
Понимание модели ввода/вывода вашего приложения может привести и к пониманию различий между приложением, работающим с нагрузкой, под которой оно создавалось, и тем, которое лицом к лицу столкнулось с реальным способом своего применения. Возможно, если ваше приложение невелико и не создаёт большой нагрузки, то для него это не так важно. Но по мере роста трафика использование ошибочной модели ввода/вывода может погрузить вас в мир боли.
Как и в большинстве других ситуаций с несколькими возможными решениями, дело не в том, какой из вариантов лучше, дело в понимании компромиссов. В этой статье мы сравним Node, Java, Go и PHP из-под Apache, обсудим модели ввода/вывода в разных языках, рассмотрим достоинства и недостатки каждой модели и прогоним простенькие бенчмарки. Если вас волнует производительность ввода/вывода вашего следующего веб-приложения, то эта статья для вас.
Основы ввода/вывода: освежим знания
Для понимания факторов, относящихся к вводу/выводу, сначала нужно вспомнить некоторые концепции, используемые на уровне ОС. Маловероятно, что со многими из них вам придётся иметь дело напрямую, скорее всего, вы будете работать с ними опосредованно, через runtime-окружение приложения. И подробности играют важную роль.
Системные вызовы
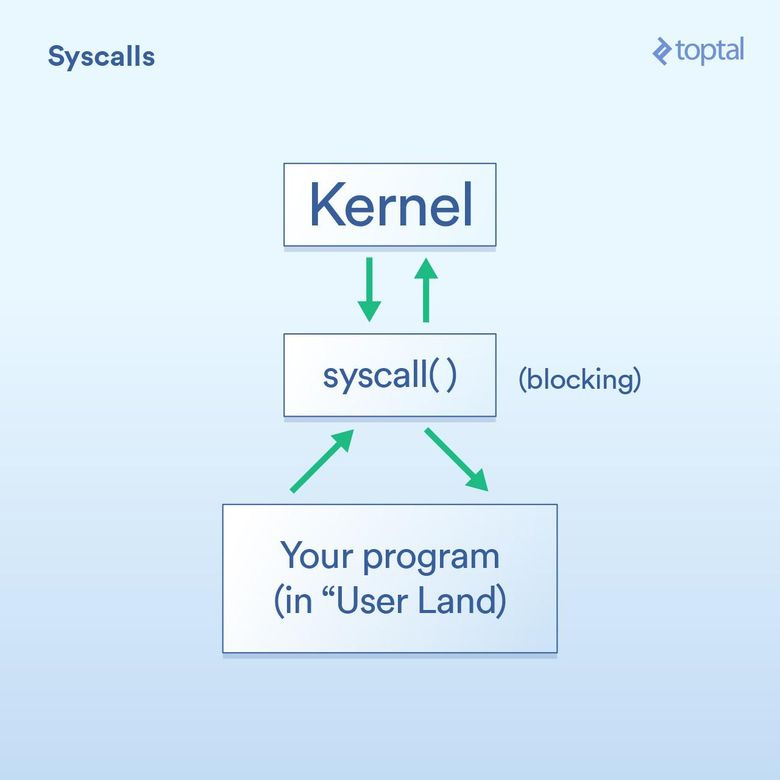
Возьмём сначала системные вызовы, которые можно описать так:
Ваша программа (в так называемом пользовательском пространстве) должна просить ядро операционной системы выполнить операцию ввода/вывода от имени вашей программы.
Системные вызовы — это способ, с помощью которого программа просит ядро что-то сделать. Специфика их реализаций зависит от ОС, но базовый принцип везде один и тот же. Должна быть какая-то конкретная инструкция для передачи управления из вашей программы через ядро (как вызов функции, только со специальной «добавкой» для работы в такой ситуации). В целом системные вызовы блокирующие, т. е. программа ждёт, пока ядро не вернётся к вашему коду.
- Ядро выполняет базовую операцию ввода/вывода на нужном устройстве (диске, сетевой карте и т. д.) и отвечает системному вызову. В реальной жизни ядро может выполнять целый ряд действий после вашего запроса, включая ожидание готовности устройства, обновление его внутреннего состояния и т. д. Но вам об этом не нужно беспокоиться. Это обязанности ядра.
