Анализ отзывов пользователей ресторанов был частью задачи тестирования SentiRuEval-2015, прошедшего в рамках конференции Диалог-2015. В этой статье поговорим о том, что собственно делают такие анализаторы, зачем это нужно на практике, и как создать такое средство своими руками с помощью Meanotek NeuText API
Анализ отзывов по аспектам часто разделяют на несколько этапов. Рассмотрим например предложение «японские блюда были вкусными, но официант работал медленно». На первом этапе мы выделяем из него важные для нас слова или словосочетания. В данном случае это «японские блюда», «вкусными», «официант», «медленно». Это позволяет понять, о чем идет речь в предложении. Далее мы можем захотеть сгруппировать термины — например отнести «блюда» и «вкусными» к еде, а «официант» к обслуживанию. Такая группировка позволит выдавать агрегированную статистику. Наконец, мы можем захотеть оценить тональность терминов, говорится о них что-то положительное или отрицательное
Зачем: Ответить на этот вопрос сейчас не так-то просто. В предположении организаторов тестирования задачей является в итоге оценить тональность отзыва в целом, т. е. сказать, что автор этого отзыва считает обслуживание хорошим, а интерьер плохим. Но эта задача сегодня решается другими методами — на большинстве сайтов-отзовиков предусмотрено, что когда пользователь оставляет отзыв, он также заполняет вручную оценки по аспектам. Доступность такой информации резко снижает ценность подобного синтетического анализа. Хотя можно, конечно, выделять дополнительные аспекты, анализировать посты с форумов, но все это имеет для пользователя вторичное значение.
Но, допустим, нам нужно решить обратную задачу. Например, вы владелец ресторана, и вам интересно, почему в разделе «интерьер» указана плохая оценка. А связь с исходным текстом на сайтах с ручной оценкой по большей части утеряна. Придется просмотреть все отзывы с негативной оценкой целиком, чтобы найти нужные сведения. А отзывы эти бывают, прямо скажем, довольно длинные и содержащие много «воды», вроде «вчера у моей подруги было день рожденья. Мы собрались и долго думали куда пойти. Обычно мы...» ну и так далее. Выделив важные аспектные термины, можно подсветить их в тексте, или показать только содержащие их предложения, или даже, подсчитать их и вывести такую сводку:
Громкая музыка — 34
Накурено — 8
Кондиционер — 4
Грязно в туалете — 2
Сократив трудозатраты на анализ мы повысим эффективность бизнеса, плюс ресторан будет иметь возможность реагировать на различные проблемы и запросы посетителей. Хотя конечно, не все владельцы ресторанов предметно занимаются таким тщательным мониторингом отзывов, но это уже другой вопрос.
Реализация: Для реализации с помощью Meanotek NeuText API вам будет нужен бесплатный API ключ, если у вас еще нет его, то можно получить здесь. Как и в прошлый раз, нам потребуется обучающая выборка. В обучающих данных, созданных разработчиками SentiRuEval-2015 различают явные термины (блюда, еда, официант, ресторан, стол и т. п.) и неявные термины (вкусный, громкий, пересоленый). Вы можете использовать готовую разметку, или придумать свои обозначения.
Исходные выборки SentiRuEval -2015 находятся в публичном доступе в виде XML файлов. В этих данных нет предварительной обработки, (разбиение на предложения, слова и т.п). Поэтому, мы приготовили данные в нужном формате использования с нашем API (загрузить). В нашей выборке представлены только явные аспектные термины (explicit) и она также разделена на два файла: rest_expl_train.txt – данные для обучения модели и rest_expl_test.txt – данные для проверки результатов (оба файла сделаны из исходной обучающей выборки SentiRuEval-2015).
Здесь есть правда одна тонкость — если встретится фраза вроде «принес официант рыбные блюда», то «официант рыбные блюда» будет выделено как один термин, хотя их на самом деле здесь два — «официант» и «рыбные блюда». Поэтому часто для первого и последнего слова термина используют отдельные обозначения — чтобы можно было потом разделить. Но это не всегда бывает оправданно, т.к. в отсутствии достаточного числа примеров таких сливающихся терминов, модель может все равно не научится правильно ставить начало и конец, и увеличение числа классов потребует увеличения объема обучающей выборки для получения адекватного качества работы модели. Поэтому, имеет смысл попробовать оба варианта и сравнить качество получаемых результатов, но если времени нет, вполне подойдет и первый вариант.
Создать модель можно аналогично предыдущему примеру с извлечением названий товаров. Для упрощения работы с API можно использовать библиотеку для .NET Framework
также в комплекте есть исполняемый файл примера, с помощью которого можно загрузить произвольные файлы и проверить результаты без написания кода.
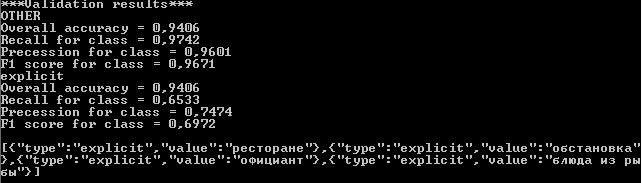
После обучения модели, мы запрашиваем статистику на тестовой выборке, а также разбор для нового примера:
Вот что получилось:
Специально для этой статьи я сделал также онлайн-демо на php, в виде формы в которую можно ввести данные и получить выделенные термины.
Подробнее об API извлечения информации из текста можно прочитать в предыдущей записи, а технические детали работы есть в нашей статье, опубликованной в сборнике «Компьютерная лингвистика и интеллектуальные технологии» (текст на английском языке).
