
Исторически в Почте Mail.Ru использовался механизм от «большого» Поиска (go.mail.ru); однако для задач поиска по почтовым ящикам такой вариант не был оптимальным ввиду большого потребления ресурсов и относительной сложности в обслуживании. Поиском по почте пользуются около 3% владельцев почтовых ящиков; однако, хотя эта цифра кажется относительно небольшой, ящики этих людей обычно достаточно объемны, и поиск им действительно необходим. Поэтому мы приняли решение написать специализированный поисковый демон, который будет заниматься именно поиском по почте. Основными требованиями к нему стали ограничения по потребляемым ресурсам (размер индекса — не более 3% от размера почтового ящика, среднее потребление оперативной памяти — не более 100 Мб, средняя утилизация CPU — не более 3%) и скорости исполнения запросов (среднее время — не более 200 мс). О том, как он был организован, я расскажу ниже.
Два основных процесса, выполняемых в рамках решения задачи поиска по почте, это индексация ящиков и исполнение поисковых запросов. В момент получения нового письма необходимо пополнить поисковый индекс, внеся в него это письмо. Очевидно, что данные в индексе должны быть упорядочены и максимально компактны; однако в таком случае наиболее вероятно, что потребуется вставка в середину файла, которая породит собой весьма «тяжелую» запись на диск. Учитывая, что приход нового письма происходит во много раз чаще, чем исполнение какого-либо поискового запроса, использование такой тяжелой операции для поддержания поискового индекса в актуальном состоянии сомнительно.
Мы приняли решение сделать индекс из двух файлов: snapshot, который содержит полнотекстовый индекс (отсортированные данные), и xlog, содержащий список последовательных транзакций, примененных к индексу. Любая операция над индексом (например, получение нового письма) вызывает одну запись на диск — это запись в конец файла xlog. В момент исполнения поискового запроса по факту происходит две операции поиска — бинарный поиск по snapshot и последовательный поиск по xlog — результаты которых объединяются. В тот момент, когда скорость поиска по xlog перестает нас удовлетворять, мы выполняем перестроение snapshot — вносим в него все изменения из xlog, а xlog начинаем копить заново. Данный момент определяется автоматически по одной из двух возможных политик: когда время исполнения очередного запроса превысит установленный порог, либо когда установленный порог будет превышен размером файла xlog.
Индексация нового письма начинается с токенизации. Токенизация — это разбиение письма на отдельные слова (полнотекстовый поиск работает с точностью до целого слова и не способен искать по произвольной подстроке). Стоит заметить, что токенизация является не самой тривиальной задачей. Возьмем, например, email-адрес
d.kalugin-balashov@corp.mail.ru
Очевидно, он является целым словом. Разумно сделать возможным поиск также и по слову d.kalugin (изучение поисковых запросов пользователей показало, что они часто пытаются искать по «части email»). Однако поддерживать все подстроки данного слова нельзя, так как это приведет к резкому росту размера индекса, и, как следствие, потере скорости исполнения запросов. Весьма разумно разбивать слово на подстроки только по знакам препинания. Соответственно, мы получаем следующие подслова:
d.kalugin-balashov@corp.mail.ru
d.kalugin-balashov@corp.mail
d.kalugin-balashov@corp
d.kalugin-balashov
d.kalugin
d
kalugin-balashov@corp.mail.ru
kalugin-balashov@corp.mail
kalugin-balashov@corp
kalugin-balashov
kalugin
balashov@corp.mail.ru
balashov@corp.mail
balashov@corp
balashov
corp.mail.ru
corp.mail
mail.ru
mail
ru
Все данные слова войдут в индекс.
Заметим, что такое рекурсивное разбиение на слова имеет некоторые проблемы. Например, системным администраторам часто приходят служебные письма, которые содержат в себе различные пути (/usr/local/something/libexec/libany.so), зачастую весьма длинные. Такие слова могут вызывать большую глубину рекурсии. Поэтому слова, которые имеют длину больше заданной в конфигурационном файле токенизатора, не разбиваются на токены рекурсивно, а разбиваются на подслова минимальной длины (само исходное слово, тем не менее, тоже попадает в индекс).
Например, возьмем слово:
/usr/local/something/libexec/libany.so
При условии, что его длина больше длины, допустимой для рекурсивной токенизации, оно разбивается на следующие подслова:
/usr/local/something/libexec/libany.so
usr
local
something
libexec
libany
so
Такое разбиение дает менее качественные результаты поиска, однако является компромиссным вариантом в плане соотношения качество/ресурсы.
Окончательным этапом токенизации является получение первой формы слова (для поиска всех словоформ используется лемматизатор от «большого поиска») и взятие от нее CRC32. Все слова в индексе являются именно этими 32-битными целыми числами.
Письмо имеет определенный набор числовых (папка, дата, размер, флажок, наличие вложений и т. д.) и текстовых (тема, отправитель, текст и т. д.) зон. Список зон конфигурируется в специальном файле и может быть дополнен в процессе эксплуатации поисковой системы.
Snapshot состоит из двух частей — словарь (список всех слов, встречающихся в письмах, и указатели (смещения)) и собственно списки документов (и зон), на которые ссылаются указатели из словаря. При поиске происходит чтение словаря, в котором находятся слова, содержащиеся в поисковом запросе, после чего читаются списки документов по указателям из словаря; результаты объединяются. В среднем поисковый запрос (с использованием только snapshot) по одному слову требует двух обращений к диску — для чтения словаря и чтения списка документов.

