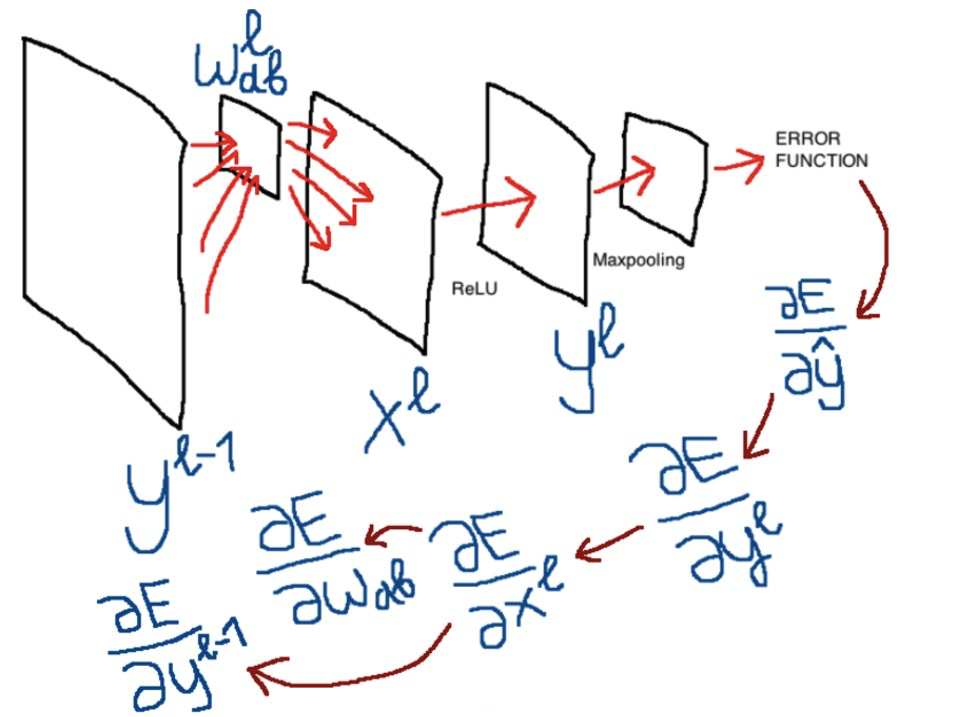
Несмотря на то, что можно найти не одну статью, объясняющую принцип метода обратного распространения ошибки в сверточных сетях (раз, два, три и даже дающих “интуитивное” понимание — четыре), мне, тем не менее, никак не удавалось полностью понять эту тему. Кажется, что авторы недостаточно внимания уделяют обычным примерам либо же опускают какие-то хорошо понятные им, но не очевидные другим особенности, и весь материал по этой причине становится неподъемным. Мне хотелось разложить все по полочкам для самого себя и в итоге конспекты вылились в статью. Я постарался исключить все недостатки существующих объяснений и надеюсь, что эта статья ни у кого не вызовет вопросов или недопониманий. И, может, следующий новичок, который, также как и я, захочет во всем разобраться, потратит уже меньше времени.
В этой, первой статье, мы рассмотрим архитектуру будущей сети, и все формулы для прямого прохождения через эту сеть. Во второй статье мы подробно остановимся на обратном распространении ошибки, выведем и разберем формулы — ради этой части все и затевалось, именно формулы для обучения модели и в особенности сверточного слоя показались мне самыми тяжелыми. Последняя статья представит примерный вид реализации сети на python, а также попробуем обучить сеть на настоящем датасете и сравним результаты с аналогичной реализацией, но уже с помощью библиотеки pytorch. В течение всего материала я буду по частям выкладывать код на python, чтобы сразу можно было видеть реализации формул. При написании кода акцентировал внимание на том, чтобы формулы легко “читались” в строках, меньше времени уделяя оптимизации и красоте. Вообще, конечная цель — чтобы читатель разобрался во всех тонкостях обновления параметров сверточной и полносвязной сетей и смог представить, как может выглядеть работающий код этой сети.
Чего не будет в этих статьях? Объяснений основ математики и частных производных, подробностей “интуитивного” понимания сути backpropagation (для начала можете прочесть эту отличную статью) или того, как работают сети вообще, в том числе сверточные. Для лучшего понимания материала желательно знать эти вещи и особенно — основы работы нейросетей.
Итак, первая статья.
