Говорят, метатеги для целей SEO мертвы и больше нет смысла прописывать заветную строку meta keywords. Действительно, в современных многофакторных алгоритмах этот тег потерял свой вес. Но это вовсе не значит, что нужно отказываться от работы с семантическим ядром сайта — оно по-прежнему бесценно для структурирования сайта, формирования тематики (которой и интересуются поисковики) и даже для контекстной рекламы. Собрать ядро — задача не из лёгких, собрать его с умом и не превратить в «накидайте мне синонимов» — ещё сложнее. Так вот, в статье пойдет речь о макросах и формулах MS Excel, которые упростят обработку больших семантических ядер. Представляем вам небольшого Excel-робота от нашего изобретательного и не жадного специалиста отдела контекстной рекламы RealWeb Дмитрия Тумайкина. Ему и слово.

«Привет, Хабр! C самого начала хочу предупредить читателей, что разработка не является чем-то новым на рынке по логике и принципу работы, но имеет ряд преимуществ перед другими известными инструментами:
Файл является одним из серии файлов для специалистов по контекстной рекламе (планируются ещё интересные и очень полезные «роботы»). К слову сказать, разработка была создана «с нуля», и уже постфактум стало известно, что на рынке уже есть схожие макросы для табличных редакторов – например, публикация Devaka (макрос для OpenOffice) и разработка команды MFC-team, являющаяся адаптацией этого макроса под MS Excel. Впрочем, ни один из файлов не мог удовлетворить мои потребности как потребности специалиста по контекстной рекламе. У нашей разработки есть свои преимущества, о чём расскажу чуть ниже.
Допустим, есть большое семантическое ядро. Каким образом оно было получено, нас не интересует. По сути это неструктурированный набор запросов, который мы хотели бы структурировать. Каким образом мы делаем это вручную?
Будучи искренне верящим в то, что лень — двигатель прогресса, и написавшим по этой причине не один макрос, я начал искать инструменты, которые позволили бы весь процесс максимально автоматизировать. Среди вариантов я не нашёл ни одного, полностью удовлетворяющего моим требованиям. И вот почему.
KeyСollector и СловоЁБ — многофункциональные программы, одна из задач которых – сбор семантического ядра. Первая платная, вторая является урезанной бесплатной версией. В них есть модуль «стоп-слова», позволяющий отметить фразы в таблице, содержащие данные стоп-слова.
Минусы данных программ:
http://py7.ru/tools/group/ — инструменты появились в открытом доступе совсем недавно, но завоевали нешуточную популярность. Механика работы данного инструмента немного отличается от KeyCollector-а, но проблемы те же самые – ошибки со словоформами, невозможность анализировать несколько категорий одновременно.
Вышеупомянутые макросы Devaka и MFC. Здесь основной проблемой является то, что оба макроса используют алгоритм поиска по «маске», т.е. если слово-маркер является составляющей частью любого из слов, весь запрос относится к этой категории. В итоге, чем короче слово-маркер – тем больше ошибок, со словами Б и БУ невозможно работать априори, но верхний порог по символам даже в 6 символов не избавит вас от необходимости перепроверять всё сделанное. Например, слово «ванная» встречается в сотнях отглагольных прилагательных (лакированная, гофрированная…). Понятно, что во многих случаях о релевантности и речи не идёт.
… я и создал свой файл сблэкджэком формулами и макросами. Не мудрствуя лукаво, он просто анализирует, встречается ли слово в точном соответствии в вашем запросе, поэтому никаких ошибок нет априори. Многие формулы (Substring, Multicat) не написаны с нуля, а являются импортированными из надстройки PLEX (за которую отдельная благодарность ее создателю).
