
Привет, Коллеги!
27 июня закончилось соревнование на Kaggle по подсчёту морских львов (сивучей) на аэрофотоснимках NOAA Fisheries Steller Sea Lions Population Count. В нем состязались 385 команд. Хочу поделиться с вами историей нашего участия в челлендже и (почти) победой в нём.
Небольшое лирическое отступление.
Как многие уже знают, Kaggle – это платформа для проведения онлайн соревнований по Data Science. И в последнее время там стало появляться всё больше и больше задач из области компьютерного зрения. Для меня этот тип задач наиболее увлекателен. И соревнование Steller Sea Lions Population Count — одно из них. Я буду повествовать с расчётом на читателя, который знает основы глубокого обучения применительно к картинкам, поэтому многие вещи я не буду детально объяснять.
Пару слов о себе. Я учусь в аспирантуре в университете города Хайдельберг в Германии. Занимаюсь исследованиями в области глубокого обучения и компьютерного зрения. Страничка нашей группы CompVis.
Захотелось поучаствовать в рейтинговом соревновании на Kaggle с призами. На это дело мной был также подбит Дмитрий Котовенко , который в это время проходил учебную практику в нашей научной группе. Было решено участвовать в соревновании по компьютерному зрению.
На тот момент у меня был некий опыт участия в соревнованиях на Kaggle, но только в нерейтинговых, за которые не дают ни медалей, ни очков опыта (Ranking Points). Но у меня был довольно обширный опыт работы с изображениями с помощью глубокого обучения. У Димы же был опыт на Kaggle в рейтинговых соревнованиях, и была 1 бронзовая медаль, но работать с компьютерным зрением он только начинал.
Перед нами встал нелёгкий выбор из 3 соревнований: предсказание рака матки на медицинских изображениях, классификация спутниковых изображений из лесов Амазонии и подсчёт сивучей на аэрофотоснимках. Первое было отброшено из-за визуально не очень приятных картинок, а между вторым и третьим было выбрано третье из-за более раннего дедлайна.
Постановка задачи
В связи со значительным уменьшением популяции сивучей на западных Алеутских островах (принадлежащих США) за последние 30 лет ученые из NOAA Fisheries Alaska Fisheries Science Center ведут постоянный учет количества особей с помощью аэрофотоснимков с дронов. До этого времени подсчет особей производился на фотоснимках вручную. Биологам требовалось до 4 месяцев, чтобы посчитать количество сивучей на тысячах фотографий, получаемых NOAA Fisheries каждый год. Задача этого соревнования — разработать алгоритм для автоматического подсчета сивучей на аэрофотоснимках.
Все сивучи разделены на 5 классов:
- adult_males — взрослые самцы (
 ),
), - subadult_males – молодые самцы (
 ),
), - adult_females – взрослые самки (
 ),
), - juveniles – подростки (
 ),
), - pups – детёныши (
 ).
).
 ),
), ),
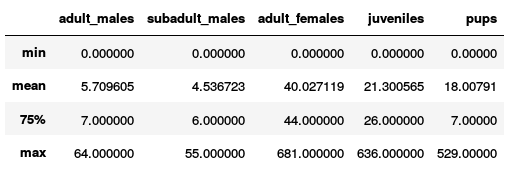
),Дано 948 тренировочных картинок, для каждой из которых известно Ground Truth число особей каждого класса. Требуется предсказать число особей по классам на каждой из 18641 тестовых картинок. Вот пример некоторых частей из датасета.

Картинки разных разрешений: 4608x3456 до 5760x3840. Качество и масштаб очень разнообразный, как видно из примера выше.
Положение на лидерборде определяется ошибкой RMSE, усредненной по всем тестовым изображениям и по классам.
Как бонус организаторы предоставили копии тренировочных изображений с сивучами, помеченными точками разного цвета. Каждый цвет соответствовал определенному классу. Все эти точки были кем-то размечены вручную (я надеюсь, биологами), и они не всегда находились чётко в центре животного. То есть, по факту, мы имеем грубую позицию каждой особи, заданную одной точкой. Выглядит это так.