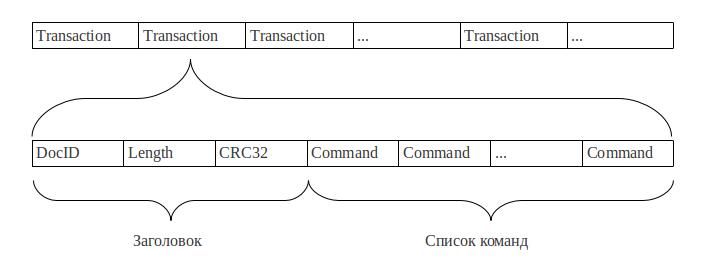
Xlog состоит из последовательно записанных транзакций. Целостность каждой транзакции гарантируется контрольной суммой (CRC32) ее содержимого. При чтении xlog все транзакции, для которых не сошлась контрольная сумма, пропускаются (однако процесс чтения не прерывается до тех пор, пока количество ошибок не превысит определенное число, установленное в конфигурационном файле). Транзакция, как правило, состоит из нескольких команд и описывает всегда ровно одно письмо. Главную роль играет команда, описывающая список слов, которые присутствуют в данном письме, и номера текстовых зон, в которых они встречаются. Исполнение поискового запроса над xlog требует чтения всего файла в память и анализа всех транзакций, поэтому размеры xlog сильно ограничены. Результаты исполнения запросов над xlog и snapshot объединяются в один общий результат.
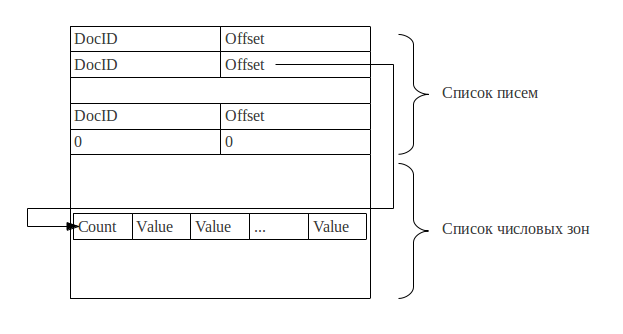
После того как сформирован список писем, в которых встречаются слова из запроса, происходит получение значений всех числовых зон для них. Значения числовых зон хранятся в файле nzdata. Структура файла аналогична структуре snapshot — это словарь, содержащий все номера писем и указатели, ссылающиеся на список значений числовых зон данного письма. Однако данный файл читается в память целиком ввиду того, что число обращений к данным внутри него, в отличие от snapshot, велико, а сам файл имеет намного меньшие размеры. Отметим, что nzdata не содержит все актуальные значения числовых зон. Он, как и snapshot, содержит значения числовых зон на определенный момент, а все последующие их изменения содержатся в xlog. Перестроение nzdata производится в тот же момент, что и snapshot. После подгрузки всех числовых зон происходит второе чтение xlog и применение всех команд, которые описывают изменения числовых зон, к загруженным результатам. Также отметим, что поисковый демон, прежде чем обратиться к nzdata, пробует получить числовые зоны от демона, обеспечивающего работу с почтовыми индексами (которые кэшируются в памяти при активной работе с ящиком). Этот способ во много раз быстрее и обеспечивает консистентность данных. Получение числовых зон из nzdata происходит, по сути, только в аварийных ситуациях.
Получив числовые зоны, поисковый демон начинает применять фильтры, указанные в запросе. Фильтры — это ограничения числовых зон: «равно», «не равно», «больше», и т. д. Самые популярные фильтры — ограничение на дату («за вчера», «за неделю»), на папку («Входящие», «Отправленные», «не в Спаме»), на какой-либо флаг («Непрочитанное», «Отмеченное флажком», «С вложениями»). Фильтры применяются последовательно к каждому письму из списка результатов и исключают часть писем оттуда.

