
Привет, Хабр! Мы продолжаем нашу традицию и снова выпускаем ежемесячный набор рецензий на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество ODS!
Статьи выбираются либо из личного интереса, либо из-за близости к проходящим сейчас соревнованиям. Напоминаем, что описания статей даются без изменений и именно в том виде, в котором авторы запостили их в канал #article_essence. Если вы хотите предложить свою статью или у вас есть какие-то пожелания — просто напишите в комментариях и мы постараемся всё учесть в дальнейшем.
Статьи на сегодня:
- Machine Learning: An Applied Econometric Approach
- Squeeze-and-Excitation Networks
- Improved Variational Autoencoders for Text Modeling using Dilated Convolutions
- Training RNNs as Fast as CNNs
- Transforming Auto-encoders
- A Relatively Small Turing Machine Whose Behavior Is Independent of Set Theory
- Analysis of telomere length and telomerase activity in tree species of various life-spans, and with age in the bristlecone pine Pinus longaeva
- Outrageously Large Neural Networks: The Sparsely-gated Mixture-of-experts Layer
- The Consciousness Prior
1. Machine Learning: An Applied Econometric Approach
→ Оригинал статьи
Автор: dr_no
Вступление
Про важность ML и т.д. и т.п., есть ссылки на публикации про интро в ML, Big Data и экономику, LASSO с точки зрения эконометристов и данных высоких размерностей. Про разницу и связь parameter estimation vs prediction в задачах регрессии.
How Machine Learning Works
Постановка задачи supervised machine learning, сравнение работы метода наименьших квадратов, регрессионного дерева (regression tree), LASSO, random forest'а (из 700 деревьев), про оверфит/кроссвалидацию/кфолды.
Оценка результатов работы разных подходов:
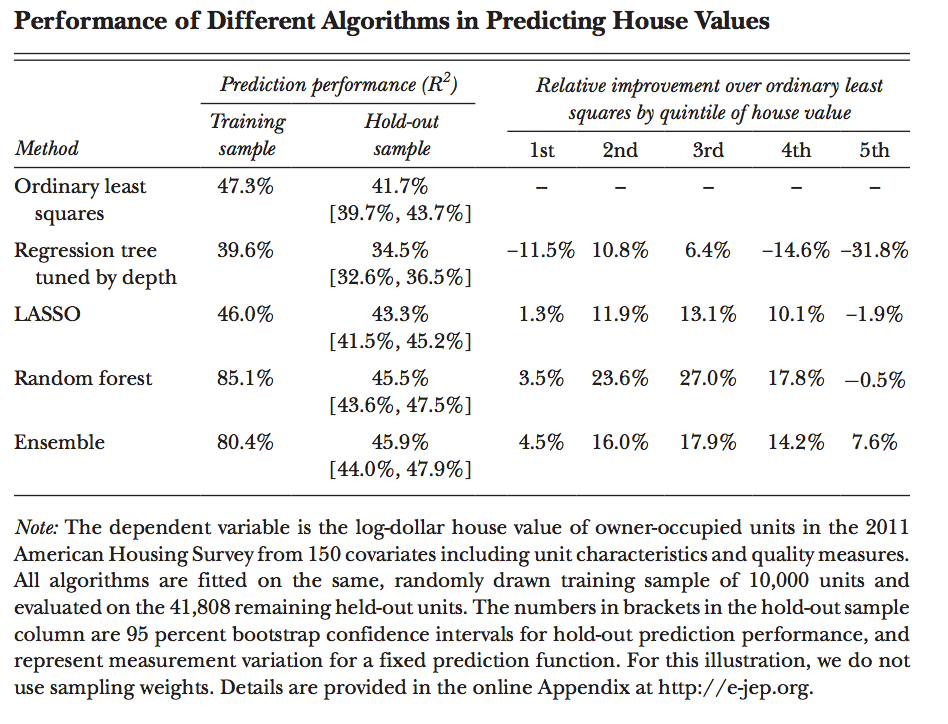
Дальше проходятся по идее регуляризации, эмперической подкрутке параметров модели.
