

Мы в Одноклассниках занимаемся поиском узких мест в инфраструктуре, состоящей более чем из 10 тысяч серверов. Когда мы слегка задолбались мониторить 5000 серверов вручную, нам понадобилось автоматизированное решение.
Точнее, не так. Когда в седой древности появился примерно 20-й сервер, стали использовать Big Brother — простейший мониторинг, который просто собирает статистику и показывает её в виде мелких картинок. Всё очень, очень просто. Ни приблизить, ни как-то ввести диапазоны допустимых изменений нельзя. Только смотреть картинки. Вот такие:
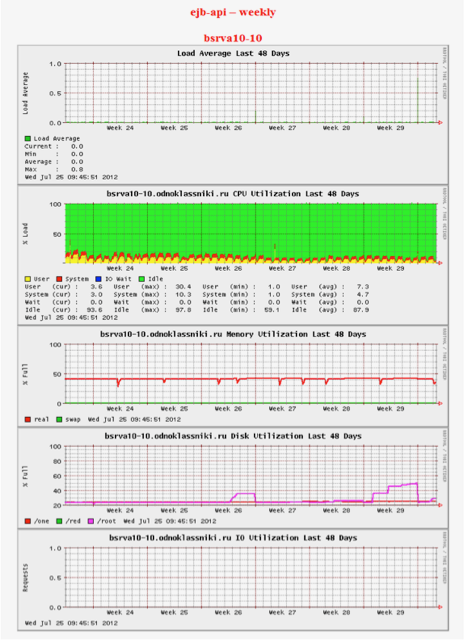
Два инженера тратили по одному рабочему дню в неделю, просто отсматривая их и ставя тикеты там, где график показался «не таким». Понимаю, звучит реально странно, но началось это с нескольких машин, и потом как-то неожиданно доросло до 5000 инстансов.
Поэтому мы сделали новую систему мониторинга — и сейчас на работу с 10 тысячами серверов тратим по 1-2 часа в неделю на обработку алертов. Расскажу, как это устроено.
Почему это надо
Инцидент-менеджмент у нас был поставлен задолго до начала работ. В «железной» части серверы работали штатно и хорошо обслуживались. Сложности были с предсказанием узких мест и выявлением нетипичных ошибок. В 2013 году сбой в Одноклассниках привёл к тому, что сайт был недоступен в течение нескольких дней, о чём мы уже писали. Мы извлекли из этого уроки, и уделили очень много внимания именно предотвращению инцидентов.
С ростом числа серверов стало важно не только эффективно управлять всеми ресурсами, мониторить и учитывать их, но и оперативно фиксировать опасные тенденции, которые могут привести к появлению узких мест в инфраструктуре сайта. А также предотвращать эскалацию обнаруженных проблем. Именно о том, как мы анализируем и прогнозируем состояние своих IT-ресурсов, и пойдёт речь.
