Привет, Хабр!
У нас заканчивается уже порядком букинистическая книга "Ruby. Объектно-ориентированное проектирование" Сэнди Метц, которую мы надеемся обновить в будущем году. Тем временем мы убедились, что читателей госпожи Метц немало интересуют ее взгляды на ООП, а не только на ООП в Ruby, поэтому предлагаем перевод ее сентябрьской статьи с большим количеством картинок и немалым количеством интересных выводов на заявленную тему. Приятного чтения!
Привет!
Бывает, я размышляю о том, как развиваются приложения, и что делать, если результаты нас не устраивают. При этом я обдумываю три явно разнохарактерные идеи. В этом посте я изложу все три и объединю их. Надеюсь, что, поняв эти взаимосвязи, мы лучше разберемся и в наших приложениях.
Эти мысли – мое личное мнение, основаны лишь на моем собственном опыте. Ваше мнение может отличаться, но, надеюсь, что подкину вам пищу для размышлений. Ниже – много картинок. Представьте себе, что я прямо перед вами рисую их на маркерной доске.
Первая идея принадлежит Мартину Фаулеру и называется «Design Stamina Hypothesis» (гипотеза об устойчивости архитектуры).
Фаулер иллюстрирует эту идею при помощи следующей псевдо-схемы.

Рис. 1
По вертикальной оси откладывается накопленная функциональность. Чем выше линия графика — тем больше мы успели сделать. По горизонтальной оси откладывается потраченное время. Чем дальше вправо — тем позже.
В координатной сетке вычерчены два разных графика. Оранжевая линия показывает, какой объем функциональности мы будем продуцировать к любому моменту времени, если станем заниматься дизайном с первого же дня работы. Синяя линия показывает, каков будет результат, если пренебречь серьезным дизайном. Обратите внимание: на первом этапе синяя линия растет достаточно быстро, но в конце концов оранжевая линия ее обгоняет.
Согласно гипотезе об устойчивости архитектуры, на раннем этапе проекта мы успеваем сделать больше, если не слишком заморачиваемся об архитектуре. Однако, если не заниматься архитектурой вообще, то рано или поздно в ходе проекта наступит момент, когда для дальнейшего развития заняться архитектурой будет необходимо.
Следующая идея связана с отличиями между процедурным и объектно-ориентированным кодом.
Здесь мы сравним процедурный и объектно-ориентированный код в контексте того, насколько удобно модифицировать и понимать код первой и второй парадигмы. На следующей схеме представлены компромиссы, на которые требует идти первый и второй вариант.

Рис. 2
Удобство модификации кода откладывается по вертикальной оси. Код, изменять который проще всего, находится снизу. Чем сложнее его изменять — тем он выше.
По горизонтальной оси откладывается понятность кода. Самый очевидный код находится слева, самый сложный для восприятия – справа.
Простая процедура – это всего лишь список шагов. Простые процедуры легко осмысливаются и легко изменяются, они находятся в левой нижней четверти этой схемы. Этот сектор – наиболее дешевый и эффективный.
Для решения некоторых задач оптимально подходит как раз простой процедурный код без лишних условий и без дублирования. Что может быть бюджетнее? Пишем код и сразу запускаем.
Однако, со временем ситуация может измениться. Появится запрос на новую возможность (feature request), ради выполнения которого потребуется добавить условную логику или продублировать элементы решения в нескольких местах, что приведет нас к ситуации с рис. 3.
