 От переводчика: Это первая статья из цикла о Node.js от команды Mozilla Identity, которая занимается проектом Persona. Как клиентская, так и серверная часть Persona написаны на JavaScript. В ходе работы команда проекта создала несколько инструментов на все случаи жизни — от локализации до отладки, управления зависимостями и многого другого. В этой серии статей разработчики Mozilla делятся с сообществом своим опытом и этими инструментами, которые пригодятся любому, кто пишет высоконагруженный сервис на Node.js.
От переводчика: Это первая статья из цикла о Node.js от команды Mozilla Identity, которая занимается проектом Persona. Как клиентская, так и серверная часть Persona написаны на JavaScript. В ходе работы команда проекта создала несколько инструментов на все случаи жизни — от локализации до отладки, управления зависимостями и многого другого. В этой серии статей разработчики Mozilla делятся с сообществом своим опытом и этими инструментами, которые пригодятся любому, кто пишет высоконагруженный сервис на Node.js.Первая статья цикла посвящена распространённой проблеме Node.js — утечкам памяти, особенностям утечек в высоконагруженных проектах и библиотеке node-memwatch, которая помогает найти и устранить такие утечки в Node.
Все статьи цикла:
- "Охотимся за утечками памяти в Node.js"
- "Нагружаем Node под завязку"
- "Храним сессии на клиенте, чтобы упростить масштабирование приложения"
- "Производительность фронтэнда. Часть 1 — конкатенация, компрессия, кэширование"
- "Пишем сервер, который не падает под нагрузкой"
- "Производительность фронтэнда. Часть 2 — кешируем динамический контент с помощью etagify"
- "Приручаем конфигурации веб-приложений с помощью node-convict"
- "Производительность фронтенда. Часть 3 — оптимизация шрифтов"
- "Локализация приложений Node.js. Часть 1"
- "Локализация приложений Node.js. Часть 2: инструментарий и процесс"
- "Локализация приложений Node.js. Часть 3: локализация в действии"
- "Awsbox — PaaS-инфраструктура для развёртывания приложений Node.js в облаке Amazon"
Зачем заморачиваться?
Вы можете спросить, зачем вообще отслеживать утечки памяти? Неужели нет более важных дел? Почему бы просто не перезапускать процесс время от времени, или просто добавить памяти на сервер? Есть три причины, по которым устранять утечки всё-таки важно:
- Возможно, вы не сильно переживаете об утечках памяти, но этого нельзя сказать о V8 (движок JavaScript на котором работает Node). Чем больше памяти занято, тем активнее работает сборщик мусора, замедляя ваше приложение. Так что в Node утечки напрямую вредят производительности.
- Утечки могут привести к другим проблемам. Протекающий код может блокировать ограниченные ресурсы. У вас могут закончиться файловые дескрипторы или вы вдруг не сможете открыть ещё одно соединение с БД. Такие проблемы могут возникнуть задолго до того, как кончится память, но обрушат ваше приложение ничуть не хуже.
- Рано или поздно ваше приложение упадёт. И это наверняка случится во время наплыва посетителей. Вас все засмеют и будут писать про вас гадости на Hacker News.
Откуда доносится звук падающих капель?
В сложном приложении есть много мест, где могут возникать утечки. Наверное, самое известное и наболевшее место — замыкания. Так как замыкания могут долго хранить ссылки на переменные из их области видимости, они становятся самым частым местом протечки.
Некоторые утечки можно рано или поздно обнаружить, просто поискав их в коде, но в асинхронном мире Node мы постоянно создаём множество замыканий в виде колбэков. И если они отрабатывают медленнее, чем создаются, фрагменты памяти каждого колбэка нагромождаются так, что код, который вовсе не выглядит текущим, ведёт себя как текущий. Такие утечки отследить гораздо труднее.
Приложение также может течь из-за ошибки в чужом коде, от которого оно зависит. Иногда вы можете найти место у себя в программе, вызывающее утечку, но бывает так, что вам остаётся только растерянно глядеть на свой идеально отлаженный код, недоумевая, как вообще он может течь?
Именно такие, трудные для отслеживания, утечки создали потребность в node-memwatch. Легенда гласит, что давным-давно, несколько месяцев назад, наш программист Ллойд Хилайель заперся в чулане на два дня, пытаясь выследить утечку, которая проявлялась только под очень большой нагрузкой (кстати, он автор следующей статьи в этой серии, посвящённой как раз нагрузочному тестированию).