Немного статистики
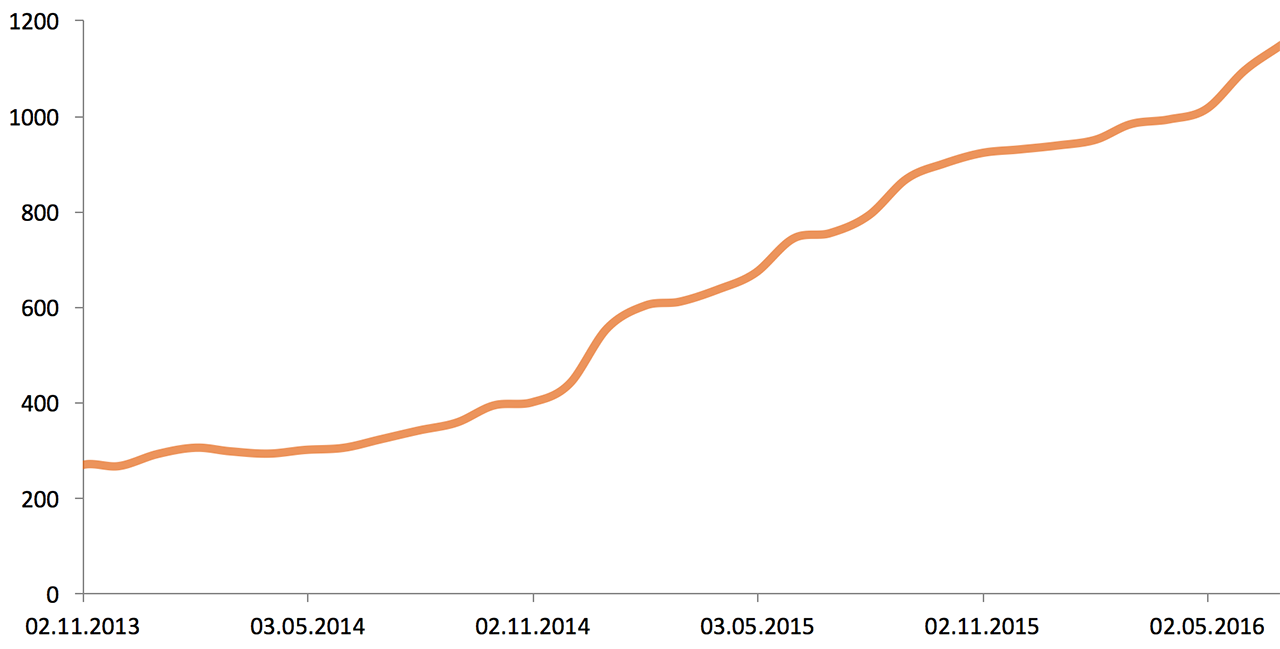
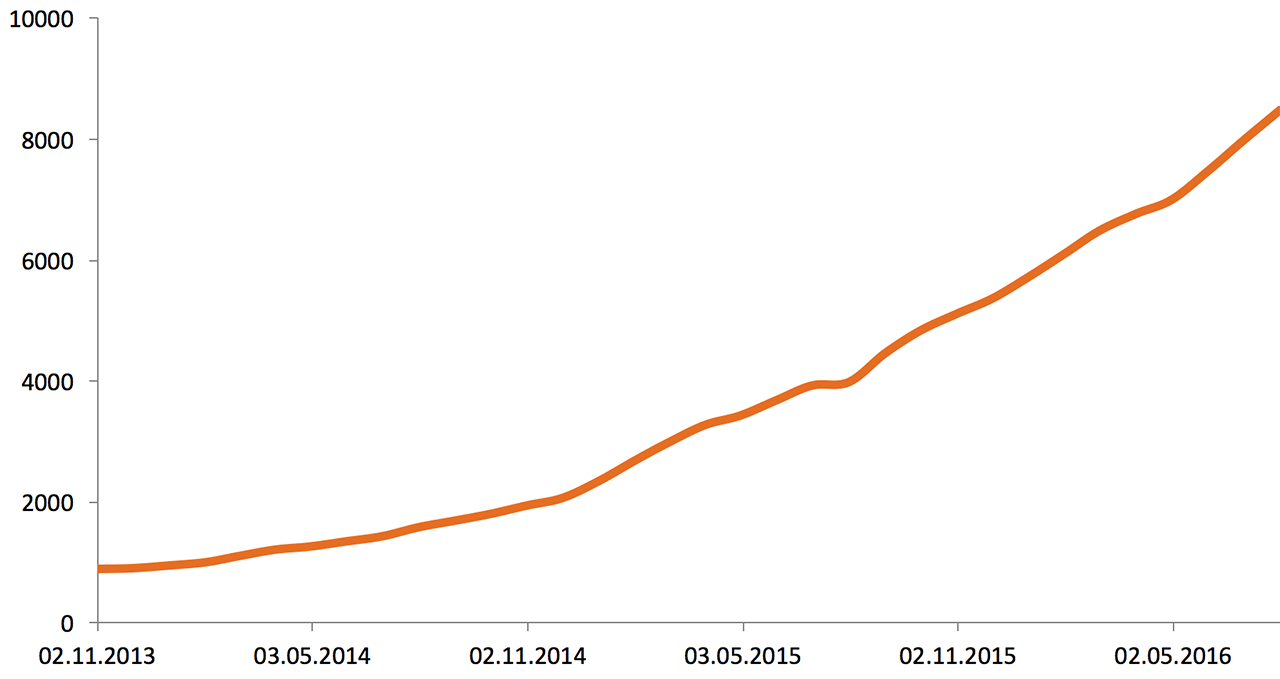
В начале 2013 года инфраструктура Одноклассников состояла из 5000 серверов и систем хранения данных. Вот рост за два с половиной года:
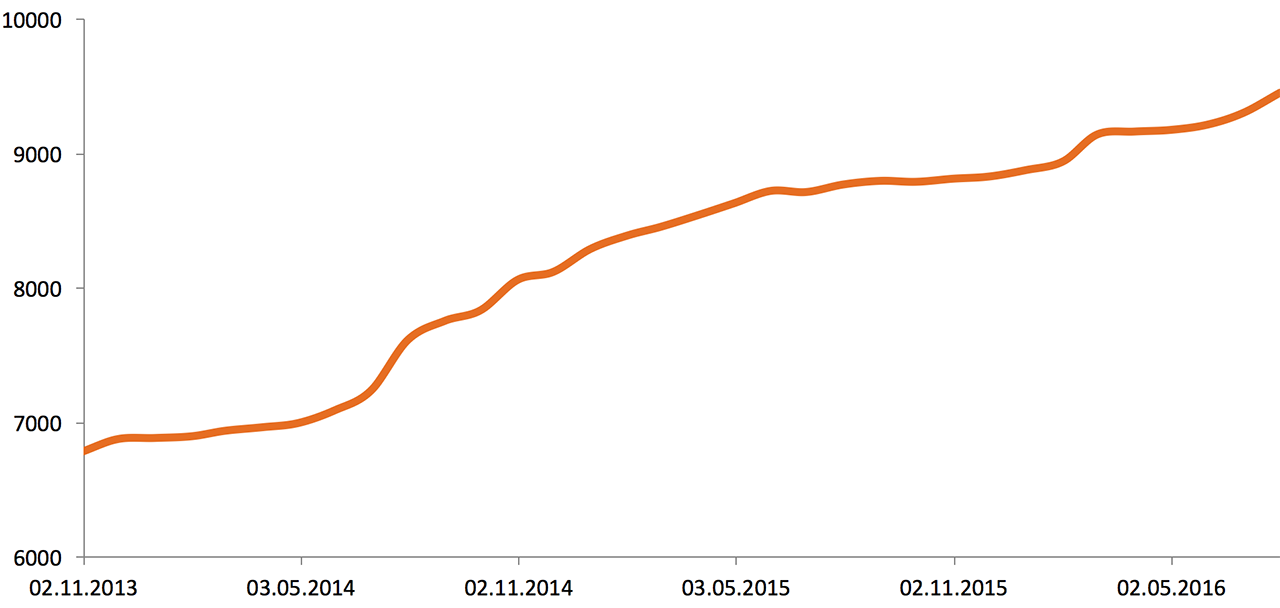
Объём внешнего сетевого трафика (2013—2016), Gbit/s:
Объём хранимых данных (2013—2016), Tb:
Показатели работы приложений, оборудования и бизнес-метрик отслеживаются командой мониторинга в режиме 24/7. В связи с тем, что и без того большая инфраструктура продолжает активно расти, решение проблем с узкими местами в ней может занять существенное время. Именно поэтому одного оперативного мониторинга недостаточно. Чтобы разобраться с неприятностями максимально быстро, требуется прогнозировать рост нагрузки. Это делается следующим образом: команда мониторинга раз в неделю запускает автоматическую проверку операционных показателей всех серверов, массивов и сетевых устройств, по итогам которой получает список всех возможных проблем с оборудованием. Список передаётся системным администраторам и сетевым специалистам.
