
В своей предыдущей статье я писал, что мне не нравится подход, при котором статические анализаторы кода оцениваются с помощью синтетических тестов. В статье приводился пример, воспринимаемый анализатором как особый случай, на который сознательно не выдаётся предупреждение. Если честно, я не ожидал такого всплеска комментариев на тему того, что анализатор может очень редко, но не выдать предупреждение на ошибку из-за реализованных в нём механизмов отсечения ложных срабатываний. Борьба с ложными срабатываниями настолько большая составляющая любого статического анализатора, что как-то даже не понятно, что тут собственно обсуждать. Это надо делать и всё. Такие механизмы существуют не только в нашем анализаторе, но и в других анализаторах/компиляторах. Тем не менее, раз этот момент вызвал столь бурное обсуждение, я думаю, стоит уделить ему внимание, поэтому и написал эту поясняющую статью.
Введение
Всё началось с публикации "Почему я не люблю синтетические тесты". Можно сказать, что эта статья писалась для себя про запас. Иногда в дискуссиях мне требуется пояснить, почему мне не нравятся те или иные синтетические тесты. Каждый раз писать длинные ответы тяжело, поэтому я давно планировал подготовить статью-ответ, на которую смогу давать ссылку. И когда я рассматривал itc-benchmarks, то понял, что это хороший момент написать текст, пока у меня свежи впечатления и можно выбрать пару тестов, которые я могу включить в статью.
Я не ожидал такое неприятие этой статьи со стороны сообщества программистов и комментариев на различных площадках и в почте. Причина этого, наверное, в том, что я занимаюсь разработкой статических анализаторов вот уже 10 лет и некоторые вопросы кажутся для меня столь очевидными, что я рассматриваю их слишком кратко и категорично. Попробую устранить недопонимание и рассказать, как и почему ведётся борьба с ложными срабатываниями.
Текст статьи может относиться к любому инструменту, PVS-Studio собственно тут ни при чем. Аналогичную статью мог бы написать кто-то из разработчиков GCC, Coverity или Cppcheck.
Ручная работа с ложными срабатываниями
Прежде чем приступить к основной теме, хочу внести ясность касательно разметки ложных сообщений. У меня сложилось впечатление, что многие начали писать негативные комментарии, не разобравшись, о чем идёт речь. Я встретил комментарии в духе:
Вы пошли по неверному пути. Вместо того чтобы предоставить механизмы подавления ложных срабатываний, вы пытаетесь самостоятельно устранять их как можно больше и наверняка часто ошибаетесь.
Дам разъяснения, чтобы более не возвращаться к обсуждению этой темы. PVS-Studio предоставляет несколько механизмов для устранения ложных срабатываний, которые в любом случае неизбежны:
- Подавление предупреждения в конкретной строке с помощью комментариев.
- Массовое подавление предупреждений, возникающих из-за макроса. Это также осуществляется с помощью специальных комментариев.
- Аналогично для строк кода, содержащих определённую последовательность символов.
- Полное отключение неактуальных для данного проекта диагностик с помощью настроек или специальных комментариев.
- Исключение из анализа части кода с помощью #ifndef PVS_STUDIO.
- Изменение настроек некоторых диагностик с помощью комментариев специального вида. Про них говорится в описании конкретных диагностик (см. в качестве примера V719: V719_COUNT_NAME).
Подробно все эти возможности описаны в разделе документации "Подавление ложных предупреждений". Выключать предупреждения или подавлять предупреждения в макросах, можно также используя конфигурационные файлы (см. pvsconfig).
Отдельно следует выделить систему массовой разметки предупреждений с помощью специальной базы. Это позволяет быстро интегрировать анализатор в процесс разработки больших проектов. Идеология этого процесса изложена в статье "Практика использования анализатора PVS-Studio".
Всё это относится к явному указанию, что не считать ошибками. Однако, это не снимает задачу минимизации предупреждений с помощью специальных исключений. Ценность анализатора не в том, что он ругается на всё подряд, а в том, как много он знает ситуаций, когда ругаться не надо.
