В этой статье мы поговорим о шаблонах проектирования «Единица работы» и «Репозиторий» в контексте тестового веб-приложения на ASP.NET Core (с использованием встроенного DI), которое мы с вами вместе и разработаем. В результате мы получим две реализации взаимодействия с хранилищем: настоящую, на основе базы данных SQLite, и фейковую, для быстрого тестирования, на основе перечисления в памяти. Переключение между этими двумя реализациями будет выполняться изменением одной строчки кода.

Традиционно, если вы еще не работали с ASP.NET Core, то здесь есть ссылки на все, что для этого понадобится.
Запускаем Visual Studio, создаем новое веб-приложение:

Веб-приложение готово. При желании его можно запустить.
Начнем с моделей. Вынесем их классы в отдельный проект — библиотеку классов AspNetCoreStorage.Data.Models:

Добавим класс нашей единственной модели Item:
Для нашего примера этого хватит.
Теперь перейдем непосредственно к взаимодействию с хранилищем, которое в нашем веб-приложении будет реализовано с применением двух шаблонов проектирования — Единица работы и Репозиторий. Имплементация этих шаблонов упрощенно означает, что взаимодействие с хранилищем в рамках одного запроса будет гарантированно производиться в едином контексте хранилища, а для каждой модели будет создан отдельный репозиторий, содержащий все необходимые методы для манипуляций с ней.
Для обеспечения возможности простого переключения между различными реализациями взаимодействия с хранилищем, наше веб-приложение не должно использовать какую-то конкретную реализацию напрямую. Вместо этого все взаимодействие с хранилищем должно производиться через слой абстракций. Опишем его в библиотеке классов AspNetCoreStorage.Data.Abstractions (создадим соответствующий проект).
Для начала добавим интерфейс IStorageContext без каких-либо свойств или методов:
Классы, реализующие этот интерфейс, будут непосредственно описывать хранилище (например, базу данных со строкой подключения к ней).
Далее, добавим интерфейс IStorage. Он содержит два метода — GetRepository и Save:
Этот интерфейс описывает реализацию шаблона проектирования Единица работы. Объект класса, реализующего этот интерфейс, будет единственной точкой доступа к хранилищу и должен существовать в единственном экземпляре в рамках одного запроса к веб-приложению. За создание этого объекта у нас будет отвечать встроенный в ASP.NET Core DI.
Метод GetRepository будет находить и возвращать репозиторий соответствующего типа (для соответствующей модели), а метод Save — фиксировать изменения, произведенные всеми репозиториями.
Наконец, добавим интерфейс IRepository с единственным методом SetStorageContext:
Очевидно, что этот интерфейс описывает классы репозиториев. В момент запроса репозитория объект класса, реализующего интерфейс IStorage, будет передавать единый контекст хранилища в возвращаемый репозиторий с помощью метода SetStorageContext, чтобы все обращения к репозиторию производились в рамках этого единого контекста, как мы говорили выше.
На этом общие интерфейсы описаны. Теперь добавим интерфейс репозитория нашей единственной модели Item — IItemRepository. Этот интерфейс содержит лишь один метод — All:
В реальном веб-приложении здесь также могли бы быть описаны методы Create, Edit, Delete, какие-то методы для извлечения объектов по различным параметрам и так далее, но в нашем упрощенном примере в них необходимости нет.
Как мы уже договорились выше, у нас будет две реализации взаимодействия с хранилищем: на основе базы данных SQLite и на основе перечисления в памяти. Начнем со второй, так как она проще. Опишем ее в библиотеке классов AspNetCoreStorage.Data.Mock (создадим соответствующий проект).
Нам понадобится реализовать 3 интерфейса из нашего слоя абстракций: IStorageContext, IStorage и IItemRepository (т. к. IItemRepository расширяет IRepository).
