
Когда говорят про разработку игр, обычно речь идет о шейдерах, графике, AI и т.д. Крайне редко затрагивается серверная часть игровых проектов, а ещё реже — базы данных. Исправим это досадное недоразумение: сегодня я расскажу о нашем опыте работы с базами данных, который мы приобрели в ходе разработки Аллодов Онлайн и нашего нового проекта Skyforge. Обе эти игры — клиентские MMORPG. В первой зарегистрировано несколько миллионов игроков. Вторая разрабатывается студией в строжайшей секретности в недрах Allods Team.
Меня зовут Андрей Фролов. Я ведущий программист Allods Team и работаю в команде сервера. Мой опыт разработки — почти 10 лет, но в игры я попал только в октябре 2009. В коллективе я уже больше трёх лет, с марта 2010. Начинал работу на Аллодах Онлайн, а сейчас на Skyforge. Занимаюсь всем, что так или иначе связано с сервером Skyforge и базами данных. В этой статье я расскажу о базах данных в онлайн-играх на примере Аллодов и Skyforge.

Если вы не очень любите читать, предлагаю пролистать статью до конца и посмотреть видеозапись моего доклада с Конференции разработчиков игр. Тем же, кто останется в посте, положен бонус — важное дополнение к докладу в виде рассказа о гибриде NoSQL-JSON и реляционной модели данных.
Игровая база — это типичная OLTP-система (много маленьких и коротких транзакций). Но использование баз данных в играх несколько отличается от их использования в вебе, банках и прочем энтерпрайзе. Во-первых, это связано с тем, что модель данных в играх существенно сложнее, чем в банках. Во-вторых, большинство программистов в геймдеве вышли из сурового мира C++, прихватив с собой бороду и любовь к бинарной запаковке. Абсолютно все они, если им надо сохранить персонажа на диск, первым делом хотят сериализовать его в файл. Именно так всё и начиналось в Аллодах Онлайн. Программисты сделали файловое хранилище, но быстро одумались и переписали всё под MySQL. Проект успешно запустили, люди играли, опыт копился.
Что у нас было в Аллодах:
Через несколько лет стартовал Skyforge. У Skyforge были совсем другие требования, и поэтому пришлось пересмотреть наш подход к работе с базами.
Вот эти требования:
Ну что же, давайте заглянем за кулисы и посмотрим, к чему мы пришли в ходе эволюционного развития нашей технологической мысли.
Во-первых, наш сервер распределённый. База тоже распределённая. Во-вторых, архитектура нашего сервера — сервисно-ориентированная. Это значит, что всё представлено в виде сервисов, которые обмениваются сообщениями. В игре существуют десятки сервисов, но прямой доступ к базе данных есть только у сервисов исполнения транзакций. В общем виде и в меру моих художественных способностей это выглядит примерно вот так:
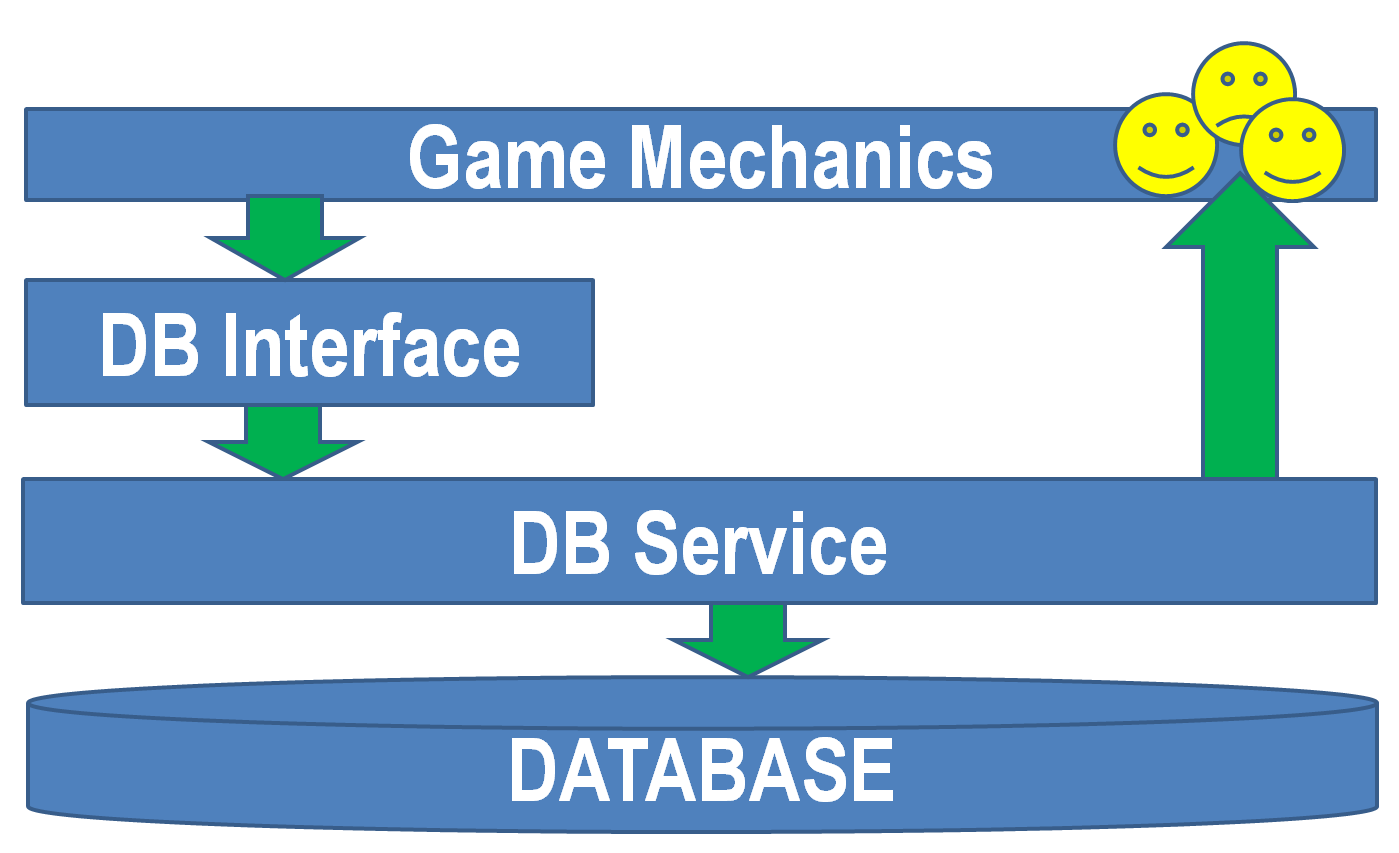
Нужно только учесть, что все изображённые на картинке элементы существуют в нескольких экземплярах.
Эта нехитрая схема имеет один важный момент. Наш аватар нужен для работоспособности игровой механики, но как побочный эффект он же фактически является кэшем над базой данных. Все запросы вида «Покажи мне предметы этого игрока» или «А где находится аватар Василий?» обслуживаются этим аватаром. Когда игрок входит в игру, мы загружаем его аватара, и он живёт до тех пор, пока игрок онлайн. Такой нехитрый трюк позволяет снять с базы большую часть запросов на чтение и даже часть запросов на запись.
Мы делим все данные игрока на две категории:
Итак, как же мы синхронизируем состояние наших важных данных в базе и аватара, который находится на другом сервере? Всё на самом деле довольно просто. Рассмотрим схему взятия предмета.
В Skyforge мы отказались от MySQL по совокупности причин, перечисленных ниже.
PostgreSQL решал все эти проблемы, взамен давая только проблему с автовакуумом. Базу NoSQL мы решили не брать, т.к. у нас очень высокие требования к консистентности данных, а ни одна в мире NoSQL-база не может консистентно и транзакционно переложить предмет от одного аватара другому. Eventual consistency в этом случае нас не очень устраивал, т.к. это сильно портит game experience.
То, что мы используем PostgreSQL, ещё не значит, что мы должны хранить данные в реляционном виде. Реляционную базу можно использовать в качестве key-value storage
Полностью реляционная модель нас не устраивает, т.к. содержит в себе несколько узких мест, критичных для производительности. Например, у нас есть игрок, а у него есть квесты. Игрок может выполнить сотни квестов, и при входе в игру нам надо будет их все показать. Если пользоваться реляционной моделью, придётся делать запрос на выдачу сотни строк из базы, а это медленно. С другой стороны, нереляционная модель имеет множество минусов: отсутствие констрейнтов, невозможность обновить данные частично и т.п.
После разнообразных экспериментов мы сошлись на том, что нас удовлетворяет связка реляционной модели, в которой часть полей содержит нереляционные данные. В Аллодах и до недавнего времени в Skyforge мы часть данных сериализовали бинарно и хранили в качестве полей в таблицах. Но буквально три недели назад мы наконец-то всё поняли и теперь храним данные в реляционной схеме с JSON-вставками.
