
Чем занят отдел обработки запросов в Поиске Mail.Ru? Если одним предложением, мы пытаемся «понять» запрос, то есть осуществляем подготовку запроса к поиску, приводим его в вид, пригодный для взаимодействия с нашим индексом, ранжированием, подмесами и прочими компонентами. Если же вы хотите узнать о нашей работе подробнее — добро пожаловать под кат. В этом посте я расскажу об одной из областей нашей работы — парсере запросов.
На рисунке изображена структура сервиса поиска. Участки системы, в которых работаем мы, выделены розовым цветом.
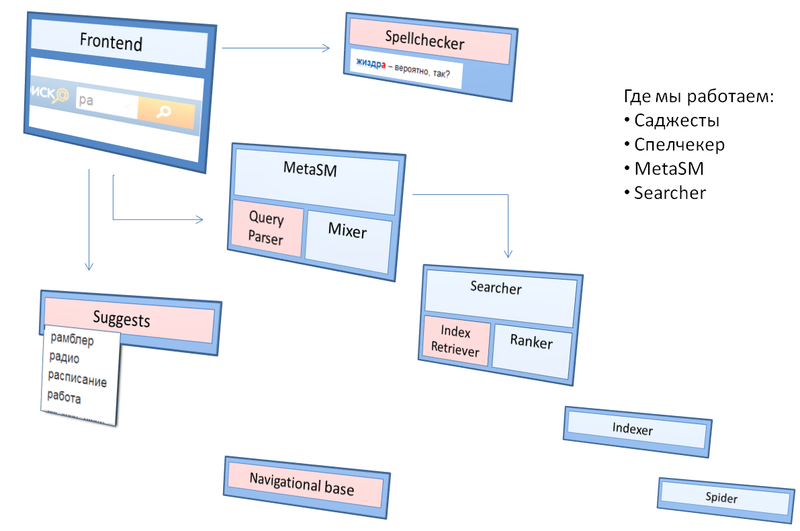
Рис. 1. Наше место в поиске
Фронтенд предоставляет пользователю форму для ввода запроса, по готовности запрос пересылается на MetaSM, где попадает в Query Parser, занимающийся его разбором и классификацией. Затем запрос, обогащенный дополнительными параметрами, в виде дерева передается на бэкенды, где на основе этого дерева из индекса извлекаются соответствующие запросу данные, передаваемые на окончательную обработку ранжированию.
До того, как запрос передан в систему поиска, он обрабатывается еще двумя компонентами. Первый — саджесты, сервис, который реагирует практически на каждое нажатие клавиши, предлагая подходящие, по его мнению, варианты продолжения запроса. Второй — спеллчекер, которому запрос передается после отправки: он анализирует запрос на предмет опечаток.
Навигационная база изображена отдельно исходя из функционала; на самом деле она интегрирована в парсер запросов, но об этом — чуть ниже.
Зачем вообще нужна какая-либо классификация запроса и предварительный анализ? Причина в том, что разные классы запросов требуют разных данных, разных формул ранжирования, разных визуальных представлений результатов.
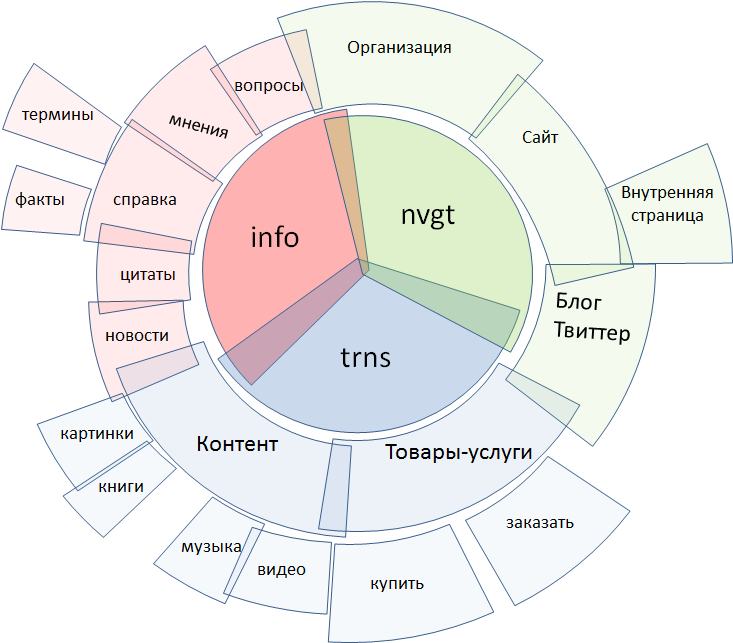
Рис. 2. Разновидности запросов
Традиционно все поисковые запросы разделяют на три класса:
● информационные
● навигационные
● транзакционные
Каждый из них, в свою очередь, распадается на более мелкие классы. Эта диаграмма не претендует на полноту, процесс сегментации всего множества запросов, по сути, фрактален — это скорее вопрос терпения и ресурсов. Здесь указаны лишь самые основные элементы.
