 Доводилось ли вам сталкиваться с системами искусственного интеллекта? Полагаем, ответ большинства хабравчан будет положительным. Ведь ИИ уже перестал быть «чем-то за гранью фантастики». Системы распознавания речи Siri, IBM Watson, ViaVoice, виртуальные игроки Deep Blue, AlphaGo и даже такие ранние системы, как MYCIN, разработанная в 1970-х годах в Стэнфордском университете и предназначенная для диагностирования бактерий, вызывающих тяжелые инфекции, а также для рекомендации необходимого количества антибиотиков — все это вариации на тему ИИ. Но, несмотря на то, что технологии стремительно набирают ход, современные системы все еще весьма «угловаты», и главная проблема, с которой сталкиваются исследователи, — это языковое обучение. Заставить систему говорить не сложно, но объяснить ей «физику» окружающего мира — то, что человек понимает на интуитивном уровне — пока не удавалось никому.
Доводилось ли вам сталкиваться с системами искусственного интеллекта? Полагаем, ответ большинства хабравчан будет положительным. Ведь ИИ уже перестал быть «чем-то за гранью фантастики». Системы распознавания речи Siri, IBM Watson, ViaVoice, виртуальные игроки Deep Blue, AlphaGo и даже такие ранние системы, как MYCIN, разработанная в 1970-х годах в Стэнфордском университете и предназначенная для диагностирования бактерий, вызывающих тяжелые инфекции, а также для рекомендации необходимого количества антибиотиков — все это вариации на тему ИИ. Но, несмотря на то, что технологии стремительно набирают ход, современные системы все еще весьма «угловаты», и главная проблема, с которой сталкиваются исследователи, — это языковое обучение. Заставить систему говорить не сложно, но объяснить ей «физику» окружающего мира — то, что человек понимает на интуитивном уровне — пока не удавалось никому.Тема языковой проблемы искусственного интеллекта широко раскрывается в статье Уилла Найта, главного редактора AI MIT Technology Review, которую специалисты PayOnline, системы автоматизации приема онлайн-платежей, старательно перевели для пользователей Хабрахабра. Ниже представляем сам перевод.
Примерно в середине крайне напряженной игры в Го, проходившей в южнокорейском Сеуле, участниками которой были один из лучших игроков всех времен Ли Седоль и созданный Google искусственный интеллект под названием AlphaGo, программа сделала загадочный шаг, продемонстрировавший пугающее преимущество над своим человеческим оппонентом.
На 37 шаге AlphaGo решила поставить черный камень в нелепое, на первый взгляд, положение. Казалось, что этот ход, больше похожий на характерную ошибку новичка, наверняка приведет к сдаче существенной части игрового поля, тогд как суть игры, напротив, заключается в контроле игрового пространства. Телевизионные комментаторы гадали в чем же дело: то ли это они не поняли хода машины, то ли у нее произошел какой-то сбой. На самом деле, вопреки всеобщему представлению, ход номер 37 позволил AlphaGo создать сильную позицию в центре доски. Программа Google одержала убедительную победу, совершив ход, который, на ее месте не сделал бы ни один человек.