Блокирующие и неблокирующие вызовы
Выше говорилось, что системные вызовы — блокирующие, и в целом это так. Однако некоторые вызовы можно охарактеризовать как неблокирующие. Это означает, что ядро принимает ваш запрос, кладёт его в очередь или какой-то буфер, а затем безо всякого ожидания немедленно возвращается к выполняемому в данный момент вводу/выводу. Так что «блокирование» происходит лишь на очень небольшой период времени, достаточный для постановки вашего запроса в очередь.
Чтобы было понятнее, вот некоторые примеры (системных вызовов Linux):
read()— блокирующий вызов: вы передаёте ему дескриптор (handle), говорящий, какой файл взять и в какой буфер доставить считываемые данные; вызов возвращается, когда данные окажутся в месте назначения. Всё просто и понятно.epoll_create(),epoll_ctl()иepoll_wait()— вызовы, которые, соответственно, позволяют создавать группу дескрипторов для прослушивания; добавлять дескрипторы в группу / удалять их из неё; блокировать до тех пор, пока не появится активность. Это позволяет эффективно управлять большим количеством операций ввода/вывода с помощью одного потока выполнения. Хорошо, что есть такая функциональность, но её довольно сложно использовать.
Важно понимать различия в тайминге. Если ядро процессора работает на частоте 3 ГГц, без каких-либо оптимизаций, то оно выполняет 3 миллиарда тактов в секунду (3 такта в наносекунду). Для неблокирующего системного вызова могут потребоваться десятки тактов, то есть несколько наносекунд. Вызов, блокирующий получение информации по сети, может выполняться гораздо дольше: например, 200 миллисекунд (1/5 секунды). То есть если неблокирующий вызов длится 20 наносекунд, то блокирующий — 200 миллионов наносекунд. Процесс ждёт выполнения блокирующего вызова в 10 миллионов раз дольше.

Ядро предоставляет средства для выполнения как блокирующих («считай данные из сетевого подключения и дай их мне»), так и неблокирующих («скажи мне, когда в этих сетевых подключениях появятся новые данные») вводов/выводов. И в зависимости от выбранного механизма длительность блокировки вызывающего процесса будет разительно отличаться.
Диспетчеризация (Scheduling)
Диспетчеризация также крайне важна, если у вас есть много потоков выполнения или процессов, которые начинают блокировать.
Для нашей задачи разница между процессом и потоком выполнения невелика. В реальной жизни самое главное отличие между ними с точки зрения производительности заключается в том, что поток выполнения использует одну и ту же область памяти, а процессы получают собственные области. Поэтому отдельные процессы требуют гораздо больше памяти. Но если мы говорим о диспетчеризации, то всё сводится к тому, сколько потокам и процессам нужно времени выполнения на доступных ядрах процессора. Если у вас есть 300 потоков и восемь ядер, то придётся поделить время так, чтобы каждый поток получил свою долю: каждое ядро недолго выполняет один поток, а затем переходит к следующему. Это делается с помощью переключения контекста, когда процессор переключается с одного выполняемого потока/процесса на другой.
Но с этими переключениями контекста связаны определённые затраты — они занимают какое-то время. Иногда это может происходить меньше, чем за 100 наносекунд, но нередко переключение занимает 1000 наносекунд и больше, в зависимости от особенностей реализации, скорости/архитектуры процессора, его кеша и т. д.
И чем больше потоков выполнения (или процессов), тем больше переключений контекста. Если речь идёт о тысячах потоков, когда на переключения с каждого из них уходят сотни наносекунд, то всё выполняется очень неторопливо.
Однако неблокирующие вызовы по существу говорят ядру: «Вызови меня только тогда, когда появятся новые данные или событие в одном из этих подключений». Эти вызовы созданы для эффективной обработки большой нагрузки по вводу/выводу и уменьшения количества переключений контекста.
Ещё не потеряли нить рассуждения? Сейчас начинается самое интересное: мы рассмотрим, что некоторые популярные языки могут делать с вышеописанными инструментами, и сформулируем выводы о компромиссах между простотой использования и производительностью… и другими интересными пикантностями.
В качестве примечания: в статье приведены тривиальные примеры (в некоторых случаях неполные, когда будут показаны только релевантные биты). Обращения к базе данных, внешние системы кеширования (Memcache и т. д.) и многие другие вещи в результате будут выполняться под капотом, но, по сути, это те же вызовы операций ввода/вывода, который окажут то же влияние, что и приведённые в статье простенькие примеры. В сценариях, в которых ввод/вывод описан как блокирующий (PHP, Java), HTTP-запросы и операции чтения и записи сами по себе являются блокирующими вызовами: в системе скрыто немало операций ввода/вывода, что приводит к проблемам с производительностью, которые надо учитывать.
