В прошлые разы мы рассмотрели механизм индексирования PostgreSQL, интерфейс методов доступа, и два метода: хеш-индекс и B-дерево. В этой части займемся индексами GiST.
GiST
GiST — сокращение от «generalized search tree». Это сбалансированное дерево поиска, точно так же, как и рассмотренный ранее b-tree.
В чем же разница? Индекс b-tree жестко привязан к семантике сравнения: поддержка операторов «больше», «меньше», «равно» — это все, на что он способен (зато способен очень хорошо!). Но в современных базах хранятся и такие типы данных, для которых эти операторы просто не имеют смысла: геоданные, текстовые документы, картинки…
Тут на помощь и приходит индексный метод GiST. Он позволяет задать принцип распределения данных произвольного типа по сбалансированному дереву, и метод использования этого представления для доступа по некоторому оператору. Например, в GiST-индекс можно «уложить» R-дерево для пространственных данных с поддержкой операторов взаимного расположения (находится слева, справа; содержит и т. п.), или RD-дерево для множеств с поддержкой операторов пересечения или вхождения.
За счет расширяемости в PostgreSQL вполне можно создать совершенно новый метод доступа с нуля: для этого надо реализовать интерфейс с механизмом индексирования. Но это требует продумывания не только логики индексации, но и страничной структуры, эффективной реализации блокировок, поддержки журнала упреждающей записи — что подразумевает очень высокую квалификацию разработчика и большую трудоемкость. GiST упрощает задачу, беря на себя низкоуровневые проблемы и предоставляя свой собственный интерфейс: несколько функций, относящихся не к технической сфере, а к прикладной области. В этом смысле можно говорить о том, что GiST является каркасом для построения новых методов доступа.
Устройство
GiST — сбалансированное по высоте дерево, состоящее из узлов-страниц. Узлы состоят из индексных записей.
Каждая запись листового узла (листовая запись) содержит, если говорить в самом общем виде, некий предикат (логическое выражение) и ссылку на строку таблицы (TID). Индексированные данные (ключ) должны удовлетворять этому предикату.
Каждая запись внутреннего узла (внутренняя запись) также содержит предикат и ссылку на дочерний узел, причем все индексированные данные дочернего поддерева должны удовлетворять этому предикату. Иными словами, предикат внутренней записи включает в себя предикаты всех дочерних записей. Это важное свойство, заменяющее индексу GiST простую упорядоченность B-дерева.
Поиск в дереве GiST использует специальную функцию согласованности (consistent) — одну из функций, определяемых интерфейсом, и реализуемую по-своему для каждого поддерживаемого семейства операторов.
Функция согласованности вызывается для индексной записи и определяет, «согласуется» ли предикат данной записи с поисковым условием (вида «индексированное-поле оператор выражение»). Для внутренней записи она фактически определяет, надо ли спускаться в соответствующее поддерево, а для листовой записи — удовлетворяют ли индексированные данные условию.
Поиск, как обычно в дереве, начинается с корневого узла. С помощью функции согласованности выясняется, в какие дочерние узлы имеет смысл заходить (их может оказаться несколько), а в какие — нет. Затем алгоритм повторяется для каждого из найденных дочерних узлов. Если же узел является листовым, то запись, отобранная функцией согласованности, возвращается в качестве одного из результатов.
Поиск производится в глубину: алгоритм в первую очередь старается добраться до какого-нибудь листового узла. Это позволяет по возможности быстро вернуть первые результаты (что может быть важно, если пользователя интересуют не все результаты, а только несколько).
Еще раз обратим внимание, что функция согласованности не должна иметь какое-либо отношение к операторам «больше», «меньше» или «равно». Ее семантика может быть совершенно иной, и поэтому не предполагается, что индекс будет выдавать значения в каком-то определенном порядке.
Мы не будем рассматривать алгоритмы вставки и удаления значений в GiST — для этого используется еще несколько интерфейсных функций. Но есть один важный момент. При вставке в индекс нового значения для него выбирается такая родительская запись, чтобы ее предикат пришлось расширить как можно меньше (в идеале, не расширить вовсе). Но при удалении значения предикат родительской записи уже не сужается. Это происходит только в двух случаях: при разделении страницы на две (когда на странице не хватает места для вставки новой индексной записи) и при полном перестроении индекса (командами reindex или vacuum full). Поэтому эффективность GiST-индекса при часто меняющихся данных может со временем деградировать.
Дальше мы рассмотрим несколько примеров индексов для разных типов данных и полезные свойства GiST:
- точки (и другие геометрические объекты) и поиск ближайших соседей;
- интервалы и ограничения исключения;
- полнотекстовый поиск.
R-дерево для точек
Продемонстрируем сказанное выше на примере индекса для точек на плоскости (похожие индексы можно построить и для других геометрических объектов). Обычное B-дерево не подходит для такого типа данных, так как для точек не определены операторы сравнения.
Идея R-дерева состоит в том, что плоскость разбивается на прямоугольники, которые в сумме покрывают все индексируемые точки. Индексная запись хранит прямоугольник, а предикат можно сформулировать так: «искомая точка лежит внутри данного прямоугольника».