Через два дня поисков он обнаружил, что искомая ошибка была в ядре Node: обработчики событий в
http.ClientRequest не освобождали память как следует (патч для исправления этой ошибки добавлял всего два маленьких, но очень важных символа в код Node.js). Перенесённые мучения заставили Ллойда написать инструмент, который помогал бы искать подобные утечки.Инструменты для поиска утечек
Для поиска утечек в приложениях Node.js уже есть хорошая и постоянно растущая подборка инструментов. Вот некоторые из них:
- node-mtrace Джимба Эссера, которая использует утилиту GCC mtrace для профилирования использования кучи;
- node-heap-dump Дэйва Пачеко, который делает снимок кучи V8 и записывает его в огромный файл JSON. Включает в себя инструменты для исследования и разбора этого снимка средствами JavaScript;
- v8-profiler и node-inspector Дэнни Коутса, основанные на профилировщике V8 и отладчике WebKit Web Inspector;
- руководство по утечкам памяти в Node Феликса Гайзендорфера, которое коротко и ясно рассказывает об основах работы с v8-profiler и node-inspector;
- платформа Joyent SmartOS, которая предоставляет целый арсенал инструментов для поиска и устранения утечек в Node.js.
Нам нравятся эти и многие другие инструменты, но ни один из них не подходил идеально для нашего окружения. Web Inspector великолепен для приложений в разработке, но труден в использовании на боевом, работающем приложении, особенно когда используется много серверов и процессов. Поэтому с его помощью трудно ловить ошибки, которые проявляются не сразу и только под большой нагрузкой. Такие инструменты, как dtrace или libumem тоже прекрасны, но не работают во всех ОС.
Встречайте: node-memwatch
Нам нужна была кроссплатформенная библиотека для отладки, не требующая никаких дополнительных инструментов, с помощью которой мы могли бы находить места и причины утечек памяти. И поэтому мы написали node-memwatch.
Он предоставляет три вещи:
- Событие
'leak'
memwatch.on('leak', function(info) { // Взглянуть на info, и выяснить, есть ли утечка });
- Событие
'stats'
var memwatch = require('memwatch'); memwatch.on('stats', function(stats) { // изучить статистику использования памяти после сборки мусора });
- Класс, отслеживающий diff кучи:
var hd = new memwatch.HeapDiff(); // код приложения ... var diff = hd.end();
Кроме того, есть функция для принудительного вызова сборщика мусора, что может оказаться полезным при тестировании. То есть всё-таки четыре вещи, а не три.
var stats = memwatch.gc();
memwatch.on('stats', ...): статистика кучи после сборки мусора
node-memwatch может выдавать статистику использования кучи непосредственно после окончания работы сборщика мусора, до того, как выделяется память любым новым объектам. Для этого используется хук
V8::AddGCEpilogueCallback. В статистику включены поля:
- usage_trend
- current_base
- estimated_base
- num_full_gc
- num_inc_gc
- heap_compactions
- min
- max
Вот пример, который показывает, как выглядит изменение статистики использования памяти у подтекающего приложения. Зигзагообразная зелёная линия показывает использование памяти по данным
process.memoryUsage(), а красная — значение current_base из статистики node-memwatch. Внизу слева приведены дополнительные данные. 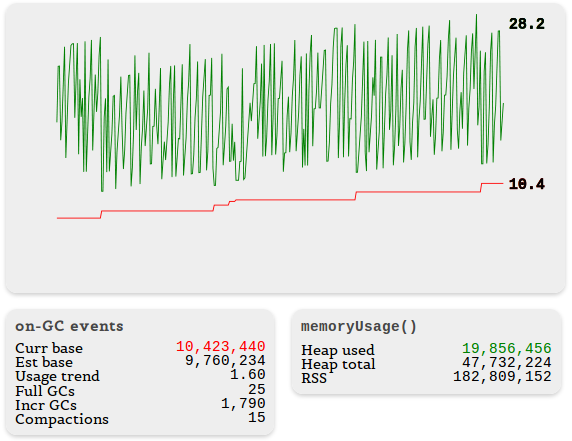
Обратите внимание, как часто происходит инкрементальная сборка мусора. Это тревожный знак, указывающий на то, что V8 приходится попотеть, вычищая память.
