
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.На самом деле, мало кто действительно понимает, как работают реляционные БД. А многие разработчики очень не любят, когда они чего-то не понимают. Если реляционные БД используют порядка 40 лет, значит тому есть причина. РБД — штука очень интересная, поскольку в ее основе лежат полезные и широко используемые понятия. Если вы хотели бы разобраться в том, как работают РБД, то эта статья для вас.
Сразу нужно подчеркнуть: из этого материала вы НЕ узнаете, как можно использовать БД. Однако для усвоения материала вы должны уметь написать хотя бы простенький запрос на соединение и CRUD-запрос. Этого вполне достаточно для понимания статьи, остальное будет объяснено.
Статья состоит из трёх частей:
- Обзор низкоуровневых и высокоуровневых компонентов БД.
- Обзор процесса оптимизации запросов.
- Обзор управления транзакциями и буферным пулом.
1. Основы
Давным-давно (в далёкой-далёкой галактике) разработчики должны были держать в голове точное количество операций, которые они кодят. Они всем сердцем чувствовали алгоритмы и структуры данных, поскольку не могли себе позволить тратить впустую ресурсы процессора и памяти на своих медленных компьютерах прошлого. В этой главе мы вспомним некоторые концепции, которые необходимы для понимания работы БД.
1.1. О(1) против О(n2)
Сегодня многие разработчики не особо задумываются о временнόй сложности алгоритмов… и они правы! Но когда приходится работать с большим объёмом данных, или если нужно экономить миллисекунды, то временнáя сложность становится крайне важна.
1.1.1. Концепция
Временнáя сложность используется для оценки производительности алгоритма, как долго будет выполняться алгоритм для входных данных определённого размера. Обозначается временнáя сложность как «О» (читается как «О большое»). Это обозначение используется вместе с функцией, описывающей количество операций, осуществляемых алгоритмом для обработки входных данных.
Например, если сказать «этот алгоритм есть О большое от некоторой функции», то это означает, что для определённого объёма входных данных алгоритму нужно выполнить количество операций, пропорциональное значению функции от этого определённого объёма данных.
Здесь важен не объём данных, а динамика увеличения количества операций с ростом объёма. Временнáя сложность не позволяет вычислить точное количество, но зато представляет собой хороший способ оценки.
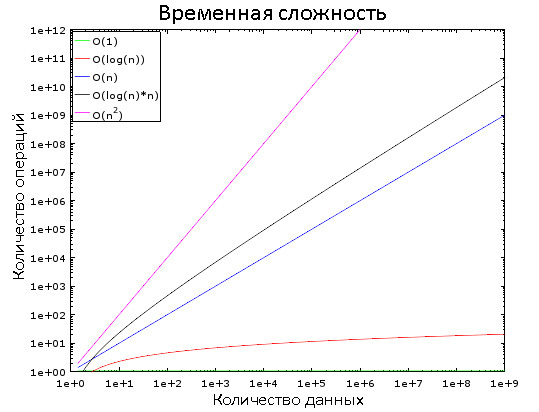
На этом графике вы видите, как изменяются разные классы сложностей. Для наглядности используется логарифмическая шкала. Иными словами, количество данных быстро увеличивается от 1 до 1 000 000. Мы видим, что:
- O(1) является «константным временем», то есть её значение постоянно.
- O(log(n)) — логарифмическое время, возрастает очень медленно.
- Хуже всего со сложностью обстоят дела у O(n2) — квадратичного времени.
- Два остальных класса сложности быстро возрастают.
1.1.2. Примеры
При небольшом количестве входных данных разница между О(1) и О(n2) пренебрежимо мала. Допустим, у нас есть алгоритм, которому нужно обработать 2000 элементов.
- Алгоритму с О(1) для этого потребуется 1 операция.
- O(log(n)) — 7 операций.
- O(n) — 2000 операций.
- O(n*log(n)) — 14 000 операций.
- O(n2) — 4 000 000 операций.
Кажется, что разница между О(1) и O(n2) огромна, но на деле вы потеряете не более 2 мс. Глазом моргнуть не успеете, в буквальном смысле. Современные процессоры выполняют сотни миллионов операций в секунду, и именно поэтому во многих проектах разработчики пренебрегают оптимизацией производительности.
Но возьмём теперь 1 000 000 элементов, что не слишком много по меркам БД:
- Алгоритму с О(1) для обработки потребуется 1 операция.
- O(log(n)) — 14 операций.
- O(n) — 1 000 000 операций.
- O(n*log(n)) — 14 000 000 операций.
- O(n2) — 1 000 000 000 000 операций.
В случае с последними двумя алгоритмами можно будет успеть выпить кофе. А если добавить ещё один 0 к количеству элементов, то за время обработки можно и вздремнуть.
1.1.3. Ещё немного подробностей
Чтобы вы могли ориентироваться:
- Поиск элемента в хорошей хэш-таблице занимает О(1).
- В хорошо сбалансированном дереве — O(log(n)).
- В массиве — O(n).
- Наилучшие алгоритмы сортировки имеют сложность O(n*log(n)).
- Плохие алгоритмы сортировки — O(n2).
Ниже мы рассмотрим эти алгоритмы и структуры данных.
Существует несколько классов временнόй сложности:
- Средняя сложность
- Сложность в наилучшем случае
- Сложность в наихудшем случае
Чаще всего встречается третий класс. Кстати, понятие «сложности» применимо также к потреблению алгоритмом памяти и операций ввода/вывода дисковой системы.
Существуют сложности куда хуже, чем n2:
- n4: характерно для некоторых плохих алгоритмов.
- 3n: ещё хуже! Ниже будет рассмотрен один алгоритм с подобной временнόй сложностью.
- n!: вообще адский треш. Замучаетесь ждать результат даже на небольших объёмах данных.
- nn: если вы дождались результата выполнения этого алгоритма, то впору задаться вопросом, а стоит ли вам вообще этим заниматься?
1.2. Сортировка слиянием
Что вы делаете, когда вам нужно отсортировать коллекцию? Вызываете функцию sort(), верно? Но понимаете ли вы, как она работает?
Есть несколько хороших алгоритмов сортировки, но здесь мы рассмотрим только один из них: сортировку слиянием. Возможно, сейчас вам это знание не кажется полезным, но вы поменяете мнение после глав про оптимизацию запросов. Более того, понимание работы этого алгоритма поможет понять принцип важной операции — соединение слиянием.
1.2.1. Слияние
В основе алгоритма сортировки слиянием лежит одна хитрость: для слияния двух отсортированных массивов размером N/2 каждый требуется всего лишь N операций, называющихся слиянием.
Рассмотрим пример операции слияния:
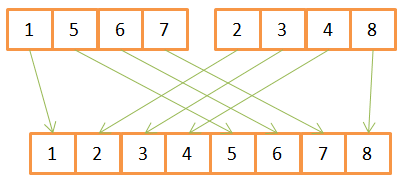
Как видите, для создания отсортированного массива из 8 элементов, для каждого из них нужно провести по одной итерации в двух исходных массивах. Поскольку они уже заранее отсортированы, то:
- Сначала в них сравниваются имеющиеся элементы,
- наименьший из них переносится в новый массив,
- а затем происходит возврат в тот массив, откуда был взят предыдущий элемент.
- Шаги 1-3 повторяются до тех пор, пока в одном из исходных массивов не останется лишь один элемент.
- После этого из второго массива переносятся все оставшиеся элементы.
Данный алгоритм хорошо работает лишь потому, что оба исходных массива были заранее отсортированы, поэтому ему не нужно возвращаться в их начало во время очередной итерации.
Пример псевдокода сортировки слиянием:
array mergeSort(array a)
if(length(a)==1)
return a[0];
end if
//recursive calls
[left_array right_array] := split_into_2_equally_sized_arrays(a);
array new_left_array := mergeSort(left_array);
array new_right_array := mergeSort(right_array);
//merging the 2 small ordered arrays into a big one
array result := merge(new_left_array,new_right_array);
return result;
Данный алгоритм разбивает задачу на ряд маленьких подзадач (парадигма «разделяй и властвуй»). Если вы не поняли сути, то попробуйте представить, что алгоритм состоит из двух фаз:
- Фаза деления — массив делится на более мелкие массивы.
- Фаза сортировки — мелкие массивы собираются вместе (сливаются).
1.2.2. Фаза деления
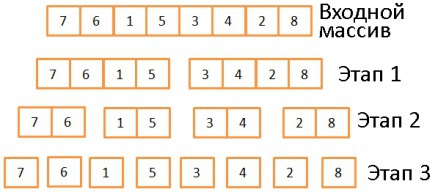
В три этапа исходный массив делится на подмассивы, состоящие из одного элемента. Вообще, количество этапов деления определяется как log(N) (в данном случае N=8, log(N) = 3). Идея в том, чтобы на каждом этапе делить входящие массивы пополам. То есть описывается логарифмом с основанием 2.
1.2.3. Фаза сортировки
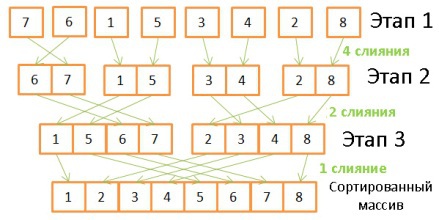
Здесь происходит обратная операция, объединение массивов с двукратным увеличением их размеров. Для этого требуется проделать на каждом этапе по 8 операций:
- На первом этапе происходит 4 слияния, по 2 операции каждое.
- На втором — 2 слияния по 4 операции.
- На третьем — 1 слияние из 8 операций.
Поскольку количество этапов определяется как log(N), то общее количество операций определяется как N * log(N).
1.2.4. Возможности сортировки слиянием
В чём преимущества данного алгоритма?
- Его можно модифицировать для уменьшения потребления памяти, если вы хотите не создавать новые массивы, а модифицировать входящий (так называемый «алгоритм замещения»).
- Его можно модифицировать для уменьшения потребления памяти и использования дисковой подсистемы, снизив количество операций ввода/вывода. Идея заключается в том, что в памяти находятся только те части данных, которые подвергаются обработке в конкретный момент времени. Это особенно важно, когда нужно сортировать многогигабайтные таблицы, а в наличии есть только буфер мегабайт на 100. Данный алгоритм называется «внешней сортировкой».
- Его можно модифицировать для запуска в нескольких параллельных процессах/потоках/серверах
- Например, распределённая сортировка слиянием является ключевой особенностью Hadoop.
Этот алгоритм может практически превращать свинец в золото! Он используется в большинстве (если не во всех) СУБД, хотя и не он один. Если вас интересует больше грязных подробностей, можете почитать одну исследовательскую работу, в которой разбираются плюсы и минусы распространённых алгоритмов сортировки.
1.3. Массив, дерево и хэш-таблица
Итак, с временнόй сложностью и сортировкой разобрались. Теперь давайте обсудим три структуры данных, на которых держатся современные БД.
1.3.1. Массив
Двумерный массив — простейшая структура данных. Таблица может быть представлена в виде массива:
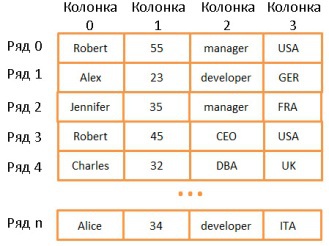
Здесь каждая строка представляет собой какой-то объект, колонка — свойство объекта. Причём разные колонки содержат разные типы данных (целые числа, строки, даты и т.д.).
Это очень удобный способ хранения и визуализации информации, но очень неподходящий для случаев, когда нужно найти какое-то конкретное значение. Допустим, вам нужно найти всех сотрудников, работающих в Великобритании. Для этого придётся просмотреть все строки, чтобы найти те, где имеется значение “UK”. На это потребуется N операций (N — количество строк). Не так уж и плохо, но хорошо бы и побыстрее. И здесь нам помогут деревья.
Примечание: большинство современных СУБД используют продвинутые виды массивов, позволяющие эффективнее хранить таблицы (например, на основе куч или индексов). Но это не решает проблему скорости поиска по колонкам.
1.3.2. Дерево и индекс БД
Бинарное дерево поиска — это дерево, в котором ключ в каждом узле должен быть:
- Больше, чем любой из ключей в ветке слева.
- Меньше, чем любой из ключей в ветке справа.
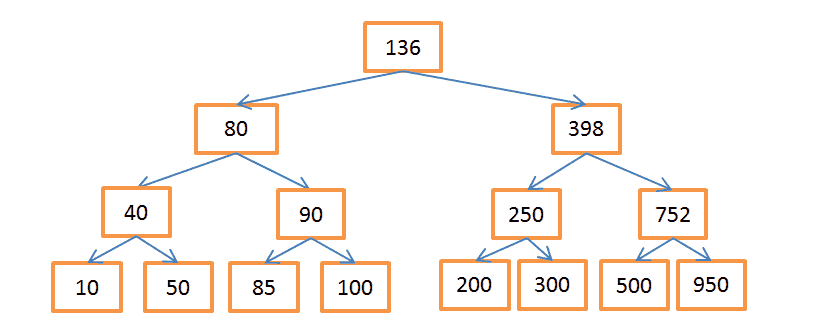
Каждый узел представляет собой указатель на строку в связанной таблице.