Корень R-дерева будет содержать несколько самых крупных прямоугольников (возможно, даже пересекающихся). Дочерние узлы будут содержать меньшие по размеру прямоугольники, вложенные в родительский, в совокупности охватывающие все нижележащие точки.
Листовые узлы, по идее, должны содержать индексируемые точки, однако тип данных во всех индексных записях должен совпадать; поэтому хранятся все те же прямоугольники, но «схлопнутые» до точек.
Чтобы представить себе такую структуру наглядно, ниже приведены рисунки трех уровней R-дерева; точки представляют координаты аэропортов (аналогично таблице airports демо-базы, но здесь взято больше данных с сайта openflights.org).
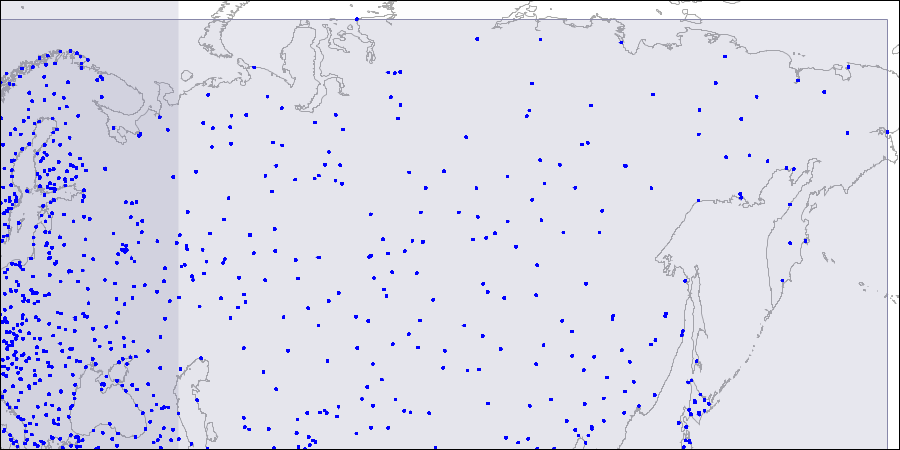
Первый уровень; видны два больших пересекающихся прямоугольника.

Второй уровень; большие прямоугольники распадаются на области поменьше.
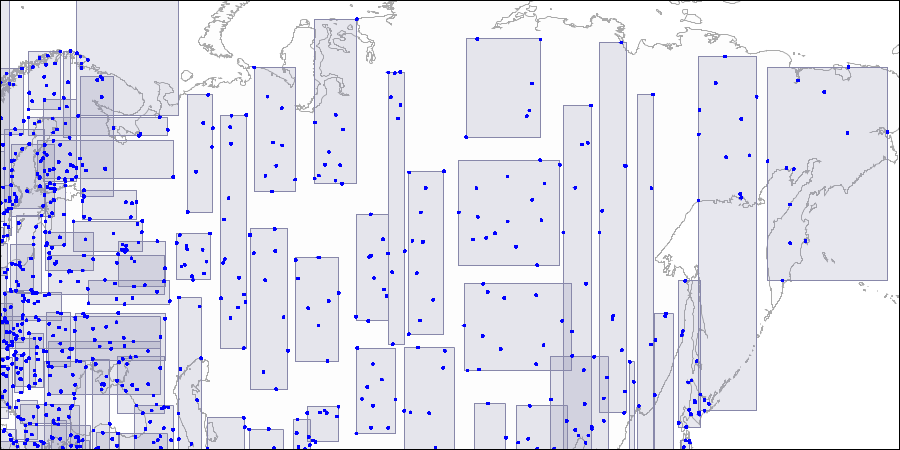
Третий уровень; каждый прямоугольник содержит столько точек, чтобы они помещались на одну страницу индекса.
Рассмотрим теперь подробнее совсем простой «одноуровневый» пример:
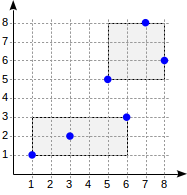
postgres=# create table points(p point);
CREATE TABLE
postgres=# insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
INSERT 0 6
postgres=# create index on points using gist(p);
CREATE INDEX
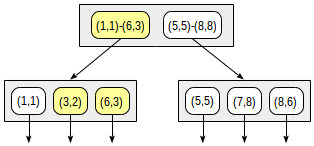
Структура индекса при таком разбиении будет выглядеть следующим образом:
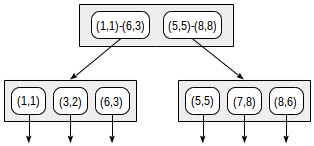
Созданный индекс может использоваться для ускорения, например, такого запроса: «найти все точки, входящие в заданный прямоугольник». Это условие формулируется так:
p <@ box '(2,1),(6,3)' (оператор <@ из семейства points_ops означает «содержится в»):postgres=# set enable_seqscan = off;
SET
postgres=# explain(costs off) select * from points where p <@ box '(2,1),(7,4)';
QUERY PLAN
----------------------------------------------
Index Only Scan using points_p_idx on points
Index Cond: (p <@ '(7,4),(2,1)'::box)
(2 rows)
Функция согласованности для такого оператора («индексированное-поле <@ выражение», где индексированное-поле является точкой, а выражение — прямоугольником) определена следующим образом. Для внутренней записи она возвращает «да», если ее прямоугольник пересекается с прямоугольником, определяемым выражением. Для листовой записи функция возвращает «да», если ее точка («схлопнутый» прямоугольник) содержится в прямоугольнике, определяемым выражением.