Дальше про применение к экономическим задачам:
0) выбор модели;
1) подготовка/трансформация данных;
2) важность производных фич (соотношение площади к количеству комнат, etc) при условии регуляризации, сложность при вычислении большого количества подобных и прочее;
3) тюнинг, тут подводится идея, что эконометрика может помочь, с одной стороны, помогая делать design choices (количество фолдов, вид функции предсказания), а с другой — помогая определить итоговое качество соответствия предсказаний (second, given the fitted prediction function, it must enable us to make inferences about estimated fit. The hold-out sample exactly allows us to form properly sized tests about predictive properties of the fitted function);
What Do We (Not) Learn from Machine Learning Output
Про бессмысленность попыток найти закономерности моделируемого процесса на основании функции предсказания. Если при предсказании цены дома, переменная N кухонь не задействована, означает ли это, что этот фактор не важен? Подобные выводы некорректны.
Проблема подобных выводов — отсутствие стандартной ошибки коэффициентов. Даже с моделью, результатом которой является линейная функция, это составляет проблему, потому что причина может крыться в самом выборе модели.
Еще одним примером подобной проблемы идет повторное построение 10 моделей аналогичных исходной (LASSO predictor) с сравнивым качество на подмножестве исходных данных.
Причина вышеизложенного — корреляция, взаимозаменяемость фичей; итоговый выбор зависит от данных. Далее говорится, что в традиционном подходе, корелляция в наблюдаемых значениях отразилась бы в большой стандартной ошибке предписания итогового влияния той или иной переменной.
В ML же мы можем получить огромное количество разных функций и разные коэффициенты будут давать сравнимое качество предсказаний. Регуляризация только подливает масла в огонь, заставляя нас выбирать менее сложные, а значит, и более неправильные модели, приводя с собой систематические ошибки опущенных переменных (omitted variable bias).
Все-таки иногда модели могут давать пищу для размышлений о природе моделируемых вещей.
