
Привет, Хабр! С этого выпуска мы начинаем хорошую традицию: каждый месяц будет выходить набор рецензий на некоторые научные статьи от членов сообщества Open Data Science из канала #article_essence. Хотите получать их раньше всех — вступайте в сообщество ODS!
Статьи выбираются либо из личного интереса, либо из-за близости к проходящим сейчас соревнованиям. Если вы хотите предложить свою статью или у вас есть какие-то пожелания — просто напишите в комментариях и мы постараемся всё учесть в дальнейшем.
Статьи на сегодня:
- Fitting to Noise or Nothing At All: Machine Learning in Markets
- Learned in Translation: Contextualized Word Vectors
- Create Anime Characters with A.I. !
- LiveMaps: Converting Map Images into Interactive Maps
- Random Erasing Data Augmentation
- YellowFin and the Art of Momentum Tuning
- The Devil is in the Decoder
- Improving Deep Learning using Generic Data Augmentation
- Learning both Weights and Connections for Efficient Neural Networks
- Focal Loss for Dense Object Detection
- Borrowing Treasures from the Wealthy: Deep Transfer Learning through Selective Joint Fine-tuning
- Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
1. Fitting to Noise or Nothing At All: Machine Learning in Markets
Оригинал статьи
Автор: kt{at}ut{dot}ee
Это рецензия на статью, в которой диплернингом предсказываются финансовые рынки. Автор поста (далее — ZHD) указывает на следующие очевидные глупости данной и схожих статей:
- Притягивание за уши показателя accuracy методом взятия максимума из всех экспериментов. Медиана, наоборот, как раз соответствует случайному предсказанию.
- Хвастовство "хорошими результатами", которые получены на инструментах, которые сейчас вообще не торгуются (т.е. у них константная цена). В целом, ZHD рекомендует сравнивать трейдинговые модели не со случайным предсказателем, а со стратегией buy and hold.
- Авторы "симулируют" свою стратегию, предполагая отсутствие комиссий при сделках и то, что любую сделку можно выполнить по цене, равной среднему между high и low за последние пять минут. Из-за этого в симуляциях наилучшая прибыль получается у наименее ликвидных инструментов (которые на деле далеко не всегда продадутся по средней цене за пять минут, поэтому вся прибыль скорее всего "получена" за счет нечестного предположения о ликвидности). Вдобавок, авторы хвастаются только несколькими "удачными" моделями, умалчивая всё, что отсимулировалось в минус.
- Авторы не учитывают время работы бирж (в том числе, очные сессии для сделок (trading pits)) и по мнению ZHD это неправильно.
2. Learned in Translation: Contextualized Word Vectors
→ Оригинал статьи
→ Код
Автор: kt{at}ut{dot}ee
Трансфер лернинг в наше время — стандартный прием. Взять сетку, натренированную на породах болонок из ImageNet, и прикрутить её куда-то для распознавания типов соплей — это уже стандартная программа для всех мамкиных диплёрнеров. В контексте обработки текста, трансфер лернинг обычно менее глубокий и упирается в использование заготовленных векторов слов типа Word2Vec, GloVe итд.
Авторы статьи предлагают углубить текстовый трансфер лернинг на один уровень следующим образом:
- Натренируем LSTM-based seq2seq модель (вида encoder + decoder with attention over encoder hidden states) для перевода, скажем, с английского на немецкий.
- Возьмем из неё только encoder (он будет простенького вида LSTM(Embedding(word_idxs)). Этот энкодер умеет превращать последовательность слов в последовательность LSTM hidden states. Т.к. эти hidden states взяты не случайно (их переводческая модель использует в своём аттеншене), то однозначно в них будет полезный сигнал.
- Ну и всё, давайте теперь строить любые другие текстовые модели, которым мы на вход будем скармливать не только GloVe векторы слов, но и приклеенные к ним соответствующие LSTM hidden векторы из нашего переводческого энкодера (их мы будем называть Context Vectors, CoVe).
Далее авторы наворачивают какую-то нетривиальную модель c biattention и maxout (видимо, завалялась с их прошлой работы) и сравнивают, как она работает в разных задачах, если ей на входе скормить случайный эмбеддинг, GloVe, GloVe+CoVe, GloVe+CoVe+CharNGramEmbeddings.
По результатам кажется, что добавление CoVe повышает точность голого GloVe примерно на 1%. Иногда эффект меньше, иногда отрицательный, иногда добавление вместо CoVe в модель CharNGrams работает так же или даже лучше. В любом случае, совмещение GloVe+CoVe+CharNGrams работает точно лучше всех других методов.