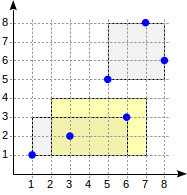
Поиск начинается с корневого узла. Прямоугольник (2,1)-(7,4) пересекается с (1,1)-(6,3), но не пересекается с (5,5)-(8,8), поэтому во второе поддерево спускаться не нужно.
Придя в листовой узел, перебираем три содержащиеся там точки и две из них возвращаем в качестве результата: (3,2) и (6,3).
postgres=# select * from points where p <@ box '(2,1),(7,4)';
p
-------
(3,2)
(6,3)
(2 rows)
Внутри
Обычный pageinspect, увы, не позволяет заглянуть внутрь GiST-индекса. Но есть другой способ — расширение gevel. Оно не входит в стандартную поставку; смотрите инструкцию по установке.
Если все проделано правильно, вам будут доступны три функции. Во-первых, некоторая статистика:
postgres=# select * from gist_stat('airports_coordinates_idx');
gist_stat
------------------------------------------
Number of levels: 4 +
Number of pages: 690 +
Number of leaf pages: 625 +
Number of tuples: 7873 +
Number of invalid tuples: 0 +
Number of leaf tuples: 7184 +
Total size of tuples: 354692 bytes +
Total size of leaf tuples: 323596 bytes +
Total size of index: 5652480 bytes+
(1 row)
Тут видно, что индекс по координатам аэропорта занял 690 страниц и состоит из четырех уровней: корень и два внутренних уровня были показаны выше на рисунках, а четвертый уровень — листовой.
На самом деле индекс для восьми тысяч точек будет занимать гораздо меньше места: здесь для наглядности он был создан с заполнением 10%.
Во-вторых, можно вывести дерево индекса:
postgres=# select * from gist_tree('airports_coordinates_idx');
gist_tree
-----------------------------------------------------------------------------------------
0(l:0) blk: 0 numTuple: 5 free: 7928b(2.84%) rightlink:4294967295 (InvalidBlockNumber) +
1(l:1) blk: 335 numTuple: 15 free: 7488b(8.24%) rightlink:220 (OK) +
1(l:2) blk: 128 numTuple: 9 free: 7752b(5.00%) rightlink:49 (OK) +
1(l:3) blk: 57 numTuple: 12 free: 7620b(6.62%) rightlink:35 (OK) +
2(l:3) blk: 62 numTuple: 9 free: 7752b(5.00%) rightlink:57 (OK) +
3(l:3) blk: 72 numTuple: 7 free: 7840b(3.92%) rightlink:23 (OK) +
4(l:3) blk: 115 numTuple: 17 free: 7400b(9.31%) rightlink:33 (OK) +
...
И в-третьих, можно вывести сами данные, которые хранятся в индексных записях. Тонкий момент: результат функции надо преобразовывать к нужному типу данных. В нашем случае этот тип — box (ограничивающий прямоугольник). Например, на верхнем уровне видим пять записей:
postgres=# select level, a from gist_print('airports_coordinates_idx')
as t(level int, valid bool, a box) where level = 1;
level | a
-------+-----------------------------------------------------------------------
1 | (47.663586,80.803207),(-39.2938003540039,-90)
1 | (179.951004028,15.6700000762939),(15.2428998947144,-77.9634017944336)
1 | (177.740997314453,73.5178070068359),(15.0664,10.57970047)
1 | (-77.3191986083984,79.9946975708),(-179.876998901,-43.810001373291)
1 | (-39.864200592041,82.5177993774),(-81.254096984863,-64.2382965088)
(5 rows)
Собственно, рисунки выше были подготовлены как раз на основе этих данных.
Поисковые и упорядочивающие операторы
Операторы, рассмотренные до сих пор (такие, как
<@ в предикате p <@ box '(2,1),(7,4)'), можно назвать поисковыми, так как они задают условия поиска в запросе.Есть и другой тип операторов — упорядочивающие. Они используются для указания порядка выдаваемых результатов во фразе order by там, где обычно применяется простое указание полей. Вот пример такого запроса:
postgres=# select * from points order by p <-> point '(4,7)' limit 2;
p
-------
(5,5)
(7,8)
(2 rows)
Здесь
p <-> point '(4,7)' — выражение, использующее упорядочивающий оператор <->, который обозначает расстояние от одного аргумента до другого. Смысл запроса: выдать две точки, ближайшие к точке (4,7). Такой поиск известен как k-NN — k-nearest neighbor search.Для поддержки такого вида запросов метода доступа должен определить дополнительную функцию расстояния (distance), а упорядочивающий оператор должен быть включен в соответствующий класс операторов (например, для точек — класс points_ops). Вот запрос который показывает операторы и их тип (s — поисковый, o — упорядочивающий):
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gist'
and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy
-------------------+-------------+--------------
<<(point,point) | s | 1 строго слева
>>(point,point) | s | 5 строго справа
~=(point,point) | s | 6 совпадает
<^(point,point) | s | 10 строго снизу
>^(point,point) | s | 11 строго сверху
<->(point,point) | o | 15 расстояние
<@(point,box) | s | 28 содержится в прямоугольнике
<@(point,polygon) | s | 48 содержится в полигоне
<@(point,circle) | s | 68 содержится в окружности
(9 rows)
Здесь показаны также и номера стратегий с расшифровкой их значения. Видно, что стратегий гораздо больше, чем у btree; только часть их них поддерживается для точек. Для других типов данных могут определяться другие стратегии.