Транзакционные запросы включают в себя поиск контента, содержащегося в интернете, и поиск объектов, находящихся «в оффлайне», т.е., прежде всего, различных товаров и услуг. Навигационные запросы — поиск явно указанных сайтов, блогов и микроблогов, личных страниц, организаций. Информационный — самый широкий в смысловом плане класс запросов, к нему относится все остальное: это новости, справочные запросы по фактам и терминам, поиск мнений и отзывов, ответы на вопросы и многое другое.
Сразу отмечу, что один запрос зачастую имеет признаки сразу нескольких классов. Поэтому классификация — это не создание древовидной структуры, в каждую ячейку которой попадает часть запроса, а скорее тэгирование, то есть наделение запроса дополнительными свойствами.
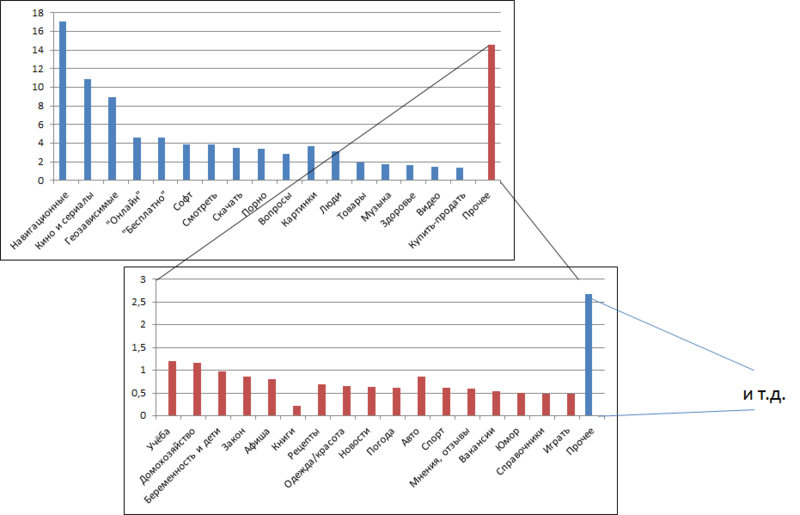
Рис. 3. Частотное распределение разных классов запросов
По оценке размеров различных классов запросов видно, что малое количество классов содержит большую долю потока запросов, а за ними следует длинный хвост уменьшающихся фрагментов потока запросов. Чем уже тема, тем меньше по ней запросов и тем больше таких тем.
С практической точки зрения это значит, что мы не стремимся классифицировать абсолютно все запросы — мы скорее пытаемся отщипнуть от общего потока запросов наиболее важные. Как правило, критерием выбора класса является его частотность, но не только: это могут быть запросы, которые мы можем качественно обработать, интересно визуализировать результаты и так далее.
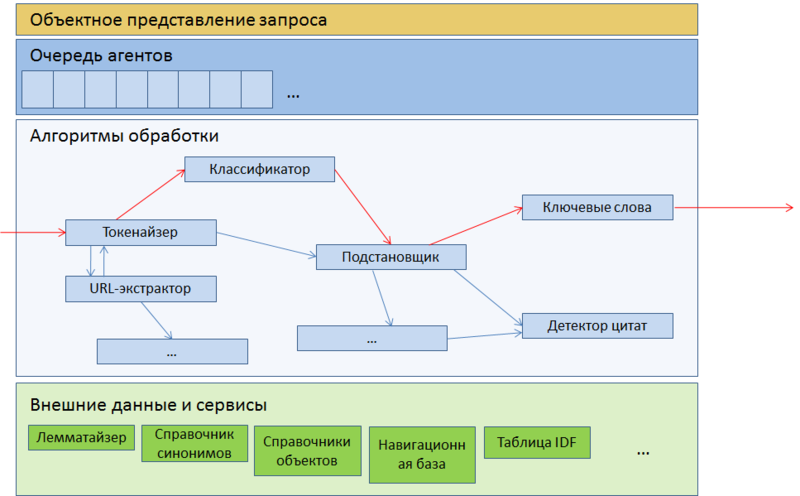
Рис. 4. Архитектура парсера запросов
Парсер представляет собой очередь агентов, каждый из которых производит какое-либо более или менее атомарное действие над запросом, начиная от разбиения его на слова и другие регулярные сущности типа URL-ов и телефонных номеров, и заканчивая сложными классификаторами типа детектора цитат.
Агенты выстроены в очередь. Каждый запрос прогоняется через эту очередь, причём результаты работы каждого агента влияют на дальнейший логический путь запроса — например, запрос, классифицированный как навигационный, не попадёт на обработку детектора цитат. Сам запрос здесь представляется как некая доска объявлений, на которой каждый агент может оставить свое сообщение, прочитать сообщения других агентов и при необходимости изменить или отменить их. По завершении запрос передается дополнительным программам подмесов и, в конечном счете, отправляется на бэкенды, где все записанные агентами дополнительные параметры используются как факторы ранжирования.
