

Сейчас у нас в Одноклассниках есть четыре географически распределённых дата-центра, 11 тыс. серверов, более 1 тыс. сетевых устройств, 180 сервисов. Под сервисами мы понимаем фото, видео, музыку, ленту и т. д. Ежедневно сайт посещают десятки миллионов уникальных пользователей. И за всем этим хозяйством необходимо следить, чем и занимаются:
- команда инженеров, которая устанавливает оборудование, меняет диски, решает hardware-инциденты;
- команда мониторинга, которая как раз ищет эти инциденты и отдаёт в работу другим командам;
- сетевые администраторы, они работают с сетью, настраивают оборудование;
- системные администраторы, они администрируют и настраивают портал;
- разработчики.
Мы сами устанавливаем и настраиваем наши серверы, но так как их очень много, то неизбежно, что каждый день что-то ломается. И наша самая главная задача в таком случае — увидеть поломку быстрее пользователей. Поэтому за работу всего портала отвечает целая команда мониторинга. Они просматривают графики, ищут в них аномалии, заводят инциденты, распределяют «автоинциденты», которые создаются при помощи связки Zabbix + JIRA. Мы не просто мониторим бизнес-логику, но и автоматически её анализируем. Подробнее об этом я и расскажу далее.
Остановимся на просмотре графиков и поиске аномалий. Какие у нас графики, что такое аномалия, что такое инцидент?
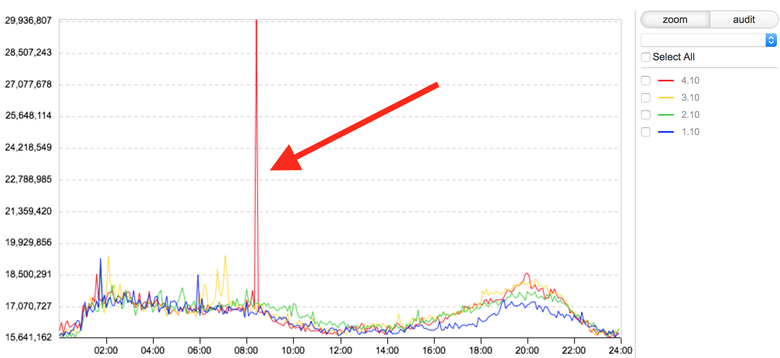
На этом графике изображена продолжительность загрузки нашей ленты, время в нс. Красным цветом показан текущий день. Скакнула продолжительность загрузки ленты активности. Для нас это инцидент, т. е. есть вероятность того, что у пользователей в какой-то момент времени медленно загружалась основная часть сайта — лента активности. Все большие инциденты начинаются именно с таких скачков: сначала один, потом два, а в итоге всё ломается. Поэтому команда мониторинга должна обнаружить скачок и создать тикет в JIRA со всей известной информацией. Проверить все наши сервисы и базы, чтобы найти причину. Пока мы не знаем, что сломалось, мы не знаем, что нужно чинить. Чтобы вручную найти причину скачка на графике, нужно просмотреть десятки, а иногда и сотни других графиков.
Экскурс в прошлое
Раньше, когда портал по всем показателям был сильно меньше, мы делали дашборды с графиками, которых было немного — всего где-то 100—200 штук. Но Одноклассники росли и развивались, появлялись всё новые сервисы, графиков становилось всё больше и больше.
Допустим, запускался новый сервис. Программист, который его сделал, был заинтересован в том, чтобы сервис мониторился со всех сторон. Поэтому он давал команде мониторинга много графиков и говорил: «Теперь вы, ребята, смотрите за всеми ними». Но на тот момент мы не могли просматривать слишком много графиков. Если на каждый сервис их будет по паре десятков, то задача быстро становится невыполнимой. Поэтому мы выделяли и мониторили только самые важные (по мнению автора сервиса) графики. Но иногда бывало так, что при запуске сервиса инцидент был заметен только на «неважных» графиках, которых нет в основных дашбордах. В результате мы пропускали инциденты.