Теоретическая справка
Теперь немного теории. Каждое диагностическое сообщение анализатора оценивается двумя характеристиками:
- Критичность ошибки (насколько она фатальна для программы).
- Достоверность ошибки (какова вероятность, что найден настоящий дефект, а не просто непонятный анализатору код).
Эти два критерия у каждой диагностики могут сочетаться в любых пропорциях. Поэтому идеально описывать типы диагностик, размещая их на двумерном графике:
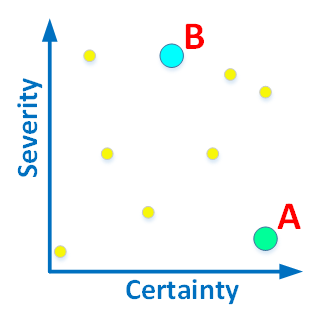
Рисунок 1. Диагностики можно оценивать по критичности и достоверности.
Приведу пару поясняющих примеров. Диагностика A, определяющая что в *.cpp файле нет заголовка из комментариев, будет располагаться в правом нижнем углу. Забытый комментарий не приведёт к сбою программы, хотя и является ошибкой с точки зрения принятого в команде стандарта кодирования. При этом очень точно можно определить, есть комментарий или нет. Поэтому достоверность ошибки высокая.
Диагностика B, говорящая, что некоторые из членов класса не инициализируется в конструкторе, будет размещаться в середине верней части. Достоверность этой ошибки не очень высокая, так как анализатор мог просто не понять, как и где инициализируется этот член (это сложно). Инициализацию программист может выполнить уже после того как отработает конструктор. Таким образом, неинициализированный член в конструкторе вовсе не обязательно является ошибкой. Зато эта диагностика находится в верхней части графика, так как если это действительно ошибка, то она критическим образом сказывается на работоспособности программы. Использование неинициализированной переменной — это серьезный дефект.
Надеюсь идея понятна. Однако, я думаю читатель согласится, что такое распределение ошибок на графике сложно для восприятия. Поэтому некоторые анализаторы упрощают этот график до таблицы из девяти или четырёх ячеек:

Рисунок 2. Упрощенный вариант классификации. Используется 4 ячейки.
Так, например, поступали авторы анализатора Goanna, пока их не купила компания Coverity, которую в свою очередь потом купила компания Synopsys. Они как раз классифицировали предупреждения, выдаваемые анализатором, относя их к одной из 9 ячеек:

Рисунок 3. Фрагмент из Goanna reference guide (Version 3.3). Используется 9 ячеек.
Впрочем, и этот способ непривычен и неудобен для использования. Программистам хочется, чтобы предупреждения были расположены на одномерном графике: не важно -> важно. Это привычно, тем более, что на том же принципе строятся предупреждения компиляторов, разделенные на разные уровни.
Свести двумерную классификацию к одномерной непросто. Вот как мы поступили в анализаторе PVS-Studio. У нас просто нет нижней части двумерного графика:
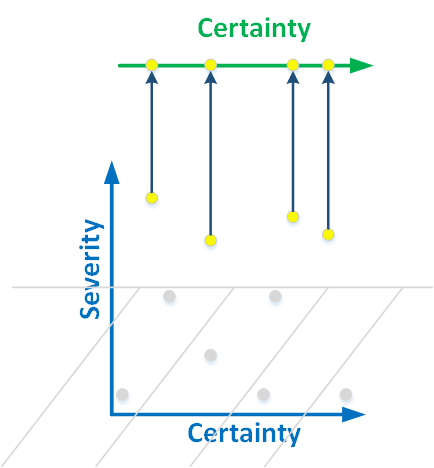
Рисунок 4. Мы проецируем предупреждения высокого уровня критичности на линию. Ошибки начинают классифицироваться по достоверности.