Вышеприведённое дерево содержит N = 15 элементов. Допустим, нам нужно найти узел со значением 208:
- Начнём с узла, содержащего ключ 136. Поскольку 136 < 208, то следуем по правой ветке дерева.
- 398 > 208, значит спускаемся по левой ветке, исходящей из этого узла.
- 250 > 208, опять идём по левой ветке.
- 200 < 208, нужно пойти по правой ветке. Но поскольку у узла с ключом 200 нет веток, то искомое значение не существует. Если бы оно существовало, то у узла-200 были бы ветки.
Допустим, теперь нужно найти узел со значением 40:
- Опять начинаем с корневого узла-136. Раз 136 > 40, значит идём по левой ветке.
- 80 > 40, снова «поворачиваем налево».
- 40 = 40, такой узел существует. Извлекаем ID строки, хранящийся в этом узле (это не значение ключа), и ищем по нему в связанной таблице.
- Зная ID строки, можно очень быстро извлечь нужные данные.
Каждая процедура поиска состоит из определённого количества операций по мере путешествия по ветвям дерева. Количество операций определяется как Log(N), так же как и в случае с сортировкой слиянием.
Но вернёмся к нашей проблеме.
Допустим, у нас есть строковые значения, соответствующие названиям разных государств. Соответственно и узлы дерева содержат строковые ключи. Чтобы найти сотрудников, работающих в “UK”, нужно просмотреть все узлы, чтобы найти соответствующий, и извлечь из него ID всех строк, содержащих данное значение. В отличие от поиска по массиву, здесь нам потребуется всего log(N) операций. Описанная конструкция называется индексом БД.
Такой индекс можно создать для любой группы колонок (для строковых, целочисленных, их комбинаций, дат и т.д.), если у вас есть функция для сравнения ключей (т.е. групп колонок). Таким образом вы можете распределить ключи в определённом порядке.
Индекс В+дерева
Несмотря на высокую скорость поиска, дерево плохо работает в случаях, когда нужно получить несколько элементов в пределах двух значений. Временнáя сложность будет равна О(N), потому что нам придётся просмотреть каждый узел и сравнить его с заданными условиями. Более того, данная процедура требует большого количества операций ввода/вывода, ведь нужно считывать всё дерево. То есть нам нужен более эффективный способ запроса диапазона. В современных БД для этого используется модифицированная версия дерева — В+дерево. Его особенность в том, что информацию (ID строк связанной таблицы) хранят лишь самые нижние узлы («листья»), а все остальные узлы предназначены для оптимизации поиска по дереву.
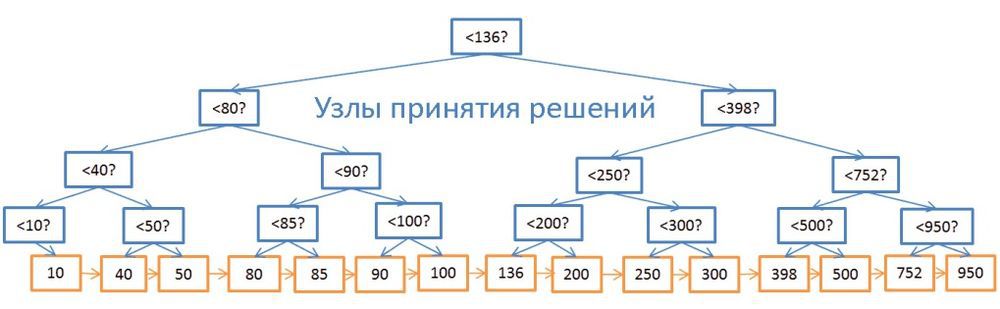
Как видите, здесь вдвое больше узлов. «Узлы принятия решений» помогают найти нужные узлы, содержащие ID строк в таблице. Но сложность поиска всё ещё равна О(log(N)) (добавился один уровень узлов). Однако главной особенностью B-дерева является то, что «листья» образуют наследственные связи.
Допустим, нам нужно найти значения в диапазоне от 40 до 100:
- Сначала ищем всё, что больше 40 или значения, ближайшего к нему, если 40 не существует. Совсем как в обычном дереве.
- А затем, с помощью связей наследования, выбираем всё, что меньше 100.
Пусть дерево содержит N узлов, и нам нужно выбрать М наследников. Для поиска конкретного узла потребуется log(N) операций, как и в обычном дереве. Но найдя его, мы тратим только М операций на поиск М наследников. То есть суммарно нам потребуется М + log(N) операций, в отличие от N в случае с обычным деревом. Нам даже не нужно считывать дерево целиком, а только М + log(N) узлов, так что дисковая система задействуется меньше. Если значение М невелико (например, 200), а N — напротив, большое, (1 000 000), то выигрыш в скорости поиска будет очень значителен.
Но есть ложка дёгтя на этом празднике жизни. Если вы добавляете или убираете строки в БД, а, следовательно, и в связанном индексе В+дерева, то:
- Необходимо сохранять порядок размещения узлов внутри В-дерева, иначе вы ничего не сможете найти.
- Нужно, чтобы В+дерево состояло из как можно меньшего количества уровней, иначе временнáя сложность будет не О(log(N)), а О(N).
Иными словами, В+дерево должно быть самоуправляемым и самобалансирующимся. В связи с низкоуровневой оптимизацией, В+деревья должны быть полностью сбалансированы. К счастью, всё это можно сделать с помощью операций «умного» удаления и вставки. Но за это приходится платить: операции вставки и удаления в В+дереве имеют сложность О(log(N)). Так что наверняка многим из вас знаком такой совет: не надо увлекаться созданием большого количества индексов. В противном случае сильно падает производительность при добавлении/обновлении/удалении строк, поскольку БД приходится актуализировать и всевозможные индексы, а каждый из них требует О(log(N)) операций. К тому же индексы увеличивают нагрузку на диспетчер транзакций, об этом мы поговорим ниже.
Подробнее о В+деревьях можно почитать на Википедии, а также в статьях (один, два) от ведущих разработчиков MySQL. В них рассказывается о том, как InnoDB (движок MySQL) работает с индексами.
1.3.3. Хэш-таблица
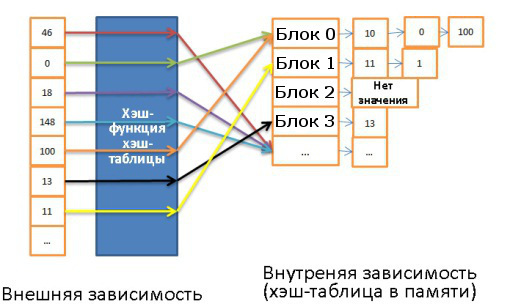
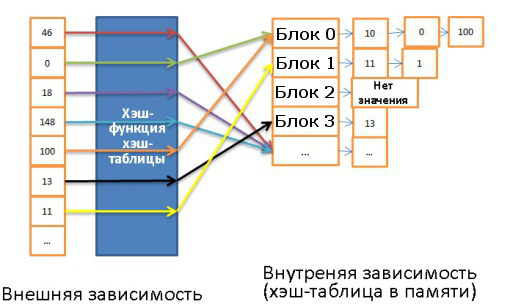
Эта структура данных очень полезна для случаев, когда особенно важна скорость поиска. Понимание работы хэш-таблицы необходимо для последующего понимания такой важной операции, как хэш-соединение (hash join). Хэш-таблица зачастую используется для хранения некоторых внутренних данных (таблицы блокировок, буферного пула). Данная структура используется для быстрого поиска элементов по их ключам. Для построения хэш-таблицы нужны:
- Ключ для каждого элемента.
- Хэш-функция, вычисляющая хэши по ключам. Хэши ещё называют блоками.
- Функция сравнения ключей. Найдя правильный блок, мы можем с помощью этой функции найти искомый элемент внутри блока.
Вот пример простой хэш-таблицы:
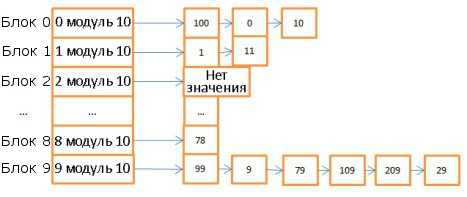
Здесь 10 блоков, в качестве хэш-функции брался модуль 10 от значения ключа. То есть для поиска нужного блока достаточно знать последнюю цифру значения ключа: если это 0, то элемент хранится в корзине 0, если 1, то в корзине 1, и т.д. В качестве функции сравнения используется операция сравнения двух целочисленных.
Допустим, нам нужно найти элемент 78:
- Хэш-таблица вычисляет значение хэша, оно равно 8.
- Обращаемся к блоку 8 и сразу находим искомый элемент.
То есть мы затратили всего две операции: на вычисление хэша и на поиск внутри блока.
- Теперь поищем элемент 59:
- Вычисляем хэш, он равен 9.
- Обращаемся к блоку 9, первый элемент равен 99. Поскольку 99 не равно 59, то сравниваем со вторым элементом (9), потом с третьим (79), и так далее вплоть до последнего (29).
- Искомый элемент отсутствует.
Итого мы затратили 7 операций.
Как видите, скорость поиска зависит от искомого значения. Изменим хэш-функцию, будет вычислять хэши по модулю 1 000 000 (то есть берём последние 6 цифр). В этом случае на поиск элемента 59 уйдёт лишь одна операция, поскольку в блоке 000059 нет никаких элементов. Поэтому крайне важно подобрать удачную хэш-функцию, которая будет генерировать блоки с очень небольшим количеством элементов.
В вышеприведённом примере нетрудно подобрать подходящий вариант. Но это слишком простой случай. Гораздо труднее выбрать хэш-функцию, если ключи:
- Строковые (например, фамилии).
- Двойные строковые (имена и фамилии).
- Двойные строковые с датой (добавляются даты рождения)
и т.д.
Но если вам удалось подобрать хорошую хэш-функцию, то сложность поиска по таблице будет равна О(1).
Массив против хэш-таблицы
Почему бы не использовать одни массивы? Дело в том, что:
- Хэш-таблицу можно загрузить в память наполовину, а остальное оставить на диске.
- В случае с массивом вам придётся использовать смежное пространство памяти. И если вы загружаете большую таблицу, то очень сложно обеспечить достаточный объём этого самого смежного пространства.
- Вы можете выбрать любые ключи для хэш-таблицы. Например, название государства И фамилию человека.
За подробностями можете обратиться к статье о Java HashMap, это пример эффективной реализации хэш-таблицы. Для этого вам не нужно разбираться в Java, если что.
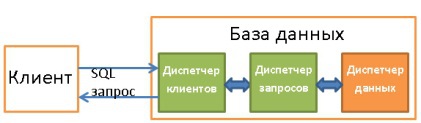
2. Общий обзор
Мы рассмотрели базовые компоненты БД. Теперь давайте отойдём назад и окинем взглядом всю картину.
БД представляет собой совокупность информации, к которой можно легко получить доступ и модифицировать. Но то же самое можно сказать и о группе файлов. По сути, простейшие БД, наподобие SQLite, как раз и представляют собой лишь кучки файлов. Но тут важно, как именно эти файлы организованы внутри и связаны между собой, поскольку SQLite позволяет:
- Использовать транзакции для обеспечения сохранности и связанности данных.
- Быстро обрабатывать данные вне зависимости от их объёма.
В общем виде структуру БД можно представить так:
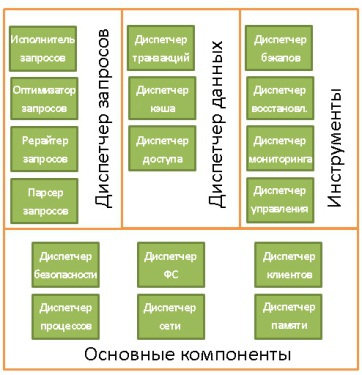
На самом деле, существует куча разных представлений о том, как может выглядеть структура БД. Так что не надо зацикливаться на данной иллюстрации. Нужно лишь усвоить, что БД состоит из различных компонентов, взаимодействующих между собой.
Основные компоненты БД (Core Components):
- Диспетчер процессов. Во многих БД имеется пул процессов/потоков, которыми нужно управлять. Причём в погоне за производительностью некоторые БД используют свои собственные потоки, а не предоставляемые ОС.
- Диспетчер сети. Пропускная способность сети имеет большое значение, особенно для распределённых БД.
