Моя история не для всех. В том смысле, что тема не хайповая. Но тем, кто в теме, надеюсь, будет интересно. Она (история) основана на реальном опыте последних лет. Я расскажу об одном из вариантов — с моей точки зрения, эффективном, — управления сложным архитектурным ландшафтом.
Что я подразумеваю под «сложным»: это несколько сотен бизнес-приложений с довольно внушительной дисперсией атрибутов — технологии, разнородность функциональности, связанность с другим приложениями, критичность, возраст, размер и так далее. Добавьте сюда динамику, поскольку ландшафт неустанно меняют несколько десятков внутренних и внешних команд. Иными словами — самый отпетый, или, на устойчивом жаргоне, «кровавый» энтерпрайз.
Очевидно, что в этом бурлящем котле каждая новая инициатива по изменению начиналась с поисков: где и что нужно делать, как определить достаточность и необходимость изменений. То есть проводился анализ. И поскольку котел большой и градус изменений высокий, то анализ, а он должен быть качественным, длился месяцами. Но тщательность не гарантировала 100%-го качества, поскольку на той же поляне, что и ваша инициатива, могли толкаться другие, внося непредвиденные вами изменения.
Кто-то скажет, что это обычная картина для «кровавого» энтерпрайза. То ли дело Agile-команды с единственным владельцем продукта. Всё учтено, и команда знает всё. Не буду спорить. Во многом это правда. Но на рваном лоскутном ландшафте независимых команд не построишь. А действительно крупные задачи одной командой не решишь. Да и в любой методологии должен быть разумный уровень порядка.
Именно с наведения порядка мы и начали. Это вылилось в создание единого архитектурного репозитория. Начнем с его мета-модели. По моему мнению, подобные изменения всегда надо начинать с разработки мета-модели. Это лучший способ объяснить заинтересованным сторонам и, самое главное, самим себе, что сможет дать новый репозиторий. Мета-модель покажет, как ваши цели ложатся на возможности систем, где репозиторий будет реализовываться. При её разработке проще всего посмотреть на документы, которые уже есть в вашей компании. Изучите имеющийся опыт. Посмотрите на ванильные модели различных вендоров. Если уж совсем по-серьезному, то почитайте ГОСТы, например, ГОСТ 57100 (ISO 42010).
Для начала включайте в мета-модель только самое необходимое, поскольку начинать лучше с простого. Потом, если окажется, что такой модели недостаточно, то развить её не составит труда. Причем развитие будет осознанным. То есть здесь самый правильный подход — итеративный. Начинайте с небольшого участка архитектуры. Посмотрите, как с ней справляется ваша модель. Достаточно ли в ней элементов, связей и атрибутов для поставленных целей и тогда принимайте решение о ее развитии.
Мы подошли к мета-модели сугубо утилитарно. В качестве перспективных были определены три цели:
Модель была основана на идеях Togaf. Она имеет несколько слоев и представляет две части репозитория: Current и Solution. ”Current” на сегодняшний день в упрощенном виде представлена на рисунке.

Solution в основном повторяет структуру “Current”, но имеет некоторые особенности.
Хотя и сейчас модель остается довольно простой, но первый вариант был значительно проще. Это был только слой Application. Потом репозиторий пополнился компонентами, потом бизнес-объектами и бизнес-слоем.
Время от времени мы ощущаем последствия лаконичности модели, но для нас гораздо важнее не её усложнение, а зона покрытой репозиторием архитектуры и актуальность информации в репозитории. Так что, похоже, мы нашли ту золотую серединку, когда хватает сил на поддержание актуальной информации в репозитории и в тоже время уровень детализации полезен и достаточен для анализа архитектуры и создания решений для инициатив.
В основе нашего репозитория лежит Sparx Enterprise Architect: были использованы почти все возможности, предоставляемые этой системой по кастомизации решения — используется своя мета-модель (технология MDG), поддерживаемая тысячами строк кода на Java и Javascript. Конечно, кастомизация ведет к необходимости самостоятельного развития и поддержки, но мы были к этому готовы.
Теперь немного подробнее о том, что из себя представляет текущая состояние репозитория.