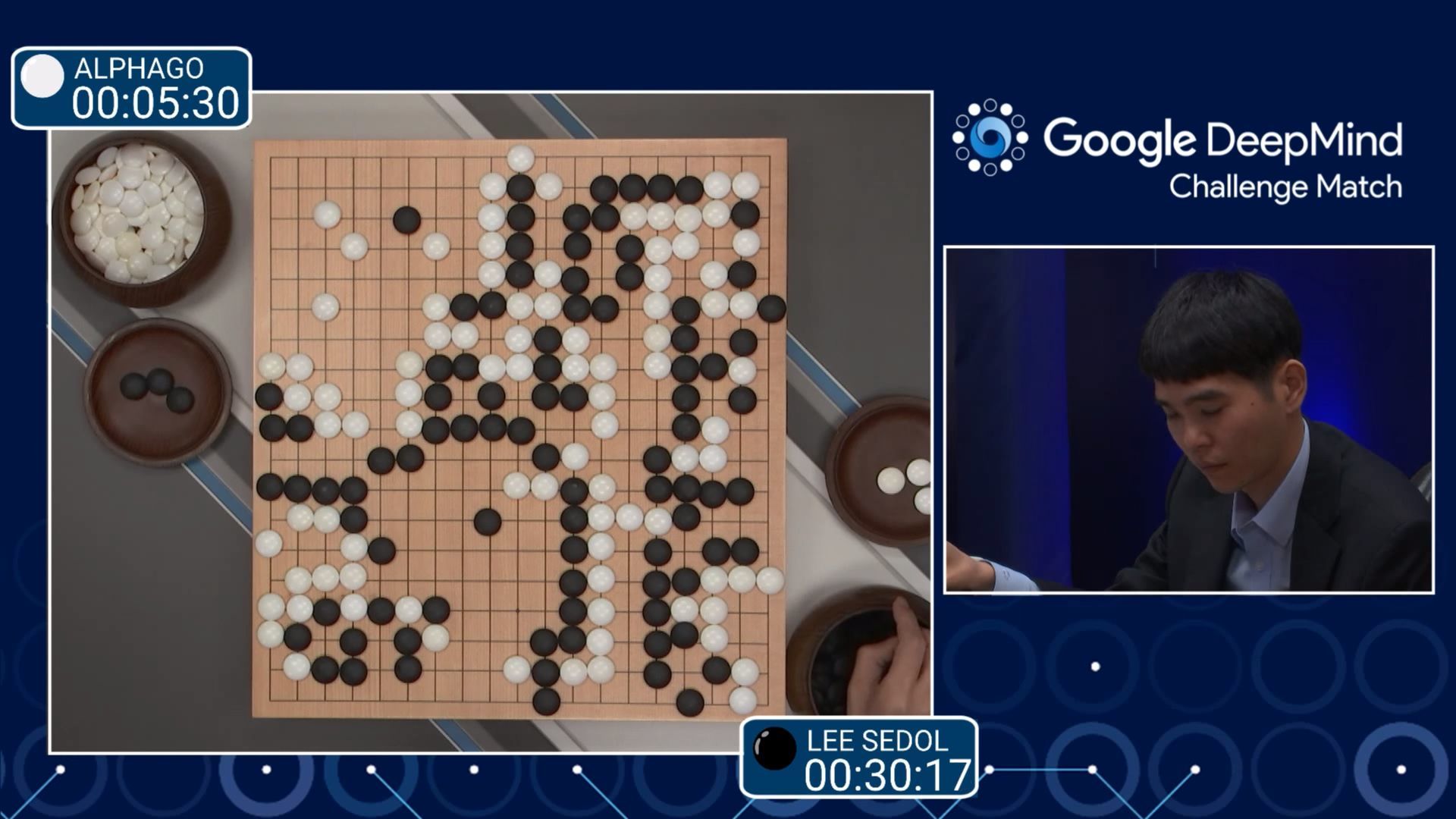
Победа AlphaGo выглядит особенно впечатляюще, поскольку многие считают древнюю игру в Го хорошей проверкой на развитость интуитивного интеллекта. Ее правила крайне просты: два игрока по очереди расставляют черные и белые камни на пересечениях вертикальных и горизонтальных линий доски, пытаясь окружить камни оппонента и тем самым исключить их из игры. Несмотря на эту простоту, хорошая игра в Го требует немалых умственных усилий.
Если в шахматах игроки способны «видеть» на несколько шагов вперед, то в Го этот процесс выходит на новый уровень: просчет оптимальных вариантов в каждой отдельной партии очень быстро становится практически нереальной задачей. При этом в отличие от шахмат, в Го практически нет классических маневров или шаблонов. Нет в ней и какого-либо очевидного способа оценить преимущество, поскольку даже искушенному игроку бывает сложно дать однозначное объяснение тому, почему он сделал тот или иной ход. Все эти особенности делают невозможным написание простого набора правил, следуя которому компьютерная программа могла бы играть на одном уровне с профессионалами.