Реализация интерфейса IStorageContext в случае с перечислением в памяти не будет содержать никакого кода, это просто пустой класс, поэтому перейдем сразу к IStorage. Класс небольшой, поэтому приведем его здесь целиком:
Как видим, класс содержит свойство StorageContext, которое инициализируется в конструкторе. Метод GetRepository перебирает все типы текущей сборки в поисках реализации заданного параметром T интерфейса репозитория. В случае, если подходящий тип обнаружен, создается соответствующий объект репозитория, вызывается его метод SetStorageContext и затем этот объект возвращается. Метод Save не делает ничего. (На самом деле, мы могли бы вообще не использовать StorageContext в этой реализации, передавая null в SetStorageContext, но оставим его для единообразия.)
Теперь посмотрим на реализацию интерфейса IItemRepository:
Все очень просто. Метод All возвращает набор элементов из переменной items, которая инициализируется в конструкторе. Метод SetStorageContext не делает ничего, так как никакого контекста в этом случае нам не нужно.
Теперь реализуем те же самые интерфейсы, но уже для работы с базой данных SQLite. На этот раз реализация IStorageContext потребует написания некоторого кода:
Как видим, кроме реализации интерфейса IStorageContext этот класс еще и наследует DbContext, представляющий контекст базы данных в Entity Framework Core, чьи методы OnConfiguring и OnModelCreating он и переопределяет (не будем на них останавливаться). Также обратите внимание на переменную connectionString.
Реализация интерфейса IStorage идентична приведенной выше, за исключением того, что в конструктор класса StorageContext необходимо передать строку подключения (конечно, в реальном приложении указывать строку подключения таким образом неправильно, ее следовало бы взять из параметров конфигурации):
А также, метод Save должен теперь вызывать метод SaveChanges контекста хранилища, унаследованный от DbContext:
Реализация интерфейса IItemRepository выглядит теперь таким образом:
Метод SetStorageContext принимает объект класса, реализующего интерфейс IStorageContext, и приводит его к StorageContext (то есть к конкретной реализации, о которой этот репозиторий осведомлен, так как сам является ее частью), затем с помощью метода Set инициализирует переменную dbSet, которая представляет таблицу в базе данных SQLite. Метод All на этот раз возвращает реальные данные из таблицы базы данных, используя переменную dbSet.
Конечно, если бы у нас было более одного репозитория, было бы логично вынести общую реализацию в какой-нибудь RepositoryBase, где параметр T описывал бы тип модели, параметризировал dbSet и передавался затем в метод Set контекста хранилища.
Теперь мы готовы немного модифицировать наше веб-приложение, чтобы заставить его выводить список объектов нашего класса Item на главной странице.
Для начала, добавим ссылки на обе конкретные реализации взаимодействия с хранилищем в раздел dependencies файла project.json основного проекта веб-приложения. В итоге получится как-то так:
Теперь перейдем к методу ConfigureServices класса Startup и добавим туда регистрацию сервиса IStorage для двух разных реализаций (одну из них закомментируем, обратите внимание, что реализации регистрируются с помощью метода AddScoped, что означает, что временем жизни объекта является один запрос):
Теперь перейдем к контроллеру HomeController:
Мы добавили переменную storage типа IStorage и инициализируем ее в конструкторе. Встроенный в ASP.NET Core DI сам передаст зарегистрированную реализацию интерфейса IStorage в конструктор контроллера во время его создания.
Далее, в методе Index мы получаем доступный репозиторий, реализующий интерфейс IItemRepository (напоминаем, все получаемые таким образом репозитории будут иметь единый контекст хранилища благодаря применению шаблона проектирования Единица работы) и передаем в представление набор объектов класса Item, получив их с помощью метода All репозитория.