Ну и дальше много вдохновительных речей на тему применения ML, Big Data, спутниковых снимков для решения абсолютно, казалось бы, не связанных задач (освещение ночью и экономические показатели), приводятся подобные задачи в других прикладных областях, выводы к ним. Например, задача решения судьи: после задержания, судья должен решить, будет ли подсудимый ждать слушания дома или за решеткой.
Сомнительные мысли на тему supervised ML с точки зрения пользы для эконометристов. Из того, что понравилось:
1) Итоговые веса и результирующая функция не особо пока говорят о underlying problem;
2) Сводная таблица моделей и регуляризации;
3) Некоторые референсы;
4) Факт выбора "за решетку/домой" судьей.
Читать особо не советовал бы, но если у вас в окружении есть кто-то из эконометристов, кто не видит ценности в ML, можно было бы подсунуть ему эту статью.
2. Squeeze-and-Excitation Networks (победитель ImageNet 2017)
→ Оригинал статьи
Автор: kostia
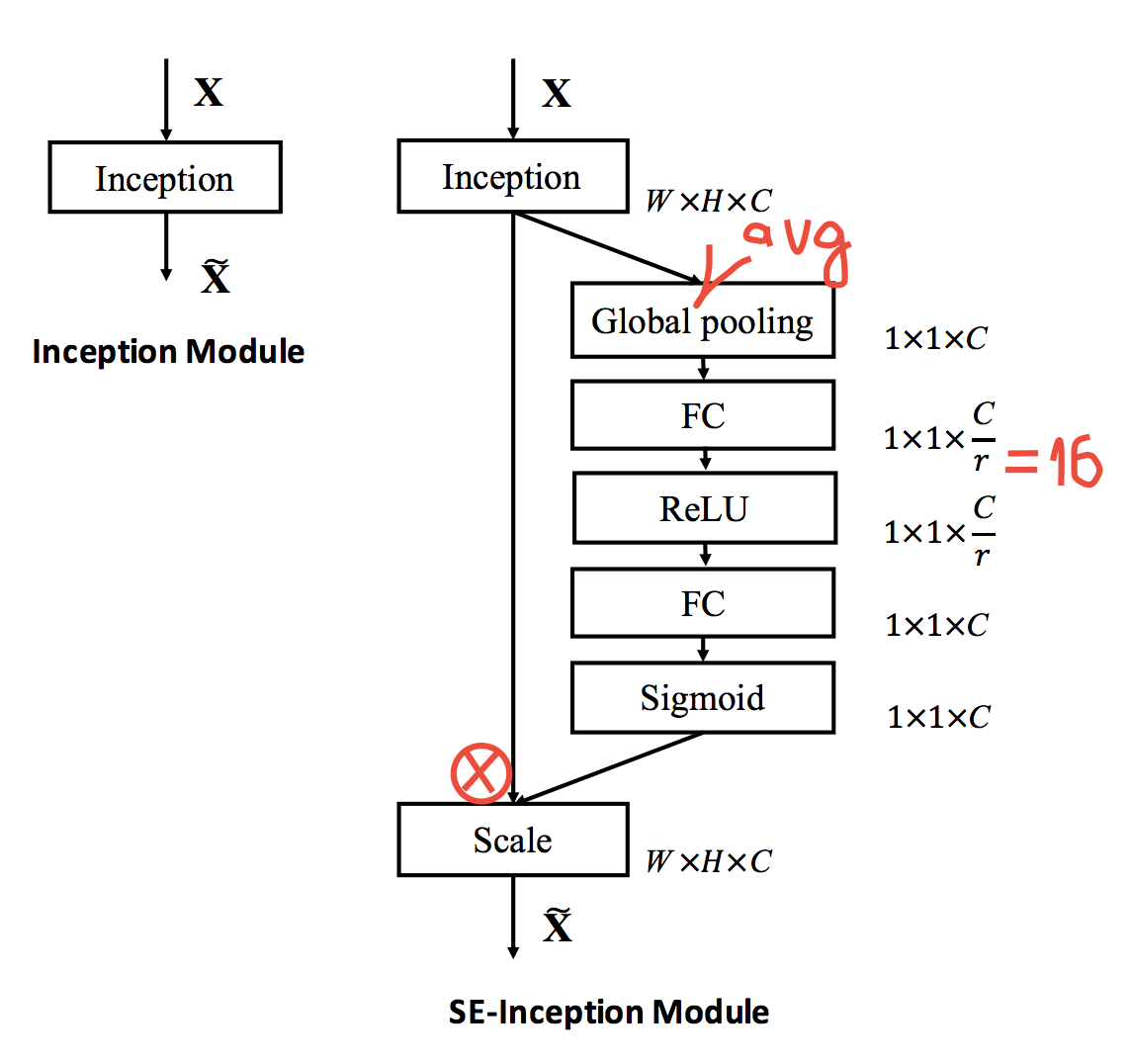
В наши любимые ResNet, Inception и т.п. можно добавить SE Module и поднять accuracy: например, новый top5 на ImageNet 2.25% после 2.99% в прошлом году, а для ResNet50 получается 6.6% вместо 7.5%, т.е. почти как ResNet100 при минимальном overhead по flops и около 10% overhead по времени.
Модуль очень простой, вставляется после convolution block во все SoTA архитектуры и производит, по сути, gating каналов. Подробнее, как он работает, показано на рисунке: делаем global average pooling, дальше blottleneck с ReLU, и потом gating через сигмоиду. Интуиция в том, чтобы явно моделировать зависимости между каналами и перекалибровывать их.
Еще в статье есть эмпирический анализ работы модуля: на нижних слоях он делает что-то одинаковое для всех классов, а ближе к выходу, для разных классов — разное.
3. Improved Variational Autoencoders for Text Modeling using Dilated Convolutions
→ Оригинал статьи
Автор: asobolev
Речь пойдёт про вариационные автоэнкодеры для текста, что помогает, например, в unsupervised режиме находить хорошие фичи. Однако, если делать такой VAE по-наивному, то есть используя RNN энкодер и RNN декодер, то многие авторы рапортуют о трудностях обучения. На самом деле, проблема в том, что RNN уже достаточно мощная модель сама по себе и в состоянии моделировать языковую модель без дополнительной информации, а рекурретные сети моделируют именно такие распределения.