На выбор языка программирования для проекта влияет много факторов. Также немало факторов влияет на производительность. Но если вас беспокоит, что ваша программа в основном упрётся во ввод/вывод, если производительность ввода/вывода жизненно важна для проекта, то вам нужно знать обо всех этих факторах.
В 1990-х многие носили обувь Converse и писали CGI-скрипты на Perl. Затем появился PHP, и хотя его любят критиковать, но этот язык сильно облегчил создание динамических веб-страниц.
PHP использует очень простую модель. Существует ряд вариаций, но среднестатистический PHP-сервер выглядит так.
От пользовательского браузера поступает HTTP-запрос на ваш веб-сервер Apache. Тот создаёт отдельный процесс для каждого запроса, применяя некоторые оптимизации, позволяющие повторно использовать процессы ради минимизации их количества (создание процесса, к слову, задача медленная). Apache вызывает PHP и просит его выполнить соответствующий .php-файл, лежащий на диске. PHP-код выполняется и делает блокирующие вызовы ввода/вывода. Вы вызываете в PHP file_get_contents(), который под капотом выполняет системные вызовы read() и ждёт результаты.
Конечно, реальный код просто встроен прямо в вашу страницу, а операции являются блокирующими:
<?php
// blocking file I/O
$file_data = file_get_contents(‘/path/to/file.dat’);
// blocking network I/O
$curl = curl_init('http://example.com/example-microservice');
$result = curl_exec($curl);
// some more blocking network I/O
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
?>Вот как это выглядит с точки зрения интеграции в систему:
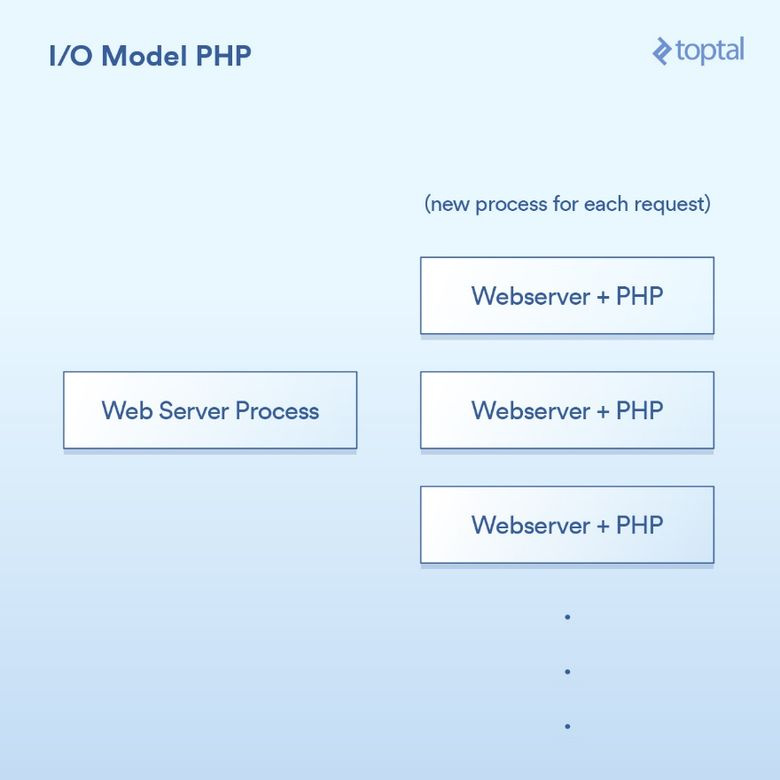
Всё просто: один процесс на запрос. Вызовы ввода/вывода просто блокируют. Достоинства? Схема простая, и она работает. Недостатки? После 20 тысяч параллельных клиентских обращений сервер просто расплавится. Этот подход плохо масштабируем, потому что не используются предоставляемые ядром ОС инструменты для работы с большим объёмом ввода/вывода (epoll и пр.). Ситуацию усугубляет то, что выполнение отдельного процесса на каждый запрос приводит к потреблению большого объёма системных ресурсов, особенно памяти, которая зачастую заканчивается в первую очередь.