Что мониторится
На всех серверах и их массивах мы проверяем следующие параметры:
- общую нагрузку на процессор, а также нагрузку на отдельно взятое ядро;
- утилизацию диска (I/O Utilization) и дисковую очередь (I/O Queue). Система автоматически определяет SSD/HDD, так как лимиты на них разные;
- свободное место на каждом дисковом разделе;
- утилизацию памяти, так как разные сервисы используют память по-разному. Есть несколько формул, которые высчитывают использованную/свободную память для каждой серверной группы, учитывая специфику задач, которые надо решать на конкретной группе (формула по дефолту: Free + Buffers + Cached + SReclaimable — Shmem);
- использование swap и tmpfs;
- Load Average;
- трафик на сетевых интерфейсах сервера;
- GC Count, Full GC Count и GC Time (речь о Java Garbage Collection).
На центральных свитчах (core) и маршрутизаторах проверяется использование памяти, нагрузка на процессор и, естественно, трафик. На коммутаторах уровня доступа трафик access-портов не мониторим, так как его мы проверяем непосредственно на уровне сетевых интерфейсов серверов.
Аналитика
Данные собираются со всех хостов при помощи SNMP и затем аккумулируются в систему DWH (Data Warehouse). О DWH мы рассказывали на Хабре ранее — в статье BI в Одноклассниках: сбор данных и их доставка до DWH. В каждом ЦОД стоят свои серверы для сбора этой статистики. Статистика с устройств собирается ежеминутно. Данные выгружаются в DWH каждые 90 минут. Каждый ЦОД генерирует свой комплект данных, их объём — 300—800 Mb за выгрузку, а это 300 Гб в неделю. Данные не аппроксимируются, поэтому есть возможность узнать точное время начала проблемы, что помогает найти её причину.