На мой взгляд, из-за того, что авторы навернули нехилую модель с аттеншеном поверх сравниваемых типов эмбеддинга (GloVe vs CoVe), замер эффекта полезности CoVe получился излишне зашумленным и не очень убедительным. Я бы предпочел увидеть более "лабораторный" замер.
3. Create Anime Characters with A.I. !
→ Оригинал статьи
→ Сайт
Автор: kt{at}ut{dot}ee
Существует сайт Getchu, на котором собраны "профили" анимешных героев различных японских игр с картинками-иллюстрациями. Эти картинки можно скачать.
Для нахождения лица на картинке можно использовать некую тулзу "lbpcascade animeface". Таким образом авторы получили 42к анимешных лиц, которые они потом ручками пересмотрели и выкинули 4% плохих примеров.
Имеется некая уже готовая CNN-модель Illustration2Vec, которая умеет распознавать на анимешных картинках свойства типа "улыбка", "цвет волос", итд. Авторы использовали её для того, чтобы отлейблить картинки и выбрали 34 интересующих их тэга.
Авторы запихнули это всё в DRAGAN (Kodali et al, где это отличается от обычных GAN авторы не углубляются, видимо, непринципиально).
Чтобы уметь генерировать картинки с заданными атрибутами, авторы делают как в ACGAN:
- Кормят генератору вектор атрибутов.
- Заставляют дискриминатор этот вектор предсказывать.
- Дополнительно штрафуют генератор пропорционально тому, насколько дискриминатор не угадал верный класс.
И генератор, и дискриминатор — довольно замороченные конволюционные SRResNet-ы (у генератора 16-блоковый, у дискриминатора 10-блоковый). У дискриминатора авторы убрали батчнорм-слои "since it would bring correlations within the mini-batch, which is undesired for the computation of the gradient norm." Я не очень понял эту проблему, поясните если вдруг кому ясно.
Тренировалось всё Адамом с уменьшающимся lr начиная от 0.0002, не очень понятно как долго.
Для вебаппа авторы сконвертировали сеть под WebDNN (https://github.com/mil-tokyo/webdnn) и поэтому генерят все картинки прямо в браузере на клиенте (!).
4. LiveMaps: Converting Map Images into Interactive Maps
→ Оригинал статьи
→ Статья — победитель Best Short Paper Awart SIGIR 2017
Автор: zevsone
Предложена принципиально новая система (LiveMaps) для анализа изображений карт и извлечения релевантного viewport'a.
Система позволяет делать аннотации для изображений, полученных с помощью поискового движка, позволяя пользователям переходить по ссылке, которая открывает интерактивную карту с центром в локации, соответствующей найденному изображению.
LiveMaps работает в несколько приемов. Сперва проверяется является ли изображение картой.
Если "да", система пытается определить геолокацию этого изображения. Для определения локации используется текстовая и визуальная информация извлеченная из изображения. В итоге, система создает интерактивную карту, отображающую географическую область, вычисленную для изображения.
Результаты оценки на датасете локаций с высоким рангом показывают, что система способна конструировать очень точные интерактивные карты, достигая при этом хорошего покрытия.
P.S. Совсем не ожидал получить best short paper award на такой маститой конфе (121 short paper в претендентах в этом году, все industry гиганты).
5. Random Erasing Data Augmentation
→ Оригинал статьи
Автор: egor.v.panfilov{at}gmail{dot}com
Статья посвящена исследованию одного из простейших методов аугментации изображений — Random Erasing (по-русски, закрашиванию случайных прямоугольников).
Аугментация параметризовалась 4-мя параметрами: (P_prob) вероятность применения к каждой картинке батча, (P_area) размер региона (area ratio), (P_aspect) соотношение сторон региона (aspect ratio), (P_value) заполняемое значением: случайные / среднее на ImageNet / 0 / 255.

Авторы провели оценку влияния данного метода аугментации на 3-х задачах: (A) object classification, (B) object detection, © person re-identification.