Примечание: в Ruby используется очень похожий подход, и в широком, общем смысле в рамках нашей статьи они могут считаться одинаковыми.
Многопоточный подход: Java
Java пришёл в те времена, когда вы как раз купили своё первое доменное имя, и было так круто везде в разговоре вставлять словечки «точка ком». В Java встроена многопоточность (multithreading) — отличная функция (особенно на момент своего создания).
Большинство Java веб-серверов создают новый поток выполнения для каждого поступающего запроса, и уже в этом потоке в конце концов вызывают функцию, которую написали вы, разработчик приложения.
Выполнение ввода/вывода в Java Servlet выглядит так:
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
// blocking file I/O
InputStream fileIs = new FileInputStream("/path/to/file");
// blocking network I/O
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
InputStream netIs = urlConnection.getInputStream();
// some more blocking network I/O
out.println("...");
}Поскольку наш метод doGet соответствует одному запросу и выполняется в собственном потоке, то вместо отдельного процесса для каждого запроса, требующего отдельной памяти, мы получаем отдельный поток выполнения. Это даёт приятные возможности, например можно поделиться состоянием или закешировать данные между потоками, потому что они способны обращаться к памяти друг друга. Но оказываемое при этом влияние на взаимодействие с диспетчером почти аналогично тому, что и в примере с PHP. Каждый запрос получает новый поток, и различные операции ввода/вывода блокируют внутри потока до тех пор, пока запрос не будет полностью выполнен. Потоки объединяются (pooled), чтобы минимизировать стоимость их создания и уничтожения, но в любом случае если у нас тысячи подключений, то создаются тысячи потоков, что плохо сказывается на работе диспетчера.
Важным поворотным моментом в Java 1.4 (и значительным апгрейдом в 1.7) стала возможность выполнения неблокирующих вызовов ввода/вывода. Большинство приложений, веб- и прочих, их не используют, но они хотя бы есть. Некоторые Java веб-серверы пытаются как-то применять преимущества неблокирующих вызовов, однако подавляющее большинство развёрнутых Java-приложений всё ещё работает так, как описано выше.

Java из коробки обладает некоторыми хорошими возможностями с точки зрения ввода/вывода, но они всё же не решают проблем, которые возникают в приложениях, активно использующих ввод/вывод и сильно тормозящих из-за обработки многих тысяч блокирующих потоков выполнения.
Неблокирующий ввод/вывод: Node
Node.js снискал себе популярность с точки зрения хорошей производительности ввода/вывода. Любой, кто хотя бы вскользь познакомился с Node, говорит, что он неблокирующий, что он эффективно обрабатывает операции ввода/вывода. И в целом это так. Но дьявол в деталях, точнее в колдовстве, с помощью которого достигается хорошая производительность.
Суть сдвига парадигмы, реализуемого Node, такова: вместо того чтобы сказать: «Напиши здесь свой код для обработки запроса», он говорит: «Напиши здесь свой код для начала обработки запроса». Каждый раз, когда вам нужно использовать ввод/вывод, вы делаете запрос и отдаёте callback-функцию, который Node вызовет по окончании работы.
Типичный код Node для выполнения операции ввода/вывода по запросу выглядит так:
http.createServer(function(request, response) {
fs.readFile('/path/to/file', 'utf8', function(err, data) {
response.end(data);
});
});Здесь есть две callback-функции. Первая вызывается, когда стартует запрос. Вторая — когда становятся доступными данные файла.
По сути, это позволяет Node эффективно обрабатывать ввод/вывод между двумя callback-функциями. Более подходящий сценарий: вызов базы данных из Node. Но я не буду приводить конкретный пример, потому что там используется тот же принцип: вы инициируете вызов базы данных и даёте Node callback-функцию; он с помощью неблокирующих вызовов отдельно выполняет операции ввода/вывода, а когда запрошенные вами данные становятся доступны, вызывает callback-функцию. Этот механизм постановки в очередь вызовов ввода/вывода с последующим вызовом callback-функции называется циклом событий (event loop). И он хорошо работает.
