Привет, Хабр! Мы уже говорили про Theano и Tensorflow (а также много про что еще), а сегодня сегодня пришло время поговорить про Keras.
Изначально Keras вырос как удобная надстройка над Theano. Отсюда и его греческое имя — κέρας, что значит "рог" по-гречески, что, в свою очередь, является отсылкой к Одиссее Гомера. Хотя, с тех пор утекло много воды, и Keras стал сначала поддерживать Tensorflow, а потом и вовсе стал его частью. Впрочем, наш рассказ будет посвящен не сложной судьбе этого фреймворка, а его возможностям. Если вам интересно, добро пожаловать под кат.

Начать стоит от печки, то есть с оглавления.
- [Установка]
- [Бэкенды]
- [Практический пример]
- [Данные]
- [Модель]
- [Sequential API]
- [Functional API]
- [Подготовка модели к работе]
- [Custom loss]
- [Обучение и тестирование]
- [Callbacks]
- [Tensorboard]
- [Продвинутые графы]
- [Заключение]
Установка
Установка Keras чрезвычайно проста, т.к. он является обычным питоновским пакетом:
pip install kerasТеперь мы можем приступить к его разбору, но сначала поговорим про бэкенды.
ВНИМАНИЕ: Чтобы работать с Keras, у вас уже должен быть установлен хотя бы один из фреймворков — Theano или Tensorflow.
Бэкенды
Бэкенды — это то, из-за чего Keras стал известен и популярен (помимо прочих достоинств, которые мы разберем ниже). Keras позволяет использовать в качестве бэкенда разные другие фреймворки. При этом написанный вами код будет исполняться независимо от используемого бэкенда. Начиналась разработка, как мы уже говорили, с Theano, но со временем добавился Tensorflow. Сейчас Keras по умолчанию работает именно с ним, но если вы хотите использовать Theano, то есть два варианта, как это сделать:
- Отредактировать файл конфигурации keras.json, который лежит по пути
$HOME/.keras/keras.json(или%USERPROFILE%\.keras\keras.jsonв случае операционных систем семейства Windows). Нам нужно полеbackend:
{ "image_data_format": "channels_last", "epsilon": 1e-07, "floatx": "float32", "backend": "theano" } - Второй путь — это задать переменную окружения
KERAS_BACKEND, например, так:
KERAS_BACKEND=theano python -c "from keras import backend" Using Theano backend.
Стоит отметить, что сейчас ведется работа по написанию биндингов для CNTK от Microsoft, так что через некоторое время появится еще один доступный бэкенд. Следить за этим можно здесь.
Также существует MXNet Keras backend, который пока не обладает всей функциональностью, но если вы используете MXNet, вы можете обратить внимание на такую возможность.
Еще существует интересный проект Keras.js, дающий возможность запускать натренированные модели Keras из браузера на машинах, где есть GPU.
Так что бэкенды Keras ширятся и со временем захватят мир! (Но это неточно.)
Практический пример
В прошлых статьях много внимания было уделено описанию работы классических моделей машинного обучения на описываемых фреймворках. Кажется, теперь мы можем взять в качестве примера [не очень] глубокую нейронную сеть.
Данные

Обучение любой модели в машинном обучении начинается с данных. Keras содержит внутри несколько обучающих датасетов, но они уже приведены в удобную для работы форму и не позволяют показать всю мощь Keras. Поэтому мы возьмем более сырой датасет. Это будет датасет 20 newsgroups — 20 тысяч новостных сообщений из групп Usenet (это такая система обмена почтой родом из 1990-х, родственная FIDO, который, может быть, чуть лучше знаком читателю) примерно поровну распределенных по 20 категориям. Мы будем учить нашу сеть правильно распределять сообщения по этим новостным группам.
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')
newsgroups_test = fetch_20newsgroups(subset='test')Вот пример содержания документа из обучающей выборки:
From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15
I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small. In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.
Thanks,
- IL
— brought to you by your neighborhood Lerxst ----
Препроцессинг
Keras содержит в себе инструменты для удобного препроцессинга текстов, картинок и временных рядов, иными словами, самых распространенных типов данных. Сегодня мы работаем с текстами, поэтому нам нужно разбить их на токены и привести в матричную форму.