Функция расстояния вызывается для элемента индекса и должна определить расстояние (с учетом семантики оператора) от значения, определяемого выражением («индексированное-поле упорядочивающий-оператор выражение»), до данного элемента. Для листового элемента это просто расстояние до индексированного значения. Для внутреннего элемента функция должна вернуть минимальное из расстояний до дочерних листовых элементов. Поскольку перебирать все дочерние записи было бы весьма накладно, функция имеет право оптимистически приуменьшать расстояние, но ценой ухудшения эффективности поиска. Однако преувеличивать она не должна категорически — это нарушит работу индекса.
Функция расстояния может возвращать значение любого типа, допускающего сортировку (для упорядочения PostgreSQL будет использовать семантику сравнения из соответствующего семейства операторов метода доступа btree, как было описано ранее).
В случае точек на плоскости расстояние понимается в самом обычном смысле: значение выражения
(x1,y1) <-> (x2,y2) равно корню из суммы квадратов разностей абсцисс и ординат. За расстояние от точки до ограничивающего прямоугольника принимается минимальное расстояние от точки до этого прямоугольника, или ноль, если точка находится внутри него. Это значение легко вычислить, не обходя дочерние точки, и оно гарантированно не больше расстояния до любой из дочерних точек.Рассмотрим алгоритм поиска для приведенного выше запроса.
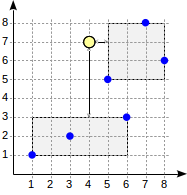
Поиск начинается с корневого узла. В нем имеется два ограничивающих прямоугольника. Расстояние до (1,1)-(6,3) составляет 4.0, а до (5,5)-(8,8) — 1.0.
Обход дочерних узлов происходит в порядке увеличения расстояния. Таким образом, сначала спускаемся в ближайший дочерний узел и находим расстояния до точек (для наглядности покажем цифры на рисунке):

Этой информации уже достаточно, чтобы вернуть первые две точки (5,5) и (7,8). Поскольку нам известно, что расстояние до точек, находящихся внутри прямоугольника (1,1)-(6,3), составляет 4.0 или больше, то нет необходимости спускаться в первый дочерний узел.
Что, если бы нам потребовалось найти первые три точки?
postgres=# select * from points order by p <-> point '(4,7)' limit 3;
p
-------
(5,5)
(7,8)
(8,6)
(3 rows)
Хотя все эти точки содержатся во втором дочернем узле, мы не можем вернуть (8,6), не заглянув в первый дочерний узел, поскольку там могут оказаться более близкие точки (так как 4.0 < 4.1).

Этот пример поясняет требования к функции расстояния для внутренних записей. Выбрав для второй записи меньшее расстояние (4.0 вместо реальных 4.5), мы ухудшили эффективность (алгоритм напрасно стал просматривать лишний узел), но не нарушили правильность работы.
До недавнего времени GiST был единственным методом доступа, умеющим работать с упорядочивающими операторами. Но ситуация изменилась: в эту компанию уже добавился метод RUM (про который мы будем говорить позже), и не исключено, что к ним присоединится старое доброе B-дерево — патч, написанный нашим коллегой Никитой Глуховым, обсуждается сообществом.
R-дерево для интервалов
Другим примером использования метода доступа gist является индексирование интервалов, например, временных (тип tsrange). Вся разница в том, что внутренние узлы дерева будут содержать не ограничивающие прямоугольники, а ограничивающие интервалы.
