
Николай Морев (Mail.Ru)
Я сегодня буду говорить о нашем опыте работы по ускорению времени запуска приложения, и чему он нас научил.
Здесь мы видим, что для большинства пользователей время запуска было порядка 4-х секунд, даже немного больше. Поэтому в последнее время мы решили больше внимания уделить именно качеству продукта, а не новой функциональности. Мы начали увеличивать покрытие тестами, начали работать над уменьшением размера приложения, над оптимизацией скорости запуска, над оптимизацией использования сетевых ресурсов. И вот чему мы научились.
Наше приложение – это e-mail клиент, позволяющий работать с любыми почтовыми ящиками, не только с теми, которые заведены на mail.ru. И мы существуем в Store с 2012 года, хотя история разработки приложения немного дольше и уходит корнями в приложение Агент Мail.Ru.
Практически все это время мы находимся в районе 30-ой позиции в рейтинге самых популярных бесплатных приложений в русском Store и в районе 1-2-ой позиции в разделе производительности. Сегодня речь тоже пойдет про производительность, но не совсем про ту. Для международной аудитории мы делаем то же самое приложение, немного с другим дизайном, под названием MyMail. И наши пользователи иногда это замечают.

Я сегодня буду говорить о нашем опыте работы по ускорению времени запуска приложения, и чему он нас научил.
Наши пользователи, в принципе, постоянно нам указывают на какие-то проблемы с приложениями и говорят о том, что для них действительно важно. Вот некоторые примеры отзывов в AppStore:
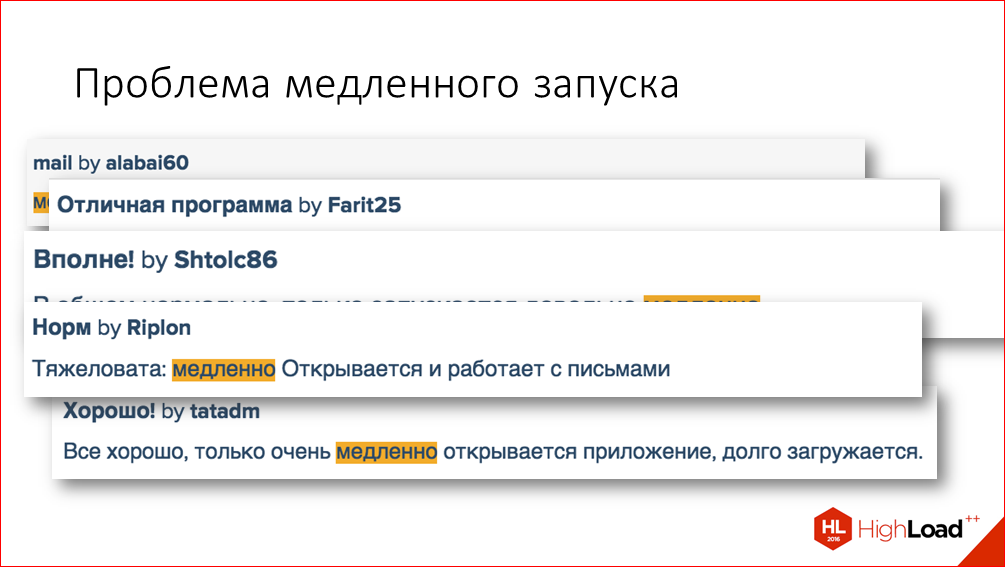
К тому же, данные аналитики, которые мы собираем также подтверждали наличие проблемы со временем запуска.

Здесь мы видим, что для большинства пользователей время запуска было порядка 4-х секунд, даже немного больше. Поэтому в последнее время мы решили больше внимания уделить именно качеству продукта, а не новой функциональности. Мы начали увеличивать покрытие тестами, начали работать над уменьшением размера приложения, над оптимизацией скорости запуска, над оптимизацией использования сетевых ресурсов.
Сперва давайте посмотрим, как же мы пришли к актуальности этой проблемы? Как так получилось, что проблема со скоростью запуска стала нас волновать. Возможно, вы перечисленные факторы сможете сопоставить со своим приложением и понять, а, вообще, стоит ли этим заниматься?

Самое первое – это то, что у нашего приложения такой сценарий использования, что пользователи запускают его по многу раз в течение дня. И естественно, при этом, если приложение запускается медленно, это всех раздражает.
Вторая причина – очевидный ответ на очень многие вопросы в разработке: «Так исторически сложилось». Проблему с производительностью я бы отнес к проблемам, которые называют техническим долгом. Эти проблемы накапливаются постепенно, по мере добавления новой функциональности, незаметно для всех, а бывает и так, что даже умышленно, чтобы ускорить время разработки. Думаю, всем знакомы такие ситуации. По этой причине вряд ли имеет смысл заниматься оптимизацией скорости запуска, если у вас ваше приложение запускают не так часто.
И еще одна причина – отсутствие постоянного контроля за производительностью. Процесс накопления технического долга, как мы все знаем, естественен, и в приложение постоянно добавляется новый код, способный повлиять на скорость запуска. Часть этого кода действительно необходимо выполнять в процессе старта, это такие вещи как настройка библиотеки логирования, запуск библиотеки для отлова крэшей и т.д. А часть, получается, что добавляется в процесс запуска случайно, т.е. по недосмотру. Например, мы в нашем приложении на старте, так исторически сложилось, что мы настраиваем внешний вид для всех экранов приложения, даже если они непосредственно в самом начале не показываются.
Все это осложняется тем, что каждый раз время старта увеличивается на очень незначительную величину. И это ухудшение невозможно заметить при ручном тестировании и даже, если мы будем использовать специальные инструменты типа профайлера, мы можем не заметить это ухудшение, потому что погрешность при изменении в профайлере будет больше, чем сделанные ухудшения.
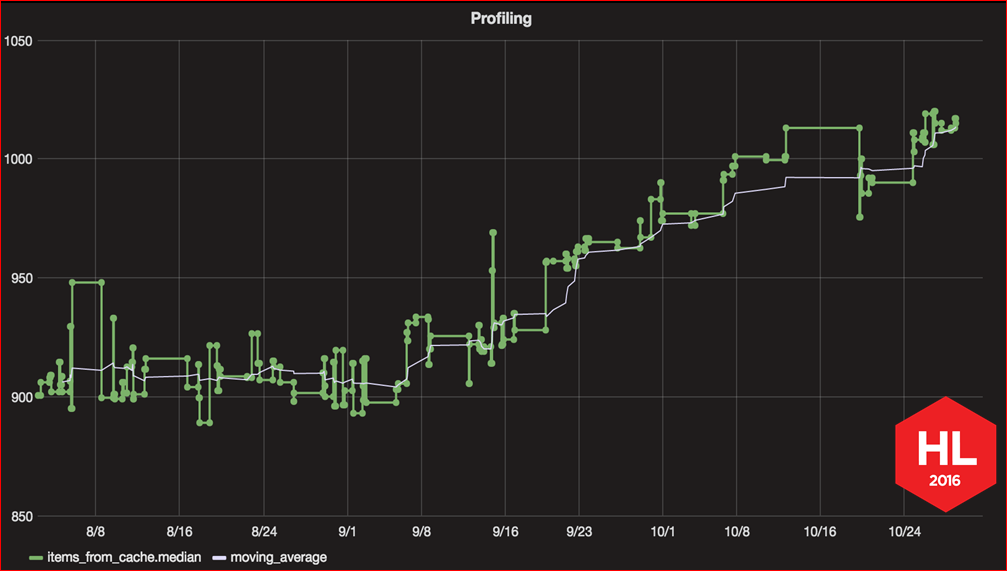
Вот такой график скорости запуска мы построили за последние несколько месяцев. Он именно показывает эту проблему, как постепенно, по чуть-чуть скорость запуска все увеличивается, увеличивается с каждым новым коммитом. Этот график был одним из результатов проделанной нами работы по улучшению скорости запуска, и дальше я расскажу, как и вы тоже можете построить такой график для своего приложения.