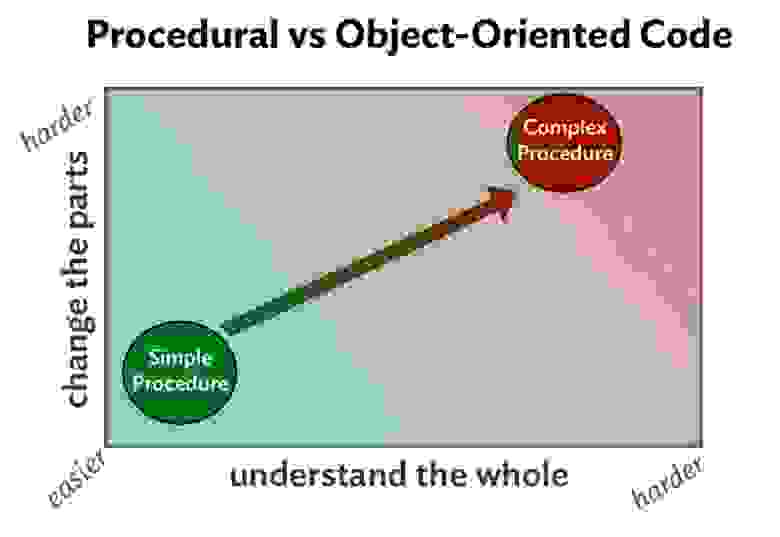
Рис. 3
Выше показано, как дешевая и эффективная процедура превратилась в сложную, обросшую условиями и дублями «трясину»; такой код сложно понимать и менять.
Простые процедуры необременительны, сложные – затратны. Единственный комплимент, который можно отвесить сложной процедуре (и он действительно единственный) – отметить, что весь этот #$%@! код находится в одном и том же месте. Однако, компактность как таковая еще не оправдывает сложности. Код можно упорядочивать и более рациональными способами.
На следующей схеме учтен и объектно-ориентированный код. Обратите внимание: ОО-решение немного затратнее обычной процедуры, но не сравнится по издержкам со сложным.
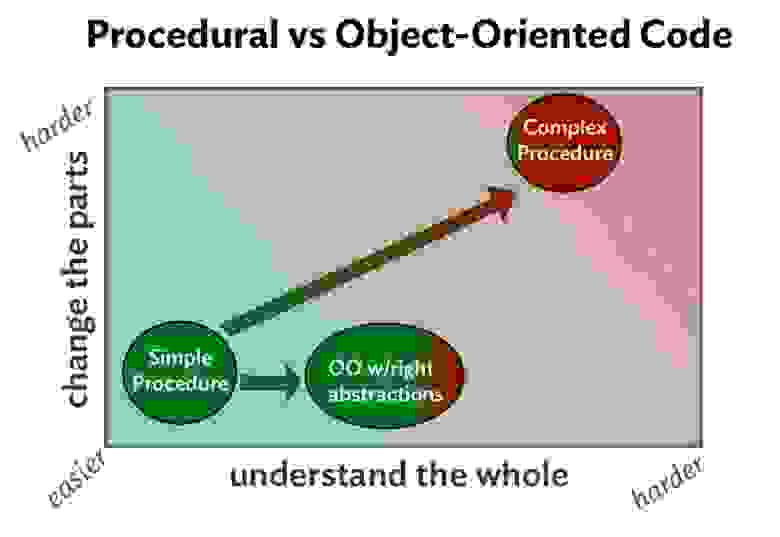
Рис. 4
В объектно-ориентированных решениях небольшие взаимозаменяемые объекты коммуницируют при помощи сообщений. Сообщения позволяют прокладывать своеобразные «швы», позволяющие заменять имеющиеся объекты аналогичными, выполняющими ту же роль. Обмен сообщениями облегчает модификацию поведения – для модификации требуется просто подставить новые элементы.
Также важно отметить, что обмен сообщениями скрывает детали получения результата. С точки зрения отправителя сообщение всего лишь описывает намерение. Получатель сообщения предоставляет реализацию, которая не известна отправителю. Таким образом, при помощи сообщений без труда обеспечивается локальная заменяемость, правда, за счет сокрытия удаленной реализации от отправителя.
Что касается сложных процедур, ОО-подход понятнее и сподручнее при изменениях. В случае с простыми процедурами ОО-код столь же удобно изменять, но в целом понимать его, вполне возможно, будет сложнее.
Итак, OO – не бесспорный и не беспроигрышный вариант. Все зависит от сложности стоящей перед вами задачи и от того, насколько долговечным должно быть ваше приложение.