Простой пример. Будем сдавать в аренду домик в деревне и хранить в таблице интервалы бронирования:
postgres=# create table reservations(during tsrange);
CREATE TABLE
postgres=# insert into reservations(during) values
('[2016-12-30, 2017-01-09)'),
('[2017-02-23, 2017-02-27)'),
('[2017-04-29, 2017-05-02)');
INSERT 0 3
postgres=# create index on reservations using gist(during);
CREATE INDEX
Индекс может использоваться, например, для ускорения следующего запроса:
postgres=# select * from reservations where during && '[2017-01-01, 2017-04-01)';
during
-----------------------------------------------
["2016-12-30 00:00:00","2017-01-08 00:00:00")
["2017-02-23 00:00:00","2017-02-26 00:00:00")
(2 rows)
postgres=# explain (costs off) select * from reservations where during && '[2017-01-01, 2017-04-01)';
QUERY PLAN
------------------------------------------------------------------------------------
Index Only Scan using reservations_during_idx on reservations
Index Cond: (during && '["2017-01-01 00:00:00","2017-04-01 00:00:00")'::tsrange)
(2 rows)
Оператор
&& для интервалов обозначает пересечение; таким образом запрос должен выдать все интервалы, пересекающиеся с заданным. Для такого оператора функция согласованности определяет, пересекается ли указанный интервал со значением во внутренней или листовой записи.Заметим, что и в этом случае речь не идет о том, чтобы получить интервалы в определенном порядке, хотя для интервалов определены операторы сравнения. Для них можно использовать индекс b-tree, но в таком случае придется обойтись без поддержки таких операций, как:
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'range_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gist'
and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy
-------------------------+-------------+--------------
@>(anyrange,anyelement) | s | 16 содержит элемент
<<(anyrange,anyrange) | s | 1 строго слева
&<(anyrange,anyrange) | s | 2 не выходит за правую границу
&&(anyrange,anyrange) | s | 3 пересекается
&>(anyrange,anyrange) | s | 4 не выходит за левую границу
>>(anyrange,anyrange) | s | 5 строго справа
-|-(anyrange,anyrange) | s | 6 прилегает
@>(anyrange,anyrange) | s | 7 содержит интервал
<@(anyrange,anyrange) | s | 8 содержится в интервале
=(anyrange,anyrange) | s | 18 равен
(10 rows)
(Кроме равенства, которое входит и в класс операторов для метода доступа btree.)
Внутри
Внутрь можно заглянуть все тем же расширением gevel. Надо только не забыть поменять тип данных в вызове gist_print:
postgres=# select level, a from gist_print('reservations_during_idx')
as t(level int, valid bool, a tsrange);
level | a
-------+-----------------------------------------------
1 | ["2016-12-30 00:00:00","2017-01-09 00:00:00")
1 | ["2017-02-23 00:00:00","2017-02-27 00:00:00")
1 | ["2017-04-29 00:00:00","2017-05-02 00:00:00")
(3 rows)
Ограничение исключения
Индекс GiST может применяться для поддержки ограничений исключения (exclude).
Ограничение исключения гарантирует, что заданные поля любых двух строк таблицы не будут «соответствовать» друг другу в смысле некоторого оператора. Если в качестве оператора выбрать «равно», то получится в точности ограничение уникальности: заданные поля любых двух строк не равны друг другу.
Как и ограничение уникальности, ограничение исключения поддерживается индексом. Можно выбрать любой оператор, лишь бы он:
- поддерживался индексным методом — свойство can_exclude (это, например, методы btree, gist или spgist, но не gin);
- был коммутативен, то есть должно выполняться условие: a оператор b =
b оператор a.
Вот перечень подходящих стратегий и примеры операторов (операторы, как мы помним, могут называться по-разному и быть доступны не для всех типов данных):
- для btree:
- «равно»
=
- «равно»
- для gist и spgist:
- «пересечение»
&& - «совпадение»
~= - «прилегание»
-|-
- «пересечение»
Заметим, что использовать оператор равенства в ограничении исключения можно, но не имеет практического смысла: ограничение уникальности будет эффективнее. Именно поэтому мы не касались ограничений исключения, когда говорили о B-деревьях.
Приведем пример использования ограничения исключения. Логично не допускать бронирования домика на пересекающиеся интервалы времени.
postgres=# alter table reservations add exclude using gist(during with &&);
ALTER TABLE
После создания ограничения целостности мы можем добавлять строки:
postgres=# insert into reservations(during) values ('[2017-06-10, 2017-06-13)');
INSERT 0 1
Но попытка вставить в таблицу пересекающийся интервал приведет к ошибке:
postgres=# insert into reservations(during) values ('[2017-05-15, 2017-06-15)');
ERROR: conflicting key value violates exclusion constraint "reservations_during_excl"
DETAIL: Key (during)=(["2017-05-15 00:00:00","2017-06-15 00:00:00")) conflicts with existing key (during)=(["2017-06-10 00:00:00","2017-06-13 00:00:00")).
Расширение btree_gist
Усложним задачу. Наш скромный бизнес расширяется и мы собираемся сдавать несколько домиков:
postgres=# alter table reservations add house_no integer default 1;
ALTER TABLE
Нам нужно изменить ограничение исключения так, чтобы учитывать и номер дома. Однако GiST не поддерживает операцию равенства для целых чисел:
postgres=# alter table reservations drop constraint reservations_during_excl;
ALTER TABLE
postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
ERROR: data type integer has no default operator class for access method "gist"
HINT: You must specify an operator class for the index or define a default operator class for the data type.
В этом случае поможет расширение btree_gist, которое добавляет GiST-поддержку операций, характерных для B-деревьев. В конце концов, GiST может работать с любыми операторами, так почему бы не научить его работать с «больше», «меньше», «равно»?
postgres=# create extension btree_gist;
CREATE EXTENSION
postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
ALTER TABLE
Теперь мы по-прежнему не можем забронировать первый домик на те же даты:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 1);
ERROR: conflicting key value violates exclusion constraint "reservations_during_house_no_excl"
Зато можем забронировать второй:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 2);
INSERT 0 1
Но надо понимать, что хотя GiST и может как-то работать с операциями «больше», «меньше», «равно», B-дерево все равно справляется с ними лучше. Так что такой прием стоит использовать только, если индекс GiST необходим по существу — как в нашем примере.