Мы выявляем только те ошибки, которые могут привести к неправильной работе программы. Забытый комментарий в начале файла не может привести к падению программы и не интересен нам. А вот неинициализированный член класса мы ищем, так как это критическая ошибка.
Таким образом, нам надо классифицировать ошибки по уровню их достоверности. Этот уровень достоверности есть не что иное, как распределение сообщений анализаторов по трем группам (High, Medium, Low).

Рисунок 5. Фрагмент интерфейсного окна PVS-Studio. Включен просмотр диагностик общего назначения уровня High и Medium.
Причем одно и тоже предупреждение может попасть на разные уровни, в зависимости от того, насколько анализатор уверен, что нашел ошибку, а не выдал ложное срабатывание.
При этом повторю, что все предупреждения ищут ошибки, которые могут быть критичны для программы. Просто иногда анализатор уверен больше, а иногда меньше, что нашел ошибку.
Примечание. Конечно, и тут есть определенная относительность. Например, в PVS-Studio имеется предупреждение, V553 которое анализатор выдаёт, когда встречает функцию длиной более 2000 строк кода. Такая функция не обязательно должна содержать ошибку. Но на практике, крайне высока вероятность, что эта функция служит источником ошибок. Такую функцию невозможно протестировать юнит-тестами. Можно рассматривать наличие такой функции в коде как дефект. Впрочем, подобных диагностик всего несколько и основная задача анализатора — это поиск выходов за границы массива, неопределённого поведения и прочих фатальных ошибок (см. таблицу).
Ложные срабатывания и уровни достоверности
Предупреждения PVS-Studio выявляют участки кода, про которые можно сказать, что они в большей или меньшей степени, приводят к серьёзным сбоям в работе программы. Поэтому уровни предупреждений в PVS-Studio — это не критичность ошибок, а их достоверность. Впрочем, критичность иногда тоже может учитываться для распределения по уровням, но не будем вдаваться в такие мелкие детали, так как нам важна общая картина.
Кратко: Уровни — это достоверность выявленной ошибки.
Критика, которая высказывалась к предыдущей статье, сводилась к тому, что, борясь с ложными предупреждениями, мы можем потерять полезные предупреждения. На самом деле, предупреждения обычно никуда не деваются, а только движутся по уровням достоверности. И те редкие варианты ошибок, за которые переживали читатели, как правило просто скапливаются на уровне Low, который мы не рекомендуем для просмотра. Полностью исчезают только совсем бессмысленные предупреждения, от просмотра которых не будет никакого толку.

Рисунок 6. Оставлять что-то про запас хорошо. Но в какой-то момент надо уметь остановиться.
Читателей видимо насторожили мои слова, что могут исчезнуть и полезные сообщения. Не вижу смысла это отрицать. Такая вероятность существует, но она столь несущественна, что волноваться об этом не следует. Я покажу на примерах, что брать в расчет эти случаи смысла нет. Но давайте начнем с темы размещения сообщений на разных уровнях.
В некоторых случаях сразу понятно на какой уровень достоверности следует поместить предупреждение. В качестве примера рассмотрим простую диагностику V518, которая выявляет следующий паттерн ошибки:
char *p = (char *)malloc(strlen(src + 1));Скорее всего, неправильно поставили скобку. Хотели прибавить 1, чтобы было куда разместить терминальный ноль. Но ошиблись и, в результате, памяти выделяется на 2 байта меньше, чем следовало.
Теоретически можно представить, что программист хотел написать именно такой код, но вероятность этого крайне мала. Поэтому достоверность данного предупреждения очень высока, и оно всегда помещается в сообщения уровня High.
У этой диагностики, кстати, даже нет ни одного исключения. Если нашли такой паттерн, значит ошибка.
В других случаях сразу понятно, что достоверность ошибки низкая и сообщение отправляется всегда на уровень Low. Таких диагностик у нас очень мало, так как это означает, что диагностика получилась неудачной. Одной из таких бестолковых диагностик является V608, которая выявляет повторяющиеся последовательности, состоящие из операторов явного приведения типов. Ищутся выражения вида:
y = (A)(B)(A)(B)x;Не помню уже, зачем мы делали эту диагностику. Пока я ещё ни разу не видел, чтобы эта диагностика выявила настоящую ошибку. Избыточный код она находила (обычно в сложных макросах), но не ошибки.