Теперь выведем полученный список объектов в представлении. Для этого укажем перечисление объектов класса Item в качестве модели вида для представления, а затем в цикле выведем значения свойства Name каждого из объектов:
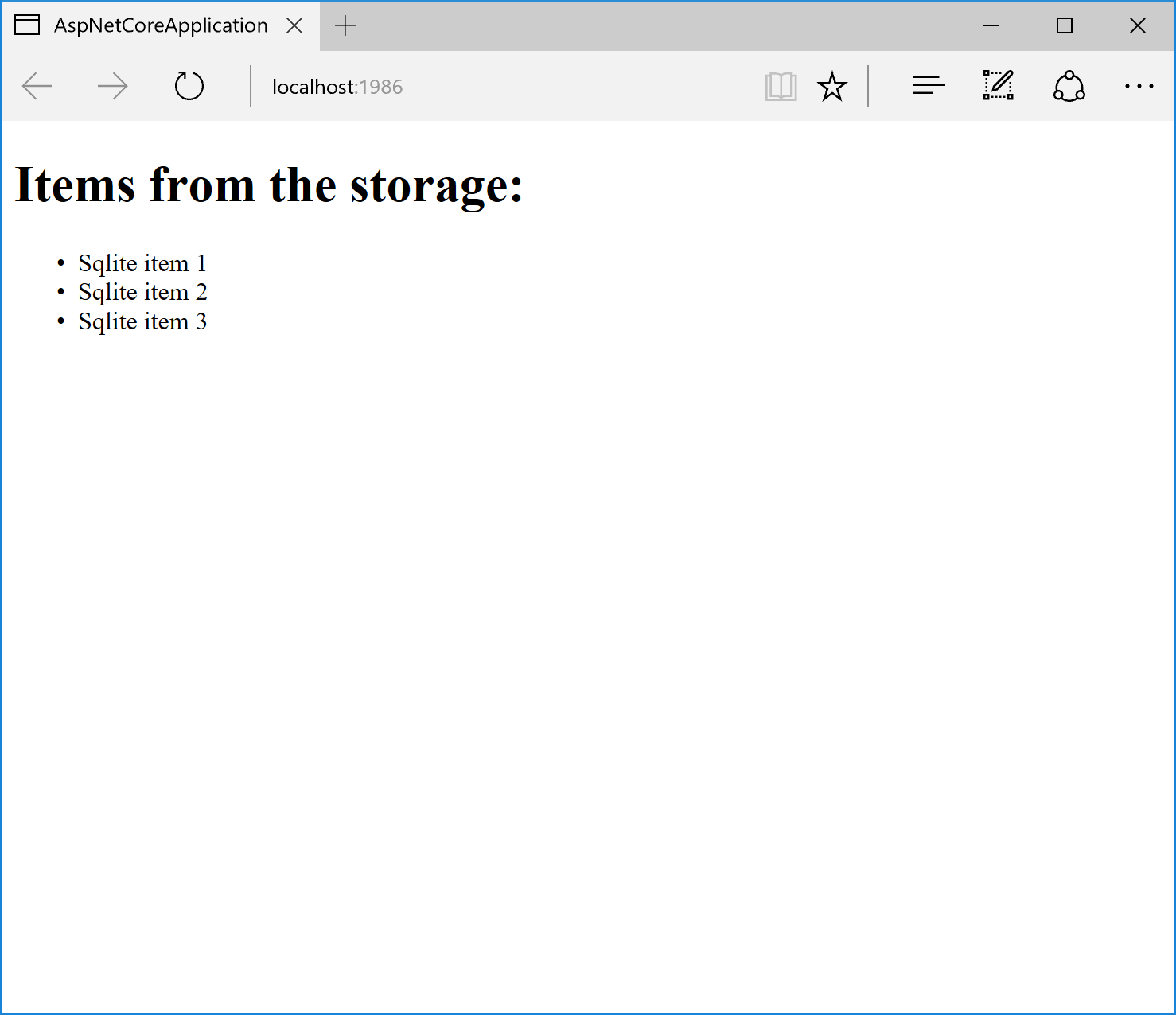
Если сейчас запустить наше веб-приложение мы должны получить следующий результат:

Если же мы поменяем регистрацию реализации интерфейса IStorage на другую, то и результат изменится:
Как видим, все работает!
Встроенный в ASP.NET Core механизм внедрения зависимостей (DI) очень упрощает реализацию подобных нашей задач и делает ее более близкой, простой и понятной новичкам. Что касается непосредственно Единицы работы и Репозитория — для типичных веб-приложений это наиболее удачное решение взаимодействия с данными, упрощающее командную разработку и тестирование.
Тестовый проект выложен на GitHub.

Дмитрий Сикорский — владелец и руководитель компании-разработчика программного обеспечения «Юбрейнианс», а также, совладелец киевской службы доставки пиццы «Пиццариум».
