Привет, Хабр! Продолжаем рассказывать о прошедшем 12-14 сентября форуме Data Science Week 2017, и на очереди обзор второго и третьего дня, где были затронуты вопросы построения рекомендательных систем, анализа данных в Bitcoin и построения успешной карьеры в области работы с данными.

Второй день Data Science Week открыл Александр Ульянов — Руководитель разработки моделей в Сбербанке, выпускник 6-го запуска программы “Специалист по большим данным”. Александр рассказал об использовании библиотеки LibFM при построении рекомендательных систем в кабельном и интернет-телевидении. Эта задача является одной из лабораторных работ на программе, и Александр занял первое место по ее результатам.
Сразу же стоит заметить, что эта библиотека применима не только в рекомендательных системах, но и в анализе временных рядов. Интересно, что про нее на русском языке очень мало материалов, хотя благодаря ей было выиграно несколько соревнований на Kaggle.
В данном случае стояла классическая задача рекомендации: есть пользователь, есть фильм, хотим для каждого фильма предсказать его рейтинг для этого пользователя и затем рекомендовать этому пользователю фильмы с максимальным предсказанным рейтингом, либо оценить вероятность покупки того или иного фильма этим пользователем.
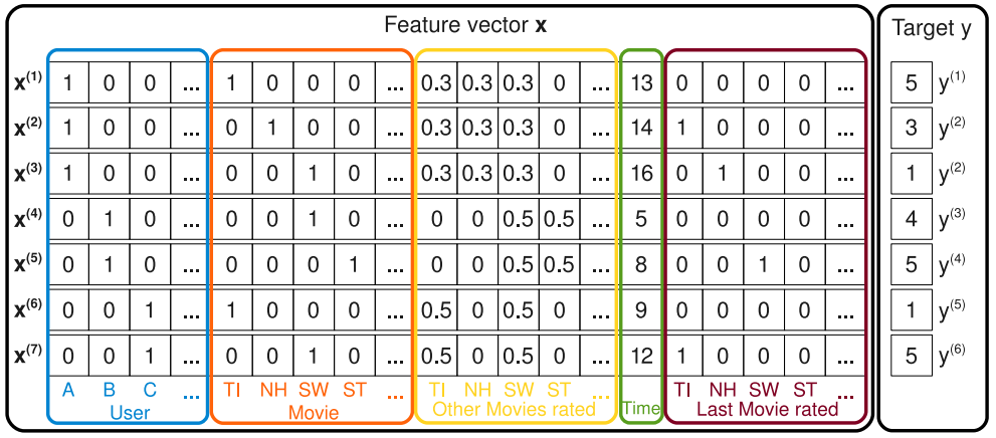
Основная проблема построения таких систем — сконструировать пространство признаков таким образом, чтобы в нем уместилось огромное количество информации как о пользователях (личный кабинет, соц. сети), так и о фильмах (жанр, год выпуска, актеры). Решение заключается в представлении каждого события — пользователь поставил оценку фильму — в виде вектора-строки, организованного вот так:

Совместив все векторы, получаем очень сильно разреженную матрицу с более чем 150 000 столбцов, которая и будет пространством признаков, а в качестве целевой переменной примем оценку рейтинга или итоговое событие — купил/не купил фильм:
Теперь перейдем непосредственно к самой модели, которая может быть разделена на 2 части: классическая линейная регрессия и факторное взаимодействие между собой всех множителей, которое, за счет регулирования параметра k, позволяет алгоритму работать с такой sparse-матрицей:
где . Теперь, когда модель формализована, рассмотрим ее первоначальный вариант с использованием лишь информации об id абонента, id телепередачи и факте ее покупки. В качестве метрики взяли ROC-AUC:
. Теперь, когда модель формализована, рассмотрим ее первоначальный вариант с использованием лишь информации об id абонента, id телепередачи и факте ее покупки. В качестве метрики взяли ROC-AUC:
В результате без использования дополнительных данных о клиентах и телепередачах удалось получить значение ROC-AUC равное 0.923. Добавление информации о фильмах (жанр и год выпуска) позволило увеличить значение метрики до 0.935. Наконец, использовав всю имеющуюся информацию (добавились данные о клиенте: временной интервал просмотра, вживую или в записи), мы получили итоговые 0.936.
Особенности библиотеки:
Далее Александр Филатов из департамента аналитики Visa в России рассказал о том, как наладить диалог между аналитиками и бизнесом, чтобы последние действительно понимали на основании чего была построена модель и выдвинуты рекомендации.
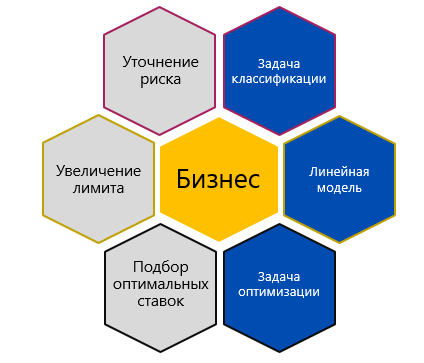
К примеру, у какого-то банка имеется портфель кредитных карт, прибыль с которого нужно максимизировать. С точки зрения бизнеса есть 3 подхода к этой задачи, каждому из которых можно поставить соответствующую математическую модель:
На этом этапе в дело вступают аналитики, начинают строить модели, тестировать их, получая результат и оформляя отчет, в котором написано, что R-квадрат равен 90%, ROC-AUC равен 0.92 и ROI — 110%, проект окупится менее, чем через год и отправляют отчет бизнесу, который говорит на совершенно другом языке, видит это решение, но не может его распознать. Как правильно донести проблему и ее решение до бизнеса?
Самый простой способ это сделать — сочинить историю и рассказать ее. Здесь можно выделить 3 главных этапа создания истории:
В итоге по модели, видно, что необходимо работать с клиентами, находящимися в правой верхней части, они имеют наибольшую ценность сейчас и принесут еще больше дохода в будущем. После рассказанной истории это видно и бизнесу, который, познакомившись с клиентами и особенностями их поведения, оценив степень влияния каждого из них на финансовый результат компании, гораздо легче воспринимает модели и рекомендации аналитиков.
Андрей Манолов из Riftman рассказал о проекте по применению Apache Spark для анализа информации в Bitcoin. Главная проблема заключалась в том, что в биткоине напрямую не хранится информация об отправителях и получателях переводов и о том, какой у них баланс кошелька. У каждой транзакции в биткоине есть выходы, обладающие значениями, показывающими сколько монет было отправлено в пользу кого-то другого, и входы, значениями не обладающими: в них записана лишь ссылка на предыдущую транзакцию и номер выхода.
Таким образом, чтобы получить необходимую информацию мы подняли биткоин-ноду на хостинге в объединенной сети и настроили так, что все данные загружались в кластер Apache Spark, и там проводилась следующая обратная операция: мы раскручиваем весь процесс в обратную сторону, двигаясь от выходов со значениями транзакций к входам со ссылками на предыдущие транзакции, затем обратно к выходам и так далее, пока не поймем, какому адресу какое количество биткоинов принадлежит. Таким образом, было сделано 3 job-а на Spark-е: выгрузка всех интересующих нас транзакций (в нашем случае out > 10 BTC), Broadcast join и Self join. В итоге получаем 3 таблицы данных в удобном для анализа формате.
Возможные области применения и развития решения:
Если рассматриваемый кошелек находится в 1-2 «шагах» от «плохого», то скорее всего он каким-то образом связан с нелегальными сделками и не может быть легализован.
Второй день завершил Кирилл Данилюк — Data Scientist в RnD Lab со своим пайплайном использования Deep Learning для распознавания дорожных знаков, о котором мы вам рассказывали тут, тут и тут.
Третий день DSW начался с Александра Ларионова — CEO компании BSSL, которая занимается бизнес-социометрией по методике “Азимут” — системой оценки сотрудников, применяемой для анализа взаимодействий и компетенций сотрудников в организации.
Перед тем, как приступить непосредственно к анализу, необходимо собрать данные посредством опроса. Сотрудники компании отвечают на вопросы о рабочих отношениях внутри коллектива: кто из коллег за последние полгода вносил вклад в задачи, над которыми вы работали? Чье внимание, содействие или помощь были вам необходимы?
Затем на основании этих данных строятся ряд методик:
Матрица совместимости. Помимо того, насколько здоровые отношения в коллективе, нам бы хотелось узнать о взаимозаменяемости сотрудников (на случай болезни, отпуска и т.д). Для этого используется множество метрик: софт-скиллс заменяющего, знакомство с кругом задач, позитивные отношения с кругом взаимодействия заменяемого и им самим. Также, если человек систематически выбирает кого-то на «отрицательные вопросы» («был недоступен», «занят»), то скорее всего он к нему относится не очень хорошо и наоборот. Затем по ответам сотрудников строится матрица совместимости, где по строкам и столбцам отмечены сотрудники, а на пересечении — коэффициенты корреляции их ответов, умноженные на 1000:

Как видно по матрице, например, Уильям имеет отличные отношения с Сильвией и Алисой, но не с Джоном.
Далее была панельная дискуссия по теме «Подбор команд по работе с данными и оценка их эффективности». Модератором выступила Ольга Филатова, вице-президент по персоналу и образовательным проектам Mail.ru Group, а участниками были Виктор Кантор (Яндекс), Андрей Уваров (МегаФон), Павел Клеменков (Rambler&Co), Александр Ерофеев (Сбербанк). Об этой часовой сессии мы напишем отдельно, потому что рассказать там есть о чем.
Продолжила разговор о работе в команде Анаит Антонян, CEO компании Buran HR, занимающейся подбором людей для создания стартап-команд. Она рассказала о том, как молодому IT специалисту выбрать между работой в стартапе и крупной корпорации, и кто в итоге удовлетворен своим выбором.
“По многолетнему опыту работы в области HR, я могу сказать, что существуют компетенции, которые больше подходят для работы в стартапе, которые при этом могут осложнить работу в крупной компании:
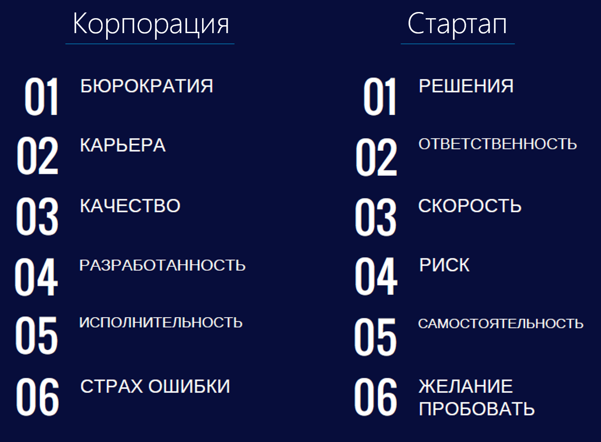
При этом, если говорить об удовлетворенности своим выбором, то здесь ситуация такая, что молодой (до 27 лет) стартапер в среднем на 40% более доволен своей работой, чем корпоративный сотрудник того же возраста, при этом для людей старше 32 лет ситуация противоположная: взрослый «корпорат» в среднем на 36% более доволен.
Рассматривая не IT отрасль в целом, а Data Science, можно заметить, что специалисты в этой области чувствуют себя более счастливыми чем другие разработчики”:

Завершала насыщенный третий день и всю конференцию Наталья Тихомирова — executive-коуч и руководитель направления компании BestBrains Consultancy рассказом о том, как подготовить себя к новым поворотам в карьере.
Для того, чтобы быть готовым к смене рабочего места, паузе в карьере и другим изменениям в профессиональной жизни, сначала необходимо четко осознать собственный вклад в деятельность компании и начать работать с собственными страхами.
Как бы банально это ни звучало, страх — это нормально. Чтобы его побороть, я предлагаю использовать следующую методику: перед стартом какого-либо поворота в карьере, когда вы не знаете как попасть в заветную точку Б, моделируйте 2 ситуации, которые и заставляют нас сдвинуться с места: самая страшная, самая адская ситуация, которая может с вами произойти на пути к конечной цели, а затем обязательно моделируйте самое желанное, то, что хочется больше всего. В результате, раскручивая свой путь таким образом от конечной точки к начальной вам будет легче осознать, что вас сдерживает, а что двигает вперед.
То же самое и с ошибками. В России и на Западе подход к ошибкам кардинально различается. У нас не принято открыто о них говорить, каждая карьерная история у нас «вычищена» до блеска, в то время как на Западе люди открыто говорят о своих карьерных провалах, поскольку таким образом сразу понятно, что победы не случайны, а являются результатом сделанных выводов и множества попыток.
На следующем этапе необходимо разобраться в себе и ответить на следующие вопросы: «Что я знаю и умею?», «Что для меня важно?», «Куда и зачем я иду?». Истинное знание о себе и об окружающей профессиональной среде работает на адекватную самооценку, уверенность в себе и эффективность. Еще один важный вопрос: «Что может меня остановить?». Это может быть низкая мотивация, отсутствие поддержки, коммуникационная изоляция и другие факторы, которые нужно выявлять и регулировать.
Наконец, когда человек четко осознает кто он, куда хочет попасть и кем стать до карьерного поворота, пора действовать:

Партнером Data Science Week 2017 выступает компания МегаФон, а инфо-партнером — компания Pressfeed.
Pressfeed — Способ бесплатно получать публикации о своей компании. Сервис подписки на запросы журналистов для представителей бизнеса и PR-специалистов. Журналист оставляет запрос, вы отвечаете. Регистрируйтесь. Удачной работы.

Второй день
Сбербанк
Второй день Data Science Week открыл Александр Ульянов — Руководитель разработки моделей в Сбербанке, выпускник 6-го запуска программы “Специалист по большим данным”. Александр рассказал об использовании библиотеки LibFM при построении рекомендательных систем в кабельном и интернет-телевидении. Эта задача является одной из лабораторных работ на программе, и Александр занял первое место по ее результатам.
Сразу же стоит заметить, что эта библиотека применима не только в рекомендательных системах, но и в анализе временных рядов. Интересно, что про нее на русском языке очень мало материалов, хотя благодаря ей было выиграно несколько соревнований на Kaggle.
В данном случае стояла классическая задача рекомендации: есть пользователь, есть фильм, хотим для каждого фильма предсказать его рейтинг для этого пользователя и затем рекомендовать этому пользователю фильмы с максимальным предсказанным рейтингом, либо оценить вероятность покупки того или иного фильма этим пользователем.
Основная проблема построения таких систем — сконструировать пространство признаков таким образом, чтобы в нем уместилось огромное количество информации как о пользователях (личный кабинет, соц. сети), так и о фильмах (жанр, год выпуска, актеры). Решение заключается в представлении каждого события — пользователь поставил оценку фильму — в виде вектора-строки, организованного вот так:

Совместив все векторы, получаем очень сильно разреженную матрицу с более чем 150 000 столбцов, которая и будет пространством признаков, а в качестве целевой переменной примем оценку рейтинга или итоговое событие — купил/не купил фильм:

Теперь перейдем непосредственно к самой модели, которая может быть разделена на 2 части: классическая линейная регрессия и факторное взаимодействие между собой всех множителей, которое, за счет регулирования параметра k, позволяет алгоритму работать с такой sparse-матрицей:

где
. Теперь, когда модель формализована, рассмотрим ее первоначальный вариант с использованием лишь информации об id абонента, id телепередачи и факте ее покупки. В качестве метрики взяли ROC-AUC:fm_train.to_csv('train.libfm', header = None, index = False, sep = ' ')
fm_test.to_csv('test.libfm', header = None, index = False, sep = ' ')
# не забываем очистить данные от кавычек, которые достались в наследство при записи строк в файл:
!sed -i ' s/" //g' train.libfm
!sed -i ' s/" //g' test.libfm
!./libFM -task c -train train,libfm -test test.libfm -method als -dim '1,1,8'
-iter 200 \ -regular ’0,0,15’ -init_stdev 0.1 -out prob9.txtВ результате без использования дополнительных данных о клиентах и телепередачах удалось получить значение ROC-AUC равное 0.923. Добавление информации о фильмах (жанр и год выпуска) позволило увеличить значение метрики до 0.935. Наконец, использовав всю имеющуюся информацию (добавились данные о клиенте: временной интервал просмотра, вживую или в записи), мы получили итоговые 0.936.
Особенности библиотеки:
- Возможность добавлять неограниченное количество «фичей» за счёт работы с форматом sparse-векторов.
- Нелинейная основа алгоритма (когда учитываются не только сами по себе «фичи», но и их взаимодействие между собой).
- Относительно высокая скорость вычислений (O(kn), где n — число «фичей», а k — гиперпараметр модели, который определяет размерность взаимодействующих векторов (порядка 10)).
- Требуется специальная подготовка данных в sparse-формате.
- Обширный набор инструментов оптимизации: от MCMC (Markov chain Monte Carlo) до ALS (Alternating Least Squares).
VISA
Далее Александр Филатов из департамента аналитики Visa в России рассказал о том, как наладить диалог между аналитиками и бизнесом, чтобы последние действительно понимали на основании чего была построена модель и выдвинуты рекомендации.
К примеру, у какого-то банка имеется портфель кредитных карт, прибыль с которого нужно максимизировать. С точки зрения бизнеса есть 3 подхода к этой задачи, каждому из которых можно поставить соответствующую математическую модель:

На этом этапе в дело вступают аналитики, начинают строить модели, тестировать их, получая результат и оформляя отчет, в котором написано, что R-квадрат равен 90%, ROC-AUC равен 0.92 и ROI — 110%, проект окупится менее, чем через год и отправляют отчет бизнесу, который говорит на совершенно другом языке, видит это решение, но не может его распознать. Как правильно донести проблему и ее решение до бизнеса?
Самый простой способ это сделать — сочинить историю и рассказать ее. Здесь можно выделить 3 главных этапа создания истории:
- Описание действующих лиц. Конечно, любая история начинается с представления действующих лиц, поэтому в рамках нашего кейса сначала разделим всех наших клиентов на разные группы: продвинутые пользователи карт (пользователи более чем 3 банков, активные пользователи), международные пользователи (путешественники, иностранные граждане), заемщики (наличие ипотеки, автокредита) и другие.
- Раскрытие характеров. Когда все действующие лица известны, начнем раскрывать характеры персонажей и сравним их по каким-то похожим характеристикам: сколько дохода приносят, как быстро развиваются и т.д. К примеру, в группе активных пользователей карт оказывается доля женщин составляет 80%, и поэтому надо им предлагать женские товары или повышенный cashback. На этом этапе у бизнеса начинает складываться понимание того, с какими клиентами нужно работать и в каком направлении двигаться.
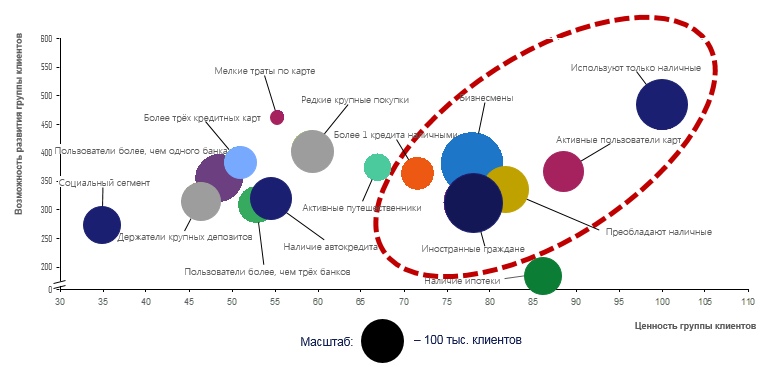
- Анализ влияния персонажей на итоговый результат. Наконец, когда бизнес проникся сутью истории, самое время вспомнить, что мы построили модель, у нас есть прогноз, и мы можем оценить потенциальную прибыль. Проще всего результат модели показать на двумерном графике:

В итоге по модели, видно, что необходимо работать с клиентами, находящимися в правой верхней части, они имеют наибольшую ценность сейчас и принесут еще больше дохода в будущем. После рассказанной истории это видно и бизнесу, который, познакомившись с клиентами и особенностями их поведения, оценив степень влияния каждого из них на финансовый результат компании, гораздо легче воспринимает модели и рекомендации аналитиков.
Riftman
Андрей Манолов из Riftman рассказал о проекте по применению Apache Spark для анализа информации в Bitcoin. Главная проблема заключалась в том, что в биткоине напрямую не хранится информация об отправителях и получателях переводов и о том, какой у них баланс кошелька. У каждой транзакции в биткоине есть выходы, обладающие значениями, показывающими сколько монет было отправлено в пользу кого-то другого, и входы, значениями не обладающими: в них записана лишь ссылка на предыдущую транзакцию и номер выхода.
Таким образом, чтобы получить необходимую информацию мы подняли биткоин-ноду на хостинге в объединенной сети и настроили так, что все данные загружались в кластер Apache Spark, и там проводилась следующая обратная операция: мы раскручиваем весь процесс в обратную сторону, двигаясь от выходов со значениями транзакций к входам со ссылками на предыдущие транзакции, затем обратно к выходам и так далее, пока не поймем, какому адресу какое количество биткоинов принадлежит. Таким образом, было сделано 3 job-а на Spark-е: выгрузка всех интересующих нас транзакций (в нашем случае out > 10 BTC), Broadcast join и Self join. В итоге получаем 3 таблицы данных в удобном для анализа формате.
Возможные области применения и развития решения:
- Генерация торговых сигналов для трейдинга. С помощью нашего проекта можно выявлять массовые поступления денег на биржу — событие, которое положительно коррелирует с увеличением курса биткоина (растет спрос на криптовалюту при неизменном предложении), что может быть использовано в трейдинге.
- Отслеживание происхождения средств на легализуемом кошельке. Также данное решение может помочь в вопросе легализации кошельков, поскольку сегодня биткоин нередко используется в качестве платежного средства для нелегальных целей. К примеру, зная источник средств на интересующем нас кошельке и имея реестр «плохих» кошельков, можно посчитать на графе расстояние от легализуемого до «плохого»:

Если рассматриваемый кошелек находится в 1-2 «шагах» от «плохого», то скорее всего он каким-то образом связан с нелегальными сделками и не может быть легализован.
RnD Lab
Второй день завершил Кирилл Данилюк — Data Scientist в RnD Lab со своим пайплайном использования Deep Learning для распознавания дорожных знаков, о котором мы вам рассказывали тут, тут и тут.
Третий день
BSSL
Третий день DSW начался с Александра Ларионова — CEO компании BSSL, которая занимается бизнес-социометрией по методике “Азимут” — системой оценки сотрудников, применяемой для анализа взаимодействий и компетенций сотрудников в организации.
Перед тем, как приступить непосредственно к анализу, необходимо собрать данные посредством опроса. Сотрудники компании отвечают на вопросы о рабочих отношениях внутри коллектива: кто из коллег за последние полгода вносил вклад в задачи, над которыми вы работали? Чье внимание, содействие или помощь были вам необходимы?
Затем на основании этих данных строятся ряд методик:
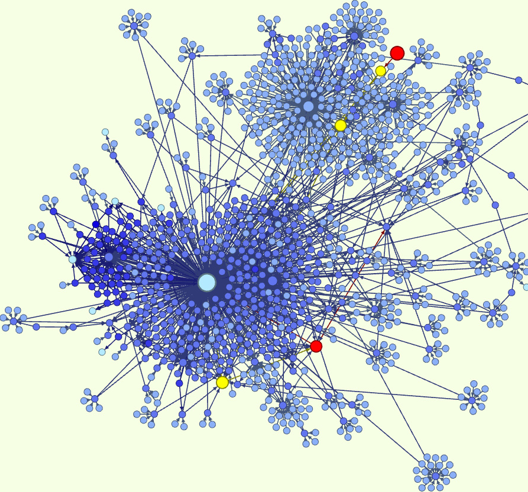
- Социальная сеть и индекс цитирования. Для измерения востребованности каждого сотрудника мы можем построить социальный граф, где будет ярко видно, кто «нужен» большему числу людей, то есть человек с наибольшим количеством входящих стрелок и будет наиболее востребованным в коллективе. Альтернативной метрикой востребованности может стать Page Rank (PR), который используется Google для ранжирования страниц. Логика алгоритма такова, что если на мою страницу ссылается другая цитируемая страница, то мой PR растет быстрее, чем если бы на нее ссылалось множество нецитируемых страниц. Для примера рассмотрим граф ниже:
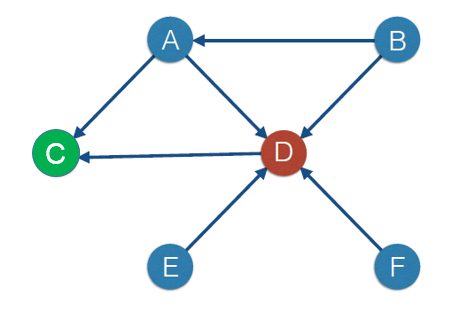
С одной стороны, наибольшая доля коллектива «нуждается» в сотруднике D, но если посмотреть на это с точки зрения Page Rank, то именно сотрудник C, а не D является наиболее востребованным, поскольку к нему часто обращается человек, к которому в свою очередь обращается много людей.
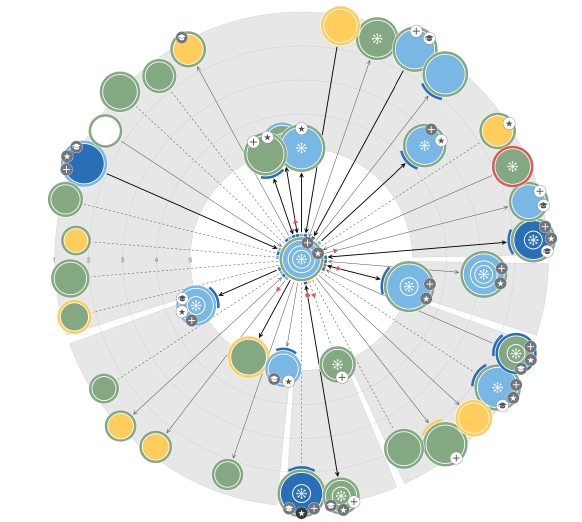
- Эгоцентрическая сеть. Очевидно, что социальные графы хорошо подходят для малого количества участников — 10, 20, но когда их число намного больше изобразить все связи невозможно. Есть альтернатива в виде эгоцентрической сети — способа визуализации взаимоотношений одного конкретного человека с коллегами, где близость кружка к центру означает интенсивность взаимодействия с «центром», размер кружка — востребованность и так далее (всего около 10 параметров).