Большинство же диагностик «плавает» по уровням в зависимости от уверенности анализатора, что найден настоящий баг.
Мы интерпретируем уровни так:
High (первый уровень). Скорее всего, это ошибка. Обязательно изучите этот код! Если это даже не ошибка, то скорее всего код плохо написан и его всё равно следует поправить, дабы он не смущал анализаторы и других членов команды разработчиков. Поясню на примере:
if (A == B)
A = 1; B = 2;Возможно, ошибки здесь нет и фигурные скобки не нужны. Есть малюсенькая вероятность, что программист всегда хотел присваивать переменной B значение 2. Однако, думаю все согласятся, что такой код надо переписать, даже если ошибки нет:
if (A == B)
A = 1;
B = 2;Medium (второй уровень). Этот код кажется содержит ошибку, но анализатор не уверен. Если Вы исправили все предупреждения уровня High, то будет полезно позаниматься и предупреждениями уровня Medium.
Low (третий уровень). Предупреждения с низким уровнем достоверности, которые мы вообще не рекомендуем для изучения. Обратите внимание, что когда мы пишем статьи про проверку проектов, мы рассматриваем только уровни High и Medium и не связываемся с уровнем Low.
Мы поступили точно также, и когда работали над проектом Unreal Engine. Нашей целью было изничтожить все предупреждения первого и второго уровня общего назначения. На третий уровень мы не заглядывали.
Как я уже сказал, большинству диагностик может быть назначен различный уровень, в зависимости от набора признаков. Одни признаки могут снижать, а другие повышать достоверность. Подбираются они эмпирически на основании прогона диагностик на более чем ста открытых проектах.
Рассмотрим, как диагностика может перемещаться по разным уровням. Для примера, возьмем диагностику V572, которая предупреждает о подозрительном явном приведении типа. С помощью оператора new создается объект класса, указатель на который затем кастится к другому типу:
T *p = (T *)(new A);Это странная конструкция. Если класс A наследуется от T, то приведение типа лишнее и его можно просто убрать. Если не наследуется, то это, скорее всего, ошибка. Однако, анализатор не до конца уверен, что это ошибка и для начала назначает уровень достоверности Medium. Какой бы странной ни была эта конструкция, она иногда соответствует корректно работающему коду. Пример привести не могу, так как не помню, что это за ситуации.
Если же создается массив элементов, а затем приводится к указателю на базовый класс, это гораздо опаснее:
Base *p = (Base *)(new Derived[10]);Здесь анализатор выдаст предупреждение уровня High. Размер базового класса может быть меньше наследника и тогда при доступе к элементу p[1] мы «влезем не пойми куда» и будем работать с некорректными данными. Даже если пока размер базового класса и наследника совпадает, то все равно этот код следует править. Пока программисту может везти, но очень легко всё сломать, добавив в класс-наследник новый член класса.
Есть и обратная ситуация, когда происходит приведение к тому же типу:
T *p = (T *)(new T);Такой код может появляться, когда кто-то слишком долго работал с C и забыл, что в отличии от вызова функции malloc обязательное приведение типа не нужно. Или в результате рефакторинга старого кода, при котором C программа, превращается в C++ программу.
Никакой ошибки здесь нет и сообщение можно вообще не выдавать. На всякий случай оно остается, но перемещается на уровень Low. Смотреть это сообщение и править код не обязательно, но если кто-то хочет навести красоту в коде, то мы не против.
В комментариях к предыдущей статье, люди переживали, что могут случайно исчезнуть предупреждения, которые хоть и с малой вероятностью, но могут указывать на ошибку. Как правило, такие сообщения не исчезают, а перемещаются на Low уровень. Один из таких примеров мы как раз только что рассмотрели: «T *p = (T *)(new T);». Ошибки здесь нет, но вдруг что-то не так… Желающие имеют возможность изучить код.