На этом же этапе применяются группировщики, которые подсчитывают «сколько бы было результатов, если бы был применен такой фильтр».

Следующим этапом является ранжирование. В случае поиска по почте, в отличие от других задач полнотекстового поиска, наиболее релевантная функция ранжирования очевидна и проста — это сортировка по дате письма. Заканчивается ранжирование отсечением писем, не попадающих в текущую страницу (аналог операции LIMIT в SQL).
Для формирования результата поиска одних числовых зон мало. Так как после ранжирования остается чаще всего не более 25 писем (стандартное количество писем, отображаемых на одной странице), тяжелые операции загрузки и обработки текстовых зон происходят именно на этом этапе. Каждая текстовая зона после загрузки разбивается на слова, среди которых выделяются присутствовавшие в поисковом запросе (с учетом словоформ и без учета регистра). Данные слова «подсвечиваются» тегами <b> и </b>, а сама текстовая зона обрезается слева и справа до определенного размера, в который гарантированно входит первое выделенное слово.

Индекс саджестов строится в момент перестройки xlog в snapshot. Математическое ожидание длины запроса — 6 символов.
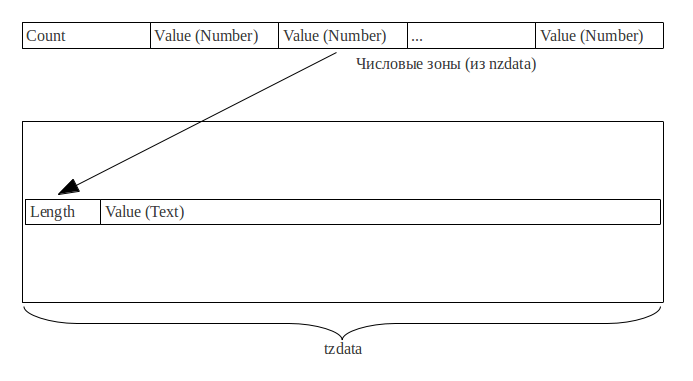
В индексе саджестов хранятся слова, не приведенные к первой форме, в том регистре, в котором находятся в письме. Индекс саджестов состоит из двух частей:
1. Словарь, состоящий из префиксов слов (длиной до 6 символов). Для слов длиной свыше 6 символов в словаре хранятся ссылки на списки постфиксов.
2. Множество списков постфиксов (произвольной длины).