В час команда мониторинга обрабатывала 650 графиков, разбитых на четыре дашборда, каждый из которых ребята из команды просматривали с определенным интервалом. Интервал просмотра каждого дашборда свой (от 15 минут до часа). За восьмичасовую смену через дежурного проходило в среднем 7 тыс. графиков, иногда больше. Много. С этим нужно было что-то сделать. Ведь приходилось не только мониторить тысячи графиков, но и расследовать инциденты. Это действительно сложно и долго, потому что к решению проблем (а в огромной системе уровня Одноклассников какие-то проблемы с железом или софтом возникают постоянно, это аксиома больших систем) подключались и подключаются ещё и разработчики, и админы. К тому же при ручном мониторинге волей-неволей всегда что-то пропускалось.
Когда первый час смотришь 650 картинок, вроде как реагируешь на всё, но когда идёт второй, третий, четвёртый час смены — глаз замыливается, мозг устаёт, и ты начинаешь пропускать аномалии, которые потом тебе же и приходится расследовать. В результате мы решили сделать систему, которая решала бы все описанные выше проблемы.
Все сервисы Одноклассников взаимодействуют между собой. К примеру, сервис фото обращается к сервисам классов, оценок, комментариев и т. д.; это вкратце, подробнее смотрите здесь. По-настоящему взаимодействуют не сервисы, а серверы, которые обслуживают эти сервисы. Мы стали собирать статистические данные о запросах между двумя конкретными серверами, а именно:
- направление связи: какой сервер обращается к какому;
- количество запросов;
- количество запросов, завершившихся ошибкой;
- время выполнения запросов;
- метод, по которому общаются серверы.
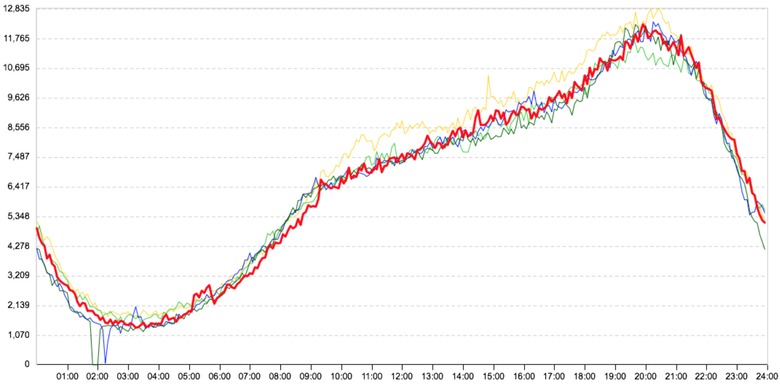
Для примера, вот так выглядит график взаимодействия нашего обычного веб-сервера с нашим типовым сервером бизнес-логики. График показывает количество запросов между ними:
Зная, как общаются наши серверы между собой, мы смогли бы построить граф работы всего портала, который мог бы выглядеть как-то так:
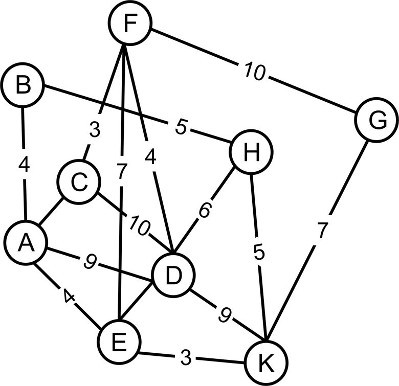
Но есть одна маленькая проблема: у нас 11 тыс. серверов. Такой граф получился бы огромным, построить и наглядно отрисовать его сложно. Решение напрашивается. Каждый сервер играет какую-то роль в инфраструктуре, т. е. у него есть свой (микро-)сервис, всего их 280 штук: лента новостей, личные сообщения, социальный граф (например, граф дружб) и пр. И чтобы уменьшить граф связей серверной инфраструктуры, мы решили сгруппировать физические серверы по функциональности, фактически выделив кластеры, обслуживающие ту или иную подсистему в Одноклассниках. Большие микросервисы типа веб-серверов, кешей и серверов бизнес-логики мы разделили по дата-центрам.