Никто не обучал AlphaGo игре в Го. Вместо этого программа проанализировала тысячи игр и сыграла миллионы партий против самой себя. В числе прочих ИИ-техник программа использовала один из наиболее популярных в настоящее время методов под названием «глубинное обучение». Его суть сводится к математическим вычислениям, имитирующим происходящие в головном мозге процессы, когда связанные слои нейронов активизируются во время опознания и запоминания новой информации. Программа выучила себя сама с помощью многочасовой практики, постепенно совершенствуя способность интуитивно чувствовать стратегию. Тот факт, что в результате этого она смогла победить одного из сильнейших игроков в Го, представляет собой по-настоящему знаковое событие в развитии машинного обучения и искусственного интеллекта.

A Rubber Ball Thrown on the Sea — Лоуренс Вайнер, 1970 / 2014
О визуальном сопровождении статьи
Одна из причин, по которым понимание языка так трудно дается компьютерам и программам искусственного интеллекта заключается в том, что значения слов часто зависят от контекста и даже внешнего вида отдельных букв и слов. Эта статья сопровождается серией изображений, авторы которых продемонстрировали примеры использования различных визуальных образов, общий смысл которых выходит далеко за рамки значения использованных в них букв.
Спустя несколько часов после хода номер 37 AlphaGo завершила партию победой, доведя свое преимущество в серии из трех побед до двух очков. После этого Седоль стоял перед толпой журналистов и фотографов, вежливо принося свои извинения за то, что подвел человечество. «У меня просто нет слов», — сказал он, жмурясь под шквалом фотовспышек.
Неожиданный успех AlphaGo свидетельствует о значительном прогрессе в области искусственного интеллекта, которого ученым удалось достичь за последние несколько лет, спустя десятилетия ступора и откатов назад, часто называемых «ИИ-зимой». Глубинное обучение открывает машинам дорогу к интенсивному самообучению, позволяющему решать комплексные задачи, всего каких-то два года назад считавшихся доступными только для людей с исключительным уровнем интеллекта. Самоуправляемые автомобили уже сегодня стали данностью обозримого будущего. Кроме того, уже совсем скоро ИИ-системы, основанные на применении методов глубинного обучения, будут помогать людям диагностировать болезни и рекомендовать лечение.
Но несмотря на этот впечатляющий прогресс, существует одна фундаментальная область знаний, судьба которой в контексте ИИ остается неясной: языковое знание. Системы вроде Siri или IBM Watson могут следовать простым воспроизведенным вслух или на письме командам и отвечать на элементарные вопросы, однако они не способны поддерживать беседу и не понимают реального смысла слов, которые используют. Если мы хотим по-настоящему ощутить на себе весь преобразовательный потенциал ИИ, ситуация в этой области должна измениться.
Несмотря на то, что AlphaGo не умеет разговаривать, он содержит в себе технологию, которая может вывести машинное понимание языка на более высокий уровень. В стенах таких компаний, как Google, Facebook и Amazon, а также лидирующих академических лабораториях по изучению ИИ, исследователи предпринимают попытки полноценного решения задачи, которая кажется неразрешимой. Среди применяемых ими разработок есть глубинное обучение и некоторые другие ИИ-инструменты, обеспечившие успех AlphaGo и общее возрождение интереса к ИИ. Успешность их работы позволит осознать масштаб и характер явления, определяемого как революция искусственного интеллекта. От результатов их деятельности также будет зависеть и то, насколько коммуникабельными будут машины будущего и смогут ли они стать близкими друзьями людей в их повседневной жизни, или так и останутся загадочными черными ящиками, стремящимися к еще большей автономности.
«Создать человечную ИИ-систему, в основе работы которой не было бы языка, просто невозможно, — говорит Джош Таненбаум, профессор когнитивистики и вычислительной техники MIT. — Это одна из самых очевидных характерных особенностей человеческого интеллекта».
Возможно, те же методы, которые позволили AlphaGo завоевать первенство в Го однажды позволят компьютерам овладеть языком, а может быть, для этого потребуется нечто большее. В любом случае, если программы искусственного интеллекта не научатся понимать язык, воздействие, которое ИИ окажет на общество, будет иным. Конечно, у нас в распоряжении по-прежнему будут невероятно мощные и умные программы, такие как AlphaGo. Однако наши отношения с ИИ, вероятно, будут характеризоваться гораздо меньшей степенью сотрудничества и дружественности.