Давайте рассмотрим другой пример. Диагностика V531: подозрительно умножать один sizeof на другой sizeof:
size_t s = sizeof(float) * sizeof(float);Это бессмысленное выражение и, скорее всего, здесь допущена какая-то ошибка, например, опечатка. Анализатор выдаст на этот код предупреждение уровня High.
Однако, есть ситуация, когда уровень предупреждение заменяется на Low. Так происходит, когда одним из множителей выступает sizeof(char).
Все выражения «sizeof(T) * sizeof(char)» которые мы наблюдали более чем на ста проектах не являлись ошибками. Почти всегда это были какие-то макросы, где такое умножение получалось в силу подстановки одного макроса в другой.
Можно не смотреть на эти предупреждения, поэтому они и спрятаны от глаз пользователей в раздел Low-предупреждений. Однако, желающие по-прежнему могут их изучать.

Рисунок 7. Теперь читатель знает, что он всегда может отправиться в плавание по бескрайним просторам предупреждений уровня Low.
Исключения в диагностиках
Исключения бывают как действующие на отдельные диагностики, так и на группы диагностик. Начнем с «исключений массового поражения». В программах есть код, который никогда не выполняется. В нём на самом деле можно вообще не искать ошибки. Раз код не выполняется, то ошибки никак не проявят себя. Поэтому многие диагностики не применяются к невыполняемому коду. Поясню это на примере:
int *p = NULL;
if (p)
{
*p = 1;
}При разыменовании указателя, его единственное возможное значение NULL. Больше здесь нет никакого другого значения, которое могло бы храниться в переменной 'p'. Однако, срабатывает исключение, что разыменование находится в коде, который никогда не выполняется. А раз он не выполняется, то и никакой ошибки нет. Разыменование будет выполняться только тогда, когда в переменную p поместят значение, отличное от NULL.
Кто-то может сказать, что предупреждение могло бы быть полезно, так как подскажет, что условие всегда ложно. Но это забота других диагностик, например, V547.
Будет ли кому-то полезно, если анализатор начнёт предупреждать о том, что в приведённом выше коде разыменовывается нулевой указатель? Нет.
Теперь перейдём к частным исключениям в диагностиках. Вернемся к уже рассмотренной нами ранее диагностике V572:
T *p = (T *)(new A);Есть исключения, когда это сообщение выдано не будет. Один из таких случаев, приведение к (void). Пример:
(void) new A();Объект создают и сознательно оставляют жить до окончания работы программы. Эта конструкция не могла появиться случайно из-за опечатки. Это сознательное действие по подавлению предупреждений компиляторов и анализаторов на запись вида:
new A();Многие инструменты будут ругаться на такую конструкцию. Компилятор/анализатор подозревает, что человек забыл записать указатель, который вернёт оператор new. Поэтому человек сознательно использовал подавление предупреждений, добавив приведение к типу void.
Да, этот код странен. Но раз человек просит оставить этот код в покое, то так и надо поступить. Задача анализатора искать ошибки, а не заставлять человека писать ещё более изощрённые конструкции, чтобы запутать компилятор/анализатор и избавиться от предупреждений.
Будет ли кому-то полезно все равно выдавать предупреждение? Нет. Тот, кто писал этот код, спасибо не скажет.
Теперь вернемся к диагностике V531:
sizeof(A) * sizeof(B)Есть ли случаи, когда вообще не стоит выдавать никакие сообщения, даже уровня Low? Да, есть.
Типовая задача: надо вычислить размер буфера, размер которого кратен размеру другого буфера. Скажем есть массив из 125 элементов типа int, и надо создать массив из 125 элементов типа double. Для этого количество элементов массива надо умножить на размер объекта. Вот только при подсчёте количества элементов легко ошибиться. Поэтому программисты используют специальные макросы, чтобы безопасно вычислять количество элементов. Подробнее зачем и как это делать я неоднократно писал в разных своих статьях (см. здесь упоминание макроса arraysize).
