наши поисковые технологии. Но ситуация на рынке вносит свои корректировки, и в первую очередь сюда вмешиваются так называемые «браузерные войны».
Было время, когда поиск не был связан с браузером. Тогда поисковая система была просто очередным сайтом, на который пользователь заходил по своему усмотрению. Представьте себе —Internet Explorer до 7-й версии, появившейся в 2006-м году, не имел строки поиска; Firefox имел строку поиска с первой версии, но сам он при этом появился только в 2004-м году.
Откуда же взялась строка поиска? Придумали её не авторы браузеров — впервые она появилась в составе Google Toolbar, вышедшего в 2001-м году. Google Toolbar добавлял в браузер функциональность «быстрого доступа к поиску Google» – а именно, поисковую строчку в свою панель:
Зачем Google выпустил свой тулбар? Вот как описывает его предназначение Дуглас Эдвардс, бренд-менеджер Гугла в тот момент, в своей книге «I'm Feeling Lucky: The Confessions of Google Employee Number 59»:
«The Toolbar was a secret weapon in our war against Microsoft. By embedding the Toolbar in the browser, Google opened another front in the battle for unfiltered access to users. Bill Gates wanted complete control over the PC experience, and rumors abounded that the next version of Windows would incorporate a search box right on the desktop. We needed to make sure Google's search box didn't become an obsolete relic».
«Toolbar был секретным оружием в войне против Microsoft. Интегрировав Toolbar в браузер, Google открыл очередной фронт в битве за прямой доступ к пользователям. Биллу Гейтсу хотелось полностью контролировать то, как пользователи взаимодействуют с ПК: множились слухи, что в следующей версии Windows строка поиска будет устанавливаться прямо на рабочий стол. Необходимо было принять меры, чтобы строка поиска Google не стала пережитком прошлого».
Как распространялся тулбар? Да всё так же, вместе с популярным программным обеспечением: RealPlayer, Adobe Macromedia Shockwave Player и т.п.
Понятно, что другие поисковики начали распространять свои тулбары (Yahoo Toolbar, например), а производители браузеров не преминули воспользоваться этой возможностью получения дополнительного источника доходов от поисковых систем и встроили поисковую строчку к себе, введя понятие «поисковик по умолчанию».
Бизнес-департаменты производителей браузеров выбрали очевидную стратегию: браузер — точка входа пользователя в интернет, настройки поиска по умолчанию с высокой вероятностью будут использоваться аудиторий браузера — так почему бы не продать эти настройки? И они были по-своему правы, ведь интернет-поиск — это продукт с практически нулевой «приклеиваемостью».
На этом пункте стоит остановиться подробнее. Многие возмутятся: «нет, человек привыкает к поиску и пользуется только той системой, которой доверяет», но практика доказывает обратное. Если, скажем, ваш почтовый ящик или аккаунт соц. сети по какой-то причине недоступен, вы не переходите тут же в другой почтовый сервис или другую социальную сеть, ведь вы «приклеены» к своим аккаунтам: их знают ваши друзья, коллеги, семья. Смена аккаунта — долгий и болезненный процесс. С поисковиками же всё совсем иначе: пользователь не привязан к той или иной системе. Если поисковик по каким-то причинам недоступен, пользователи не сидят и не ждут, когда он, наконец, заработает — они просто идут в другие системы (например, мы отчётливо видели это по счётчикам LiveInternet год назад, во время сбоев у одного из наших конкурентов). При этом пользователи не сильно страдают от аварии, ведь все поисковики устроены примерно одинаково (поисковая строка, запрос, страница результатов) и даже неопытный юзер не растеряется при работе с любым из них. Более того, примерно в 90% случаев пользователь получит ответ на свой вопрос, в какой бы системе он его ни искал.
Итак, поиск, с одной стороны имеет практически нулевую «приклеиваемость» (в английском языке есть специальный термин «stickiness»). С другой — какой-то поиск уже предустановлен в браузер по умолчанию, и довольно большое количество людей будет использовать его только по той причине, что им удобно пользоваться именно оттуда. И если поиск, стоящий за поисковой строчкой, удовлетворяет задачам пользователя, то он может продолжить его использовать.