«С самого начала исследований ученым не давал покоя один вопрос: “Что если у нас были бы сущности, разумные с точки зрения эффективности, но отличающиеся от нас, в том смысле, что они не способны понять нашу человеческу природу и осознать ее?”, — говорит Терри Виноград, почетный профессор Стэндфордского Университета. — Представьте себе машины, существование которых основано не на человеческом интеллекте, а на “больших данных”, и которые при этом управляют миром».
Заклинатели машин
Через несколько месяцев после триумфа AlphaGo я отправился в Кремниевую долину — самое сердце последнего бума в сфере искусственного интеллекта. Мне хотелось нанести визит исследователям, добившимся заметного прогресса в области практического применения ИИ и прямо сейчас пытающимся вывести машины на более высокий уровень понимания языка.
Я начал с Винограда, который живет в окрестностях Пало-Альто, прямо у южной части стэндфордского кампуса, неподалеку от штаб-квартиры Google, Facebook и Apple. Кучерявые белые волосы и густые усы делают его еще более похожим на авторитетного академика, излучающего к тому же заразительный энтузиазм.
В далекий 1968 год Виноград предпринял одну из самых первых попыток научить машину разумному разговору. Будучи одаренным математиком и очарованным языкознаниями ученым, он оказался в новой лаборатории MIT по изучению искусственного интеллекта с целью написания докторской работы и решил разработать программу, способную вести текстовые беседы с людьми на языке повседневного общения. В то время эта задача не казалась чересчур амбициозной. Область ИИ развивалась семимильными шагами, а другие сотрудники MIT работали над созданием сложных систем машинного зрения и футуристическими роботизированными манипуляторами.
«Мы тогда чувствовали себя так, будто изучали неизведанное и абсолютно не были ограничены в возможностях», — вспоминает он.

Four Colors Four Words — Джозеф Кошут, 1966
И все же далеко не все были убеждены в том, что освоение языка — простая задача. Некоторые критики, включая влиятельного лингвиста и профессора MIT Ноама Чомски, полагали, что в своих попытках научить машины понимать человеческий язык исследователи ИИ неизбежно столкнутся с проблемами, просто потому, что механика человеческого языка тогда была изучена слабо. Виноград вспоминает даже, как однажды на вечеринке один из студентов Чомски прекратил с ним общение, едва услышав, что тот работает в лаборатории ИИ.
Но были и причины для оптимизма. Несколькими годами ранее Джозеф Вайзенбаум, немецкий профессор из MIT, создал первого в истории чат-бота. Виртуальный собеседник, названный ELIZA, был запрограммирован вести себя, как карикатурный психотерапевт, повторяющий ключевые фразы утверждений или задающий развивающие беседу вопросы. Если бы вы, например, сказали ей, что злитесь на свою мать, то в ответ она бы спросила: «Что еще приходит вам на ум, когда вы думаете о своей матери?». Этот дешевый, на первый взгляд, трюк, сработал на удивление хорошо. Вайзенбаум был шокирован, когда некоторые из участников испытаний начали рассказывать машине о своих самых темных секретах.
Виноград хотел создать нечто такое, что будет способно понимать язык. Начал он с общего упрощения задачи. Он создал примитивную виртуальную среду, «блочный мир», состоящий из горстки воображаемых объектов, расположенных на таком же, воображаемом, столе. Далее он создал программу под названием SHRDLU, способную обрабатывать все существительные и глаголы, применяя простые правила грамматики, необходимые для обращения к голому виртуальному миру. SHRDLU (набор букв, без всякого смысла повторяющий последовательность второго столбца клавиатуры линотипа) могла описывать объекты, отвечать на вопросы об их взаимосвязи и выполнять набранные команды, внося соответствующие им изменения в блочный мир. Она даже обладала некоторым подобием памяти. То есть, если вы говорили ей переместить красный конус и после этого упоминали «конус», то она автоматически подразумевала фигуру красного цвета, а не какого-либо другого.
SHRDLU всюду демонстрировали как один из символов фундаментального прогресса в области ИИ. Но это была только иллюзия. Когда Виноград попытался расширить блочный мир программы, то правила, необходимые для учета используемых слов и грамматических связей, стали слишком громоздкими и неуправляемыми. Несколькими годами позже он прекратил работу над программой и, в конечном счете, бросил и работу с ИИ для того, чтобы сосредоточиться на других областях исследований.