Но сначала поговорим о том, как построить сам процесс работы над улучшением скорости запуска.
Всем известно, что главное правило оптимизации: преждевременная оптимизация – корень всех зол. Поэтому, прежде чем начать, нужно определиться с главными вопросами – что именно мы оптимизируем, как пользователи почувствуют эффект от нашей оптимизации, как вы поймете, привело изменение к поставленной цели или нет и, вообще, неплохо бы сперва убедиться, а, в принципе, возможна ли оптимизация, и какое максимальное значение, на которое мы можем улучшить скорость запуска, потому что скорость может зависеть не только от вашего кода, но и от каких-то внешних факторов, на которые вы не можете повлиять. Начнем отвечать на эти вопросы.
Что мы оптимизировали? Мы выбрали для оптимизации основной сценарий запуска, наиболее частый. Это когда приложение выгружено из памяти, пользователь до этого уже залогинил свою учетную запись и при запуске попадает в список писем в папке «Входящие». Примерно так это выглядит:
Далее. Эффект, который должны почувствовать пользователи.

В результате всех оптимизаций у пользователя должно пропасть ощущение тормозов на старте. Чтобы этого добиться, мы заходим с двух сторон – мы пытаемся уменьшить само время, но, кроме этого, мы пытаемся улучшить субъективное восприятие времени старта.
Здесь я буду говорить только о технической части – как мы улучшали время, но в моей статье, ссылку на которую я дам позже, вы можете найти и несколько приемов улучшения субъективного восприятия.
Далее. Как измерять, что оптимизация дала эффект?

В процессе работы над оптимизацией, в процессе, когда мы пытались найти места, которые можно оптимизировать, мы использовали Time Profiler. Для оценки общего эффекта от сделанного изменения мы использовали логи, встроенные в приложение. Почему мы не использовали Time Profiler? Потому что, если вы в приложении какую-то маленькую часть вырезали, заоптимизировали, убрали какой-то код, далеко не факт, что это повлияет на общее время старта. И, естественно, чтобы измерения были максимально полезными, мы все измерения производим на самом медленном устройстве, которое у нас есть, и ни в коем случае не на симуляторе.
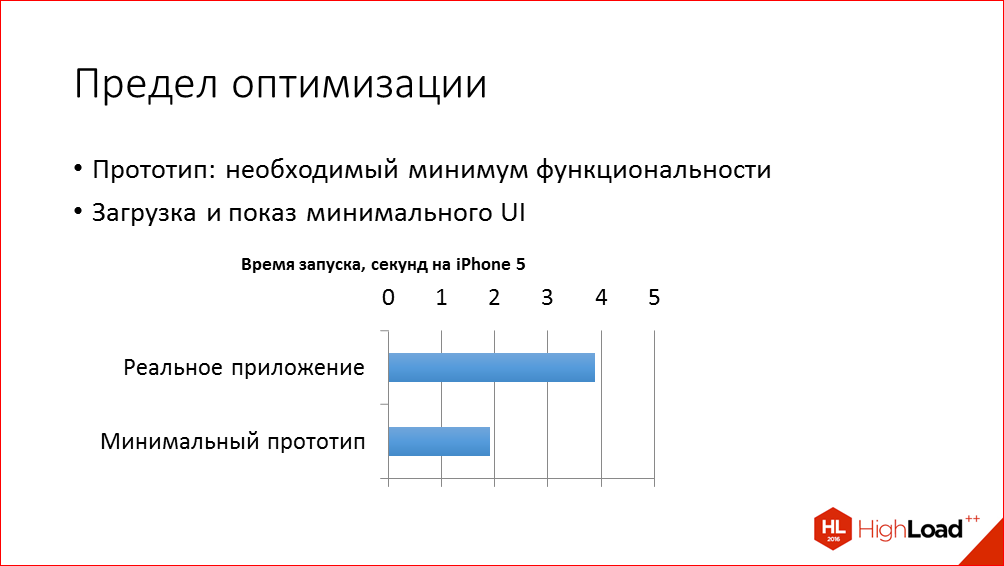
И ответ на последний вопрос – какой, в принципе, предел оптимизации возможен – мы получили следующим образом. Мы создали простое тестовое приложение, с минимальной функциональностью, которое, буквально, шаблон Single View Application в Xcode, и добавили туда экраны с заголовком, список писем и несколько ячеек, которые имитируют список писем. И на этом приложении мы измерили время, ниже которого мы, в принципе, не сможем оптимизировать. И мы поняли, что порядка двух секунд теоретически возможности для оптимизации у нас есть.
Перейдем к оптимизации непосредственно. Начнем с первого этапа запуска.