На уровне бизнес-слоя основными элементами являются бизнес-сервисы и сценарии использования:

Сервисы:
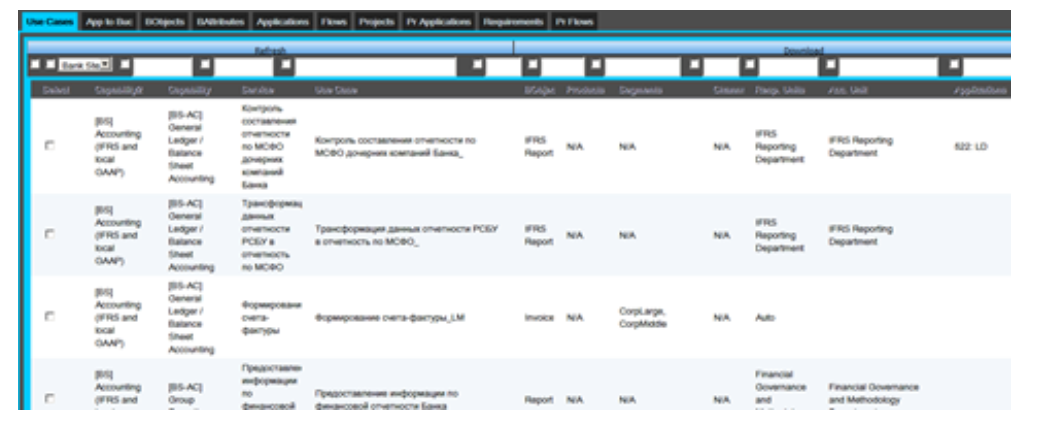
И сценарии использования:
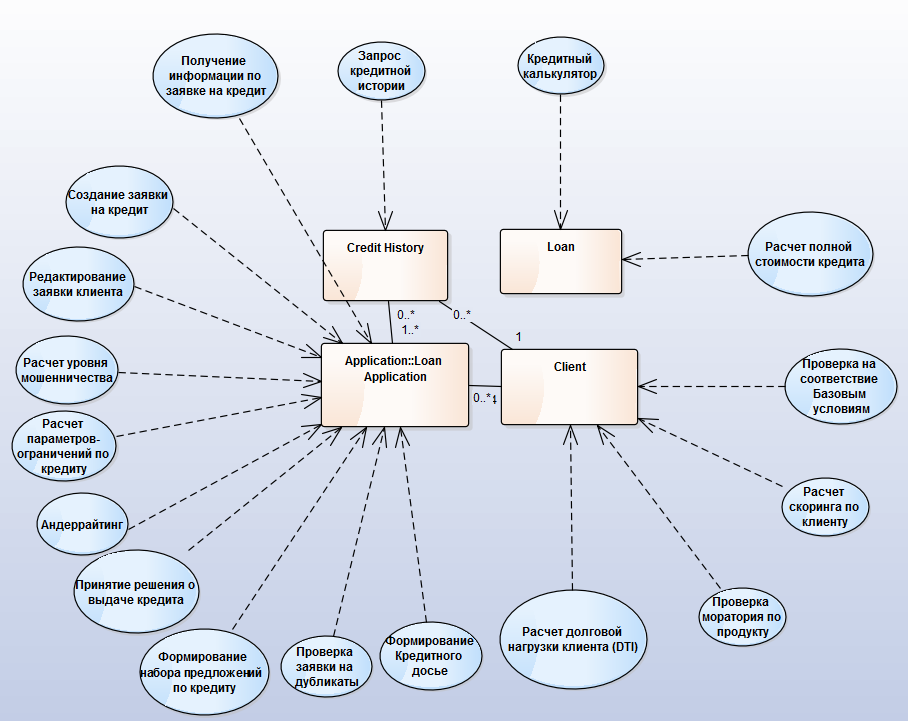
В нашем случае сценарии использования детализируют бизнес-сервис в конкретных условиях его применения. Но всё же сценарий — это довольно крупно-гранулярное представление бизнес-функциональности.
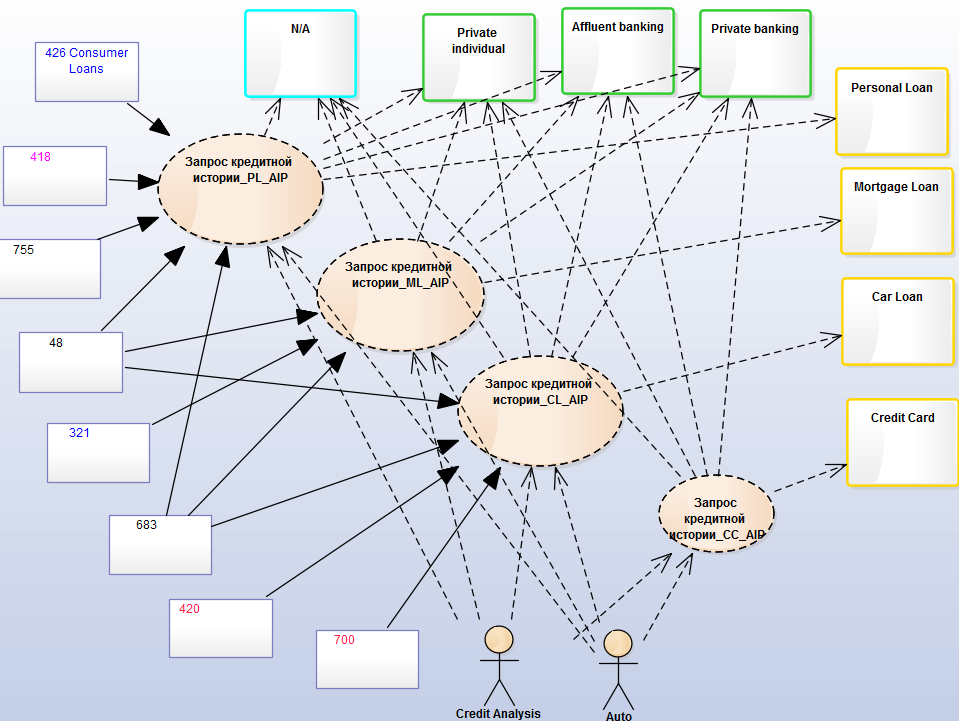
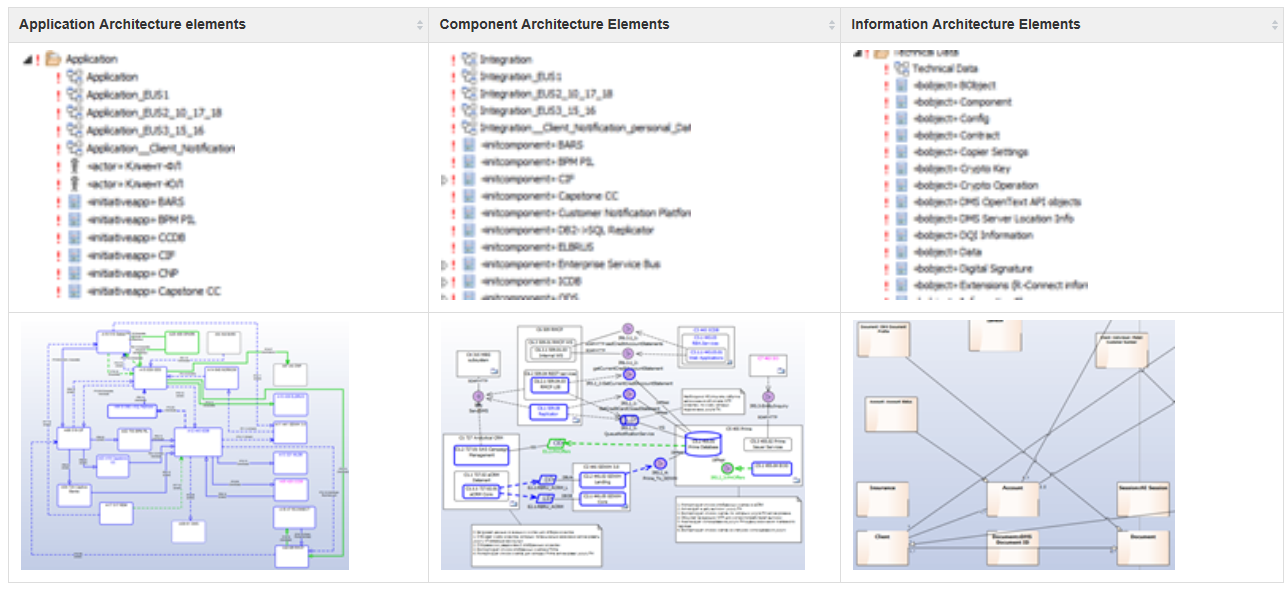
Сценарии использования автоматизируются приложениями — это уже уровень Application Architecture, где приложения связаны между собой информационными потоками:

Потоки содержат бизнес-объекты из слоя Data Architrecture:

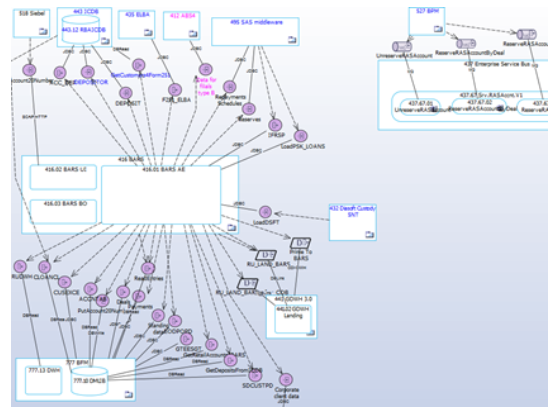
Основой для Application Architecture является Component Architecture, где каждое приложение имеет представление своей структуры в виде компонентов, а потоки детализируются в виде взаимодействия компонентов через интерфейсы:
Теперь посмотрите еще раз на упомянутые элементы и их взаимоотношения. Всё очень просто, но позволяет на достаточном уровне описать архитектуру крупного банка. После нескольких лет работы в репозитории накопилось почти десять тысяч архитектурных элементов, между которыми сформировалось несколько десятков тысяч связей. И это только Current Architecture.