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(newsgroups_train["data"]) # теперь токенизатор знает словарь для этого корпуса текстов
x_train = tokenizer.texts_to_matrix(newsgroups_train["data"], mode='binary')
x_test = tokenizer.texts_to_matrix(newsgroups_test["data"], mode='binary')На выходе у нас получились бинарные матрицы вот таких размеров:
x_train shape: (11314, 1000)
x_test shape: (7532, 1000)Первое число — количество документов в выборке, а второе — размер нашего словаря (одна тысяча в этом примере).
Еще нам понадобится преобразовать метки классов к матричному виду для обучения с помощью кросс-энтропии. Для этого мы переведем номер класса в так называемый one-hot вектор, т.е. вектор, состоящий из нулей и одной единицы:
y_train = keras.utils.to_categorical(newsgroups_train["target"], num_classes)
y_test = keras.utils.to_categorical(newsgroups_test["target"], num_classes)На выходе получим также бинарные матрицы вот таких размеров:
y_train shape: (11314, 20)
y_test shape: (7532, 20)Как мы видим, размеры этих матриц частично совпадают с матрицами данных (по первой координате — числу документов в обучающей и тестовой выборках), а частично — нет. По второй координате у нас стоит число классов (20, как следует из названия датасета).
Все, теперь мы готовы учить нашу сеть классифицировать новости!
Модель
Модель в Keras можно описать двумя основными способами:
Sequential API
Первый — последовательное описание модели, например, вот так:
model = Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))или вот так:
model = Sequential([
Dense(512, input_shape=(max_words,)),
Activation('relu'),
Dropout(0.5),
Dense(num_classes),
Activation('softmax')
])Functional API
Некоторое время назад появилась возможность использовать функциональное API для создания модели — второй способ:
a = Input(shape=(max_words,))
b = Dense(512)(a)
b = Activation('relu')(b)
b = Dropout(0.5)(b)
b = Dense(num_classes)(b)
b = Activation('softmax')(b)
model = Model(inputs=a, outputs=b)Принципиального отличия между способами нет, выбирайте, какой вам больше по душе.
Класс Model (и унаследованный от него Sequential) имеет удобный интерфейс, позволяющий посмотреть, какие слои входят в модель — model.layers, входы — model.inputs, и выходы — model.outputs.
Также очень удобный метод отображения и сохранения модели — model.to_yaml.
backend: tensorflow
class_name: Model
config:
input_layers:
- [input_4, 0, 0]
layers:
- class_name: InputLayer
config:
batch_input_shape: !!python/tuple [null, 1000]
dtype: float32
name: input_4
sparse: false
inbound_nodes: []
name: input_4
- class_name: Dense
config:
activation: linear
activity_regularizer: null
bias_constraint: null
bias_initializer:
class_name: Zeros
config: {}
bias_regularizer: null
kernel_constraint: null
kernel_initializer:
class_name: VarianceScaling
config: {distribution: uniform, mode: fan_avg, scale: 1.0, seed: null}
kernel_regularizer: null
name: dense_10
trainable: true
units: 512
use_bias: true
inbound_nodes:
- - - input_4
- 0
- 0
- {}
name: dense_10
- class_name: Activation
config: {activation: relu, name: activation_9, trainable: true}
inbound_nodes:
- - - dense_10
- 0
- 0
- {}
name: activation_9
- class_name: Dropout
config: {name: dropout_5, rate: 0.5, trainable: true}
inbound_nodes:
- - - activation_9
- 0
- 0
- {}
name: dropout_5
- class_name: Dense
config:
activation: linear
activity_regularizer: null
bias_constraint: null
bias_initializer:
class_name: Zeros
config: {}
bias_regularizer: null
kernel_constraint: null
kernel_initializer:
class_name: VarianceScaling
config: {distribution: uniform, mode: fan_avg, scale: 1.0, seed: null}
kernel_regularizer: null
name: dense_11
trainable: true
units: !!python/object/apply:numpy.core.multiarray.scalar
- !!python/object/apply:numpy.dtype
args: [i8, 0, 1]
state: !!python/tuple [3, <, null, null, null, -1, -1, 0]
- !!binary |
FAAAAAAAAAA=
use_bias: true
inbound_nodes:
- - - dropout_5
- 0
- 0
- {}
name: dense_11
- class_name: Activation
config: {activation: softmax, name: activation_10, trainable: true}
inbound_nodes:
- - - dense_11
- 0
- 0
- {}
name: activation_10
name: model_1
output_layers:
- [activation_10, 0, 0]
keras_version: 2.0.2Это позволяет сохранять модели в человеко-читаемом виде, а также инстанциировать модели из такого описания:
from keras.models import model_from_yaml
yaml_string = model.to_yaml()
model = model_from_yaml(yaml_string)Важно отметить, что модель, сохраненная в текстовом виде (кстати, возможно сохранение также и в JSON) не содержит весов. Для сохранения и загрузки весов используйте функции save_weights и load_weights соответственно.