В результате такой группировки по кластерам граф сильно уменьшился: осталось около 300 вершин и 2,5 тыс. рёбер между ними. Это помогло построить граф того, как в действительности работает портал Одноклассники:

По кругу расположены микросервисы. Линии — это взаимосвязи. На данной картинке выделен один микросервис (вверху справа). Зелёные линии — куда ходит этот микросервис, а коричневые — кто ходит к нему. Мы пытались по-разному расположить вершины графа на плоскости, потому что без хорошей визуализации топологии граф было сложно как-то использовать. Думали сделать его динамическим и подсвечивать проблемные связи, т. е. те, на графиках которых есть аномалии, но это не работает: граф очень большой.
Но зачем показывать весь граф всегда? Мы решили вернуться к исходной задаче и посмотреть на него в момент реального инцидента. И через несколько дней такой случай представился — возникла аномалия в системе личных сообщений: пользователь хотел написать сообщение, но у него очень долго подгружалась история переписки. Отличный кейс! Мы решили перестроить граф, оставив только те связи, в которых есть аномалия. Вот что у нас получилось:
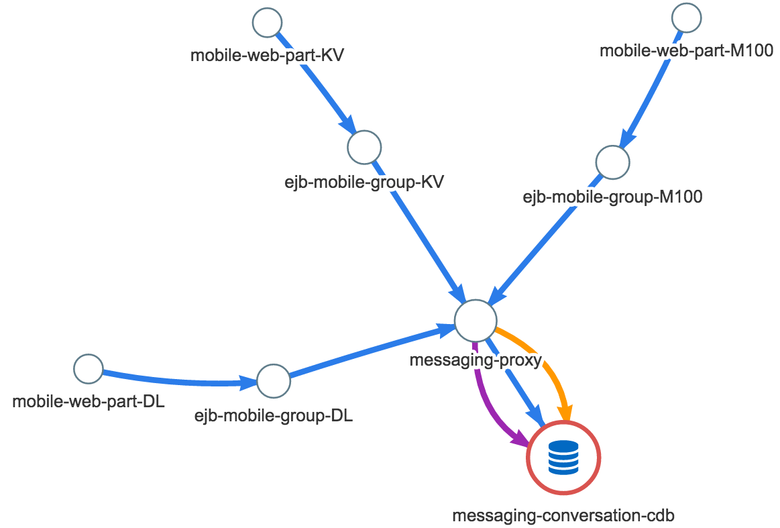
Синим цветом показано время между двумя микросервисами (в каждом микросервисе разное количество серверов), жёлтый цвет — количество запросов, а фиолетовый — ошибки. Быстро стало понятно, что это не просто новая вьюшка для графа. Граф реально указывал на проблему. Проблему стало видно! Если говорить языком сухих цифр, продолжительность запросов мобильных веб-серверов к серверам сервиса сообщений в момент описываемого инцидента увеличилась где-то на 0,5 мс. Время отклика от серверов бизнес-логики до messaging proxy — на 10 мс. И самое главное, средняя latency запросов в хранилище данных увеличилась на 40 мс. Появились ошибки, вызовов к базе стало меньше: вероятно, не все пользователи дожидались конца загрузки истории сообщений, они закрывали окно переписки. По этому графу сразу стало видно, куда копать — кластер messaging-conversation-cdb, который хранит историю переписки. Другими словами, причина очевидна: последнее звено графа, как раз там и рост времени самый значительный.
Протестировав этот подход ещё несколько раз, мы поняли, что он работает. Нам очень понравилась идея с построением графа проблемных взаимосвязей, и мы решили развивать систему дальше, не останавливаясь только на статистике взаимодействия серверов. Мы также стали анализировать статистику отдачи контента с веб-серверов: время, ошибки, запросы, трафик. Добавили мониторинг платежей (денег) — зачастую мы узнаём о проблемах у наших платёжных агрегаторов быстрее, чем они сами, о чём и сообщаем им, отправляя «письма счастья». Кроме того, мы начали мониторить логины по странам как в мобильной, так и в веб-версии и добавили разные технические графики. В итоге сейчас мы в режиме реального времени мониторим 100 тыс. графиков. Это действительно много!