Первый этап – это время, которое проходит от нажатия на иконку приложения до передачи управления нашему собственному коду. На самом деле, на этом этапе очень много всего происходит, и он вполне может занять ощутимое время.
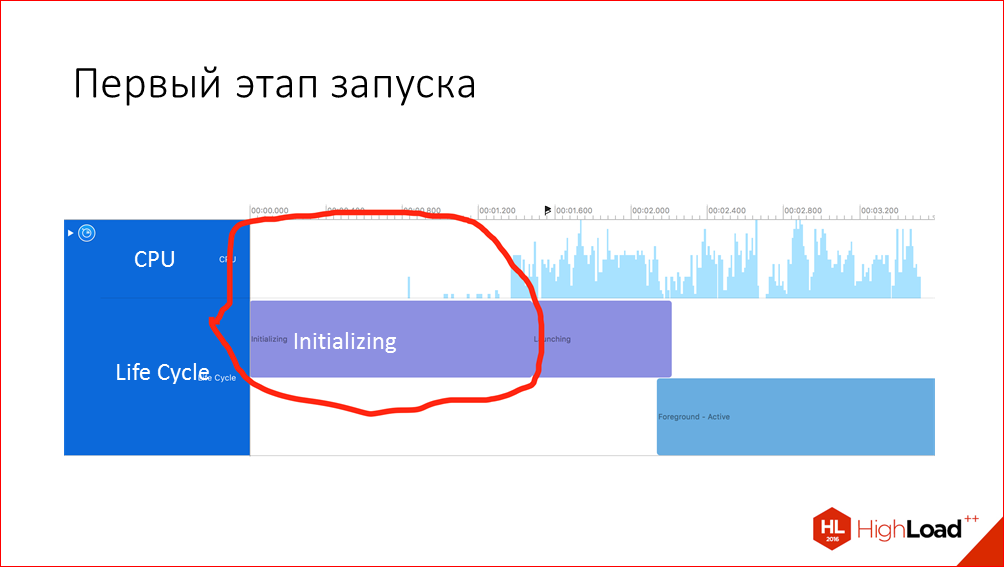
Плохая новость заключается в том, что по первому этапу вы почти никаких данных в профайлере увидеть не сможете, но хорошая новость в том, что все-таки есть некоторые возможности повлиять на это время.
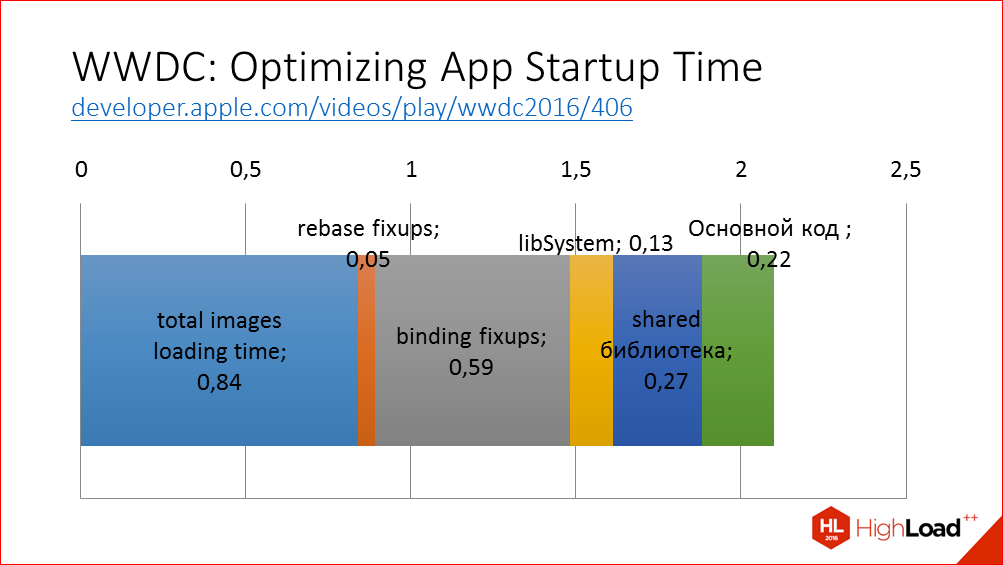
На WWDC в этом году был отличный доклад про первый этап, очень подробно рассматривалось, что именно здесь происходит, и давались рекомендации, что мы можем сделать с этим.
Что здесь происходит? iOS загружает исполняемый код приложения в память, производит над ними необходимые манипуляции, сдвиг показателей, который есть в нашем приложении; выполняет привязку указателей к внешним библиотекам, выполняет проверку подписей всех исполняемых файлов, и затем выполняются методы load и статические конструкторы. Это самый первый код, который именно уже наш код, а не код операционной системы. Для примера я привел диаграмму, как это выглядит в нашем приложении, какая разбивка по различным этапам. Для своего приложения вы те же самые данные можете получить с помощью переменной окружения DYLD_PRINT_STATISTICS в Xcode. Соответственно, чтобы ускорить первый этап, основная рекомендация – уменьшить эти этапы. Как же это сделать?

Это я вырезал слайд из доклада на WWDC, который вкратце суммирует все рекомендации – чтобы приложение работало быстрее, вам просто надо делать меньше вещей в приложении.
Какие еще рекомендации?