RD-дерево для полнотекстового поиска
Про полнотекстовый поиск
Начнем с минималистического введения в полнотекстовый поиск PostgreSQL (если вы в теме, это раздел можно смело пропустить).
Задача полнотекстового поиска состоит в том, чтобы среди набора документов выбрать те, которые соответствуют поисковому запросу. (Если результатов много, то важно находить наилучшее соответствие, но про это пока промолчим.)
Документ для целей поиска приводится к специальному типу tsvector, который содержит лексемы и их позиции в документе. Лексемы — это слова, преобразованные к виду, удобному для поиска. Например, стандартно слова приводятся к нижнему регистру и у них отрезаются изменяемые окончания:
postgres=# set default_text_search_config = russian;
SET
postgres=# select to_tsvector('И встал Айболит, побежал Айболит. По полям, по лесам, по лугам он бежит.');
to_tsvector
--------------------------------------------------------------------
'айбол':3,5 'беж':13 'встал':2 'лес':9 'луг':11 'побежа':4 'пол':7
(1 row)
Тут также видно, что некоторые слова (называемые стоп-словами) вообще выкинуты («и», «по»), так как они, предположительно, встречаются слишком часто, чтобы поиск по ним был осмысленным. Разумеется, все эти преобразования настраиваются, но речь сейчас не о том.
Поисковый запрос представляется другим типом — tsquery. Запрос, грубо говоря, состоит из одной или нескольких лексем, соединенных логическими связками: «и»
&, «или» |, «не» !. Также можно использовать скобки для уточнения приоритета операций.postgres=# select to_tsquery('Айболит & (побежал | пошел)');
to_tsquery
----------------------------------
'айбол' & ( 'побежа' | 'пошел' )
(1 row)
Для полнотекстового поиска используется один-единственный оператор соответствия @@.
postgres=# select to_tsvector('И встал Айболит, побежал Айболит.') @@ to_tsquery('Айболит & (побежал | пошел)');
?column?
----------
t
(1 row)
postgres=# select to_tsvector('И встал Айболит, побежал Айболит.') @@ to_tsquery('Бармалей & (побежал | пошел)');
?column?
----------
f
(1 row)
Этих сведений пока будет достаточно. Чуть подробнее поговорим о полнотекстовом поиске в одной из следующих частей, посвященной индексу GIN.
RD-деревья
Чтобы полнотекстовый поиск работал быстро, нужно, во-первых, хранить в таблице столбец типа tsvector (чтобы не выполнять дорогое преобразование каждый раз при поиске), и во-вторых, построить по этому полю индекс. Один из возможных методов доступа для этого — GiST.
postgres=# create table ts(doc text, doc_tsv tsvector);
CREATE TABLE
postgres=# create index on ts using gist(doc_tsv);
CREATE INDEX
postgres=# insert into ts(doc) values
('Во поле береза стояла'), ('Во поле кудрявая стояла'), ('Люли, люли, стояла'),
('Некому березу заломати'), ('Некому кудряву заломати'), ('Люли, люли, заломати'),
('Я пойду погуляю'), ('Белую березу заломаю'), ('Люли, люли, заломаю');
INSERT 0 9
postgres=# update ts set doc_tsv = to_tsvector(doc);
UPDATE 9
Последний шаг (преобразование документа в tsvector), конечно, удобно возложить на триггер.
postgres=# select * from ts;
doc | doc_tsv
-------------------------+--------------------------------
Во поле береза стояла | 'берез':3 'пол':2 'стоя':4
Во поле кудрявая стояла | 'кудряв':3 'пол':2 'стоя':4
Люли, люли, стояла | 'люл':1,2 'стоя':3
Некому березу заломати | 'берез':2 'заломат':3 'нек':1
Некому кудряву заломати | 'заломат':3 'кудряв':2 'нек':1
Люли, люли, заломати | 'заломат':3 'люл':1,2
Я пойду погуляю | 'погуля':3 'пойд':2
Белую березу заломаю | 'бел':1 'берез':2 'залома':3
Люли, люли, заломаю | 'залома':3 'люл':1,2
(9 rows)
Как должен быть устроен индекс? Непосредственно R-дерево здесь не годится — непонятно, что такое «ограничивающий прямоугольник» для документов. Зато можно применить некоторую модификацию этого подхода для множеств — так называемое RD-дерево (RD — это Russian Doll, матрешка). Под множеством в данном случае мы понимаем множество лексем документа, но вообще множество может быть любым.
Идея RD-деревьев в том, чтобы вместо ограничивающего прямоугольника взять ограничивающее множество — то есть множество, содержащее все элементы дочерних множеств.