Соответственно, раз обычные RNN-декодеры такие мощные, давайте заменим их на что-нибудь попроще. Таким "чем-нибудь попроще" авторы выбрали "дырявые свёртки" (dilated convolutions, чей дебют произошёл в статье про WaveNet, как я понимаю, не путать с strided convolutions, см. тут). Как я понимаю, причина такого выбора в том, что даже относительно неглубокий декодер будет иметь достаточно широкую область видимости, т.е. уметь моделировать достаточно протяжённые локальные зависимости. Ожидаемо, путём увеличения глубины такого декодера мы будем увеличивать его мощность.
Авторы расматривают не только сам VAE, но и semi-supervised learning на его основе. Кроме того, такая модель умеет думать о метках класса, поэтому её естественно использовать для кластеризации, что авторы и делают.
Эксперименты: в качестве энкодера была взята обычная LSTM, а в качестве декодера – LSTM бейзлайн и 4 свёрточно-дырявых декодера разной глубины: маленький, средний, большой и очень большой (с областями видимости 16, 63, 125 и 187, соответственно). У LSTM бейзлайна получилась неплохая перплексити на задаче моделирования языка (на датасетах отзывов Yelp'а и Yahoo ответов), но он игнорировал скрытый код. В целом виден паттерн: чем меньше (и слабее) декодер, тем активнее он использует скрытый код, но тем сложнее ему выучить хорошую языковую модель. Оптимальным декодером получился большой свёрточно-дырявый, а очень большой работал хуже и игнорировал код.
Собственно, зачем это всё делалось: хочется иметь хорошее скрытое представление (код), которое было бы полезно в других задачах. Для начала авторы делают его двумерным и показыают, как топики, которые есть в датасете кластеризуютя автоматически. Потом начинается semi-supervised learning, когда авторы на смешном количестве размеченных примеров (от 100 до 2000) довольно успешно (относительно существующих методов, сравнения с обучением "с нуля" не было) обучают supervised модель для классификации на 5 или 10 классов.
Кроме того, в самом конце есть маленький примерчик того, как включение информации о метках класса в модель помогает в итоге генерировать (VAE же генеративная модель!) семплы, обуславливаясь на этот самый класс.
Extra thoughts:
- Результат о том, что декодер должен быть не очень сильным, но и не очень слабым, на мой взгляд, весьма разумен: у текста есть некая "высокоуровнекая идея", которую нам бы хотелось захватить скрытым кодом, а синтаксические флуктуации кодом моделировать не хотелось бы, поэтому маленькие декодеры хоть и активно используют код, возможно, пихают туда всякую ерунду (это предположение, конечно же, нуждается в экспериментальной проверке);
- Про условную генерацию было сказано мало;
- Результаты по semi-supervised обучению выглядят хорошо в сравнении с аналогичными методами, однако интересно посмотреть на то, каких чисел вообще можно добиться на том же датасете с полной разметкой;
- Даже маленький свёрточно-дырявый декодер имел достаточно большую область видимости. Возможно, ему не хватало глубинной ёмкости, эксперименты на эту тему тоже не помешали бы.
4. Training RNNs as Fast as CNNs
→ Оригинал статьи
Код
Автор: gsoul
Завезли SRU (Simple Recurrent Unit) — убрали зависимость на h_(t-1) и сделали рекуррентные сети распараллеливаемыми. Пишут, что потерь в качестве нет, а скорость при этом возрастает в 5-10 раз и сравнима со сверхточными сетями. Более того, во многих случаях результаты показаны лучше, чем у LSTM-аналогов, а тестировали его на довольно широком круге задач: text comprehension, language modelling, machine translation, speech recognition.
Вся суть статьи в этой картинке:

Еще из довольно значимых выводов — то, что для машинного перевода они смогли настекать 10 слоев SRU без видимых тенденций к оверфиту. И тут нужно учитывать, что в машинном переводе слои энкодера и декодера обычно считаются симметрично, т.е. по факту это 20 слоев рекуррентных сетей, что есть огого. Для сравнения, простые смертные для машинного перевода строят модели на 4 + 4 слоя. Гугл, в конце 2016 — начале 2017 писал, что они более-менее успешно тренируют 6 + 6 слоев, и для своего прода, на тот момент, делали 8+8 слоев, но это уже было практически нереально натренировать, при том, что эти 16 слоев раскладывали на 8 ГПУ.