Архитектура системы
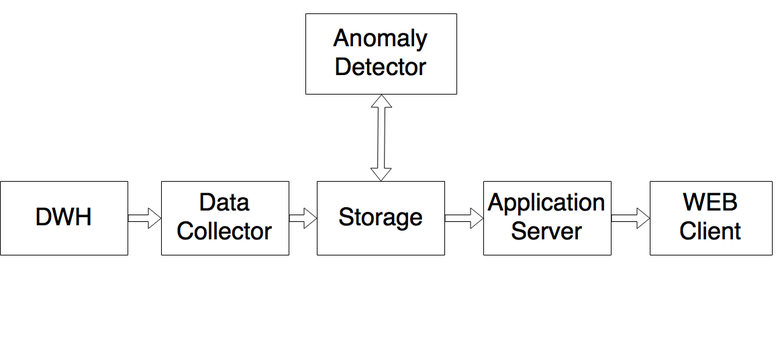
Все логи пишутся в Data Warehouse. Это централизованная система хранилища статистики, построенная на Druid’е. За сутки туда попадает 3 триллиона событий, которые после агрегации помещаются в 3 миллиарда записей, или около 600 Гб. Сервис Data Collector, написанный на .NET, забирает необходимые для системы данные (мы мониторим не все графики, некоторые созданы для иных целей) и кладёт их в Storage — базу на MSSQL, хранилище подготовленных для анализа данных. Anomaly Detector забирает данные и анализирует, помогая искать аномалии в числовых последовательностях. Если он видит аномалию, то помечает и кладёт результат обратно в Storage. Application Server (также написан на .NET) ходит к Storage за данными о найденных аномалиях и к дополнительным сервисам (типа нашей JIRA, системы управления порталом, LiveInternet — там мы смотрим активность по всему рунету), подготавливает всю информацию и передаёт веб-клиенту.
Самый интересный модуль здесь — Anomaly Detector — представляет собой написанный на .NET сервис. Вот как он работает.

Входные данные — то, что мы должны давать системе для обучения.
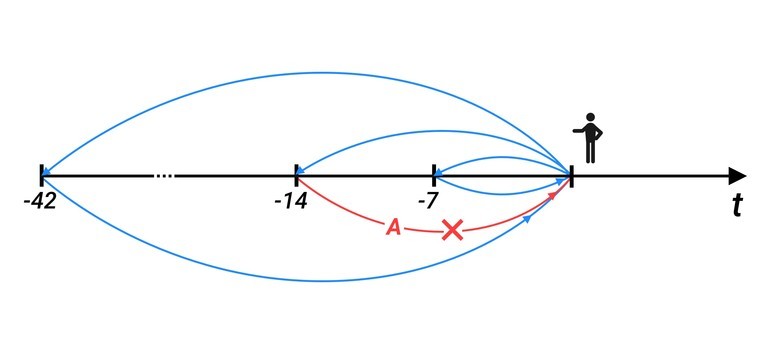
Это значения, которые были в такой же момент времени 7, 14, ..., 42 дня назад, мы берём шесть недель (т. е. если сегодня понедельник, то в обучающую выборку идут все понедельники). Берём значения в тот момент времени, который анализируется сейчас, плюс два соседних значения — как слева, так и справа. Это делается для нормального распределения выборки. Если в тот момент система отметила какие-то значения как аномальные, то они не включаются в выборку.