Основным поставщиком данных для парсера запросов являются словари. Это огромные файлы, содержащие сгруппированные массивы строк, каждый из которых имеет определенный смысл.

Рис. 5. Словари: пример из жизни
На рисунке представлен фрагмент одного из словарей, в котором собраны слова, наиболее характерные для запросов класса «Фильмы». Каждой из этих групп слов может быть сопоставлен маркер (на рисунке он окружен зеленой рамкой). Он обозначает, что в случае нахождения в запросе такого фрагмента всему запросу будет поставлен флаг, сигнализирующий, что предметом этого запроса является кино.
В этих же словарях задаются синонимы (красная рамка на рисунке). Благодаря им, если, к примеру, в запросе есть слово “саундтрек”, то запрос будет расширен словосочетаниями “звуковая дорожка”, “саунд трек” и аббревиатурой ОST.
Таких словарей существует несколько десятков. Размер некоторых из них —сотни тысяч, даже миллионы подобных строк. На их основе происходит первичная обработка запроса, его раскрашивание, после чего работает более сложная логика.
Возьмем три запроса:
● Пираты Карибского моря
● глубина Карибского моря
● последствия Карибского кризиса
С точки зрения текстового поиска все они — просто строки, содержащие по три слова, в то время как с точки зрения пользователя каждый из них имеет совершенно различный смысл. Наша же цель — сообщить системе как можно больше об этих различиях.
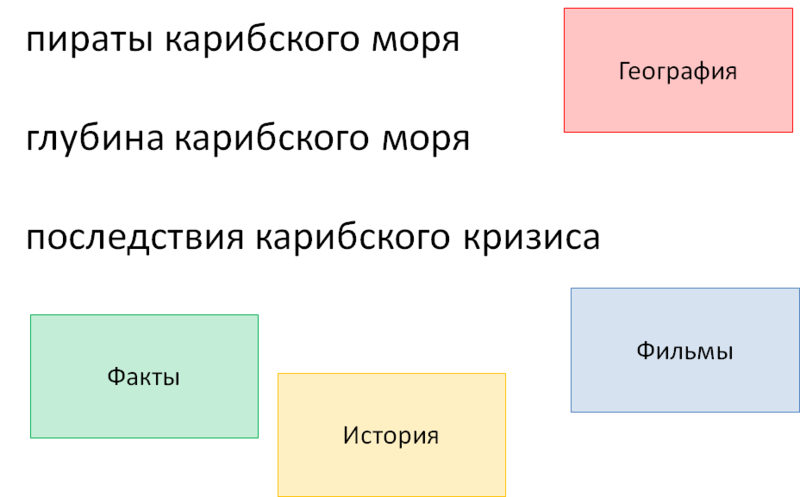
Рис. 6. Словари и маркеры
Четыре словаря на рисунке выбраны для наглядности и не вполне соответствуют реально существующим. Эти словари содержат подходящие для подмеса факты, словарь с историческими событиями, словарь с фильмами и словарь с географическими объектами. Все слова и словосочетания запроса прогоняются через эти словари, в результате чего находятся следующие фрагменты:
● Пираты Карибского моря тэгируется как фильм, внутри которого находится какая-то география
● глубина Карибского моря – это некий объективный факт
● Последствия Карибского кризиса содержит маркер факта, о чем свидетельствует слово «последствия», и исторического события – Карибский кризис.
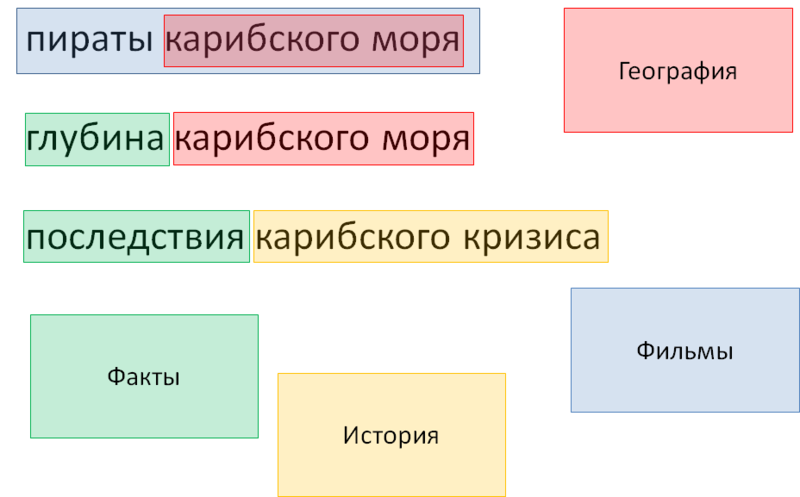
Рис. 7. Словари и маркеры: промежуточный результат
Последним этапом мы удаляем включенный в фильм географический объект, чтобы он не мешал выборке. Необходимость такого удаления также настраивается синтаксисом в словаре. Это называется жадность маркеров: как правило (но далеко не всегда), большое количество маркеров и включение одного в другой означает, что внутренний маркер нужно игнорировать.
