

14 мая прошёл отборочный раунд Russian Code Cup 2017. По традиции выкладываем разбор задач и подводим итоги.
A. Маленькие числа
B. Новая клавиатура
C. Складывание фигуры
D. Остроугольные треугольники
E. Объединение массивов
F. Два поддерева
В раунде участвовали 603 человека: приблизительно по 200 лучших программистов с каждого квалификационного раунда. По результатам отборочного раунда мы взяли в финал 55 участников.
Все шесть задач отборочного раунда не смог решить ни один участник. С пятью задачами справились 15 человек. С четырьмя — еще 55 участников.
Трое лучших:
- На первом месте со значительным отрывом от преследователей (на 15 минут) оказался Ипатов Михаил из Костромы.
- Второе место занял Тихомиров Михаил из Москвы.
- На третьем месте — Пышкин Игорь из Санкт-Петербурга.
Кроме того, в топ-10 попали:
- Митричев Петр, Цюрих, Швейцария
- Геннадий Короткевич, Санкт-Петербург, Россия
- Александр Останин, Долгопрудный, Россия
- Ершов Станислав, Санкт-Петербург, Россия
- Djokic Nikola
- Данилюк Алексей, Одинцово, Россия
- Du Yuhao, Пекин, Китай
Всех участников и рейтинговую таблицу раунда можно найти здесь.
Поздравляем всех прошедших в финал, который состоится в сентябре 2017 года. Ну а теперь — разбор задач.
A. Маленькие числа
Ограничение по времени — 2 секунды
Ограничение по памяти — 256 мегабайт
У мальчика Влада есть два любимых числа a и b. Недавно его в школе научили делить и умножать, и он сразу побежал делить и умножать свои любимые числа.
Сначала он написал в тетрадке числа a и b, после чего решил, что будет последовательно производить с ними одну из трёх операций:
- Поделить оба числа на какой-то из их общих делителей;
- Поделить a на один из его делителей g, а b умножить на g;
- Поделить b на один из его делителей g, а a умножить на g.
После каждой операции он стирает старые числа, записывает два получившихся числа обратно в тетрадку и может продолжить операции с ними.
Так как Влад ещё маленький, ему нравятся числа поменьше, потому он стремится минимизировать сумму чисел, написанных в тетрадке. Сам он не справляется. Помогите Владу определить, какую минимальную сумму чисел возможно получить такими операциями, и приведите пример пары чисел, которая может получиться в итоге.
Формат входных данных
Входные данные содержат несколько тестовых наборов. В первой строке задано количество тестов t (1 ≤ t ≤ 500).
Каждый тест описывается следующим образом: в единственной строке описания теста содержатся два числа a и b (1 ≤ a, b ≤ 109) — любимые числа Влада.
Формат выходных данных
Для каждого теста в отдельной строке выведите ответ на него — пару с минимальной суммой, которую можно получить применяя операции из условия.
Если ответов несколько, то разрешается вывести любой из них.
Примеры
Входные данные
2
4 5
4 6
Выходные данные
1 5
2 3
Для начала разложим числа a и b на простые.
Теперь заметим, что если какое-то простое число p входит в произведение ab в степени выше первой, то мы можем либо сразу поделить оба числа на число p, либо если же одно из чисел не делится на p, то перенесём в него множитель p из другого числа, после чего поделим на p.
Очевидно, что чётность вхождения простых чисел в произведение ab не меняется во всех операциях. Тогда давайте оставим все простые в первой степени. Остались числа p1, p2, ..., pn. Давайте назовём произведение всех этих простых чисел d, d ≤ ab. Утверждается, что этих простых не может быть больше 14. Если 1 ≤ a, b ≤ 109, то произведение ab ≤ 1018, а произведение первых 15 простых чисел превышает 1018). Теперь заметим, что конечный ответ — пара чисел (x, y) таких, что xy = d. Из этого следует, что второй элемент пары определяется однозначно по первому. Переберём все возможные делители d числа x за O(2n), и выберем наилучшую пару.