Визуализация модели
Нельзя обойти стороной визуализацию. Keras имеет встроенную визуализацию для моделей:
from keras.utils import plot_model
plot_model(model, to_file='model.png', show_shapes=True)Этот код сохранит под именем model.png вот такую картинку:
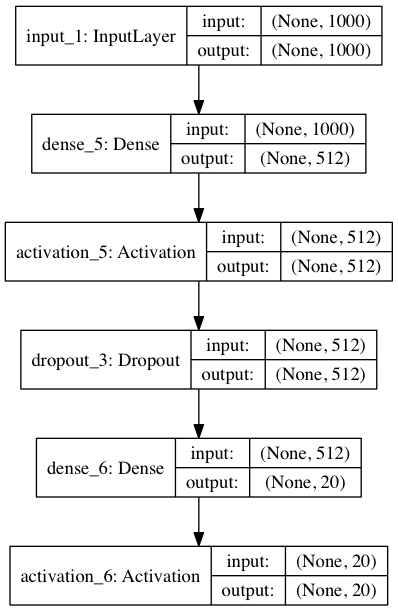
Здесь мы дополнительно отобразили размеры входов и выходов для слоев. None, идущий первым в кортеже размеров — это размерность батча. Т.к. стоит None, то батч может быть произвольным.
Если вы захотите отобразить ее в jupyter-ноутбуке, вам нужен немного другой код:
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))Важно отметить, что для визуализации нужен пакет graphviz, а также питоновский пакет pydot. Есть тонкий момент, что для корректной работы визуализации пакет pydot из репозитория не пойдет, нужно взять его обновленную версию pydot-ng.
pip install pydot-ngПакет graphviz в Ubuntu ставится так (в других дистрибутивах Linux аналогично):
apt install graphvizНа MacOS (используя систему пакетов HomeBrew):
brew install graphvizИнструкцию установки на Windows можно посмотреть здесь.
Подготовка модели к работе
Итак, мы сформировали нашу модель. Теперь нужно подготовить ее к работе:
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])Что означают параметры функции compile? loss — это функция ошибки, в нашем случае — это перекрестная энтропия, именно для нее мы подготавливали наши метки в виде матриц; optimizer — используемый оптимизатор, здесь мог бы быть обычный стохастический градиентный спуск, но Adam показывает лучшую сходимость на этой задаче; metrics — метрики, по которым считается качество модели, в нашем случае — это точность (accuracy), то есть доля верно угаданных ответов.
Custom loss
Несмотря на то, что Keras содержит большинство популярных функций ошибки, для вашей задачи может потребоваться что-то уникальное. Чтобы сделать свой собственный loss, нужно немного: просто определить функцию, принимающую векторы правильных и предсказанных ответов и выдающую одно число на выход. Для тренировки сделаем свою функцию расчета перекрестной энтропии. Чтобы она чем-то отличалась, введем так называемый clipping — обрезание значений вектора сверху и снизу. Да, еще важное замечание: нестандартный loss может быть необходимо описывать в терминах нижележащего фреймворка, но мы можем обойтись средствами Keras.
from keras import backend as K
epsilon = 1.0e-9
def custom_objective(y_true, y_pred):
'''Yet another cross-entropy'''
y_pred = K.clip(y_pred, epsilon, 1.0 - epsilon)
y_pred /= K.sum(y_pred, axis=-1, keepdims=True)
cce = categorical_crossentropy(y_pred, y_true)
return cceЗдесь y_true и y_pred — тензоры из Tensorflow, поэтому для их обработки используются функции Tensorflow.