(A): Использовались 6 архитектур, начиная с AlexNet, заканчивая ResNeXt. Датасет — CIFAR10/100. Оптимальное значение параметров: P_prob = 0.5, P_aspect = в широком диапазоне, но желательно не 1(квадрат), P_area = 0.02-0.4 (2-40% изображения), P_value = random или среднее на ImageNet, для 0 и 255 результаты существенно хуже. Сравнили также с другими методами и аугментации (random cropping, random flipping), и регуляризации (dropout, random noise): в порядке снижения эффективности — всё вместе, random cropping, random flipping, random erasing. Drouput и random noise данный метод уделывет "в щепки". В целом, метод не самый мощный, но при оптимальных параметрах стабильно даёт 1% точности (5.5% -> 4.5%). Также пишут, что он повышает робастность классификатора к перекрытиям объектов :you-dont-say:.
(B): Использовалась Fast-RCNN на PASCAL VOC 2007+2012. Реализовали 3 схемы: IRE (Image-aware Random Erasing, также выбираем регион для зануления вслепую), ORE (Object-aware, зануляем только части bounding box'ов), I+ORE (и там, и там). Существенной разницы по mAP между этими методами нет. По сравнению с чистым Fast-RCNN, дают порядка 5% (67->71 на VOC07, 70->75 на VOC07+12), столько же, сколько и A-Fast-RCNN. Оптимальные параметры — P_prob = 0.5, P_area = 0.02-0.2 (2-20%), P_aspect = 0.3-3.33 (от лежачей до стоячей полоски).
(С): Использовались ID-discim.Embedding (IDE), Triplet Net, и SVD-Net (все на базе ResNet, предобученной на ImageNet) на Market-1501 / DukeMTMC-reID / CUHK03. На всех моделях и датасетах аугментация стабильно даёт не менее 2% (до 8%) для Rank@1, и не менее 3% (до 8%) для mAP. Параметры те же, что и для (B).
В целом, несмотря на простоту метода, исследование и статья довольно аккуратные и подробные (10 страниц), с кучей графиков и таблиц. Порадовали китайцы, ничего не скажешь.
6. YellowFin and the Art of Momentum Tuning
→ Оригинал статьи
→ Дополнительный материал про momentum
Автор: Arech
Давно я её читал, поэтому очень-очень поверхностно: после вдумчивого курения свойств классического моментума (он же моментум Бориса Поляка), на одномерных строго выпуклых квадратичных целях чуваки вывели (или нашли у кого-то?) неравенство, связывающее коэффициенты learning rate и моментума так, чтобы они попадали в некий "робастный" регион, гарантирующий наибыстрейшее схождение алгоритма SGD. Потом показали(?), что оное утверждение в принципе может как-то выполняться и для некоторых невыпуклых функций, по крайней мере в некоторой их локальной области, которую можно более-менее апроксимировать квадратичным приближением. После чего решили запилить свой тюнер YellowFin, который на основании знания предыдущей истории изменения градиента, апроксимировал бы нужные для неравенства характеристики поверхности функции ошибки (дисперсия градиента, некая "обощённая" кривизна поверхности и расстояние до локального минимума квадратичной апроксимации текущей точки) и, с помощью этих апроксимаций, выдавал бы подходящие значения learning rate и моментума для использования в SGD.
Также, изучив вопрос асинхронной (распределённой) тренировки сетей, чуваки предложили обобщение своего метода (Closed-loop YellowFin), которое учитывает, что реальный моментум в таких условиях оказывается больше запланированного.
Тестировали свёрточные 110- и 164-слойные ResNet на CIFAR10 и 100 соответственно, и какие-то LSTM на PTB, TS и WSJ. Результаты интересные (от х1.18 до х2.8 ускорения относительно Адама), но, как обычно, есть вопросы к постановке эксперимента — грубый подбор коэффициентов для компетиторов, + емнип, только один прогон на каждую архитектуру, + показаны результаты только тренировочного набора… Короче, есть к чему докопаться...
Как-то так, надеюсь, по деталям не сильно наврал.
Я подумывал запилить его к своей либине, но крепко влип в Self-Normalizing Neural Networks (SELU+AlphaDropout), которыми занялся чуть раньше и которые оказались мне крайне полезны, поэтому пока руки не дошли. Слежу за тем тредом в Lesagne (https://github.com/Lasagne/Lasagne/issues/856 — у человека возникли проблемы с воспроизводством результатов) и вообще, надеюсь, что будет больше инфы по воспроизводству их результатов. Так что если кто попробует — делитесь чокак.
7. The Devil is in the Decoder
→ Оригинал статьи
Автор: ternaus
Вопрос с тем, какой UpSampling лучше для различных архитектур, где есть Decoder, теребит умы многих, особенно тех, кто борется за пятый знак после запятой в задачах сегментации, super resolution, colorization, depth, boundary detection.