«Ограничения оказались гораздо строже, чем мы думали в самом начале», — признается ученый.
Виноград пришел к выводу, что предоставить машинам способность к подлинному пониманию языка с помощью доступных в то время инструментов было просто невозможно. Проблема состояла в том, что, как писал профессор философии Калифорнийского университета в Беркли Хьюберт Дрейфус в своей книге 1972 года «Чего не могут вычислительные машины», многие вещи, которые делают люди, требуют своего рода инстинктивного мышления, воспроизвести которое с помощью жестких правил нельзя. Именно поэтому до матча между Седолем и AlphaGo многие эксперты выражали сомнения по поводу того, что машины смогут овладеть игрой в Го.

Pure Beauty — Джон Балдессари, 1966-68
Но даже в то время, пока Дрейфус развивал свою теорию, группа исследователей работала над подходом, который, в конечном счете, должен был наделить машины как раз таким типом мышления. Почерпнув немного вдохновения из открытий нейронауки, они экспериментировали с искусственными нейронными сетями — слоями математически симулированных нейронов, которые можно было приучить к активации в ответ на определенные входящие данные. Первые подобные системы были ужасно медленными, и от подхода отказались в силу непрактичности его логического аппарата. Крайне важно, однако, отметить, что нейронные сети могли обучаться такому поведению, запрограммировать которое заранее было невозможно, и позже этот навык оказался очень полезен для решения простых задач, таких, как распознание рукописных символов. Работа в этом направлении приобрела коммерческий характер в 90-х, когда стала использоваться для чтения цифр на чеках. Сторонники подхода были убеждены, что нейронные сети, в конечном счете, позволят машинам показывать гораздо более значимые результаты, чем то, что они могли в те годы. В один прекрасный день, заявляли они, технологии смогут даже понимать язык.
На протяжении последних нескольких лет нейронные сети стали во много раз сложнее и эффективнее. Подход был усилен благодаря успехам в области математики и, что важно, появлению более быстрого компьютерного оборудования и доступности огромного количества данных. К 2009 году исследователи из Университета Торонто показали, что многослойная сеть глубинного обучения способна распознавать речь с рекордной точностью. А в 2012 году эта же группа ученых выиграла конкурс по машинному зрению, представив невероятно точный алгоритм глубинного обучения.
Для распознания отдельных объектов изображения нейронная сеть глубинного обучения использует простой трюк. Слой симулируемых нейронов получает входные данные в форме изображения, и некоторые из этих нейронов активируются в ответ на интенсивность отдельных пикселей. Получаемый после этого сигнал проходит через многие другие слои связанных нейронов перед тем, как достигнуть выходного слоя, который сигнализирует о том, что объект был опознан. Для регулировки чувствительности нейронов и последующего воспроизведения их корректной реакции используется математическая техника под названием «обратное распространение ошибки». Именно этот шаг позволяет системе учиться. Каждый слой сети реагирует на разные элементы изображения, например, на края, цвета или структуру. Подобные системы сегодня способны распознавать объекты, животных или лица с точностью, сопоставимой с возможностями любого современного человека.
Попытки применить глубинное обучение к языкам сталкиваются с очевидной проблемой, суть которой заключается в том, что слова — это условные символы и в этом отношении они принципиально отличаются от художественных образов. Два слова, например, могут быть похожи по значению и состоять при этом из совершенно разных букв, а одно и то же слово в разных контекстах может обозначать совершенно разные вещи.
В 80-х годах исследователи предложили интересный способ превращения процесса изучения языка в такой тип задачи, с которым нейронная сеть сможет справиться. Они показали, что слова могут быть представлены в виде математических векторов, что позволяет рассчитать сходства между родственными словами. К примеру, «лодка» и «вода» близки друг другу в векторном пространстве, несмотря на то, что выглядят эти два слова совершенно по-разному. Исследователи из Монреальского университета под руководством Йошуа Бенгио и другая группа из Google использовали этот подход для создания сетей, где каждое слово в предложении может быть использовано для построения более сложной модели представления, которую Джефри Хинтон, профессор из Университета Торонто и видный исследователь методики глубинного обучения, называет «вектором мысли».