К чему мы приходим? У ведущих поисковых систем не осталось другого выхода, кроме как бороться за поисковые строки браузеров, распространяя свои десктопные поисковые продукты — тулбары, которые в процессе инсталляции меняют дефолтный поиск в барузере пользователя. Зачинщиком этой борьбы был Google, остальным пришлось защищаться. Можно, к примеру, прочитать такие слова Аркадия Воложа, создателя и владельца Яндекса, в его интервью:
«Когда в 2006–2007гг. доля Google на российском поисковом рынке стала расти, мы сначала не могли понять, из-за чего. Потом стало очевидно, что Google продвигает себя путем встраивания в браузеры (Opera, Firefox). А с выходом собственного браузера и мобильной операционной системы Google вообще стал разрушать соответствующие рынки».
Так как Mail.Ru – это ещё и поиск, то он не может стоять в стороне от «браузерных войн». Мы просто вышли на рынок немного позже других. Сейчас качество нашего Поиска заметно выросло, и наша дистрибуция является реакцией на ту самую борьбу тулбаров, которая ведётся на рынке. При этом для нас действительно важно, что всё большее количество людей, которые пробуют пользоваться нашим Поиском, остаются довольны результатами.
К слову, наша дистрибуционная политика в несколько раз менее активна, чем у ближайшего конкурента. Мы видим это по счётчику top.mail.ru, который установлен на большей части сайтов рунета. Если пользователь переходит на сайт по запросу через один из дистрибуционных продуктов (тулбар, собственный браузер, сёрчбокс браузера-партнёра), в URL присутствует параметр clid=… Таким образом, мы можем оценить ёмкость дистрибуционных запросов: у конкурента она почти в 4 раза больше, чем у нас.
Но давайте от дистрибуции перейдем к тому, как устроены другие поисковые системы. Ведь внутренние обсуждения архитектуры мы, естественно, начинали с изучения архитектурных решений других поисковиков. Я не буду подробно описывать их архитектуры — вместо этого я дам ссылки на открытые материалы и выделю те особенности их решений, которые мне кажутся важными.
Подготовка данных в крупных поисковых системах
Рамблер
Поисковая система Рамблер, ныне закрытая, обладала рядом интересных архитектурных идей. Например, было известно об их собственной системе хранения данных (NoSQL, как сейчас модно называть подобные системы) и распределённых вычислений HICS (или HCS), использовавшейся, в частности, для вычислений на графе ссылок. Так же HICS позволял стандартизировать представление данных внутри поиска единым универсальным форматом.
Архитектура Рамблера довольно сильно отличалась от нашей в организации спайдера. У нас спайдер был выполнен как отдельный сервер, со своей, самописной, базой адресов скачанных страниц. Для выкачки каждого сайта запускался отдельный процесс, который одновременно качал страницы, парсил их, выделял новые ссылки и мог сразу же по ним пойти. Спайдер Рамблера был сделан значительно проще.
На одном сервере был расположен большой текстовый файл со всеми известными Рамблеру адресами документов, по одному на строку, отсортированный в лексикографическом порядке. Раз в сутки этот файл обходился и генерировались другие текстовые файлы-задания на выкачку, которые выполнялись специальными программами, умеющими только скачивать документы по списку адресов. Затем документы парсились, извлекались ссылки и клались рядом с этим большим файлом-списком всех известных документов, сортировались, после чего списки сливались в новый большой файл, и цикл повторялся снова.
Достоинства такого подхода были в простоте, наличии единого реестра всех известных документов. Недостатки заключались в невозможности пройти по свежеизвлечённым адресам документов сразу же, так как скачивание новых документов могло случиться только на следующей итерации спайдера. Кроме того, размер базы и скорость её обработки была ограничена одним сервером.
Наш же спайдер, наоборот, мог быстро пройти по всем новым ссылкам с сайта, но очень плохо управлялся снаружи. В него было тяжело «влить» дополнительные данные к адресам (необходимые для ранжирования документов внутри сайта, определяющие приоритетность выкачки), трудно было сделать дамп базы.
Яндекс
О внутреннем устройстве поиска Яндекса было известно не так много до тех пор, пока Ден Расковалов не рассказал о нём в своём курсе лекций.
Оттуда можно узнать, что поиск Яндекса состоит из двух разных кластеров:
- пакетной обработки данных
- обработки данных в реальном времени (это не совсем уж «реальное время» в том смысле, в котором этот термин используется в системах управления, где просрочка времени выполнения задач может быть критичной. Скорее, это возможность попадания документа в индекс максимально быстро и независимо от других документов или задач; этакий «мягкий» вариант реального времени)
Первый используется для штатной обкачки интернета, второй – для доставки в индекс самых лучших и интересных документов, появившихся только что. Будем рассматривать пока что только пакетную обработку, потому что до обновления индекса в реальном времени нам тогда было довольно далеко, мы хотели выйти на обновление индекса раз в один-два дня.