Перейдем ко второму пункту обозначенных выше целей. Нам требуется создавать Solution Architecture для инициатив различных размеров, реализуемых по различным методологиям, включая Agile.
Решение описывается для каждого слоя архитектуры. Мета-модель Solution части репозитория в основном повторяет структуру Current, но имеет отличия. Например, набор атрибутов пересекается лишь частично. Плюс элементы и связи из части Solution имеют набор атрибутов, необходимых для описания решения.
Пройдемся по всем четырем слоям решения.
Бизнес архитектура содержит два вида элементов. Это крупные Use Cases, которые реализуются в проекте, и более детальные Requirements для «водопадных» проектов или User Stories в случае Agile-инициатив. Причем Use Cases обязательно имеют своё зеркало в части Current. При этом Requirements и User Stories — это элементы исключительно части Solution и не имеют представления в части Current. Еще одна важная деталь: Sparx-репозиторий не является для них мастер-системой. Они экспортируются из других систем.
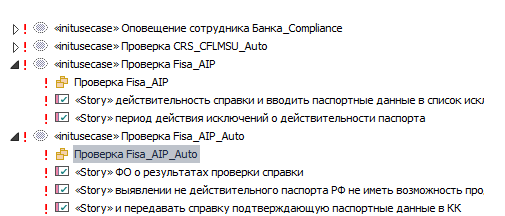
Requirements и User Stories сопоставляются с ответственными за них приложениями.