Ребята из Гугла и UCL заморочились и написали статью, где эмпирическим путем решили проверить кто лучше и найти в этом логику.
Проверили — выяснилось, что разница есть, но логика не очень просматривается.
Для сегментации:
[1] Transposed Conv = Upsampling + Conv и который все яростно используют в Unet норм.
[2] добрасывание skiped connections, то есть, трансформация SegNet => Unet железобетонно добрасывает. Это интуитивно понятно, но тут есть циферки.
[3] Такое ощущение, что Separable Transposed, которое Transposed, но с меньшим числом параметоров для сегментации, работает лучше. Хотелось бы, чтобы народ в #proj_cars это проверил.
[4] Хитроумный Bilinear additive Upsampling, который они предложили, на сегментации работает примерно как [3]. Но это тоже в сторону коллектива из #proj_cars проверить
[5] Они добрасывают residual connections куда-то, что тоже в теории может что-то добавить, но куда именно — не очень понятно, и добрасывает очень неуверенно и не всегда.
Для задач сегментации они используют resnet 50 как base и потом сверху добавляют decoder.
Для задачи instance boundary detection они решили выбрать метрику, при которой меньше оверфитишь на алгоритм разметки + циферки побольше получаются.
То есть, During the evaluation, predicted contour pixels within three from ground truth pixels are assumed to be correct. Что сразу ставит вопрос о том, как это все переносится на задачи, где важен каждый пиксель. (Тут вспоминается Костин трюк со спутников для поиска заборов толщиной в один пиксель и то, как народ борется за +-1 пиксель на границах в задаче про машинки)
[6] У всех сетей, что они тренируют, у весов используется L2 регуляризация порядка 0.0002
Карпатый, вроде, тоже в свое время говорил, что всегда так делает для более стабильной сходимости. (Это мне надо попробовать, если кто так делает и это дает что-то заметное, было бы неплохо рассказать об этом в тредике)
Summary:
[1] Вопрос о том, кто и когда лучше они подняли, но не ответили.
[2] Они предложили еще один метод делать Upsampling, который работает не хуже других.
[3] Подтвердили, что skipped connection однозначно помогают, а residual — в зависимости от фазы луны.
Ждем месяц, о том, что скажет человеческий GridSearch на #proj_cars.
8. Improving Deep Learning using Generic Data Augmentation
→ Оригинал статьи
Автор: egor.v.panfilov{at}gmail{dot}com
Эпиграф: Лавры китайцев не дают покоя никому, даже на чёрном континенте. Хороших компьютеров, правда, пока не завезли, но Тернаус велел писать, "и вот они продолжают".
Авторы попытались провести бенчмарк методов аугментации изображений на задаче классификации изображений, и выработать рекомендации по их использованию для различных случаев. В первом приближении, данные методы разделить на 2 категории: Generic (общеприменимые) и Complex (использующие информацию о домене / генеративные). В данной статье рассматриваются только Generic.
Все эксперименты в статье проводились на Caltech-101 (101 класс, 9144 изображения) с использованием ZFNet (половина информативной части статьи о том, как лучше всего обучить ванильную ZFNet). Обучали 30 эпох, используя DL4j. Рассматриваемые методы аугментации: (1) без аугмен-ции, (2-4) геометрические: horizontal flipping, rotating (-30deg и +30deg), cropping (4 угловых кропа), (5-7) фотометрические: color jittering, edge enhacement (добавляем к изображению результат фильтра Собеля), fancy PCA (усиливаем principal компоненты на изображениях).
Результаты: к бейзлайну (top1/top5: 48.1%/64.5%) (a) flipping даёт +1/2%, но увеличивает разброс точности, (b) rotating даёт +2%, (с) cropping даёт +14%, (d) color jittering +1.5/2.5%, (d-e) edge enhancement и fancy PCA по +1/2%. Т.е. среди геометрических методов впереди cropping, среди фотометрических — color jittering. В заключении авторы пишут, что существенное улучшение точности при аугментации cropping'ом может быть связано с тем, что датасет получается в 4 раза больше исходного (сбалансировать-то не судьба). Из положительного — не забыли 5-fold кросс-валидацию при оценке точности моделей. Почему были выбраны конкретно эти методы аугментации среди других (в т.ч. более популярных) узнаем, видимо, в следующей статье.