(image credits to bestfitting)
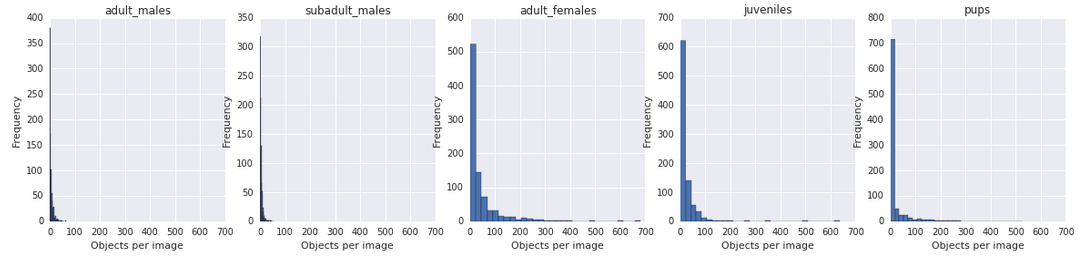
Самые частые классы сивучей — это самки ( ), подростки (
), подростки ( ) и детеныши (
) и детеныши ( ).
).
Проблемы
Здесь я кратко перечислю, какие были проблемы с данными, да и с задачей в целом.
- Зашумленность разметки. Не на всех тренировочных картинках были размечены все сивучи (часто биологи пропускали тех, что плавают в воде).
- Нет чёткого разделение между парами классов adult_males и subadult_males, adult_females и juveniles. Мы не всегда даже глазами можем понять где самка, а где подросток. Та же проблема со взрослыми и молодыми самцами. На вопрос “как вы их размечали?” биолог из NOAA ответил на форуме, что часто отличать классы приходилось только по поведенческим признакам. Например, взрослые самцы часто окружены множеством самок (сивучи живут гаремами), а молодые, еще не успешные, вынуждены одиноко ютиться в отдалении от всех.
- Детенышей бывает затруднительно отличить от мокрого камня. Они в разы меньше, чем другие особи.
- Нет segmentation масок — только грубая позиция животных. Лобовой подход на сегментацию объектов не применим.
- Разные масштабы изображений в целом. В том числе, на глаз, масштаб на тренировочных изображениях меньше чем в тестовых.
- Задача подсчёта случайных объектов (не людей) не очень освещена в научных статьях. Обычно все считают людей на фотографиях. Про животных, а тем более из нескольких классов, публикаций найдено не было.
- Огромное количество тестовых картинок (18641) большого разрешения. Предсказание занимало от 10 до 30 часов на одном Titan X.
Причем, большая часть из тестовых картинок добавлена исключительно в целях избежания того, что участники будут вручную аннотировать тест. То есть предсказания на некоторых из них никак не влияли на финальный счёт.
Как мы решали
В Германии, как и в России, в этом году выпали большие выходные на 1 Мая. Свободные дни с субботы по понедельник оказались как никогда кстати для того, чтобы начать погружаться в задачу. Соревнование длилось уже больше месяца. Всё началось с того, что мы с Димой Котовенко в субботу прочитали условие.
Первое впечатление было противоречивым. Много данных, нету устоявшегося способа, как решать такие задачи. Но это подогревало интерес. Не всё ж "стакать xgboost-ы”. Цель я поставил себе довольно скромную — просто попасть в топ-100 и получить бронзовую медальку. Хотя потом цели поменялись.
Первых 3 дня ушло на обработку данных и написание первой версии пайплайна. Один добрый человек, Radu Stoicescu, выложил кернел, который преобразовывал точки на тренировочных изображениях в координаты и класс сивуча. Здорово, что на это не пришлось тратить своё время. Первый сабмит я сделал только через неделю после начала.
Очевидно, решать эту задачу в лоб с помощью semantic segmentation нельзя, так как нет Ground Truth масок. Нужно либо генерить грубые маски самому либо обучать в духе weak supervision. Хотелось начать с чего-то попроще.
Задача подсчёта числа объектов/людей не является новой, и мы начали искать похожие статьи. Было найдено несколько релевантных работ, но все про подсчёт людей CrowdNet, Fully Convolutional Crowd Counting, Cross-scene Crowd Counting via Deep Convolutional Neural Networks. Все они имели одну общую идею, основанную на Fully Convolutional Networks и регрессии. Я начал с чего-то похожего.