Далее мы применяем тест Граббса: он ищет выбросы в числовых последовательностях и говорит, аномалия это или нет. Вот пример аномалии, это график времени загрузки одного из компонентов Одноклассников:

Из графика следует, что аномалия возникла в 6:30 утра. А вот так это видит наша система на базе теста Граббса:
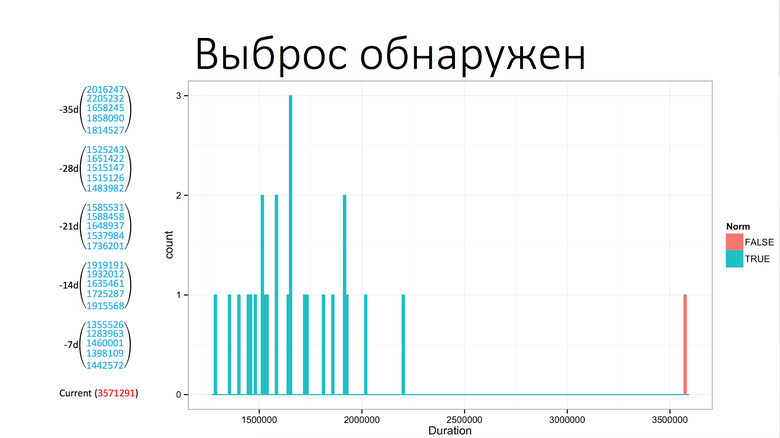
Слева значения, которые были раньше в этот же промежуток времени, плюс-минус два значения слева и справа. Снизу текущее значение. Тест Граббса говорит, что это аномалия, обнаружен выброс. Далее мы делаем фильтрацию. Фильтрация — это борьба с ложными срабатываниями, потому что тест Граббса находит всё, но для нас это не всегда аномалии. Вот какие бывают «ложные аномалии».
Незначительное отклонение от тренда
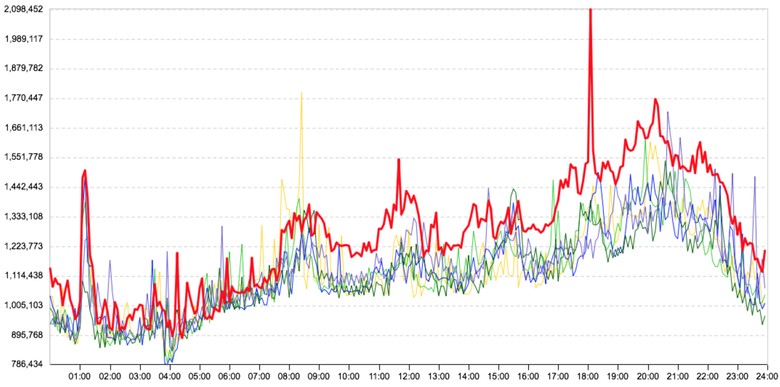
На графике показано среднее время запросов одной из связи микросервисов. Красная линия (рассматриваемый день) идёт чуть выше остальных дней. Здесь действительно есть отклонение, и тест Граббса его найдёт, но для нас он некритичен. Ситуация двоякая: нам важно обнаружить аномалию, но без ложных срабатываний. Опытным путём мы пришли к тому, что для нас некритично отклонение на 20 % по времени и на 15 % по запросам. Правда, не на всех связях, а только на основных. Поэтому в данном случае связь не будет отмечена как аномалия. Но повторюсь, если бы это был график важной связи, такой как время от веб-серверов до серверов бизнес-логики, она была бы отмечена как аномалия, так как, скорее всего, эффект для пользователей незначителен; нужно разбираться, пока он не стал заметен.
Сильно зашумлённые графики
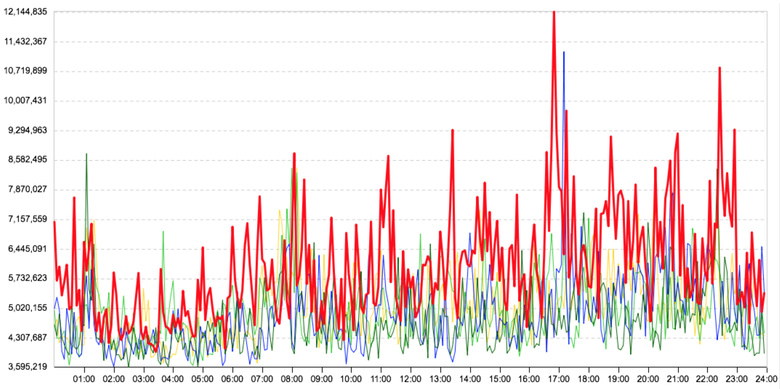
В сильно зашумлённых графиках мы используем агрегацию данных, т. е. система скажет, что в графике есть аномалия, только тогда, когда аномалия несколько раз подряд попадёт на радар. Некритично, что мы узнаём о проблеме чуть позже, главное — что мы узнаём и что это точно проблема. Но если скачки достаточно значительные, тогда правило не работает, так как нам важно отлавливать не только резкое изменение тренда, но и кратковременные затыки: они зачастую приводят к серьёзным проблемам.