1. Создание внешнего интерфейса веб-службы для приложения.
2. В ногу со временем: Используем JWT в ASP.NET Core.
3. ASP.NET Core на Nano Server.

Подготовка
Традиционно, если вы еще не работали с ASP.NET Core, то здесь есть ссылки на все, что для этого понадобится.
Запускаем Visual Studio, создаем новое веб-приложение:
Веб-приложение готово. При желании его можно запустить.
Приступаем
Модели
Начнем с моделей. Вынесем их классы в отдельный проект — библиотеку классов AspNetCoreStorage.Data.Models:
Добавим класс нашей единственной модели Item:
public class Item
{
public int Id { get; set; }
public string Name { get; set; }
}
Для нашего примера этого хватит.
Абстракции взаимодействия с хранилищем
Теперь перейдем непосредственно к взаимодействию с хранилищем, которое в нашем веб-приложении будет реализовано с применением двух шаблонов проектирования — Единица работы и Репозиторий. Имплементация этих шаблонов упрощенно означает, что взаимодействие с хранилищем в рамках одного запроса будет гарантированно производиться в едином контексте хранилища, а для каждой модели будет создан отдельный репозиторий, содержащий все необходимые методы для манипуляций с ней.
Для обеспечения возможности простого переключения между различными реализациями взаимодействия с хранилищем, наше веб-приложение не должно использовать какую-то конкретную реализацию напрямую. Вместо этого все взаимодействие с хранилищем должно производиться через слой абстракций. Опишем его в библиотеке классов AspNetCoreStorage.Data.Abstractions (создадим соответствующий проект).
Для начала добавим интерфейс IStorageContext без каких-либо свойств или методов:
public interface IStorageContext
{
}
Классы, реализующие этот интерфейс, будут непосредственно описывать хранилище (например, базу данных со строкой подключения к ней).
Далее, добавим интерфейс IStorage. Он содержит два метода — GetRepository и Save:
public interface IStorage
{
T GetRepository<T>() where T : IRepository;
void Save();
}
Этот интерфейс описывает реализацию шаблона проектирования Единица работы. Объект класса, реализующего этот интерфейс, будет единственной точкой доступа к хранилищу и должен существовать в единственном экземпляре в рамках одного запроса к веб-приложению. За создание этого объекта у нас будет отвечать встроенный в ASP.NET Core DI.
Метод GetRepository будет находить и возвращать репозиторий соответствующего типа (для соответствующей модели), а метод Save — фиксировать изменения, произведенные всеми репозиториями.
Наконец, добавим интерфейс IRepository с единственным методом SetStorageContext:
public interface IRepository
{
void SetStorageContext(IStorageContext storageContext);
}
Очевидно, что этот интерфейс описывает классы репозиториев. В момент запроса репозитория объект класса, реализующего интерфейс IStorage, будет передавать единый контекст хранилища в возвращаемый репозиторий с помощью метода SetStorageContext, чтобы все обращения к репозиторию производились в рамках этого единого контекста, как мы говорили выше.
На этом общие интерфейсы описаны. Теперь добавим интерфейс репозитория нашей единственной модели Item — IItemRepository. Этот интерфейс содержит лишь один метод — All:
public interface IItemRepository : IRepository
{
IEnumerable<Item> All();
}
В реальном веб-приложении здесь также могли бы быть описаны методы Create, Edit, Delete, какие-то методы для извлечения объектов по различным параметрам и так далее, но в нашем упрощенном примере в них необходимости нет.
Конкретные реализации взаимодействия с хранилищем: перечисление в памяти
Как мы уже договорились выше, у нас будет две реализации взаимодействия с хранилищем: на основе базы данных SQLite и на основе перечисления в памяти. Начнем со второй, так как она проще. Опишем ее в библиотеке классов AspNetCoreStorage.Data.Mock (создадим соответствующий проект).
Нам понадобится реализовать 3 интерфейса из нашего слоя абстракций: IStorageContext, IStorage и IItemRepository (т. к. IItemRepository расширяет IRepository).