Для использования другой функции потерь достаточно изменить значения параметра loss функции compile, передав туда объект нашей функции потерь (в питоне функции — тоже объекты, хотя это уже совсем другая история):
model.compile(loss=custom_objective,
optimizer='adam',
metrics=['accuracy'])Обучение и тестирование
Наконец, пришло время для обучения модели:
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1)Метод fit делает именно это. Он принимает на вход обучающую выборку вместе с метками — x_train и y_train, размером батча batch_size, который ограничивает количество примеров, подаваемых за раз, количеством эпох для обучения epochs (одна эпоха — это один раз полностью пройденная моделью обучающая выборка), а также тем, какую долю обучающей выборки отдать под валидацию — validation_split.
Возвращает этот метод history — это история ошибок на каждом шаге обучения.
И наконец, тестирование. Метод evaluate получает на вход тестовую выборку вместе с метками для нее. Метрика была задана еще при подготовке к работе, так что больше ничего не нужно. (Но мы укажем еще размер батча).
score = model.evaluate(x_test, y_test, batch_size=batch_size)Callbacks
Нужно также сказать несколько слов о такой важной особенности Keras, как колбеки. Через них реализовано много полезной функциональности. Например, если вы тренируете сеть в течение очень долгого времени, вам нужно понять, когда пора остановиться, если ошибка на вашем датасете перестала уменьшаться. По-английски описываемая функциональность называется "early stopping" ("ранняя остановка"). Посмотрим, как мы можем применить его при обучении нашей сети:
from keras.callbacks import EarlyStopping
early_stopping=EarlyStopping(monitor='value_loss')
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=[early_stopping])Проведите эксперимент и проверьте, как быстро сработает early stopping в нашем примере?
Tensorboard
Еще в качестве колбека можно использовать сохранение логов в формате, удобном для Tensorboard (о нем разговор был в статье про Tensorflow, вкратце — это специальная утилита для обработки и визуализации информации из логов Tensorflow).
from keras.callbacks import TensorBoard
tensorboard=TensorBoard(log_dir='./logs', write_graph=True)
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=[tensorboard])После того, как обучение закончится (или даже в процессе!), вы можете запустить Tensorboard, указав абсолютный путь к директории с логами:
tensorboard --logdir=/path/to/logsТам можно посмотреть, например, как менялась целевая метрика на валидационной выборке:

(Кстати, тут можно заметить, что наша сеть переобучается.)
Продвинутые графы
Теперь рассмотрим построение чуть более сложного графа вычислений. У нейросети может быть множество входов и выходов, входные данные могут преобразовываться разнообразными отображениями. Для переиспользования частей сложных графов (в частности, для transfer learning) имеет смысл описывать модель в модульном стиле, позволяющем удобным образом извлекать, сохранять и применять к новым входным данным куски модели.
Наиболее удобно описывать модель, смешивая оба способа — Functional API и Sequential API, описанные ранее.
Рассмотрим этот подход на примере модели Siamese Network. Схожие модели активно используются на практике для получения векторных представлений, обладающих полезными свойствами. Например, подобная модель может быть использована для того, чтобы выучить такое отображение фотографий лиц в вектор, что вектора для похожих лиц будут близко друг к другу. В частности, этим пользуются приложения поиска по изображениям, такие как FindFace.
Иллюстрацию модели можно видеть на диаграмме:

Здесь функция G превращает входную картинку в вектор, после чего вычисляется расстояние между векторами для пары картинок. Если картинки из одного класса, расстояние нужно минимизировать, если из разных — максимизировать.
После того, как такая нейросеть будет обучена, мы сможем представить произвольную картинку в виде вектора G(x) и использовать это представление либо для поиска ближайших изображений, либо как вектор признаков для других алгоритмов машинного обучения.
Будем описывать модель в коде соответствующим образом, максимально упростив извлечение и переиспользование частей нейросети.