Опытным путем было установлено, что построение индекса саджестов с префиксами длиной именно в 6 символов минимизирует его размер. Индекс саджестов, в отличие от поискового индекса, имеет смысл кэшировать, но хранить в памяти относительно недолго, потому что пользователям свойственно вводить несколько букв подряд до тех пор, пока выдача саджестов их не устроит. Кэшируется список префиксов (полностью) и все прочитанные к настоящему моменту с диска списки постфиксов. Данные из xlog-а не используются при генерации саджеста, т. к. чтение xlog может занять достаточно большое время. Поэтому индекс саджестов всегда немного «отстает» от реального состояния ящика. Индекс саджестов пополняется данными из xlog во время очередного перестроения snapshot.
Если у вас есть вопросы по реализации или есть опыт решения подобной задачи — давайте делиться наработками.
Дмитрий Калугин-Балашов,
Программист команды Почты Mail.Ru
Два основных процесса, выполняемых в рамках решения задачи поиска по почте, это индексация ящиков и исполнение поисковых запросов. В момент получения нового письма необходимо пополнить поисковый индекс, внеся в него это письмо. Очевидно, что данные в индексе должны быть упорядочены и максимально компактны; однако в таком случае наиболее вероятно, что потребуется вставка в середину файла, которая породит собой весьма «тяжелую» запись на диск. Учитывая, что приход нового письма происходит во много раз чаще, чем исполнение какого-либо поискового запроса, использование такой тяжелой операции для поддержания поискового индекса в актуальном состоянии сомнительно.
Мы приняли решение сделать индекс из двух файлов: snapshot, который содержит полнотекстовый индекс (отсортированные данные), и xlog, содержащий список последовательных транзакций, примененных к индексу. Любая операция над индексом (например, получение нового письма) вызывает одну запись на диск — это запись в конец файла xlog. В момент исполнения поискового запроса по факту происходит две операции поиска — бинарный поиск по snapshot и последовательный поиск по xlog — результаты которых объединяются. В тот момент, когда скорость поиска по xlog перестает нас удовлетворять, мы выполняем перестроение snapshot — вносим в него все изменения из xlog, а xlog начинаем копить заново. Данный момент определяется автоматически по одной из двух возможных политик: когда время исполнения очередного запроса превысит установленный порог, либо когда установленный порог будет превышен размером файла xlog.
Индексация нового письма начинается с токенизации. Токенизация — это разбиение письма на отдельные слова (полнотекстовый поиск работает с точностью до целого слова и не способен искать по произвольной подстроке). Стоит заметить, что токенизация является не самой тривиальной задачей. Возьмем, например, email-адрес
d.kalugin-balashov@corp.mail.ru
Очевидно, он является целым словом. Разумно сделать возможным поиск также и по слову d.kalugin (изучение поисковых запросов пользователей показало, что они часто пытаются искать по «части email»). Однако поддерживать все подстроки данного слова нельзя, так как это приведет к резкому росту размера индекса, и, как следствие, потере скорости исполнения запросов. Весьма разумно разбивать слово на подстроки только по знакам препинания. Соответственно, мы получаем следующие подслова:
d.kalugin-balashov@corp.mail.ru
d.kalugin-balashov@corp.mail
d.kalugin-balashov@corp
d.kalugin-balashov
d.kalugin
d
kalugin-balashov@corp.mail.ru
kalugin-balashov@corp.mail
kalugin-balashov@corp
kalugin-balashov
kalugin
balashov@corp.mail.ru
balashov@corp.mail
balashov@corp
balashov
corp.mail.ru
corp.mail
mail.ru
ru
Все данные слова войдут в индекс.
Заметим, что такое рекурсивное разбиение на слова имеет некоторые проблемы. Например, системным администраторам часто приходят служебные письма, которые содержат в себе различные пути (/usr/local/something/libexec/libany.so), зачастую весьма длинные. Такие слова могут вызывать большую глубину рекурсии. Поэтому слова, которые имеют длину больше заданной в конфигурационном файле токенизатора, не разбиваются на токены рекурсивно, а разбиваются на подслова минимальной длины (само исходное слово, тем не менее, тоже попадает в индекс).
Например, возьмем слово:
/usr/local/something/libexec/libany.so
При условии, что его длина больше длины, допустимой для рекурсивной токенизации, оно разбивается на следующие подслова:
/usr/local/something/libexec/libany.so
usr
local
something
libexec
libany
so
Такое разбиение дает менее качественные результаты поиска, однако является компромиссным вариантом в плане соотношения качество/ресурсы.
Окончательным этапом токенизации является получение первой формы слова (для поиска всех словоформ используется лемматизатор от «большого поиска») и взятие от нее CRC32. Все слова в индексе являются именно этими 32-битными целыми числами.
Письмо имеет определенный набор числовых (папка, дата, размер, флажок, наличие вложений и т. д.) и текстовых (тема, отправитель, текст и т. д.) зон. Список зон конфигурируется в специальном файле и может быть дополнен в процессе эксплуатации поисковой системы.
Snapshot состоит из двух частей — словарь (список всех слов, встречающихся в письмах, и указатели (смещения)) и собственно списки документов (и зон), на которые ссылаются указатели из словаря. При поиске происходит чтение словаря, в котором находятся слова, содержащиеся в поисковом запросе, после чего читаются списки документов по указателям из словаря; результаты объединяются. В среднем поисковый запрос (с использованием только snapshot) по одному слову требует двух обращений к диску — для чтения словаря и чтения списка документов.

Xlog состоит из последовательно записанных транзакций. Целостность каждой транзакции гарантируется контрольной суммой (CRC32) ее содержимого. При чтении xlog все транзакции, для которых не сошлась контрольная сумма, пропускаются (однако процесс чтения не прерывается до тех пор, пока количество ошибок не превысит определенное число, установленное в конфигурационном файле). Транзакция, как правило, состоит из нескольких команд и описывает всегда ровно одно письмо. Главную роль играет команда, описывающая список слов, которые присутствуют в данном письме, и номера текстовых зон, в которых они встречаются. Исполнение поискового запроса над xlog требует чтения всего файла в память и анализа всех транзакций, поэтому размеры xlog сильно ограничены. Результаты исполнения запросов над xlog и snapshot объединяются в один общий результат.