После раскрытия макроса получаются конструкции вида:
template <typename T, size_t N>
char (*RtlpNumberOf( __unaligned T (&)[N] ))[N];
....
size_t s = sizeof(*RtlpNumberOf(liA->Text)) * sizeof(wchar_t);Первый sizeof используется для вычисления количества элементов. Второй sizeof вычисляет размер объекта. В результате всё хорошо, и мы правильно вычисляем размер массива в байтах. Возможно читателю не понятно, о чем собственно идёт речь. Приношу извинения, но не хочется отклоняться от сути повествования и вдаваться в разъяснения.
В общем, существует некая магия, когда умножение двух операторов sizeof — это совершенно нормально и ожидаемо. Анализатор умеет распознавать такой паттерн вычисления размера буфера и не выдаёт предупреждение.
Будет ли кому-то полезно все равно выдавать предупреждение? Нет. Это совершенно корректный и надёжно написанный код. Так и надо писать.
Идём дальше. Анализатор выдаст предупреждение V559 на конструкцию вида:
if (a = 5)Чтобы подавить предупреждение на подобном коде, выражение нужно взять в двойные скобки:
if ((a = 5))Это является подсказкой анализаторам и компилятором, что ошибки никакой нет, и человек сознательно хочет присвоить значение внутри условия. Кто и когда придумал такой способ подсказки я не знаю, но он общепризнанный и поддерживается многими компиляторами и анализаторами.
Анализатор PVS-Studio, естественно, тоже промолчит на подобный код.
Быть может, стоило переместить предупреждение на уровень Low, а не полностью подавлять его? Нет.
Есть ли вероятность, что человек случайно поставит лишние круглые скобки вокруг неправильного выражения? Да есть, но крайне маленькая. Вы часто ставите лишние скобки? Не думаю. Скорее это происходит 1 раз на 1000 операторов if. Или даже реже. Соответственно вероятность того, что из-за лишних скобок будет пропущена ошибка, менее 1/1000.
Быть может, лучше всё равно выдавать предупреждение? Нет. Тем самым мы лишим человека «легальной возможности» избежать предупреждения на его коде, но при этом вероятность найти дополнительную ошибку крайне мала.
Я приводил уже подобные аргументы в комментариях к предыдущей статье, но они убедили не всех. Поэтому попробую подойти к этой теме с ещё одной стороны.
У меня есть вопрос к тем, кто утверждает, что хочет видеть все-все предупреждения. Вы уже покрыли юнит-тестами 100% кода? Нет? Как же так, ведь там могут быть ошибки?!
Сам дам ответ за оппонента. Покрыть 100% кода тестами крайне сложно и дорого. Цена, которая будет заплачена за 100% покрытия, не окупит вложения времени и сил.
Вот тоже самое и со статическим анализом. Есть черта, при пересечении которой время на разбор предупреждений анализатора превысит любые разумные пределы. Поэтому нет никакого практического смысла выдавать как можно больше предупреждений.
Давайте рассмотрим ещё один случай, когда не выдается предупреждение V559:
if (ptr = (int *)malloc(sizeof(int) * 100))Это классический паттерн выделения памяти и одновременной проверки, что память выделилась. Понятно, что никакой ошибки здесь нет. Человек явно не желал написать:
if (ptr == (int *)malloc(sizeof(int) * 100))Такое выражение не имеет практического смысла и в добавок приводит к утечке памяти. Так что присваивание внутри условия — это именно то, что и хотел сделать программист.
Будет ли польза от того, если анализатор станет выдавать предупреждения на такие конструкции? Нет.
Давайте завершим главу ещё одним примером исключения, который мне будет тяжелее обосновать, но я постараюсь донести читателю нашу философию.
Диагностика V501 — один из лидеров по количеству исключений. Однако, эти исключения не мешают диагностике эффективно работать (proof).