P.S. При этом BLEU En->De у них как-то вышел не очень, возможно из-за маленького времени обучения.
5. Transforming Auto-encoders
→ Оригинал статьи
Автор: yane123
Речь пойдет о новом типе архитектур сетей для работы с изображениями. Хинтон и ко считают, что если речь о работе с изображениями, то будущее вряд ли за сверточными сетями. И что можно получить более удобную репрезентацию инвариантов в данных, если отказаться от сверток в пользу капсул.
Цель каждой капсулы в составе сети — научиться распознавать некую сущность во всем диапазоне доступных к наблюдению трансформаций (например, смещений). Капсула представляет собой небольшую нейросеть, состоящую из распознавателя, генеративной части и скрытого слоя. То, что находится в скрытом слое, интерпретируется как выходное значение капсулы (которое пойдет к вышестоящим капсулам), и оно состоит из двух вещей:
- Вероятность того, что сущность Х присутствует на картинке. Она же — “степень узнавания” сущности Х капсулой.
- “Параметры инстанцирования” конкретного экземпляра сущности Х.
Генеративная часть капсулы осуществляет генерацию исключительно по этим самым параметрам инстанцирования. Результат генерации затем умножается на степень уверенности капсулы. Если он равен нулю, то и вклад капсулы в итоговую реконструкцию тоже будет нулевым.
Трактовка модели: если всевозможные обличья некоего инварианта Х уложить на многообразие, то “степень узнавания” на выходе капсулы не будет зависеть от того, какая точка на многообразии соответствует данному экземпляру. Высокая степень узнавания будет говорить лишь о факте попадания в нужное многообразие. А вот параметры инстанцирования уже зависят от положения объекта внутри многообразия.
Это как в ООП: если капсула А активировалась с большой степенью уверенности, значит на сцене, скорей всего, присутствует объект класса А. Если предположить, что он действительно там присутствует, то на выходе капсулы А — его параметры.
В простейшем случае этими параметрами может быть пара чисел, трактуемых как координаты объекта на 2д-картинке. В чуть более сложном, это может быть матрица трансформации, которая будет прикладываться к “каноничному” представлению распознанной сущности. Короче, тут можно проявлять фантазию.
Остается вопрос, как организовать обучение этих капсул, чтоб они начали работать таким "ООП-методом". В статье показано, что это достигается, если обучать капсулы на парах изображений. При этом, второе изображение является трансформацией первого (например, сдвиг), а сама сеть имеет доступ к информации о трансформации (например, куда и насколько сдвинулись). Здесь как у мозга с его саккадами.
Используя описанный подход к обучению, можно заставить капсулы построить репрезентацию любых таких свойств изображений, которыми мы можем управлять. В статье рассказывается о паре экспериментов с капсулами и отрисованы их приобретенные специализации.
Мое личное резюме: клево! очень.
6. A Relatively Small Turing Machine Whose Behavior Is Independent of Set Theory
→ Оригинал статьи
Автор: kt
Эталонная статья для фанатов беспощадно абстрактных и миленько бестолковых отделов теоретического компьютерсаенса, с прелестным флёром инженерии.
В этой работе авторы задались целью построить машину Тьюринга, которая бы останавливалась только если аксиоматика теории множеств Цермело-Франкеля с аксиомой выбора (т.е. ZFC — то, что лежит в основе всей нашей математики) противоречива. Так как мы знаем, благодаря Гёделю, что, пользуясь правилами ZFC, невозможно доказать или опровергнуть противоречивость правил ZFC, то невозможно будет доказать или опровергнуть то, что соответствующая программа работает бесконечно, что как бы прикольно.