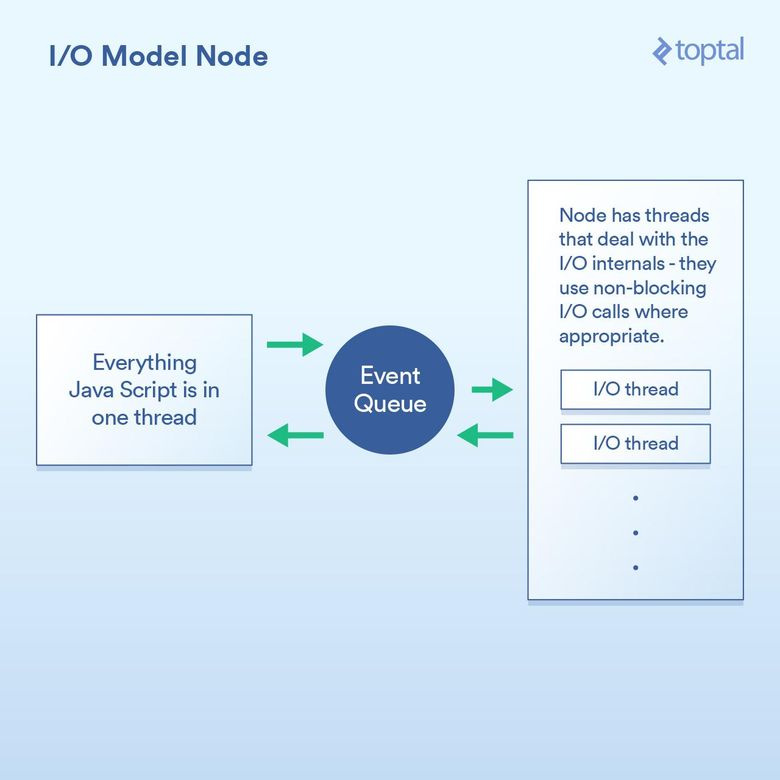
Но под капотом модели есть уловка. По большей части она связана с реализацией JS-движка V8 (JS-движок Chrome, используемый Node). Весь JS-код, который вы пишете, выполняется в одном потоке. Задумайтесь над этим. Это означает, что в то время как ввод/вывод происходит с помощью эффективных неблокирующих методик, ваш JS выполняет все связанные с процессором операции в одном потоке, когда один кусок кода блокирует следующий. Характерный пример того, к чему это способно привести: циклический проход по записям базы данных, чтобы неким образом обработать их, прежде чем отдавать клиенту. Вот как это может работать:
var handler = function(request, response) {
connection.query('SELECT ...', function (err, rows) {
if (err) { throw err };
for (var i = 0; i < rows.length; i++) {
// do processing on each row
}
response.end(...); // write out the results
})
};Хотя Node и обрабатывает ввод/вывод эффективно, но, например, цикл for использует такты процессора внутри одного, и только одного основного потока выполнения. И если у вас 10 тысяч подключений, то этот цикл может убить всё приложение, в зависимости от того, сколько он длится. Ведь в рамках основного потока выполнения нужно поочерёдно уделять процессорное время каждому запросу.
Вся эта концепция основана на предпосылке, что операции ввода/вывода — самая медленная часть, а значит, важнее всего обрабатывать их как можно эффективнее, даже за счёт последовательной обработки всех остальных операций. В каких-то случаях это справедливо, но не во всех.
Другое дело — это лишь мнение, — что может быть весьма утомительным писать кучу вложенных колбэков, и кто-то считает, что это сильно ухудшает читабельность кода. Нередко в Node-коде можно встретить четыре, пять и даже больше уровней вложенности.
И мы снова вернулись к компромиссам. Модель Node хорошо работает в том случае, если основная причина плохой производительности связана с вводом/выводом. Но её ахиллесова пята в том, что вы можете использовать функцию, которая обрабатывает HTTP-запрос, вставить код, зависящий от процессора, и это приведёт к тормозам во всех сетевых подключениях.
Естественное неблокирование: Go
Прежде чем перейти к обсуждению Go, должен сообщить, что я его поклонник. Я использовал этот язык во многих проектах, открыто пропагандирую предоставляемые им выигрыши в производительности, причём отмечаю их роль в своей работе.
И всё-таки давайте посмотрим, как Go работает с операциями ввода/вывода. Одна из ключевых особенностей языка — в нём есть собственный диспетчер. Вместо привязки каждого потока выполнения к одному потоку на уровне ОС Go использует концепцию горутин. В зависимости от задачи, выполняемой горутиной, среда выполнения языка может приписывать горутину к потоку ОС и заставлять исполнять её — или переводить её в режим ожидания и не ассоциировать с потоком ОС. Каждый запрос, поступающий от HTTP-сервера Go, обрабатывается в отдельной горутине.