Апдейты портала
Во время апдейтов какая-то группа серверов выводится из ротации и останавливается. То есть запросы от неё и к ней падают в ноль, и система показывает такие случаи как аномалии (и правильно делает). Ложное срабатывание, ведь на пользователей это никак не влияет. Допустим, есть восемь групп серверов, выводятся по две. Две вывелись, и вся нагрузка перешла на другие группы. И чтобы не было ложных срабатываний, мы сделали рубильник: во время апдейтов включаем его и смотрим в сумме на те микросервисы, которые разъединены по дата-центрам. Вот как (красиво) выглядит график количества запросов в разбивке по таким группам:
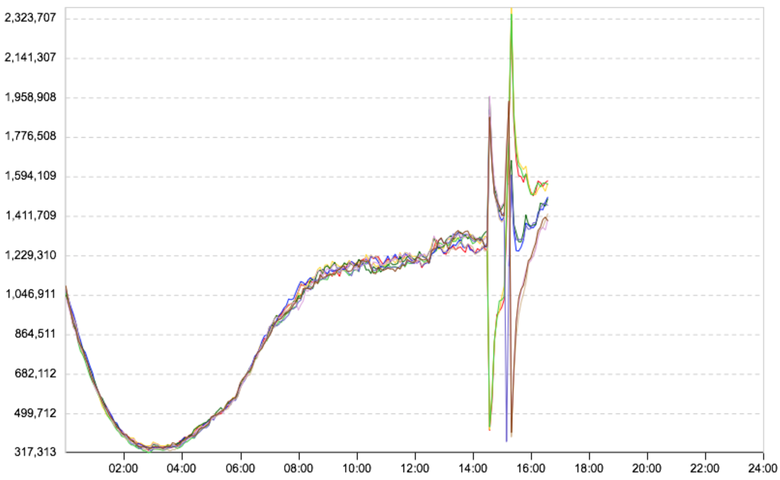
Работа с сетью
При работе с сетью частенько происходит unicast storm, который засоряет сеть, и поэтому время взаимодействия двух микросервисов почти всегда ненадолго, но значительно подскакивает. Поэтому мы отслеживаем возникновение unicast storm в дата-центрах (было ли отправлено сразу много пакетов?). Если обнаруживается шторм, то мы показываем дата-центр, в котором он произошёл, а дежурные выясняют причины.
Сезонное колебание активности
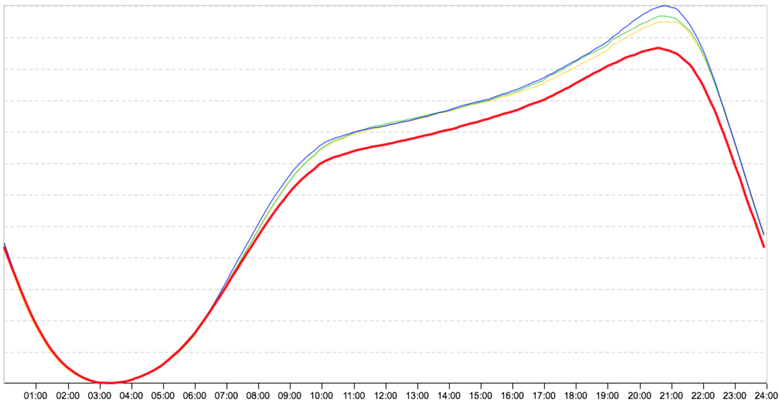
Это картинка за 30 апреля: перед большими праздниками люди разъехались на отдых, и красная линия с 8:00 пошла чуть ниже. И такое по всем сервисам. Мы понимаем, что это влияние сезонности и нужно как-то перестраивать алгоритм. Тогда включаем другой алгоритм, который знает приблизительные отклонения пользовательской активности; он смотрит на онлайны и другие метрики, переосмысливает их и не отображает подобные срабатывания.
Как работает система?