Самая простая программа требуемого вида — та, что просто перечисляет по порядку все возможные выводы из ZFC и останавливается, когда находит противоречие (например, 1=0). Однако в форме машины Тьюринга такая программа была бы слишком сложна, а хотелось бы что-нибудь попроще. Для этого авторы использовали несколько трюков, в частности:
Существует некая "Лемма Фридмана" вида "для любых к, н, р, граф на подмножествах рациональных чисел блабла содержит блабла", которая, как доказал Фридман, эквивалентна непротиворечивости ZFC. Поэтому вместо того, чтобы перебирать все теоремы ZFC можно перебирать все графы нужного вида, пока не найдется "плохой", что гораздо проще.
- По хорошему, "программой" в машине Тьюринга являются её состояния, а "лента" нужна для промежуточных вычислений. Запихивание программы в состояния, однако, быстро множит их количество, что некрасиво. Красивее выписать код программы на ленту, а в состояниях записать эдакий "универсальный интерпретатор" этого кода. Т.е. суммарная машина Тьюринга сначала пишет на ленту свой код, а потом выполняет его. В плане количества нужных состояний получается короче.
Для реализации этой красоты авторы реализовали два специальных языка: TMD, для удобного описания машин Тьюринга (из которого можно скомпилировать собственно машину), и Laconic — высокоуровневый C-подобный язык, компилирующийся в TMD.
В результате они получили требуемую машину Тьюринга из 7918 состояний. Потом их понесло, и они наваяли машину Тьюринга для доказательств гипотез Гольдбаха (4888 состояний) и Римана (5372 состояния).
Одним из забавных следствий этого результата является следующее. Пусть BB(k) — максимальное конечное количество шагов, которое может сделать машина Тьюринга с k состояниями (т.н. функция busy beaver). В таком случае BB(7918) (а так же BB(k) для любого k >= 7918) — невычислимое число (значение его невозможно доказать или опровергнуть из ZFC).
7. Analysis of telomere length and telomerase activity in tree species of various life-spans, and with age in the bristlecone pine Pinus longaeva
→ Оригинал статьи
Автор: kt
Насколько мы знаем, клетки при делении теряют часть своего ДНК (теломеры), что обеспечивает т.н. клеточное старение. У некоторых клеток (эмбриональные, раковые) против этого есть специальный белок — теломераза, который восстанавливает теломеры и даёт клеткам вечную жизнь.
Интересен вопрос того, что происходит в деревьях, ведь некоторые из них могут жить сотни и тысячи лет, при этом рост их в основном происходит в районе меристемов (т.е. как бы "эмбриональных" клеток). Если верить авторам статьи, на 2005 год особой ясности в вопросе клеточного старения растений не было (и, как я лично для себя вынес, статья больше ясности не внесла).
Авторы взяли у деревьев шести разных видов разных возрастов пробы иголок, древесины и корней, замерили распределение длин теломер и активности теломеразы в них, и привели соответствующие графики зависимости этих показателей от вида дерева ("долгоживущие", "среднеживущие", "маложивущие") и возраста в рамках одного вида (сосна какая-то).
Авторы увидели, что длины самых длинных теломер и активность теломеразы как будто в среднем больше у долгоживущих деревьев, но статистической значимости авторы не показывают, так что может там её особо и нет (размер выборки измеряется в десятках точек). Более того, в рамках одного вида кажется, что длина теломер в корнях растет с возрастом, а активность теломеразы вообще словно циклична (с длиной цикла порядка 1000 лет). Короче, на самом деле, нифига не понятно кроме того, что теломераза-таки работает.
8. Outrageously Large Neural Networks: The Sparsely-gated Mixture-of-experts Layer
→ Оригинал статьи
Автор: yane123
Мотивация
Если перед моделью стоит задача выучить сложную предметную область, то в модели должно быть много параметров. Сеть должна быть большая. Активировать всю большую сеть на каждом такте — дорого. Хочется, чтоб в каждый момент времени работали/обучались лишь отдельные её участки (conditional computation).
Модель
Авторы предложили новый тип слоя — смесь экспертов под разреженным шлюзом. Суть: есть нейросеть-шлюз, которая работает менеджером и решает, кто из подведомственных ей экспертов будет обрабатывать текущие данные. Экспертами выступают простые нейросети прямого распространения. Их очень много (тысячи), но в каждый момент менеджер выбирает лишь несколько из них. И шлюз, и эксперты обучаются совместно обратным распространением.