Диагностика выдаёт предупреждения на выражения вида:
if (A == A)
int X = Q - Q;Если левый и правый операнды идентичны, то это подозрительно.
Одно из исключений гласит, что не стоит выдавать предупреждения, если операция '/' или '-' применяется к числовым константам. Примеры:
double w = 1./1.;
R[3] = 100 - 100;Дело в том, что программисты часто специально пишут подобные выражения, не упрощая их. Это позволяет легче понять смысл программы. Чаще всего подобные ситуации встречаются в приложениях, осуществляющих много вычислений.
Пример реального кода с подобными выражениями:
h261e_Clip(mRCqa, 1./31. , 1./1.);Можем ли мы пропустить какую-то ошибку из-за такого исключения? Да, можем. Однако, преимущества от сокращения количества ложных срабатываний значительно превышают потенциальную пользу от потери полезных предупреждений.
Подобное деление или вычитание является стандартной распространенной практикой в программировании. Риск потерять срабатывание оправдан.
Возможно, там хотели написать другое выражение? Да, это не исключено. Однако, такие рассуждения — это путь в никуда. Фразу «вдруг хотели написать что-то другое», можно применить и к 1./31. И тут мы приходим к идее идеального анализатора, который просто ругается подряд на все строки в программе. Даже на пустые. Вдруг неправильно, что она пустая. Вдруг там надо было вызвать функцию foo().

Рисунок 8. Нужно уметь остановиться. Иначе полезная прогулка по диагностикам превратится в какую-то фигню.
Лучше потерять 1 полезное сообщение, чем при этом показать за компанию ещё 1000 бесполезных. В этом нет ничего ужасного. Полнота выявления ошибок — не единственный критерий полезности анализатора. Не менее важен ещё и баланс между полезными и бесполезными сообщениями. Внимательность быстро теряется. Просматривая отчет с большим количеством ложных срабатываний, человек начинает очень невнимательно относиться к предупреждениям и пропускает многие ошибки, размечая их как не ошибки.
Ещё раз кратко об исключениях
Мне кажется, я всё подробно объяснил, но предвижу что могу вновь услышать комментарий вот такого типа:
Не понимаю, зачем вам жаловаться на непонимание вместо того, чтобы просто сделать функцию и к ней кнопку «вкл/выкл». Хочешь — пользуешься, не хочешь, не нужно — не пользуйся. Да, это работа. Но и да, это ваша работа.

Рисунок 9. Реакция единорога на пожелание сделать настройку, которая отключает всю фильтрацию предупреждений.
Предлагается сделать кнопку, которая будет показывать все предупреждения без ограничений с выключенными исключениями.
Есть такая кнопка уже в анализаторе! Есть! Она называется «Low» и показывает предупреждения с минимальным уровнем достоверности.
Видимо, многие просто неправильно воспринимают термин «исключения». В виде исключений оформлены множество совершенно необходимых условий для адекватной диагностики проблем.
Поясню это, опираясь на диагностику V519. Она предупреждает, что одному и тому же объекту дважды подряд присваиваются значения. Пример:
x = 1;
x = 2;Но только в таком виде диагностика не применима. Поэтому начинаются уточнения, такие как:
Исключение N1. Объект участвует во втором выражении в составе правого операнда операции =.
Если это исключение убрать, то анализатор начнет ругаться на совершенно нормальный код:
x = A();
x = x + B();Хочет кто-то посвятить свои силы и время, чтобы просматривать код такого вида? Нет. И убедить в обратном нас не получится.
Главная мысль
У меня нет цели в этой статье кому-то что-то доказать или оправдаться. Её цель направить мысли читателей в правильное русло. Я стараюсь объяснить, что попытка получить как можно больше предупреждений от анализаторов — контрпродуктивна. Это не поможет сделать разрабатываемый проект более надежным, зато отнимет время, которое можно было бы потратить на альтернативные методы повышения качества программы.