Теперь, обращаясь к долговечности, рассмотрим последнюю идею — перепахивание кода (churn).
Обзор идеи «перепахивания» дан в статье Майкла Физерса Getting Empirical about Refactoring. Перепахивание – это характеристика, позволяющая оценить, насколько часто изменяется файл.
Феномен «перепахивания» интересен и сам по себе, но еще полезнее рассмотреть его в контексте «сложности». В статье Физерса есть следующая схема, на которую я добавила зеленую кривую.

Рис. 5
На этом рисунке показатель перепахивания откладывается по горизонтали, а сложность кода – по вертикали.
Сложный код, который изменяют редко, локализован в верхней левой четверти этой схемы. Да, сложность никому не нравится, но, если код не меняется, то нам ничего не стоит держать его сложным. Вообразите себе, что код – это шкафчик, набитый стопками пластиковой посуды. Достаточно приоткрыть дверцу – и все высыплется наружу. О коде из этого сегмента можно забыть, пока пересмотр не горит.
Простой код, который изменяют очень часто, относится к нижней правой четверти. Если код незамысловат (как, например, код в конфигурационном файле), то изменить его не составляет труда. Пока код остается прост, его можно менять по мере необходимости, так часто, как вздумается.
В левой нижней четверти находится код, который не слишком сложен и не так часто меняется – то есть, он уже организован эффективно, и на него также можно не обращать внимания.
Зеленая кривая начинается из левой верхней четверти, проходит через нижнюю левую и далее в нижнюю правую. Желательно, чтобы именно вдоль этой кривой был сосредоточен код в наших приложениях. Обратите внимание: кривая не заходит в верхнюю правую четверть.
Правая верхняя четверть – это сложный код, который часто меняется. По определению такой код будет сложно понимать и неудобно менять. Лучше, чтобы эта четверть так и пустовала, а если какой-то код туда и попадет, то он срочно нуждается в рефакторинге.
Теперь, когда мы рассмотрели эти идеи в общем контексте, я расскажу, опираясь на них, каким образом приложение может эволюционировать в порочном направлении.
Код развивается предсказуемо, превращаясь в мешанину
Существует характерный «код-мешанина», который попадается мне снова и снова. Предлагаю несколько схем с сайта Code Climate, иллюстрирующие на примерах нескольких проектов характерные симптомы превращения кода именно в такую мешанину (по состоянию на 7 сентября 2017).
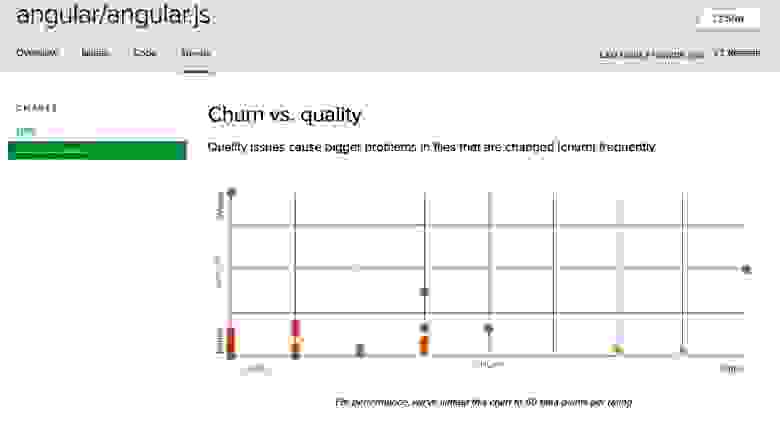
Рис. 6

Рис. 7
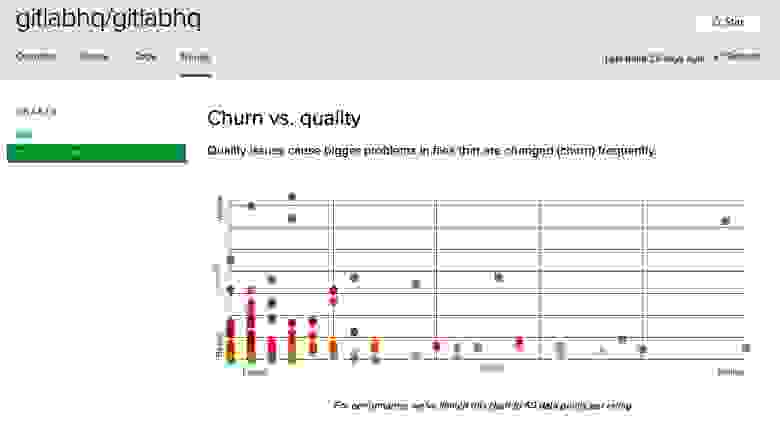
Рис. 8
Приведенные выше схемы «Перепахивание vs. качество» составлены на сайте Code Climate по мотивам физеровской идеи «Пересмотр файла vs. сложность». Обратите внимание: на всех схемах точки сосредоточены вдоль кривых, напоминающих зеленую кривую с рис. 6. Это хорошо. Похвалю разработчиков – в большинстве этих приложений сложный код почти не меняется, большинство изменений вносится в простой код.