Все серверы в зависимости от своей роли в инфраструктуре разбиты на группы, на которые навешиваются thresholds (лимиты). После превышения лимита устройство попадёт в отчет. Группировка всех хостов происходит в специально разработанной для этого системе Service Catalog. Так как лимиты навешиваются на группу серверов, то новые серверы в группе автоматически начинают мониториться по таким же лимитам. Если администратор создал новую группу, тогда на неё автоматически навешиваются жёсткие лимиты, и если серверы новой группы попадают в проверку, то принимается решение, нормально это или нет. Если программисты считают, что это нормальное поведение для группы серверов, лимит поднимается. Для удобного управления лимитами создана панель управления, которая выглядит так:
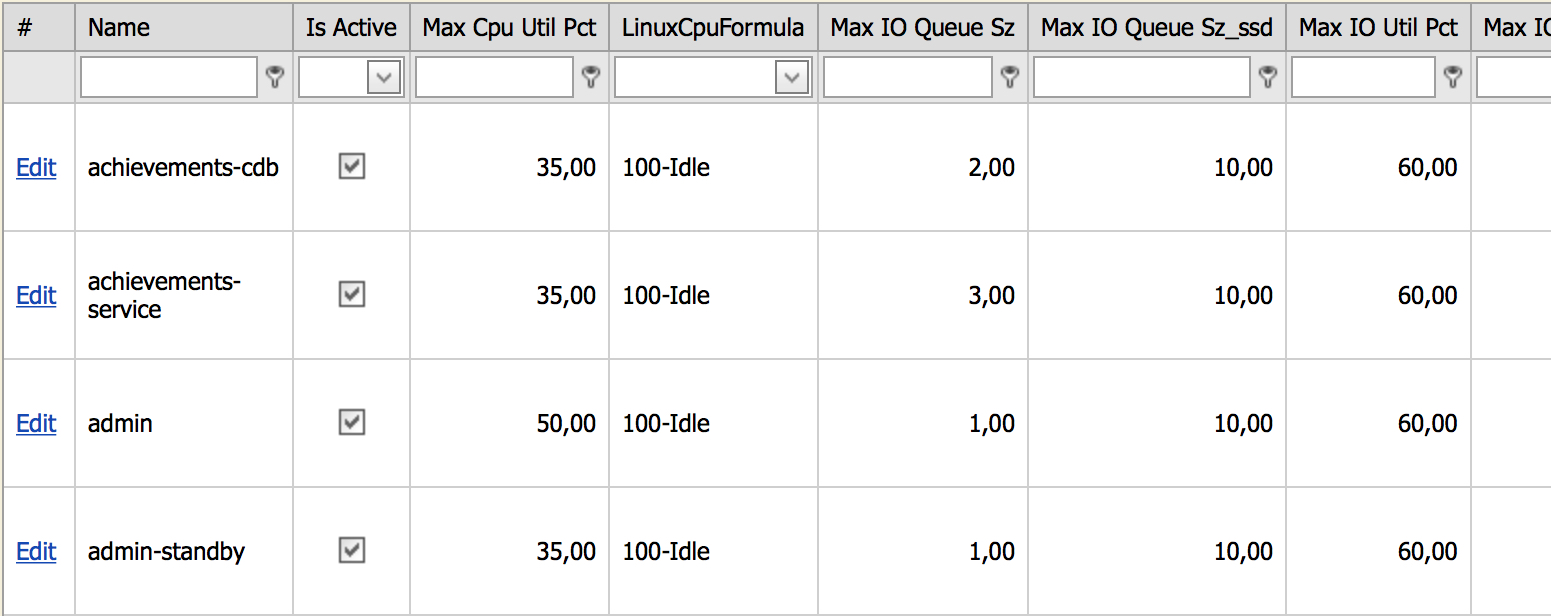
В этой админке можно увидеть все уникальные группы серверов и их лимиты. Например, на скриншоте видны лимиты для группы achievements-cdb:
- максимальная нагрузка на процессор не должна превышать 35 %;
- формула для расчета нагрузки на процессор 100 % — idle;
- лимит на дисковую очередь для HDD-дисков — 2, для SSD — 10.
И так далее. Поправить какой-либо лимит можно, только ссылаясь на задачу, в которой описаны причины изменения. Окно изменения лимита:
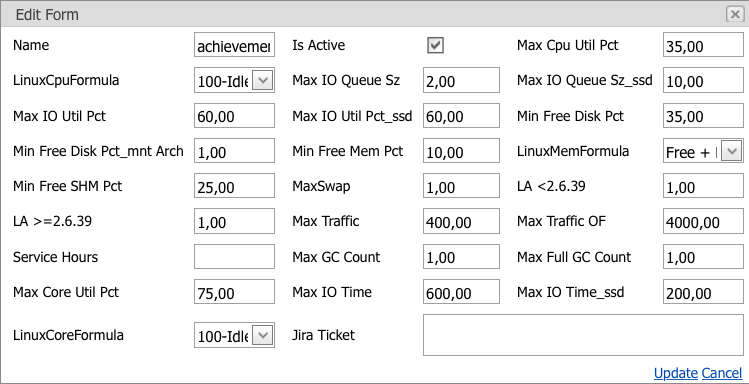
На скриншоте перечислены все текущие лимиты для группы серверов с возможностью их изменения. Применить изменения можно только в том случае, если заполнено поле «Jira Ticket»; в него записывается задача, в рамках которой решалась проблема.