Идея crowd counting на пальцах
Хотим научиться предсказывать хитмапы (2D матрицы) для каждого класса, да такие, что бы можно было просуммировать значения в каждом из них и получить число объектов класса.
Для этого генерируем Grount Truth хитмапы следующим образом: в центре каждого объекта рисуем гауссиану. Это удобно, потому что интеграл гауссианы равен 1. Получаем 5 хитмапов (по одному на каждый из 5 классов) для каждой картинки из тренировочной выборки. Выглядит это так.

Увеличить
Среднеквадратичное отклонение гауссиан для разных классов выставил на глазок. Для самцов – побольше, для детенышей – поменьше. Нейронная сеть (тут и далее по тексту я имею в виду сверточную нейронную сеть) принимает на вход изображения, нарезанные на куски (тайлы) по 256x256 пикселей, и выплёвывает 5 хитмапов для каждого тайла. Функция потерь – норма Фробениуса разности предсказанных хитмапов и Ground Truth хитмапов, что эквивалентно L2 норме вектора, полученного векторизацией разности хитмапов. Такой подход иногда называют Density Map Regression. Чтобы получить итоговое число особей в каждом классе, мы суммируем значения в каждом хитмапе на выходе.
| Метод | Public Leaderboard RMSE |
|---|---|
| Baseline 1: предсказать везде 0 | 29.08704 |
| Baseline 2: предсказать везде среднее по train | 26.83658 |
| Мой Density Map Regression | 25.51889 |
Моё решение, основанное на Density Map Regression, было немного лучше бейзлайна и давало 25.5. Вышло как-то не очень.

В задачах на зрение, бывает очень полезно посмотреть глазами на то, что породила ваша сеть, случаются откровения. Я так и сделал. Посмотрел на предсказания сети — они вырождаются в нуль по всем классам, кроме одного. Общее число животных предсказывалось ещё куда ни шло, но все сивучи относились сетью к одному классу.
Оригинальная задача, которая решалась в статьях — это подсчет количества людей в толпе, т. е. был только один класс объектов. Вероятно, Density Map Regression не очень хороший выбор для задачи с несколькими классами. Да и всё усугубляет огромная вариация плотности и масштаба объектов. Пробовал менять L2 на L1 функцию потерь и взвешивать классы, всё это не сильно влияло на результат.
Было ощущение, что L2 и L1 функции потерь делают что-то не так в случае взаимоисключающих классов, и что попиксельная cross-entropy функция потерь может работать лучше. Это натолкнуло меня на идею натренировать сеть сегментировать особей с попиксельной cross-entropy функцией потерь. В качестве Ground Truth масок я нарисовал квадратики с центром в ранее полученных координатах объектов.
Но тут появилась новая проблема. Как получить количество особей из сегментации? В чатике ODS Константин Лопухин признался, что использует xgboost для регрессии числа сивучей по набору фич, посчитанных по маскам. Мы же хотели придумать как сделать всё end-to-end с помощью нейронных сетей.
Тем временем, пока я занимался crowd counting и сегментацией, у Димы заработал простой как апельсин подход. Он взял VGG-19, натренированную на классификации Imagenet, и зафайнтьюнил ее предсказывать количество сивучей по тайлу. Он использовал обычную L2 функцию потерь. Получилось как всегда — чем проще метод, тем лучше результат.
Итак, стало понятно, что обычная регрессия делает свое дело и делает хорошо. Идея с сегментацией была радостно отложена до лучших времен. Я решил обучить VGG-16 на регрессию. Присобачил в конце выходной слой для регрессии на 5 классов сивучей. Каждый выходной нейрон предсказывал количество особей соответствующего класса.
Я резко вышел в топ-20 c RMSE 20.5 на паблик лидерборде.

К этому моменту целеполагание претерпело небольшие изменения. Стало понятно, что целиться имеет смысл не в топ-100, а как минимум в топ-10. Это уже не казалось чем-то недостижимым.
Выяснилось, что на test выборке многие снимки были другого масштаба, сивучи на них выглядели крупнее, чем на train. Костя Лопухин (отдельное ему за это спасибо) написал в слаке ODS, что уменьшение тестовых картинок по каждой размерности в 2 раза давало существенный прирост на паблик лидерборде.