На выходе шлюз выдает вектор длиной n, где n — количество экспертов. Функция активации шлюза — софтмакс с парой добавлений: шум и разреженность. Разреженность задается просто — в векторе выбирается k самых ярких ячеек, а остальные насильно выставляются в минус бесконечность (чтоб софтмакс на них потом дал ноль, и это значило бы незадействование эксперта на данной задаче).
Сложности
Одна из сложностей в том, что чем больше экспертов, тем меньше часть батча, которая придется на каждого эксперта. Увеличивать батч до бесконечности невозможно, т.к. размер памяти ограничен, и авторам пришлось искать другие подходы.
Другой тонкий момент это балансировка нагрузки между экспертами. На практике оказалось, что сеть склонна впадать в ступор устойчивое состояние, в котором шлюз постоянно выбирает одних и тех же экспертов, и другим нет возможности обучаться. Авторы решили проблему, прибавив к функции стоимости пару штрафов за такое поведение. Для каждого эксперта подсчитывалось, насколько он был востребован шлюзом при обсчете данного батча. Штраф подталкивает всех экспертов иметь равную востребованность. Построению гладкого штрафа посвящен аппендикс.
Еще один момент: инициализация весов. Мягкие ограничения (как упомянутый штраф за неравномерность нагрузки по экспертам) начинают работать не сразу, и простейший способ избежать мгновенного сваливания сети в режим "выбираю одного и того же" — инициализировать веса шлюза одинаково.
Результат
Тестирование проводилось на задачах по работе с текстом (1 Billion Words Benchmark и машинный перевод). Говорят, работает сравнимо с лучшими методами.
9. The Consciousness Prior
→ Оригинал статьи
Автор: asobolev
Мини-заметка на 4 страницах о гипотетическом подходе к созданию RL-агентов с механизмом сознания/изучению распутанных (disentangled) представлений, обильно политая баззвордом conscious (это слово в заметке встречается 41 раз! Сорок один! По десять раз на страницу, Карл!)
Для выучивания распутанных представлений, т.е. таких, в которых одна компонента скрытого состояния влияет только на одно свойство рассматриваемого объекта (например, угол поворота лица по горизонали), предлагается завести т.н. сознающее состояние (conscious state), обращающее разреженное внимание (sparse attention) на первое скрытое состояние, выбирая только несколько его компонентов и пытаясь сделать разумное утверждение о них, что бы это ни значило. В принципе, если две компоненты скрытого состояния регулируют одно и то же свойство, то мы по одному из них не сможем сделать разумных утверждений (однако, никаких гарантий, что этот фактор не свяжет поворт по горизонтали и по вертикали в поворот по диагонали, нет).
Предполагается, что у нас есть последовательность наблюдений s_t (как обычно в RL) и мы крутим поверх неё RNN'ку (какая вам больше нравится), генерирующую нам на каждом шаге выход h_t — это и есть наше скрытое представление, которое мы хотим сделать максимально распутанным.
Теперь о том, как вычислять это самое сознающее состояние c_t: предлагается завести некую нейрость C(h_t, c_{t-1}, z_t), которая будет обращать разреженное внимание на компоненты h_t, пользуясь контекстом c_{t-1}, а ещё добавим стохастичности для большего веселья разведования (exploration).
Теперь о том, как мы всё-таки хотели бы обучать это сознающее состояние. Было бы очень круто, если бы мы таким образом могли предсказывать будущее, например, пусть мы хотим в момент времени t делать какое-то предсказание о будущем в виде c_t, а через k шагов проверять его с помощью h_{t+k}. Поэтому вводим ещё одну нейросеть V(h_t, c_{t-k}), которая будет делать именно это. Правда, с каким лоссом её обучать — непонятно.
Экспериментов нет (во всей лабе из 100+ человек не нашлось желающих взяться за задачу?), но вы держитесь в заметке есть идеи о том, какие эксперименты можно было бы провести.
За редактуру спасибо yuli_semenova.