Члену команды мониторинга приходит граф, или просто связь, и он может сделать с ней четыре вещи:
- Отметить как известную аномалию, чтобы она ушла на время. Допустим, пользователь знает, почему она произошла. Некий программист сказал: «Я сейчас включу какой-то функционал, здесь время возрастёт, и я его через два часа выключу». Пользователь со спокойной душой описывает всё в нужных полях, и это событие временно его не беспокоит.
- Создать инцидент. Он заводится в самой системе и автоматически появляется в JIRA (создаётся JIRA ticket, куда передаётся вся необходимая информация об инциденте).
- Указать как новый тренд. Допустим, программист чем-то дополняет свой сервис и ожидает увеличения продолжительности запроса. С этого момента нужно иначе анализировать график, и пользователь указывает, что начался новый тренд.
- Ничего не сделать, если, допустим, проскочило какое-то ложное срабатывание.
Возможности системы, облегчающие работу с ней:
- Если с каким-то графом уже возникали проблемы, то система подскажет, чем это было вызвано. Мы храним все отметки пользователей, которыми они маркируют графы.
- Связь с JIRA. Инциденты создаются в системе мониторинга и автоматически появляются в JIRA. Система проверяет статусы инцидентов: бывает, что пользователь создал инцидент и забывает его обновлять, а если на связи есть инцидент без времени завершения, то такие связи не показываются. Если в этот момент проблема усугубляется, тогда система скажет об этом. То же самое и с уже известной аномалией. Если дежурный ненадолго спрятал аномалию как известную, но она усугубилась, то система подскажет, что надо посмотреть вот эти графики.
- Связь с системой конфигурации. У нас есть система конфигурации портала, с помощью которой программисты вносят изменения в портал. Пользователь видит какой-то граф и может посмотреть, какие изменения на портале были в этот момент. Это позволяет понять, какой именно программист приложил руку к проблеме, а значит, и поможет с решением.
- Если какому-нибудь админу или программисту интересно, что происходило с его (микро-)сервисом, то он может посмотреть, например, какие аномалии возникали ночью или за всю неделю.
- Система позволяет работать удалённо и совместно: если один пользователь отмечает какую-то связь как известную аномалию, то другой сразу же видит, кто и почему отметил выброс как аномалию и что именно произошло.
- Графический интерфейс. Я отношу его к фичам.
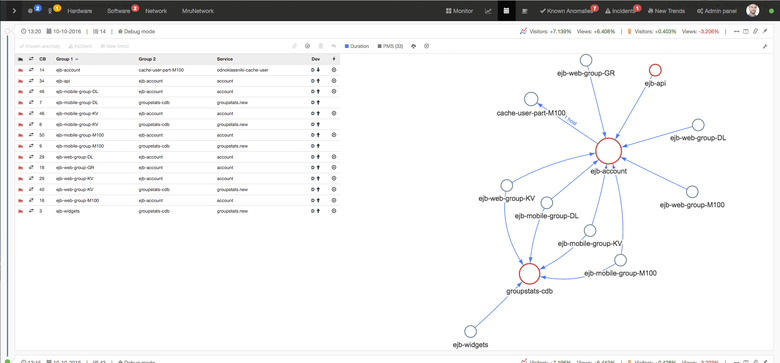
Картинка кликабельна
Слева таблица, справа граф, сверху шапка. Таблицы и граф дублируются по содержанию. Над графом отображается активность по всему рунету и по Одноклассникам. Это нужно для отслеживания отклонений активности. Слева вверху — пользователь видит, сколько сейчас на нём открытых инцидентов. Также там находятся вкладки по «автоинцидентам»; они, как уже писалось выше, создаются при помощи связки Zabbix + JIRA, на которых загорается количество новых инцидентов, созданных системой: HardWare, SoftWare, Network. Справа — вкладки, куда попадают обработанные связи: Known Anomalies, Incidents, New Trends. На них же баблами появляется количество усугубившихся проблем.