Но Дима тоже не лыком шит, он подкрутил что-то в своей VGG-19, уменьшил картинки и вышел на 2-e место со скором ~16.
Подбор архитектуры и гиперпараметров сети

(image credits to Konstantin Lopuhin)
С функцией потерь у нас всё понятно. Время начинать экспериментировать с более глубокими сетями. В ход пошли VGG-19, ResnetV2-101, ResnetV2-121, ResnetV2-152 и тяжелая артиллерия — Inception-Resnet-V2.
Inception-Resnet-V2 — это архитектура придуманная Google, которая представляет собой комбинацию трюков от Inception архитектур (inception блоки) и от ResNet архитектур (residual соединения). Эта сеть изрядно глубже предыдущих и выглядит этот монстр вот так.
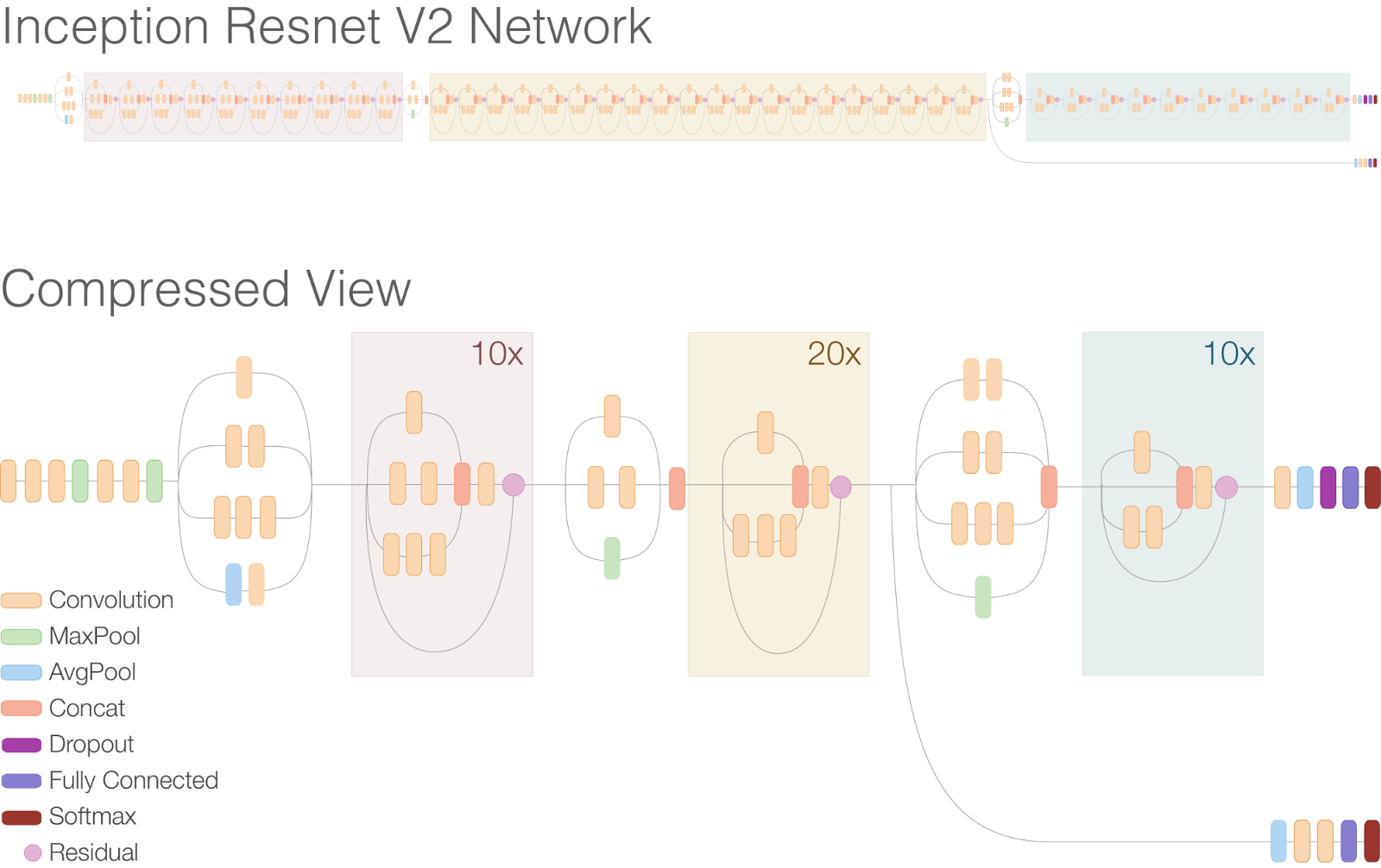
(image from research.googleblog.com)
В статье "Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning" ребята из Google показывают, что эта архитектура давала на тот момент state of the art на Imagenet без использования ансамблей.