9. Learning both Weights and Connections for Efficient Neural Networks
→ Оригинал статьи
Автор: egor.v.panfilov{at}gmail{dot}com
Статья рассматривает проблему выского потребления ресурсов современными архитектурами DNN (в частности, CNN). Самый главный бич — это обращение к динамической памяти. Например, инференс сети с 1 млрд связей на 20Гц потребляет ~13Вт.
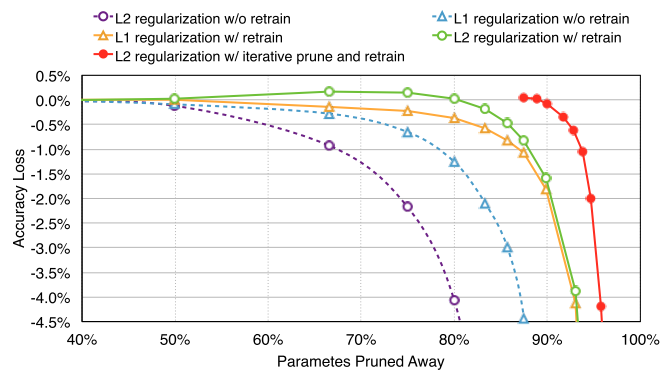
Авторы предлагают метод снижения числа активных нейронов и связей в сети — prunning. Работает следующим образом: (1) обучаем сеть на полном датасете, (2) маскируем связи с весами ниже определённого уровня, (3) дообучаем оставшиеся связи на полном датасете. Шаги (2) и (3) можно и нужно повторять несколько раз, так как агрессивный (за 1 подход) prunning показывает результаты немного хуже (для AlexNet на ImageNet, например, 5x против 9x). Хитрости: использовать L2-регуляризацию весов, при дообучении уменьшать dropout, уменьшать learning rate, прунить и дообучать CONV и FC слои раздельно, выкидывать мёртвые (non-connected) нейроны по результатам шага (2).
Эксперименты производились в Caffe с сетями Lenet-300-100, Lenet-5 на MNIST, AlexNet, VGG-16 на ImageNet. На MNIST: уменьшили число весов и FLOP'ов в 12 раз, а также обнаружили, что prunning проявляет свойство механизма attention (по краям режет больше). На ImageNet: AlexNet обучали 75 часов и дообучали 173 часа, VGG-16 прунили и дообучали 5 раз. По весам удалось сжать в 9 и 13 раз соответственно, по FLOP'ам — в 3.3 и 5 раз. Интересен профиль того, как прунятся связи: первый CONV-слой ужимается меньше чем в 2 раза, следующие CONV — в 3 и более (до 12), скрытые FC — в 10-20 раз, последний FC слой — в 4 раза.
В заключение, авторы приводят результаты сравнения различных методов prunning'а (с L1-, L2-регуляризацией, с дообучением и без, отдельно по CONV, отдельно по FC). Вкратце, есть лень прунить, то учите сеть с L1, и половину слоёв можно просто выкинуть. Если не лень — только L2, прунить и дообучать итеративно ~5 раз. И последнее, хранение весов в sparse виде у авторов давало overhead в ~16% — не то чтобы критично, когда у вас сеть в 10 раз меньше.
10. Focal Loss for Dense Object Detection
→ Оригинал статьи
Автор: kt{at}ut{dot}ee
Как известно, процесс поиска моделей в машинном обучении упирается в оптимизацию некой целевой функции потерь. Самая простая функция потерь — процент ошибок на тренинг-сете, но её оптимизировать сложно и результат статистически плох, поэтому на практике используют разные суррогатные лоссы: квадрат ошибки, минус логарифм вероятности, экспонента от минус скора, hinge loss и т.д. Все суррогатные лоссы являются монотонными функциями, штрафующими ошибки тем больше, чем больше величина ошибки. Любой лосс можно интерпретировать как вид распределения целевой переменной (например, квадрат ошибок соответствует гауссовому распределению).
Авторы работы обнаружили, что суррогатный лосс вида
loss(p, y) := -(1-p)^gamma log(p) if y == 1 else -p^gamma log(1-p)
ещё нигде не использовался и не публиковался. Зачем нужно использовать именно такой лосс, а не ещё какой-нибудь, и каков смысл подразумеваемого распределения, авторы не знают, но им он кажется прикольным, т.к. здесь есть лишний параметр gamma, с помощью которого можно как будто бы подкручивать величину штрафа "легким" примерам. Авторы назвали эту функцию "focal loss".