Схема работы диспетчера:

Под капотом это реализовано с помощью разных ухищрений в runtime-среде Go, которая реализует вызовы ввода/вывода, делая запросы на запись/чтение/подключение и т. д., затем переводя текущую горутину в спящий режим с информацией, позволяющей снова активировать горутину, когда можно будет предпринять следующее действие.
Фактически runtime-среда Go делает нечто, не слишком отличающееся от того, что делает Node. За исключением того, что механизм колбэков встроен в реализацию вызовов ввода/вывода и автоматически взаимодействует с диспетчером. Также Go не страдает от проблем, возникающих из-за того, что вам приходится помещать весь обрабатывающий код в один поток выполнения: Go автоматически распределяет горутины по такому количеству потоков ОС, какое он считает подходящим в соответствии с логикой диспетчера. Код выглядит так:
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
// the underlying network call here is non-blocking
rows, err := db.Query("SELECT ...")
for _, row := range rows {
// do something with the rows,
// each request in its own goroutine
}
w.Write(...) // write the response, also non-blocking
}Как видите, базовая структура кода того, что мы делаем, напоминает структуру более простых подходов, но под капотом использует неблокирующий ввод/вывод.
В большинстве случаев нам удаётся «взять лучшее от двух миров». Для всех важных вещей используется неблокирующий ввод/вывод; при этом код выглядит как блокирующий, но всё же получается более лёгким в понимании и сопровождении. Остальное решается при взаимодействии между диспетчерами Go и ОС. Это неполное описание магии, и если вы создаёте большую систему, то рекомендуется уделить время более глубокому изучению работы с вводом/выводом. В то же время окружение, полученное вами из коробки, хорошо работает и масштабируется.
У Go есть свои недостатки, но в целом они не относятся к работе с вводом/выводом.
Ложь, наглая ложь и бенчмарки
Трудно привести конкретные тайминги переключения контекста при использовании вышеописанных моделей. К тому же эта информация вряд ли была бы вам полезна. Вместо этого предлагаю прогнать простенькие бенчмарки и сравнить общую производительность HTTP-сервера в разных серверных окружениях. Но имейте в виду, что на результирующую производительность «HTTP-запрос/ответ» влияет много факторов, и приведённые здесь данные позволят получить лишь общее представление.
Для каждой из сред я написал код, он считывает 64-килобайтный файл, заполненный случайными байтами, затем N раз применяет к нему хеширование по алгоритму SHA-256 (N определяется в строке URL-запроса, например, .../test.php?n=100) и выводит на экран получившийся хеш в шестнадцатеричном представлении. Это очень простой способ прогнать один и тот же бенчмарк с единообразным количеством операций ввода/вывода и управляемым способом увеличения использования процессора.
Более подробную информацию о тестируемых средах можно почитать здесь.
Сначала рассмотрим примеры с небольшим распараллеливанием (low concurrency). Прогоним 2000 итераций с 300 одновременными запросами и применением только одного хеширования к каждому запросу (N = 1):
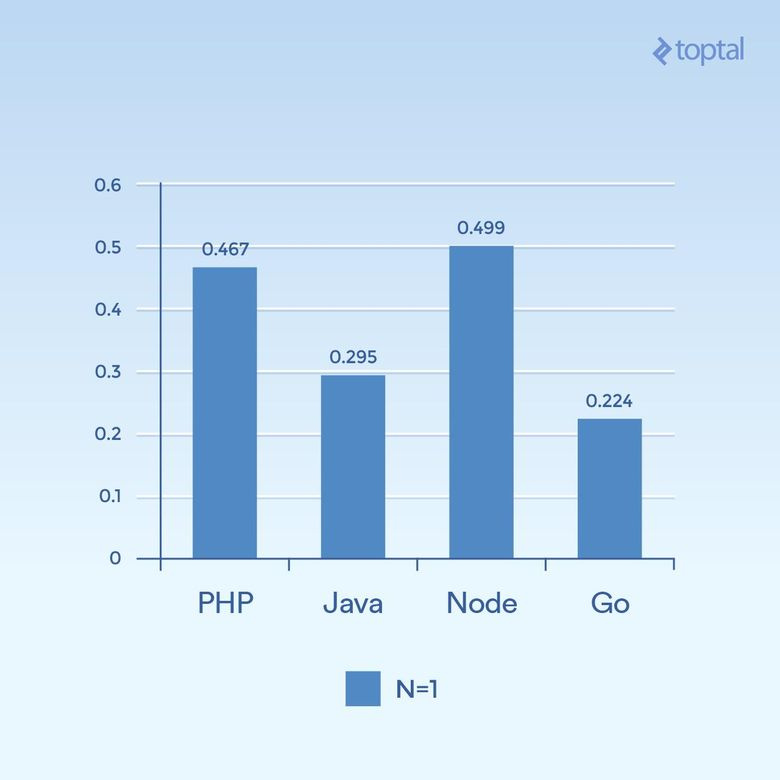
Сколько миллисекунд потребовалось на выполнение всех одновременных запросов. Чем меньше, тем лучше
На основании одного графика трудно делать какие-то выводы. Но создаётся впечатление, что при таком объёме подключений и вычислений мы видим результаты, которые больше похожи на общую продолжительность выполнения самих языков, а не длительность обработки операций ввода/вывода. Обратите внимание, что медленнее всего работают так называемые скриптовые языки (слабая типизация, динамическая интерпретация).