Важный вопрос — как представлять множества в индексных записях. Наверное, самый прямолинейный способ — просто перечислить все элементы множества. Вот как это могло бы выглядеть:

Тогда, например, для доступа по условию
doc_tsv @@ to_tsquery('стояла') можно было бы спускать только в те узлы, в которых есть лексема 'стоя':
Проблемы такого представления вполне очевидны. Количество лексем в документе может быть весьма большим, так что индексные записи будут занимать много места и попадать в TOAST, делая индекс гораздо менее эффективным. Даже если в каждом документе немного уникальных лексем, объединение множеств все равно может получиться очень большим — чем выше к корню, тем больше будут индексные записи.
Такое представление иногда используется, но для других типов данных. А для полнотекстового поиска применяется другое, более компактное, решение — так называемое сигнатурное дерево. Идея его хорошо знакома всем, кто имел дело с фильтром Блума.
Каждую лексему можно представить своей сигнатурой: битовой строкой определенной длины, в которой все биты нулевые, кроме одного. Номер этого бита определяется значением хеш-функции от лексемы (про то, как устроены хеш-функции, мы говорили ранее).
Сигнатурой документа называется побитовое «или» сигнатур всех лексем документа.
Допустим, сигнатуры наших лексем такие:
бел 1000000
берез 0001000
залома 0000010
заломат 0010000
кудряв 0000100
люл 0100000
нек 0000100
погуля 0000001
пойд 0000010
пол 0000010
стоя 0010000
Тогда сигнатуры документов получатся следующими:
Во поле береза стояла 0011010
Во поле кудрявая стояла 0010110
Люли, люли, стояла 0110000
Некому березу заломати 0011100
Некому кудряву заломати 0010100
Люли, люли, заломати 0110000
Я пойду погуляю 0000011
Белую березу заломаю 1001010
Люли, люли, заломаю 0100010
Дерево индекса можно представить так:

Преимущества такого подхода налицо: индексные записи имеют одинаковый и небольшой размер, индекс получается компактным. Но виден и недостаток: из-за компактности теряется точность.
Рассмотрим то же самое условие
doc_tsv @@ to_tsquery('стояла'). Вычислим сигнатуру поискового запроса точно так же, как и для документа: в нашем случае 0010000. Функция согласованности должна выдать все дочерние узлы, сигнатура которых содержит хотя бы один бит из сигнатуры запроса:
Сравните с картинкой выше: видно, что дерево «пожелтело» — а это значит, что возникают ложные положительные срабатывания (то, что у нас называется ошибками первого рода) и при поиске перебираются лишние узлы. Тут мы зацепили лексему «заломат», сигнатура которой по несчастью совпала с сигнатурой искомой лексемы «стоя». Важно, что ложных отрицательных срабатываний (ошибок второго рода) в такой схеме быть не может, то есть мы гарантированно не пропустим нужное значение.
Кроме того, может так получиться, что и разные документы получат одинаковые сигнатуры: в нашем примере не повезло «люли, люли, стояла» и «люли, люли, заломати» (у обоих сигнатура 0110000). И если в листовой индексной записи не хранить само значение tsvector, то и сам индекс будет давать ложные срабатывания. Разумеется, в таком случае метод доступа попросит индексный механизм перепроверять результат по таблице, так что пользователь этих ложных срабатываний не увидит. Но эффективность поиска вполне может пострадать.
На самом деле сигнатура в текущей реализации занимает 124 байта вместо семи бит на наших картинках, так что вероятность коллизий существенно меньше, чем в примере. Но ведь и документов на практике индексируется гораздо больше. Чтобы как-то снизить число ложных срабатываний индексного метода, реализация идет на хитрость: индексированный tsvector сохраняется в листовой индексной записи, но только если он не занимает много места (чуть меньше 1/16 страницы, что составляет около половины килобайта для страниц 8 КБ).
Пример
Чтобы посмотреть, как индексирование работает на реальных данных, возьмем архив рассылки pgsql-hackers. В использованной в примере версии содержится 356125 писем с датой отправления, темой, автором и текстом:
fts=# select * from mail_messages order by sent limit 1;
-[ RECORD 1 ]------------------------------------------------------------------------
id | 1572389
parent_id | 1562808
sent | 1997-06-24 11:31:09
subject | Re: [HACKERS] Array bug is still there....
author | "Thomas G. Lockhart" <Thomas.Lockhart@jpl.nasa.gov>
body_plain | Andrew Martin wrote: +
| > Just run the regression tests on 6.1 and as I suspected the array bug +
| > is still there. The regression test passes because the expected output+
| > has been fixed to the *wrong* output. +
| +
| OK, I think I understand the current array behavior, which is apparently+
| different than the behavior for v1.0x. +
...
Добавляем и заполняем столбец типа tsvector и строим индекс. Здесь мы объединим в один вектор три значения (тему, автора и текст письма), чтобы показать, что документ не обязан быть один полем, а может состоять из совершенно произвольных частей.
fts=# alter table mail_messages add column tsv tsvector;
ALTER TABLE
fts=# update mail_messages
set tsv = to_tsvector(subject||' '||author||' '||body_plain);
NOTICE: word is too long to be indexed
DETAIL: Words longer than 2047 characters are ignored.