Реализация интерфейса IStorageContext в случае с перечислением в памяти не будет содержать никакого кода, это просто пустой класс, поэтому перейдем сразу к IStorage. Класс небольшой, поэтому приведем его здесь целиком:
public class Storage : IStorage
{
public StorageContext StorageContext { get; private set; }
public Storage()
{
this.StorageContext = new StorageContext();
}
public T GetRepository<T>() where T : IRepository
{
foreach (Type type in this.GetType().GetTypeInfo().Assembly.GetTypes())
{
if (typeof(T).GetTypeInfo().IsAssignableFrom(type) && type.GetTypeInfo().IsClass)
{
T repository = (T)Activator.CreateInstance(type);
repository.SetStorageContext(this.StorageContext);
return repository;
}
}
return default(T);
}
public void Save()
{
// Do nothing
}
}
Как видим, класс содержит свойство StorageContext, которое инициализируется в конструкторе. Метод GetRepository перебирает все типы текущей сборки в поисках реализации заданного параметром T интерфейса репозитория. В случае, если подходящий тип обнаружен, создается соответствующий объект репозитория, вызывается его метод SetStorageContext и затем этот объект возвращается. Метод Save не делает ничего. (На самом деле, мы могли бы вообще не использовать StorageContext в этой реализации, передавая null в SetStorageContext, но оставим его для единообразия.)
Теперь посмотрим на реализацию интерфейса IItemRepository:
public class ItemRepository : IItemRepository
{
public readonly IList<Item> items;
public ItemRepository()
{
this.items = new List<Item>();
this.items.Add(new Item() { Id = 1, Name = "Mock item 1" });
this.items.Add(new Item() { Id = 2, Name = "Mock item 2" });
this.items.Add(new Item() { Id = 3, Name = "Mock item 3" });
}
public void SetStorageContext(IStorageContext storageContext)
{
// Do nothing
}
public IEnumerable<Item> All()
{
return this.items.OrderBy(i => i.Name);
}
}
Все очень просто. Метод All возвращает набор элементов из переменной items, которая инициализируется в конструкторе. Метод SetStorageContext не делает ничего, так как никакого контекста в этом случае нам не нужно.
Конкретные реализации взаимодействия с хранилищем: база данных SQLite
Теперь реализуем те же самые интерфейсы, но уже для работы с базой данных SQLite. На этот раз реализация IStorageContext потребует написания некоторого кода:
public class StorageContext : DbContext, IStorageContext
{
private string connectionString;
public StorageContext(string connectionString)
{
this.connectionString = connectionString;
}
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
base.OnConfiguring(optionsBuilder);
optionsBuilder.UseSqlite(this.connectionString);
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.Entity<Item>(etb =>
{
etb.HasKey(e => e.Id);
etb.Property(e => e.Id);
etb.ForSqliteToTable("Items");
}
);
}
}
Как видим, кроме реализации интерфейса IStorageContext этот класс еще и наследует DbContext, представляющий контекст базы данных в Entity Framework Core, чьи методы OnConfiguring и OnModelCreating он и переопределяет (не будем на них останавливаться). Также обратите внимание на переменную connectionString.
Реализация интерфейса IStorage идентична приведенной выше, за исключением того, что в конструктор класса StorageContext необходимо передать строку подключения (конечно, в реальном приложении указывать строку подключения таким образом неправильно, ее следовало бы взять из параметров конфигурации):
this.StorageContext = new StorageContext("Data Source=..\\..\\..\\db.sqlite");
А также, метод Save должен теперь вызывать метод SaveChanges контекста хранилища, унаследованный от DbContext:
public void Save()
{
this.StorageContext.SaveChanges();
}
Реализация интерфейса IItemRepository выглядит теперь таким образом:
public class ItemRepository : IItemRepository
{
private StorageContext storageContext;
private DbSet<Item> dbSet;
public void SetStorageContext(IStorageContext storageContext)
{
this.storageContext = storageContext as StorageContext;
this.dbSet = this.storageContext.Set<Item>();
}
public IEnumerable<Item> All()
{
return this.dbSet.OrderBy(i => i.Name);
}
}
Метод SetStorageContext принимает объект класса, реализующего интерфейс IStorageContext, и приводит его к StorageContext (то есть к конкретной реализации, о которой этот репозиторий осведомлен, так как сам является ее частью), затем с помощью метода Set инициализирует переменную dbSet, которая представляет таблицу в базе данных SQLite. Метод All на этот раз возвращает реальные данные из таблицы базы данных, используя переменную dbSet.
