

В начале 2014 года к нам в отдел контентных проектов пришла задача унификации дизайна. Дизайнеры хотели единый стиль проектов и принципы работы интерфейсов. Это будет удобно пользователям, облегчит запуск новых проектов и редизайн существующих (более подробно об этом писал Юра Ветров). Команда фронтенда получит возможность использовать схожие компоненты верстки на разных проектах, что уменьшит время разработки и поддержки существующего функционала. Для команды бэкенда задача оказалась нетривиальной: большинство наших проектов написана на Perl (Template Toolkit), Недвижимость на PHP, Дети и Здоровье используют Django. Но от нас требовалось реализовать не только поддержку единого шаблонизатора, но и согласовать единый формат отдаваемых данных в шаблоны. Обилие подгружаемых AJAX-блочков требовало поддержку еще и клиентской шаблонизации.
Таким образом, задача унификации дизайна превратилась в задачу выбора единого шаблонизатора для Perl, Python, PHP и JS.
Первые шаги
Задача казалась сложной и в полной мере не решаемой, мы стали искать разные варианты. Начали с готовых решений. Первой идеей было портировать шаблонизатор Django Dotiac::DTL на Perl или template toolkit на Python. Template toolkit позволяет писать программную логику в шаблонах, это делает их непереносимыми на другие языки. Шаблоны Django значительно ограничивают программирование в шаблонах, но и от расширений в виде фильтров и своих тегов придется отказаться, либо дублировать логику на Perl и JS. Кроме того, неизвестно, насколько функциональны портированные версии. Таким образом, эта идея свелась к использованию базовых конструкций шаблонизатора (блоки условий if/else, циклов for, включений include). Для этого полноценный порт не нужен. А функционал, который хочется использовать, но нельзя по тем или иным причинам (например, не реализован на другом языке, либо реализован иначе), будет только мешать общему процессу. Поэтому до тестирования производительности мы так и не дошли. Эту идею отложили.
Вторая идея была использовать Mustache. Этот шаблонизатор доступен на множестве языков от популярных в вебе (PHP, Python, Perl, Ruby, JS) до весьма далеких от него (R, Bash, Delphi). Отсутствие логики в шаблонах поначалу даже привлекало: процесс подготовки данных для шаблонизации контролирует полностью бэкенд, никакой логики в самих шаблонах. Но это оказалось излишней крайностью. Подготовка данных показалась слишком трудоемкой, механизм инклюдов (partials) был неудобным, требовался сборщик шаблонов. Вместе с фразой «на мой взгляд, это кусок ада на земле» мы перестали рассматривать усы.
Еще была идея написать свой простой шаблонизатор на всех необходимых языках, либо мета-описание, из которого можно будет создавать нужные шаблоны. Задача выглядела трудоемкой, мы продолжили искать варианты.
Fest
Fest — это шаблонизатор, компилирующий XML шаблоны в JavaScript функции. В то время у нас уже был опыт использования феста в мобильных версиях. Основное отличие от больших версий было в том, что в то время поисковые роботы уделяли мало внимания мобильным версиям, и мы могли позволить себе шаблонизацию полностью на клиенте, экономив при этом ресурсы сервера. Выглядело это следующим образом в HTML-странице:
<script>
document.write(fest[’news.xml’], context)
</script>
Где context — это сериализованные в JSON данные. Отрендеренный HTML выводился в страницу через document.write.
Использование феста решает вопрос шаблонизации на клиенте, нам нужно было научиться исполнять этот JS на сервере. Команда фронтенда также поддержала этот вариант. Для исполнения JavaScript на сервере мы выбрали популярный V8 от Google. V8 развивается стремительно, но постоянные «Performance and stability improvements» часто ломают обратную совместимость даже в минорных версиях. Это понятно, V8 разрабатывается в первую очередь для Chrome — браузера, новые версии которого приходят взамен старым. Мы начали использовать V8, перенимая опыт наших коллег из Почты.
V8
Первым делом мы стали искать готовые решения — биндинги для Python и Perl. Немного помучавшись со сборкой пакетов (V8 значительно опережают свои биндинги, и подобрать совместимые версии оказалось непросто), мы стали их пробовать. Сразу же заметили дорогое поднятие контекста: создание контекста занимает порядка 10 мс, рендеринг шаблона — 20 мс. Таким образом, контекст должен создаваться 1 раз на запрос, а, в идеале, переиспользоваться последующими. Поэтому никакой речи не шло о том, чтобы встроить рендеринг общих компонентов на фесте в родной шаблонизатор (TemplateToolkit или Django). На фест надо переходить полностью.