- Диспетчер файловой системы. Первым «бутылочным горлышком» любой БД является производительность дисковой подсистемы. Поэтому очень важно иметь диспетчер, который идеально работает с файловой системой ОС или даже заменяет её.
- Диспетчер памяти. Чтобы не упереться в невысокую производительность дисковой подсистемы, нужно иметь много оперативной памяти. А значит, нужно эффективно ею управлять, что и делает данный диспетчер. Особенно когда у вас много одновременных запросов, использующих память.
- Диспетчер безопасности. Управляет аутентификацией и авторизацией пользователей.
- Диспетчер клиентов. Управляет клиентскими соединениями.
Инструменты (Tools):
- Диспетчер резервного копирования. Назначение очевидно.
- Диспетчер восстановления. Используется для восстановления когерентного состояния БД после сбоя.
- Диспетчер мониторинга. Занимается протоколированием всех активностей внутри БД и используется для наблюдения за её состоянием.
- Диспетчер общего управления. Хранит метаданные (вроде наименований и структуры таблиц) и используется для управления базами, схемами, табличными пространствами и т.д.
Диспетчер запросов (Query Manager):
- Парсер запросов. Проверяет их валидность.
- Рерайтер запросов. Осуществляет предварительную оптимизацию.
- Оптимизатор запросов.
- Исполнитель запросов. Компилирует и исполняет.
Диспетчер данных (Data Manager):
- Диспетчер транзакций. Занимается их обработкой.
- Диспетчер кэша. Используется для отправки данных перед использованием и перед записью на диск.
- Диспетчер доступа к данным. Управляет доступом к данным в дисковой подсистеме.
Далее мы рассмотрим, как БД управляет SQL-запросами с помощью:
- Диспетчера клиентов.
- Диспетчера запросов.
- Диспетчера данных.
3. Диспетчер клиентов
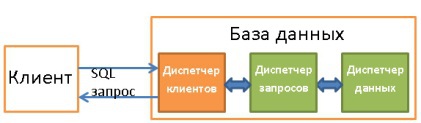
Используется для управления соединениями с клиентами — веб-серверами или конечными пользователями/приложениями. Диспетчер клиентов обеспечивает разные способы доступа к БД с помощью как всем известных API (JDBC, ODBC, OLE-DB и т.д.), так и с помощью проприетарных.
Когда вы подключаетесь к БД:
- Диспетчер сначала аутентифицирует вас (проверят логин и пароль), а потом авторизует для использования БД. Эти права доступа определяются вашим DBA.
- Далее диспетчер проверяет, есть ли доступный процесс (или поток), который может обработать ваш запрос.
- Также он сверяет, не находится ли база в состоянии высокой нагрузки.
- Диспетчер может подождать, пока не высвободятся нужные ресурсы. Если период ожидания закончился, а они не высвободились, диспетчер закрывает соединение с сообщением об ошибке.
- Если же ресурсы имеются, то диспетчер перенаправляет ваш запрос диспетчеру запросов.
- Поскольку диспетчер клиентов передаёт и получает данные от диспетчера запросов, то он сохраняет их в буфере частями и отправляет вам.
- При возникновении проблемы диспетчер прерывает соединение с каким-то объяснением и высвобождает ресурсы.
4. Диспетчер запросов
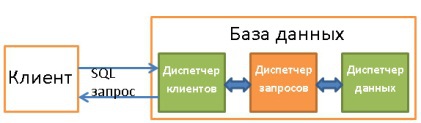
Именно он является сердцем БД. Здесь все плохо написанные запросы превращаются в быстроисполняемый код, затем происходит исполнение, а результат отправляется диспетчеру клиентов. Описанный процесс состоит из нескольких этапов:
- Запрос сначала проверяется на валидность (парсится).
- Затем он перезаписывается с целью исключения бесполезных операций и предварительной оптимизации.
- Далее производится окончательная оптимизация для повышения производительности. После этого запрос трансформируется в план исполнения и доступа к данным.
- План компилируется.
- И исполняется.
Если вы хотите узнать больше, то можете изучить следующие материалы:
- Access Path Selection in a Relational Database Management System. Статья 1979 года посвящена оптимизации.
- Очень хорошая и глубокая презентация о том, как DB2 9.x оптимизирует запросы.
- Не менее хорошая презентация о том, как тем же самым занимается PostgreSQL. Здесь информация подана в наиболее понятной форме.
- Официальная документация SQL по оптимизации. Читается довольно легко, поскольку SQLite используется простые правила. К тому же это единственный официальный документ по данной теме.
- Хорошая презентация о том, как SQL Server 2005 оптимизирует запросы.
- Официальный документ об оптимизации в Oracle 12c.
- Два теоретических курса по оптимизации запросов от автора книги “Database System Concepts”: первый и второй. Хороший материал, акцентирующий внимание на экономии операций ввода/вывода. Но для усвоения требуется хорошо владеть CS.
- Ещё один теоретический курс, более доступный для понимания. Но он посвящён операторам объединения и управлению операциями ввода/вывода.
4.1. Парсер запросов
Каждый SQL-оператор отправляется в парсер и проверяется на правильность синтаксиса. Если вы сделаете ошибку в запросе, то парсер его отклонит. Например, напишете SLECT вместо SELECT.
Но этим функции парсера не ограничиваются. Он также проверяет, чтобы ключевые слова использовались в правильном порядке. Например, если WHERE будет идти до SELECT, то запрос будет отклонён.
Также парсер анализирует таблицы и их поля внутри запроса. Он использует метаданные БД для проверки:
- Самого факта существования таблицы.
- Наличия в ней полей.
- Возможности осуществления операций с полями имеющихся типов. Например, нельзя сравнивать целочисленные со строковыми, или использовать функцию substring() применительно к целочисленному).
Далее парсер проверяет, имеете ли вы вообще право читать (или записывать) таблицы в запросе. Эти права доступа также задаются вашим DBA.
В ходе всех этих проверок SQL-запрос трансформируется во внутреннее представление (чаще всего в дерево). Если всё в порядке, то оно отправляется в рерайтер запросов.
4.2. Рерайтер запросов
В его задачи входит:
- Предварительная оптимизация запроса.
- Исключение ненужных операций.
- Помощь оптимизатору в поиске наилучшего возможного решения.
Рерайтер применяет к запросу список известных правил. Если запрос всем им удовлетворяет, то он перезаписывается. Вот некоторые из этих правил:
- Слияние представлений (видов). Если вы используете в запросе представление, то оно трансформируется с помощью SQL-кода.
- Сведение подзапросов. Наличие подзапросов сильно затрудняет оптимизацию, так что рерайтер старается так модифицировать запрос, чтобы избавиться от подзапросов.
Например, этот запрос:
SELECT PERSON.*
FROM PERSON
WHERE PERSON.person_key IN
(SELECT MAILS.person_key
FROM MAILS
WHERE MAILS.mail LIKE 'christophe%');
будет заменён на:
SELECT PERSON.*
FROM PERSON, MAILS
WHERE PERSON.person_key = MAILS.person_key
and MAILS.mail LIKE 'christophe%';
- Исключение ненужных операций. Допустим, вы используете DISTINCT несмотря на то, что у вас применяется условие UNIQUE, предотвращающее появление не уникальных данных. В этом случае ключевое слово DISTINCT удаляется парсером.
- Предотвращение ненужных объединений. Если вы дважды указали одно и то же условие объединения, поскольку одно из них было скрыто в представлении, или просто бессмысленно из-за транзитивности, то оно удаляется.
- Арифметические вычисления. Если вы пишете что-то, требующее вычисления, то оно делается однократно в ходе перезаписи. Скажем, WHERE AGE > 10+2 трансформируется в WHERE AGE > 12. А TODATE (какая-то дата) заменяется на дату в соответствующем формате.
- Partition pruning. Если вы используете партиционированные таблицы, рерайтер может найти подходящие партиции.
- Перезапись материализованного представления. Если у вас есть материализованное представление, совпадающее с подмножеством предикатов в запросе, то рерайтер проверяет, является ли представление актуальным, и модифицирует запрос так, чтобы он использовал материализованное представление вместо таблиц.
- Особые правила. Если у вас специфические правила модификации запроса (вроде политик Oracle), то рерайтер может их применить.
- OLAP-трансформации. Трансформируются функции анализа/кадрирования, звездообразные объединения, свёртывание и т.д. Поскольку рерайтер и оптимизатор очень тесно взаимодействуют, то, скорее всего, OLAP-трансформации может осуществлять и оптимизатор, на усмотрение БД.
После применения политик запрос отправляется в оптимизатор, и там начинается самое веселье.
4.3. Статистика
Прежде чем перейти к рассмотрению оптимизирования запросов, давайте поговорим о статистике, поскольку без неё БД становится совершенно безмозглой. Если вы не скажете ей проанализировать собственные данные, она этого и не сделает, сделав очень плохие допущения.
Какого рода информация нужна БД?
Сначала давайте вспомним, как БД и ОС хранят данные. Для этого они используют такие минимально возможные сущности, как страницы или блоки (размером по 4 или 8 Кбайт по умолчанию). Если вам нужно сохранить 1 Кбайт, то на это всё-равно уйдёт целая страница. То есть вы попусту тратите много места в памяти и на диске.
Вернёмся к нашей статистике. Когда вы просите БД собрать статистику, она:
- Подсчитывает количество строк/страниц в таблице.
- Для каждой колонки:
- Считает количество уникальных значений.
- Определяет длину значений данных (мин, макс, среднее).
- Определяет диапазон значений данных (мин, макс, среднее).
- Собирает информацию об индексах БД.
Вся эта информация помогает оптимизатору спрогнозировать количество операций ввода/вывода, а также потребление ресурсов процессора и памяти при исполнении запроса.
Очень большое значение имеет статистика по каждой колонке. Например, нам нужно в таблице объединить две колонки: «фамилия» и «имя». Благодаря статистике БД знает, что в ней содержится 1 000 уникальных значений «имя» и 1 000 000 — «фамилия». Поэтому база объединит данные именно в таком порядке — «фамилия, имя», а не «имя, фамилия»: это требует гораздо меньше операций сравнения, поскольку вероятность совпадения фамилий гораздо ниже, и в большинстве случаев для сравнения достаточно брать 2-3 первые буквы фамилии.
Но всё это базовая статистика. Можно также попросить БД собрать дополнительную статистику и построить гистограммы. Они дают представление о распределении значений внутри колонок. Например, определить самые часто встречающиеся значения, квантили и т.д. Эта дополнительная статистика помогает БД ещё лучше планировать запрос. Особенно в случае с предикатами равенства (WHERE AGE=18) или предикатами диапазонов (WHERE AGE > 10 AND AGE < 40), поскольку БД будет лучше представлять количество колонок, имеющих отношение к этим предикатам (селективность, избирательность).
Статистика хранится в виде метаданных. Например, вы можете найти её в:
- Oracle: USER/ALL/DBA_TABLES и USER/ALL/DBA_TAB_COLUMNS
- DB2: SYSCAT.TABLES и SYSCAT.COLUMNS
Статистику нужно регулярно обновлять. Нет ничего хуже, чем БД, считающая, что состоит из 500 строк, в то время как в ней их 1 000 000. К сожалению, на сбор статистики уходит некоторое время, поэтому в большинстве БД по умолчанию эта операция не выполняется автоматически. Когда у вас миллионы записей, то собрать по ним статистику довольно затруднительно. В этом случае можно собирать только базовую информацию, или брать небольшую часть базы (например, 10%) и собирать по ней полную статистику. Но тут есть риск того, что оставшаяся часть данных может существенно отличаться, и значит ваша статистика окажется нерепрезентативной. А это приведёт к неправильному планированию запроса и увеличению времени его исполнения.
Если вы хотите узнать больше о статистике, читайте документацию к своим БД. Лучше всего это описано для PostgreSQL.
4.4. Оптимизатор запросов
Все современные БД используют CBO (Cost Based Optimization), стоимостную оптимизацию. Суть её заключается в том, что для каждой операции определяется её «стоимость», а затем общая стоимость запроса уменьшается с помощью использования наиболее «дешёвых» цепочек операций.
Для лучшего понимания стоимостной оптимизации мы рассмотрим три распространённых способа объединения двух таблиц и увидим, как даже простой запрос на объединение может превратиться в кошмар для оптимизатора. В нашем рассмотрении мы будем ориентироваться на временнỳю сложность, хотя оптимизатор вычисляет «стоимость» в ресурсах процессора, памяти и операциях ввода/вывода. Просто временнáя сложность — понятие приблизительное, а для определения необходимых ресурсов процессора нужно подсчитывать все операции, включая добавление, операторы if, умножение, итерации и т.д.
Кроме того:
- Для выполнения каждой высокоуровневой операции процессор выполняет разное количество низкоуровневых операций.