B. Новая клавиатура
Ограничение по времени — 2 секунды
Ограничение по памяти — 256 мегабайт
Петя купил новую клавиатуру. Она поддерживает n раскладок. В каждой раскладке можно набирать некоторое подмножество строчных букв латинского алфавита. Пронумеруем раскладки от 1 до n.
Петя хочет набрать некоторое сообщение, состоящее из m строчных букв латинского алфавита. Исходно активна первая раскладка. Петя может производить следующие действия:
- Переключить раскладку. Тогда, если текущая раскладка имела номер i, новая раскладка будет иметь номер i mod n + 1, где mod — операция взятия остатка по модулю. Если предыдущим действием Петя также переключал раскладку, это действие займет b миллисекунд, иначе это действие займет a миллисекунд.
- Набрать символ. Петя может добавить в конец текущего сообщения любую букву, содержащуюся в текущей раскладке. На это действие он потратит c миллисекунд.
Помогите Пете определить минимальное время, необходимое, чтобы набрать сообщение, либо выясните, что набрать сообщение невозможно. Раскладка, которая останется включенной после набора сообщения, может быть любой.
Формат входных данных
В первой строке содержатся четыре целых числа n, a, b и c — количество раскладок у клавиатуры, и количество миллисекунд, необходимых для совершения переключения раскладки и набора символа (1 ≤ n ≤ 2 000, 1 ≤ b ≤ a ≤ 109, 1 ≤ c ≤ 109).
В следующих n строках содержится описание раскладок. Каждая раскладка описывается непустой строкой, в которой каждая строчная буква латинского алфавита встречается не более одного раза — подмножество букв, которые можно набрать в этой раскладке. Буквы в этой строке упорядочены в алфавитном порядке.
В последней строке содержится строка s — сообщение, которое хочет набрать Петя (длина строки s от 1 до 2 000). Строка s состоит из строчных латинских букв.
Формат выходных данных
Выведите единственное целое число — минимальное количество миллисекунд, необходимое, чтобы набрать сообщение. Выведите - 1, если набрать сообщение невозможно.
Примеры
Входные данные
5 3 2 1
abc
d
e
f
def
abcdef
Выходные данные
15
Входные данные
1 1 1 1
a
z
Выходные данные
-1
Используем для решения метод динамического программирования. Состояние — d[i][j][k], где i — флаг, обозначающий тип предыдущего действия (0, если это было переключение раскладки, и 1, если это был набор символа), j — номер текущей раскладки, и k — количество набранных символов. Значение — минимальное время, необходимое, чтобы достичь этого состояния.
Переберем k. Для фиксированного k переберем j от 1 до n два раза. Обновим d[0][j % n + 1][k] = min(d[0][j % n + 1][k], min(d[0][j][k] + b, d[1][j][k] + a)). Перебрать j от 1 до n два раза нужно потому, что после набора k-го символа может быть включена раскладка с номером большим, чем раскладка, в которой будет набран следующий символ, и будет необходимо произвести переключение раскладок по циклу до нужной. После этого переберем j еще раз и обновим значения для k + 1. Если в j-й раскладке есть k-й символ сообщения, d[1][j][k + 1] = min(d[0][j][k], d[1][j][k]) + c.
В конце ответ равняется min(d[1][j][m]), где m = length(s), по всем j от 1 до n.
C. Складывание фигуры
Ограничение по времени — 2 секунды
Ограничение по памяти — 256 мегабайт
Пете как всегда стало скучно на уроке математики, поэтому он стал закрашивать в своей тетради клетки. Когда ему это надоело, он заметил, что у него получилась связная клетчатая фигура из k клеток — между любыми двумя закрашенными клетками существует путь по другим закрашенным клеткам, причем соседние клетки в этом пути имеют общую сторону.
Аккуратно вырезав ее из тетради, он сложил ее пополам вдоль линии клетчатой сетки (по горизонтали или по вертикали — он точно не запомнил), а также нарисовал копию сложенной фигуры в тетради. И не зря! Петя потерял фигуру, и все что у него осталось — копия сложенной фигуры, нарисованная в тетради. Теперь он хочет восстановить исходную фигуру.
Восстановить исходную фигуру однозначно не всегда возможно, однако Петя решил, что ему достаточно будет нарисовать хотя бы какую-нибудь фигуру из k клеток, которую можно сложить пополам так, чтобы получилась имеющаяся у него сложенная фигура. Помогите ему — найдите любую исходную связную фигуру из k клеток, удовлетворяющую этому условию.
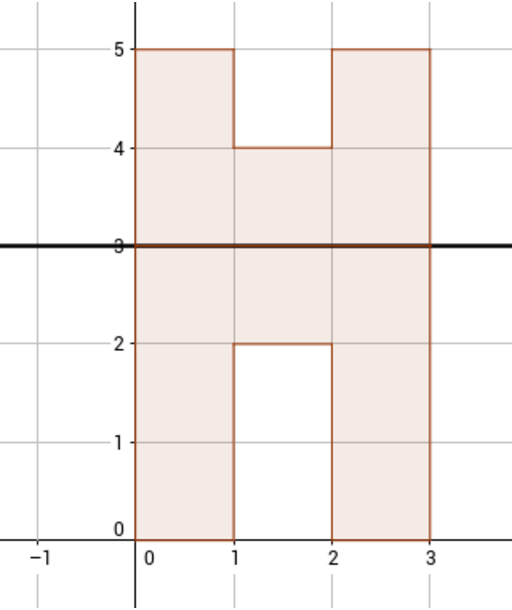
Рассмотрим второй пример теста из условия. В нем сложенная фигура предславляет собой букву «П», а исходная фигура состоит из 12 клеток. Один из возможных вариантов исходной фигуры представлен на рисунке (сгиб происходит по прямой y = 3):
Формат входных данных
Входные данные содержат несколько тестовых наборов. В первой строке задано количество тестов t (1 ≤ t ≤ 200).
Каждый из следующих t тестов описывается следующим образом: в первой строке описания теста содержится два целых числа n, k — количество закрашенных клеток, из которых состоит сложенная фигура Васи и количество клеток в исходной фигуре (1 ≤ n < k ≤ 105).
В каждой из следующих n строк содержатся два числа xi, yi — координатылевого нижнего угла i-й закрашенной клетки ( - 108 ≤ xi, yi ≤ 108). Гарантируется, что все закрашенные клетки различны и образуют связную фигуру.
Гарантируется, что сумма k во всех тестах одних входных данных не превосходит 105.
Формат выходных данных
Для каждого теста выведите ответ на него. Необходимо вывести описание фигуры и способа согнуть ее, чтобы получить фигуру из входного файла.
В первой строке выведите линию сгиба, а в k следующих строках по два целых числа (x'i, y'i) — координаты клеток связной фигуры, которую можно сложить пополам по выведенной линии сгиба, чтобы получить фигуру во входных данных.
Линия сгиба должна быть выведена одним из 4 способов:
- L num — сгиб производится по прямой x = num, левая часть накладывается поверх правой;
- R num — сгиб производится по прямой x = num, правая часть накладывается поверх левой;
- U num — сгиб производится по прямой y = num, верхняя часть накладывается поверх нижней;
- D num — сгиб производится по прямой y = num, нижняя часть накладывается поверх верхней.
Все x'i, y'i, а также координата линии сгиба по модулю не должны превышать 109. Гарантируется, что такая фигура существует. Если существует несколько подходящих ответов, разрешается вывести любой из них.
Примеры
Входные данные
2
7 14
0 0
0 1
0 2
1 2
2 2
2 1
2 0
7 12
0 0
0 1
0 2
1 2
2 2
2 1
2 0
Выходные данные
L 0
0 0
0 1
0 2
1 2
2 0
2 1
2 2
-1 0
-1 1
-1 2
-2 2
-3 2
-3 1
-3 0
U 3
0 0
0 1
0 2
1 2
2 2
2 1
2 0
0 3
1 3
2 3
0 4
2 4
Заметим, что возможных линий сгиба ровно четыре: две по горизонтали и две по вертикали, так как фигура должна полностью лежать с одной из сторон сгиба, а также касаться его.
Возьмём любую из клеток сложенной фигуры с минимальной координатой по оси OX — клетку (xi, yi). За линию сгиба возьмём вертикальную прямую x = xi, касающуюся этой клетки. Теперь слева нужно восстановить k – n клеток первоначальной фигуры, чтобы после накладывания левой части вдоль линии сгиба на правую получилась сложенная фигура из входных данных. Так как k – n ≤ n (иначе после сгиба стало бы больше n клеток), достаточно выделить из сложенной фигуры k – n клеток, образующих связную фигуру, содержащую клетку (xi, yi). Это можно сделать простым обходом в глубину.
D. Остроугольные треугольники
Ограничение по времени — 4 секунды
Ограничение по памяти — 256 мегабайт
Совсем недавно московский десятиклассник Дмитрий Захаров обогнал всех в построении множества точек в d-мерном пространстве, таких что все треугольники с вершинами в этих точках остроугольные.
Таня решила померяться силами с Дмитрием. Разумеется, она планирует использовать компьютер. Для начала она хочет решить следующую задачу. Дано n точек на плоскости, требуется найти количество остроугольных треугольников с вершинами в этих точках. Треугольник называется остроугольным, если все его углы строго меньше 90 градусов.
Формат входных данных
Входные данные содержат несколько тестовых наборов. В первой строке задано количество тестов t (1 ≤ t ≤ 666).
Каждый из тестов описывается следующим образом: в первой строке описания теста содержатся число n (3 ≤ n ≤ 2000) — количество точек.
В следующих n строках содержатся по два числа xi, yi ( - 109 ≤ x, y ≤ 109) — координаты точек. Гарантируется, что все точки в одном тесте различные.
Суммарное количество точек по всем тестам одних входных данных не превосходит 2000.
Формат выходных данных
Для каждого теста в отдельной строке выведите ответ на него — количество остроугольных треугольников с вершинами в заданных точках.
Примеры
Входные данные
2
5
1 1
2 2
3 3
4 1
6 4
5
0 0
3 1
5 1
5 -1
1 3
Выходные данные
3
4
Для подсчёта остроугольных треугольников достаточно из общего количества треугольников вычесть количество прямоугольных и тупоугольных треугольников. Будем считать три точки на одной прямой вырожденным тупоугольным треугольником.
Общее количество треугольников, которые можно построить с вершинами в заданных точках, равно Cn3.
Заметим: количество прямоугольных и тупоугольных треугольников равно количеству прямых и тупых углов с вершинами в заданных точках.
Осталось посчитать количество углов не меньше 90 градусов с вершинами в заданных точках. Переберём угловую точку и отсортируем по углу относительно данной все остальные точки. Воспользуемся методом двух указателей. Переберём вторую точку, которая будет образовывать угол. Для подсчета количества подходящих третьих точек достаточно заметить, что все точки, которые образуют угол не меньше 90 градусов с двумя другими точками, лежат на отрезке в отсортированном порядке и что отрезок сдвигается только в сторону увеличения угла.
Время работы решения: O(n2log(n)).
E. Объединение массивов
Ограничение по времени — 4 секунды
Ограничение по памяти — 256 мегабайт
Рассмотрим два массива натуральных чисел A = [a1, a2, ..., an] и B = [b1, b2, ..., bm]. Будем называть их k-объединением лексикографически минимальный массив чисел R длиной k, который разбивается на две непустые подпоследовательности, первая из которых является подпоследовательностью массива A, а вторая — подпоследовательностью массива B.
Формально говоря, необходимо найти лексикографически минимальный массив R = [r1, r2, ..., rk], для которого существуют непустые наборы индексов 1 ≤ i1, 1 < i1, 2 < ... < i1, t ≤ n и 1 < j1, 1 < j1, 2 < ... < j1, k - t ≤ m в исходных массивах, а также наборы индексов 1 ≤ i2, 1 < i2, 2 < ... < i2, t ≤ k и 1 ≤ j2, 1 < j2, 1 < ... < j2, k - t ≤ k, такие что:
- Для любых 1 ≤ p ≤ t, 1 ≤ q ≤ k - t выполнено i2, p ≠ j2, q;
- Для любого 1 ≤ p ≤ t выполнено ai1, p = ri1, p;
- Для любого 1 ≤ p ≤ k - t выполнено bj1, p = rj1, p.
Например, если A = [1, 2, 1, 3, 1, 2, 1], B = [1, 2, 3, 1], а k = 9, то их k-объеднением будет R = [1, 1, 1, 1, 2, 1, 2, 3, 1] (подпоследовательность из первого массива — [1, 1, 1, 2, 1], подпоследовательность из второго массива — [1, 2, 3, 1]).
По двум данным массивам A и B, а также числу k найдите их k-объединение R.
Формат входных данных
В первой строке ввода содержится число n — размер массива A (1 ≤ n ≤ 3000).
Во второй строке содержится n чисел ai — массив A (1 ≤ ai ≤ 3000).
В третьей строке содержится число m — размер массива B (1 ≤ m ≤ 3000).
Во четвертой строке содержится m чисел bi — массив B (1 ≤ bi ≤ 3000).
В последней строке содержится число k (2 ≤ k ≤ n + m).
Формат выходных данных
Выведите k-объединение заданных во входном файле массивов.
Примеры
Входные данные
7
1 2 1 3 1 2 1
4
1 2 3 1
9
Выходные данные
1 1 1 1 2 1 2 3 1
Приведём два решения этой задачи: за O(k2•log(k)) и O(k2).
Решение за O(k2•log(k))
Разобьём решение задачи на три пункта:
- Для каждого массива X (A или B) и каждой длины 1 ≤ length ≤ |X| найдём minSubsequenceX[length] — лексикографически минимальную подпоследовательность X длины length.
- Переберём длину подпоследовательности в первом массиве — 1 ≤ t ≤ min(k – 1, |A|). Если 1 ≤ k – t ≤ |B|, возьмём minSubsequenceA[t] и minSubsequenceB[k – t], их надо объединить.
- Объединим две подпоследовательности в одну, получив тем самым лексикографически минимальную подпоследовательность длины k, обновим ответ.
Чтобы найти minSubsequenceX[length] для каждого length, сделаем вот что:
- Посчитаем next[i][c], в котором будет храниться следующее после i вхождение символа c в X.
- Посчитаем firstSymbol[length][i] — первый символ лексикографически минимальной подпоследовательности массива X[i..|X| – 1] длиной length. Для этого заметим следующее:
- Если j1 = next[i][1] существует, то firstSymbol[1][i], firstSymbol[2][i],… firstSymbol[|X| – j1][i] начинаются с 1;
- Если j2 = next[i][2] существует, то firstSymbol[|X| – j1 + 1][i], ..., firstSymbol[|X| – j2][i] начинаются с 2;
- ...
- Если j|alphabet| = next[i][|alphabet| существует, то firstSymbol[max(|X| – j1, |X| – j2, ..., |X| – j|alphabet| - 1) + 1][i], ..., firstSymbol[|X| – j|alphabet|][i] начинаются с |alphabet|.
где alphabet — максимальное возможное число в массиве X.
- Посчитав firstSymbol[length][i], можно восстановить лексикографически минимальную подпоследовательность X для каждой длины итеративно по одной букве.
Этот пункт работает за O(|X|2).
Найдя две лексикографически минимальные подпоследовательности SA и SB, их надо объединить в одну лексикографически минимальную длиной k. Будем двигаться по подпоследовательностям двумя указателями p1 и p2. Если SAp1 ≠ SBp2, то двигаем указатель, стоящий на меньшем числе. Если SAp1 = SBp2, двоичным поиском найдём наибольший общий префикс SA[p1..|SA|] и SB[p2..|SB|] и сравним следующие числа. Для сравнения подотрезков SA и SB можно использовать хеши.
Этот пункт работает за O((|SA| + |SB|)•log(max(|SA|, |SB|))) = O(k•log(k)).
Итого, суммируя все три пункта, получаем асимптотику O(|A|2 + |B|2 + k2•log(k)) = O(k2•log(k)).
Решение за O(k2)
Назовём массив A нулевым, а массив B — первым. Будем строить ответ по одному элементу. Также станем поддерживать вспомогательное значение dp[i][j], где i — номер массива (0 или 1), а j — индекс в этом массиве. dp[i][j] равно минимальному индексу в массиве 1 – i, с которого можно продолжать строить ответ, если в массиве i мы остановимся на индексе j.
На t-й из k итераций построения ответа будем находить минимальный элемент, такой, что, добавив его в ответ, последовательность можно закончить, т. е. что оставшихся элементов хотя бы k – t – 1. Также нужно учесть, что обе подпоследовательности обоих массивов, из которых строится ответ, должны быть непустые.
После добавления найденного элемента v в ответ за O(|A| + |B|) обновим значения dp. Для этого будем пользоваться посчитанным в предыдущем решении массивом next.
F. Два поддерева
Ограничение по времени — 4 секунды
Ограничение по памяти — 256 мегабайт
Рассмотрим подвешенное дерево. Рассмотрим вершину v, имеющую в поддереве хотя бы одну вершину на расстоянии k от v. Будем называть k-поддеревом вершины v дерево, полученное из поддерева вершины v удалением всех вершин, расстояние от которых до v больше k. Например, на иллюстрации ниже красным отмечено 2-поддерево вершины 3.

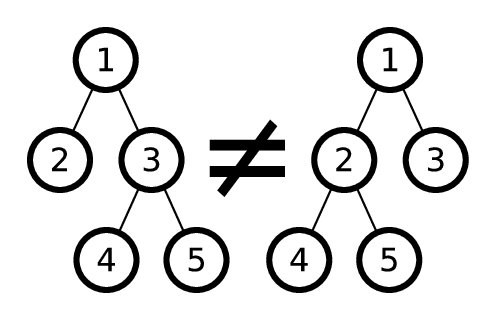
Будем называть два дерева одинаковыми, если можно перенумеровать вершины первого так, чтобы получить второе, при этом менять порядок детей у вершин не разрешается. Например, следующие два дерева не являются одинаковыми:
Дано подвешенное дерево. Требуется определить наибольшее k такое, что у него есть два одинаковых k-поддерева, корни которых различны. Эти поддеревья могут пересекаться.
На рисунке приведены деревья из примеров.
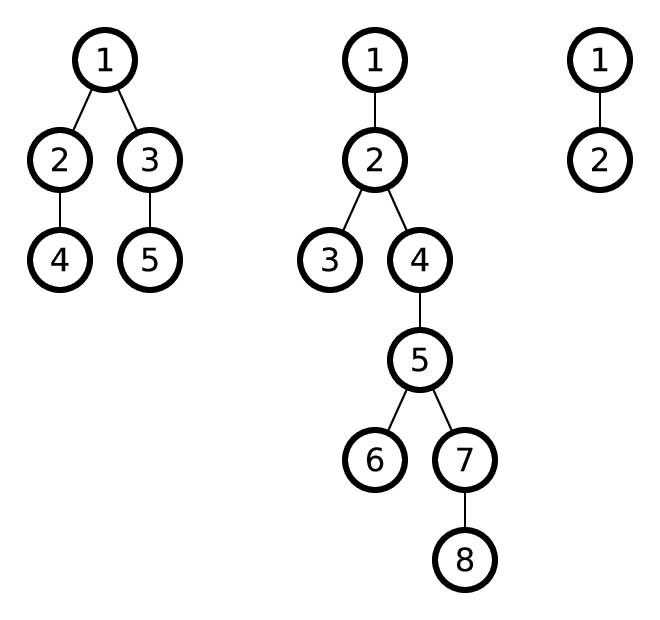
В первом примере корни одинаковых 1-поддеревьев — это вершины 2 и 3.
Во втором примере корни одинаковых 3-поддеревьев — это вершины 1 и 4.
В третьем примере корни одинаковых 0-поддеревьев — это вершины 1 и 2.
Формат входных данных
В первой строке задано число t — количество тестов (1 ≤ t ≤ 104).
Каждый из t тестов описывается следующим образом: в первой строке задано число n — количество вершин (2 ≤ n ≤ 105).
Далее следует n строк. В i-й из них задано число cnti — количество детей вершины i, а далее следуют cnti чисел — номера детей вершины i. Вершины нумеруются с единицы. Корнем дерева является вершина 1. Гарантируется, что заданный граф является деревом с корнем в 1.