После того как сформирован список писем, в которых встречаются слова из запроса, происходит получение значений всех числовых зон для них. Значения числовых зон хранятся в файле nzdata. Структура файла аналогична структуре snapshot — это словарь, содержащий все номера писем и указатели, ссылающиеся на список значений числовых зон данного письма. Однако данный файл читается в память целиком ввиду того, что число обращений к данным внутри него, в отличие от snapshot, велико, а сам файл имеет намного меньшие размеры. Отметим, что nzdata не содержит все актуальные значения числовых зон. Он, как и snapshot, содержит значения числовых зон на определенный момент, а все последующие их изменения содержатся в xlog. Перестроение nzdata производится в тот же момент, что и snapshot. После подгрузки всех числовых зон происходит второе чтение xlog и применение всех команд, которые описывают изменения числовых зон, к загруженным результатам. Также отметим, что поисковый демон, прежде чем обратиться к nzdata, пробует получить числовые зоны от демона, обеспечивающего работу с почтовыми индексами (которые кэшируются в памяти при активной работе с ящиком). Этот способ во много раз быстрее и обеспечивает консистентность данных. Получение числовых зон из nzdata происходит, по сути, только в аварийных ситуациях.

Получив числовые зоны, поисковый демон начинает применять фильтры, указанные в запросе. Фильтры — это ограничения числовых зон: «равно», «не равно», «больше», и т. д. Самые популярные фильтры — ограничение на дату («за вчера», «за неделю»), на папку («Входящие», «Отправленные», «не в Спаме»), на какой-либо флаг («Непрочитанное», «Отмеченное флажком», «С вложениями»). Фильтры применяются последовательно к каждому письму из списка результатов и исключают часть писем оттуда.

На этом же этапе применяются группировщики, которые подсчитывают «сколько бы было результатов, если бы был применен такой фильтр».

Следующим этапом является ранжирование. В случае поиска по почте, в отличие от других задач полнотекстового поиска, наиболее релевантная функция ранжирования очевидна и проста — это сортировка по дате письма. Заканчивается ранжирование отсечением писем, не попадающих в текущую страницу (аналог операции LIMIT в SQL).
Для формирования результата поиска одних числовых зон мало. Так как после ранжирования остается чаще всего не более 25 писем (стандартное количество писем, отображаемых на одной странице), тяжелые операции загрузки и обработки текстовых зон происходят именно на этом этапе. Каждая текстовая зона после загрузки разбивается на слова, среди которых выделяются присутствовавшие в поисковом запросе (с учетом словоформ и без учета регистра). Данные слова «подсвечиваются» тегами <b> и </b>, а сама текстовая зона обрезается слева и справа до определенного размера, в который гарантированно входит первое выделенное слово.


Индекс саджестов строится в момент перестройки xlog в snapshot. Математическое ожидание длины запроса — 6 символов.

В индексе саджестов хранятся слова, не приведенные к первой форме, в том регистре, в котором находятся в письме. Индекс саджестов состоит из двух частей:
1. Словарь, состоящий из префиксов слов (длиной до 6 символов). Для слов длиной свыше 6 символов в словаре хранятся ссылки на списки постфиксов.
2. Множество списков постфиксов (произвольной длины).

Опытным путем было установлено, что построение индекса саджестов с префиксами длиной именно в 6 символов минимизирует его размер. Индекс саджестов, в отличие от поискового индекса, имеет смысл кэшировать, но хранить в памяти относительно недолго, потому что пользователям свойственно вводить несколько букв подряд до тех пор, пока выдача саджестов их не устроит. Кэшируется список префиксов (полностью) и все прочитанные к настоящему моменту с диска списки постфиксов. Данные из xlog-а не используются при генерации саджеста, т. к. чтение xlog может занять достаточно большое время. Поэтому индекс саджестов всегда немного «отстает» от реального состояния ящика. Индекс саджестов пополняется данными из xlog во время очередного перестроения snapshot.
Если у вас есть вопросы по реализации или есть опыт решения подобной задачи — давайте делиться наработками.
Дмитрий Калугин-Балашов,
Программист команды Почты Mail.Ru