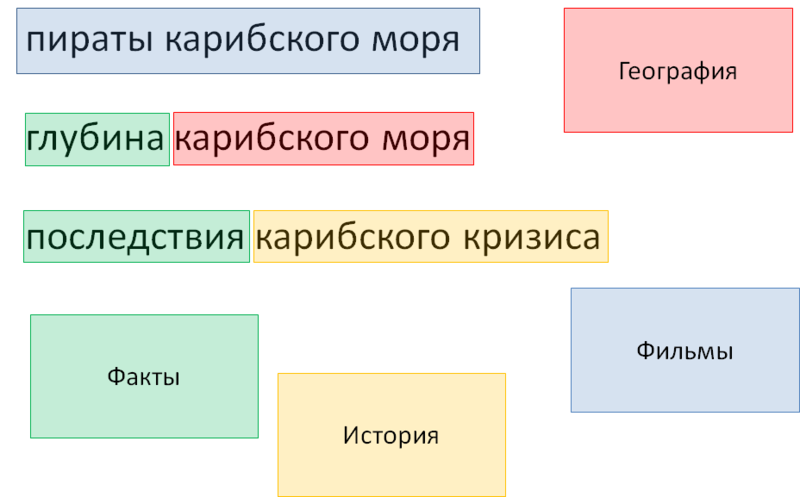
Рис. 8. Словари и маркеры: итог
Содержимое словарей делится на два больших класса:
● Частотные выражения-маркеры, характеризующие определенную тематику или намерение пользователя. Такие словари составляются вручную.
● Объекты (фильмы, рецепты, блюда, знаменитые личности, географические названия и т.д.).
С точки зрения наполнения словарей объекты представляют наибольший интерес. Здесь существует несколько подходов. Первый – это, опять же, составлять их вручную. Это самый качественный способ получения данных, но и самый трудоемкий.
Автоматическое создание словаря объектов – тема для отдельного поста, но если описать вкратце, то это замысловатый набор простых алгоритмов, который на основе небольшой обучающей выборки объектов заданного типа выбирает из лога все запросы, содержащие объекты того же типа, при этом разбивая каждый из этих запросов на объект и его контекст.

Необходимо отметить, что многие запросы неоднозначны: например, по запросу «скачать хоббит» совершенно невозможно сказать, что именно хочет скачать пользователь — фильм, мульфильм, книгу или игру.
Конечным этапом работы парсера запросов является передача полученной информации ранжированию. Перед этим происходит пересечение данных о запросе и о структуре и данных из индекса. Если вкратце, то для каждого слова запроса из обратного индекса извлекаются списки документов, которые затем пересекаются по правилам, заданным структурой дерева запроса. Сложность заключается в том, что у всех слов разные веса, некоторые слова могут быть сочтены необязательными, имеет значение порядок слов, их формы в запросе, расстояния между ними и другие свойства. Все полученные данные вместе со всеми флагами запроса передаются ранжированию, где становятся частью множества факторов, определяющих окончательный результат поиска.
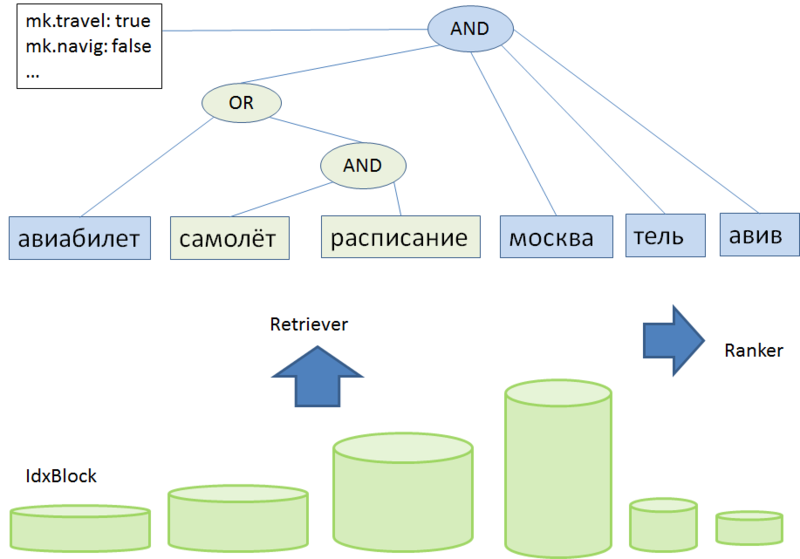
Рис. 9. Дерево запроса: авиабилеты москва тель-авив
Цитатные запросы представляют собой пример более сложной классификации, которую невозможно качественно сделать на основе одних словарей. Изначально при обработке цитат просто анализировался лог запроса: выявлялось, какие там есть цитаты, чем они отличаются. Основные, самые очевидные признаки цитатного запроса – это большая длина, грамматическая согласованность слов, наличие заглавных букв и знаков препинания. На основе этих признаков был реализован первый агент, который, используя вручную подобранные коэффициенты и примитивную логику if-then-else, рассчитывал вероятность того, что запрос является цитатой.