Эти биндинги вполне внушали доверие, проекты развивались, в интернете публиковались примеры использования. И мы стали их использовать. В то время шел редизайн проектов Авто (Perl) и Здоровье (Python), на них мы испытывали новую технологию. В контроллерах мы формировали контекст, сериализовали его в JSON, и отправляли в загруженный шаблон:
ctx = PyV8.JSContext()
with ctx:
ctx.eval(template)
ctx.eval('fest["%s"](%s)' % (fest_template_name, json_context)
Это был рабочий вариант, но все оказалось не так радужно. Помимо, собственно, шаблонов, существуют общие утилиты-хелперы. Их следует загружать в V8 один раз и использовать при рендеринге страниц. Обертки над V8 позволяли загружать такой код, но делать это нужно было строго один раз. Повторная загрузка приводила к утечке памяти. То же происходило и с кодом шаблонов. В результате контекст создавался на каждый запрос, а после — убивался. Шаблонизация проходила медленно, значительно тратились ресурсы процессора, но память не текла. Но все работало более-менее стабильно. В итоге Авто запустился на этой схеме.
Обертки над V8 позволяют использовать объекты языка в контексте JavaScript. Но в случае с PyV8 это совсем не работает. Все версии, которые я пробовал, либо быстро утекали, либо очищали память, но падали в segfault. Использование биндингов свелось чисто к исполнению JavaScript с некоторым оверхедом, так как биндинг честно проверяет тип переданных объектов. На Здоровье пробовать PyV8 в бою мы уже не стали.
Тем временем коллеги с почты поделились своим решением. Это отдельно живущий демон, который получает имя шаблона и контекст (JSON-строка), в ответ отдает HTML, который мы отдаем пользователю. Во многом он решает наши проблемы. Демон умеет загружать общие хелперы на старте, кешировать в память шаблоны, работает стабильно по скорости и по памяти. Но все же это было не идеальное решение. Этот инструмент Почта разрабатывала под свои задачи, которые отличаются от наших. Их шаблоны значительно меньше и легче наших и исполняются быстрее. Ранее Андрей Сумин писал про 1 мc на шаблонизацию (JavaScript на сервере, 1ms на трансформацию), мы имеем в среднем 15-20 мс.
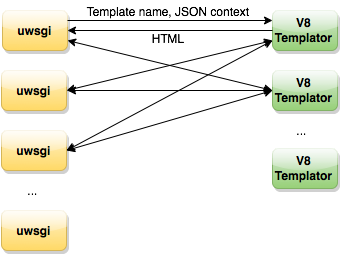
Их решение предполагает один процесс демона-шаблонизатора на сервер, мы себе это позволить не можем. Хотя для нас коллеги сделали мультипроцессорную версию, проблемы, требующие решения, оставались:
- Отдельно стоящий демон требует стабильной работы. Его работу нужно мониторить, уметь быстро переключаться на резервный сервер.
- Логи с ошибками не связаны с адресом страницы, на которой они возникают.
- Логи пишутся в файл, а не в общую систему сбора статистики.
- Чтобы не было задержек, надо иметь одинаковое количество воркеров бэкенда и демона-шаблонизатора.
Еще у нас был интересный случай. Однажды в шаблонах по ошибке возник вечный цикл, он полностью занимал воркера, это приводило к плачевным последствиям. Хотя подобных случаев впредь не возникало, защиты от таких ошибок у нас не было. В итоге с этой схемой запустилось Здоровье. Но на этом мы не остановились. Следующим шагом был отказ от отдельного демона, мы решили встроить шаблонизацию в исполняемый процесс Perl и Python. В итоге была написана общая обертка над V8, которая умела читать JS-файлы (хелперы и шаблоны), загружать код в память и исполнять (т.е. рендерить шаблоны в HTML).