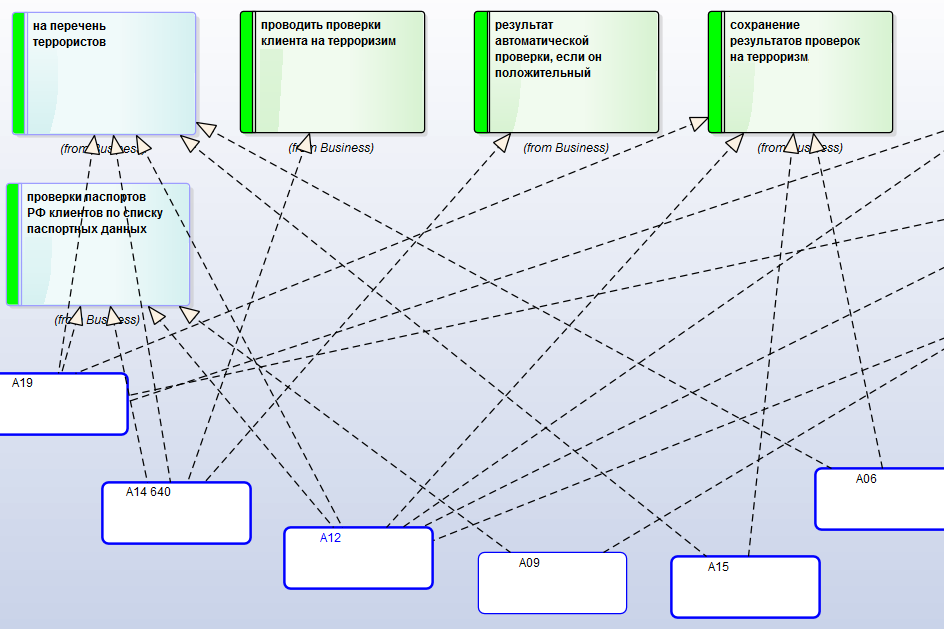
Оставшиеся слои Solution Architecture имеют диаграммы, похожие на Current Architecture:
Цветовая гамма элементов и связей Solution Architecture передает вид архитектурных изменений. Описание изменений можно заносить как в соответствующие атрибуты элементов и связей, так и в прикрепленные к элементам Notes.
На основе этих данных генерируются соответствующие части архитектурного документа.
Хотя, как показывает практика, наиболее востребованными являются диаграммы. Именно они используются во время обсуждений с Enterprise-архитекторами, командами разработчиков, вендорами и на Архитектурном комитете.
Что самое замечательное, в силу «единственности» репозитория все элементы и связи, используемые на диаграммах, задокументированы и единообразно понимаются всеми участниками дискуссий. Поэтому, изначально все участники находятся на одной волне.
Еще один выдающийся момент. Описание Solution-архитектуры достаточно для актуализации текущего ландшафта. Таким образом, по факту выпуска решения в production, архитектурные изменения с помощью скриптов переносятся из части Solution в часть Current.

Репозиторий благодаря такой взаимосвязи остается актуальным несмотря на постоянные инициативы по изменениям ландшафта.
Репозиторий с таким значительным количеством элементов и связей, в котором работают десятки пользователей, надо содержать в адекватном состоянии. Например, все обязательные атрибуты должны быть заполнены; связи между элементами должны быть определенного вида. Более того, состояние архитектур Application и Component должно соответствовать одно другому, поскольку они представляют одни и те же приложения, но с разной степенью детализации.
Конечно, обучение пользователей играет важную роль. Но этого крайне мало. Людям свойственно ошибаться. Мы смягчили эту проблему с помощью кода на Java и JavaScript. Каждую ночь по расписанию запускаются скрипты, которые значительно облегчают нашу жизнь:
Сравнивая два состояния — сегодняшний день и тот «доисторический» период, — однозначно можно отметить, что требования к архитекторам возросли. Вырос и порог входа для любого человека, которому по тем или иным причинам необходим анализ архитектуры.
Крайне важным является то, что люди, ответственные за ведение репозитория, тратят на это достаточно много времени и, в нашем случае, должны уметь разрабатывать код.
Возвращаясь к мета-модели репозитория, хочу отметить, что в рамках простой модели очень сложно свести воедино мнение многих заинтересованных сторон, и еще сложнее оставаться с нею продолжительное время. И любые изменения в мета-модели должны в том или ином виде отразиться в скриптах автоматизации.
С другой стороны, анализ архитектуры и дизайн решения стали проще и значительно короче. Качество Solution-архитектуры возросло на порядок. Решение стало намного детальнее и всегда остаётся консистентным. В работе архитектора теперь минимизированы рутинные операции, связанные с оформлением документации, с необходимостью поддержки её в актуальном состоянии. Архитектор действительно занимается творчеством.
И в заключении несколько слов об инструменте, который мы использовали для реализации репозитория, о Sparx Enterprise Architect. С моей точки зрения, у него выдающееся соотношение цена/качество. Конечно, в основном это обусловлено его низкой ценой, но присутствует практически вся необходимая нам функциональность.
Что нам не хватает, так это разнообразных интерактивных вьюшек на данные в архитектурном репозитории. Ведь качественный анализ без них крайне затруднен. Начинали мы с простых SQL-запросов напрямую к базе данных Sparx. Но потом решили эту проблему самостоятельной разработкой. Дополнительно к самому Sparx мы смотрим на репозиторий через кастомное веб-приложение, где наиболее популярные вьюшки представлены в табличном виде с возможностью фильтрации, сортировки и трассировки между ними по выбранным значениям:

Что я подразумеваю под «сложным»: это несколько сотен бизнес-приложений с довольно внушительной дисперсией атрибутов — технологии, разнородность функциональности, связанность с другим приложениями, критичность, возраст, размер и так далее. Добавьте сюда динамику, поскольку ландшафт неустанно меняют несколько десятков внутренних и внешних команд. Иными словами — самый отпетый, или, на устойчивом жаргоне, «кровавый» энтерпрайз.