memwatch.on('leak', ...): динамика использования памяти
Мы используем простую эвристику чтобы предупредить о возможном появлении утечки. Если после пяти сборок мусора подряд использование памяти растёт, срабатывает событие 'leak'. Информация о возможной утечке выводится в удобной читабельной форме:
{ start: Fri, 29 Jun 2012 14:12:13 GMT,
end: Fri, 29 Jun 2012 14:12:33 GMT,
growth: 67984,
reason: 'heap growth over 5 consecutive GCs (20s) - 11.67 mb/hr' }
memwatch.HeapDiff(): находим утечки
Наконец, node-memwatch умеет сравнивать снимки кучи, включающие имена количество объектов, занимающих память. Diff помогает найти нарушителей.
var hd = new memwatch.HeapDiff();
// Код приложения ...
var diff = hd.end();
Содержимое объекта
diff выглядит так:{
"before": {
"nodes": 11625,
"size_bytes": 1869904,
"size": "1.78 mb"
},
"after": {
"nodes": 21435,
"size_bytes": 2119136,
"size": "2.02 mb"
},
"change": {
"size_bytes": 249232,
"size": "243.39 kb",
"freed_nodes": 197,
"allocated_nodes": 10007,
"details": [
{
"what": "Array",
"size_bytes": 66688,
"size": "65.13 kb",
"+": 4,
"-": 78
},
{
"what": "Code",
"size_bytes": -55296,
"size": "-54 kb",
"+": 1,
"-": 57
},
{
"what": "LeakingClass",
"size_bytes": 239952,
"size": "234.33 kb",
"+": 9998,
"-": 0
},
{
"what": "String",
"size_bytes": -2120,
"size": "-2.07 kb",
"+": 3,
"-": 62
}
]
}
}
HeapDiff вызывает сборщик мусора перед тем, как собирать статистику, чтобы в данных не было слишком много ненужной чепухи. При этом событие 'stats' не возникает, так что вы можете спокойно вызывать HeapDiff внутри обработчика 'stats'. Вот пример статистики, в которую мы добавили перечень объектов, занимающих больше всего места в куче
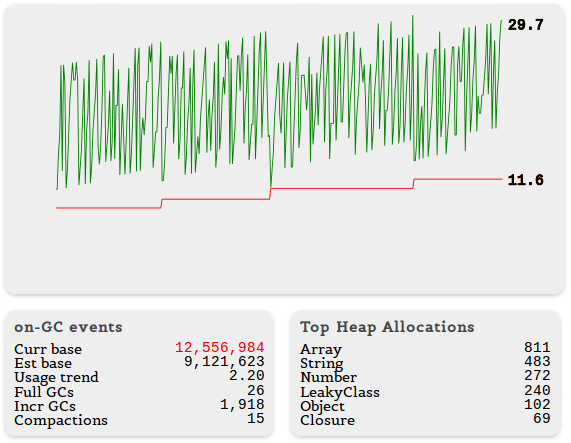
Что дальше?
Возможности node-memwatch:
- точное отслеживание использования памяти;
- уведомления о возможных утечках;
- средства для получения diff'а кучи;
- кроссплатформенность;
- отсутствие зависимостей от других инструментов.
Мы хотим большего. В частности, хотим, чтобы node-memwatch умел приводить конкретные данные протекающих объектов — имена переменных, индексы массивов, куски кода замыканий.
Мы надеемся, что node-memwatch будет полезен вам при отладке подтекающих приложений Node.js, вы форкнете его и примете участие в его улучшении.
Все статьи цикла:
- "Охотимся за утечками памяти в Node.js"
- "Нагружаем Node под завязку"
- "Храним сессии на клиенте, чтобы упростить масштабирование приложения"
- "Производительность фронтэнда. Часть 1 — конкатенация, компрессия, кэширование"
- "Пишем сервер, который не падает под нагрузкой"
- "Производительность фронтэнда. Часть 2 — кешируем динамический контент с помощью etagify"
- "Приручаем конфигурации веб-приложений с помощью node-convict"
- "Производительность фронтенда. Часть 3 — оптимизация шрифтов"
- "Локализация приложений Node.js. Часть 1"
- "Локализация приложений Node.js. Часть 2: инструментарий и процесс"
- "Локализация приложений Node.js. Часть 3: локализация в действии"
- "Awsbox — PaaS-инфраструктура для развёртывания приложений Node.js в облаке Amazon"