Сокращаем количество динамических фреймворков, которые у вас в приложении есть. Почему? Потому что они загружаются намного медленнее системных фреймворков, загрузка системных динамических фреймворков уже заранее оптимизирована в операционной системе, и в качестве оптимального количества собственных динамических фреймворков приводится число 5.
В нашем приложении у нас всего один динамический фреймворк и, главным образом, мы его добавили для того, чтобы вшарить код между различными эксеншенами и чтобы сократить размер приложения, чтобы этот код не дублировался. Но, в принципе, если мы думали только о скорости запуска, мы могли бы отказаться от динамических фреймворков.
Кстати, если вы используете swift, то он добавляет сразу несколько собственных динамических фреймворков, которые тоже считаются в этот лимит. Т.е. получается, что использование swift добавляет определенный overhead на старте.
На этапы, которые здесь отмечены как rebase fixups, binding fixups, влияет количество символов Objective-C в вашем приложении, поэтому здесь основная рекомендация, которая давалась в докладе – это писать большие классы и писать большие методы. Или переходить на swift, где все адреса задаются статически и не нужно делать эти этапы, или, по крайней мере, они сокращаются.
Естественно, для уже существующего большого приложения это не очень полезная рекомендация, потому что придется делать большой рефакторинг, перетестировать заново кучу кода, да и, вообще, читаемость кода, естественно, снижается при этом. Поэтому даже для новых приложений я бы не рекомендовал такой способ оптимизации.

Второй этап, когда мы уже получили управление от операционной системы. Здесь у нас уже больше простор для действий, потому что мы можем свой код как-нибудь поменять и, естественно, для исследований здесь мы начали использовать Time Profiler. Не буду объяснять, что такое Time Profiler.

Time Profiler – очень крутой и мощный инструмент, он нам очень сильно помог, но здесь я перечислю несколько проблем или недостатков, которые он для нас решить не смог.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Первое – мы не нашли в приложении каких-то явных узких мест, которые можно было бы просто выпилить, и сразу бы все улучшилось. Это известная проблема разработки под названием «равномерно медленный код» и она является следствием правильного подхода к разработке, когда мы сначала пытаемся сделать работающий и хорошо читаемый код, а потом уже думаем об оптимизации. Еще одной причиной такой проблемы могут быть сами особенности используемой платформы. Например, вот здесь мы видим, что накладные расходы на вызов методов Objective-C занимают достаточно ощутимое время.

Вторая проблема Time Profiler. В некоторых случаях мы в Time Profiler’е можем увидеть такие вот тяжелые части дерева вызовов, но проблема в том, что по ним не всегда можно понять, к какой именно вьюшке относится определенный вызов, к какой именно части приложения. И такое наблюдается в основном, когда мы анализируем layout или загрузку вьюшек из XIB’ов. В XIB’ах тоже может быть довольно сложная иерархия, и не всегда понятно, какая вьюшка там медленно загружается.
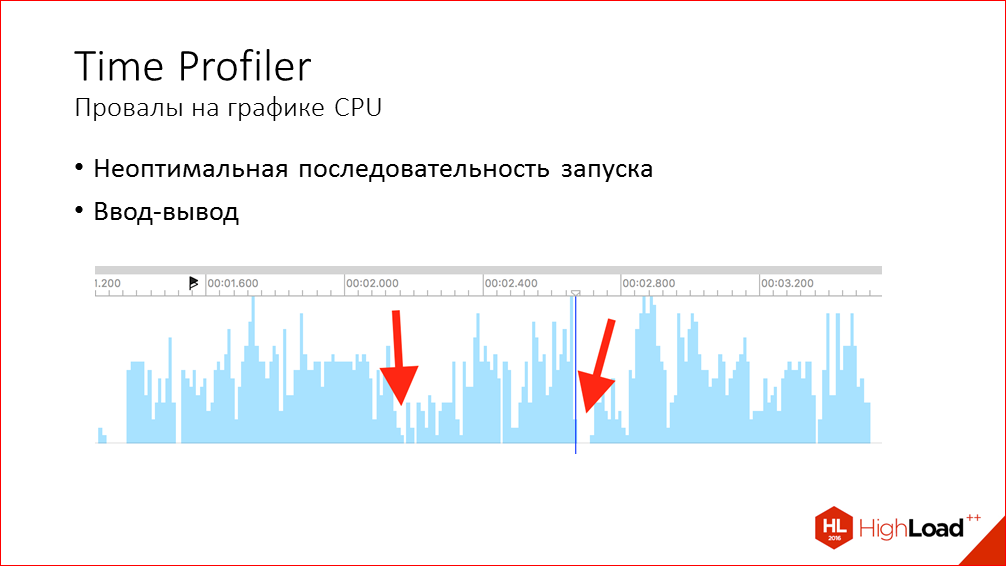
Следующая проблема – провалы на графике использования CPU. В идеале, конечно же, чтобы все очень быстро работало, главный тред должен быть постоянно загружен на 100%, там постоянно должно что-то выполняться. Но на графике мы всегда видим провалы, они могут быть небольшие или более крупные, и Time Profiler нам практически ничего не говорит о том, из-за чего они возникают, что к ним приводит. Но основных причин здесь может быть две:
- Во-первых, сама последовательность запуска может быть выстроена таким образом, что происходит ожидание завершения какого-нибудь действия, которое задерживает остальные этапы запуска, но, в принципе, оно не для всего нужно. Например, мы пытаемся открыть базу данных и только после этого продолжить остальные действия, при том, что какие-то из этих действий могут не зависеть от базы данных.
- Еще одна проблема, которая к этому может приводить, т.е. к провалам – это синхронные операции ввода-вывода. Как очевидные, когда мы работаем с файлами, или когда сторонние библиотеки работают с файлами, так и менее очевидные. Так некоторые вызовы системные в SDK общаются с системными процессами по XPC, и в эти моменты тоже могут возникать такие провалы. Примеры таких вызовов – это работа с Key Chain’ом, с Touch ID, проверка пермишнов на доступ фото или к геолокации.
Еще одна проблема Time Profiler’а, про которую я уже упомянул ранее – это то, что в нем сложно понять общий эффект от оптимизации из-за того, что разброс измерений может быть довольно большим. Вот это я делал измерения на одном и том же приложении без каких-либо изменений, и мы видим, что от запуска к запуску время варьируется очень сильно:

На что еще можно обратить внимание при поиске мест для оптимизации?