Анализ отзывов по аспектам часто разделяют на несколько этапов. Рассмотрим например предложение «японские блюда были вкусными, но официант работал медленно». На первом этапе мы выделяем из него важные для нас слова или словосочетания. В данном случае это «японские блюда», «вкусными», «официант», «медленно». Это позволяет понять, о чем идет речь в предложении. Далее мы можем захотеть сгруппировать термины — например отнести «блюда» и «вкусными» к еде, а «официант» к обслуживанию. Такая группировка позволит выдавать агрегированную статистику. Наконец, мы можем захотеть оценить тональность терминов, говорится о них что-то положительное или отрицательное
Зачем: Ответить на этот вопрос сейчас не так-то просто. В предположении организаторов тестирования задачей является в итоге оценить тональность отзыва в целом, т. е. сказать, что автор этого отзыва считает обслуживание хорошим, а интерьер плохим. Но эта задача сегодня решается другими методами — на большинстве сайтов-отзовиков предусмотрено, что когда пользователь оставляет отзыв, он также заполняет вручную оценки по аспектам. Доступность такой информации резко снижает ценность подобного синтетического анализа. Хотя можно, конечно, выделять дополнительные аспекты, анализировать посты с форумов, но все это имеет для пользователя вторичное значение.
Но, допустим, нам нужно решить обратную задачу. Например, вы владелец ресторана, и вам интересно, почему в разделе «интерьер» указана плохая оценка. А связь с исходным текстом на сайтах с ручной оценкой по большей части утеряна. Придется просмотреть все отзывы с негативной оценкой целиком, чтобы найти нужные сведения. А отзывы эти бывают, прямо скажем, довольно длинные и содержащие много «воды», вроде «вчера у моей подруги было день рожденья. Мы собрались и долго думали куда пойти. Обычно мы...» ну и так далее. Выделив важные аспектные термины, можно подсветить их в тексте, или показать только содержащие их предложения, или даже, подсчитать их и вывести такую сводку:
Громкая музыка — 34
Накурено — 8
Кондиционер — 4
Грязно в туалете — 2
Сократив трудозатраты на анализ мы повысим эффективность бизнеса, плюс ресторан будет иметь возможность реагировать на различные проблемы и запросы посетителей. Хотя конечно, не все владельцы ресторанов предметно занимаются таким тщательным мониторингом отзывов, но это уже другой вопрос.
Реализация: Для реализации с помощью Meanotek NeuText API вам будет нужен бесплатный API ключ, если у вас еще нет его, то можно получить здесь. Как и в прошлый раз, нам потребуется обучающая выборка. В обучающих данных, созданных разработчиками SentiRuEval-2015 различают явные термины (блюда, еда, официант, ресторан, стол и т. п.) и неявные термины (вкусный, громкий, пересоленый). Вы можете использовать готовую разметку, или придумать свои обозначения.
Исходные выборки SentiRuEval -2015 находятся в публичном доступе в виде XML файлов. В этих данных нет предварительной обработки, (разбиение на предложения, слова и т.п). Поэтому, мы приготовили данные в нужном формате использования с нашем API (загрузить). В нашей выборке представлены только явные аспектные термины (explicit) и она также разделена на два файла: rest_expl_train.txt – данные для обучения модели и rest_expl_test.txt – данные для проверки результатов (оба файла сделаны из исходной обучающей выборки SentiRuEval-2015).
| японские | explicit |
| блюда | explicit |
| были | |
| вкусными | implicit |
| , | |
| официант | explicit |
| ... |
Здесь есть правда одна тонкость — если встретится фраза вроде «принес официант рыбные блюда», то «официант рыбные блюда» будет выделено как один термин, хотя их на самом деле здесь два — «официант» и «рыбные блюда». Поэтому часто для первого и последнего слова термина используют отдельные обозначения — чтобы можно было потом разделить. Но это не всегда бывает оправданно, т.к. в отсутствии достаточного числа примеров таких сливающихся терминов, модель может все равно не научится правильно ставить начало и конец, и увеличение числа классов потребует увеличения объема обучающей выборки для получения адекватного качества работы модели. Поэтому, имеет смысл попробовать оба варианта и сравнить качество получаемых результатов, но если времени нет, вполне подойдет и первый вариант.
Создать модель можно аналогично предыдущему примеру с извлечением названий товаров. Для упрощения работы с API можно использовать библиотеку для .NET Framework
Model MyModel = new Model("Ваш api ключ","RestExplModel");
MyModel.CreateModel();
Console.WriteLine("Загружаем обучающие данные");
MyModel.UploadTrainData("rest_expl_train.txt");
Console.WriteLine("Загружаем проверочные данные");
MyModel.UploadTestData ("rest_expl_dev.txt");
Console.WriteLine("Обучение модели");
MyModel.TrainModel();
также в комплекте есть исполняемый файл примера, с помощью которого можно загрузить произвольные файлы и проверить результаты без написания кода.
После обучения модели, мы запрашиваем статистику на тестовой выборке, а также разбор для нового примера:
Console.WriteLine(MyModel.GetValidationResults());
string p = model.GetPredictionsJson("В ресторане оказалась приятная обстановка, был хороший официант, подавали вкусные блюда из рыбы");
Console.WriteLine(p);
Вот что получилось:

Специально для этой статьи я сделал также онлайн-демо на php, в виде формы в которую можно ввести данные и получить выделенные термины.
Подробнее об API извлечения информации из текста можно прочитать в предыдущей записи, а технические детали работы есть в нашей статье, опубликованной в сборнике «Компьютерная лингвистика и интеллектуальные технологии» (текст на английском языке).