Кроме самих архитектур мне пришлось перебрать:
- различные размеры входного тайла: от 224x224 до 512x512 пикселей;
- тип пулинга после свёрточных слоёв: sum-pooling или average-pooling;
- количество дополнительных FC-слоёв перед финальным: 0, 1 или 2;
- количество нейронов в дополнительных FC-слоях: 128 или 256.
Лучшей комбинацией оказались: Inception-Resnet-V2-BASE + average-pooling + FC-слой на 256 нейронов + Dropout + финальный FC-слой на 5 нейронов. Inception-Resnet-V2-BASE обозначает часть оригинальной сети от первого до последнего сверточного слоя.
Лучшим размером входного тайла оказался 299x299 пикселей.
Аугментации изображений
Для тренировочных картинок мы делали типичный набор аугментаций для задач из CV.
К каждому тайлу применялись:
- Случайные флипы слева направо и сверху вниз;
- случайные вращения на углы, кратные 90 градусов;
- случайное масштабирование в 0.83 — 1.25 раза.
Цвет мы не аугментировали, так как это довольно скользкая дорожка. Зачастую сивучей отличить от ландшафта можно было только по цвету.
Test time augmentation мы не делали. Потому что предсказание на всех тестовых картинках и так занимало полдня.
Продолжение истории
В какой-то момент, пока я перебирал гиперпараметры и архитектуры сетей, мы объединились в команду с Димой Котовенко. Я в тот момент был 2-м месте, Дима на 3-м. Для отвода китайцев в ложном направлении команду назвали "DL Sucks".

Объединились, потому что было бы нечестно у кого-то забирать медальку, ведь с Димой мы активно обсуждали наши решения и обменивались идеями. Этому событию очень порадовался Костя, мы освободили ему призовое место. С 4-го он попал на 3-е.
Последние 3-4 недели соревнования мы плотно держались на 2-м месте на паблик лидерборде, по одной десятой, по одной тысячной улучшая скор перебором гиперпараметров и стакая модели.
Нам казалось, что уменьшение в 2 раза всех тестовых изображений — это пошло и грубо. Хотелось сделать всё красиво, чтобы сеть предсказала как нужно отмасштабировать каждое из изображений. Дима инвестировал в эту идею довольно много времени. Если вкратце, то он пытался по картинке предсказать масштаб сивучей, что равносильно предсказанию высоты полета дрона во время съемки. К сожалению, из-за недостатка времени и ряда проблем, с которыми мы столкнулись, это не было доведено до конца. Например, многие картинки содержат только одного сивуча и большая часть пространства — это море и камни. Поэтому, не всегда, глядя только на скалы или море, возможно понять с какой высоты был сделан снимок.
За пару дней до дедлайна мы собрали все лучшие модели и сделали ансамбль из 24 нейронных сетей. Все модели имели лучшую архитектуру Inception-Resnet-V2, которую я описал ранее. Отличались модели только тем, насколько агрессивно мы аугментировали картинки, на каком масштабе тестовых изображений делались предсказания. Выходы с разных сетей усреднялись.
Команда "DL Sucks" закончила соревнование на 2-м месте на паблик лидерборде, что не могло не радовать, так как мы были "в деньгах". Мы понимали, что на прайвэт лидерборде всё может поменяться и нас вообще может выкинуть из первой десятки. У нас был приличный разрыв с 4-м и 5-м местом, и это добавляло нам уверенности. Вот так выглядело положение на лидерборде:
1-е место 10.98445 outrunner (Китаец 1)
2-е место 13.29065 Мы (DL Sucks)
3-е место 13.36938 Костя Лопухин
4-е место 14.03458 bestfitting (Китаец 2)
5-е место 14.47301 LeiLei-WeiWei (Команда из двух китайцев)
Оставалось дождаться финальных результатов...