Конволюция
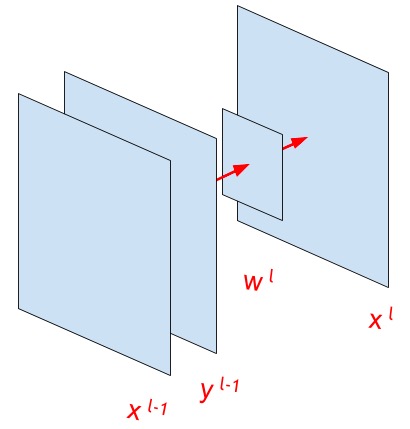
Иллюстрация выше обозначает основные переменные, которые будут использоваться в дальнейшем изложении.
Давайте рассмотрим формулу конволюции. Но сначала, что мы хотим увидеть в формуле, что она должна отражать? Давайте обратимся к википедии:
“В сверточной нейронной сети в операции свертки используется лишь ограниченная матрица весов небольшого размера, которую «двигают» по всему обрабатываемому слою (в самом начале — непосредственно по входному изображению), формируя после каждого сдвига сигнал активации для нейрона следующего слоя с аналогичной позицией. То есть для различных нейронов выходного слоя используются одна и та же матрица весов, которую также называют ядром свертки… Тогда следующий слой, получившийся в результате операции свертки такой матрицей весов, показывает наличие данного признака в обрабатываемом слое и её координаты, формируя так называемую карту признаков (англ. feature map).”
Значит, формула свертки должна показывать “движение” ядра
 по входному изображению или карте признаков
по входному изображению или карте признаков  . Именно это и показывает следующая формула:
. Именно это и показывает следующая формула:
Здесь подстрочные индексы
 ,
,  ,
,  ,
,  — это индексы элементов в матрицах, а
— это индексы элементов в матрицах, а  — величина шага свертки (stride).
— величина шага свертки (stride).Надстрочные индексы
 и
и  — это индексы слоев сети.
— это индексы слоев сети. — выход какой-то предыдущей функции, либо входное изображение сети — это после прохождения функции активации (например, relu или сигмоида; пункт про функции активации будет немного позже) — ядро свертки
— выход какой-то предыдущей функции, либо входное изображение сети — это после прохождения функции активации (например, relu или сигмоида; пункт про функции активации будет немного позже) — ядро свертки — bias или смещение (на картинке выше отсутствует)
— bias или смещение (на картинке выше отсутствует) — результат операции конволюции. То есть операции проходят отдельно для каждого элемента
— результат операции конволюции. То есть операции проходят отдельно для каждого элемента  матрицы , размерность которой
матрицы , размерность которой  .
.Ниже отличная иллюстрация работы формулы конволюции. Синим цветом отображена
, зеленым — , и серая движущаяся матрица три на три — это ядро свертки :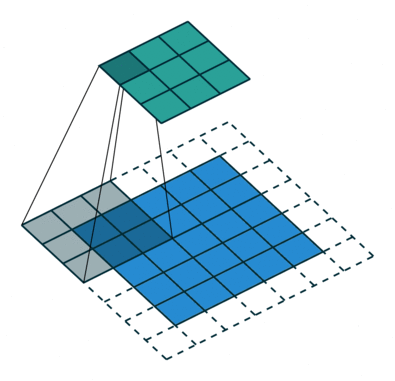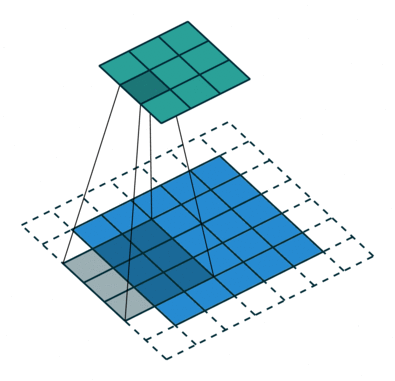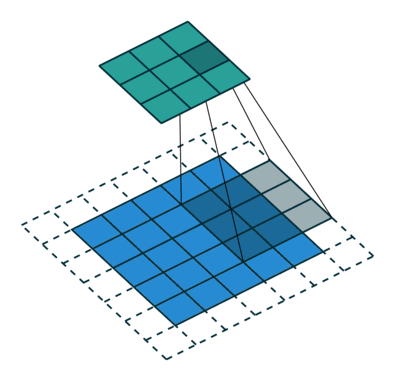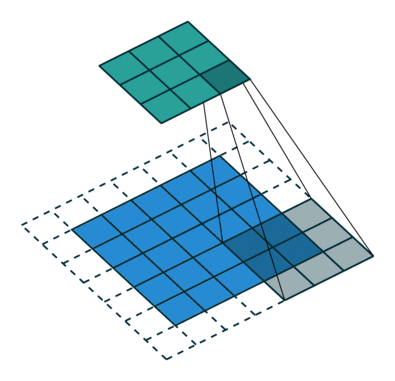
Центральный элемент ядра
Итак, индексация элементов ядра происходит в зависимости от расположения центрального элемента. Фактически, центральный элемент определяет начало “координатной оси” ядра свертки. Посмотрите картинку ниже, слева ядро с центральным элементом в нулевой строке и нулевом столбце, справа — в первой строке и первом столбце:
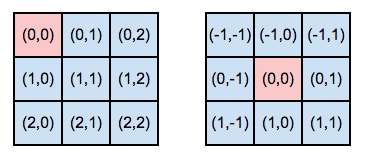
Но, возвращаясь к формуле конволюции, что означает — сумма от минус бесконечности до плюс бесконечности? Ведь само ядро имеет вполне определенные размеры и у него нет бесконечного числа элементов. Я находил разные варианты написания формулы, например,
 (вот и вот). Также находил и варианты с бесконечностью, как в варианте в начале статьи (вот и вот). Но последний показался мне более “общим” случаем.