Очевидно, что в этом бурлящем котле каждая новая инициатива по изменению начиналась с поисков: где и что нужно делать, как определить достаточность и необходимость изменений. То есть проводился анализ. И поскольку котел большой и градус изменений высокий, то анализ, а он должен быть качественным, длился месяцами. Но тщательность не гарантировала 100%-го качества, поскольку на той же поляне, что и ваша инициатива, могли толкаться другие, внося непредвиденные вами изменения.
Кто-то скажет, что это обычная картина для «кровавого» энтерпрайза. То ли дело Agile-команды с единственным владельцем продукта. Всё учтено, и команда знает всё. Не буду спорить. Во многом это правда. Но на рваном лоскутном ландшафте независимых команд не построишь. А действительно крупные задачи одной командой не решишь. Да и в любой методологии должен быть разумный уровень порядка.
Единый архитектурный репозиторий
Именно с наведения порядка мы и начали. Это вылилось в создание единого архитектурного репозитория. Начнем с его мета-модели. По моему мнению, подобные изменения всегда надо начинать с разработки мета-модели. Это лучший способ объяснить заинтересованным сторонам и, самое главное, самим себе, что сможет дать новый репозиторий. Мета-модель покажет, как ваши цели ложатся на возможности систем, где репозиторий будет реализовываться. При её разработке проще всего посмотреть на документы, которые уже есть в вашей компании. Изучите имеющийся опыт. Посмотрите на ванильные модели различных вендоров. Если уж совсем по-серьезному, то почитайте ГОСТы, например, ГОСТ 57100 (ISO 42010).
Для начала включайте в мета-модель только самое необходимое, поскольку начинать лучше с простого. Потом, если окажется, что такой модели недостаточно, то развить её не составит труда. Причем развитие будет осознанным. То есть здесь самый правильный подход — итеративный. Начинайте с небольшого участка архитектуры. Посмотрите, как с ней справляется ваша модель. Достаточно ли в ней элементов, связей и атрибутов для поставленных целей и тогда принимайте решение о ее развитии.
Мы подошли к мета-модели сугубо утилитарно. В качестве перспективных были определены три цели:
- Иметь описание текущего архитектурного ландшафта.
- На базе текущего ландшафта уметь создавать Solution-архитектуру для изменений.
- Поддерживать репозиторий в актуальном состоянии.
Модель была основана на идеях Togaf. Она имеет несколько слоев и представляет две части репозитория: Current и Solution. ”Current” на сегодняшний день в упрощенном виде представлена на рисунке.

Solution в основном повторяет структуру “Current”, но имеет некоторые особенности.
Хотя и сейчас модель остается довольно простой, но первый вариант был значительно проще. Это был только слой Application. Потом репозиторий пополнился компонентами, потом бизнес-объектами и бизнес-слоем.
Время от времени мы ощущаем последствия лаконичности модели, но для нас гораздо важнее не её усложнение, а зона покрытой репозиторием архитектуры и актуальность информации в репозитории. Так что, похоже, мы нашли ту золотую серединку, когда хватает сил на поддержание актуальной информации в репозитории и в тоже время уровень детализации полезен и достаточен для анализа архитектуры и создания решений для инициатив.
В основе нашего репозитория лежит Sparx Enterprise Architect: были использованы почти все возможности, предоставляемые этой системой по кастомизации решения — используется своя мета-модель (технология MDG), поддерживаемая тысячами строк кода на Java и Javascript. Конечно, кастомизация ведет к необходимости самостоятельного развития и поддержки, но мы были к этому готовы.
Current Architecture
Теперь немного подробнее о том, что из себя представляет текущая состояние репозитория.
На уровне бизнес-слоя основными элементами являются бизнес-сервисы и сценарии использования:
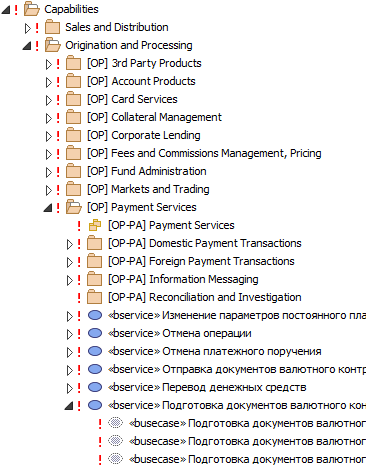
Сервисы:
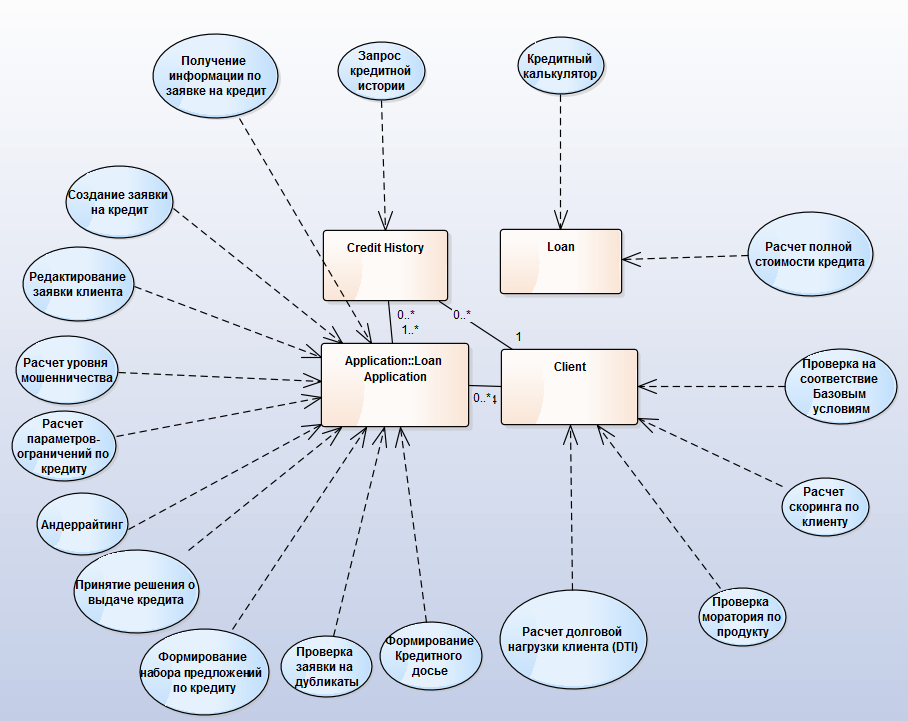
И сценарии использования:
В нашем случае сценарии использования детализируют бизнес-сервис в конкретных условиях его применения. Но всё же сценарий — это довольно крупно-гранулярное представление бизнес-функциональности.