Однако, на всех этих схемах есть и нежелательная «периферия» — код, расположенный в верхней правой четверти. Я не видела исходного кода этих приложений, но на основе одних лишь этих схем могу кое-что предположить о классах, оказавшихся на этой периферии. Думаю, что они:
Если хотите – можете убедиться сами. Если щелкнуть по каждой вышеприведенной схеме, то откроется соответствующая приложению страница на Code Climate. Оказавшись там, щелкните по периферийной точке – и откроется ссылка на соответствующий код. Как я уже сказала, в сущности, я не знаю этих приложений, но… уверена, что, исходя из их размера, сложности и темпов перепахивания, в данном случае ошибаться не могу. Если схема изменится к тому моменту, как вы будете читать эту статью, просто пропустите этот пример ;) и поверьте, что принцип работает.
Такая структура прослеживается во многих приложениях. Большая часть кода в приложении вполне понятна, и менять такой код несложно. Но в приложении обязательно найдется несколько больших, сложных и постоянно перепахиваемых классов – именно в этих классах выражены исключительно важные идеи предметной области.
Работа над этими периферийными классами всем ненавистна. Прикоснешься – сразу сломаешь. Тесты не гарантируют безопасности. Никакие меры не помогают. Несмотря на все старания, классы бухнут на глазах и усложняются. Было плохо – становится еще хуже.
Как такое происходит?
Можно объяснить проблему, воспользовавшись тремя вышеизложенными идеями. А если проблема понятна — то есть надежда ее предотвратить.
Я утверждаю:
Вот так и получаются приложения, в которых множество мелких эффективных классов соседствуют с дорогущим и громоздким бегемотом, напичканным условными конструкциями. Ряд небольших и безобидных поправок в самом важном коде вашего приложения превращают этот код в настолько сложный класс, что исправить эту проблему никому не под силу. Проблема явственно проявляется в пункте 15 из вышеприведенного списка, но коренится в пункте 8, когда сложность помаленьку нарастает, пока вся логика не пройдет точку невозврата.
Подолгу цепляться за процедурный код столь же вредно, как и слишком рано приступать к дизайну. Если важные классы в вашей предметной области меняются часто, при этом постоянно увеличиваются и обрастают условными конструкциями, то безотлагательно прекратите такую разработку. Реализуйте изменения в виде небольших, хорошо спроектированных классов, взаимодействующих с имеющимся объектом.
Класс на 5 000 строк обладает таким тяготением, что становится сложно представить, как в таком случае написать набор десятистрочных вспомогательных классов, которые удовлетворяли бы новым требованиям. В любом случае, пишите новые классы. Чтобы периферийные классы вновь подтянулись к зеленой линии, не поддавайтесь соблазну впихнуть еще больше кода в те объекты, которые и так уже огромны. Создавайте маленькие объекты, и со временем большие исчезнут.