Однако когда факторов становится много, и оценивать влияние каждого из них вручную уже невозможно и даже вредно, применяются различные алгоритмы машинного включения. При выявлении цитат используется тот же код, который применяется в ранжировании. Реакцией на цитатный запрос является не только влияние этого фактора на ранжирование, но и изменение алгоритма склейки похожих документов. При ложном срабатывании классификатора, следствием чего оказывается неудачный поиск в целом, приходится делать перезапрос, в котором запрос уже более не считается цитатным. Таким образом, парсер влияет и на алгоритм поиска в целом.
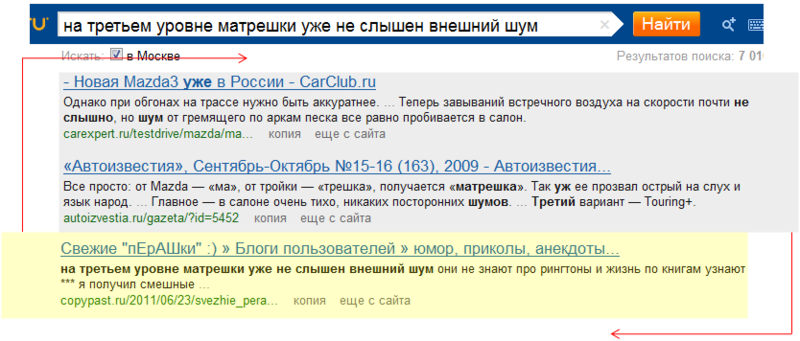
Рис. 10. Цитатные запросы
Для машинного обучения применяются деревья принятия решений и методы, основанные на Марковских моделях. Более сложные методы непозволительно дороги для real-time. Поэтому кластеризация запросов или выделение объектов выносится в предварительную обработку, а не делается на лету.
О навигационных запросах я расскажу отдельно — ждите продолжения в ближайшие дни. Кроме того, в следующих сериях я подробно остановлюсь на спеллчекере и саджестах.
Если у вас есть вопросы или полезный опыт, которым вы хотели бы поделиться, добро пожаловать в комментарии.
Михаил Долинин,
руководитель группы обработки поисковых запросов
Где мы, кто мы и где здесь парсер?
На рисунке изображена структура сервиса поиска. Участки системы, в которых работаем мы, выделены розовым цветом.

Рис. 1. Наше место в поиске
Фронтенд предоставляет пользователю форму для ввода запроса, по готовности запрос пересылается на MetaSM, где попадает в Query Parser, занимающийся его разбором и классификацией. Затем запрос, обогащенный дополнительными параметрами, в виде дерева передается на бэкенды, где на основе этого дерева из индекса извлекаются соответствующие запросу данные, передаваемые на окончательную обработку ранжированию.
До того, как запрос передан в систему поиска, он обрабатывается еще двумя компонентами. Первый — саджесты, сервис, который реагирует практически на каждое нажатие клавиши, предлагая подходящие, по его мнению, варианты продолжения запроса. Второй — спеллчекер, которому запрос передается после отправки: он анализирует запрос на предмет опечаток.
Навигационная база изображена отдельно исходя из функционала; на самом деле она интегрирована в парсер запросов, но об этом — чуть ниже.
Классы и разновидности запросов
Зачем вообще нужна какая-либо классификация запроса и предварительный анализ? Причина в том, что разные классы запросов требуют разных данных, разных формул ранжирования, разных визуальных представлений результатов.