Сначала определим на Keras функцию, отображающую входной вектор.
def create_base_network(input_dim):
seq = Sequential()
seq.add(Dense(128, input_shape=(input_dim,), activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(128, activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(128, activation='relu'))
return seqОбратите внимание: мы описали модель с помощью Sequential API, однако обернули ее создание в функцию. Теперь мы можем создать такую модель, вызвав эту функцию, и применить ее с помощью Functional API ко входным данным:
base_network = create_base_network(input_dim)
input_a = Input(shape=(input_dim,))
input_b = Input(shape=(input_dim,))
processed_a = base_network(input_a)
processed_b = base_network(input_b)Теперь в переменных processed_a и processed_b лежат векторные представления, полученные путем применения сети, определенной ранее, к входным данным.
Нужно посчитать между ними расстояния. Для этого в Keras предусмотрена функция-обертка Lambda, представляющая любое выражение как слой (Layer). Не забудьте, что мы обрабатываем данные в батчах, так что у всех тензоров всегда есть дополнительная размерность, отвечающая за размер батча.
from keras import backend as K
def euclidean_distance(vects):
x, y = vects
return K.sqrt(K.sum(K.square(x - y), axis=1, keepdims=True))
distance = Lambda(euclidean_distance)([processed_a, processed_b])Отлично, мы получили расстояние между внутренними представлениями, теперь осталось собрать входы и расстояние в одну модель.
model = Model([input_a, input_b], distance)Благодаря модульной структуре мы можем использовать base_network отдельно, что особенно полезно после обучения модели. Как это можно сделать? Посмотрим на слои нашей модели:
>>> model.layers
[<keras.engine.topology.InputLayer object at 0x7f238fdacb38>, <keras.engine.topology.InputLayer object at 0x7f238fdc34a8>, <keras.models.Sequential object at 0x7f239127c3c8>, <keras.layers.core.Lambda object at 0x7f238fddc4a8>]Видим третий объект в списке типа models.Sequential. Это и есть модель, отображающая входную картинку в вектор. Чтобы ее извлечь и использовать как полноценную модель (можно дообучать, валидировать, встраивать в другой граф) достаточно всего лишь вытащить ее из списка слоев:
>>> embedding_model = model.layers[2]
>>> embedding_model.layers
[<keras.layers.core.Dense object at 0x7f23c4e557f0>, <keras.layers.core.Dropout object at 0x7f238fe97908>, <keras.layers.core.Dense object at 0x7f238fe44898>, <keras.layers.core.Dropout object at 0x7f238fe449e8>, <keras.layers.core.Dense object at 0x7f238fe01f60>]Например для уже обученной на данных MNIST сиамской сети с размерностью на выходе base_model, равной двум, можно визуализировать векторные представления следующим образом:
Загрузим данные и приведем картинки размера 28x28 к плоским векторам.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_test = x_test.reshape(10000, 784)Отобразим картинки с помощью извлеченной ранее модели:
embeddings = embedding_model.predict(x_test)Теперь в embeddings лежат двумерные вектора, их можно изобразить на плоскости:
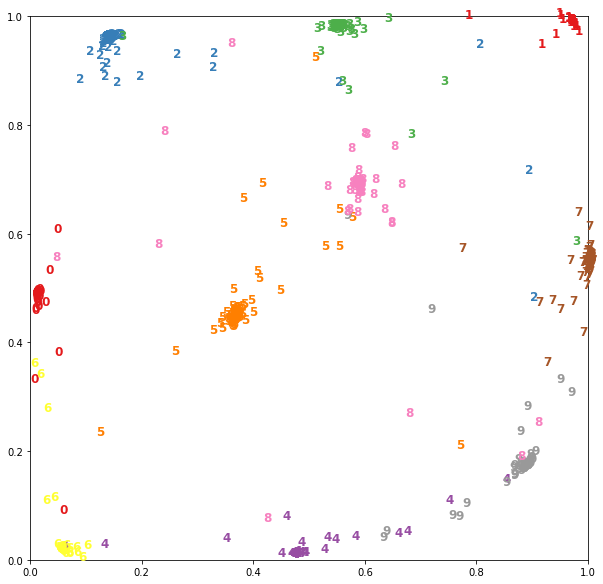
Полноценный пример сиамской сети можно увидеть здесь.
Заключение
Вот и все, мы сделали первые модели на Keras! Надеемся, что предоставляемые им возможности заинтересовали вас, так что вы будете его использовать в своей работе.