Выглядит это примерно так:
Такая схема позволяет нам использовать все бонусы реляционной модели и компенсировать её узкие места нереляционными вставками на JSON. Кроме того, PostgreSQL 9.3 позволяет делать запросы по JSON. Таким образом, мы получаем эдакий коктейль два в одном — PostgreSQL и MongoDB по цене PostgreSQL.
Чтобы справиться с нагрузкой на запись, мы шардируем нашу базу данных по аккаунтам. Для этого мы в ID сущности кодируем номер шарда, на котором живёт аватар, и аккаунт.
ID состоит из двух частей: первый байт — номер шарда, остальные — ID сущности внутри шарда.
long id = <shard_id> <account_id>
В игре существует несколько десятков сервисов баз данных. Каждый из них однотредовый и работает со своей маленькой базой. Несколько таких маленьких баз мы помещаем на один физический сервис. Такой подход используют многие интернет-гиганты, называется он virtual shards и решает проблему перебалансировки. Допустим, у нас есть два физических сервера, и на них лежит по 15 маленьких шардов. Если у нас вдруг появилось много пользователей и всё стало тормозить, мы просто покупаем ещё один сервер и перекладываем на него по 5 шардов со старых серверов. И вместо схемы 2х15 мы очень просто получаем схему 3х10. Таким образом, можно очень просто осуществлять перебалансировку без необходимости распиливать данные внутри базы данных.
Настоящей серебряной пулей в борьбе за перформанс для нас стал SSD. Твердотельные диски позволили нам записывать тысячи транзакций в секунду на диск без дорогостоящих RAID-массивов. И, что для нас очень важно, мы записываем данные на диск синхронно, без отложенных коммитов и отключения fsync.
Небольшое отступление. Наша игровая база данных на самом деле не очень большая, около 200 ГБ, и поэтому может уместиться на один SSD. Но если подойти к проблеме производительности базы с умом, с помощью SSD можно ускорить и бóльшие базы. На SSD достаточно положить файлы WAL PostgreSQL, в которые идёт основная нагрузка на запись, а остальные данные можно разместить на более медленных дисках. В результате от использования SSD может выиграть практически любой проект!
Есть четыре факта, комбинация которых привела нас к интересному решению.
Отсюда родилась отличная идея, как использовать процессорные мощности репличной машины и повысить надёжность хранения данных.

Базы данных, находящиеся на первом сервере, синхронно реплицируются на второй. Второй сервер синхронно реплицируется на первый. Таким образом, вместо пары master—slave мы получаем два полноценных сервера, двойное резервирование и наличие реплики, которую можно перевести в асинхронный режим и забэкапить без вреда для основного сервера.
Более подробно об этой и некоторых других темах вы можете узнать из видеозаписи доклада с Конференции разработчиков игр.
Cлайды доступны здесь.
На вопросы по БД в онлайн-играх с удовольствием отвечу в комментариях.
Остальные наши статьи о различных аспектах работки игр можно почитать на нашем сайте и в нашем сообществе Вконтакте
Меня зовут Андрей Фролов. Я ведущий программист Allods Team и работаю в команде сервера. Мой опыт разработки — почти 10 лет, но в игры я попал только в октябре 2009. В коллективе я уже больше трёх лет, с марта 2010. Начинал работу на Аллодах Онлайн, а сейчас на Skyforge. Занимаюсь всем, что так или иначе связано с сервером Skyforge и базами данных. В этой статье я расскажу о базах данных в онлайн-играх на примере Аллодов и Skyforge.

Если вы не очень любите читать, предлагаю пролистать статью до конца и посмотреть видеозапись моего доклада с Конференции разработчиков игр. Тем же, кто останется в посте, положен бонус — важное дополнение к докладу в виде рассказа о гибриде NoSQL-JSON и реляционной модели данных.
Эволюция
Игровая база — это типичная OLTP-система (много маленьких и коротких транзакций). Но использование баз данных в играх несколько отличается от их использования в вебе, банках и прочем энтерпрайзе. Во-первых, это связано с тем, что модель данных в играх существенно сложнее, чем в банках. Во-вторых, большинство программистов в геймдеве вышли из сурового мира C++, прихватив с собой бороду и любовь к бинарной запаковке. Абсолютно все они, если им надо сохранить персонажа на диск, первым делом хотят сериализовать его в файл. Именно так всё и начиналось в Аллодах Онлайн. Программисты сделали файловое хранилище, но быстро одумались и переписали всё под MySQL. Проект успешно запустили, люди играли, опыт копился.