(вот и вот). Также находил и варианты с бесконечностью, как в варианте в начале статьи (вот и вот). Но последний показался мне более “общим” случаем.Минус в формуле для ядра свертки — это следствие расположения центрального элемента. Нам следует “перебрать” все возможные существующие элементы, и начать можно от минус бесконечности. Или от минус
и . Если элемент по этим индексам не определен для данного ядра, то умножение происходит на ноль, и фактически операции начинаются не от минус бесконечности, а от умноженной на минус один позиции центрального элемента (в нумерации “старых” координат). А закончится операция не на плюс бесконечности, а на разности между количеством элементов ядра по рассматриваемой оси минус индекс центрального элемента (опять-таки в нумерации “старой” координатной оси). Причем последнее значение полученного диапазона не включается (так как индексация от нуля).На словах может звучать тяжело, и, наверное, лучше всего посмотреть, как это можно реализовать на python. Ниже ссылка на jupyter-ноутбук для расчета индексов “новой” оси ядра в зависимости от выбранного центрального элемента:
recalculating_kernel_indexes.ipynb
На картинке ниже мы объявили центром ядра тот элемент, который находится в позиции (1,1).
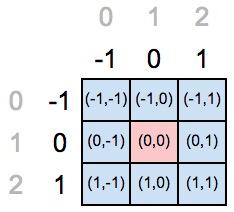
Но “старые” координаты говорят нам, что позиция центрального элемента должна находиться по индексам (0,0), а значит, необходимо переопределить координатные оси для нового положения центрального элемента.
Если мы подставим в код выше наши значения, то получим заполненный питоновский лист значениями из range(-1, 2), то есть лист будет содержать [-1,0,1]. Еще раз, почему range(-1, 2)? “Минус один” потому, что операция начинается от минус индекса нашего центрального элемента, а “два” получается как длина оси (равная трем) минус индекс центрального элемента в старых координатах (то есть один). Последний элемент range не включается.
Кросс-корреляция
Приведу еще раз формулу конволюции:

заменены на плюсы. На практике, применяя формулу конволюции, мы можем видеть, что ядро при свертке “переворачивается” (причем переворачивается относительно центрального элемента!), в то время как при кросс-корреляции элементы ядра при свертке сохраняют свои позиции. Посмотрите иллюстрацию, чтобы лучше понять, что здесь имеется в виду: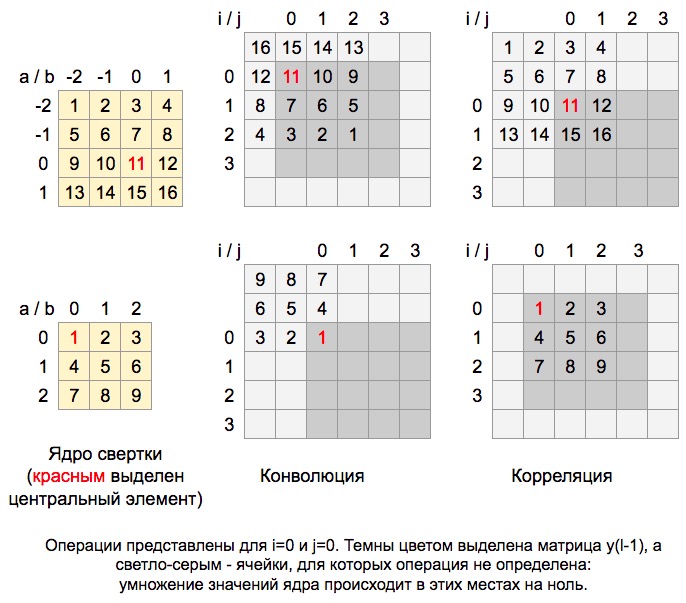
Здесь можно видеть позицию ядра, его расположение во время свертки относительно матрицы
. Ниже jupyter с примерами, аналогичными тем, что на картинке выше, только уже для всех и demo_of_conv_feed.ipynb
И сразу хотелось бы отметить, что выбор центрального элемента или значений шага свертки, размеров матрицы ядра, формулы корреляции или конволюции — все эти нюансы непосредственно отражаются в формулах обратного распространения ошибки и поэтому обучение будет проходить корректно вне зависимости от выбранных параметров. В коде я постарался реализовать все эти вещи, их можно будет настраивать и попробовать запустить все самостоятельно.