И что бы вы думали? Китаец нас обошел! Мы были сдвинуты со 2-го на 4-ое место. Ну ничего, зато получили по золотой медали ;)
Первое место, как оказалось, занял другой китаец, альфа-гусь outrunner. И решение у него было почти как у нас. Обучил VGG-16 c дополнительным полносвязным слоем на 1024 нейрона предсказывать количество особей по классам. Что вывело его на первое место, так это ad-hoc увеличение количества подростков на 50% и уменьшение количества самок на такое же число, умножение количества детёнышей на 1.2. Такой трюк поднял бы нас на несколько позиций выше.
Финальное положение мест:
1-е место 10.85644 outrunner (Китаец 1)
2-е место 12.50888 Костя Лопухин
3-е место 13.03257 (Китаец 2)
4-е место 13.18968 Мы (DL Sucks)
5-е место 14.47301 Дмитро Поплавский (тоже в слаке ODS) в команде с 2 другими
Пару слов о других решениях
Резонный вопрос — а нельзя ли натренировать детектор и посчитать потом баундинг боксы каждого класса? Ответ — можно. Некоторые парни так и сделали. Александр Буслаев (13-ое место) натренировал SSD, а Владимир Игловиков (49-ое место) — Faster RCNN.
Пример предсказания Владимира:

(image credits to Vladimir Iglovikov)
Минус такого подхода состоит в том, что он сильно ошибается, когда сивучи на фотографии очень плотно лежат друг к другу. А наличие нескольких различных классов еще и усугубляет ситуацию.
Решение, основанное на сегментации с помощью UNet, тоже имеет место быть и вывело Константина на 2 место. Он предсказывал маленькие квадратики, которые он нарисовал внутри каждого сивуча. Далее — танцы с бубном. По предсказанным хитмапам Костя вычислял различные фичи (площади выше заданных порогов, количество и вероятности блобов) и скармливал их в xgboost для предсказания числа особей.

(image credits to Konstantin Lopuhin)
Подробнее про его решение можно посмотреть на youtube.
У 3-го места (bestfitting) тоже решение основано на UNet. Опишу его в двух словах. Парень разметил вручную сегментационные маски для 3 изображений, обучил UNet и предсказал маски на еще 100 изображениях. Поправил маски этих 100 изображений руками и заново обучил на них сеть. С его слов, это дало очень хороший результат. Вот пример его предсказания.

(image credits to bestfitting)
Для получения числа особей по маскам он использовал морфологические операции и детектор блобов.
Заключение
Итак, начальная цель была попасть хотя бы в топ-100. Цель мы выполнили и даже перевыполнили. Было перепробовано много всяких подходов, архитектур и аугментаций. Оказалось, проще метод – лучше. А для сетей, как ни странно, глубже — лучше. Inception-Resnet-V2 после допиливания, обученная предсказывать количество особей по классам, давала наилучший результат.
В любом случае это был полезный опыт создания хорошего решения новой задачи в сжатые сроки.
В аспирантуре я исследую в основном Unsupervised Learning и Similarity Learning. И мне, хоть я и занимаюсь компьютерным зрением каждый день, было интересно поработать с какой-то новой задачей, не связанной с моим основным направлением. Kaggle дает возможность получше изучить разные Deep Learning фреймворки и попробовать их на практике, а также поимплементировать известные алгоритмы, посмотреть как они работают на других задачах. Мешает ли Kaggle ресерчу? Вряд ли он мешает, скорее помогает, расширяет кругозор. Хотя времени он отнимает достаточно. Могу сказать, что проводил за этим соревнованием по 40 часов в неделю (прямо как вторая работа), занимаясь каждый день по вечерам и на выходных. Но оно того стоило.
Кто дочитал, тому спасибо за внимание и успехов в будущих соревнованиях!
Мой профиль на Kaggle: Artem.Sanakoev
Краткое техническое описание нашего решения на Kaggle: ссылка
Код решения на github: ссылка