- Стоимость процессорных операций (с точки зрения циклов) разная у разных видов процессоров, то есть она зависит от конкретной архитектуры ЦПУ.
Поэтому нам будет проще оценивать в виде сложности. Но помните, что чаще всего производительность БД ограничивается дисковой подсистемой, а не процессорными ресурсами.
4.4.1. Индексы
Мы говорили о них, когда рассматривали В-деревья. Как вы помните, индексы уже отсортированы. К слову, есть и другие виды индексов, например, битовые (bitmap index). Но они не дают выигрыша с точки зрения использования процессора, памяти и дисковой подсистемы по сравнению с индексами В-деревьев. Кроме того, многие современные БД могут динамически создавать временные индексы для текущих запросов, если это поможет уменьшить стоимость выполнения плана.
4.4.2. Способы обращений
Прежде чем применять операторы объединения, нужно сначала получить необходимые данные. Сделать это можно следующими способами.
- Полное сканирование. БД просто считывает целиком таблицу или индекс. Как вы понимаете, для дисковой подсистемы индекс читать дешевле, чем таблицу.
- Сканирование диапазона. Используется, например, когда вы используете предикаты наподобие WHERE AGE > 20 AND AGE < 40. Конечно, для сканирования диапазона индекса вам нужно иметь индекс для поля AGE.
В первой части статьи мы уже выяснили, что временнáя сложность запроса диапазона определяется как M + log(N), где N — количество данных в индексе, а М — предположительное количество строк внутри диапазона. Значения обеих этих переменных нам известны благодаря статистике. При сканировании диапазона считывается лишь часть индекса, поэтому данная операция стоит меньше по сравнению с полным сканированием. - Сканирование по уникальным значениям. Используется в тех случаях, когда вам нужно получить из индекса только какое-то одно значение.
- Обращение по ID строки. Если БД использует индекс, то бόльшую часть времени она будет заниматься поиском связанных с ним строк. Например, мы делаем такой запрос:
SELECT LASTNAME, FIRSTNAME from PERSON WHERE AGE = 28
Если у нас есть индекс для колонки возраста, то оптимизатор воспользуется индексом для поиска всех 28-летних, а затем запросит ID соответствующих строк таблицы, поскольку индекс содержит информацию только о возрасте.
Допустим, у нас другой запрос:
SELECT TYPE_PERSON.CATEGORY from PERSON, TYPE_PERSON WHERE PERSON.AGE = TYPE_PERSON.AGE
Для объединения с TYPE_PERSON будет использоваться индекс по колонке PERSON. Но поскольку мы не запрашивали информацию у таблицы PERSON, то и обращаться к ней по ID строк никто не будет.
Данный подход хорош только при небольшом количестве обращений, поскольку он дорог с точки зрения ввода/вывода. Если вам нужно часто обращаться по ID, то лучше воспользоваться полным сканированием. - Другие способы. О них можно почитать в документации Oracle. В разных БД могут использоваться разные названия, но принципы везде одни и те же.
4.4.3. Операции объединения
Итак, мы знаем, как получить данные, пришла пора их объединить. Но сначала давайте определимся с новыми терминами: внутренние зависимости и внешние зависимости. Зависимостью может быть:
- таблица,
- индекс,
- промежуточный результат предыдущей операции (например, предыдущего объединения).
Когда мы объединяем две зависимости, алгоритмы объединения управляют ими по-разному. Допустим, A JOIN B является объединением А и В, где А является внешней зависимостью, а В — внутренней.
Чаще всего стоимость A JOIN B не равна стоимости B JOIN A.
Предположим, что внешняя зависимость содержит N элементов, а внутренняя — М. Как вы помните, оптимизатору известны эти значения благодаря статистике. N и M являются кардинальными числами зависимостей.
- Объединение с помощью вложенных циклов. Это простейший способ объединения.
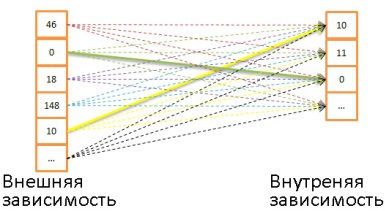
Работает он так: для каждой строки внешней зависимости ищутся совпадения по всем строкам внутренней зависимости.
Пример псеводокода:
nested_loop_join(array outer, array inner) for each row a in outer for each row b in inner if (match_join_condition(a,b)) write_result_in_output(a,b) end if end for end for
Поскольку здесь двойная итерация, временнáя сложность определяется как О(N*M).
Для каждой из N строк внешней зависимости нужно считать М строк внешней зависимости. То есть этот алгоритм требует N + N*M чтений с диска. Если внутренняя зависимость достаточно мала, то можно поместить её целиком в память, и тогда на долю дисковой подсистемы придётся только M + N чтений. Так что рекомендуется делать внутреннюю зависимость как можно компактнее, чтобы загнать в память.
С точки зрения временнόй сложности разницы никакой.
Также можно заменить внутреннюю зависимость индексом, это позволит сэкономить операции ввода/вывода.
Если внутренняя зависимость не влезает в память целиком, можно использовать другой алгоритм, более экономно использующий диск.
- Вместо чтения обеих зависимостей построчно, они считываются группами строк (bunch), при этом в памяти сохраняется по одной группе из каждой зависимости.
- Строки из этих групп сравниваются между собой, а найденные совпадения сохраняются отдельно.
- Затем в память подгружаются новые группы и тоже сравниваются друг с другом.
И так далее, пока группы не закончатся.
Пример алгоритма:
// improved version to reduce the disk I/O. nested_loop_join_v2(file outer, file inner) for each bunch ba in outer // ba is now in memory for each bunch bb in inner // bb is now in memory for each row a in ba for each row b in bb if (match_join_condition(a,b)) write_result_in_output(a,b) end if end for end for end for end for
В данном случае временнáя сложность остаётся той же, зато снижается количество обращений к диску: (количество групп внешней + количество групп внешней * количество групп внутренней). С увеличением размера групп ещё больше уменьшается количество обращений к диску.
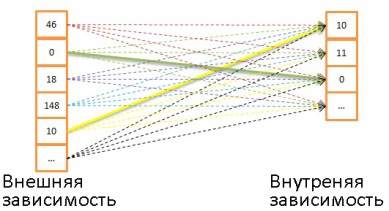
Примечание: в этом алгоритме при каждом обращении считывается больший объём данных, но это не играет роли, поскольку обращения последовательные. - Хэш-объединение. Это более сложная операция, но во многих случаях её стоимость ниже.
Алгоритм следующий:
- Считываются все элементы из внутренней зависимости.
- В памяти создаётся хэш-таблица.
- Один за другим считываются все элементы из внешней зависимости.
- Для каждого элемента вычисляется хэш (с помощью соответствующей функции из хэш-таблицы), чтобы можно было найти соответствующий блок во внутренней зависимости.
- Элементы из блока сравниваются с элементами из внешней зависимости.
Чтобы оценить этот алгоритм с точки зрения временнόй сложности, нужно сделать несколько допущений:
- Внутренняя зависимость содержит Х блоков.
- Хэш-функция распределяет хэши почти одинаково для обеих зависимостей. То есть все блоки имеют идентичный размер.
- Стоимость поиска соответствия между элементами внешней зависимости и всеми элементами внутри блока равна количеству элементов внутри блока.
Тогда временнáя сложность будет равна:
(М / Х) * (N / X) + стоимость_создания_хэш-таблицы(М) + стоимость_хэш-функции * N
А если хэш-функция создаёт достаточное маленькие блоки, то временнáя сложность будет равна О(М + N).
Есть ещё один способ хэш-объединения, более экономно расходующий память и не требующий больше операций ввода/вывода:
- Вычисляются хэш-таблицы для обеих зависимостей.
- Кладутся на диск.
- А затем сравниваются поведёрно друг с другом (один блок загружается в память, а второй считывается построчно).
Объединение слиянием. Это единственный способ объединения, в результате которого данные получаются отсортированными. В рамках этой статьи мы рассматриваем упрощённый случай, когда зависимости не делятся на внешнюю и внутреннюю, поскольку ведут себя одинаково. Однако в жизни они могут различаться, скажем, при работе с дубликатами.
Операцию объединения можно разделить на два этапа:
- (Опционально) сначала осуществляется объединение сортировкой, когда оба набора входных данных сортируются по ключам объединения.
- Затем осуществляется слияние.
Сортировка
Алгоритм сортировки слиянием уже обсуждался выше, в данном случае он вполне себя оправдывает, если вам важно экономить память.
Но бывает, что наборы данных поступают уже отсортированными, например:
- Если таблица организована нативно.
- Если зависимость является индексом при наличии условия объединения.
- Если объединение происходит с промежуточным отсортированным результатом.
Объединение слиянием
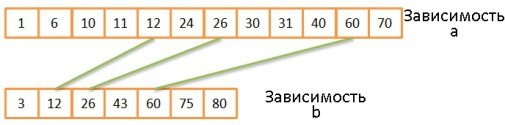
Эта операция очень похожа на операцию слияния при процедуре сортировки слиянием. Но вместо выбора всех элементов обеих зависимостей мы выбираем только равные элементы.
- Сравниваются два текущих элемента обеих зависимостей.
- Если они равны, то заносятся в результирующую таблицу, и далее сравниваются два следующих элемента, по одному из каждой зависимости.
- Если они не равны, то сравнение повторяется, но вместо наименьшего из двух элементов берётся следующий элемент из той же зависимости, поскольку вероятность совпадения в этом случае выше.
- Шаги 1-3 повторяются, пока на закончатся элементы одной из зависимостей.
Если обе зависимости уже отсортированы, то временнáя сложность равна О(N + M).
Если обе зависимости ещё нужно отсортировать, то временнáя сложность равна O(N * Log(N) + M * Log(M)).
Этот алгоритм работает хорошо, потому что обе зависимости уже отсортированы, и нам не приходится перемещаться по ним туда-обратно. Однако здесь допущено некоторое упрощение: алгоритм не обрабатывает ситуации, когда одни и те же данные встречаются многократно, то есть когда происходят многократные совпадения. В реальности используется более сложная версия алгоритма. Например:
mergeJoin(relation a, relation b) relation output integer a_key:=0; integer b_key:=0; while (a[a_key]!=null and b[b_key]!=null) if (a[a_key] < b[b_key]) a_key++; else if (a[a_key] > b[b_key]) b_key++; else //Join predicate satisfied write_result_in_output(a[a_key],b[b_key]) //We need to be careful when we increase the pointers integer a_key_temp:=a_key; integer b_key_temp:=b_key; if (a[a_key+1] != b[b_key]) b_key_temp:= b_key + 1; end if if (b[b_key+1] != a[a_key]) a_key_temp:= a_key + 1; end if if (b[b_key+1] == a[a_key] && b[b_key] == a[a_key+1]) a_key_temp:= a_key + 1; b_key_temp:= b_key + 1; end if a_key:= a_key_temp; b_key:= b_key_temp; end if end while
Какой алгоритм выбрать?
Если бы существовал самый лучший способ объединения, то не существовало бы всех этих разновидностей. Так что ответ на этот вопрос зависит от кучи факторов:
- Объём доступной памяти. Если её мало, забудьте о мощном хэш-объединении. По крайне мере, о его выполнении целиком в памяти.
- Размер двух наборов входных данных. Если у вас одна таблица большая, а вторая очень маленькая, то быстрее всего сработает объединение с помощью вложенных циклов, потому что хэш-объединение подразумевает дорогую процедуру создания хэшей. Если у вас две очень большие таблицы, то объединение с помощью вложенных циклов поглотит все ресурсы процессора.
- Наличие индексов. Если у вас два индекса В-деревьев, то лучше использовать объединение слиянием.
- Нужно ли сортировать результат. Возможно, вы захотите использовать дорогое объединение слиянием (с сортировкой), если работаете с несортированными наборами данных. Тогда на выходе вы получите сортированные данные, которые удобнее объединить с результатами другого объединения. Или потому что запрос косвенно или явно предполагает получение данных, отсортированных операторами ORDER BY/GROUP BY/DISTINCT.
- Отсортированы ли выходные зависимости. В данном случае лучше использовать объединение слиянием.
- Зависимости каких типов вы используете. Объединение по эквивалентности (таблицаА.колонка1 = таблицаБ.колонка2)? Внутренние зависимости, внешние, декартово произведение или самообъединение (self-join)? В разных ситуациях некоторые способы объединения не работают.
- Распределение данных. Если данные отклонены по условию объединения (например, вы объединяете людей по фамилиям, но часто встречаются однофамильцы), то ни в коем случае нельзя использовать хэш-объединение. Иначе хэш-функция будет создавать корзины с очень плохим внутренним распределением.
- Нужно ли выполнять объединение в несколько процессов/потоков.
Алчущие знаний могут углубиться в документацию по DB2, ORACLE и SQL Server.