Ночью, когда нагрузка на серверы значительно ниже, выполняются различные служебные и расчетные задачи, создающие дополнительную нагрузку, но они никак не влияют на пользователей или функционал портала, поэтому такие срабатывания мы считаем ложными, и для борьбы с ними был введен дополнительный параметр — сервисное окно. Сервисное окно — это интервал времени, в котором возможно превышение лимита, что не считается проблемой и в отчёт не попадает. Также к ложным срабатываниям относятся кратковременные скачки. Сетевая и серверная проверки разделены, так как серверные и сетевые проблемы решают разные отделы.
Что происходит с отчётом
Отчёт собирается по средам в один клик. Затем один из пяти «дневных» инженеров снимается с обычного «патрулирования» ресурса и работы по управлению тикетами, и начинает читать отчёт. Проверка занимает не более полутора часов. В отчёте — список всех возможных проблем в инфраструктуре, как новых, так и старых, которые ещё не решены. Каждая проблема может стать алертом админу, а сисадмин уже решает — сразу поправить или завести тикет.
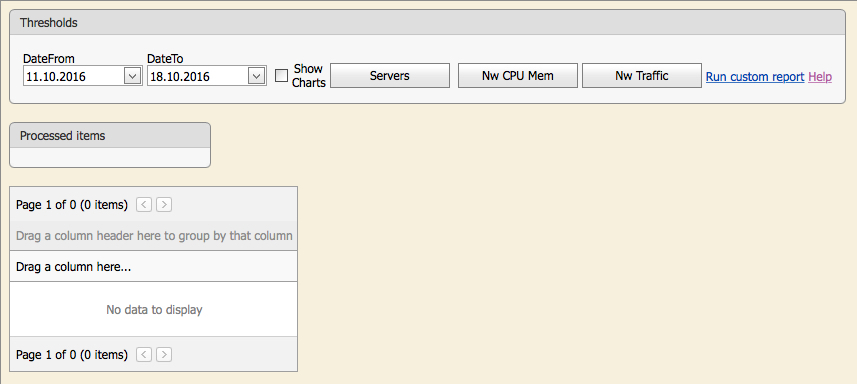
На картинке показано начальное окно проверки. Пользователь может кликнуть на соответствующую кнопку и запустить автоматическую проверку: «Servers» — всех серверов, «Nw CPU Mem» — использования памяти и процессора на сетевых устройствах, «Nw Traffic» — трафика на центральных свитчах (core) и маршрутизаторах.
Система интегрирована с JIRA (система управления задачами). Если проблема (превышен лимит) уже решается, напротив неё находится линк на тикет, в рамках которого ведётся работа над проблемой или которым она вызвана со статусом тикета. Так мы видим, в рамках какой задачи проблема решалась ранее — т.е. будет тикет со статусом Resolve.
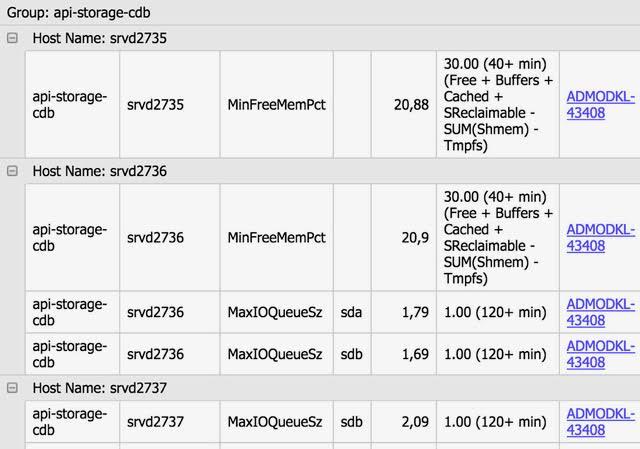
Все новые проблемы передаются старшим системным администраторам и старшим сетевым специалистам, которые создают тикеты в JIRA для решения каждой проблемы в отдельности, затем эти тикеты линкуются к соответствующим проблемам. У системного администратора есть возможность запустить специальную проверку по любому параметру, достаточно указать группу(-ы) серверов, параметр и лимит, а система сама выдаст все серверы, которые превысили лимит. Также можно посмотреть график по любому параметру любого сервера с линией лимита.