Авторы подобрали один набор данных и одну модель-нейросеть на которых, если подогнать значения параметра, в табличке результатов виден якобы некий положительный эффект от использования такого лосса вместо обычной кросс-энтропии (взвешенной по классам). На самом деле, большая часть статьи жует вопросы применения RetinaNet для детекции объектов, не сильно зависящие от выбора лосс-функции.
Статья обязательна к прочтению всем начинающим свой путь в академии, т.к. она прекрасно иллюстрирует то, как писать убедительно-смотрящиеся публикации, когда в голове вообще нет хороших идей.
Альтернативное мнение
Следи за руками: чуваки взяли один из стандартных, довольно сложных датасетов, на которых меряются в детекции, взяли простенькую сеть без особых наворотов (то из чего все другие уже пробовали выжать сколько могли), приложили свой лосс и получили сходу результат single model без мультскейла и прочих трюков выше чем все остальные на этом датасете, включая все сети в одну стадию и более продвинутые двухстадийные. Чтобы убедиться, что дело в лоссе, а не чём-то ещё, они попробовали другие варианты, которые до этого были крутыми и модными техниками — балансирование кросс-энтропии, OHEM и получили результат стабильно выше на своём. Покрутили параметры своего и нашли вариант, который работает лучше всех и даже попробовали чуток объяснить почему (там есть график, где видно что гамма ниже 2 даёт довольно гладкое распределение, а больше двух уж очень резко штрафует (даже при двух там практически полка, удивительно что работает)).
Конечно, можно было им начать сравнивать 40 вариантов сетей, с миллионом вариантов гиперпараметров и на всех известных датасетах, да ещё и кроссвалидацию 10 раз по 10 фолдов, но сколько бы это времени тогда заняло и когда была бы публикация готова и сколько бы там было разных идей?
Тут всё просто — изменили один компонент, получили результат превосходящий SoTA на конкретном датасете. Убедились, что результат вызван изменением, а не чем-то ещё. Fin.
Альтернативное мнение
Наверное, стоит добавить, что если бы статья позиционировалась как представление RetinaNet, она бы смотрелась, по-моему, совсем по-другому. Она ведь и построена на самом-то деле в основном как пример применения RetinaNet. Зачем в неё внезапно вставили упор на лосс и странный заголовок, мне лично непонятно. Объективных замеров, подтверждающих высказанные про этот лосс тезисы там всё-таки нет.
Может быть, например, RetinaNet планируется опубликовать в более серьезном формате и с другим порядком авторов, а это — просто продукт стороннего эксперимента, который тоже решили лишней публикацией оформить потому что студент ведь работал и молодец. В таком случае это опять же пример того, как высосать лишнюю статью из воздуха.
В любом случае, я для себя никак не могу вынести из этой статьи обещанный в заглавии и тексте тезис "вкручивайте такой лосс везде и будет вам счастье".