4.4.4. Упрощённые примеры
Допустим, нам нужно объединить пять таблиц, чтобы получить полное представление о неких людях. Каждый человек может иметь:
- Несколько номеров мобильных телефонов.
- Несколько адресов электронной почты.
- Несколько физических адресов.
- Несколько номеров банковских счетов.
То есть нужно быстро дать ответ на этот запрос:
SELECT * from PERSON, MOBILES, MAILS,ADRESSES, BANK_ACCOUNTS
WHERE
PERSON.PERSON_ID = MOBILES.PERSON_ID
AND PERSON.PERSON_ID = MAILS.PERSON_ID
AND PERSON.PERSON_ID = ADRESSES.PERSON_ID
AND PERSON.PERSON_ID = BANK_ACCOUNTS.PERSON_ID
Оптимизатору нужно найти наилучший способ обработки данных. Но есть две проблемы:
- Какой способ объединения использовать? Есть три варианта (хэш-объединение, объединение слиянием, объединение с помощью вложенных циклов), с возможностью использования 0, 1 или 2 индексов. Не говоря уже о том, что индексы тоже могут быть разными.
- В каком порядке нужно производить объединение?
Например, ниже представлены возможные планы для трёх объединений четырёх таблиц:
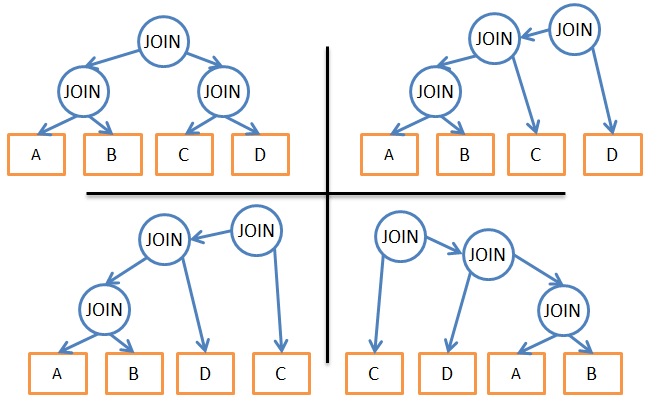
Исходя из описанного, какие есть варианты действий?
- Использовать брутфорс-подход. С помощью статистики подсчитать стоимость каждого из возможных планов исполнения запроса и выбрать самый дешёвый. Но вариантов довольно много. Для каждого порядка объединения можно использовать три разных способа объединения, итого 34=81 возможных планов исполнения. В случае с бинарным деревом задача выбора порядка объединения превращается в задачу о перестановках, и количество вариантов равно (2 * 4)! / (4 + 1)!.. В результате, в данном очень упрощённом примере общее количество возможных планов исполнения запроса составляет 34 * (2 * 4)! / (4 + 1)! = 27 216. Если добавить к этому варианты, когда при объединении слиянием используется 0, 1 или 2 индекса В-дерева, то количество возможных планов повышается до 210 000. Мы уже упоминали, что это ОЧЕНЬ ПРОСТОЙ запрос?
- Поплакать и уволиться. Очень соблазнительно, но непродуктивно, да и деньги нужны.
- Попробовать несколько планов и выбрать самый дешёвый. Раз обсчитать стоимость всех возможных вариантов не получается, можно взять произвольный тестовый набор данных и прогнать по нему все виды планов, чтобы оценить их стоимость и выбрать лучший.
- Применить «умные» правила для уменьшения количества возможных планов.
Есть два типа правил:
- «Логические», с помощью которых можно исключить бесполезные варианты. Но они далеко не всегда применимы. Например, «при объединении с помощью вложенных циклов внутренняя зависимость должна являться наименьшим набором данных».
- Можно не искать наиболее выгодное решение и применить более жёсткие правила для уменьшения числа возможных планов. Скажем, «если зависимость мала, используем объединение с помощью вложенных циклов, но никогда — объединение слиянием или хэш-объединение».
Даже столь простой пример ставит нас перед огромным выбором. А в реальных запросах могут присутствовать и другие операторы отношения: OUTER JOIN, CROSS JOIN, GROUP BY, ORDER BY, PROJECTION, UNION, INTERSECT, DISTINCT и т.д. То есть количество возможных планов исполнения будет ещё больше.
Так как же БД делает выбор?
4.4.5. Динамическое программирование, «жадный» алгоритм и эвристика
Реляционная БД использует разные подходы, о которых было сказано выше. И задачей оптимизатора является поиск подходящего решения в течение ограниченного времени. В большинстве случаев оптимизатор ищет не наилучшее, а просто хорошее решение.
Брутфорс может подойти в случае с маленькими запросами. А благодаря способам исключения ненужных вычислений даже для запросов среднего размера можно использовать грубую мужскую силу. Это называется динамическим программированием.
Его суть заключается в том, что многие планы исполнения очень похожи.
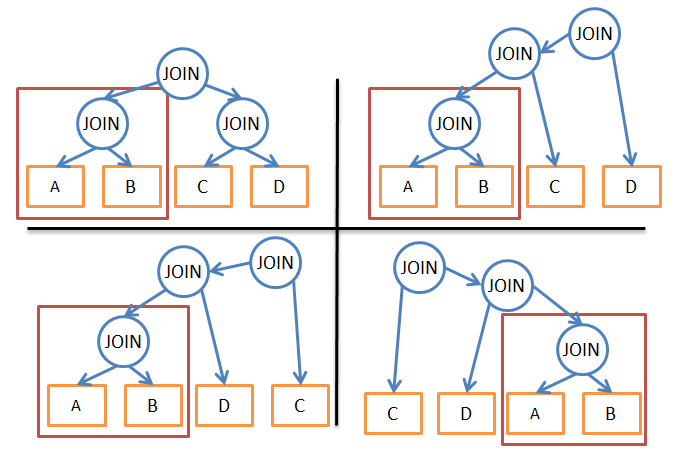
На этой иллюстрации все четыре плана используют поддерево A JOIN B. Вместо вычисления его стоимости для каждого плана, мы можем посчитать его лишь раз и затем использовать эти данные столько, сколько нужно. Иными словами, с помощью мемоизации мы решаем проблему перекрытия, то есть избегаем лишних вычислений.
Благодаря такому подходу вместо временнόй сложности (2*N)!/(N+1)! мы получаем «всего лишь» 3N. Применительно к предыдущему примеру с четырьмя объединениями это означает уменьшение количества вариантов с 336 до 81. Если взять запрос с 8 объединениями (небольшой запрос), то уменьшение сложности будет с 57 657 600 до 6 561.
Если вы уже знакомы с динамическим программированием или алгоритмизацией, можете поиграться с этим алгоритмом:
procedure findbestplan(S)
if (bestplan[S].cost infinite)
return bestplan[S]
// else bestplan[S] has not been computed earlier, compute it now
if (S contains only 1 relation)
set bestplan[S].plan and bestplan[S].cost based on the best way
of accessing S /* Using selections on S and indices on S */
else for each non-empty subset S1 of S such that S1 != S
P1= findbestplan(S1)
P2= findbestplan(S - S1)
A = best algorithm for joining results of P1 and P2
cost = P1.cost + P2.cost + cost of A
if cost < bestplan[S].cost
bestplan[S].cost = cost
bestplan[S].plan = “execute P1.plan; execute P2.plan;
join results of P1 and P2 using A”
return bestplan[S]
Динамическое программирование можно использовать и для более крупных запросов, но придётся вводить дополнительные правила (эвристику), чтобы уменьшить число возможных планов:
- Если мы анализируем только какой-то один тип планов (например, следование по левым веткам дерева), то вместо 3N получим сложность на уровне N*2N.
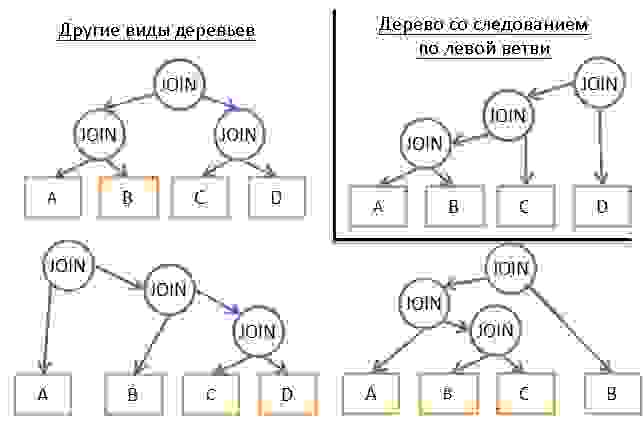
- Добавление логических правил («если таблица является индексом для данного предиката, использовать объединение слиянием только для индекса, а не таблицы») помогает уменьшить число вариантов с небольшим риском исключения наилучших решений.
- Добавление правил «на лету» (например, «выполнить операции объединения ДО всех остальных операций отношений») также сильно помогает уменьшить широту выбора.
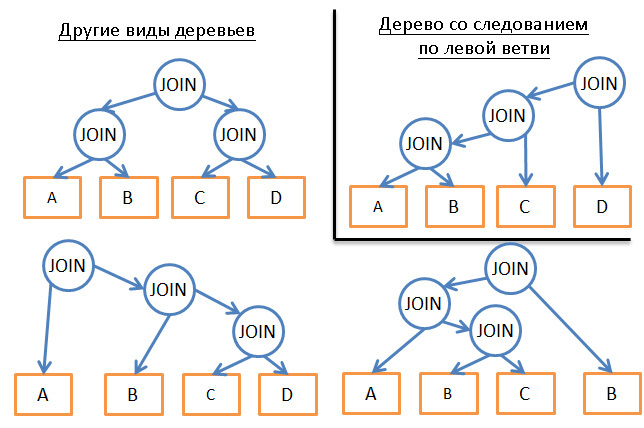
Жадные алгоритмы
Но если запрос очень велик, или если нам нужно крайне быстро получить ответ, используется другой класс алгоритмов — жадные алгоритмы.
В данном случае план исполнения запроса строится пошагово с помощью некоего правила (эвристики). Благодаря ему жадный алгоритм ищет наилучшее решение для каждого этапа по отдельности. План начинается с оператор JOIN, а затем на каждом этапе добавляется новый JOIN в соответствии с правилом.
Рассмотрим простой пример. Возьмём запрос с 4 объединениями 5 таблиц (A, B, C, D и E). Несколько упростим задачу и представим, что единственным вариантом является объединение с помощью вложенных алгоритмов. Будем использовать правило «применять объединение с наименьшей стоимостью».
- Начинаем с одной из таблиц, например, А.
- Вычисляем стоимость каждого объединения с А (она будет как в роли внешней, так и внутренней зависимости).
- Находим, что дешевле всего нам обойдётся A JOIN B.
- Затем вычисляем стоимость каждого объединения с результатом A JOIN B (его тоже рассматриваем в двух ролях).
- Находим, что выгоднее всего будет (A JOIN B) JOIN C.
- Опять делаем оценку возможных вариантов.
- …
- В конце получаем такой план исполнения запроса: (((A JOIN B) JOIN C) JOIN D) JOIN E)/
Тот же алгоритм можно применить для оценки вариантов, начинающихся с таблицы B, затем с C и т.д. В результате получим пять планов, из которых выбираем самый дешёвый.
Данный алгоритм называется «алгоритм ближайшего соседа».
Не будем углубляться в подробности, но при хорошем моделировании сложности сортировки N*log(N) данная проблема может быть легко решена. Временнáя сложность алгоритма равна О(N*log(N)) вместо О(3N) для полной версии с динамическим программированием. Если у вас большой запрос с 20 объединениями, то это будет 26 против 3 486 784 401. Большая разница, верно?
Но есть нюанс. Мы предполагаем, что если найдём наилучший способ объединения двух таблиц, то получим самую низкую стоимость при объединении результатом предыдущих объединений со следующими таблицами. Однако даже если A JOIN B будет самым дешёвым вариантом, то (A JOIN C) JOIN B может иметь стоимость ниже, чем (A JOIN B) JOIN C.
Так что если вам позарез нужно найти самый дешёвый план всех времён и народов, то можно посоветовать многократно прогонять жадные алгоритмы с использованием разных правил.
Другие алгоритмы
Если вы уже сыты по горло всеми этими алгоритмами, то можете пропустить эту главу. Она не обязательна для усвоения всего остального материала.
Многие исследователи занимаются проблемой поиска наилучшего плана исполнения запроса. Зачастую пытаются найти решения для каких-то конкретных задач и шаблонов. Например, для звездообразных объединений, исполнения параллельных запросов и т.д.
Ищутся варианты замены динамического программирования для исполнения больших запросов. Те же жадные алгоритмы являются подмножеством эвристических алгоритмов. Они действуют сообразно правилу, запоминают результат одного этапа и используют его для поиска лучшего варианта для следующего этапа. И алгоритмы, которые не всегда используют решение, найденное для предыдущего этапа, называются эвристическими.