Совместное применение двух таких сетей делает возможным высококачественный перевод между двумя языками, а объединение этого типа сети с другим, способным распознавать объекты изображений, позволяет составлять на удивление правдоподобные сопроводительные подписи к ним.
Смысл жизни
Сидя в конференц-зале, расположенном в самом сердце гудящей как улей штаб-квартиры Google в калифорнийском Маунтин-Вью, Квок Ли, один из исследователей компании, участвовавший в разработке ее новейших ИИ-решений, рассуждает над идеей машины, способной поддерживать настоящую беседу. Амбиции Ли направлены на получение полезных результатов, которые можно будеет использовать в разработке разговаривающих машин.
«Я ищу способ симулировать мыслительный процесс внутри компьютерной машины, — говорит он. — А если вы хотите симулировать мысли, вы должны уметь спросить машину, о чем она думает».

The Answer/Wasn’t Here II — Тауба Ауербах, 2008
Google уже сейчас обучает свои компьютеры основам языка. В мае компания анонсировала систему, получившую название Parsey McParseface, способную анализировать синтаксис предложения, распознавая существительные, глаголы и другие элементы текста. Несложно понять, насколько ценным могло бы оказаться машинное понимание языка для компании. Раньше поисковый алгоритм Google занимался простым отслеживанием ключевых слов и ссылок между веб-страницами. Сейчас, благодаря системе под названием RankBrain, он читает тексты на страницах, пытаясь выделить все наиболее значимые смысловые части, чтобы на основе этого знания предоставить пользователю улучшенный поисковый результат. Ли хочет значительно углубиться в этом направлении. Адаптировав систему, доказавшую свою полезность в переводе и подборе подписей к изображениям, он и его коллеги создали SmartReply, читающий содержимое сообщений Gmail и предлагающий возможные варианты ответа на них. Кроме того, он также создал программу, проанализировавшую переписку техподдержки Google с пользователями и научившуюся отвечать им на простые технические вопросы.
Совсем недавно Ли разработал программу, способную давать неплохие ответы на открытые вопросы. Ее обучение включало в себя обработку диалогов из 18900 фильмов. Некоторые из ее ответов оказываются пугающе точными. Например, на вопрос Ли о том, в чем заключается смысл жизни программа ответила: «Служить высшему благу».
«Это был весьма хороший ответ, — вспоминает он с большой ухмылкой на лице. — Я и сам, наверное, не ответил бы лучше».
Есть только одна проблема, которая быстро становится очевидной по мере наблюдения за другими ответами системы. Когда Ли спросил: «Сколько ног у кошки?», система ответила: «Четыре, я полагаю». После этого он сделал другую попытку: «Сколько ног у сороконожки?». Ответ последовал любопытный: «Восемь». По сути, программа Ли не имеет понятия о чем она говорит. Она понимает, что определенные сочетания символов могут встречаться вместе, но не имеет ни малейшего понятия о существовании реального мира. Она не знает, как на самом деле выглядит сороконожка, или как она передвигается. То есть перед нами все еще только иллюзия интеллекта, лишенная того самого здравого смысла, который мы, люди, воспринимаем как нечто само собой разумеющееся. Подобная нестабильность результатов вполне обыденна для систем глубинного обучения. Программа Google, сочиняющая подписи к изображениям, делает странные ошибки. Глядя на дорожный знак, например, она может назвать его набитым едой холодильником.
По любопытному стечению обстоятельств, ближайший сосед Терри Винограда в Пало-Альто оказался человеком, который также может помочь компьютерам получить более глубокое понимание истинного значения слов. В момент моего визита Фей-фей Ли, директор стэндфордской лаборатории искусственного интеллекта, была в декретном отпуске, однако она пригласила меня к себе домой и с гордостью представила своей очаровательной трехмесячной малышке по имени Феникс.
«Видите, она смотрит на вас чаще, чем на меня, — сказала Ли, заметив, как пристально девочка смотрит на меня. — Это потому, что вас она видит впервые, и ее система раннего распознания лиц сейчас работает на полную».