В зависимости от способа свертки — конволюции или кросс-корреляции, различной величины шага и выбора центрального элемента ядра — размерность выходной матрицы
может варьироваться. В самом простом случае, при шаге равном единице, размерность матрицы будет равна той, что была у матрицы . Общую же формулу для расчета размерности матрицы я взял из документации pytorch к Conv2d:![$W_{out} = \left\lfloor\frac{W_{in} + 2 \times \text{padding}[1] - (\text{kernel_size}[1] - 1) - 1}{\text{stride}[1]} + 1\right\rfloor$](https://habrastorage.org/getpro/habr/formulas/bc2/f09/ccb/bc2f09ccb2ebb77cb271de1ea1b576e9.svg)
![$H_{out} = \left\lfloor\frac{H_{in} + 2 \times \text{padding}[0] - (\text{kernel_size}[0] - 1) - 1}{\text{stride}[0]} + 1\right\rfloor$](https://habrastorage.org/getpro/habr/formulas/131/89f/392/13189f39269b59a592d0ce59520ec043.svg)
Формулы не учитывают положение центрального элемента, но зато так будет легче сравнивать результаты вычислений нашего кода с pytorch.
Функции активации
Ниже формулы функций активации, которые можно будет использовать в будущей модели. Фактически, это просто “превращение”
в  таким образом:
таким образом:  . Функция активации позволяет сделать сеть нелинейной, и если бы мы не использовали функции активации (тогда получалось бы, что
. Функция активации позволяет сделать сеть нелинейной, и если бы мы не использовали функции активации (тогда получалось бы, что  ) или использовали бы линейную функцию, то неважно какое количество слоев тогда было бы в сети: их все можно было бы заменить одним единственным слоем с линейной функцией активации.
) или использовали бы линейную функцию, то неважно какое количество слоев тогда было бы в сети: их все можно было бы заменить одним единственным слоем с линейной функцией активации.Итак, ReLU:


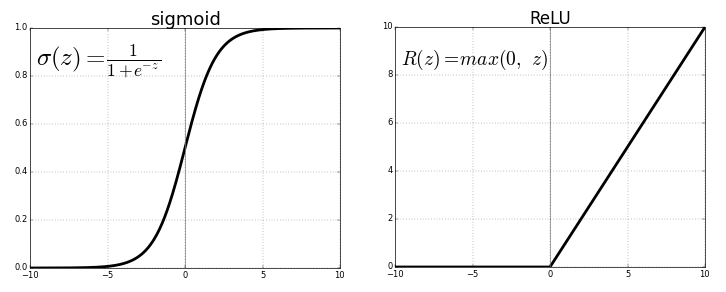
Сигмоида используется только если классов (для задачи классификации) не больше двух: выход модели будет числом от нуля (первый класс) до единицы (второй класс). Для большего же числа классов, чтобы выход модели отражал вероятность этих классов (и сумма вероятностей по выходам сети равнялась единице), используется softmax. Функция выглядит просто, но будут определенные сложности при вычислении формулы для backprop.

 — это количество классов.
— это количество классов.Слой макспулинга
Этот слой позволяет выделять важные особенности на картах признаков, дает инвариантность к нахождению объекта на картах, и также снижает размерность карт, ускоряя время работы сети.