В качестве примера можно привести генетические алгоритмы:
- Каждое решение представляет собой план полного исполнения запроса.
- Вместо одного решения (плана) алгоритм на каждом этапе формирует Х решений.
- Сначала создаётся Х планов, делается это случайным образом.
- Из них сохраняются только те планы, чья стоимости удовлетворяет некоему критерию.
- Затем эти планы смешиваются, что бы создать Х новых планов.
- Некоторые из новых планов модифицируются случайным образом.
- Предыдущие три шага повторяются Y раз.
- Из планов последнего цикла мы получаем наилучший.
Чем больше циклов, тем более дешёвый план можно рассчитать. Естественный отбор, закрепление признаков, вот это всё.
Кстати, генетические алгоритмы интегрированы в PostgreSQL.
В БД используются и такие эвристические алгоритмы, как симулированная нормализация (Simulated Annealing), итеративное улучшение (Iterative Improvement), двухфазная оптимизация (Two-Phase Optimization). Но не факт, что они применяются в корпоративных системах, возможно, их удел — исследовательские продукты.
4.4.6. Настоящие оптимизаторы
Тоже необязательная глава, можно и пропустить.
Давайте отойдём от теоретизирования и рассмотрим реальные примеры. Например, как работает оптимизатор SQLite. Это «лёгкая» БД, использующая простую оптимизацию на основе жадного алгоритма с дополнительными правилами:
- SQLite никогда не меняет порядок таблиц в операции CROSS JOIN.
- Используется объединение с помощью вложенных циклов.
- Внешние объединения всегда оцениваются в том порядке, в котором они осуществлялись.
- Вплоть до версии 3.8.0 для поиска наилучшего плана исполнения запроса используется жадный алгоритм «ближайшего соседа» (Nearest Neighor). А с версии 3.8.0 применяется «N ближайших соседей» (N3, N Nearest Neighbors).
А вот другой пример. Если почитать документацию IBM DB2, то мы узнаем, что её оптимизатор используется 7 разных уровней оптимизации:
- Жадные алгоритмы:
- 0 — минимальная оптимизация. Используется сканирование индекса, объединение с помощью вложенных циклов и исключение перезаписи некоторых запросов.
- 1 — низкая оптимизация
- 2 — полная оптимизация
- Динамическое программирование:
- 3 — средняя оптимизация и грубая аппроксимация
- 5 — полная оптимизация, используются все эвристические методики
- 7 — то же самое, но без эвристики
- 9 — максимальная оптимизация любой ценой, без оглядки на затрачиваемые усилия. Оцениваются все возможные способы объединения, включая декартовы произведения.
По умолчанию применяется уровень 5. Сюда входит:
- Сбор всей возможной статистики, включая частотные распределения и квантили.
- Применение всех правил перезаписи запросов, включая составление табличного маршрута для материализованных запросов). Исключение составляют правила, требующие интенсивных вычислений, применяемые для очень ограниченного числа случаев.
- При переборе вариантов объединения с помощью динамического программирования:
- Ограниченно используется составная внутренняя зависимость.
- Для звездообразных схем с таблицами преобразования ограниченно используются декартовы произведения.
- Рассматривается широкий диапазон способов доступа, включая предварительную выборку списка (об этом ниже), специальную операцию с индексами AND и составление табличного маршрута для материализованных запросов.
Конечно, разработчики не делятся подробностями об эвристике, используемой в их продукте, ведь оптимизатор — едва ли не самая важная часть БД. Однако известно, что по умолчанию для определения порядка объединения используется динамическое программирование, ограничиваемое эвристикой.
Прочие условия (GROUP BY, DISTINCT и т.д.) обрабатываются простыми правилами.
4.4.7. Кэш плана запросов
Поскольку составление плана требует времени, большинство БД хранят план в кэше плана запросов. Это помогает избежать ненужных вычислений одних и тех же этапов. БД должна знать, когда именно ей нужно обновить устаревшие планы. Для этого устанавливается некий порог, и если изменения в статистике его превышают, то план, относящийся к данной таблице, удаляется из кэша.
Исполнитель запросов
На данном этапе наш план уже оптимизирован. Он перекомпилируется в исполняемый код и, если ресурсов достаточно, исполняется. Операторы, содержащиеся в плане (JOIN, SORT BY и т.д.) могут обрабатываться как последовательно, так и параллельно, решение принимает исполнитель. Для получения и записи данных он взаимодействует с диспетчером данных.
5. Диспетчер данных
Диспетчер запросов исполняет запрос и нуждается в данных из таблиц и индексов. Он запрашивает их у диспетчера данных, но тут есть две трудности:
- Реляционные БД используют транзакционную модель. Нельзя в конкретный момент времени получить любые желаемые данные, потому что в это время они могут кем-то использоваться/модифицироваться.
- Извлечение данных — самая медленная операция в БД. Поэтому диспетчеру данных нужно уметь прогнозировать свою работу, чтобы своевременно заполнять буфер памяти.
5.1. Диспетчер кэша
Как уже не раз говорилось, самым узким местом в БД является дисковая подсистема. Поэтому для увеличения производительности используется диспетчер кэша.
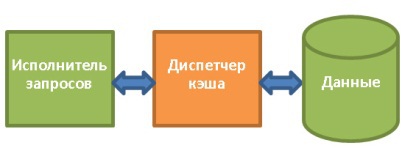
Вместо того, чтобы получать данные напрямую от файловой системы, исполнитель запросов обращается за ними к диспетчеру кэша. Тот использует содержащийся в памяти буферный пул, что позволяет радикально увеличить производительность БД. В цифрах это трудно оценить, поскольку многое зависит от того, что вам нужно:
- Последовательный доступ (полное сканирование) или случайный (доступ по ID строки).
- Читать или записывать.
Также большое значение имеет тип накопителей, используемых в дисковой системе: «винчестеры» с разной скоростью вращения шпинделя, SSD, наличие RAID в разных конфигурациях. Но можно сказать, что использование памяти в 100-100 000 раз быстрее, чем диска.
Однако тут мы сталкиваемся с другой проблемой. Диспетчеру кэша нужно положить данные в память ДО того, как они понадобятся исполнителю запросов. Иначе тому придётся ждать их получения с медленного диска.
5.1.1. Упреждение
Исполнитель запросов знает, какие данные ему понадобятся, поскольку ему известен весь план, то, какие данные содержатся на диске и статистика.
Когда исполнитель обрабатывает первую порцию данных, он просит диспетчер кэша заранее подгрузить следующую порцию. А когда переходит к её обработке, то просит ДК подгрузить третью и подтверждает, что первую порцию можно удалить из кэша.
Диспетчер кэша хранит эти данные в буферном пуле. Он также добавляет к ним сервисную информацию (триггер, latch), чтобы знать нужны ли они ещё в буфере.
Иногда исполнитель не знает, какие данные ему будут нужны, или некоторые БД не имеют подобного функционала. Тогда используется спекулятивное упреждение (speculative prefetching) (например, если исполнитель запрашивает данные 1, 3, 5, то наверняка запросит в будущем 7, 9, 11) или последовательное упреждение (sequential prefetching) (в данном случае ДК просто подгружает с диска следующую по порядку порцию данных.
Для контроля качества упреждения в современных БД используется метрика «коэффициент использования буфера/кэша» (buffer/cache hit ratio). Она показывает, как часто запрашиваемые данные оказываются в кэше, без необходимости обращения к диску. Однако низкое значение коэффициента не всегда говорит о плохом использовании кэша. Подробнее об этом можно почитать в документации Oracle.
Нельзя забывать, что буфер ограничен объёмом доступной памяти. То есть для загрузки одних данных нам приходится периодически удалять другие. Заполнение и очистка кэша потребляет часть ресурсов дисковой подсистемы и сети. Если у вас есть часто исполняемый запрос, то было бы контрпродуктивно каждый раз загружать и очищать используемые им данные. Для решения данной проблемы в современных БД используется стратегия замены буфера.
5.1.2. Стратегии замены буфера
Большинство БД (по крайне мере, SQL Server, MySQL, Oracle и DB2) используют для этого алгоритм LRU (Least Recently Used). Он предназначен для поддержания в кэше тех данных, которые недавно использовались, а значит велика вероятность, что они могут понадобиться снова.
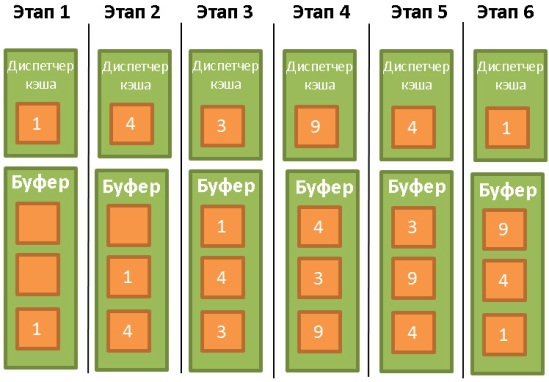
Для облегчения понимания работы алгоритма примем, что данные в буфере не блокируются триггерами (latch), а значит могут быть удалены. В нашем примере буфер может хранить три порции данных:
- Диспетчер кэша используется данные 1 и кладёт их в пустой буфер.
- Затем он использует данные 4 и тоже отправляет их в буфер.
- То же самое делается и с данными 3.
- Далее берутся данные 9. Но буфер-то уже заполнен. Поэтому из него удаляются данные 1, так как они не использовались дольше всего. После этого в буфер помещаются данные 9.
- Диспетчер кэша снова использует данные 4. Они уже есть в буфере, поэтому помечаются как последние использованные.
- Снова становятся востребованы данные 1. Чтобы их поместить в буфер, из него удаляются данные 3, как не использовавшиеся дольше всего.
Это хороший алгоритм, но у него есть некоторые ограничения. Что если у нас осуществляется полное сканирование большой таблицы? Что будет, если размер таблицы/индекса превосходит объём буфера? В этом случае алгоритм удалит из кэша вообще всё его содержимое, таким образом данные полного сканирования, скорее всего, будут использоваться лишь один раз.
Улучшения алгоритма
Чтобы этого не произошло, в некоторых БД используются специальные правила. Согласно документации Oracle:
«Для очень больших таблиц обычно используется прямой доступ, то есть блоки данных считываются напрямую, чтобы избежать переполнения буфера кэша. Для таблиц среднего размера может использоваться как прямой доступ, так и чтение из кэша. Если система решит использовать кэш, то БД помещает блоки данных в конец списка LRU, чтобы предотвратить очистку буфера».
Также используется улучшенная версия LRU — LRU-K. В SQL Server применяется LRU-K при К = 2. Суть этого алгоритма в том, что при оценке ситуации он учитывает больше информации о прошлых операциях, а не только запоминает последние использованные данные. Буква К в названии означает, что алгоритм принимает во внимание, какие данные использовались последние К раз. Им присваивается определённый вес. Когда в кэш загружаются новые данные, то старые, но часто используемые не удаляются, потому что их вес выше. Конечно, если данные больше не используются, то они всё-таки будут удалены. И чем дольше данные остаются невостребованными, тем сильнее уменьшается со временем их вес.
Вычисление веса довольно накладно, поэтому в SQL Server используется LRU-K при К равном всего лишь 2. При некотором увеличении значения К эффективность алгоритма улучшается. Вы можете ближе познакомиться с ним благодаря одной работе 1993-го года.
Другие алгоритмы
Конечно, LRU-K не единственное решение. Существуют также 2Q и CLOCK (оба похожи на LRU-K), MRU (Most Recently Used, в котором используется логика LRU, но применяется другое правило, LRFU (Least Recently and Frequently Used) и т.д. В некоторых БД можно выбирать, какой алгоритм будет использоваться.
5.1.3. Буфер записи
Мы говорили только о буфере чтения, но БД используют и буферы записи, которые накапливают данные и сбрасывают на диск порциями, вместо последовательной записи. Это позволяет экономить операции ввода/вывода.
Помните, что буферы хранят страницы (неделимые единицы данных), а не ряды из таблиц. Страница в буферном пуле называется «грязной», если она модифицирована, но не записана на диск. Есть много разных алгоритмов, с помощью которых выбирается время записи грязных страниц. Но это во многом связано с понятием транзакций.
5.2. Диспетчер транзакций
В его обязанности входит отслеживание, чтобы каждый запрос исполнялся с помощью собственной транзакции. Но прежде чем поговорить о диспетчере, давайте проясним концепцию ACID-транзакций.
5.2.1. «Под кислотой» (игра слов, если кто не понял)
ACID-транзакция (Atomicity, Isolation, Durability, Consistency) — это элементарная операция, единица работы, которая удовлетворяет 4 условиям:
- Атомарность (Atomicity). Нет ничего «меньше» транзакции, никакой более мелкой операции. Даже если транзакция длится 10 часов. В случае неудачного выполнения транзакции система возвращается в состояние «до», то есть транзакция откатывается.