Profiler нам дает очень много полезной информации, но психология наша устроена так, что очень легко попасть на ложный след. Во время анализа мы склонны больше внимания уделять не тем местам, которые действительно занимают много времени и могут дать большой выигрыш, а тем, которые нам очень легко заметны и понятны и которыми нам интересно заниматься.
Например, я в процессе поиска мест для оптимизации нашел такое место, где обращения к baseboard на этапе запуска занимали аж целых 20 мс. Я начинаю думать: «А как мне избавиться от этого всего? Может быть, заменить baseboard на что-нибудь другое?». Но, по-хорошему, нужно посмотреть на проблему на уровень выше и понять, а для чего мы, в принципе, это делаем. В нашем случае это делалось в процессе отправки статистики о запуске приложения и, в принципе, мы можем эту отправку статистики просто перенести на немного более поздний этап, и функционально от этого мало что поменяется.
Естественно, мы в первую очередь хотим сократить объем работы на главном треде. И на него в первую очередь обращаем внимание, но о фоновых тредах тоже не стоит забывать, потому что возможности распараллеливания аппаратные не безграничны. В частности, мы столкнулись с такой ситуацией, когда одна из библиотек, которую мы используем и инициализируем на старте, сразу же уходила в фоновый тред и там какую-то работу выполняла. Мы поначалу даже не смотрели, что она там делает, но потом решили просто ее отключить и посмотреть, что будет. И это дало довольно значительный эффект.
Еще в Time Profiler в глаза бросается в первую очередь, что большая часть времени расходуется на отрисовку UI и layout. Но из трейсов не всегда понятно, на что именно в UI это время расходуется, потому что там присутствуют какие-то странные системные вызовы непонятные, СA, рендер, что-нибудь. И эти вызовы могут относиться к чему угодно, к любой отрисовке на экран. Но практика показывает, что самая прожорливая в UI – это отрисовка лейблов из-за того, что относительно сложно рассчитывать их размер и отрисовывать, и любые картинки, потому что их нужно читать с диска и декодировать.
Из всего вышесказанного следует вывод – если вы хотите сократить время запуска, делайте все операции максимально лениво. Что это значит? Не создавайте и не настраивайте никакие экраны и вьюшки, если они не будут показаны сразу после старта. А вообще, пожалуй, это самый действенный способ ускорить существующее большое приложение, где нет явных bottleneck’ов.
Например, что мы сделали ленивым в своем приложении? Мы сделали ленивой загрузку картинок в процессе настройки внешнего вида для второстепенных экранов. Мы убрали промежуточный экран запуска, мы убрали создание фоновых экранов, которые находятся в боковом меню, и много другого по мелочи. В принципе, это правило относится не только к UI, но и к любой логике, любому коду, если какой-то менеджер или действие нужно инициализировать на старте приложения. Подумайте, а нельзя ли его отложить на момент появления основного пользовательского интерфейса. Возможно, с точки зрения функциональности не будет никакой разницы.
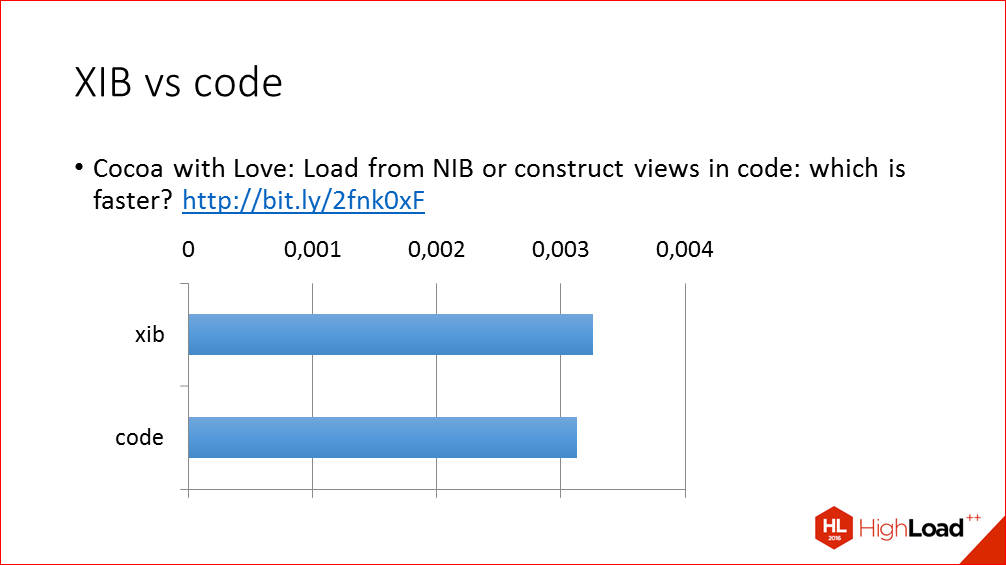
И пару слов о такой спорной теме как создание UI в интерфейс билдере или в коде. Как ни странно, XIB’ы обычно не являются проблемой, создание аналогичного UI в коде выполняется совсем незначительно быстрее, а бывают
случаи, когда даже медленнее. Здесь приведен ссылка на довольно старую запись в блоге, где это сравнение проводилось. Вы можете при желании скачать тестовый проект, правда потребуется приложить определенные усилия, чтобы его перетащить на последнюю версию Xcode, потому что это писалось в 2010 году. И вы можете сами посмотреть, а что выполняется медленнее, а что быстрее.

Ввод-вывод. В принципе, чтение и запись на флэш-память на современных устройствах происходит очень быстро, это единицы или десятки миллисекунд, поэтому не всегда стоит над этим заморачиваться, но бывает так, что ваш или сторонний код злоупотребляет этим и открывает слишком много файлов на запуске. Например, мы обнаружили такую проблему с фреймворком аналитики Flurry и с нашим собственным кодом, где мы загружаем картинки для настройки внешнего вида приложения. Time Profiler вам не покажет такие места. В Time Profiler’е вы в лучшем случае увидите небольшие провалы на графике CPU. Вместо этого вы можете использовать другой инструмент – I/O Activity, который выводит список всех операций ввода/вывода и имена соответствующих файлов. По именам потом довольно легко установить, какая часть приложения этот файл читает.
Аналогичную информацию можно получить и не только инструментом I/O Activity, но и простым брейкпоинтом на функцию open. В случае с системными фреймворками и XPC, о котором я говорил раньше, можно отследить, обращая внимание на провалы на графике CPU. В Profiler’е открываете вид Call Samples, где список всех стек-трейсов, и смотрите, какие вызовы предшествовали провалу. Так вы можете понять, какой вызов приводит к этой задержке.