Что у нас было в Аллодах:
- Java, MySQL
- Шарды. И каждый из них был рассчитан на некое ограниченное число игроков, находящихся онлайн
- Это количество игроков выдавало примерно 200 транзакций в секунду
- Сервис, который работает с базой, был однотредовым, т.к. этого было достаточно для такого количества транзакций
Через несколько лет стартовал Skyforge. У Skyforge были совсем другие требования, и поэтому пришлось пересмотреть наш подход к работе с базами.
Вот эти требования:
- У нас больше нет шардов. У нас один большой единый мир
- Мы рассчитываем наш сервер на 100000 игроков, находящихся онлайн, а возможно и больше
- По нашим прикидкам, эти игроки должны выдавать более 7000 транзакций в секунду
- Мы всё так же пишем на Java, но с MySQL мы перешли на PostgreSQL
Ну что же, давайте заглянем за кулисы и посмотрим, к чему мы пришли в ходе эволюционного развития нашей технологической мысли.
Архитектура
Во-первых, наш сервер распределённый. База тоже распределённая. Во-вторых, архитектура нашего сервера — сервисно-ориентированная. Это значит, что всё представлено в виде сервисов, которые обмениваются сообщениями. В игре существуют десятки сервисов, но прямой доступ к базе данных есть только у сервисов исполнения транзакций. В общем виде и в меру моих художественных способностей это выглядит примерно вот так:

Нужно только учесть, что все изображённые на картинке элементы существуют в нескольких экземплярах.
- На серверах игровой механики находятся аватары. Аватар — это Java-объект, представляющий нашего игрока. Серверов игровой механики в несколько раз больше, чем серверов баз данных.
- Все сервера общаются с базой данных посредством специального интерфейса. Этот интерфейс содержит сотни методов, скрывает от программистов игровой механики распределённую сущность базы и обеспечивает понятный контракт: один метод — одна транзакция. Нужно понимать, что это не один класс с сотней методов, а один класс с десятью методами, который отдают маленькие «подинтерфейсы» с десятью методами каждый. Эдакие «паки» операций.
- Сервис БД (базы данных) выполняет пришедшие операции и записывает их результаты в базу. Сервис БД и сама БД находятся на одном физическом сервере, чтобы не тратить лишнее время на сеть.
Аватар как кэш
Эта нехитрая схема имеет один важный момент. Наш аватар нужен для работоспособности игровой механики, но как побочный эффект он же фактически является кэшем над базой данных. Все запросы вида «Покажи мне предметы этого игрока» или «А где находится аватар Василий?» обслуживаются этим аватаром. Когда игрок входит в игру, мы загружаем его аватара, и он живёт до тех пор, пока игрок онлайн. Такой нехитрый трюк позволяет снять с базы большую часть запросов на чтение и даже часть запросов на запись.
Мы делим все данные игрока на две категории:
- Неважные данные, потерю которых игрок может пережить. К ним относятся позиция на карте, уровень здоровья и т.п. Такие данные мы «накапливаем» у аватара и периодически, а также один раз при выходе из игры скидываем в базу.
- Важные данные, потеря которых будет для игрока болезненной. К ним относятся предметы, деньги, квесты и подобные вещи. С этими данными всё гораздо сложнее. Мы стараемся сделать так, чтобы игрок не потерял эти данные никогда, т.к. на них он потратил очень много времени и сил. Поэтому их надо сохранять в базу синхронно. Именно сохранение важных данных и создаёт основную нагрузку на нашу базу.
Итак, как же мы синхронизируем состояние наших важных данных в базе и аватара, который находится на другом сервере? Всё на самом деле довольно просто. Рассмотрим схему взятия предмета.
- Сервер игровой механики присылает запрос к сервису базы данных «взять предмет ХХХ».
- Сервер БД выполняет необходимые проверки (достаточно ли в сумке места, не нужно ли «застекать» эту вещь и так далее). После этого он сохраняет обновлённое состояние сумки аватара в базу.
- Только если сохранение прошло успешно, аватару отсылается обновление состояния его сумки. Аватар, в свою очередь, отправляет обновления в игровой клиент. В результате игрок увидит, что у него появился предмет, только тогда, когда предмет надёжно сохранён в базу.