Статический анализатор кода не способен выявить все ошибки. И любой другой инструмент тоже не способен. Не существует серебряной пули. Качество и надежность программного обеспечения достигается разумным сочетанием разнообразных инструментов, а не попыткой выжать всё возможное и невозможное из какого-то одного инструмента.
Приведу аналогию. Безопасности на стройке стараются достичь, используя сочетание различных элементов: обучением технике безопасности, ношением каски, запретом приступать к работе в состоянии алкогольного опьянения и так далее. Неэффективно выбрать только один компонент и надеяться, что он решит все проблемы. Можно сделать чудесную бронированную каску, а лучше шлем, со встроенным счётчиком Гейгера и запасом воды на день. Но всё это не спасет от падения при выполнении высотных работ. Здесь нужно другое устройство — страховочный трос. Можно начать думать в сторону встроенного в каску парашюта. Это, конечно, интересная инженерная задача, но такой подход непрактичен. Очень скоро вес и размер каски превысят разумные пределы. Каска начнет мешаться строителям, злить их, замедлять темп работы. Есть вероятность, что строители вообще начнут тайком снимать каску и работать без неё.
Если пользователь победил все предупреждения анализатора, неразумно стремиться увидеть, как можно больше предупреждений всё более низкого уровня достоверности. Будет полезнее заняться юнит-тестами и довести покрытие кода, скажем до 80%. Стремиться к 100% покрытию я не призываю, так как время, которое потребуется на реализацию 100% покрытия и его поддержания, перевесит пользу от этого действия. Далее можно добавить в процесс тестирования один из динамических анализаторов кода. Некоторые виды дефектов, которые находят динамические анализаторы, не могут найти статические анализаторы. И наоборот. Поэтому динамический и статический анализ отлично дополняют друг друга. Можно развивать UI тесты.
Подобный комплексный подход намного лучше скажется на качестве и надежности программ. Используя несколько технологий, можно добиться лучшего качества, чем скажем на 100% покрыв тестами весь код. При этом время на 100% покрытие кода потратится намного больше.
На самом деле я думаю, что все, кто пишет, что хочет ещё больше неотфильтрованных сообщений от статических анализаторов кода, никогда этими самыми анализаторами кода не пользовались. Или пробовали их на игрушечных проектах, в которых низкая плотность ошибок. В любом настоящем проекте всегда стоит проблема, как разобраться с имеющимися ложными срабатываниями. Это большая сложная задача, над которой приходится работать как разработчикам анализаторов, так и их пользователям. Куда уж ещё больше предупреждений?!
Мы регулярно получаем от клиентов письма, где они просят устранить то или иное ложное срабатывание. А вот «дайте больше сообщений» мы ещё ни разу не слышали.
Заключение
Из этой статьи мы узнали:
- Анализатор PVS-Studio старается искать не «запахи», а настоящие ошибки, которые могут привести к неправильной работе программы.
- Диагностические сообщения разделяются на три уровня достоверности (High, Medium, Low).
- Мы рекомендуем к изучению только уровни High и Medium.
- Для тех, кто волновался, что исключения могут удалить полезную ошибку: это маловероятно. Скорее всего, такое недостоверное предупреждение перемещено на уровень Low. Можно открыть вкладку Low и изучать такие предупреждения.
- Исключения в диагностиках неизбежны, иначе инструмент начнет больше мешать, чем помогать.
Спасибо всем, кто потратил время на чтение этой большой статьи. Я сам не ожидал, что она получится такая длинная. Это показывает, что тема сложнее, чем кажется на первый взгляд.

Единорог и дальше будет стоять на страже качества программного кода. Желаю всем удачи и приглашаю дополнительно познакомиться с презентацией "PVS-Studio 2017".

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. The way static analyzers fight against false positives, and why they do it
Прочитали статью и есть вопрос?
Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: Ответы на вопросы читателей статей про PVS-Studio, версия 2015. Пожалуйста, ознакомьтесь со списком.