Пришло время обсудить плюсы и минусы Keras. К очевидным плюсам можно отнести простоту создания моделей, которая выливается в высокую скорость прототипирования. Например, авторы недавней статьи про спутники использовали именно Keras. В целом этот фреймворк становится все более и более популярным:
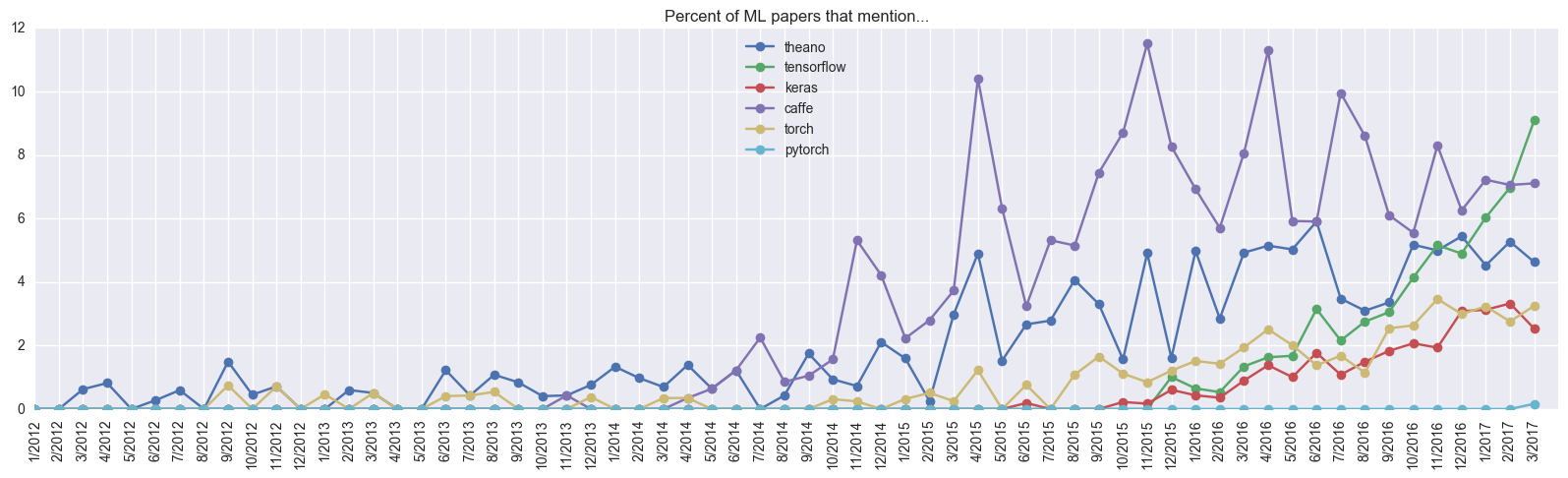
Keras за год догнал Torch, который разрабатывается уже 5 лет, судя по упоминаниям в научных статьях. Кажется, своей цели — простоты использования — Франсуа Шолле (François Chollet, автор Keras) добился. Более того, его инициатива не осталась незамеченной: буквально через несколько месяцев разработки компания Google пригласила его заниматься этим в команде, разрабатывающей Tensorflow. А также с версии Tensorflow 1.2 Keras будет включен в состав TF (tf.keras).
Также надо сказать пару слов о недостатках. К сожалению, идея Keras о универсальности кода выполняется не всегда: Keras 2.0 поломал совместимость с первой версией, некоторые функции стали называться по-другому, некоторые переехали, в общем, история похожа на второй и третий python. Отличием является то, что в случае Keras была выбрана только вторая версия для развития. Также код Keras работает на Tensorflow пока медленнее, чем на Theano (хотя для нативного кода фреймворки, как минимум, сравнимы).
В целом, можно порекомендовать Keras к использованию, когда вам нужно быстро составить и протестировать сеть для решения конкретной задачи. Но если вам нужны какие-то сложные вещи, вроде нестандартного слоя или распараллеливания кода на несколько GPU, то лучше (а подчас просто неизбежно) использовать нижележащий фреймворк.
Практически весь код из статьи есть в виде одного ноутбука здесь. Также очень рекомендуем вам документацию по Keras: keras.io, а так же официальные примеры, на которых эта статья во многом основана.
Пост написан в сотрудничестве с Wordbearer.