...
UPDATE 356125
fts=# create index on mail_messages using gist(tsv);
CREATE INDEX
Некоторое количество слов, как видно, было отброшено из-за слишком большого размера. Но в итоге индекс построен и готов поддерживать поисковые запросы:
fts=# explain (analyze, costs off)
select * from mail_messages where tsv @@ to_tsquery('magic & value');
QUERY PLAN
----------------------------------------------------------
Index Scan using mail_messages_tsv_idx on mail_messages
(actual time=0.998..416.335 rows=898 loops=1)
Index Cond: (tsv @@ to_tsquery('magic & value'::text))
Rows Removed by Index Recheck: 7859
Planning time: 0.203 ms
Execution time: 416.492 ms
(5 rows)
Здесь видно, что вместе с 898 подходящими под условие строками, метод доступа вернул еще 7859 строк, которые были отсеяны перепроверкой по таблице. Это наглядно показывает негативное влияние потери точности на эффективность.
Внутри
Для анализа содержимого индекса снова воспользуемся расширением gevel:
fts=# select level, a from gist_print('mail_messages_tsv_idx') as t(level int, valid bool, a gtsvector) where a is not null;
level | a
-------+-------------------------------
1 | 992 true bits, 0 false bits
2 | 988 true bits, 4 false bits
3 | 573 true bits, 419 false bits
4 | 65 unique words
4 | 107 unique words
4 | 64 unique words
4 | 42 unique words
...
Значения специального типа gtsvector, хранящиеся в индексных записях — это собственно сигнатура плюс, возможно, исходный tsvector. Если вектор есть, то выводится количество лексем в нем (unique words), а если нет — то число установленных (true) и сброшенных (false) битов в сигнатуре.
Видно, что в корневом узле сигнатура выродилась до «всех единиц» — то есть один уровень индекса стал полностью бесполезен (и еще один — почти совсем бесполезен с всего четырьмя сброшенными битами).
Свойства
Поглядим на свойства метода доступа gist (запросы приводились ранее):
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
gist | can_order | f
gist | can_unique | f
gist | can_multi_col | t
gist | can_exclude | t
Поддержки сортировки значений и уникальности нет. Индекс, как мы видели, можно строить по нескольким столбцам и использовать в ограничениях исключения.
Свойства индекса:
name | pg_index_has_property
---------------+-----------------------
clusterable | t
index_scan | t
bitmap_scan | t
backward_scan | f
И, самое интересное, свойства уровня столбца. Некоторые свойств будет постоянными:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
search_array | f
search_nulls | t
(Нет поддержки сортировки; индекс нельзя использовать для поиска в массиве; неопределенные значения поддерживаются.)
А вот два оставшихся свойства, distance_orderable и returnable, будут зависеть от используемого класса операторов. Например, для точек увидим:
name | pg_index_column_has_property
--------------------+------------------------------
distance_orderable | t
returnable | t
Первое свойство говорит о том, что доступен оператор расстояния для поиска ближайших соседей. А второе — что индекс может использоваться в исключительно индексном сканировании. Несмотря на то, что в листовых индексных записях хранятся не точки, а прямоугольники, метод доступа умеет возвращать то, что нужно.
А вот интервалы:
name | pg_index_column_has_property
--------------------+------------------------------
distance_orderable | f
returnable | t
Для них не определена функция расстояния, следовательно поиск ближайших соседей невозможен.
И полнотекстовый поиск:
name | pg_index_column_has_property
--------------------+------------------------------
distance_orderable | f
returnable | f
Здесь потерялась и возможность выполнять исключительно индексное сканирование, поскольку в листовых записях может оказаться только сигнатура без собственно данных. Впрочем, это небольшая потеря, поскольку значение типа tsvector все равно никого не интересует: оно используется для отбора строк, а показывать нужно исходный текст, которого в индексе все равно нет.
Другие типы данных
Напоследок обозначим еще несколько типов, которые в настоящее время поддерживает метод доступа GiST, помимо уже рассмотренных нами геометрических типов (на примере точек), диапазонов и типов полнотекстового поиска.
Из стандартных типов это IP-адреса inet, а остальное добавляется расширениями:
- cube предоставляет тип данных cube для многомерных кубов. Для него, как и для геометрических типов на плоскости, определен класс операторов GiST: R-дерево с возможностью поиска ближайших соседей.
- seg предоставляет тип данных seg для интервалов с границами, заданными с определенной точностью, и поддержку GiST-индекса для него (R-дерево).
- intarray расширяет функциональность целочисленных массивов и добавляет для них GiST-поддержку. Реализованы два класса операторов: gist__int_ops (RD-дерево с полным представлением ключей в индексных записях) и gist__bigint_ops (сигнатурное RD-дерево). Первый класс можно использовать для небольших массивов, второй — для более серьезных объемов.
- ltree добавляет тип данных ltree для древовидных структур и GiST-поддержку для него (RD-дерево).
- pg_trgm добавляет специальный класс операторов gist_trgm_ops для использования триграмм в полнотекстовом поиске. Но об этом — в другой раз вместе с индексом GIN.
Продолжение.