Матрица совместимости. Помимо того, насколько здоровые отношения в коллективе, нам бы хотелось узнать о взаимозаменяемости сотрудников (на случай болезни, отпуска и т.д). Для этого используется множество метрик: софт-скиллс заменяющего, знакомство с кругом задач, позитивные отношения с кругом взаимодействия заменяемого и им самим. Также, если человек систематически выбирает кого-то на «отрицательные вопросы» («был недоступен», «занят»), то скорее всего он к нему относится не очень хорошо и наоборот. Затем по ответам сотрудников строится матрица совместимости, где по строкам и столбцам отмечены сотрудники, а на пересечении — коэффициенты корреляции их ответов, умноженные на 1000:

Как видно по матрице, например, Уильям имеет отличные отношения с Сильвией и Алисой, но не с Джоном.
Далее была панельная дискуссия по теме «Подбор команд по работе с данными и оценка их эффективности». Модератором выступила Ольга Филатова, вице-президент по персоналу и образовательным проектам Mail.ru Group, а участниками были Виктор Кантор (Яндекс), Андрей Уваров (МегаФон), Павел Клеменков (Rambler&Co), Александр Ерофеев (Сбербанк). Об этой часовой сессии мы напишем отдельно, потому что рассказать там есть о чем.
Buran HR
Продолжила разговор о работе в команде Анаит Антонян, CEO компании Buran HR, занимающейся подбором людей для создания стартап-команд. Она рассказала о том, как молодому IT специалисту выбрать между работой в стартапе и крупной корпорации, и кто в итоге удовлетворен своим выбором.
“По многолетнему опыту работы в области HR, я могу сказать, что существуют компетенции, которые больше подходят для работы в стартапе, которые при этом могут осложнить работу в крупной компании:

При этом, если говорить об удовлетворенности своим выбором, то здесь ситуация такая, что молодой (до 27 лет) стартапер в среднем на 40% более доволен своей работой, чем корпоративный сотрудник того же возраста, при этом для людей старше 32 лет ситуация противоположная: взрослый «корпорат» в среднем на 36% более доволен.
Рассматривая не IT отрасль в целом, а Data Science, можно заметить, что специалисты в этой области чувствуют себя более счастливыми чем другие разработчики”:

Best Brains Consultancy
Завершала насыщенный третий день и всю конференцию Наталья Тихомирова — executive-коуч и руководитель направления компании BestBrains Consultancy рассказом о том, как подготовить себя к новым поворотам в карьере.
Для того, чтобы быть готовым к смене рабочего места, паузе в карьере и другим изменениям в профессиональной жизни, сначала необходимо четко осознать собственный вклад в деятельность компании и начать работать с собственными страхами.
Как бы банально это ни звучало, страх — это нормально. Чтобы его побороть, я предлагаю использовать следующую методику: перед стартом какого-либо поворота в карьере, когда вы не знаете как попасть в заветную точку Б, моделируйте 2 ситуации, которые и заставляют нас сдвинуться с места: самая страшная, самая адская ситуация, которая может с вами произойти на пути к конечной цели, а затем обязательно моделируйте самое желанное, то, что хочется больше всего. В результате, раскручивая свой путь таким образом от конечной точки к начальной вам будет легче осознать, что вас сдерживает, а что двигает вперед.
То же самое и с ошибками. В России и на Западе подход к ошибкам кардинально различается. У нас не принято открыто о них говорить, каждая карьерная история у нас «вычищена» до блеска, в то время как на Западе люди открыто говорят о своих карьерных провалах, поскольку таким образом сразу понятно, что победы не случайны, а являются результатом сделанных выводов и множества попыток.
На следующем этапе необходимо разобраться в себе и ответить на следующие вопросы: «Что я знаю и умею?», «Что для меня важно?», «Куда и зачем я иду?». Истинное знание о себе и об окружающей профессиональной среде работает на адекватную самооценку, уверенность в себе и эффективность. Еще один важный вопрос: «Что может меня остановить?». Это может быть низкая мотивация, отсутствие поддержки, коммуникационная изоляция и другие факторы, которые нужно выявлять и регулировать.
Наконец, когда человек четко осознает кто он, куда хочет попасть и кем стать до карьерного поворота, пора действовать:

Партнером Data Science Week 2017 выступает компания МегаФон, а инфо-партнером — компания Pressfeed.
Pressfeed — Способ бесплатно получать публикации о своей компании. Сервис подписки на запросы журналистов для представителей бизнеса и PR-специалистов. Журналист оставляет запрос, вы отвечаете. Регистрируйтесь. Удачной работы.