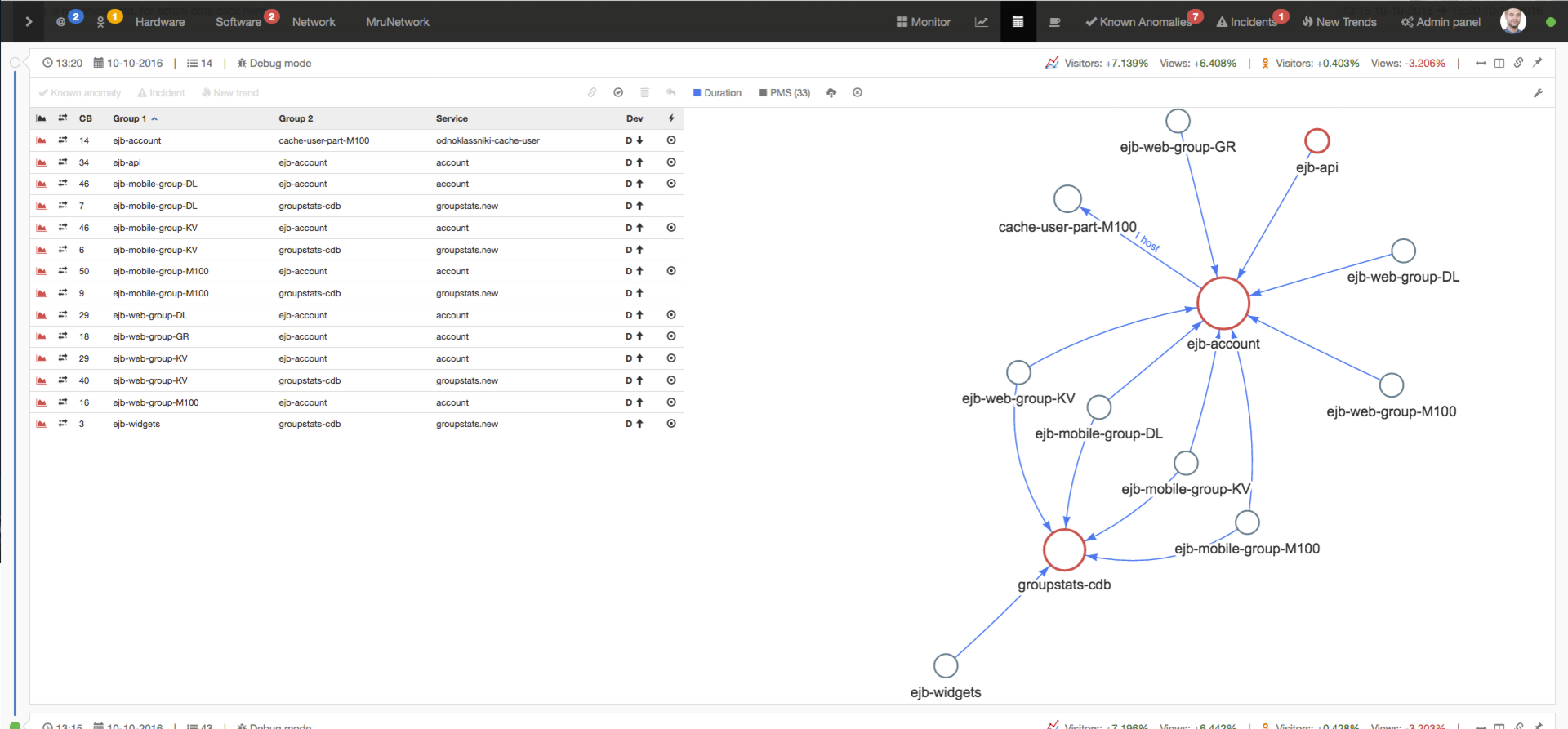
Результат работы системы
Теперь мы мониторим 100 тыс. графиков, не пропускаем инциденты, тратим значительно меньше времени на расследование. Все новые сервисы автоматически ставятся на мониторинг. Выросла производительность команды. Любой админ или программист может зайти в систему и посмотреть, что сейчас происходит, есть ли какие-то проблемы, крупные или не очень. Это помогает и админам, и программистам радоваться жизни.
Если кто-то из вас будет создавать подобную систему, мы сделали список статей, которые вам помогут. Вы найдёте их по ссылке.