У нас заканчивается уже порядком букинистическая книга "Ruby. Объектно-ориентированное проектирование" Сэнди Метц, которую мы надеемся обновить в будущем году. Тем временем мы убедились, что читателей госпожи Метц немало интересуют ее взгляды на ООП, а не только на ООП в Ruby, поэтому предлагаем перевод ее сентябрьской статьи с большим количеством картинок и немалым количеством интересных выводов на заявленную тему. Приятного чтения!
Привет!
Бывает, я размышляю о том, как развиваются приложения, и что делать, если результаты нас не устраивают. При этом я обдумываю три явно разнохарактерные идеи. В этом посте я изложу все три и объединю их. Надеюсь, что, поняв эти взаимосвязи, мы лучше разберемся и в наших приложениях.
Эти мысли – мое личное мнение, основаны лишь на моем собственном опыте. Ваше мнение может отличаться, но, надеюсь, что подкину вам пищу для размышлений. Ниже – много картинок. Представьте себе, что я прямо перед вами рисую их на маркерной доске.
Первая идея принадлежит Мартину Фаулеру и называется «Design Stamina Hypothesis» (гипотеза об устойчивости архитектуры).
#1: Гипотеза об устойчивости архитектуры
Фаулер иллюстрирует эту идею при помощи следующей псевдо-схемы.

Рис. 1
По вертикальной оси откладывается накопленная функциональность. Чем выше линия графика — тем больше мы успели сделать. По горизонтальной оси откладывается потраченное время. Чем дальше вправо — тем позже.
В координатной сетке вычерчены два разных графика. Оранжевая линия показывает, какой объем функциональности мы будем продуцировать к любому моменту времени, если станем заниматься дизайном с первого же дня работы. Синяя линия показывает, каков будет результат, если пренебречь серьезным дизайном. Обратите внимание: на первом этапе синяя линия растет достаточно быстро, но в конце концов оранжевая линия ее обгоняет.
Согласно гипотезе об устойчивости архитектуры, на раннем этапе проекта мы успеваем сделать больше, если не слишком заморачиваемся об архитектуре. Однако, если не заниматься архитектурой вообще, то рано или поздно в ходе проекта наступит момент, когда для дальнейшего развития заняться архитектурой будет необходимо.
Следующая идея связана с отличиями между процедурным и объектно-ориентированным кодом.
#2: Сравнение процедурного и объектно-ориентированного кода
Здесь мы сравним процедурный и объектно-ориентированный код в контексте того, насколько удобно модифицировать и понимать код первой и второй парадигмы. На следующей схеме представлены компромиссы, на которые требует идти первый и второй вариант.

Рис. 2
Удобство модификации кода откладывается по вертикальной оси. Код, изменять который проще всего, находится снизу. Чем сложнее его изменять — тем он выше.
По горизонтальной оси откладывается понятность кода. Самый очевидный код находится слева, самый сложный для восприятия – справа.
Простая процедура – это всего лишь список шагов. Простые процедуры легко осмысливаются и легко изменяются, они находятся в левой нижней четверти этой схемы. Этот сектор – наиболее дешевый и эффективный.
Для решения некоторых задач оптимально подходит как раз простой процедурный код без лишних условий и без дублирования. Что может быть бюджетнее? Пишем код и сразу запускаем.
Однако, со временем ситуация может измениться. Появится запрос на новую возможность (feature request), ради выполнения которого потребуется добавить условную логику или продублировать элементы решения в нескольких местах, что приведет нас к ситуации с рис. 3.
