

После нескольких лет работы с Git я обнаружил, что постепенно стал переходить на всё более сложные Git-команды в рабочем процессе. Вскоре после того как я открыл для себя Git rebase, я тоже быстро внедрил эту команду в повседневные задачи. Те, кто знаком с этой процедурой, знают, насколько это мощный инструмент и какой это соблазн — постоянно им пользоваться. Но вскоре оказалось, что rebase влечёт за собой ряд неочевидных на первый взгляд трудностей. Но прежде чем обсудить их, хочу быстро рассмотреть различия между merge и rebase.
Возьмём простой пример с интегрированием ветки feature в ветку master. При слиянии мы создаём новый коммит g, который представляет слияние между двумя ветками. График коммита ясно показывает, что произошло, и хорошо видны контуры графика «железнодорожных путей», знакомого нам по более крупным Git-репозиториям.
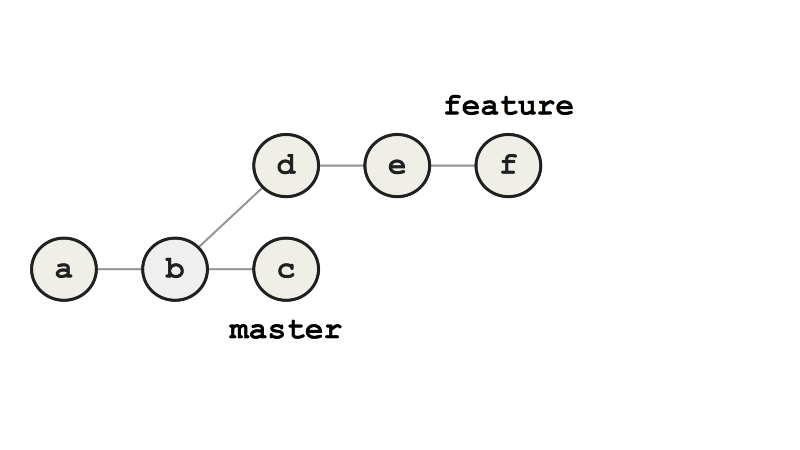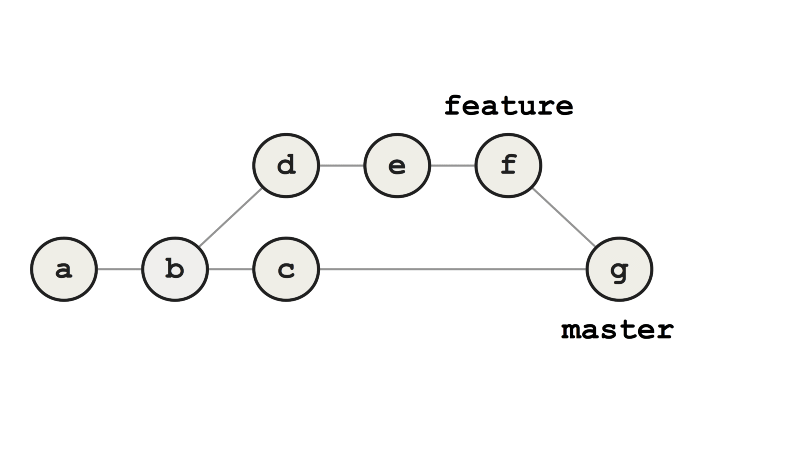
Пример слияния
Также перед слиянием можно выполнить rebase. Коммиты будут убраны, а ветка feature — сброшена в master, после чего все коммиты будут снова применены поверх feature. Диффы этих переприменённых коммитов обычно идентичны оригинальным, но у них будут другие родительские коммиты, а значит, и другие ключи SHA-1.
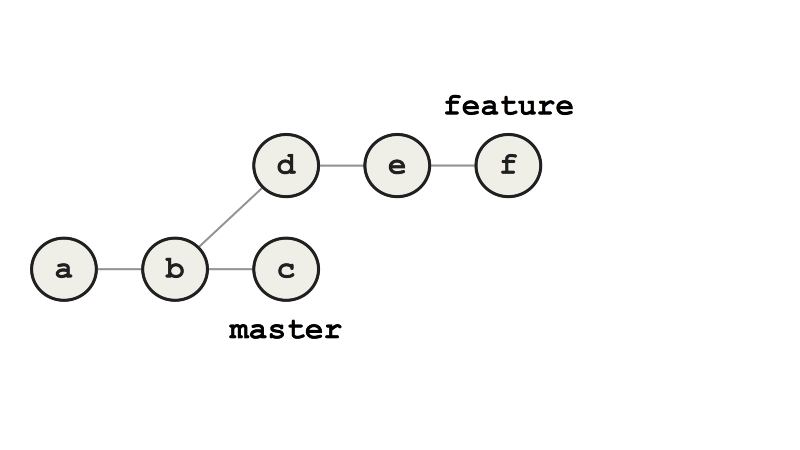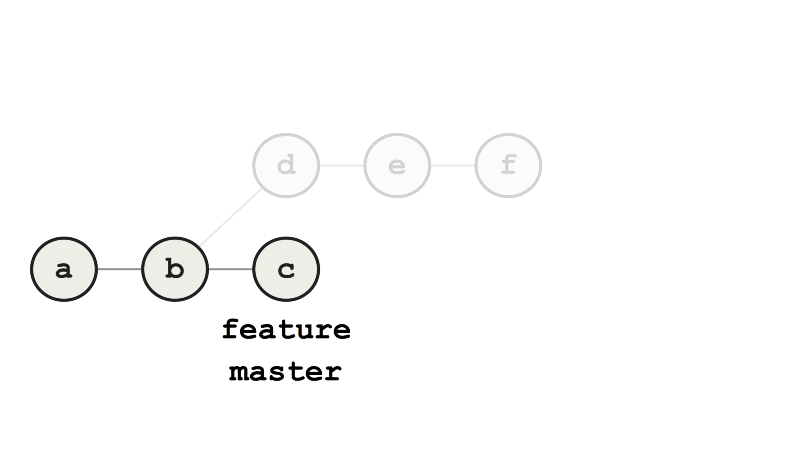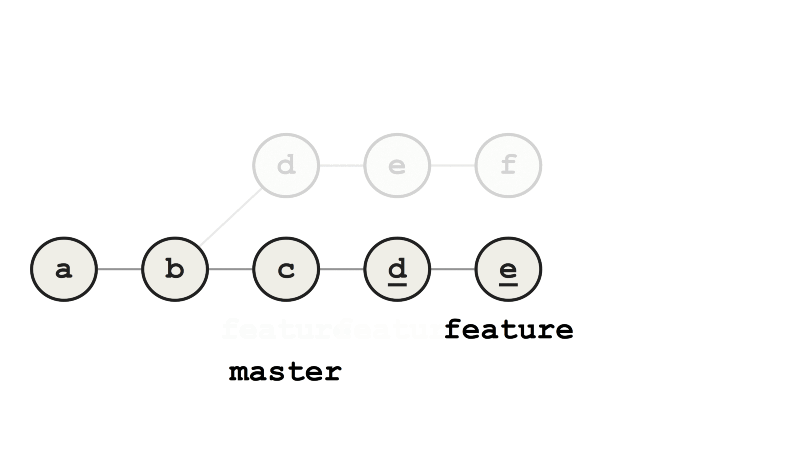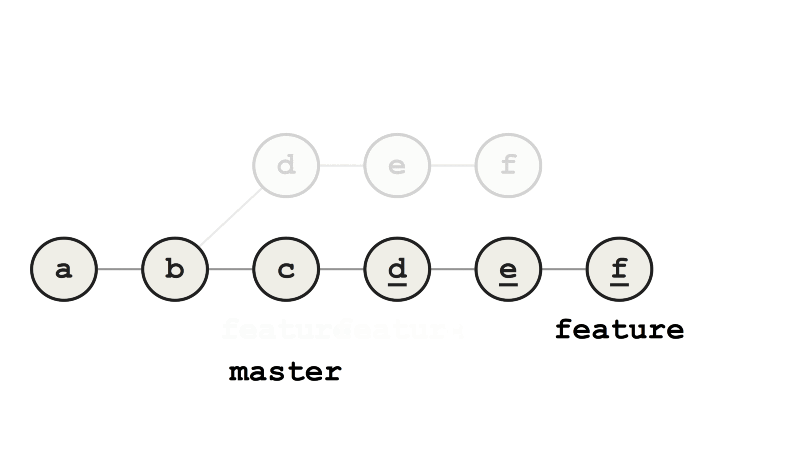
Пример rebase
Теперь мы изменили базовый коммит feature с b на c, то есть перебазировали. Слияние feature с master теперь выполняется ускоренно (fast-forward merge), потому что все коммиты feature — это прямые потомки master.
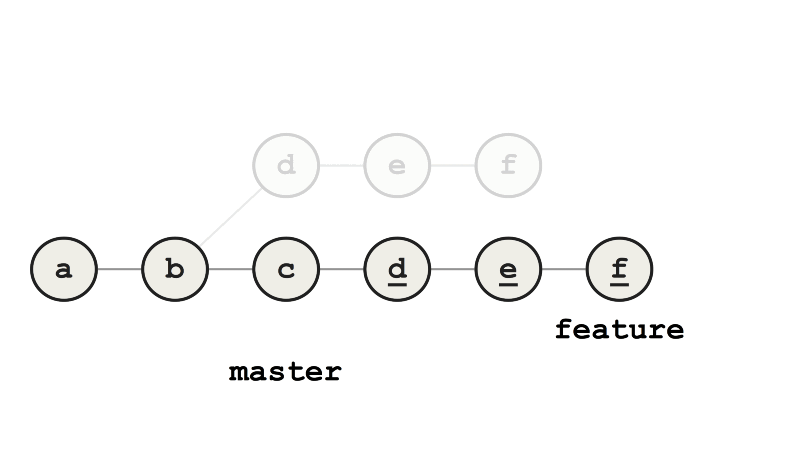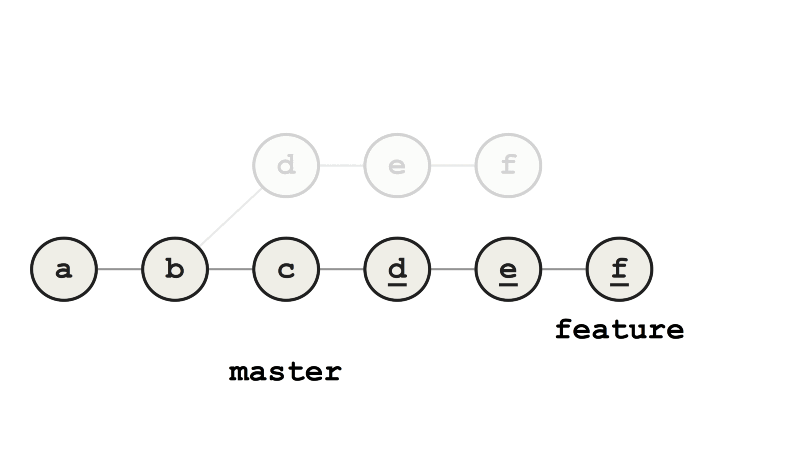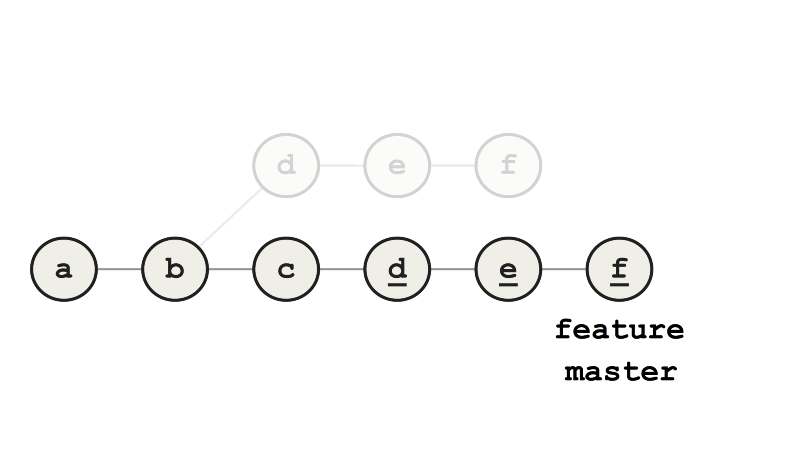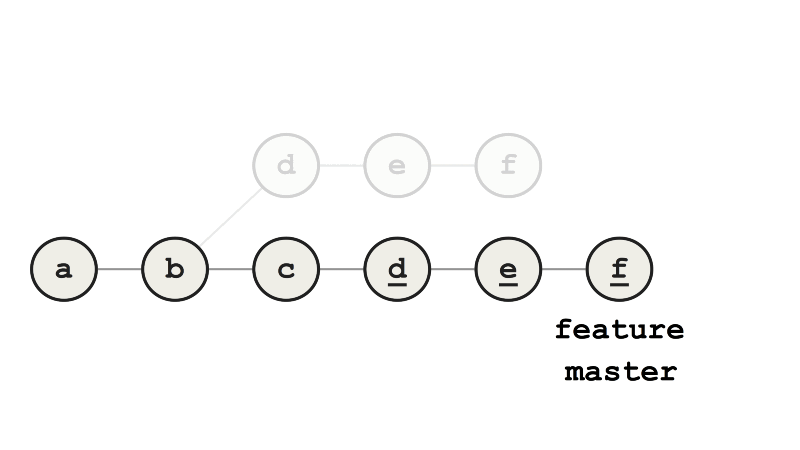
Пример ускоренного слияния
По сравнению с обычным слиянием мы получаем линейную историю изменений без ответвлений. Я предпочитал использовать rebase перед слиянием из-за улучшения читабельности и думал, что другие руководствуются той же причиной.
Но, как я упоминал, этот подход влечёт за собой ряд неочевидных сложностей.
Допустим, мы удалили из master зависимость, которая всё ещё используется в feature. Когда feature перебазируется в master, первый переприменённый коммит сломает вашу сборку, но если не будет конфликтов слияния, то процесс rebase продолжится. Ошибка из первого коммита останется во всех последующих, положив начало цепочке битых коммитов.
Эта ошибка проявится только после завершения процесса rebase, и обычно она исправляется с помощью нового bugfix-коммита g, применённого сверху.

Пример неудачного rebase
Но если при rebase возникают конфликты, Git поставит конфликтный коммит на паузу, позволив вам исправить проблему перед продолжением. Решение конфликтов посреди rebase длинной цепочки коммитов часто превращается в непростую задачу: с ней трудно справиться, не наделав новых ошибок.
Новые ошибки во время rebase — это очень большая проблема. Они возникают, когда вы переписываете историю, и могут скрыть от вас подлинные баги, которые были при первом переписывании истории. В частности, это усложнит использование Git bisect, одного из самых мощных инструментов отладки в инструментарии Git. Посмотрите на эту ветку фичи. Допустим, ближе к концу у нас появился баг.
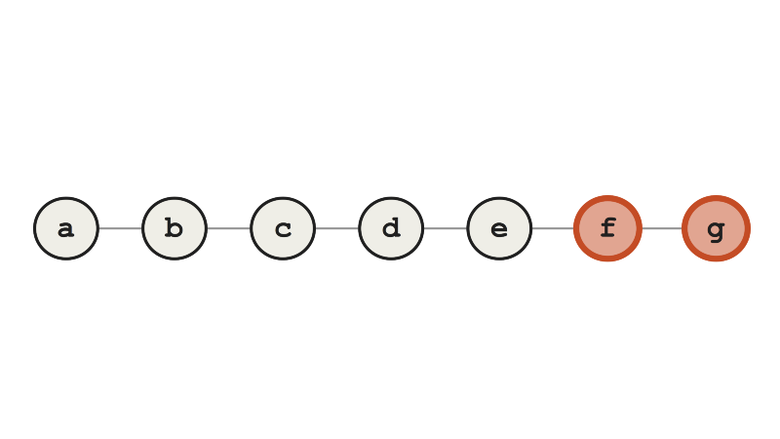
Ветка с багом ближе к концу
Вы можете не знать о баге в течение недель после слияния ветки с master. Для обнаружения коммита, с которым был внесён этот баг, вам придётся перелопатить десятки или сотни коммитов. Процесс автоматизируется, если написать скрипт для тестирования на наличие бага и автоматически запускать его во время Git bisect с помощью команды git bisect run <yourtest.sh>.
Bisect выполнит дихотомический поиск по истории, выявив коммит, в котором появился баг. На иллюстрации показано успешное обнаружение первого сбойного коммита, поскольку все сломанные коммиты содержат наш баг.
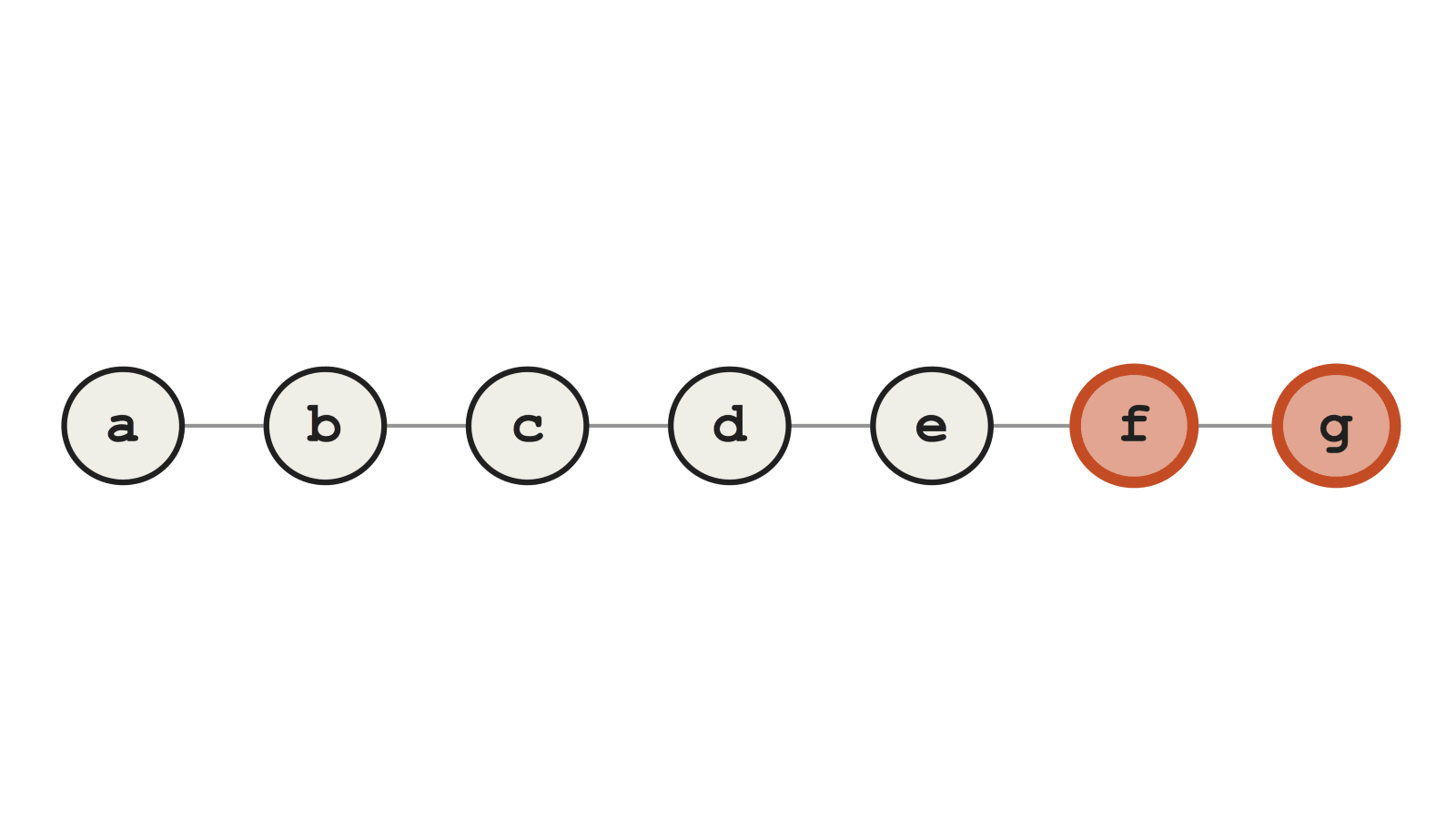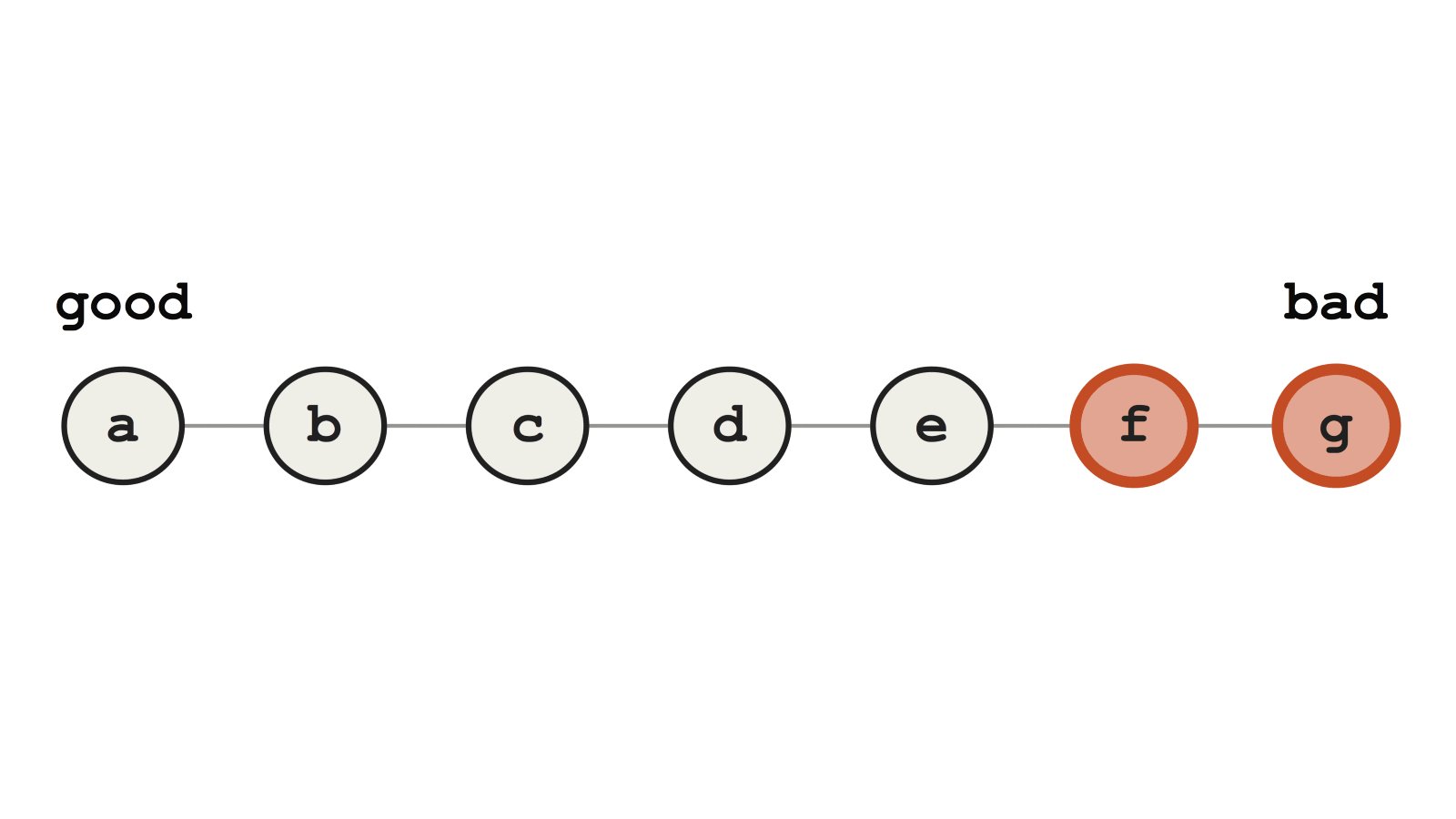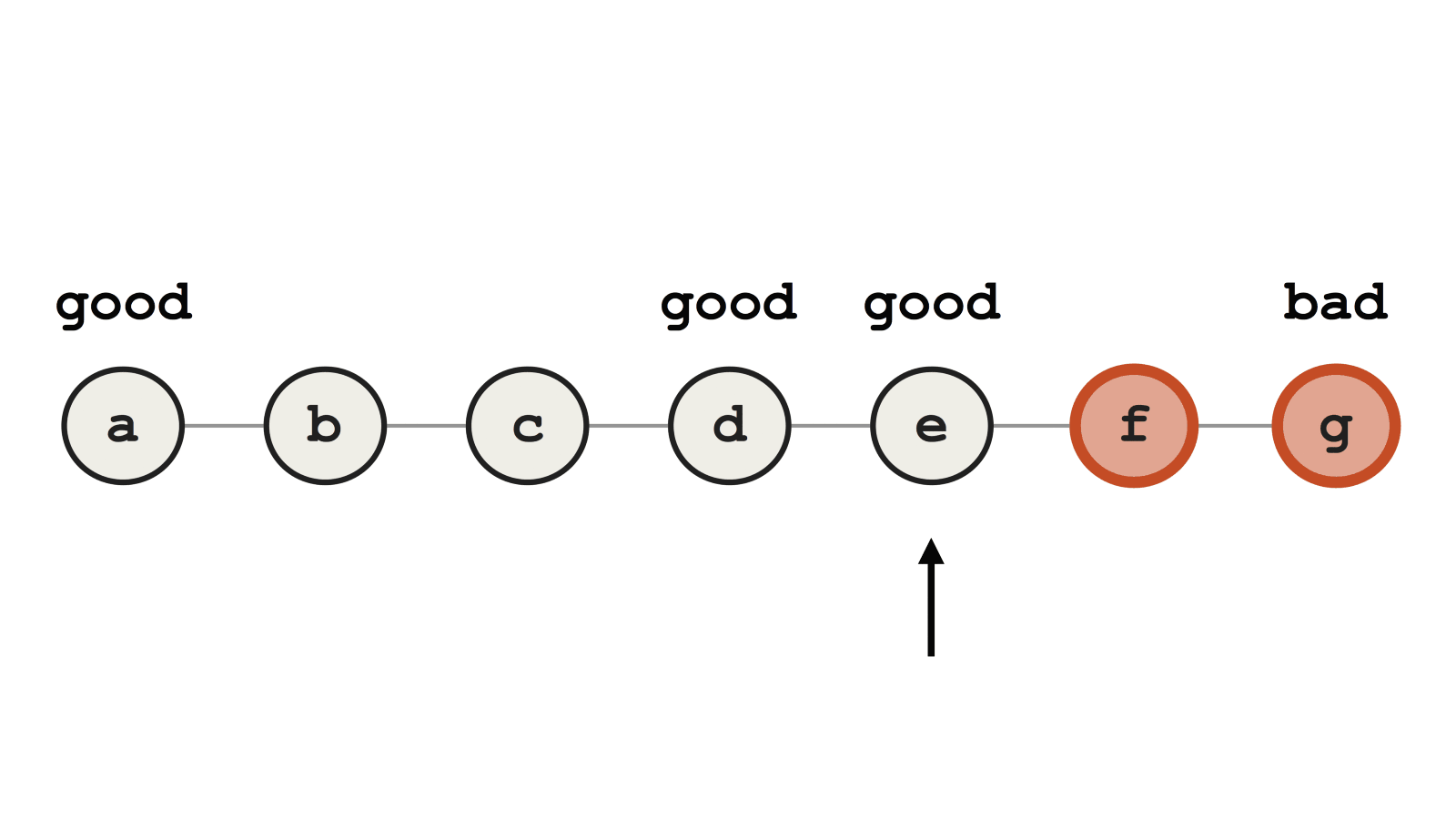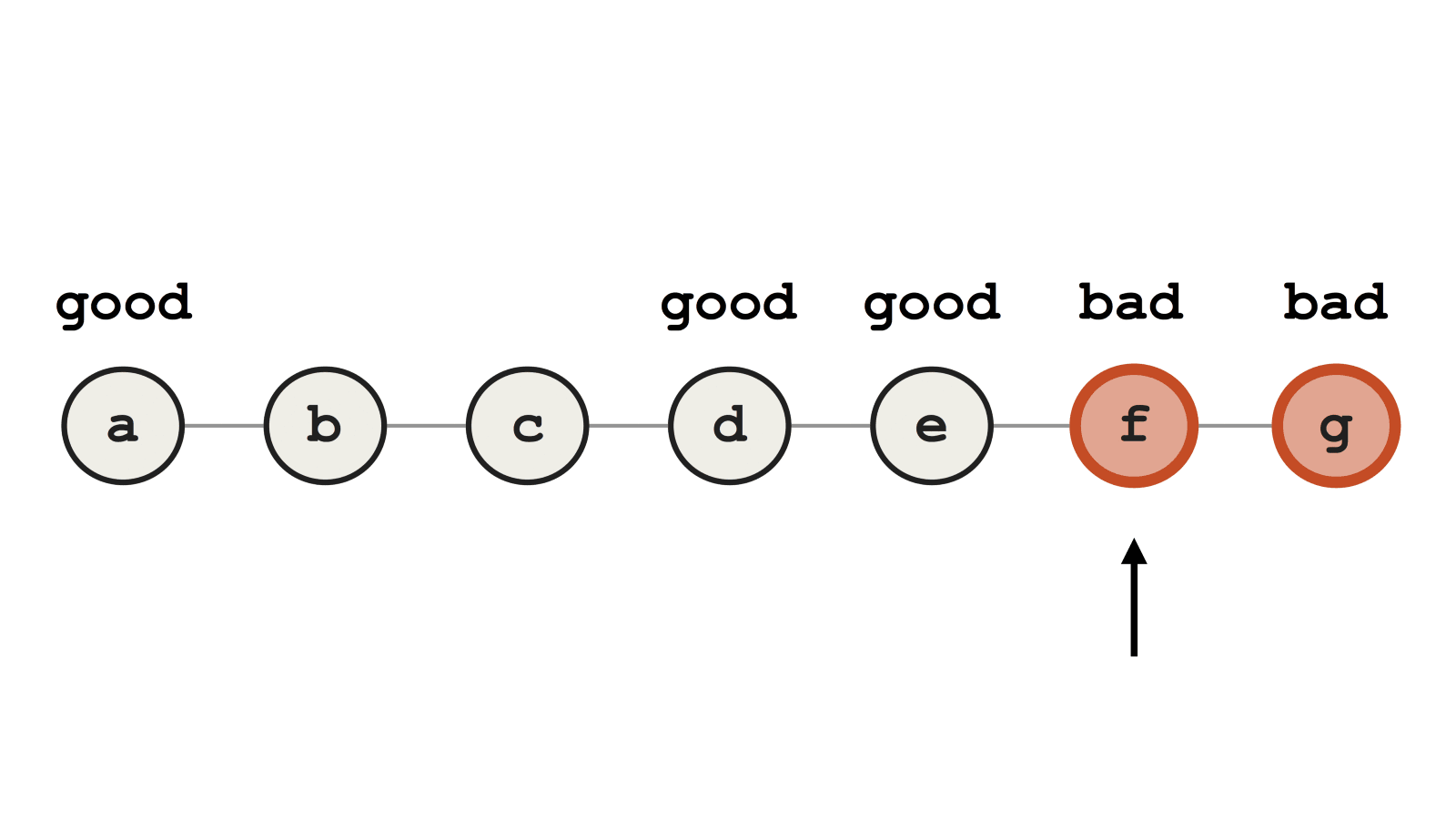
Пример успешного выполнения Git bisect
С другой стороны, если мы при rebase внесли другие битые коммиты (в нашем примере это d и e), то у bisect будут трудности. Можно понадеяться, что Git идентифицирует коммит f как сбойный, но вместо этого он ошибочно выбирает d, потому что тот содержит какие-то другие ошибки, ломающие тест.
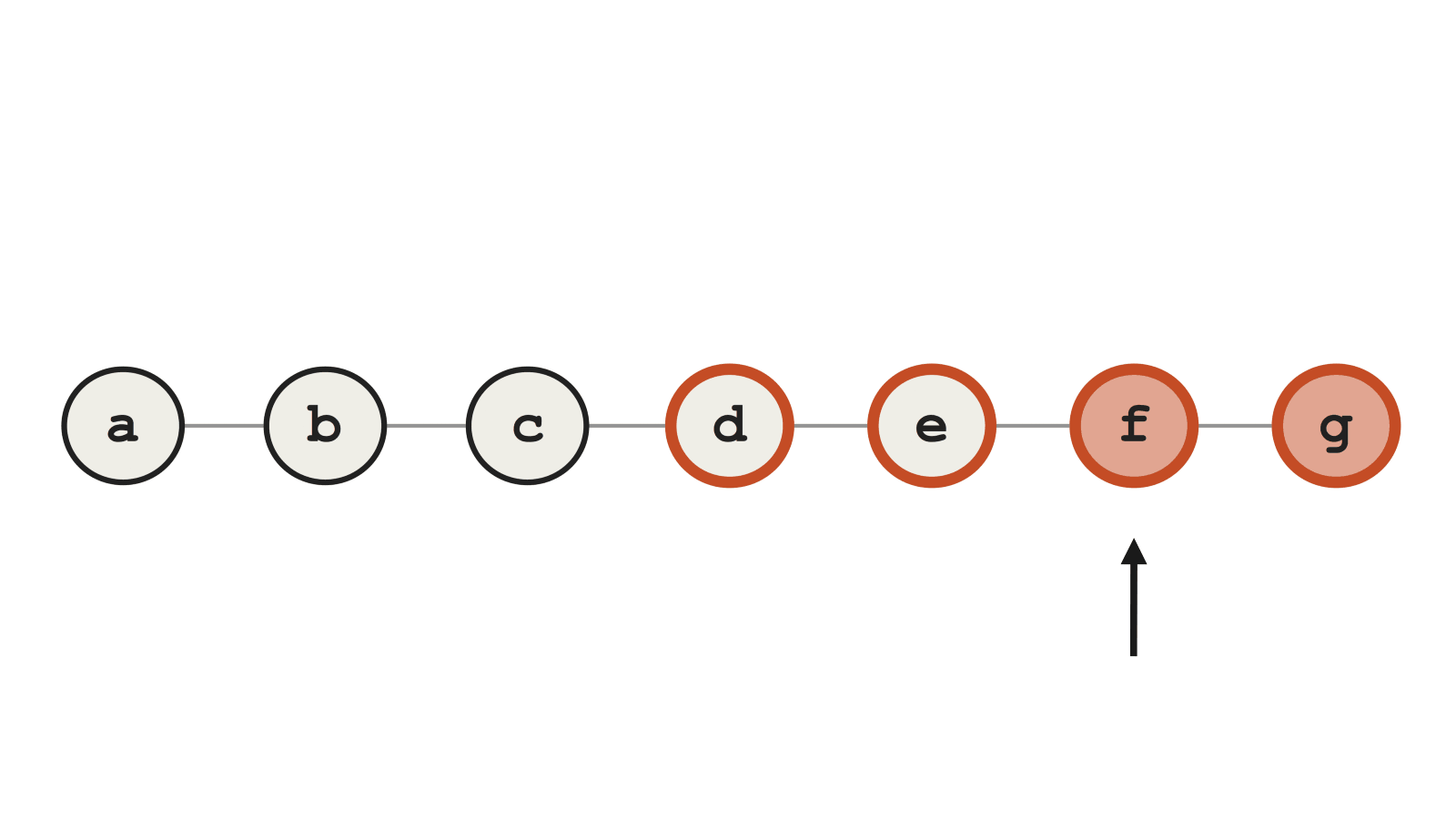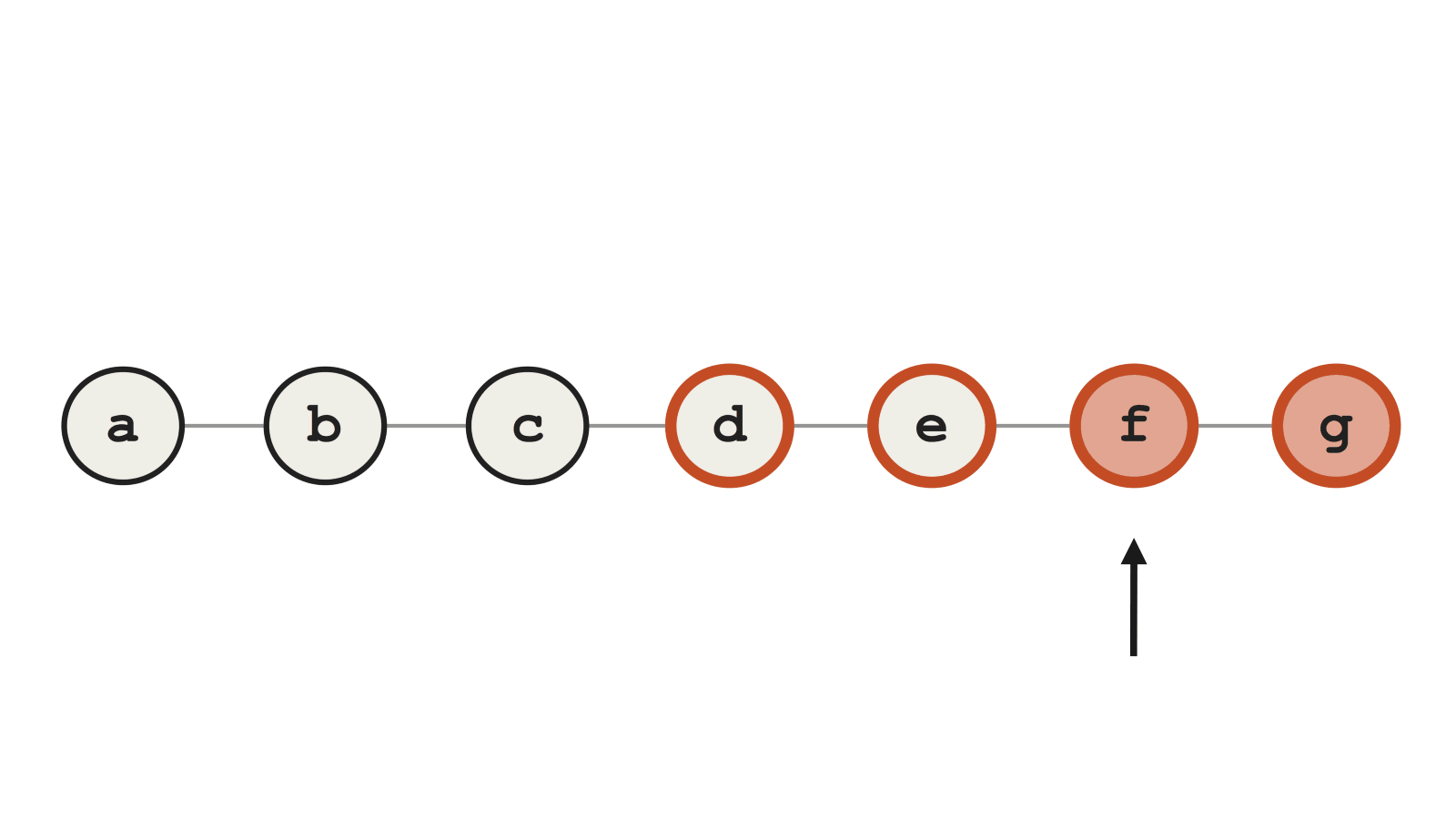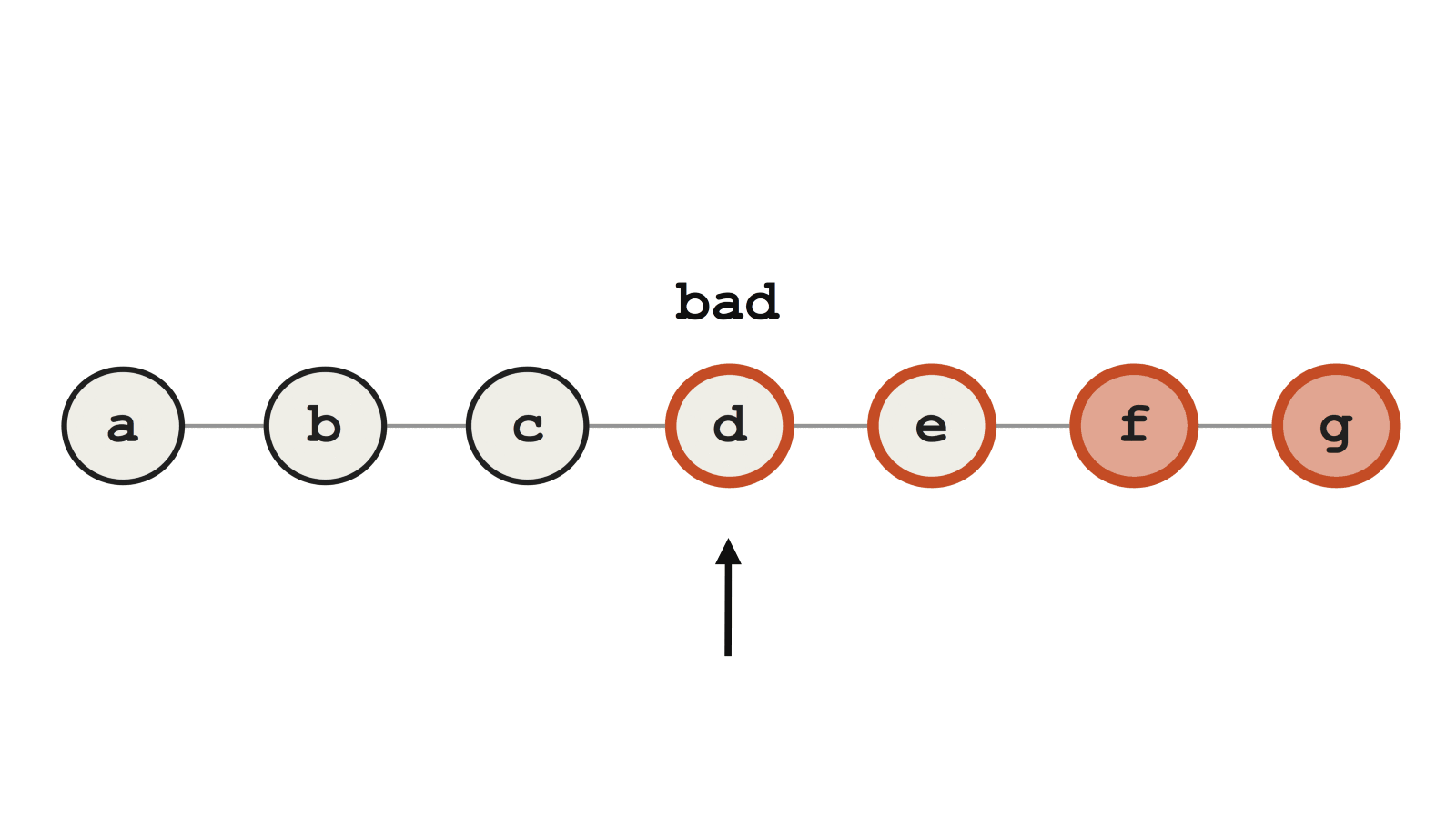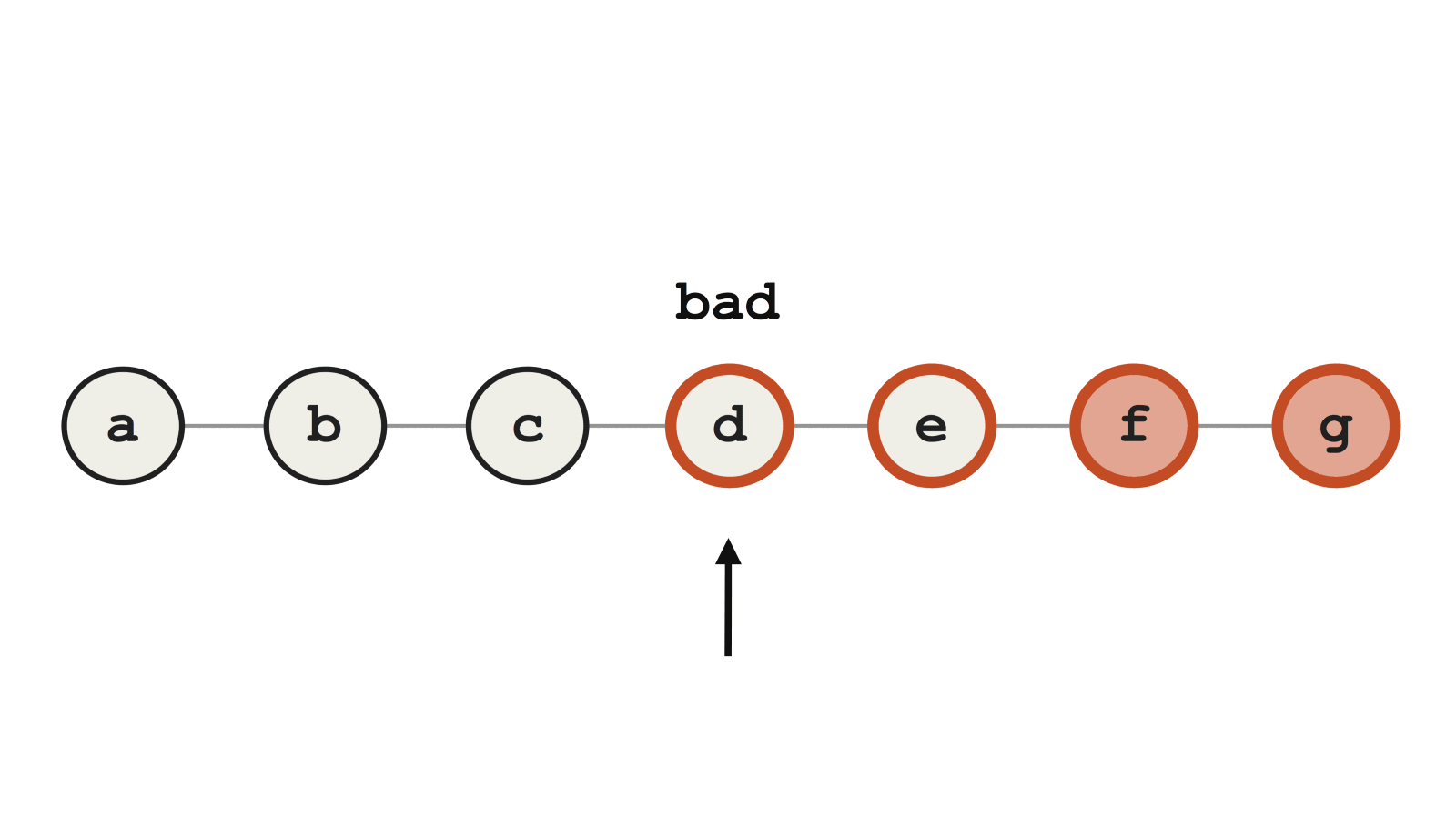
Пример сбойного Git bisect
Эта проблема гораздо важнее, чем может показаться.
Почему мы вообще используем Git? Потому что это наш самый важный инструмент для отслеживания источника багов в коде. Он наша страховочная сеть. При rebase мы снижаем важность этой роли Git ради желания получить линейную историю коммитов.
Некоторое время назад я применял bisect к нескольким сотням коммитов, чтобы найти баг в системе. Битый коммит находился в середине длинной цепочки коммитов. Она не компилировалась из-за сбойного rebase, выполненного моим коллегой. Этой ошибки можно было легко избежать, и я потратил почти день на её поиск.
Как нам избежать этих цепочек битых коммитов при rebase? Например, позволить процессу завершиться, протестировать код на баги и вернуться к истории для исправления ошибок. Для этого мы могли бы использовать интерактивный rebase.
Другой подход: вынудить Git становиться на паузу на каждом этапе процесса rebase, тестировать и немедленно исправлять баги, прежде чем продолжать дальше. Это неудобный вариант, чреватый внесением новых ошибок, так что прибегать к нему стоит лишь тогда, когда вам нужна линейная история. Есть более простой и надёжный способ?
Есть — Git merge. Простой процесс в один этап, при котором все конфликты разрешаются в единственном коммите. Получившийся коммит ясно обозначает точку интегрирования двух веток, а наша история отразит не только что произошло, но и когда.
Не нужно недооценивать важность сохранения достоверности истории. Rebase — это обман самого себя и своей команды. Вы притворяетесь, что коммиты были написаны сегодня, хотя по факту они написаны вчера на основе другого коммита. Вы вытащили коммиты из исходного контекста, завуалировав то, что произошло в действительности. Вы уверены, что код соберётся? Вы уверены, что сообщения коммитов всё ещё имеют смысл? Вы можете верить в то, что чистите и проясняете историю, но в результате добьётесь прямо противоположного.
Нельзя предсказать, какие ошибки и трудности появятся в вашей кодовой базе в будущем. Но будьте уверены — достоверная история полезнее переписанной (или фальшивой).
Что заставляет людей переносить ветки?
Думаю, тщеславие. Rebase — чисто эстетическая операция. Чистенькая история приятна нам как разработчикам, но это не может быть оправдано ни с технической точки зрения, ни с точки зрения функциональности.

Пример нелинейной истории
Графики нелинейной истории, «железнодорожные пути», могут выглядеть пугающе. Но нет никаких причин бояться их. По сути, это инструменты на основе GUI и CLI, позволяющие анализировать и визуализировать сложную Git-историю. Эти графики содержат ценную информацию о том, что и когда происходило, и мы ничего не получаем от превращения их в линейные.
Git создан для сохранения нелинейной истории, он это поощряет. Если вас это смущает, то лучше используйте более простой VCS, поддерживающий только линейную историю.
Я считаю, что лучше сохранять достоверность истории. Освойтесь с инструментами для её анализа и не поддавайтесь искушению переписать. Выгода минимальная, а риски велики. Вы скажете мне за это спасибо, когда в следующий раз будете ворошить историю в поисках таинственного бага.