PostgreSQL
В Skyforge мы отказались от MySQL по совокупности причин, перечисленных ниже.
- В MySQL все фичи размазаны по различным движкам хранения. Что-то было в InnoDB, что-то в MyISAM, что-то в движке MEMORY. Это сильно усложняло жизнь.
- В MySQL сломан механизм распределённых транзакций, который нам очень хотелось использовать. Разработчики MySQL обещали его починить только к шестой версии, которой нет ещё даже в планах.
- В MySQL был сломан механизм группового коммита. Его починили в версии 5.5, и этот пункт уже не актуален.
- В MySQL на самом деле довольно много багов, странно работающих фич и весьма ограниченный оптимизатор запросов.
PostgreSQL решал все эти проблемы, взамен давая только проблему с автовакуумом. Базу NoSQL мы решили не брать, т.к. у нас очень высокие требования к консистентности данных, а ни одна в мире NoSQL-база не может консистентно и транзакционно переложить предмет от одного аватара другому. Eventual consistency в этом случае нас не очень устраивал, т.к. это сильно портит game experience.
Гибридная схема данных
То, что мы используем PostgreSQL, ещё не значит, что мы должны хранить данные в реляционном виде. Реляционную базу можно использовать в качестве key-value storage
Полностью реляционная модель нас не устраивает, т.к. содержит в себе несколько узких мест, критичных для производительности. Например, у нас есть игрок, а у него есть квесты. Игрок может выполнить сотни квестов, и при входе в игру нам надо будет их все показать. Если пользоваться реляционной моделью, придётся делать запрос на выдачу сотни строк из базы, а это медленно. С другой стороны, нереляционная модель имеет множество минусов: отсутствие констрейнтов, невозможность обновить данные частично и т.п.
После разнообразных экспериментов мы сошлись на том, что нас удовлетворяет связка реляционной модели, в которой часть полей содержит нереляционные данные. В Аллодах и до недавнего времени в Skyforge мы часть данных сериализовали бинарно и хранили в качестве полей в таблицах. Но буквально три недели назад мы наконец-то всё поняли и теперь храним данные в реляционной схеме с JSON-вставками.
Выглядит это примерно так:
# select * from avatar limit 1;
id | 144115188075857124
position |
{"point":{"x":7402.2793,"y":6080.2197,"z":51.42402},"yaw":0.0,"map":"id:132646944","isLocal":false,"isValid":true}
death_descriptor | {"deathTime":-1,"respawnTime":-1,"sparkReturnDelay":-1,"recentDeathTimesArray":[]}
health | 1250
mana_descriptor | {"mana":{"8":300}}
avatar_client_info | \x
character_race_class_res_id | 26209282
character_sex_res_id | 550995
last_online_time | 1371814800726
Такая схема позволяет нам использовать все бонусы реляционной модели и компенсировать её узкие места нереляционными вставками на JSON. Кроме того, PostgreSQL 9.3 позволяет делать запросы по JSON. Таким образом, мы получаем эдакий коктейль два в одном — PostgreSQL и MongoDB по цене PostgreSQL.
Virtual shards
Чтобы справиться с нагрузкой на запись, мы шардируем нашу базу данных по аккаунтам. Для этого мы в ID сущности кодируем номер шарда, на котором живёт аватар, и аккаунт.
ID состоит из двух частей: первый байт — номер шарда, остальные — ID сущности внутри шарда.
long id = <shard_id> <account_id>
В игре существует несколько десятков сервисов баз данных. Каждый из них однотредовый и работает со своей маленькой базой. Несколько таких маленьких баз мы помещаем на один физический сервис. Такой подход используют многие интернет-гиганты, называется он virtual shards и решает проблему перебалансировки. Допустим, у нас есть два физических сервера, и на них лежит по 15 маленьких шардов. Если у нас вдруг появилось много пользователей и всё стало тормозить, мы просто покупаем ещё один сервер и перекладываем на него по 5 шардов со старых серверов. И вместо схемы 2х15 мы очень просто получаем схему 3х10. Таким образом, можно очень просто осуществлять перебалансировку без необходимости распиливать данные внутри базы данных.
SSD
Настоящей серебряной пулей в борьбе за перформанс для нас стал SSD. Твердотельные диски позволили нам записывать тысячи транзакций в секунду на диск без дорогостоящих RAID-массивов. И, что для нас очень важно, мы записываем данные на диск синхронно, без отложенных коммитов и отключения fsync.
Небольшое отступление. Наша игровая база данных на самом деле не очень большая, около 200 ГБ, и поэтому может уместиться на один SSD. Но если подойти к проблеме производительности базы с умом, с помощью SSD можно ускорить и бóльшие базы. На SSD достаточно положить файлы WAL PostgreSQL, в которые идёт основная нагрузка на запись, а остальные данные можно разместить на более медленных дисках. В результате от использования SSD может выиграть практически любой проект!
Перекрёстная реплика
Есть четыре факта, комбинация которых привела нас к интересному решению.
- PostgreSQL предоставляет очень интересную фичу — синхронную репликацию.
- Большой прирост производительности от SSD позволяет несколько расслабиться и не приносить надёжность в жертву скорости.
- Для резервирования и других служебных целей каждому серверу БД необходим сервер-реплика.
- Накат реплики тратит существенно меньше ресурсов, чем выполнение тех же самых операций на мастере. Ресурсы репличного сервера практически всегда простаивают.
Отсюда родилась отличная идея, как использовать процессорные мощности репличной машины и повысить надёжность хранения данных.
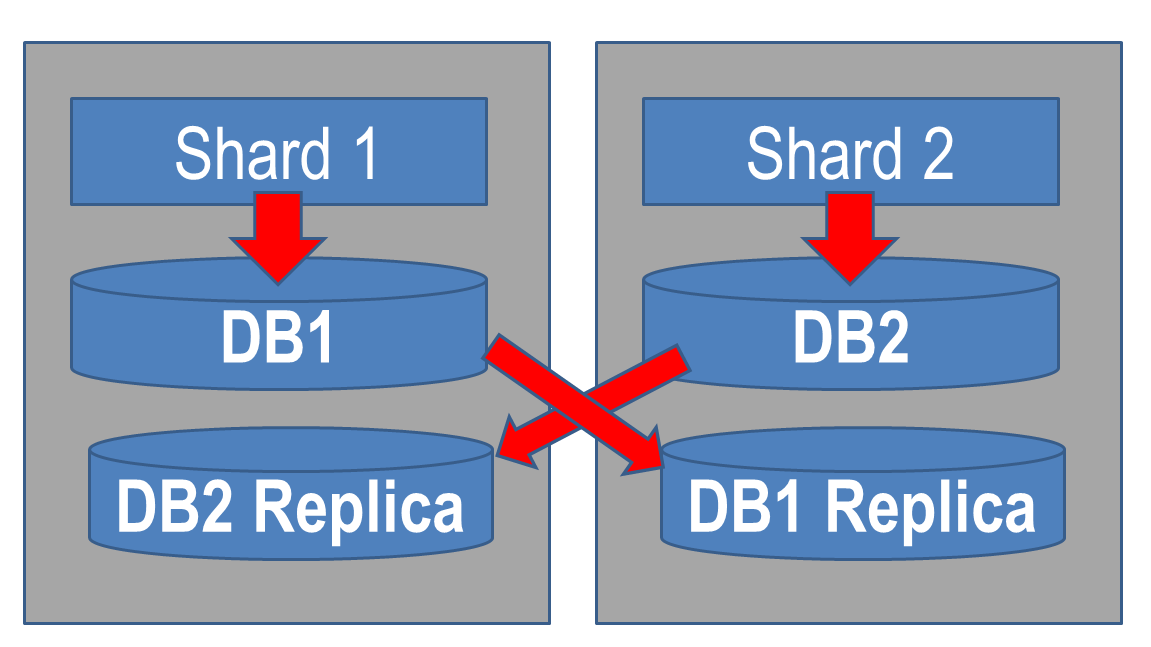
Базы данных, находящиеся на первом сервере, синхронно реплицируются на второй. Второй сервер синхронно реплицируется на первый. Таким образом, вместо пары master—slave мы получаем два полноценных сервера, двойное резервирование и наличие реплики, которую можно перевести в асинхронный режим и забэкапить без вреда для основного сервера.
Видео, слайды
Более подробно об этой и некоторых других темах вы можете узнать из видеозаписи доклада с Конференции разработчиков игр.
Cлайды доступны здесь.
На вопросы по БД в онлайн-играх с удовольствием отвечу в комментариях.
Остальные наши статьи о различных аспектах работки игр можно почитать на нашем сайте и в нашем сообществе Вконтакте