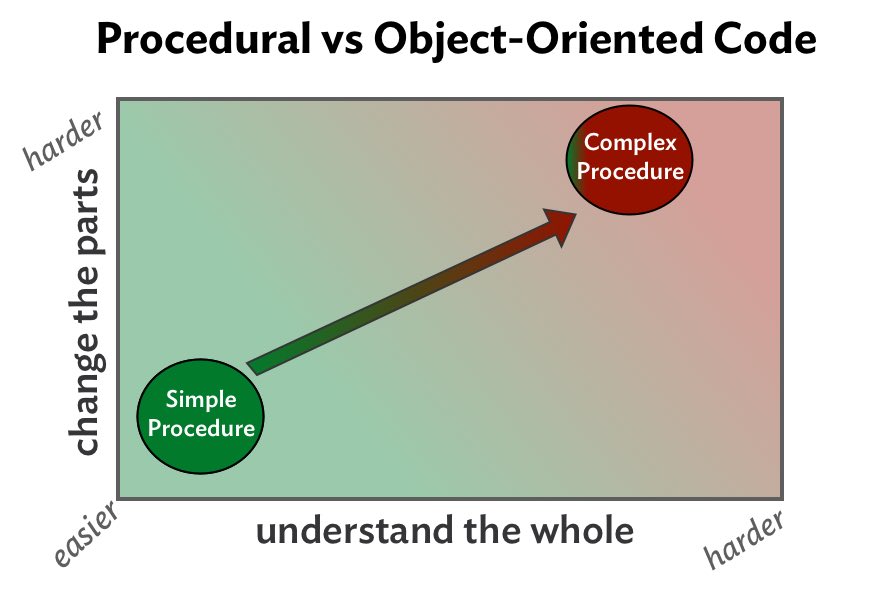
Рис. 3
Выше показано, как дешевая и эффективная процедура превратилась в сложную, обросшую условиями и дублями «трясину»; такой код сложно понимать и менять.
Простые процедуры необременительны, сложные – затратны. Единственный комплимент, который можно отвесить сложной процедуре (и он действительно единственный) – отметить, что весь этот #$%@! код находится в одном и том же месте. Однако, компактность как таковая еще не оправдывает сложности. Код можно упорядочивать и более рациональными способами.
На следующей схеме учтен и объектно-ориентированный код. Обратите внимание: ОО-решение немного затратнее обычной процедуры, но не сравнится по издержкам со сложным.

Рис. 4
В объектно-ориентированных решениях небольшие взаимозаменяемые объекты коммуницируют при помощи сообщений. Сообщения позволяют прокладывать своеобразные «швы», позволяющие заменять имеющиеся объекты аналогичными, выполняющими ту же роль. Обмен сообщениями облегчает модификацию поведения – для модификации требуется просто подставить новые элементы.
Также важно отметить, что обмен сообщениями скрывает детали получения результата. С точки зрения отправителя сообщение всего лишь описывает намерение. Получатель сообщения предоставляет реализацию, которая не известна отправителю. Таким образом, при помощи сообщений без труда обеспечивается локальная заменяемость, правда, за счет сокрытия удаленной реализации от отправителя.
Что касается сложных процедур, ОО-подход понятнее и сподручнее при изменениях. В случае с простыми процедурами ОО-код столь же удобно изменять, но в целом понимать его, вполне возможно, будет сложнее.
Итак, OO – не бесспорный и не беспроигрышный вариант. Все зависит от сложности стоящей перед вами задачи и от того, насколько долговечным должно быть ваше приложение.
Теперь, обращаясь к долговечности, рассмотрим последнюю идею — перепахивание кода (churn).
#3: Перепахивание кода и сложность
Обзор идеи «перепахивания» дан в статье Майкла Физерса Getting Empirical about Refactoring. Перепахивание – это характеристика, позволяющая оценить, насколько часто изменяется файл.
Феномен «перепахивания» интересен и сам по себе, но еще полезнее рассмотреть его в контексте «сложности». В статье Физерса есть следующая схема, на которую я добавила зеленую кривую.