Тезис "RetinaNet хорошо работает на COCO (с любым лоссом, причем!)" я, при этом, вынести вполне могу.
11. Borrowing Treasures from the Wealthy: Deep Transfer Learning through Selective Joint Fine-tuning
→ Оригинал статьи
→ Код
Автор: movchan74
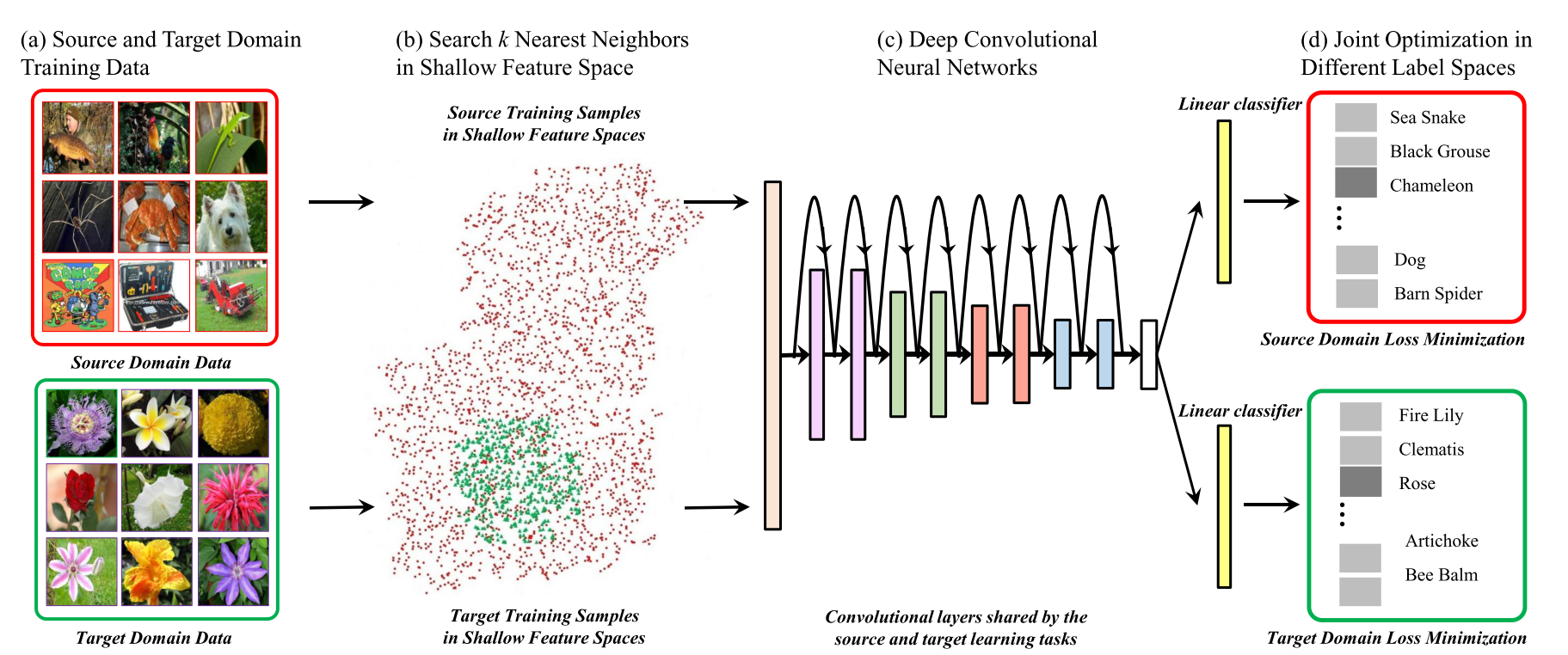
Авторы сосредоточились на проблеме классификации изображений с небольшим датасетом. Типичный подход в таком случае следующий: взять предобученную CNN на ImageNet и дообучить на своем датасете (или даже дообучить только классификационные полносвязный слои). Но при этом сеть быстро переобучается и достигает не таких значений точности, каких хотелось бы. Авторы предлагают использовать не только целевой датасет (target dataset, мало данных, далее буду называть датасет T), но и дополнительный исходный датесет (source dataset, далее буду называть датасет S) с большим количеством изображений (обычно ImageNet) и обучать мультитаск на двух датасетах одновременно (делаем после CNN две головы по одной на датасет).
Но как выяснили авторы, использование всего датасета S для обучения не очень хорошая идея, лучше использовать некоторое подмножество датасета S. И далее в статье предлагаются различные способы поиска оптимального подмножества.
Получаем следующий фреймворк:
- Берем два датасета: S и T. T — датасет с малым количеством примеров, для которого нам необходимо получить классификатор, S — большой вспомогательный датасет (обычно ImageNet).
- Выбираем подмножество изображений из датасета S, такое, что изображения из подмножества близки к изображениям из целевого датасета T. Как именно выбирать близкие рассмотрим далее.
- Учим мультитаск сеть на датасете T и выбранном подмножесте S.
Рассмотрим как предлагается выбирать подмножество датасета S. Авторы предлагают для каждого семпла из датасета T находить некоторое количество соседей из S и учиться только на них. Близость определяется как расстояние между гистограммами низкоуровневых фильтров AlexNet или фильтров Габора. Гистограммы берутся, чтобы не учитывать пространственную составляющую.
Объяснение, почему берутся низкоуровневые фильтры, приводится следующее:
- Получается лучше обучить низкоуровневые сверточные слои за счет большего количества данных, а качество этих низкоуровневых фич определяет качество фич более высоких уровней.
- Поиск похожих изображений по низкоуровневым фильтрам позволяет находить намного больше семплов для тренировки, т.к. семантика почти не учитывается.
Мне, если честно, эти объяснения не очень нравятся, но в статье так. Может я конечно что-то не понял или понял не так. Это все описано на 2 странице после слов "The motivation behind selecting images according to their low-level characteristics is two fold".
Еще из особенностей поиска близких изображений:
- Гистограммы строятся так, чтобы в среднем по всему датасету в один бин попадало примерно одинаковое количество.