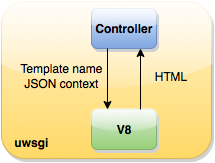
Модуль поднимает один контекст V8 на процесс и всю дальнейшую работу ведет в рамках него. В результате такого подхода родилось и название для библиотеки — V8MonoContext. Затем мы написали XS-модуль на Perl и расширение для Python, использующие эти функции в контексте языка:
renderer = MonoContext()
renderer.load_file(utils_file)
append_str = 'fest["{}.xml"]( JSON.parse(__dataFetch()) );'.format(bundle)
html, errors = renderer.execute_file(template_file, append_str, json_str)
Хелперы загружаются 1 раз при старте процесса с помощью метода load_file. Метод execute_file загружает шаблон, вызывает функцию шаблона, в которую передается JSON с данными для шаблонизации. В результате мы получаем HTML и список возможных ошибок, которые можно логировать через стандартные средства самого бэкенда. Сейчас это решение нас полностью устраивает:
- Шаблонизация является неотъемлемой частью обработки запроса пользователя внутри одного воркера. Мы можем измерить, сколько времени она занимает, логировать возможные ошибки.
- Контекст V8 поднимается один раз при старте воркера.
- JS-код загружается один раз, ресурсы сервера расходуются оптимально.
- V8 потребляет больше памяти, чем «родные» шаблонизаторы языка. Резидентная память воркеров увеличилась в среднем на 200 Мб, в максимуме на 300 Мб.
- Также не поддерживается тредовый режим, что может быть актуально для Python-проектов. Внутри одного процесса может исполняться только один контекст, остальные в это время должны быть неактивны. Так работает V8 в Chrome. Но это нам не мешает, мы работаем в prefork-режиме.
Наблюдаются и другие особенности работы V8, связанные с GC. V8 запускает свой сборщик мусора в то время, как он посчитает нужным, как правило, если память начинает заканчиваться. Существует 2 метода жить с этим:
- Запастись оперативной памятью и полностью довериться V8. Контекст V8 погибнет вместе с воркером через заданное значение MaxRequest.
- С некоторой периодичностью запускать «ручку» — сигнал о нехватке памяти LowMemoryNotification. Редкий запуск грозит продолжительной уборкой, частый будет расходовать лишние ресурсы процессора. Мы вызываем LowMemoryNotification каждые 500 запросов на шаблонизацию.
Еще можно ограничить размер выделяемой памяти для V8 (Memory management flags in V8). В этом случае GC будет запускаться чаще, но отрабатывать он будет быстрее. При нехватке памяти сервер может откладывать часть хипа в своп, а это приводит к дополнительным задержкам. В итоге на этой схеме запустилась Афиша, результаты нас полностью устроили. Вскоре с V8MonoContext научился работать PHP, следом подтянулись и другие наши проекты — Авто, Гороскопы, Здоровье, Леди, Недвижимость, Погода, Hi-Tech.
Сравнение производительности
Надо отметить, что скорость работы шаблонизатора на V8 (так же, как и любого другого активного шаблонизатора) зависит от того, с каким объемом данных он работает и какая логика к ней применяется. Чистое время рендеринга можно определить только на синтетических тестах, которые могут не всегда отражать реальную картину. В нашем случае переход с V8 происходил с редизайном, поэтому точных замеров у нас нет. Косвенно сравнивая метрики, мы получили выигрыш до 2 раз.
Подход к разработке
С переходом на фест поменялся и подход к разработке:
- Общие компоненты шаблонов должны иметь единый интерфейс для проектов, которые его используют. Это требует определенного порядка и согласованности всех участников процесса. Мы начали описывать в документации формат передаваемых на фронт данных и следовать ему. Кроме этого, мы вырабатываем общие системные решения для разных бэкендов (Perl, Python, PHP), например, работа с CSRF-токенами.
- Общие компоненты расходятся по всем проектам, поэтому особенно важно, чтобы они работали быстро и эффективно.
- У нас получилась чистая MVC-схема, в которой бэкенд отдает данные и совсем не трогает шаблоны. Если на фронте каких-либо данных не хватает, нужно ждать бэкенда.
Выводы
Поставленную задачу перехода на единый шаблонизатор для Perl, Python, PHP мы решили. Теперь общие компоненты (например, комментарии, галереи, опросы) могут быстро внедряться и расходиться по всем нашим проектам. Жирным плюсом стала для нас клиентская шаблонизация: теперь перенести логику на сторону клиента практически ничего не стоит. Следующей в этой серии будет статья со стороны фронтенда, которую мои коллеги уже готовят.