Ли провела большую часть своей карьеры, изучая машинное обучение и компьютерное зрение. Несколько лет тому назад она возглавила рабочую группу по созданию базы данных по миллионам изображений объектов, каждый из которых был помечен соответствующим ключевым словом. Тем не менее Ли считает, что машины нуждаются в более совершенном понимании событий окружающего мира, и в этом году ее команда выпустила другую базу изображений, снабженных гораздо большим количество комментариев. Каждое изображение было описано человеком с помощью десятков характеристик: «Собака едет на скейтборде», «У собаки пушистая и волнистая шерсть», «Дорога потрескалась» и так далее. Исследователи надеются, что системы машинного обучения научатся лучше понимать физический мир.
«Языковая часть мозга получает много информации, в том числе и из отделов, ответственных за обработку визуальной информации, — говорит Ли. — Важной частью создания полноценного ИИ будет интеграция этих систем».
Этот подход близок к тому, как познают окружающий мир дети, постоянно ассоциирующие слова с объектами, отношениями и действиями. Однако на этом аналогия с человеческим обучением заканчивается. Маленьким детям не нужно видеть собаку верхом на скейтборде, чтобы представить ее в уме или описать при помощи слов. Фей-фей Ли считает, что современного машинного обучения и ИИ-инструментов недостаточно, чтобы воплотить в жизнь мечту о настоящем ИИ. По мнению ученой, исследователям ИИ также придется подумать над учетом таких аспектов, как эмоциональный интеллект и навыки социального общения.
«Искусственный интеллект — это не только интенсивная обработка данных с помощью глубинного обучения, — говорит Ли. — Мы [люди] очень плохо справляемся с масштабными вычислениями, но отлично проявляем себя, когда дело доходит до абстракции и творчества».
Никто не знает, как дать машинам эти человеческие навыки, если, конечно, это вообще возможно. Быть может, в этих качествах есть нечто, присущее только людям, что делает их недосягаемыми для ИИ?
Современные ученые-когнитивисты, такие как Таненбаум из MIT, в своих теориях высказывают идею о том, что всем современным нейронным сетям, сколь большими и сложными они ни были, не хватает многих других важных компонентов разума. Люди обладают способностью обучаться очень быстро на основе относительно небольшого количества данных и имеют встроенную способность эффективно создавать в уме трехмерную модель мира.
«Язык строится на других способностях, возможно, более простых. Так или иначе, младенцы обладают ими еще до того, как в их жизни появляется разговорный язык: они воспринимают мир визуально, делают что-нибудь с помощью опорно-двигательной системы и понимают физику окружающего мира или цели других его обитателей», — говорит Таненбаум.
Если он прав, то создать языковое понимание в машинах и ИИ без попытки воспроизвести человеческое обучение, способы восприятия окружающего мира и психологии будет невозможно.
Объясни, что ты имеешь в виду
Офис Ноя Гудмана на стэндфордской кафедре психологии практически пуст, не считая пары абстрактных картин, прислоненных к одной из стен и нескольких заросших растений. Когда я приехал, Гудман увлеченно печатал что-то, сидя за своим ноутбуком и положив голые ноги на стол. Мы прогулялись через залитый солнцем кампус.
«Особенность языка заключается в том, что с одной стороны он зависит от большого количества знаний о нем, но с другой стороны он также определяется и огромным количеством общеизвестной информации об окружающем мире, и оба эти знания очень тонко переплетаются друг с другом», — объяснил он.
Гудман и его студенты разработали язык программирования под названием Webppl, который можно использовать для того, чтобы дать компьютерам некое подобие здравого смысла, основанного на теории вероятности, и затея эта, как показала практика, может оказаться весьма полезной. Одна из экспериментальных версий webppl может понимать игру слов, другая — хорошо справляется с преувеличениями. Если она услышит, что каким-то людям пришлось «целую вечность» ждать столик в ресторане, она автоматически решит, что употребление буквального значения слова в данном случае маловероятно и на самом деле этим ребятам просто пришлось долго ждать, что вызвало их негодование. Эта система далека от того, чтобы сравниться с настоящим интеллектом, однако она показывает, как новые подходы могли бы помочь создать ИИ-программы, способные разговаривать более натурально.