Когда Time Profiler не дает достаточное количество информации… Раньше я приводил пример с layout, и в таких случаях вы более подробную информацию можете получить с помощью swizzling’а методов layoutSubviews во всех классах. Что такое swizzling пояснять не буду. И Objective-C нам это легко позволяет делать. В за-swizzling’ые методы layoutSubviews мы просто вставляем логирование – сколько времени занял этот вызов, и выводим в консоль еще указатель на объект, над которым этот layout производился. После этого мы все это копируем, вставляем в табличку, в Google Sheets, и можем анализировать. Если после такого лога мы не завершаем приложение, а выходим в отладчик, ставим на паузу, мы можем по указателям примерно понять, какие вьюшки дольше всех layout’ились.

Способы поиска оптимизации, которые я выше описал, имеют большой недостаток – они не позволяют уверено ответить на вопрос, привело ли небольшое изменение к улучшению в целом, потому что последовательность запуска в большом приложении может быть довольно сложной. Это переплетение разных callback’ов на разных потоках и т.д. И то, что вы в одном месте где-то что-то убрали, это может либо перенестись на более поздний этап загрузки, либо вообще не даст никакого улучшения, потому что этот момент заменится ожиданием выполнения каких-то действий. И особенно ярко эта проблема проявляется, когда исправления, улучшения дают довольно небольшой выигрыш. Поэтому мы приходим к необходимости автоматизировать запуск измерения времени старта и выполнять большое количество замеров, чтобы по какому-то медианному времени более точно сказать, нивелировать ошибку измерений.
Конечно же, использовать Time Profiler для этого не вариант, т.к. его сложно автоматизировать, да и такой большой объем информации, который он выдает, не нужен для этой задачи. Поэтому в само приложение мы добавили отладочные логи, которые вводят в консоль и в отдельный файлик время различных этапов запуска. Примерно так эти логи выглядят:
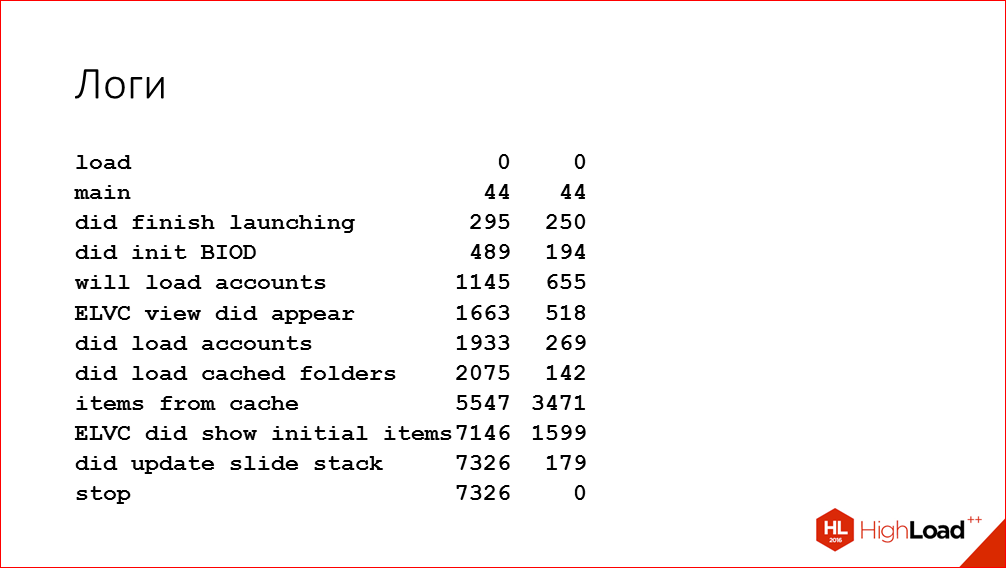
Мы здесь выбрали некоторые ключевые точки критического пути запуска приложения. В этих точках мы вводим абсолютное время от начала запуска и время с предыдущего этапа. Мы использовали такие логи не только впоследствии для автоматизации замеров, но и в ходе поиска мест для оптимизации в дополнение к Time Profiler. Потому что иногда бывает полезно просто получить представление о том, какое время занимают более крупные этапы выполнения приложения. Так мы можем понять, какому этапу нужно уделить больше времени в Time Profailer. И по таким логам можно даже строить такие вот красивые диаграммки в Google Sheets, которые наглядно все показывают:

Например, вот эта диаграмма показывает, как перераспределилось время различных этапов после одного сделанного изменения.
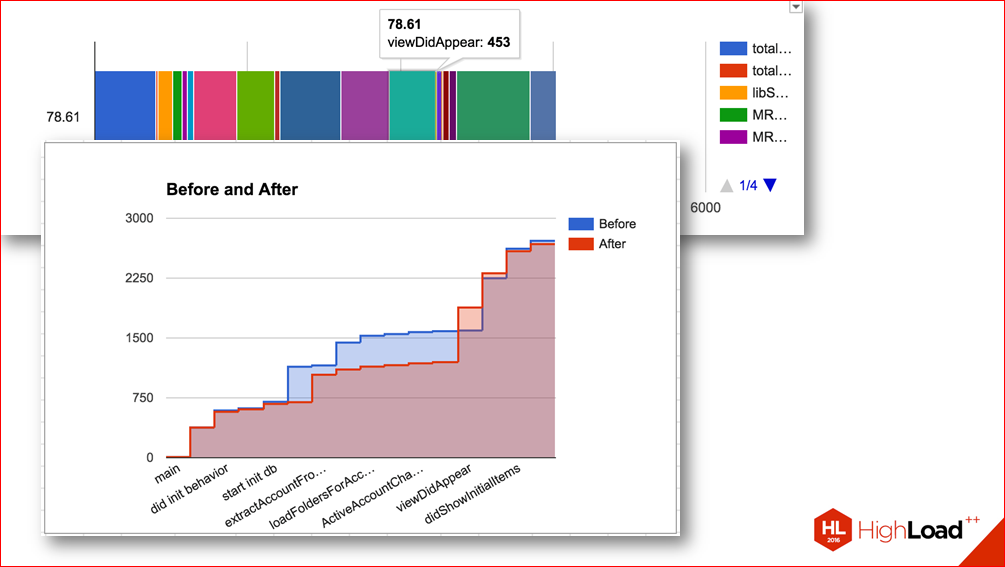
Т.е. без таких измерений вы могли бы подумать, что вы сделали какое-то улучшение, но на самом деле оказалось, что время просто перераспределилось.
Или вот такие диаграммы, которые показывают последовательность различных этапов приложения:
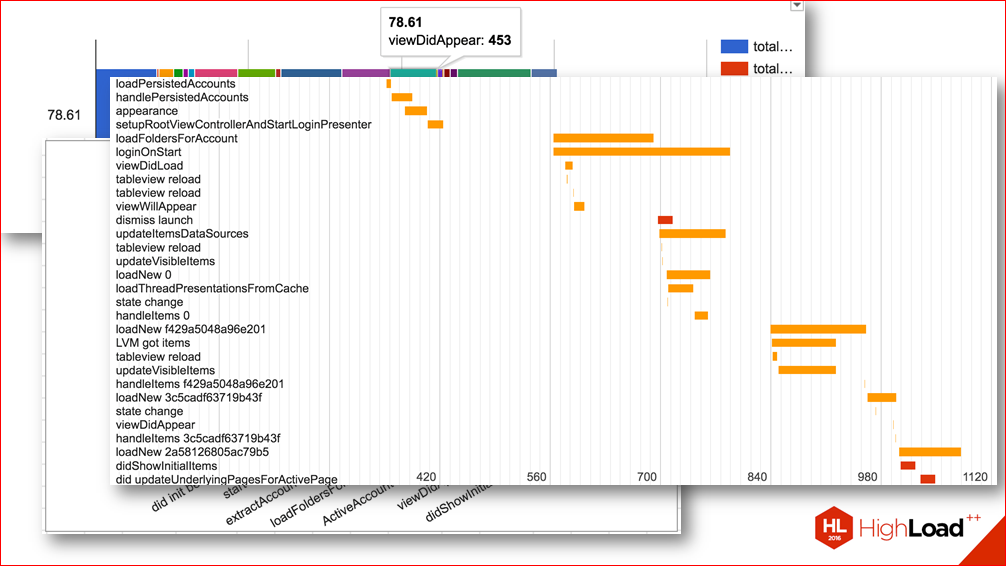
По ним можно подумать, какие места мы можем распараллелить, где у нас ненужная зависимость между этапами запуска и т.д.
Поговорим об оптимизации.
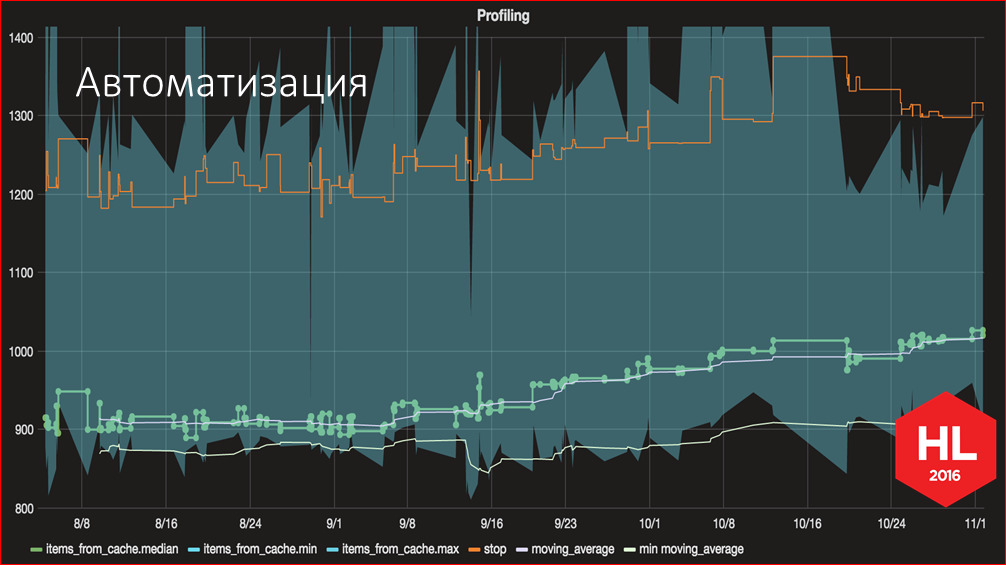
В сообществе разработчиков очень много говорится о Continuous Integration, TDD и других полезных практиках непрерывного контроля за качеством приложения, но почему-то очень мало информации о том, как контролировать именно производительность. Мы попытались восполнить этот пробел. И одним из главных достижений проделанной работы мы считаем систему, которая позволяет нам непрерывно контролировать время запуска в ходе разработки. Имея такую систему, мы решаем основную проблему, которая и привела к необходимости заниматься этим… С помощью такого графика мы теперь можем четко видеть, насколько то или иное изменение повлияло на скорость запуска, и можем принять необходимые меры, видя эти сигналы. Теперь время фидбэка сократилось очень сильно. Если раньше мы получали обратную связь от пользователей, что что-то медленно работает, то сейчас мы это очень наглядно видим.
Естественно, при использовании такой системы, так же, как и многих других полезных практик в разработке, польза такого подхода начинает быть видна только по мере эволюции приложения. В самом начале вам может быть непонятно, зачем это нужно.
Расскажу вкратце, как это технически реализовано.