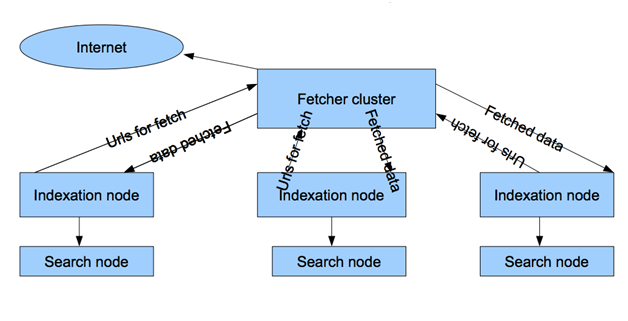
При этом, несмотря на то, что внешне кластер пакетной обработки данных Яндекса был в чём-то похож на нашу пару качающих и индексирующих кластеров, в нём было и несколько серьёзных отличий:
- База адресов страниц одна, хранится на индексирующих узлах. Как следствие, нет проблем с синхронизацией двух баз.
- Управление логикой выкачки перенесено на индексирующие узлы, т.е. узлы спайдера очень простые, качают то, что им указывают индексаторы. У нас спайдер сам определял, что ему и когда скачать.
- И, очень важное отличие, — внутри все данные представлены в виде реляционных таблиц документов, сайтов, ссылок. У нас же все данные были разнесены по разным хостам, хранились в разных форматах. Табличное представление данных значительно упрощает доступ к ним, позволяет делать различные выборки и получать самую разнообразную аналитику индекса. Всего этого мы были лишены, и на тот момент только лишь синхронизация двух наших баз документов (спайдера и индексатора) занимала неделю, причём нам приходилось останавливать на это время оба кластера.
Google, без сомнений, является мировым технологическим лидером, поэтому на него всегда обращают внимание, анализируют что он сделал, когда и зачем. А архитектура поиска Google, естественно, была для нас самой интересной. К сожалению, свои архитектурные особенности Google открывает редко, каждая статья – большое событие и практически моментально порождает параллельный OpenSource-проект (иногда и не один) реализующий описываемые технологии.
Тем, кому интересны особенности поиска Google, можно с уверенностью посоветовать изучить практически все презентации и выступления одного из самых главных специалистов в компании по внутренней инфраструктуре — Джеффри Дина (Jeffrey Dean), например:
- «Challenges in Building Large-Scale Information Retrieval Systems» (слайды) благодаря которым можно узнать, как развивался Google, начиная с самой первой версии, которая ещё была сделана студентами и аспирантами Стэнфордского университета и до 2008-го года, до внедрения Universal Search. Есть видеозапись этого выступления и аналогичное выступление в Стэндфорде, «Building Software Systems At Google and Lessons Learned»
- «MapReduce: Simplified Data Processing on Large Clusters». В статье описывается вычислительная модель, позволяющая легко распараллелить вычисления на большом количестве серверов. Сразу же после этой публикации появилась опенсорсная платформа Hadoop.
- «BigTable: A Distributed Structured Storage System», рассказ о NoSQL-базе данных BigTable, по мотивам которой были сделаны HBase и Cassandra (видео можно найти тут, слайды — здесь)
- «MapReduce, BigTable, and Other Distributed System Abstractions for Handling Large Datasets» — описание cамых известных технологий Google.
Основываясь на этих выступлениях, можно выделить следуюшие особенности архитектуры поиска Google:
- Табличная структура для подготовки данных. Вся база поиска хранится в огромной таблице, где ключом является адрес документа, а метаинформация сохраняется в отдельных колонках, объединённых в семейства. Причём таблица изначально сделана таким образом, чтобы эффективно работать с разреженными данными( т.е. когда значения в колонках есть далеко не у всех документов).
- Единая система распределённых вычислений MapReduce. Подготовка данных (включая создание поискового индекса) является последовательностью mapreduce-задач, выполняемых над таблицами BigTable или файлами в распределённой файловой системе GFS.
Всё это выглядит довольно разумно: все известные адреса документов сохраняются в одной большой таблице, по ней выполняется их приоритезация, вычисления над ссылочным графом и т.п., в неё приносит содержимое выкачанных страниц паук поиска, по ней в итоге строится индекс.