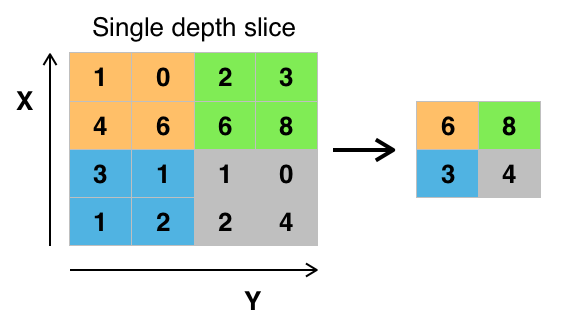
demo_of_maxpooling.ipynb
Код очень похож на свертку, причем даже сохранились те же параметры: выбор страйда, флаг операции конволюции или кросс-корреляции (так как по логике данной функции окно макспулинга тождественно ядру свертки) и выбора центрального элемента. Но, конечно, здесь не происходит поэлементного перемножения матриц, а только, собственно, выбор максимального значения из заданного окна. “Классические” значения параметров макспулинга в параметрах свертки — это кросс-корреляция и позиция центрального элемента в левом верхнем углу.
Функция из демонстрационного кода возвращает две матрицы — выходная матрица меньшей размерности и еще одна матрица с координатами элементов, которые были выбраны максимальными из исходной матрицы во время операции макспулинга. Вторая матрица пригодится во время обратного распространения ошибки.
Слой полносвязной сети
После слоев конволюции мы получим множество карт признаков. Их соединим в один вектор и этот вектор подадим на вход fully connected сети.
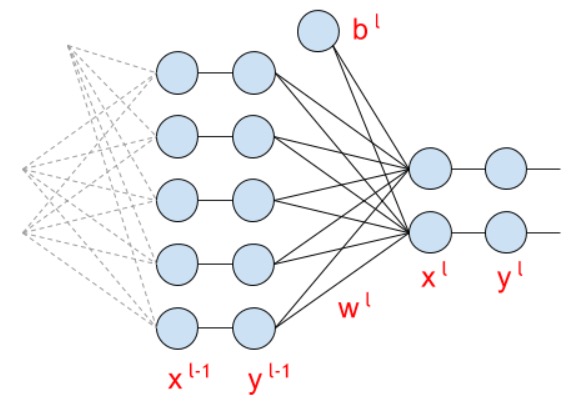
Формула для fc-слоя (fully connected) выглядит так:



Функция потерь
Завершающий этап сети — функция, оценивающая качество работы всей модели. Функция потерь находится в самом конце, после всех слоев сети. Выглядеть она может так:

— это количество классов, — выход модели, а  — правильные ответы.
— правильные ответы. здесь нужна только для сокращения формулы во время обратного распространения ошибки по сети. Можно убрать и ничего принципиально не изменится.
здесь нужна только для сокращения формулы во время обратного распространения ошибки по сети. Можно убрать и ничего принципиально не изменится.После прочтения этой статьи решил использовать cross-entropy: последняя сильнее «штрафует» за неправильный ответ (когда модель слабо уверена в выборе класса, который на самом деле является правильным). А вот MSE в свою очередь хорошо подходит для регрессии.

Структура будущей модели
Теперь, разобрав основные слои сети, мы можем представить примерный вид будущей модели:
- Функция, которая извлекает из датасета следующее изображение/батч для проведения обучения;
- Первый слой сверточной сети, который на вход принимает изображение, на выходе отдает карты признаков;
- Слой макспулинга, который снижает размерность карт признаков;
- Второй слой сверточной сети принимает полученные на предыдущем шаге карты, и на выходе дает другие карты признаков;
- Сложение полученных на предыдущем шаге карт в один вектор;
- Первый слой полносвязной сети принимает вектор, производит вычисления, которые дают значения для скрытого полносвязного слоя;
- Второй слой полносвязной сети, количество выходных нейронов которого равно количеству классов в используемом датасете;
- Выход всей модели подается в функцию потерь, которая сравнивает прогнозируемое значение с истинным, и вычисляет разницу между этими значениями.
Итоговая функция потерь является своего рода количественным “штрафом”, который можно рассматривать как меру качества прогноза модели. Это значение мы и будем использовать для обучения модели с помощью backpropagation — обратного распространения ошибки. Формулы, которые используют эту ошибку и “протягивают” ее сквозь все слои для обновления параметров и обучения модели, мы рассмотрим в следующей части статьи.
Следующие статьи серии:
Сверточная сеть на python. Часть 2. Вывод формул для обучения модели
Сверточная сеть на python. Часть 3. Применение модели