Пример попадания сервера на радары:
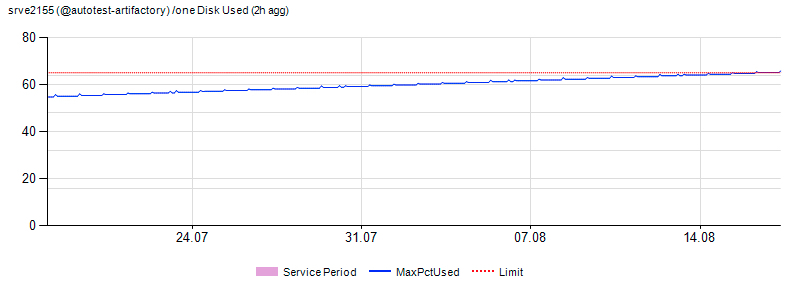
Для самых больших групп серверов (web — front end, уровень бизнес-логики и кеш данных пользователей) помимо обычной проверки производится долгосрочный прогноз, так как для решения проблем с этими группами необходимы значительные ресурсы (оборудование, время).
Долгосрочный прогноз также делает команда мониторинга, на это тратится около пяти минут. В отчёте, генерируемом системой, специалист по мониторингу видит графики основных показателей по подгруппам и в целом по группе с прогнозом на будущее, и если в течение двух-трёх месяцев будет превышен установленный лимит, то в этом случае также создаётся тикет на решение проблемы. Вот пример того, как выглядит прогноз:
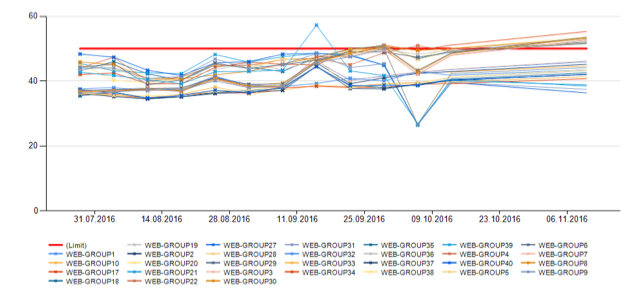
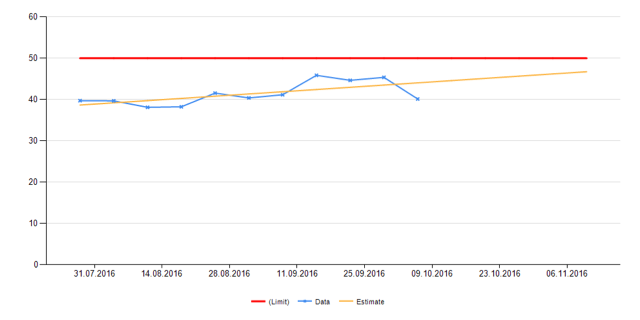
На первой картинке мы видим использование CPU всех групп web-серверов в отдельности, на второй — общее. Красной линией обозначен лимит. Жёлтая — прогноз.
Прогноз строится на основе достаточно простых алгоритмов. Вот пример алгоритма предсказания по нагрузке на CPU.
Для каждой группы серверов с шагом в семь дней строим точки по следующей формуле (пример для группы front end):
∑(n — max load — min load)/(n — 2), где:
- n — кол-во серверов в группе;
- max load — максимальное значение нагрузки, которое продержалось более 30 минут на каждом сервере в отдельности за всю неделю. Складываем все значения нагрузок по группе серверов;
- min load — минимальное значение нагрузки, вычисляется аналогично максимальному.
Для получения более точного прогноза убираем один сервер с максимальной нагрузкой и один с минимальной. Этот алгоритм может показаться простым, однако он весьма близок к реалиям, и именно поэтому изобретать сложный анализ не имеет смысла. Таким образом для каждой группы серверов мы получим еженедельные точки, по которым строится аппроксимированная линейная функция.