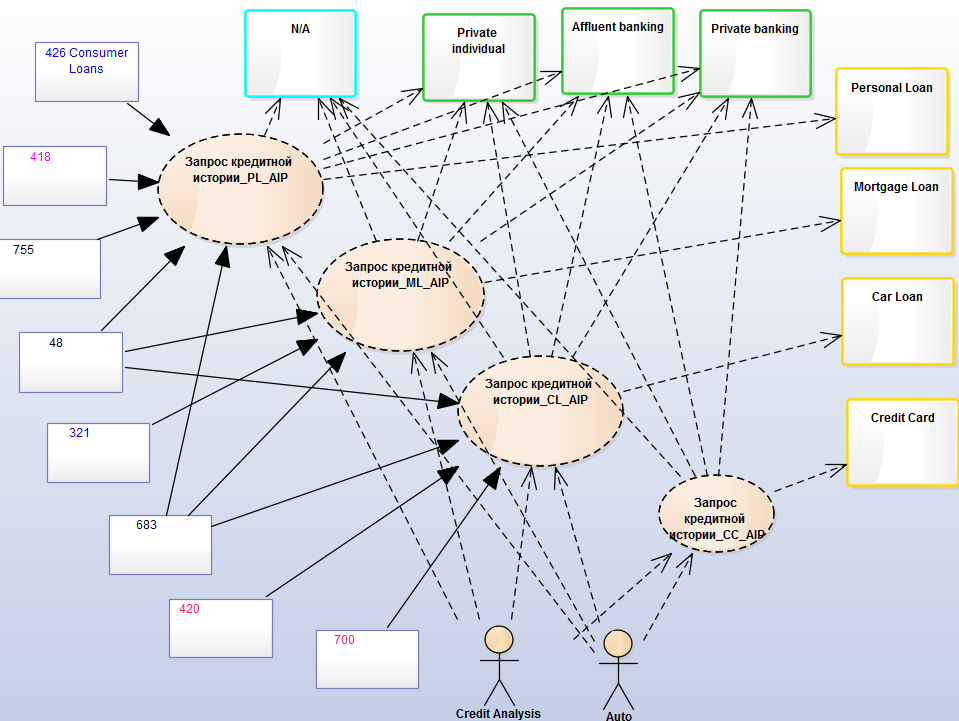
Сценарии использования автоматизируются приложениями — это уже уровень Application Architecture, где приложения связаны между собой информационными потоками:
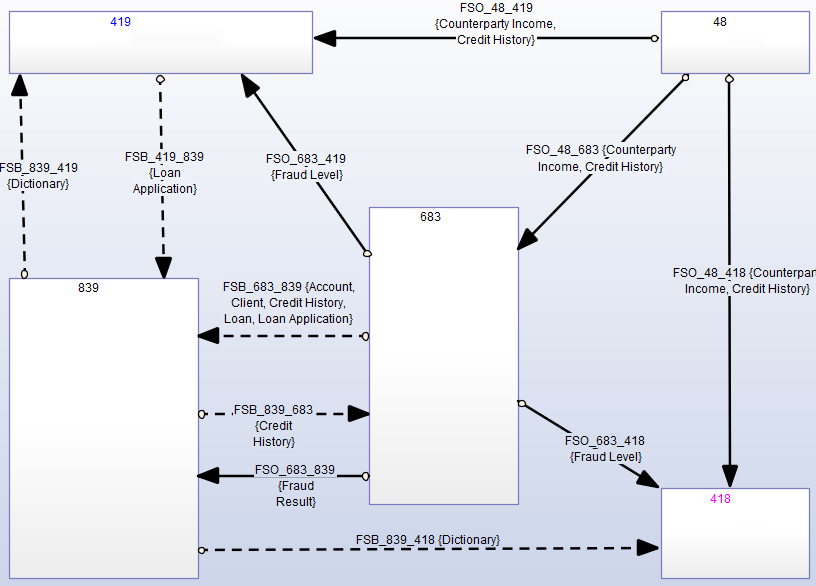
Потоки содержат бизнес-объекты из слоя Data Architrecture:
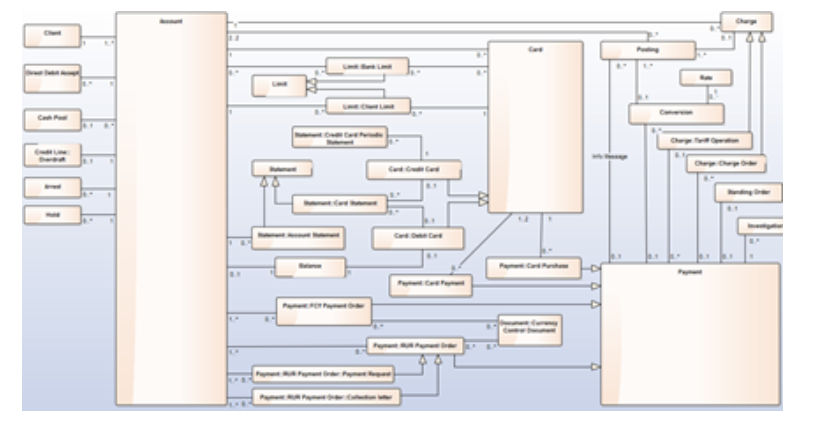
Основой для Application Architecture является Component Architecture, где каждое приложение имеет представление своей структуры в виде компонентов, а потоки детализируются в виде взаимодействия компонентов через интерфейсы:
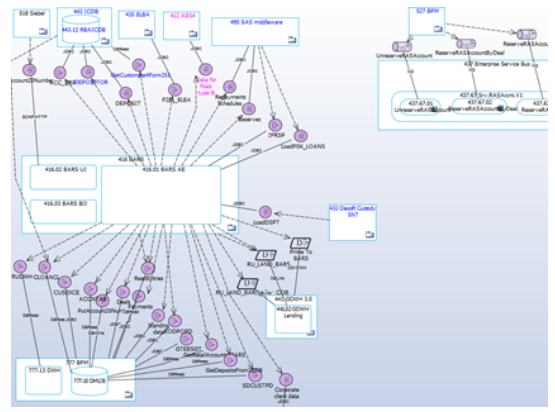
Теперь посмотрите еще раз на упомянутые элементы и их взаимоотношения. Всё очень просто, но позволяет на достаточном уровне описать архитектуру крупного банка. После нескольких лет работы в репозитории накопилось почти десять тысяч архитектурных элементов, между которыми сформировалось несколько десятков тысяч связей. И это только Current Architecture.
Solution Architecture
Перейдем ко второму пункту обозначенных выше целей. Нам требуется создавать Solution Architecture для инициатив различных размеров, реализуемых по различным методологиям, включая Agile.