В то же время пример Гудмана помогает нам оценить сложность обучения машины языку. Понимание контекстуального значения «целой вечности» — одна из типовых задач, которую системам ИИ придется научиться решать — кажется достаточно сложным достижением для современных программ, при этом подобная задача элементарна для человеческого интеллекта.
И все же, несмотря на сложность и многомерность этой задачи, начальный успех исследователей в использовании техник глубинного обучения для распознания изображений и обучении машин играм, таким как Го, по крайней мере дает надежу на то, что мы, возможно, стоим на пороге прорыва и в области языков. Если это так, эти успехи пришлись как нельзя кстати.
Если ИИ и суждено стать вездесущим инструментом, который люди будут использовать для преобразования собственного интеллекта, и которому они будут доверять решение задач в рамках тесного сотрудничества, язык должен стать ключом для этих взаимоотношений. Особую актуальность эта потребность приобретает в свете того, что глубинное обучение и другие техники, в сущности, позволяют программам искусственного интеллекта программировать самих себя.
«В общем, результаты работы системы глубинного обучения производят сильное впечатление, — говорит Джон Леонард, профессор MIT, исследующий автоматизированное вождение, — Однако, с другой стороны, их поведение бывает очень трудно понять».
Toyota, изучающая широкий спектр технологий автоматизированного вождения, инициировала исследовательский проект в MIT под руководством Джеральда Сассмана, эксперта по искусственному интеллекту и языковому программированию. Цель проекта — разработка автоматизированной системы вождения, способной объяснить, почему она совершила то или иное действие. Вполне очевидный способ объяснения в данном контексте — разговор робота с водителем.
«Разработка систем, которые понимают то, что им известно — по-настоящему трудная задача, — говорит Леонард, руководящий другим проектом Toyota в MIT. — Но, так или иначе, системе действительно придется дать не просто ответ, а предоставить полноценное объяснение».
Через несколько недель после моего возвращения в Калифорнию я слушал, как Дэвид Сильвер, исследователь из проекта Google DeepMind, принимавший участие в разработке AlphaGo, рассказывал про матч с Седолем на академической конференции в Нью-Йорке. Сильвер объяснил, что убойный ход программы во второй игре, удивил его команду не меньше всех остальных. В тот момент они могли наблюдать только за тем, как AlphaGo в реальном времени оценивала свои шансы на победу в результате того или иного хода. Однако после 37-го хода расчет показывал совсем небольшое изменение. И только несколько дней спустя, после тщательного анализа, команда Google сделала открытие: «переварив» предыдущие игры, программа рассчитала вероятность того, что человек на ее месте сделал бы тот же самый ход лишь в 1 случае из 10 тысяч. Кроме того, практика игр AlphaGo показывала, что, сыграв таким образом, она получит на удивление сильное позиционное преимущество.
Поэтому машина в некотором роде знала, что Седоль будет совершенно ошеломлен таким ходом.
По словам Сильвера, Google рассматривает некоторые варианты коммерческого применения технологии, включая разработку интеллектуального помощника и инструмента для сферы здравоохранения. После конференции я спросил его о важности общения с ИИ, лежащего в основе этих систем.
«Интересный вопрос, — сказал он после небольшой паузы. — Для некоторых приложений это может быть важно. Например, в здравоохранении общение с ИИ моджет быть полезно для понимания причины того или иного решения».
На самом деле, по мере того, как системы искусственного интеллекта становятся все более изощренными и разносторонними, нам все сложнее представить себе, как мы сможем общаться с ними без использования языка, без возможности спросить их: «Почему?». Более того, способность общаться с компьютерами легко и непринужденно сделает их на порядок полезнее, а выглядеть все это будет как какое-то волшебство. В конце концов, язык — наш самый могущественный способ разобраться в том, как устроен окружающий мир, и как мы можем взаимодействовать с ним. В общем, пришло время нашим машинам наверстать упущенное.
Продолжайте следить за обновлениями блога международной процессинговой компании PayOnline и первыми читайте переводы самых интересных материалов зарубежных изданий о технологиях.

{kind=link}