Увеличим N до 1000, оставив 300 одновременных запросов — нагрузка та же, но нужно выполнить в сто раз больше операций хеширования (значительно повышается нагрузка на процессор):
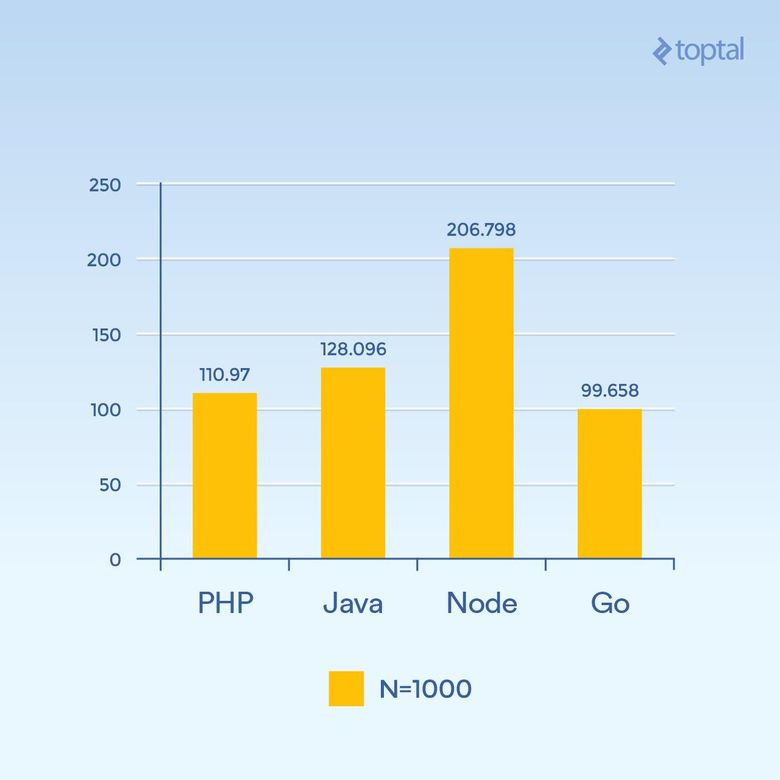
Сколько миллисекунд потребовалось на выполнение всех одновременных запросов. Чем меньше, тем лучше
Неожиданно значительно упала производительность Node, потому что операции, активно использующие процессор в каждом запросе, блокируют друг друга. Любопытно, что PHP стал гораздо лучше по производительности (по сравнению с другими) и обогнал Java. Нужно отметить, что реализация SHA-256 в PHP написана на Си, и в этом цикле путь выполнения (execution path) занимает гораздо больше времени, потому что теперь нам нужны 1000 итераций хеширования.
Теперь сделаем 5000 одновременных запросов (N = 1) или как можно ближе к этому количеству. К сожалению, в большинстве сред частота отказов была значительной. На графике отражено общее количество запросов в секунду.