Решение описывается для каждого слоя архитектуры. Мета-модель Solution части репозитория в основном повторяет структуру Current, но имеет отличия. Например, набор атрибутов пересекается лишь частично. Плюс элементы и связи из части Solution имеют набор атрибутов, необходимых для описания решения.
Пройдемся по всем четырем слоям решения.
Бизнес архитектура содержит два вида элементов. Это крупные Use Cases, которые реализуются в проекте, и более детальные Requirements для «водопадных» проектов или User Stories в случае Agile-инициатив. Причем Use Cases обязательно имеют своё зеркало в части Current. При этом Requirements и User Stories — это элементы исключительно части Solution и не имеют представления в части Current. Еще одна важная деталь: Sparx-репозиторий не является для них мастер-системой. Они экспортируются из других систем.
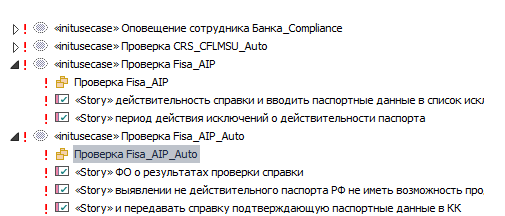
Requirements и User Stories сопоставляются с ответственными за них приложениями.

Оставшиеся слои Solution Architecture имеют диаграммы, похожие на Current Architecture:
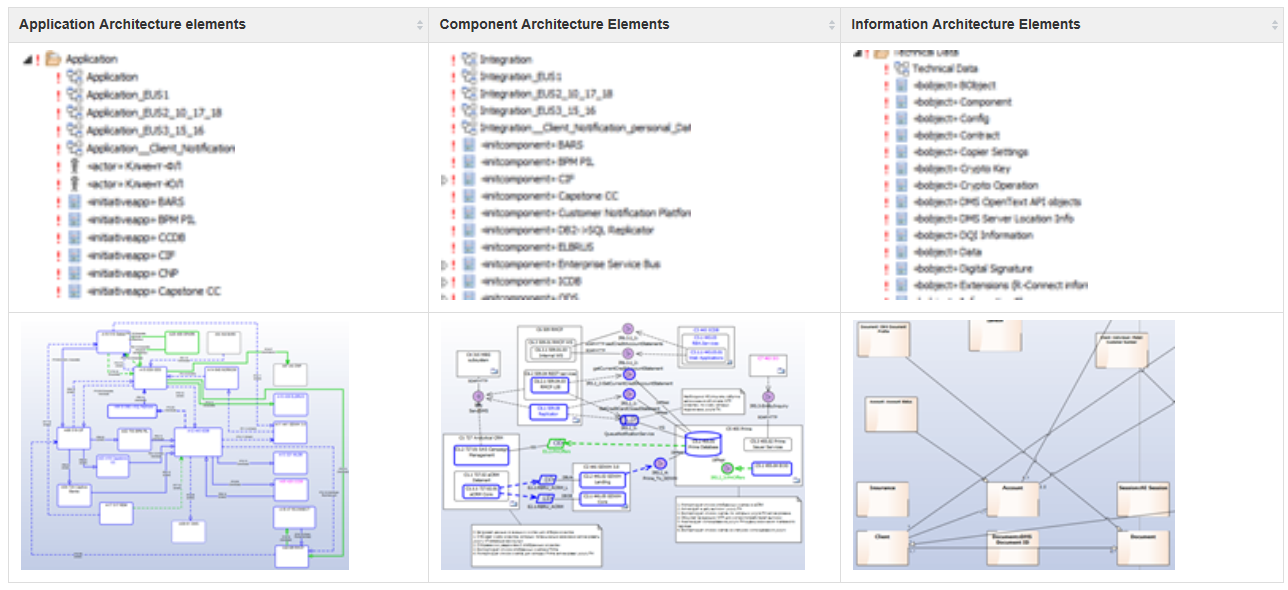
Цветовая гамма элементов и связей Solution Architecture передает вид архитектурных изменений. Описание изменений можно заносить как в соответствующие атрибуты элементов и связей, так и в прикрепленные к элементам Notes.