Конечно, если бы у нас было более одного репозитория, было бы логично вынести общую реализацию в какой-нибудь RepositoryBase, где параметр T описывал бы тип модели, параметризировал dbSet и передавался затем в метод Set контекста хранилища.
Взаимодействие веб-приложения с хранилищем
Теперь мы готовы немного модифицировать наше веб-приложение, чтобы заставить его выводить список объектов нашего класса Item на главной странице.
Для начала, добавим ссылки на обе конкретные реализации взаимодействия с хранилищем в раздел dependencies файла project.json основного проекта веб-приложения. В итоге получится как-то так:
"dependencies": {
"AspNetCoreStorage.Data.Mock": "1.0.0",
"AspNetCoreStorage.Data.Sqlite": "1.0.0",
"Microsoft.AspNetCore.Diagnostics": "1.0.0",
"Microsoft.AspNetCore.Mvc": "1.0.1",
"Microsoft.AspNetCore.Server.IISIntegration": "1.0.0",
"Microsoft.AspNetCore.Server.Kestrel": "1.0.1",
"Microsoft.Extensions.Logging.Console": "1.0.0",
"Microsoft.NETCore.App": {
"version": "1.0.1",
"type": "platform"
}
}
Теперь перейдем к методу ConfigureServices класса Startup и добавим туда регистрацию сервиса IStorage для двух разных реализаций (одну из них закомментируем, обратите внимание, что реализации регистрируются с помощью метода AddScoped, что означает, что временем жизни объекта является один запрос):
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
// Uncomment to use mock storage
services.AddScoped(typeof(IStorage), typeof(AspNetCoreStorage.Data.Mock.Storage));
// Uncomment to use SQLite storage
//services.AddScoped(typeof(IStorage), typeof(AspNetCoreStorage.Data.Sqlite.Storage));
}
Теперь перейдем к контроллеру HomeController:
public class HomeController : Controller
{
private IStorage storage;
public HomeController(IStorage storage)
{
this.storage = storage;
}
public ActionResult Index()
{
return this.View(this.storage.GetRepository<IItemRepository>().All());
}
}
Мы добавили переменную storage типа IStorage и инициализируем ее в конструкторе. Встроенный в ASP.NET Core DI сам передаст зарегистрированную реализацию интерфейса IStorage в конструктор контроллера во время его создания.
Далее, в методе Index мы получаем доступный репозиторий, реализующий интерфейс IItemRepository (напоминаем, все получаемые таким образом репозитории будут иметь единый контекст хранилища благодаря применению шаблона проектирования Единица работы) и передаем в представление набор объектов класса Item, получив их с помощью метода All репозитория.