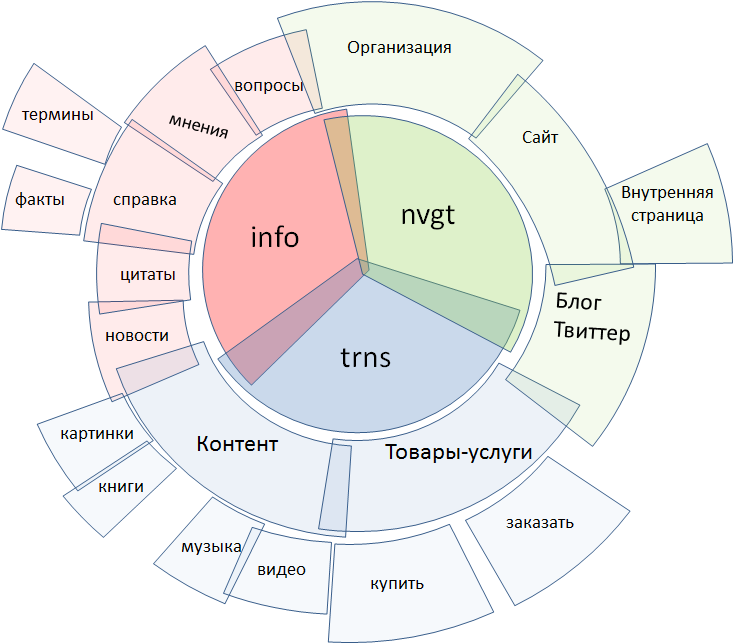
Рис. 2. Разновидности запросов
Традиционно все поисковые запросы разделяют на три класса:
● информационные
● навигационные
● транзакционные
Каждый из них, в свою очередь, распадается на более мелкие классы. Эта диаграмма не претендует на полноту, процесс сегментации всего множества запросов, по сути, фрактален — это скорее вопрос терпения и ресурсов. Здесь указаны лишь самые основные элементы.
Транзакционные запросы включают в себя поиск контента, содержащегося в интернете, и поиск объектов, находящихся «в оффлайне», т.е., прежде всего, различных товаров и услуг. Навигационные запросы — поиск явно указанных сайтов, блогов и микроблогов, личных страниц, организаций. Информационный — самый широкий в смысловом плане класс запросов, к нему относится все остальное: это новости, справочные запросы по фактам и терминам, поиск мнений и отзывов, ответы на вопросы и многое другое.
Сразу отмечу, что один запрос зачастую имеет признаки сразу нескольких классов. Поэтому классификация — это не создание древовидной структуры, в каждую ячейку которой попадает часть запроса, а скорее тэгирование, то есть наделение запроса дополнительными свойствами.
Распределение тем

Рис. 3. Частотное распределение разных классов запросов
По оценке размеров различных классов запросов видно, что малое количество классов содержит большую долю потока запросов, а за ними следует длинный хвост уменьшающихся фрагментов потока запросов. Чем уже тема, тем меньше по ней запросов и тем больше таких тем.
С практической точки зрения это значит, что мы не стремимся классифицировать абсолютно все запросы — мы скорее пытаемся отщипнуть от общего потока запросов наиболее важные. Как правило, критерием выбора класса является его частотность, но не только: это могут быть запросы, которые мы можем качественно обработать, интересно визуализировать результаты и так далее.
Архитектура парсера
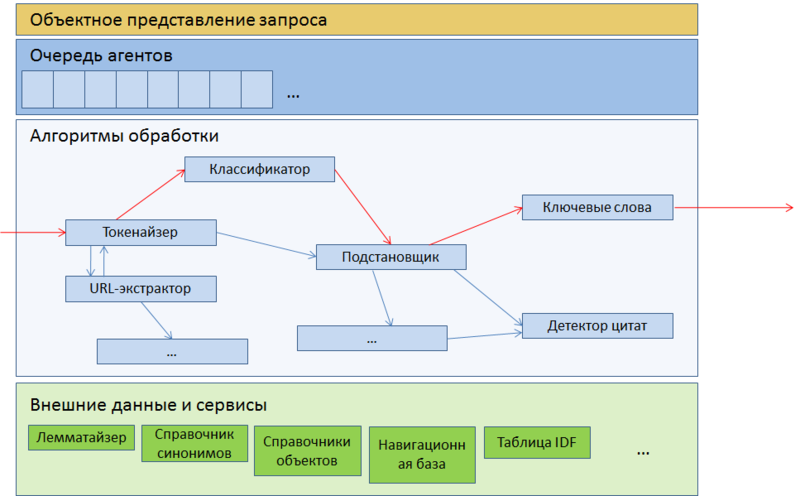
Рис. 4. Архитектура парсера запросов
Парсер представляет собой очередь агентов, каждый из которых производит какое-либо более или менее атомарное действие над запросом, начиная от разбиения его на слова и другие регулярные сущности типа URL-ов и телефонных номеров, и заканчивая сложными классификаторами типа детектора цитат.
Агенты выстроены в очередь. Каждый запрос прогоняется через эту очередь, причём результаты работы каждого агента влияют на дальнейший логический путь запроса — например, запрос, классифицированный как навигационный, не попадёт на обработку детектора цитат. Сам запрос здесь представляется как некая доска объявлений, на которой каждый агент может оставить свое сообщение, прочитать сообщения других агентов и при необходимости изменить или отменить их. По завершении запрос передается дополнительным программам подмесов и, в конечном счете, отправляется на бэкенды, где все записанные агентами дополнительные параметры используются как факторы ранжирования.
Словари
Основным поставщиком данных для парсера запросов являются словари. Это огромные файлы, содержащие сгруппированные массивы строк, каждый из которых имеет определенный смысл.