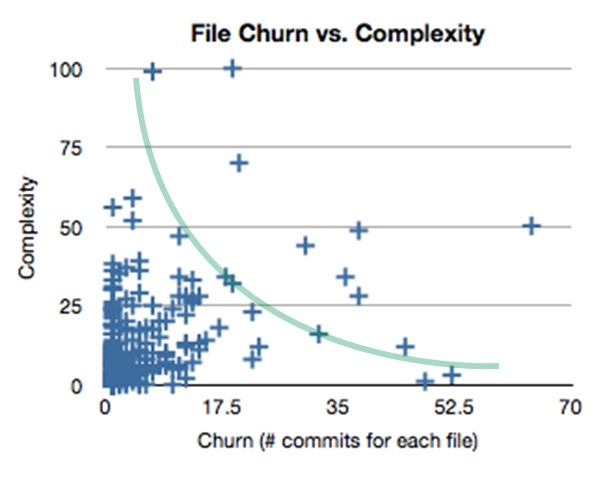
Рис. 5
На этом рисунке показатель перепахивания откладывается по горизонтали, а сложность кода – по вертикали.
Сложный код, который изменяют редко, локализован в верхней левой четверти этой схемы. Да, сложность никому не нравится, но, если код не меняется, то нам ничего не стоит держать его сложным. Вообразите себе, что код – это шкафчик, набитый стопками пластиковой посуды. Достаточно приоткрыть дверцу – и все высыплется наружу. О коде из этого сегмента можно забыть, пока пересмотр не горит.
Простой код, который изменяют очень часто, относится к нижней правой четверти. Если код незамысловат (как, например, код в конфигурационном файле), то изменить его не составляет труда. Пока код остается прост, его можно менять по мере необходимости, так часто, как вздумается.
В левой нижней четверти находится код, который не слишком сложен и не так часто меняется – то есть, он уже организован эффективно, и на него также можно не обращать внимания.
Зеленая кривая начинается из левой верхней четверти, проходит через нижнюю левую и далее в нижнюю правую. Желательно, чтобы именно вдоль этой кривой был сосредоточен код в наших приложениях. Обратите внимание: кривая не заходит в верхнюю правую четверть.
Правая верхняя четверть – это сложный код, который часто меняется. По определению такой код будет сложно понимать и неудобно менять. Лучше, чтобы эта четверть так и пустовала, а если какой-то код туда и попадет, то он срочно нуждается в рефакторинге.
Теперь, когда мы рассмотрели эти идеи в общем контексте, я расскажу, опираясь на них, каким образом приложение может эволюционировать в порочном направлении.
Код развивается предсказуемо, превращаясь в мешанину
Существует характерный «код-мешанина», который попадается мне снова и снова. Предлагаю несколько схем с сайта Code Climate, иллюстрирующие на примерах нескольких проектов характерные симптомы превращения кода именно в такую мешанину (по состоянию на 7 сентября 2017).

Рис. 6

Рис. 7

Рис. 8
Приведенные выше схемы «Перепахивание vs. качество» составлены на сайте Code Climate по мотивам физеровской идеи «Пересмотр файла vs. сложность». Обратите внимание: на всех схемах точки сосредоточены вдоль кривых, напоминающих зеленую кривую с рис. 6. Это хорошо. Похвалю разработчиков – в большинстве этих приложений сложный код почти не меняется, большинство изменений вносится в простой код.
Однако, на всех этих схемах есть и нежелательная «периферия» — код, расположенный в верхней правой четверти. Я не видела исходного кода этих приложений, но на основе одних лишь этих схем могу кое-что предположить о классах, оказавшихся на этой периферии. Думаю, что они:
- Крупнее большинства остальных классов
- Нагружены условными конструкциями и
- Описывают основные концепции предметной области
Если хотите – можете убедиться сами. Если щелкнуть по каждой вышеприведенной схеме, то откроется соответствующая приложению страница на Code Climate. Оказавшись там, щелкните по периферийной точке – и откроется ссылка на соответствующий код. Как я уже сказала, в сущности, я не знаю этих приложений, но… уверена, что, исходя из их размера, сложности и темпов перепахивания, в данном случае ошибаться не могу. Если схема изменится к тому моменту, как вы будете читать эту статью, просто пропустите этот пример ;) и поверьте, что принцип работает.
Такая структура прослеживается во многих приложениях. Большая часть кода в приложении вполне понятна, и менять такой код несложно. Но в приложении обязательно найдется несколько больших, сложных и постоянно перепахиваемых классов – именно в этих классах выражены исключительно важные идеи предметной области.