Теперь выведем полученный список объектов в представлении. Для этого укажем перечисление объектов класса Item в качестве модели вида для представления, а затем в цикле выведем значения свойства Name каждого из объектов:
@model IEnumerable<AspNetCoreStorage.Data.Models.Item>
<h1>Items from the storage:</h1>
<ul>
@foreach (var item in this.Model)
{
<li>@item.Name</li>
}
</ul>
Если сейчас запустить наше веб-приложение мы должны получить следующий результат:
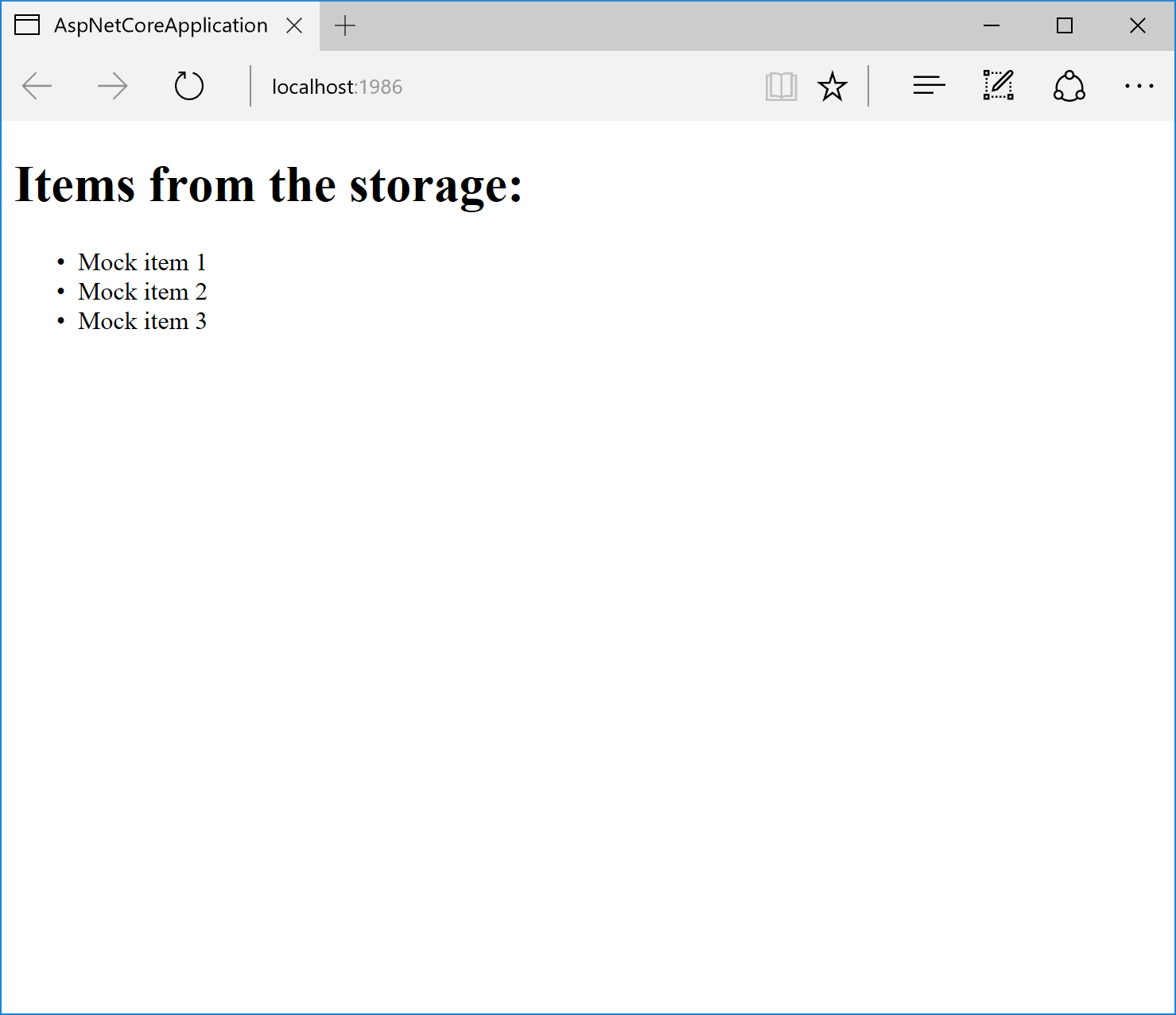
Если же мы поменяем регистрацию реализации интерфейса IStorage на другую, то и результат изменится:

Как видим, все работает!
Заключение
Встроенный в ASP.NET Core механизм внедрения зависимостей (DI) очень упрощает реализацию подобных нашей задач и делает ее более близкой, простой и понятной новичкам. Что касается непосредственно Единицы работы и Репозитория — для типичных веб-приложений это наиболее удачное решение взаимодействия с данными, упрощающее командную разработку и тестирование.
Тестовый проект выложен на GitHub.
Об авторе

Дмитрий Сикорский — владелец и руководитель компании-разработчика программного обеспечения «Юбрейнианс», а также, совладелец киевской службы доставки пиццы «Пиццариум».
Последние статьи по ASP.NET Core
1. Создание внешнего интерфейса веб-службы для приложения.
2. В ногу со временем: Используем JWT в ASP.NET Core.
3. ASP.NET Core на Nano Server.