Есть ещё одно интересное выступление уже другого специалиста Google, Дэниела Пенга (Daniel Peng) про новшества в BigTable, позволившие реализовать быстрое, в течение нескольких минут, добавление новых документов в индекс. Эта технология «снаружи» Google была разрекламирована под названием Caffeine, а в публикациях получила название Percolator. Видео выступления на OSDI’2010 можно посмотреть здесь.
Если говорить очень грубо, то это тот же самый BigTable, но в котором реализованы т.н. триггеры, — возможность загрузить свои кусочки кода, которые срабатывают на изменения внутри таблицы. Если до сих пор я описывал пакетную обработку данных, т.е. когда данные по возможности объединяются и обрабатываются вместе, то реализация того же на триггерах получается совершенно иной. Допустим, спайдер что-то скачал, поместил в таблицу новое содержимое; сработал триггер, сигнализирующий «появился новый контент, его нужно проиндексировать». Немедленно запустился процесс индексации. Получается, что все задачи поисковика в итоге могут быть разбиты на подзадачи, каждая из которых запускается по своему щелчку. Имея большое количество техники, ресурсов и отлаженный код, можно решать задачу добавления новых документов быстро, буквально за минуту — что и продемонстрировал Google.
Отличие архитектуры Google от архитектуры Яндекса, где тоже была указана система обновления индекса в режиме реального времени, в том, что в Google, как утверждается, вся процедура построения индекса выполнена на триггерах, а у Яндекса она есть только для небольшого подмножества самых лучших, самых ценных документов.
Lucene
Стоит упомянуть и ещё об одном поисковике – Lucene. Это свободно распространяемый поисковик, написанный на Java. В некотором смысле, Lucene является платформой для создания поисковиков, например, от него отпочковался поисковик по вебу под названием Nutch. По сути, Lucene — это поисковое ядро для создания индекса и поискового движка, а Nutch — это то же самое плюс спайдер, который обкачивает страницы, потому что поисковик не обязательно ищет по документам, которые находится в вебе.
На самом деле, в самом Lucene реализовано не так много интересных решений, которые могла бы позаимствовать большая поисковая система по вебу, рассчитанная на миллиарды документов. С другой стороны, не стоит забывать, что именно разработчики Lucene запустили проекты Hadoop и HBase (каждый раз, когда появлялась новая интересная статья от Google, авторы Lucene пытались применить озвученные решения у себя. Так, например, возник HВase, который является клоном BigTable). Однако эти проекты давно уже существуют сами по себе.
Для меня в Lucene/Nutch было интересно то, как они использовали Hadoop. Например, в Nutch для обкачки веба был написан специальный спайдер, выполненный целиком в виде задач для Hadoop. Т.е. весь спайдер – это просто процессы, которые запускаются в Hadoop в парадигме MapReduce. Это довольно необычное решение, выбивающееся за рамки того, как Hadoop используется. Ведь это платформа для обработки больших объёмов данных, а это предполагает, что данные уже имеются. А здесь эта задача ничего не вычисляет или обрабатывает, а, наоборот, скачивает.
С одной стороны, такое решение подкупает своей простотой. Ведь спайдеру необходимо получить все адреса одного сайта для обкачки, обходить их друг за другом, сам спайдер тоже должен быть распределённым и запускаться на нескольких серверах. Вот мы и делаем мэппер в виде разделителя адресов по сайтам, а каждый индивидуальный процесс выкачки реализуем в виде редьюсера.
С другой стороны, это довольно смелое решение, потому что сайты обкачивать тяжело — не каждый сайт отвечает за гарантированное время, и вычислительные ресурсы кластера тратятся на то, чтобы он просто ждал ответа от чужого веб-сервера. Причём проблема «медленных» сайтов всегда есть при наличии достаточно большого количества адресов на выкачку. Спайдер за 20% времени обкачивает 80% документов с быстрых сайтов, потом тратит 80% времени в попытках обкачать медленные сайты – и практически никогда не может их обкачать целиком, всегда приходится что-то бросать и оставлять «на следующий раз».
Мы некоторое время анализировали такое решение, и в результате отказались от него. Пожалуй, для нас архитектура этого спайдера была интересна как, своего рода, «отрицательный пример».
Подробнее о структуре нашего поисковика, о том, как мы строили поисковую систему, я расскажу в следующем посте.