- Изолированность (Isolation). Если в одно время выполняются две транзакции А и В, то их результат не должен зависеть от того, завершилась ли одна из них до, во время или после исполнения другой.
- Надёжность (Durability). Когда транзакция зафиксирована (commited), то есть успешно завершена, использовавшиеся ею данные остаются в БД вне зависимости от возможных происшествий (ошибки, падения).
- Консистентность (согласованность) (Consistency). В БД записываются только валидные данные (с точки зрения реляционных и функциональных связей). Консистентность зависит от атомарности и изолированности.

Во время выполнения какой-либо транзакции можно исполнять различные SQL-запросы на чтение, создание, обновление и удаление данных. Проблемы начинаются, когда две транзакции используют одни и те же данные. Классический пример — перевод денег со счёта А на счёт Б. Допустим, у нас есть две транзакции:
- Т1 берёт $100 со счёта А и отправляет их на счёт Б.
- Т2 берёт $50 со счёта А и тоже отправляет их на счёт Б.
Теперь рассмотрим эту ситуацию с точки зрения ACID-свойств:
- Атомарность позволяет быть уверенным, что какое бы событие не произошло в ходе Т1 (падение сервера, сбой сети), не может случиться так, что $100 будут списаны с А, но не придут на Б (в противном случае говорят о «несогласованном состоянии»).
- Изолированность говорит о том, что даже если Т1 и Т2 осуществляются одновременно, в результате с А будет списано $100 и та же сумма поступит на Б. Во всех остальных случаях опять говорят о несогласованном состоянии.
- Надёжность позволяет не беспокоиться о том, что Т1 исчезнет, если база упадёт сразу после коммита Т1.
- Консистентность предотвращает возможность создания денег или их уничтожения в системе.
Ниже можно не читать, это уже не важно для понимания остального материала.
Многие БД не обеспечивают полную изолированность по умолчанию, поскольку это приводит к огромным издержкам в производительности. В SQL используется 4 уровня изолированности:
- Сериализуемые транзакции (Serializable). Наивысший уровень изолированности. По умолчанию используется в SQLite. Каждая транзакция исполняется в собственной, полностью изолированной среде.
- Повторяемое чтение (Repeatable read). По умолчанию используется в MySQL. Каждая транзакция имеет свою среду, за исключением одной ситуации: если транзакция добавляет новые данные и успешно завершается, то они будут видимы для других, всё ещё выполняющихся транзакций. Но если транзакция модифицирует данные и успешно завершается, то эти изменения будут не видны для всё ещё выполняющихся транзакций. То есть для новых данных принцип изолированности нарушается.
Например, транзакция А выполняет
SELECT count(1) from TABLE_X
Потом транзакция Б добавляет в таблицу Х и коммитит новые данные. И если после этого транзакция А снова выполняет count(1), то результат будет уже другим.
Это называется фантомным чтением. - Чтение зафиксированных данных (Read commited). По умолчанию используется в Oracle, PostgreSQL и SQL Server. Это то же самое, что и повторяемое чтение, но с дополнительным нарушением изолированности. Допустим, транзакция А читает данные; затем они модифицируются или удаляются транзакцией Б, которая коммитит эти действия. Если А снова считает эти данные, то она увидит изменения (или факт удаления), сделанные Б.
Это называется неповторяемым чтением (non-repeatable read). - Чтение незафиксированных данных (Read uncommited). Самый низкий уровень изолированности. К чтению зафиксированных данных добавляется новое нарушение изолированности. Допустим, транзакция А читает данные; затем они модифицируются транзакцией Б (изменения не коммитятся, Б всё ещё выполняется). Если А считает данные снова, то увидит сделанные изменения. Если же Б будет откачена назад, то при повторном чтении А не увидит изменений, словно ничего и не было.
Это называется грязным чтением.
Большинство БД добавляют собственные уровни изолированности (например, на основе снэпшотов, как в PostgreSQL, Oracle и SQL Server). Также во многих БД не реализованы все четыре вышеописанных уровня, особенно чтение незафиксированных данных.
Пользователь или разработчик может сразу же после установления соединения переопределить уровень изолированности по умолчанию. Для этого достаточно добавить очень простую строчку кода.
5.2.2. Управление параллелизмом
Главное, для чего нам нужны изолированность, согласованность и атомарность, это возможность осуществлять операции записи над одними и теми же данными (добавлять, обновлять и удалять).
Если все транзакции будут только читать данные, то смогут работать одновременно, не влияя на другие транзакции.
Если хотя бы одна транзакция изменяет данные, читаемые другими транзакциями, то БД нужно найти способ скрыть от них эти изменения. Также нужно удостовериться, что сделанные изменения не будут удалены другими транзакциями, которые не видят изменённых данных.
Это называется управлением параллелизмом.
Проще всего просто выполнять транзакции поочерёдно. Но такой подход обычно неэффективен (задействуется лишь одно ядро одного процессора), и к тому же теряется возможность масштабирования.
Идеальный способ решения проблемы выглядит так (при каждом создании или отмене транзакции):
- Мониторить все операции каждой транзакции.
- Если две и более транзакции конфликтуют из-за чтения/изменения одних и тех же данных, то менять очерёдность операций внутри участников конфликта, чтобы свести к минимуму количество причин.
- Выполнять конфликтующие части транзакций в определённом порядке. Неконфликтующие транзакции в это время выполняются параллельно.
- Иметь в виду, что транзакции могут быть отменены.
Если подходить к вопросу более формально, то это проблема конфликта расписаний. Решать её очень трудно, а оптимизация требует больших ресурсов процессора. Корпоративные БД не могут позволить себе часами искать наилучшее расписание для каждой новой транзакции. Поэтому используются менее совершенные подходы, при которых на конфликты тратится больше времени.
5.2.3. Диспетчер блокировок
Для решения вышеописанной проблемы во многих БД используются блокировки (locks) и/или версионность данных.
Если транзакции нужны какие-то данные, то она блокирует их. Если другой транзакции они тоже потребовались, то её придётся ждать, пока первая транзакция не снимет блокировку.
Это называется эксклюзивной блокировкой.
Но слишком расточительно использовать эксклюзивные блокировки в случаях, когда транзакциям нужно всего лишь считать данные. Зачем мешать чтению данных? В таких случаях используются совместные блокировки. Если транзакции нужно считать данные, они применяет к ним совместную блокировку и читает. Это не мешает другим транзакциям тоже применять совместные блокировки и читать данные. Если же какой-то из них нужно изменить данные, то ей придётся подождать, пока все совместные блокировки не будут сняты. Только после этого она сможет применить эксклюзивную блокировку. И тогда уже всем остальным транзакциям придётся ждать её снятия, чтобы считывать эти данные.
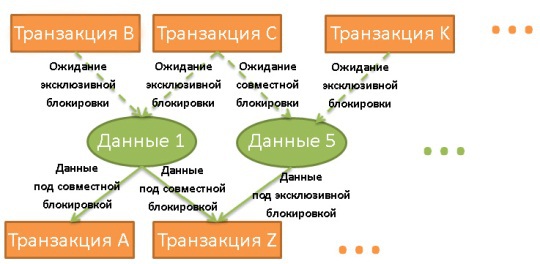
Диспетчер блокировок — это процесс, который применяет и снимает блокировки. Они хранятся в хэш-таблице (ключами являются блокируемые данные). Диспетчер знает для всех данных, какие транзакции применили блокировки или ждут их снятия.
Взаимная блокировка (deadlock)
Использование блокировок может привести к ситуации, когда две транзакции бесконечно ожидают снятия блокировок:
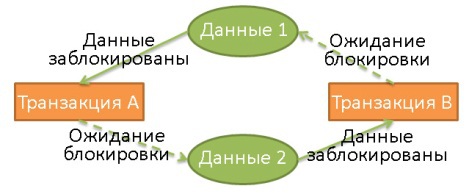
Здесь транзакция А эксклюзивно заблокировала данные 1 и ожидает освобождения данных 2. В то же время транзакция Б эксклюзивно заблокировала данные 2 и ожидает освобождения данных 1.
При взаимной блокировке диспетчер выбирает, какую транзакцию отменить (откатить назад). И решение принять не так просто:
- Будет ли лучше убить транзакцию, которая изменила последний набор данных (а значит, откат будет наименее болезненным)?
- Будет ли лучше убить самую молодую транзакцию, поскольку пользователи других транзакций прождали дольше?
- Будет ли лучше убить транзакцию, которой требуется меньше времени для завершения?
- На сколько других транзакций повлияет откат?
Но прежде чем принять решение, диспетчер должен убедиться, действительно ли возникла взаимная блокировка.
Представим хэш-таблицу в виде диаграммы, как на иллюстрации выше. Если на диаграмме присутствует циклическая связь, то взаимная блокировка подтверждена. Но поскольку проверять на наличие циклов достаточно дорого (ведь диаграмма, на которой отражены все блокировки, будет весьма большой), зачастую используется более простой подход: использование таймаутов. Если блокировка не снимается в течение определённого времени, значит транзакция вошла в состояние взаимной блокировки.
Перед наложением блокировки диспетчер также может проверить, не приведёт ли это к возникновению взаимной блокировки. Но чтобы однозначно на это ответить, тоже придётся потратиться на вычисления. Поэтому подобные предпроверки зачастую представлены в виде набора базовых правил.
Двухфазная блокировка
Проще всего полная изолированность обеспечивается, когда блокировка применяется в начале и снимается в конце транзакции. Это означает, что транзакции перед началом приходится дожидаться снятия всех блокировок, а применённые ею блокировки снимаются лишь по завершении. Такой подход можно применять, но тогда теряется куча времени на все эти ожидания снятия блокировок.
В DB2 и SQL Server применяется протокол двухфазной блокировки, при котором транзакция делится на две фазы:
- Фазу подъёма (growing phase), когда транзакция может только применять блокировки, но не снимать их.
- Фазу спада (shrinking phase), когда транзакция может только снимать блокировки (с данных, которые уже обработаны и не будут обрабатываться снова), но не применять новые.
Частый конфликт, случающийся в отсутствие двухфазной блокировки:
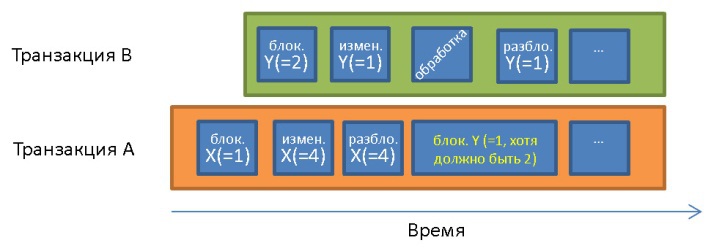
До транзакции А X = 1 и Y = 1. Она обрабатывает данные Y = 1, которые были изменены транзакцией В уже после начала транзакции А. В связи с принципом изолированности транзакция А должна обрабатывать Y = 2.
Цели, решаемые с помощью этих двух простых правил:
- Снимать блокировки, которые больше не нужны, чтобы уменьшить время ожидания других транзакций.
- Предотвращать случаи, когда транзакция получают данные, модифицированные ранее запущенной транзакцией. Такие данные не совпадают с запрашиваемыми.
Данный протокол работает замечательно, за исключением ситуации, когда транзакция модифицировала данные и сняла с них блокировку, после чего была отменена. При этом другая транзакция может считать и изменить данные, которые потом будут откачены назад. Чтобы избежать подобной ситуации, все эксклюзивные блокировки должны быть сняты по завершении транзакции.
Конечно, реальные БД используют более сложные системы, больше видов блокировок и с большей гранулярностью (блокировки строк, страниц, партиций, таблиц, табличных пространств), но суть та же.
Версионность данных
Ещё один способ решения проблемы конфликта транзакций — использование версионности данных.
- Все транзакции могут модифицировать одни и те же данные в одно и то же время.
- Каждая транзакция работает с собственной копией (версией) данных.
- Если две транзакции изменяют одни и те же данные, то принимается только одна из модификаций, другая будет отклонена, а сделавшая её транзакция будет откачена (и, может быть, перезапущена).
Это позволяет увеличить производительность, поскольку:
- Читающие транзакции не блокируют записывающие, и наоборот.
- Неповоротливый диспетчер блокировок не оказывает влияния.
В общем, всё что угодно будет лучше, чем блокировки, за исключением случаев, когда две транзакции записывают одни и те же данные. Причём это может привести к огромному перерасходу дискового пространства.
Оба подхода — блокировки и версионность — имеют плюсы и минусы, многое зависит от того, в какой ситуации они применяются (больше чтений или больше записей). Можете изучить очень хорошую презентацию, посвящённую реализации мультиверсионного управления параллелизмом в PostgreSQL.