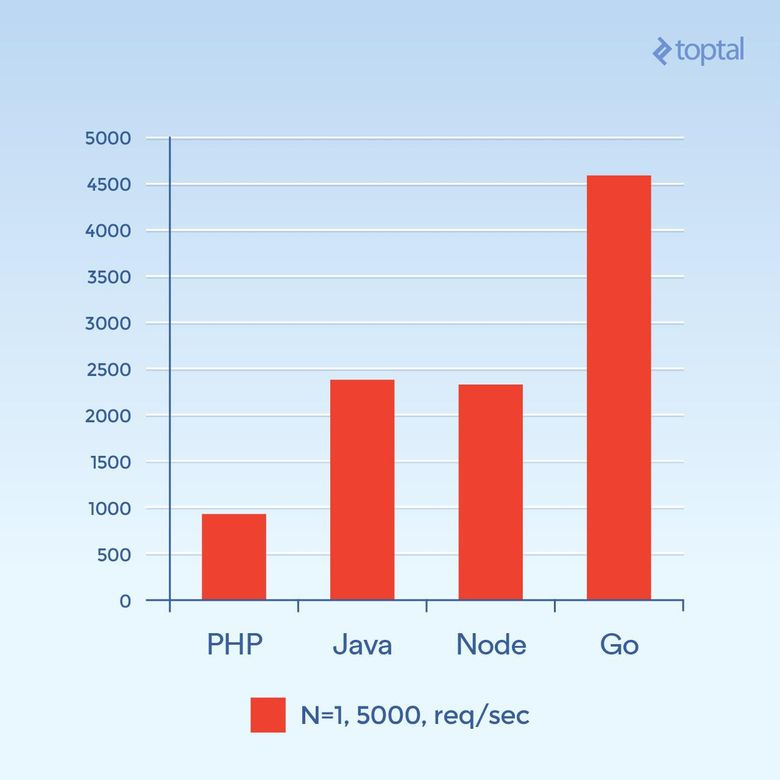
Общее количество запросов в секунду. Чем выше, тем лучше
Картина совсем другая. Это предположение, но похоже на то, что в связке PHP + Apache при большом количестве подключений доминирующим фактором становятся удельные накладные расходы, связанные с созданием новых процессов и выделением им памяти, что негативно влияет на производительность PHP. Go стал победителем, за ним идут Java, потом Node, и последний — PHP.
Несмотря на многочисленность факторов, влияющих на общую пропускную способность, и их варьирование в зависимости от приложения, чем больше вы будете знать о внутренностях протекающих процессов и сопутствующих компромиссах, тем лучше.
В итоге
Подводя итог вышесказанному, очевидно, что по мере развития языков развиваются и решения по работе с масштабными приложениями, обрабатывающими большое количество операций ввода/вывода.
Честно говоря, несмотря на данные в этой статье описания, в PHP и Java есть реализации неблокирующих вводов/выводов, доступных для использования в веб-приложениях. Но они не так распространены, как вышеописанные подходы, и потому нужно принимать в расчёт сопутствующие этим подходам накладные операционные расходы. Не говоря уже о том, что ваш код должен быть структурирован так, чтобы работать в подобных средах. Ваше «нормальное» PHP или Java веб-приложение без серьёзных модификаций вряд ли будет работать в такой среде.
Для сравнения, если выбрать несколько важных факторов, влияющих на производительность и простоту использования, то получается такая таблица:
| Язык | Потоки vs. процессы | Неблокирующие I/O | Простота использования |
|---|---|---|---|
| PHP | Процессы | Нет | |
| Java | Потоки | Доступно | Нужны колбэки |
| Node.js | Потоки | Да | Нужны колбэки |
| Go | Потоки (горутины) | Да | Колбэки не нужны |
С точки зрения потребления памяти потоки выполнения должны быть гораздо эффективнее процессов. Если также учесть факторы, относящиеся к неблокирующим операциям ввода/вывода, то по мере движения вниз по таблице общая ситуация с вводом/выводом улучшается. Так что если бы я выбирал победителя, то предпочёл бы Go.
Но в любом случае выбор среды для создания проекта тесно связан с тем, насколько хорошо ваша команда знакома с той или иной средой, а значит, и с общей потенциальной продуктивностью. Поэтому не для каждой команды будет целесообразно с головой погрузиться в разработку веб-приложений и сервисов на Node или Go. Одна из частых причин неиспользования тех или иных языков и/или сред — необходимость поиска разработчиков, знакомых с данным инструментом. Тем не менее за последние 15 лет многое изменилось.
Надеюсь, всё вышесказанное поможет вам лучше понять, что происходит под капотом нескольких языков и сред, и подскажет, как лучше решать проблемы масштабирования ваших приложений. Удачного ввода и вывода!