Рис. 5. Словари: пример из жизни
На рисунке представлен фрагмент одного из словарей, в котором собраны слова, наиболее характерные для запросов класса «Фильмы». Каждой из этих групп слов может быть сопоставлен маркер (на рисунке он окружен зеленой рамкой). Он обозначает, что в случае нахождения в запросе такого фрагмента всему запросу будет поставлен флаг, сигнализирующий, что предметом этого запроса является кино.
В этих же словарях задаются синонимы (красная рамка на рисунке). Благодаря им, если, к примеру, в запросе есть слово “саундтрек”, то запрос будет расширен словосочетаниями “звуковая дорожка”, “саунд трек” и аббревиатурой ОST.
Таких словарей существует несколько десятков. Размер некоторых из них —сотни тысяч, даже миллионы подобных строк. На их основе происходит первичная обработка запроса, его раскрашивание, после чего работает более сложная логика.
Маркеры
Возьмем три запроса:
● Пираты Карибского моря
● глубина Карибского моря
● последствия Карибского кризиса
С точки зрения текстового поиска все они — просто строки, содержащие по три слова, в то время как с точки зрения пользователя каждый из них имеет совершенно различный смысл. Наша же цель — сообщить системе как можно больше об этих различиях.
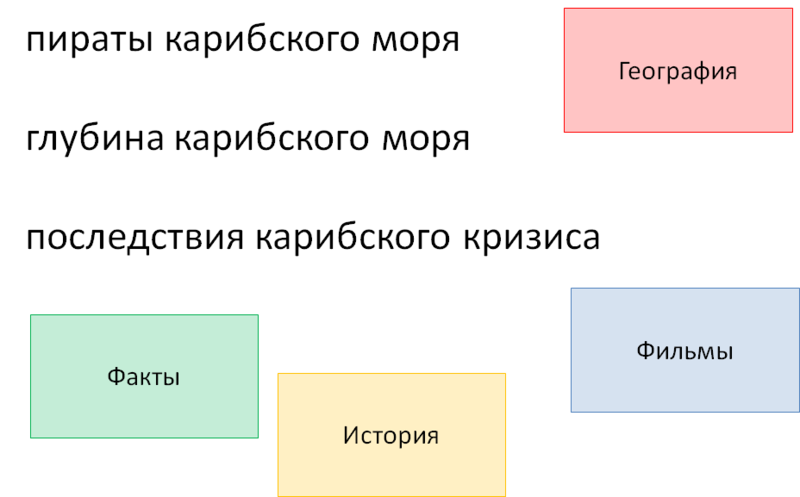
Рис. 6. Словари и маркеры
Четыре словаря на рисунке выбраны для наглядности и не вполне соответствуют реально существующим. Эти словари содержат подходящие для подмеса факты, словарь с историческими событиями, словарь с фильмами и словарь с географическими объектами. Все слова и словосочетания запроса прогоняются через эти словари, в результате чего находятся следующие фрагменты:
● Пираты Карибского моря тэгируется как фильм, внутри которого находится какая-то география
● глубина Карибского моря – это некий объективный факт
● Последствия Карибского кризиса содержит маркер факта, о чем свидетельствует слово «последствия», и исторического события – Карибский кризис.
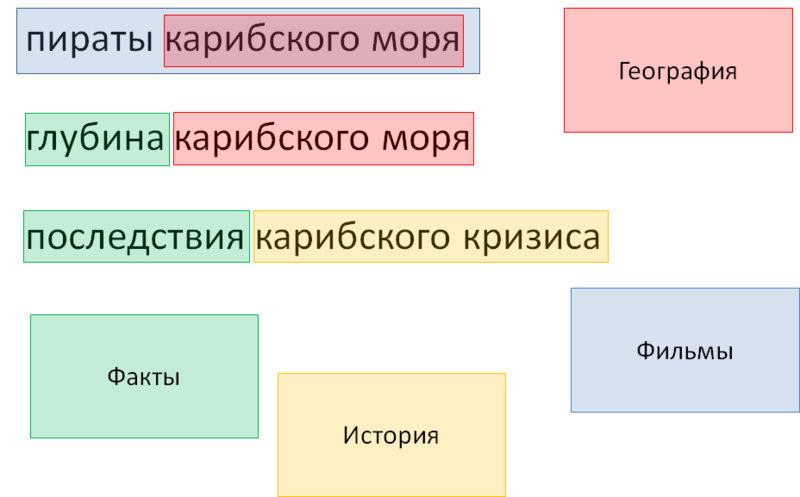
Рис. 7. Словари и маркеры: промежуточный результат
Последним этапом мы удаляем включенный в фильм географический объект, чтобы он не мешал выборке. Необходимость такого удаления также настраивается синтаксисом в словаре. Это называется жадность маркеров: как правило (но далеко не всегда), большое количество маркеров и включение одного в другой означает, что внутренний маркер нужно игнорировать.