Работа над этими периферийными классами всем ненавистна. Прикоснешься – сразу сломаешь. Тесты не гарантируют безопасности. Никакие меры не помогают. Несмотря на все старания, классы бухнут на глазах и усложняются. Было плохо – становится еще хуже.
Как такое происходит?
Можно объяснить проблему, воспользовавшись тремя вышеизложенными идеями. А если проблема понятна — то есть надежда ее предотвратить.
Я утверждаю:
- Преждевременная работа над дизайном – напрасный труд.
(Рис. 1 – оранжевая линия на ранних этапах) - Если вообще не заниматься дизайном, то код превратится в жуткую кашу.
(Рис. 1 – голубая линия на поздних этапах) - На определенном этапе потребуется инвестировать в дизайн, это сэкономит вам деньги
(Рис. 1 – точка пересечения двух линий) - Простые процедуры почти не требуют дизайна, поддерживать их легко.
(Рис. 2, Рис. 1: начало голубой линии) - Процедуры со временем усложняются, и поддерживать их становится все более затратно.
(Рис. 3, Рис. 1: голубая линия на поздних этапах) - С экономической точки зрения объектно-ориентированный код выгоднее, чем сложный процедурный код.
(Рис. 4) - Те процедуры, что наиболее важны для вашей предметной области, меняются чаще, чем неспецифические процедуры.
- Те процедуры, что наиболее важны для вашей предметной области, усложняются быстрее остального кода
- Сложно уловить тот момент, в который ваше приложение пересечет линию «целесообразности дизайна»
(Рис. 1) - 10. Вы поймете, что эта линия позади, когда темпы разработки замедлятся, а проблемы станут нарастать.
(Рис. 1 – часть голубой линии, расположенная под линией целесообразности дизайна) - К тому моменту, как вы это поймете, самый важный код уже окажется в наиболее запущенном виде.
- Умеренно сложные процедуры легко преобразовать в OO.
- Исключительно сложные процедуры труднее всего преобразуются в OO.
- Попытки преобразовать умеренно сложные процедуры в OO обычно успешны.
- Попытки преобразовать исключительно сложные процедуры в OO часто терпят фиаско.
Вот так и получаются приложения, в которых множество мелких эффективных классов соседствуют с дорогущим и громоздким бегемотом, напичканным условными конструкциями. Ряд небольших и безобидных поправок в самом важном коде вашего приложения превращают этот код в настолько сложный класс, что исправить эту проблему никому не под силу. Проблема явственно проявляется в пункте 15 из вышеприведенного списка, но коренится в пункте 8, когда сложность помаленьку нарастает, пока вся логика не пройдет точку невозврата.
Подолгу цепляться за процедурный код столь же вредно, как и слишком рано приступать к дизайну. Если важные классы в вашей предметной области меняются часто, при этом постоянно увеличиваются и обрастают условными конструкциями, то безотлагательно прекратите такую разработку. Реализуйте изменения в виде небольших, хорошо спроектированных классов, взаимодействующих с имеющимся объектом.
Класс на 5 000 строк обладает таким тяготением, что становится сложно представить, как в таком случае написать набор десятистрочных вспомогательных классов, которые удовлетворяли бы новым требованиям. В любом случае, пишите новые классы. Чтобы периферийные классы вновь подтянулись к зеленой линии, не поддавайтесь соблазну впихнуть еще больше кода в те объекты, которые и так уже огромны. Создавайте маленькие объекты, и со временем большие исчезнут.
Only registered users can participate in poll. Log in, please.
Мои впечатления
63.04% Нормальная статья, мне понравилось29
10.87% Нормальная статья, обновите пожалуйста книгу по Ruby5
10.87% Вообще не воспринимаю этого автора, обновление книги по Ruby не интересует5
34.78% Хотелось бы более общую книгу о проектировании и рефакторинге16
15.22% Не забудьте опубликовать в этой рубрике статью Майкла Физерса7
46 users voted. 14 users abstained.