На каждый коммит запускается задача на Jenkins. Она собирает приложение в релизной конфигурации с включенными профайлинговыми логами и автоматическим завершением приложения на последнем этапе, когда мы считаем, что приложение полностью запустилось. Эта сборка запускается 270 раз на специально выделенном под эту задачу устройстве. На данный момент у нас это Iphone 5S, на iOS 9.
И у вас, наверное, возникнут вопросы, откуда взялось это число 270? Очевидно, что для уменьшения погрешности, это число должно стремиться к бесконечности, но тогда каждый прогон будет занимать бесконечное время. Поэтому мы сделали 10 тыс. замеров и посчитали необходимое количество запусков по формуле определения объема выборки для нормального распределения с ошибкой около 10 мс. Из-за этого у нас на графике все немного скачет из стороны в сторону.
Кстати, если мы вернемся к графику, можем увидеть момент, когда мы переключились с 10 замеров на 270 замеров. Нижняя линия показывает минимальное время запуска из всех запусков, соответственно, когда мы увеличили количество, минимальное стало меньше.
И далее, когда мы сделали эти 270 запусков, мы обрабатываем данные по всем запускам, рассчитываем их статистические характеристики и затем сохраняем в InfluxDB, и затем по ним строится график.
Конкретные примеры скриптов, как это все делается, вы можете потом посмотреть в моей статье. Там на самом деле ничего сложного, там bash-скрипты буквально из 10 строк. Здесь же расскажу только основные моменты, какие инструменты мы для этого использовали.

Как вы все знаете, iOS – это закрытая система, поэтому для автоматизации таких задач, как автоматическая установка, автозапуск, получение результатов работы с устройства, есть два варианта. Мы либо можем работать с недокументированном USB-протоколом, который сама Apple использует в своих приложениях, либо мы можем просто поставить Jailbreak и как белые люди ходить на устройство по ssh и запускать приложение выполнением одной команды. Мы, конечно же, остановились на последнем варианте, потому что он намного проще, надежнее и гибче. Нам не нужно привязывать тестовый телефон к конкретному слейву, подключать по USB. Телефон просто лежит на столе одного из разработчиков, и с любого из слейвов Jenkins мы можем запускать на нем измерения. Или, если разработчику потребуется что-то запустить, он просто берет и запускает.
Подводные камни такого подхода, которые выявились после некоторого времени эксплуатации:

Да, теперь мы можем видеть, что на каком-то этапе разработки скорость запуска увеличилась, но, к сожалению, не всегда момент скачка совпадает именно с тем коммитом, где ухудшение произошло. Это происходит из-за погрешности измерений и из-за различных внешних факторов – на устройстве в этот момент мог выполняться какой-то системный процесс или еще что-нибудь, про что мы пока не знаем.
Даже если мы определили коммит, в котором произошло ухудшение, то чтобы его исправить, это не так просто, все равно приходится проделывать какую-то исследовательскую работу в Profiler, проводить эксперименты сравнения и анализировать код. Конечно, хотелось бы иметь какую-то методику, позволяющую без особых усилий увидеть в каких именно местах изменилось поведение в run time при влите коммита, что-то вроде гибрида Time Profiler и div, но нам такой инструмент, к сожалению, неизвестен.
И бывает и так, что производительность ухудшается из-за обновления какой-то сторонней библиотеки, и здесь мы уже мало что можем сделать.
Перечислю основные выводы, к которым мы пришли по итогам всей проделанной работы, и которые я попытался донести в своем докладе.

- Мы должны замечать проблемы первыми, до того, как это сделают пользователи.
- Все аспекты оптимизации необходимо формализовать, перед тем как мы начинаем работать, иначе мы можем оптимизировать не то, что на самом деле нужно оптимизировать, или думать, что мы что-то улучшили, хотя на самом деле улучшения не произошло.
- Time Profiler — очень крутая вещь, но не всегда его достаточно и нужно использовать и другие инструменты, как поставляемые Apple’ом, так и самописные типа swizzling’а layoutSubviews.
- Ну и, естественно, контроль за производительностью приложения должен стать частью процесса Continuous Integration.
В заключение расскажу о результатах проделанной работы с продуктовой точки зрения, а не сточки зрения разработчика. Вот запуск приложения до и после изменений (демонстрирует видео).

Видео замедленно в 2 раза для наглядности. И мы видим, что стало лучше. Хотя и незначительно, но лучше. Сложно посчитать цифро-ускорение, которое мы достигли по итогам всех работ, т.к. работы растянулись на продолжительный срок, параллельно вливались другие, не связанные с этим задачи. К тому же, методика измерения вырабатывалась по мере того, как мы это все делали, поэтому исходных цифр нет, но приблизительное сравнение «до и после» показывает, что примерно на 30% нам удалось сократить время запуска.

Есть еще такая красивая статистика от наших аналитиков, которая показывает, что количество пользователей, у которых запуск произошел менее чем за 2 секунды, увеличилось в 10 раз за это время. Может показаться не совсем очевидным, как это увеличилось в 10 раз, если улучшили всего на треть? Но если мы посчитаем взвешенное среднее по всем группам пользователей, то тоже получится примерно улучшение на 40%, что совпадает с данными Time Profiler.
Ну и, самые важные показатели для мобильных разработчиков – ретеншн и удовлетворенность пользователей – тоже немного улучшились. Вот показатели ретеншна:

И негативные отзывы в сторе.

Хотя и сложно сделать выводы из таких незначительных колебаний, но нам кажется, что работа по ускорению тоже внесла в это вклад.
Все, о чем я не успел рассказать в сегодняшнем докладе, вы можете посмотреть в моей статье на эту тему.
- Хабрахабр
Рекордное время: как мы увеличили скорость запуска приложения Почты Mail.Ru на iOS
bit.ly/2fgCzi5 - Medium
A record-breaking story of boosting the launch time of Mail.Ru’s email app for iOS
bit.ly/2f9OnGu
Контакты
→ github
Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем Highload++, а конкретно — секции «Производительность мобильных приложений».
Через пару недель нам предстоит целая конференция, посвященная мобильной разработке —
AppsConf. Здесь про оптимизацию времени загрузки расскажет уже Яндекс на примере Яндекс.Карт. А команда Mail.ru раскроет тему оптимизации размера iOS-приложения, на этот раз, на примере ICQ.