Сумма n по всем тестам в одних входных данных не превосходит 2·105.
Формат выходных данных
Для каждого теста выведите на отдельной строке максимальное k такое, что существует два одинаковых k-поддерева с разными корнями.
Примеры
Входные данные
3
5
2 2 3
1 4
1 5
0
0
8
1 2
2 3 4
0
1 5
2 6 7
0
1 8
0
2
1 2
0
Выходные данные
1
3
0
По условию в k-поддереве обязательно есть вершины на глубине k. Временно отменим это требование.
Рассмотрим все k-поддеревья для некоторого k. Их можно разбить на классы эквивалентности. Каждой вершине поставим в соответствие ck[v] — метку класса эквивалентности, которому принадлежит её k-поддерево.
При k = 0 все c0[v] равны, так как 0-поддерево любой вершины — это она сама.
При k = 1 c1[v] равно количеству детей вершины.
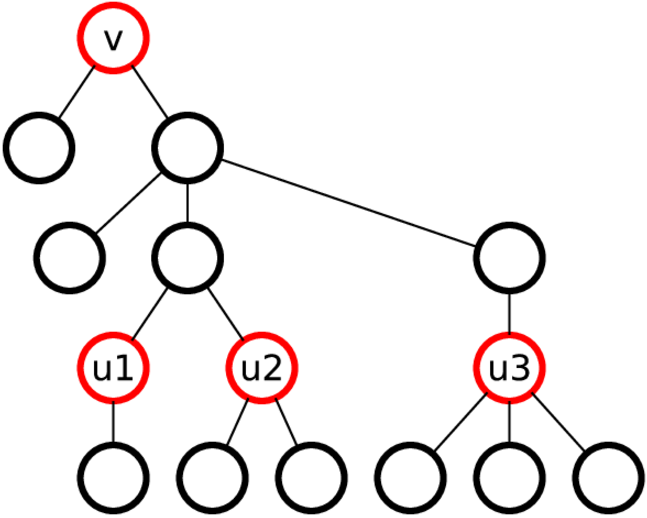
Научимся по массивам ck[v] и cm[v] строить массив ck + m[v]. Для начала поставим в соответствие каждой вершине v массив arrk + m[v], который будет однозначно задавать класс эквивалентности её k + m — поддерева. Пусть u1, ..., us — потомки вершины v на расстоянии k в порядке обхода dfs. Тогда поставим в соответствие вершине v массив arrk + m[v] = ck[v], cm[u1], ..., cm[us]. То есть k + m — поддерево вершины задаётся k-поддеревом вершины и m-поддеревьями нижней части k-поддерева. Ниже приведена иллюстрация для k = 3 и m = 1.
Чтобы получить для каждой вершины список её потомков на расстоянии k, запустим поиск в глубину от корня. Будем поддерживать в стеке путь до корня и каждую вершину класть в массив для её предка на расстоянии k.
Чтобы преобразовать массивы arrk + m[v] в числа ck + m[v], можно захешировать их, использовать бор или unordered_map из массива в номер. Время работы будет O(n), поскольку каждая вершина встречается в списках arr только один раз.
Имея массив ck[v], можно легко проверить, что существует два одинаковых k-поддерева. Для этого найдём две вершины с одинаковым ck, при этом нужно рассматривать только вершины, у которых есть потомки на расстоянии k от неё (это то требование, которое мы отменили в начале).
Чтобы найти максимальное k, посчитаем c1[v], c2[v], ..., c2t[v] (2t — максимальная степень двойки, не превосходящая n). После этого используем аналог двоичных подъёмов по k: начнём с k = 0 и по очереди попытаемся прибавить к нему 2t, 2t – 1, ..., 20.
Время работы решения: O(nlog(n)).
Планы на будущее
Не забывайте, что в сентябре пройдёт финальный раунд. После него мы также выложим условия задач и их разбор. Вы сможете почувствовать себя в шкуре финалистов и решить хардкорные задачи.
А напоследок делимся с вами одной из идей: возможно, в следующем году мы сделаем специальные номинации вроде «Лучший в языке». Тогда, например, обладатель лучшего решения на С++ получит отдельный приз. Что скажете?