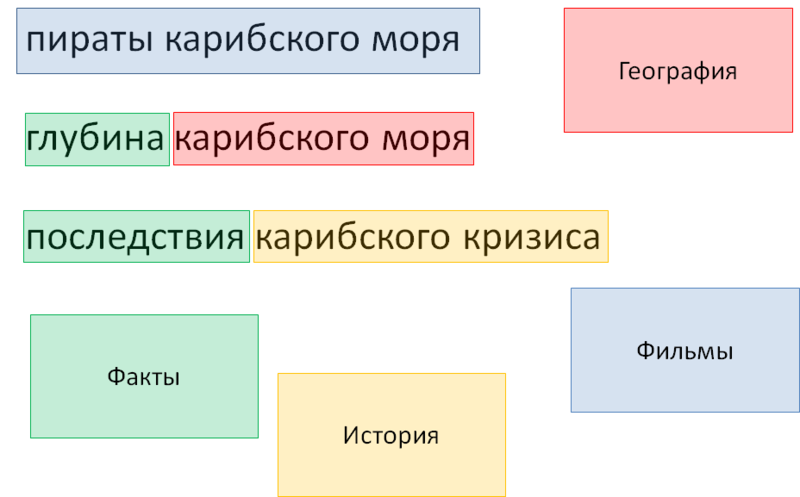
Рис. 8. Словари и маркеры: итог
Виды словарей
Содержимое словарей делится на два больших класса:
● Частотные выражения-маркеры, характеризующие определенную тематику или намерение пользователя. Такие словари составляются вручную.
● Объекты (фильмы, рецепты, блюда, знаменитые личности, географические названия и т.д.).
С точки зрения наполнения словарей объекты представляют наибольший интерес. Здесь существует несколько подходов. Первый – это, опять же, составлять их вручную. Это самый качественный способ получения данных, но и самый трудоемкий.
Автоматическое создание словаря объектов – тема для отдельного поста, но если описать вкратце, то это замысловатый набор простых алгоритмов, который на основе небольшой обучающей выборки объектов заданного типа выбирает из лога все запросы, содержащие объекты того же типа, при этом разбивая каждый из этих запросов на объект и его контекст.

Необходимо отметить, что многие запросы неоднозначны: например, по запросу «скачать хоббит» совершенно невозможно сказать, что именно хочет скачать пользователь — фильм, мульфильм, книгу или игру.
Конечным этапом работы парсера запросов является передача полученной информации ранжированию. Перед этим происходит пересечение данных о запросе и о структуре и данных из индекса. Если вкратце, то для каждого слова запроса из обратного индекса извлекаются списки документов, которые затем пересекаются по правилам, заданным структурой дерева запроса. Сложность заключается в том, что у всех слов разные веса, некоторые слова могут быть сочтены необязательными, имеет значение порядок слов, их формы в запросе, расстояния между ними и другие свойства. Все полученные данные вместе со всеми флагами запроса передаются ранжированию, где становятся частью множества факторов, определяющих окончательный результат поиска.

Рис. 9. Дерево запроса: авиабилеты москва тель-авив
Цитатные запросы
Цитатные запросы представляют собой пример более сложной классификации, которую невозможно качественно сделать на основе одних словарей. Изначально при обработке цитат просто анализировался лог запроса: выявлялось, какие там есть цитаты, чем они отличаются. Основные, самые очевидные признаки цитатного запроса – это большая длина, грамматическая согласованность слов, наличие заглавных букв и знаков препинания. На основе этих признаков был реализован первый агент, который, используя вручную подобранные коэффициенты и примитивную логику if-then-else, рассчитывал вероятность того, что запрос является цитатой.
Однако когда факторов становится много, и оценивать влияние каждого из них вручную уже невозможно и даже вредно, применяются различные алгоритмы машинного включения. При выявлении цитат используется тот же код, который применяется в ранжировании. Реакцией на цитатный запрос является не только влияние этого фактора на ранжирование, но и изменение алгоритма склейки похожих документов. При ложном срабатывании классификатора, следствием чего оказывается неудачный поиск в целом, приходится делать перезапрос, в котором запрос уже более не считается цитатным. Таким образом, парсер влияет и на алгоритм поиска в целом.
Рис. 10. Цитатные запросы
Для машинного обучения применяются деревья принятия решений и методы, основанные на Марковских моделях. Более сложные методы непозволительно дороги для real-time. Поэтому кластеризация запросов или выделение объектов выносится в предварительную обработку, а не делается на лету.
To be continued
О навигационных запросах я расскажу отдельно — ждите продолжения в ближайшие дни. Кроме того, в следующих сериях я подробно остановлюсь на спеллчекере и саджестах.
Если у вас есть вопросы или полезный опыт, которым вы хотели бы поделиться, добро пожаловать в комментарии.
Михаил Долинин,
руководитель группы обработки поисковых запросов