- Расстояние между гистограммами считается с помошью KL-дивергенции.
Авторы попробовали разные сверточные слои AlexNet и фильтры Габора для поиска близких семплов, лучше всего получилось если использовать 1+2 сверточные слои из AlexNet.
Также авторы предложили итеративный способ подбора количества похожих семплов из датасета S для каджого семпла из T. Изначально берем некоторое заданое число ближайших соседей для каждого отдельного семпла из T. Затем прогоняем обучение, и если ошибка для семпла большая, то увеличиваем количество ближайших соседей для этого семпла. Как именно производится увеличение ближайших соседей понятно из уравнения 6.
Из особенностей обучения. При формировании батча случайно выбираем семплы из датасета T, и для каждого выбранного семпла берем одного из его ближайших соседей.
Проведены эксперименты на следующих датасетах: Stanford Dogs 120, Oxford Flowers 102, Caltech 256, MIT Indoor 67. На всех датасетах получены SOTA результаты. Получилось поднять точность классфикации от 2 до 10% в зависимости от датасета.
12. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
→ Оригинал статьи
→ Код
Автор: repyevsky{at}gmail{dot}com
Статья про мета-обучение: авторы хотят научить модель объединять свой предыдущий опыт с малым количеством новой информации для решения новых заданий из некоторого общего класса.
Чтобы было понятно чего хотят добиться авторы, расскажу как оценивается модель.
В качество бенчмарка для классификации используются два датасета: Omniglot и miniImagenet. В первом рукописные буквы из нескольких алфавитов — всего около 1600 классов, 20 примеров на класс. Во втором 100 классов из Imagenet — по 600 картинок на класс. Ещё есть раздел про RL, но его я не смотрел.
Перед обучением все классы разбиваются на непересекающиеся множества train, validation и test. Для проверки, из test-классов (которые модель не видела при обучении) выбирается, например, 5 случайных классов (5-way learning). Для каждого из выбранных классов сэмплится несколько примеров, лейблы кодируются one-hot вектором длины 5. Дальше примеры для каждого класса делятся на две части A и B. Примеры из A показываются модели с ответами, а примеры из B используются для проверки точности классификации. Так формируется задание. Авторы смотрят на accuracy.
Таким образом, нужно научить модель адаптироваться к новому заданию (новому набору классов) за несколько итераций/новых примеров.
В отличии от предыдущих работ, где для этого пытались использовать RNN или feature embedding с непараметрическими методами на тесте (вроде k-ближайших соседей), авторы предлагают подход, позволяющий настроить параметры любой стандартной модели, если она обучается градиентными методами.
Ключевая идея: обновлять веса модели так, чтобы она давала лучший результат на новых заданиях.
Интуиция: внутри модели получатся универсальные для всех классов датасета представления входных данных, по которым модель сможет быстро подстроиться под новое задание.
Суть в следующем. Пусть мы хотим, чтобы наша модель F(x, p) обучалась новому заданию за 1 итерацию (1-shot learning). Тогда для обучения нужно из тренировочных классов подготовить такие же задания как на тесте. Дальше на примерах из части A мы считаем loss, его градиент и делаем одну итерацию обучения — в итоге получаем промежуточные обновленные веса p' = p - a*grad и новую версию модели — F(x, p'). Считаем loss для F(x, p') на B и минимизируем его относительно исходных весов p. Получаем настоящие новые веса — конец итерации. Когда считается градиент от градиента :xzibit:, появляются вторые производные.
На самом деле, генерируется сразу несколько заданий, объединеных в metabatch. Для каждого находится свой p' и считается свой loss. Потом все эти loss суммируются в total_loss, который уже минимизируется относительно p.
Авторы применили свой подход к базовым моделям из предыдущих работ (маленькие сверточная и полносвязная сети) и получили SOTA на обоих датасетах.
При этом, итоговая модель получается без дополнительных параметров для мета-обучения. Зато используется большое количество вычислений, в том числе из-за вторых производных. Авторы пробовали отбросить вторые производные на miniImagenet. При этом accuracy осталась почти такой же, а вычисления ускорились на 33%. Предположительно это связано с тем, что ReLU — кусочно-линейная функция и вторая производная у неё почти всегда нулевая.
Код авторов на Tensorflow. Там внутренний градиентый шаг делается вручную, а внешний с помощью AdamOptimizer.
За редактуру спасибо yuli_semenova.