На основе этих данных генерируются соответствующие части архитектурного документа.
Хотя, как показывает практика, наиболее востребованными являются диаграммы. Именно они используются во время обсуждений с Enterprise-архитекторами, командами разработчиков, вендорами и на Архитектурном комитете.
Что самое замечательное, в силу «единственности» репозитория все элементы и связи, используемые на диаграммах, задокументированы и единообразно понимаются всеми участниками дискуссий. Поэтому, изначально все участники находятся на одной волне.
 |
 |
|---|---|
| При анализе больших инициатив Solution-архитектор не тратит время на поиск информации | Software-архитектор при изучении Solution-архитектуры видит хорошо знакомые ему элементы. Он понимает, о чем эта архитектура |
Еще один выдающийся момент. Описание Solution-архитектуры достаточно для актуализации текущего ландшафта. Таким образом, по факту выпуска решения в production, архитектурные изменения с помощью скриптов переносятся из части Solution в часть Current.

Репозиторий благодаря такой взаимосвязи остается актуальным несмотря на постоянные инициативы по изменениям ландшафта.
Поддержка репозитория
Репозиторий с таким значительным количеством элементов и связей, в котором работают десятки пользователей, надо содержать в адекватном состоянии. Например, все обязательные атрибуты должны быть заполнены; связи между элементами должны быть определенного вида. Более того, состояние архитектур Application и Component должно соответствовать одно другому, поскольку они представляют одни и те же приложения, но с разной степенью детализации.
Конечно, обучение пользователей играет важную роль. Но этого крайне мало. Людям свойственно ошибаться. Мы смягчили эту проблему с помощью кода на Java и JavaScript. Каждую ночь по расписанию запускаются скрипты, которые значительно облегчают нашу жизнь:
- Проверяют содержимое репозитория на соответствие мета-модели. Скрипт либо сам исправляет ошибки, либо указывает необходимость вмешательства человека.
- Генерируют содержание Current Application Architecture на основе Current Component Architecture.
- Генерируют несколько видов диаграмм для визуализации содержимого репозитория.
- Генерируют документы Solution Architecture для подготовленных инициатив.
- Выгружают содержимое репозитория в общебанковский доступ на HTML-портал.
- Ещё одно преимущество простой мета-модели: благодаря её простоте скрипты автоматизации получаются тоже проще.
Выводы
Сравнивая два состояния — сегодняшний день и тот «доисторический» период, — однозначно можно отметить, что требования к архитекторам возросли. Вырос и порог входа для любого человека, которому по тем или иным причинам необходим анализ архитектуры.
Крайне важным является то, что люди, ответственные за ведение репозитория, тратят на это достаточно много времени и, в нашем случае, должны уметь разрабатывать код.
Возвращаясь к мета-модели репозитория, хочу отметить, что в рамках простой модели очень сложно свести воедино мнение многих заинтересованных сторон, и еще сложнее оставаться с нею продолжительное время. И любые изменения в мета-модели должны в том или ином виде отразиться в скриптах автоматизации.
С другой стороны, анализ архитектуры и дизайн решения стали проще и значительно короче. Качество Solution-архитектуры возросло на порядок. Решение стало намного детальнее и всегда остаётся консистентным. В работе архитектора теперь минимизированы рутинные операции, связанные с оформлением документации, с необходимостью поддержки её в актуальном состоянии. Архитектор действительно занимается творчеством.
И в заключении несколько слов об инструменте, который мы использовали для реализации репозитория, о Sparx Enterprise Architect. С моей точки зрения, у него выдающееся соотношение цена/качество. Конечно, в основном это обусловлено его низкой ценой, но присутствует практически вся необходимая нам функциональность.
Что нам не хватает, так это разнообразных интерактивных вьюшек на данные в архитектурном репозитории. Ведь качественный анализ без них крайне затруднен. Начинали мы с простых SQL-запросов напрямую к базе данных Sparx. Но потом решили эту проблему самостоятельной разработкой. Дополнительно к самому Sparx мы смотрим на репозиторий через кастомное веб-приложение, где наиболее популярные вьюшки представлены в табличном виде с возможностью фильтрации, сортировки и трассировки между ними по выбранным значениям: