
Изначально в нашем IMAP-сервере использовался epoll-реактор собственной разработки. Как всегда, в процессе эксплуатации и роста нагрузки потихоньку набегают замечания, в результате чего со временем начинает накапливаться технический долг и замедляться разработка.
В нашем случае были также изначальные архитектурные замечания.
Лирическое отступление про IProto: протокол очень простой: заголовок из трёх полей типа uint32_t: команда, номер пакета, длина данных. За счет поля «номер пакета» сервер может отвечать на запросы в любом порядке, а клиент может ждать ответа в асинхронном стиле и слать следующий запрос. В Mail.Ru Group он используется повсеместно — начиная с нашей Tarantool, и заканчивая сервисом антибрутфорса.
Поэтому было решено сделать тестовую версию, используя boost::asio. В этом посте я расскажу о переезде на реактор boost::asio, о его преимуществах и о подводных камнях, с которыми мы столкнулись.
Почему выбрали именно boost::asio? Как правило, асинхронное приложение подразумевает не только опрос сокетов при помощи epoll. В реальном приложении еще нужны таймеры, треды, стратегии предотвращения RC, корректная работа с SSL, родная поддержка IPv6. boost::asio позволяет делать это все в C++ стиле естественным образом.
Процесс переезда
Заменить реактор оказалось довольно просто. Этому помогло несколько факторов.
Некоторые вещи были удалены полностью, например, функционал сбора статистики. Это был осознанный шаг: для выполнения прямых обязанностей сервера это не нужно, статистика собирается «на ходу» по логам, плюс готовится отправка UDP в graphit, плюс атомарные переменные для мониторинга внутреннего состояния сервера.
В целом, увеличение стабильности и отзывчивости сервера было налицо уже в первой релизной версии, что, конечно же, порадовало. Конечно, не все было так радужно — были и некоторые проблемы. Например, с asio::strand, с настройкой правильного самоуничтожения объектов соединения, с «тяжелыми» операциями APPEND, COPY, FETCH, с boost::asio::streambuf, который не любит отдавать память. Но обо всем по порядку.
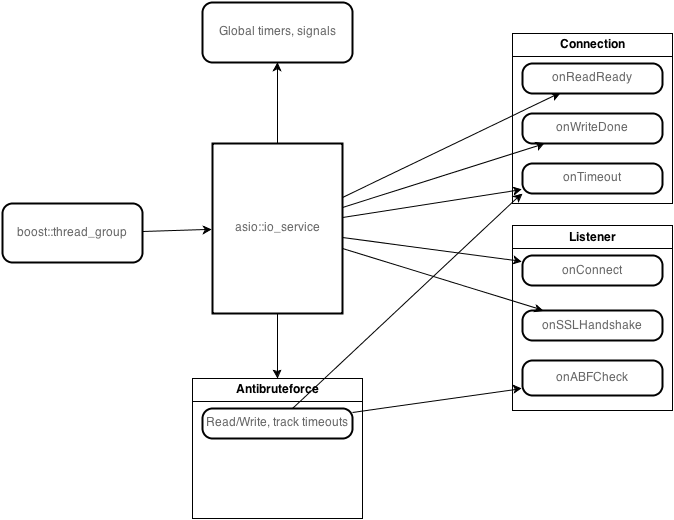
Структура сервера
Структура больше всего похожа на HTTP Server 3 из примеров boost::asio.
События обслуживаются пулом тредов, который запускает один инстанс io_service::run. Это позволяет достигнуть более высокой отзывчивости сервера, т.к. любой свободный поток может выполнить обработчик события, если он готов к выполнению.
Состояние соединения с каждым клиентом обслуживается своим экземпляром класса, реализующим базовые функции приёма/передачи/отслеживания таймаутов. Далее от него наследуются классы состояний согласно RFC: неавторизованные, авторизованные. Базовый класс содержит в себе экземпляры классов deadline_timer для отслеживания таймаутов соединения, дескриптор сокета (в нашем случае это asio::ssl::stream, т.к. в нем инкапсулируется SSL-шифрование), asio::strand для предотвращения одновременных срабатываний обработчиков событий (т.к. они являются методами этого же класса, нужно предотвратить race condition).
Есть отдельный класс Listener, который занимается прослушиванием портов, акцептом соединений на них, установкой SSL handshake. Его обработчики срабатывают в том же пуле тредов.
Различные «тяжелые» операции выполняются по-особому. Надолго блокировать strand нежелательно, при этом команды могут быть достаточно долгими (например, COPY). Поэтому применяется обходной вариант, позволяющий запустить эту работу в безопасном в плане RC режиме, но в тоже время не блокировать strand. При получении команды сервер просто проверяет, что все параметры верны, запоминает их, отключает все события, которые могут вызвать RC, а затем через io_service::post вызывает метод, который, собственно, производит действие. Получается, что действие происходит в deattached-режиме, не мешая своей блокировкой выполнять другие запросы.
Особым образом также работает команда FETCH. Дело в том, что вывод команды может иметь весьма большой размер, поэтому у «медленных» клиентов буфер записи может «зависать» довольно надолго, что поедает память на сервере. Кроме того, если формировать ответ полностью, а потом отправлять, задержка до первого ответа становится довольно большой. Поэтому обработчик старается отправлять кусками по 1 МБ, но если письмо больше, его на части не режем, т.к. это сильно усложняет процесс без видимых преимуществ. С другой стороны, пока этот 1 МБ отправляется клиенту, мы можем подготовить и привести в нужный формат следующий кусок ответа.
Как asio ведет себя под нагрузкой
Если коротко — прекрасно. Обычно на одном фронтенде около 40 тыс. клиентских соединений. Плюс еще какое-то количество — к внутренним сервисам: базам, хранилищам и т.д. Не все из них контролируются реактором asio, но пока этого достаточно. CPU редко выходит за пределы 10-20%. С памятью не все так гладко: при этом количестве соединений ее потребление на уровне 6-7 ГБ, в основном из-за тяжести некоторых команд протокола и потребления памяти SSL.
Вероятно, многие слышали о проблеме 10K. Так вот, для asio это абсолютно не проблема, особенно если ваши библиотеки и подсистемы умеют работать в non-blocking режиме. Пожалуй, это самый важный момент приложения на asio и асинхронного приложения вообще. Когда этот момент решен, вы можете обслуживать сотни тысяч соединений, если, конечно, у вас хватит памяти и CPU. Так что я считаю, что в современном мире резонно говорить о проблеме C100K или C1M.
А на самом деле…
Встретили ли мы подводные камни при внедрении asio? Конечно да. Но, на мой взгляд, их довольно просто обойти. Начнем по порядку.
Первое — asio::strand. Для тех, кто не в курсе — это такой хелпер, который умеет оборачивать коллбеки своей логикой; она не даёт вызывать в разных тредах колблеки, которые были обернуты одним экземпляром strand. Таким образом, обеспечивается безопасность обработчиков событий в multithreaded-окружении. Но этот сыр оказался не бесплатным, а дело вот в чём: strand-ы внутри себя используют так называемые «strand implementations», причем их количество зашивается на стадии компиляции. Последние, в свою очередь, содержат mutex-ы. К чему это приводит? Допустим, у нас есть соединения A, B, C, а количество «strand implementations» равно 2. Если в одном из соединений, например A, происходит долгая операция, то соединения B и C в момент аллокации стренда для них могут попасть в тот же implementation, что и А. Тогда все их хендлеры заблокируются, пока А не завершит операцию. В этом смысле простой mutex на хендлерах соединений был бы более эффективным. Осознание этой проблемы пришло далеко не сразу, а решение очень простое — при компиляции проставляем дефайны BOOST_ASIO_ENABLE_SEQUENTIAL_STRAND_ALLOCATION и BOOST_ASIO_STRAND_IMPLEMENTATIONS, равный ожидаемому количеству соединений. Почему-то такая особенность не документирована нигде, кроме как в самом коде strand_service. Конечно, если все используемые протоколы у вас неблокирующие и приложение true-асинхронное, такая проблема вряд ли будет актуальна, но в нашем случае есть legacy библиотеки, работающие в блокирующем режиме, поэтому (пока) приходится искать обходы.
Также есть кое-какие особенности, связанные с буферами чтения/записи. Если использовать asio::streambuf, нужно понимать, что данный буфер не любит отдавать память — с этим приходится считаться и делать какие-то обходные телодвижения. Несколько расстраивает, что нет родного конкурентного буфера записи. Для протоколов вроде нашего IProto это было бы очень полезной возможностью — протокол подразумевает очень большое количество небольших пакетов. Еще из минусов — нет защиты от RC при записи в сокет, поэтому не стоит в режиме SSL (да и в обычном тоже!) делать параллельные async_write; опять же нужно организовывать очередь, либо механизм переключения буферов записи, либо просто каким-то способом предотвращать параллельные вызовы. А здесь опять возникают дополнительные проблемы: если пир пропадет, буфер записи может продолжать расти, пока текущий async_write не поймет, что пира больше нет. Это может скушать вашу память, что, конечно же, опять-таки отразится на максимуме открытых соединений.
Возможно, это очевидный для многих факт, но все-таки хотелось бы подчеркнуть его отдельно: 10 тыс. соединений «наружу» — это не то же самое, что 10 тыс. соединений на каком-либо внутреннем сервисе, куда ходят только «свои». В первом случае могут произойти просто невероятные вещи, борьба с которыми и представляет наибольшую сложность. Это могут быть странные клиенты, которые умудряются отключаться до завершения SSL handshake. Могут быть и жутко медленные, которые закачивают к вам письмо размером 40 МБ со скоростью 256 Кбит/с. Звучит просто, однако команда APPEND принимает тело письма в качестве литерала; это означает, что пока письмо не закачано, команда еще не отдана и должна так или иначе находиться в памяти, а память, как известно, не резиновая. В случае с командой FETCH все наоборот: если у клиента скорость приёма медленная, а вы хотите отправить 1 МБ, этот кусок данных находится у вас в памяти до тех пор, пока он не отправится.
Поэтому, если ваш сервис смотрит «наружу», нужно учитывать очень много факторов. Такие проверенные библиотеки, как asio, снимают с вас множество проблем, о которых можно узнать только «на бою».
Заключение, планы по развитию сервера
В целом мы довольны. Сервис стал работать стабильнее, обрабатывать больше соединений, гораздо меньше крэшиться.
Дальнейшее развитие сервера неминуемо — мы планируем улучшать стабильность, расширять поддержку rfc extensions, в том числе IDLE; думаю, boost::asio легко поможет нам в этом. Пока трудно представить, сколько соединений могло бы одновременно находиться в состоянии IDLE, но, полагаю, очень много. Возможно, эффект от этого будет не так уж велик, так как многие мобильные клиенты (а сейчас их большинство) не умеют IDLE. Но сделать это на asio будет весьма просто, поэтому со стороны IMAP-сервера это вовсе не сложная доработка.
Также на подходе новые внутренние сервисы, которые по своей природе асинхронны, а общение с ними происходит по нашему любимому протоколу IProto, что позволит меньше блокироваться и, следовательно, обрабатывать запросы быстрее.
Есть вопросы? Задавайте! Есть полезный опыт внедрения? Делитесь в комментариях!
Альберт Галимов,
Программист группы backend разработки Почты
В нашем случае были также изначальные архитектурные замечания.
- Поток, обслуживающий реактор, никак не контролировался и при поступлении контрольных сигналов мог произойти race-condition. С другой стороны, останавливать или замедлять этот поток нельзя, поэтому возможные пути обхода выглядели неприемлемыми.
- Реактор не умел работать в full-duplex режиме. Это ограничивало его использование только интерактивными протоколами, каким является IMAP. Однако между серверами мы часто используем протокол IProto, который подразумевает full-duplex связь.
Лирическое отступление про IProto: протокол очень простой: заголовок из трёх полей типа uint32_t: команда, номер пакета, длина данных. За счет поля «номер пакета» сервер может отвечать на запросы в любом порядке, а клиент может ждать ответа в асинхронном стиле и слать следующий запрос. В Mail.Ru Group он используется повсеместно — начиная с нашей Tarantool, и заканчивая сервисом антибрутфорса.
Поэтому было решено сделать тестовую версию, используя boost::asio. В этом посте я расскажу о переезде на реактор boost::asio, о его преимуществах и о подводных камнях, с которыми мы столкнулись.
Почему выбрали именно boost::asio? Как правило, асинхронное приложение подразумевает не только опрос сокетов при помощи epoll. В реальном приложении еще нужны таймеры, треды, стратегии предотвращения RC, корректная работа с SSL, родная поддержка IPv6. boost::asio позволяет делать это все в C++ стиле естественным образом.
Процесс переезда
Заменить реактор оказалось довольно просто. Этому помогло несколько факторов.
- В старом реакторе точки чтения/записи были строго стандартизованы, т.к. вызывались из самого реактора, поэтому расставить коллбеки чтения/записи оказалось просто. Есть, конечно, исключения, в частности, обработка литералов и команды FETCH, у которой нужно ограничивать размер буфера записи.
- Таймеры работали отдельно от самого реактора, поэтому он были полностью заменены родным для asio deadline_timer.
- В качестве стратегии предотвращения RC используется asio::strand.
- boost::asio использует OpenSSL, которая, как известно, является общепринятым стандартом. Кроме того, скорость шифрования потока у OpenSSL существенно выше, чем у остальных библиотек (пруф).
Некоторые вещи были удалены полностью, например, функционал сбора статистики. Это был осознанный шаг: для выполнения прямых обязанностей сервера это не нужно, статистика собирается «на ходу» по логам, плюс готовится отправка UDP в graphit, плюс атомарные переменные для мониторинга внутреннего состояния сервера.
В целом, увеличение стабильности и отзывчивости сервера было налицо уже в первой релизной версии, что, конечно же, порадовало. Конечно, не все было так радужно — были и некоторые проблемы. Например, с asio::strand, с настройкой правильного самоуничтожения объектов соединения, с «тяжелыми» операциями APPEND, COPY, FETCH, с boost::asio::streambuf, который не любит отдавать память. Но обо всем по порядку.
Структура сервера
Структура больше всего похожа на HTTP Server 3 из примеров boost::asio.
События обслуживаются пулом тредов, который запускает один инстанс io_service::run. Это позволяет достигнуть более высокой отзывчивости сервера, т.к. любой свободный поток может выполнить обработчик события, если он готов к выполнению.
Состояние соединения с каждым клиентом обслуживается своим экземпляром класса, реализующим базовые функции приёма/передачи/отслеживания таймаутов. Далее от него наследуются классы состояний согласно RFC: неавторизованные, авторизованные. Базовый класс содержит в себе экземпляры классов deadline_timer для отслеживания таймаутов соединения, дескриптор сокета (в нашем случае это asio::ssl::stream, т.к. в нем инкапсулируется SSL-шифрование), asio::strand для предотвращения одновременных срабатываний обработчиков событий (т.к. они являются методами этого же класса, нужно предотвратить race condition).
Есть отдельный класс Listener, который занимается прослушиванием портов, акцептом соединений на них, установкой SSL handshake. Его обработчики срабатывают в том же пуле тредов.
Различные «тяжелые» операции выполняются по-особому. Надолго блокировать strand нежелательно, при этом команды могут быть достаточно долгими (например, COPY). Поэтому применяется обходной вариант, позволяющий запустить эту работу в безопасном в плане RC режиме, но в тоже время не блокировать strand. При получении команды сервер просто проверяет, что все параметры верны, запоминает их, отключает все события, которые могут вызвать RC, а затем через io_service::post вызывает метод, который, собственно, производит действие. Получается, что действие происходит в deattached-режиме, не мешая своей блокировкой выполнять другие запросы.
Особым образом также работает команда FETCH. Дело в том, что вывод команды может иметь весьма большой размер, поэтому у «медленных» клиентов буфер записи может «зависать» довольно надолго, что поедает память на сервере. Кроме того, если формировать ответ полностью, а потом отправлять, задержка до первого ответа становится довольно большой. Поэтому обработчик старается отправлять кусками по 1 МБ, но если письмо больше, его на части не режем, т.к. это сильно усложняет процесс без видимых преимуществ. С другой стороны, пока этот 1 МБ отправляется клиенту, мы можем подготовить и привести в нужный формат следующий кусок ответа.

Как asio ведет себя под нагрузкой
Если коротко — прекрасно. Обычно на одном фронтенде около 40 тыс. клиентских соединений. Плюс еще какое-то количество — к внутренним сервисам: базам, хранилищам и т.д. Не все из них контролируются реактором asio, но пока этого достаточно. CPU редко выходит за пределы 10-20%. С памятью не все так гладко: при этом количестве соединений ее потребление на уровне 6-7 ГБ, в основном из-за тяжести некоторых команд протокола и потребления памяти SSL.
Вероятно, многие слышали о проблеме 10K. Так вот, для asio это абсолютно не проблема, особенно если ваши библиотеки и подсистемы умеют работать в non-blocking режиме. Пожалуй, это самый важный момент приложения на asio и асинхронного приложения вообще. Когда этот момент решен, вы можете обслуживать сотни тысяч соединений, если, конечно, у вас хватит памяти и CPU. Так что я считаю, что в современном мире резонно говорить о проблеме C100K или C1M.
А на самом деле…
Встретили ли мы подводные камни при внедрении asio? Конечно да. Но, на мой взгляд, их довольно просто обойти. Начнем по порядку.
Первое — asio::strand. Для тех, кто не в курсе — это такой хелпер, который умеет оборачивать коллбеки своей логикой; она не даёт вызывать в разных тредах колблеки, которые были обернуты одним экземпляром strand. Таким образом, обеспечивается безопасность обработчиков событий в multithreaded-окружении. Но этот сыр оказался не бесплатным, а дело вот в чём: strand-ы внутри себя используют так называемые «strand implementations», причем их количество зашивается на стадии компиляции. Последние, в свою очередь, содержат mutex-ы. К чему это приводит? Допустим, у нас есть соединения A, B, C, а количество «strand implementations» равно 2. Если в одном из соединений, например A, происходит долгая операция, то соединения B и C в момент аллокации стренда для них могут попасть в тот же implementation, что и А. Тогда все их хендлеры заблокируются, пока А не завершит операцию. В этом смысле простой mutex на хендлерах соединений был бы более эффективным. Осознание этой проблемы пришло далеко не сразу, а решение очень простое — при компиляции проставляем дефайны BOOST_ASIO_ENABLE_SEQUENTIAL_STRAND_ALLOCATION и BOOST_ASIO_STRAND_IMPLEMENTATIONS, равный ожидаемому количеству соединений. Почему-то такая особенность не документирована нигде, кроме как в самом коде strand_service. Конечно, если все используемые протоколы у вас неблокирующие и приложение true-асинхронное, такая проблема вряд ли будет актуальна, но в нашем случае есть legacy библиотеки, работающие в блокирующем режиме, поэтому (пока) приходится искать обходы.
Также есть кое-какие особенности, связанные с буферами чтения/записи. Если использовать asio::streambuf, нужно понимать, что данный буфер не любит отдавать память — с этим приходится считаться и делать какие-то обходные телодвижения. Несколько расстраивает, что нет родного конкурентного буфера записи. Для протоколов вроде нашего IProto это было бы очень полезной возможностью — протокол подразумевает очень большое количество небольших пакетов. Еще из минусов — нет защиты от RC при записи в сокет, поэтому не стоит в режиме SSL (да и в обычном тоже!) делать параллельные async_write; опять же нужно организовывать очередь, либо механизм переключения буферов записи, либо просто каким-то способом предотвращать параллельные вызовы. А здесь опять возникают дополнительные проблемы: если пир пропадет, буфер записи может продолжать расти, пока текущий async_write не поймет, что пира больше нет. Это может скушать вашу память, что, конечно же, опять-таки отразится на максимуме открытых соединений.
Возможно, это очевидный для многих факт, но все-таки хотелось бы подчеркнуть его отдельно: 10 тыс. соединений «наружу» — это не то же самое, что 10 тыс. соединений на каком-либо внутреннем сервисе, куда ходят только «свои». В первом случае могут произойти просто невероятные вещи, борьба с которыми и представляет наибольшую сложность. Это могут быть странные клиенты, которые умудряются отключаться до завершения SSL handshake. Могут быть и жутко медленные, которые закачивают к вам письмо размером 40 МБ со скоростью 256 Кбит/с. Звучит просто, однако команда APPEND принимает тело письма в качестве литерала; это означает, что пока письмо не закачано, команда еще не отдана и должна так или иначе находиться в памяти, а память, как известно, не резиновая. В случае с командой FETCH все наоборот: если у клиента скорость приёма медленная, а вы хотите отправить 1 МБ, этот кусок данных находится у вас в памяти до тех пор, пока он не отправится.
Поэтому, если ваш сервис смотрит «наружу», нужно учитывать очень много факторов. Такие проверенные библиотеки, как asio, снимают с вас множество проблем, о которых можно узнать только «на бою».
Заключение, планы по развитию сервера
В целом мы довольны. Сервис стал работать стабильнее, обрабатывать больше соединений, гораздо меньше крэшиться.
Дальнейшее развитие сервера неминуемо — мы планируем улучшать стабильность, расширять поддержку rfc extensions, в том числе IDLE; думаю, boost::asio легко поможет нам в этом. Пока трудно представить, сколько соединений могло бы одновременно находиться в состоянии IDLE, но, полагаю, очень много. Возможно, эффект от этого будет не так уж велик, так как многие мобильные клиенты (а сейчас их большинство) не умеют IDLE. Но сделать это на asio будет весьма просто, поэтому со стороны IMAP-сервера это вовсе не сложная доработка.
Также на подходе новые внутренние сервисы, которые по своей природе асинхронны, а общение с ними происходит по нашему любимому протоколу IProto, что позволит меньше блокироваться и, следовательно, обрабатывать запросы быстрее.
Есть вопросы? Задавайте! Есть полезный опыт внедрения? Делитесь в комментариях!
Альберт Галимов,
Программист группы backend разработки Почты