На полученном графике можно увидеть предположительную дату, когда потребуется расширение или апгрейд группы. Аналогично предсказывается и дата, когда закончится место в больших кластерах. Проверяются кластеры фото, видео и музыки:
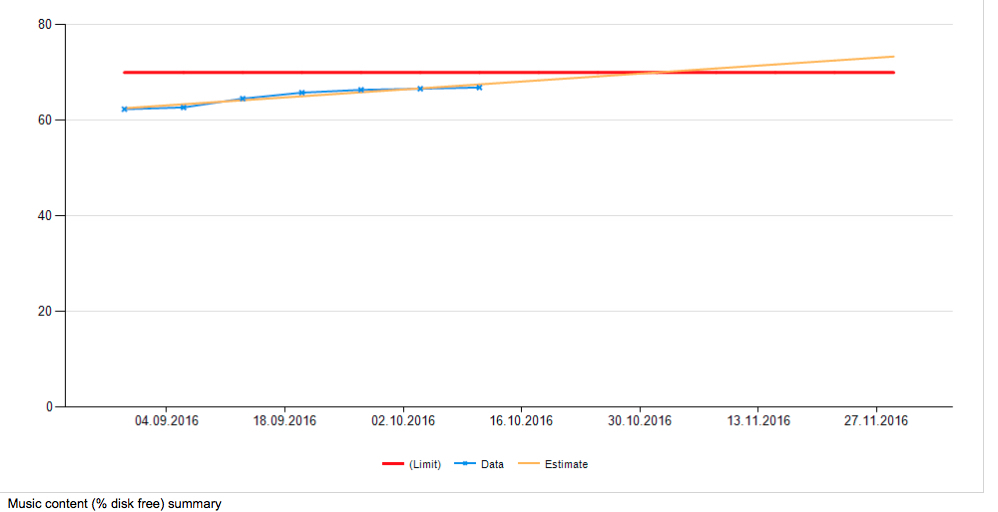
Система отбрасывает spare-диски (запасные диски в массиве), и они не попадают в эту статистику.
В итоге, после того как инженер из команды мониторинга создаст отчёт и оформит все проблемы, руководители возлагают на администраторов следующие задачи:
- расширить кластер photo;
- увеличить диски в group1 и group2;
- решить проблему с очередью на group3;
- разобраться с GC на group4;
- решить проблему с трафиком и нагрузкой на server1 и server2;
- решить проблему со swap на group5 и group6.
Все эти задачи на момент их постановки были не критичны, так как система обнаружила проблемы заранее, что значительно упростило работу системным администраторам: им не пришлось бросать всё, чтобы разрешить проблемы за короткий отрезок времени.
Новые метрики
Иногда нам нужны новые метрики. Это один-два новых показателей в год. Мы заводим их, чаще всего, по инцидентам, предполагая, что если бы чего-то заранее оповестило админа, инцидента могло бы и не быть. Однако иногда бывают нужны своего рода костыли — например, на кластере серверов с хранилищем больших фотографий как-то было утилизировано пространство на 80%. При расширении мы не могли технически перераспределить фотографии, а мониторить хотели на 70% заполнения. Образовалось две группы — почти полные сервера, которые генерировали бы алерт постоянно, и новые, девственно чистые. Вместо отдельных правил пришлось заводить виртуальную «фейковую» группу машин, которая поправила вопрос. Ещё из примеров — при массовом переходе на SSD надо было правильно выстроить мониторинг дисковой очереди, там очень отличается типичное поведение от обычных HDD.
В целом, работа устоялась, эта часть красивая, легко поддерживаемая и легко масштабируемая. Используя систему прогнозирования, мы несколько раз уже избежали нежелательной ситуации, когда сервера надо было бы закупать внезапно. Это очень хорошо прочувствовал бизнес. А админы получили ещё один слой защиты от разных мелких неприятностей.