В некоторых БД (DB2 до версии 9.7, SQL Server) используются только блокировки. Другие, вроде PostgreSQL, MySQL и Oracle, используются комбинированные подходы.
Примечание: версионность оказывает интересное влияние на индексы. Иногда в уникальном индексе появляются дубликаты, индекс может содержаться больше записей, чем строк в таблице и т.д.
Если часть данных считывается при одном уровне изолированности, а потом он увеличивается, то вырастает количество блокировок, а значит теряется больше времени на ожидания транзакций. Поэтому большинство БД не используют по умолчанию максимальный уровень изолированности.
Как обычно, за более подробной информацией обращайтесь к документации: MySQL, PostgreSQL, Oracle.
5.2.4. Диспетчер логов
Как мы уже знаем, ради увеличения производительности БД хранит часть данных в буферной памяти. Но если сервер падает во время коммита транзакции, то находящиеся в памяти данные будут потеряны. А это нарушает принцип надёжности транзакций.
Конечно, можно всё писать на диск, но при падении вы останетесь с недописанными данными, а это уже нарушение принципа атомарности.
Любые изменения, записанные транзакцией, должны быть отменены или завершены.
Это делается двумя способами:
- Теневые копии/страницы. Каждая транзакция создаёт собственную копию БД (или её часть), и работает с этой копией. В случае ошибки копия удаляется. Если всё прошло успешно, то БД мгновенно переключается на данные из копии с помощью одной уловки на уровне файловой системы, а потом удаляет «старые» данные.
- Лог транзакции. Это специальное хранилище. Перед каждой записью на диск БД пишет информацию в лог транзакции. Так что в случае сбоя БД будет знать, как удалить или завершить незавершённую транзакцию.
WAL
В больших БД с многочисленными транзакциями теневые копии/страницы занимают невероятно много места в дисковой подсистеме. Поэтому в современных БД используется лог транзакции. Он должен размещаться в защищённом от сбоев хранилище.
Большинство продуктов (в частности, Oracle, SQL Server, DB2, PostgreSQL, MySQL и SQLite) работают с логом транзакции через протокол WAL (Write-Ahead Logging). Данные протокол содержит три правила:
- Каждая модификация в БД должна сопровождаться записью в лог, и она должна вноситься ДО того, как данные будут записаны на диск.
- Записи в логе должны располагаться в соответствии с очерёдностью соответствующих событий.
- Когда транзакция коммитится, запись об этом должна вноситься в лог ДО момента успешного завершения транзакции.
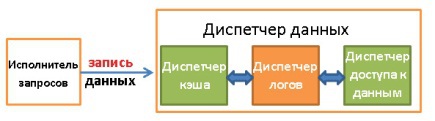
За выполнением этих правил следит диспетчер логов. Логически он расположен между диспетчером кэша и диспетчером доступа к данным. Диспетчер логов регистрирует каждую операцию, выполняемую транзакциями, до момента записи на диск. Вроде верно?
НЕВЕРНО! После всего, через что мы с вами прошли в этой статье, пора бы уже запомнить, что всё связанное с БД подвергается проклятью «эффекта базы данных». Если серьёзно, то проблема в том, что нужно найти способ писать в лог, при этом сохраняя хорошую производительность. Ведь если лог транзакций работает медленно, то он тормозит все остальные процессы.
ARIES
В 1992 год исследователи из IBM создали расширенную версию WAL, которую назвали ARIES. В том или ином виде ARIES используется большинством современных БД. Если вы захотите поглубже изучить этот протокол, можете проштудировать соответствующую работу.
Итак, ARIES расшифровывается как Algorithms for Recovery and Isolation Exploiting Semantics. У этой технологии две задачи:
- Обеспечить хорошую производительность при записи логов.
- Обеспечить быстрое и надёжное восстановление.
Есть несколько причин, по которым БД приходится откатывать транзакцию:
- Пользователь отменил её.
- Ошибка сервера или сети.
- Транзакция нарушила целостность БД. Например, вы применили к колонке условие UNIQUE, а транзакция добавила дубликат.
- Наличие взаимных блокировок.
Но иногда БД может и восстанавливать транзакцию, допустим, в случае сетевой ошибки.
Как это возможно? Чтобы ответить на это, нужно сначала разобраться с тем, какая информация сохраняется в логе.
Логи
Каждая операция (добавления/удаления/изменения) во время выполнения транзакции ведёт к появлению записи в логе. Запись содержит:
- LSN (Log Sequence Number). Это уникальный номер, значение которого определяется хронологическим порядком. То есть если операция А произошла до операции Б, LSN для А будет меньше LSN для Б. В реальности способ генерирования LSN сложнее, поскольку он связан и со способом хранения лога.
- TransID. Идентификатор транзакции, осуществившей операцию.
- PageID. Место на диске, где находятся изменённые данные.
- PrevLSN. Ссылка на предыдущую запись в логе, созданную той же транзакцией.
- UNDO. Способ отката операции.
Например, если была проведена операция обновления, то в UNDO записывается предыдущее значение/состояние изменённого элемента (физический UNDO) или обратная операция, позволяющая вернуться в предыдущее состояние (логический UNDO). В ARIES используется только логический, с физическим работать очень тяжело. - REDO. Способ повтора операции.
Кроме того, каждая страница на диске (для хранения данных, а не лога) содержит LSN последней операции, модифицировавшиеся содержащиеся здесь данные.
Насколько известно, UNDO не используется только в PostgreSQL. Вместо этого используется сборщик мусора, убирающий старые версии данных. Это связано с реализацией версионности данных в этой СУБД.
Чтобы вам было легче представить состав записи в логе, вот визуальный упрощённый пример, в котором выполняется запрос UPDATE FROM PERSON SET AGE = 18;. Пусть он исполняется в транзакции номер 18:
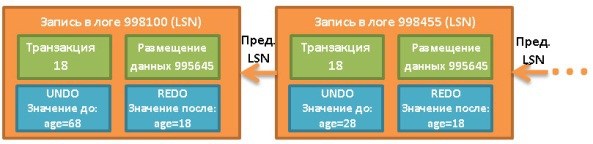
Каждый лог имеет уникальный LSN. Связанные логи относятся к одной и той же транзакции, причём линкуются они в хронологическом порядке (последний лог списка относится к последней операции).
Буфер логов
Чтобы запись в лог не превратилась в узкое место системы, используется буфер логов.
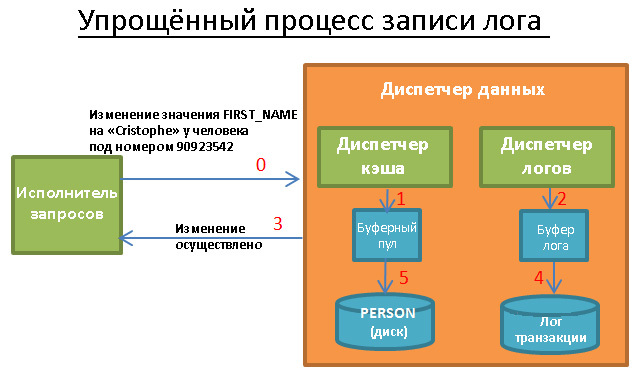
Когда исполнитель запросов запрашивает модифицированные данные:
- Диспетчер кэша хранит их в буфере.
- Диспетчер логов хранит в собственном буфере соответствующий лог.
- Исполнитель запросов определяет, завершена ли операция, и, соответственно, можно ли запрашивать изменённые данные.
- Диспетчер логов сохраняет нужную информацию в лог транзакции. Момент внесения этой записи задаётся алгоритмом.
- Диспетчер кэша записывает изменения на диск. Момент осуществления записи также задаётся алгоритмом.
Когда транзакция коммитится, это означает, что выполнены все шаги с 1 по 5. Запись в лог транзакции осуществляется быстро, поскольку представляет собой «добавление лога куда-то в лог транзакции». В то же время запись данных на диск представляет собой более сложную процедуру, при этом учитывается, что данные впоследствии должны быть быстро считаны.
Политики STEAL и FORCE
Для увеличения производительности шаг номер 5 нужно делать после коммита, поскольку в случае сбоя всё ещё возможно восстановить транзакцию с помощью REDO. Это называется «политика NO-FORCE».
Но БД может выбрать и политику FORCE ради уменьшения нагрузки во время восстановления. Тогда шаг номер 5 выполняется до коммита.
Также БД выбирает, записывать ли данные на диск пошагово (политика STEAL) или, если диспетчер буфера должен дождаться коммита, записать всё разом (NO-STEAL). Выбор зависит от того, что вам нужно: быструю запись с долгим восстановлением или быстрое восстановление?
Как упомянутые политики влияют процесс восстановления:
- Для STEAL/NO-FORCE нужны UNDO и REDO. Производительность высочайшая, но более сложная структура логов и процессов восстановления (вроде ARES). Эту комбинацию политик использует большинство БД.
- Для STEAL/FORCE нужен только UNDO.
- Для NO-STEAL/NO-FORCE — только REDO.
- Для NO-STEAL/FORCE вообще ничего не нужно. Производительность в данном случае самая низкая, и требуется огромное количество памяти.
Восстановление
Итак, как нам можно использовать наши замечательные логи? Предположим, что новый сотрудник порушил БД (правило №1: всегда виноват новичок!). Вы её перезапускаете и начинается процесс восстановления.
ARIES восстанавливает в три этапа:
- Анализ. Считывается весь лог транзакции, чтобы можно было восстановить хронологию событий, произошедших в процессе падения базы. Это помогает определить, какую транзакцию нужно откатить. Откатываются все транзакции без приказа о коммите. Также система решает, какие данные должны были записаться на диск во время сбоя.
- Повтор. Для обновления БД до состояния перед падением используется REDO. Его логи обрабатываются в хронологическом порядке. Для каждого лога считывается LSN страницы на диске, содержащей данные, которые нужно изменить.
Если LSN(страницы_на_диске)>=LSN(записи_в_логе), то значит данные уже были записаны на диск перед сбоем. Но значение было перезаписано операцией, которая была выполнена после записи в лог и до сбоя. Так что ничего не сделано, на самом деле.
Если LSN(страницы_на_диске)<LSN(записи_в_логе), то страница на диске уже обновлена.
Повтор выполняется даже для транзакций, которые будут откачены, потому что это упрощает процесс восстановления. Но современные БД наверняка этого не делают. - Отмена. На этом этапе откатываются все незавершённые на момент сбоя транзакции. Процесс начинается с последних логов каждой транзакции и обрабатывает UNDO в обратном хронологическом порядке с помощью PrevLSN.
В процессе восстановления лог транзакции должен знать о действиях, выполняемых при восстановлении. Это нужно для синхронизации сохраняемых на диск данных теми, что записаны в логе транзакции. Можно удалить записи транзакций, которые откатываются, но это очень трудно сделать. Вместо этого ARIES вносит компенсирующие записи в лог транзакции, логически аннулирующие записи откатываемых транзакций.
Если транзакция отменена «вручную», или диспетчером блокировок, или из-за сбоя сети, то этап анализа не нужен. Ведь информация для REDO и UNDO содержится в двух таблицах, размещённых в памяти:
- В таблице транзакций (тут хранятся состояния всех текущих транзакций).
- В таблице грязных страниц (здесь содержится информация о том, какие данные нужно записать на диск).
Как только появляется новая транзакция, эти таблицы обновляются диспетчером кэша и диспетчером транзакций. А поскольку таблицы хранятся в памяти, то при падении БД они пропадают.
Этап анализа нужен как раз для восстановления обеих таблиц с помощью информации из лога транзакций. Для ускорения этого этапа в ARIES используются контрольные точки. На диск время от времени записывается содержимое обеих таблиц, а также последний на момент записи LSN. Так что во время восстановления анализируются только логи, следующие после этого LSN.
6. Заключение
В качестве дополнительного обзорного чтива про базы данных можно порекомендовать статью Architecture of a Database System. Это хорошее введение в тему, написанное довольно понятным языком.
Если вы внимательно прочитали весь вышеизложенный материал, то наверняка получили представление о том, насколько велики возможности баз данных. Однако в этой статье не затронуты другие важные проблемы:
- Как управлять кластеризованными БД и глобальными транзакциями.
- Как получить снэпшот, если база всё работает.
- Как эффективно хранить и сжимать данные.
- Как управлять памятью.
Так что подумайте дважды, прежде чем выбирать между забагованной NoSQL и цельной реляционной БД. Не поймите неправильно, некоторые NoSQL-базы очень хороши. Но они ещё далеки от совершенства и могут помочь только в решении специфических проблем, связанных с некоторыми приложениями.
Итак, если вас кто-нибудь спросит, а как же работают базы данных, то вместо того, чтобы плюнуть и уйти, вы можете ответить:

Или же просто можете дать ссылку на эту статью.