Теперь подробнее о разработке, комментарии на скриншоте:
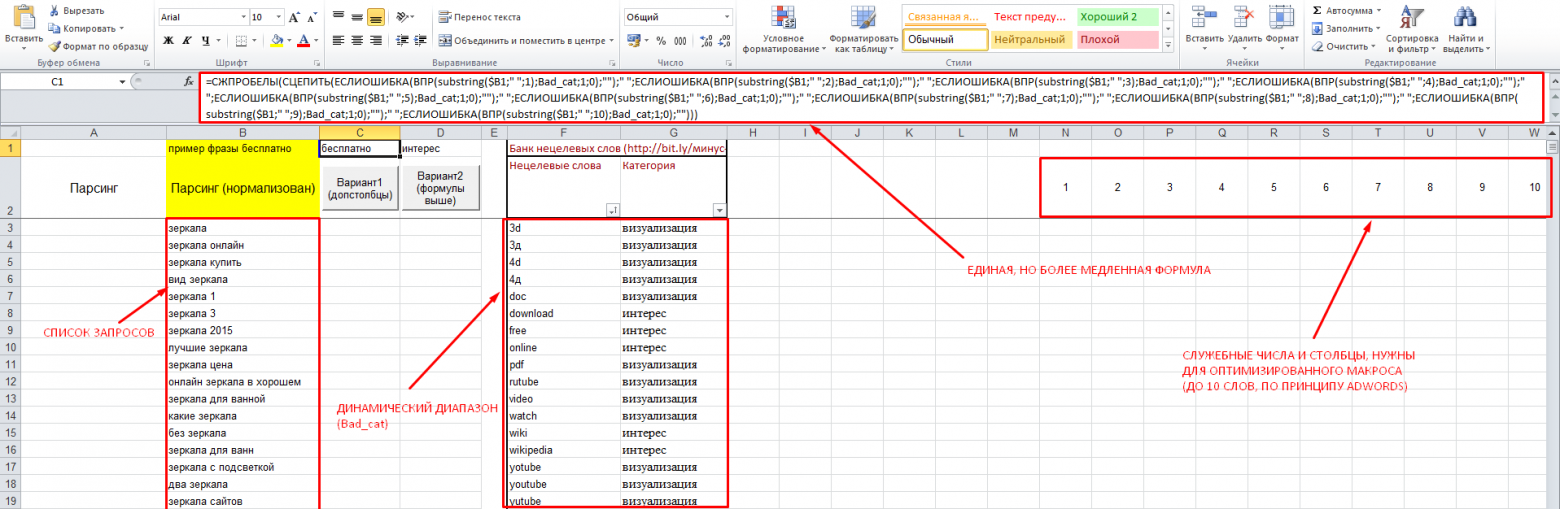
Ссылка на файл: робот-распознаватель
В файле 2 макроса, действующих по простому принципу – они:
Пример формулы, которая делает всё это в одной ячейке, сохранён в верхней строке, откуда её можно просто копировать вручную. Есть и макрос, который сделает это за вас, поместив новые данные в диапазон ровно напротив вашего списка ключей (в нём не должно быть пустых ячеек!). Однако такой вариант более ресурсозатратный, и заставит вас достаточно долго ждать, если количество ключевых слов и банк минус слов, допустим, более 5000. Поэтому создан второй макрос, делающий всё то же самое «пошагово» и отбрасывающий по пути ненужные вычисления.
Рекомендации:
Вот такая история. Берите файл, создавайте семантические ядра, используйте их в контекстной рекламе и SEO, делайте свой сайт лучше, делитесь опытом с другими.
P.S.: Пожелания и багрепорты приветствуются.
На текущий момент в файле используется линейный поиск ВПР. Позже выложу версию файла с бинарным поиском, прирост скорости вычислений на больших объемах будет колоссальный. Список минус-слов, указанный в файле, не является рекомендацией и может навредить вам и/или вашему клиенту, поэтому призываю проверять публичные списки (включая этот) на соответствие тематике вашего клиента, и дополнять его новыми словами. Формулы и макросы работают только в оригинальном файле, и не будут работать в других. Использование макросов в Excel не вредит вашему здоровью».
На этом и заканчивается история Дмитрия о создании полезного макроса. А мы напоминаем, что иногда самые сложные задачи имеют простые решения. MS Excel всегда был и остаётся главным помощником аналитиков, специалистов по контекстной рекламе и SEO-оптимизаторов. Его функции, формулы и макросы способны порождать интересные инструменты, облегчающие труд специалистов. Ну и, конечно, будет очень здорово, если некоторые из разработок будут выкладываться в открытый доступ и приносить реальную практическую пользу.

«Привет, Хабр! C самого начала хочу предупредить читателей, что разработка не является чем-то новым на рынке по логике и принципу работы, но имеет ряд преимуществ перед другими известными инструментами:
- Является полностью бесплатной для всех пользователей(в отличие от KeyCollector и ряда других подобных сервисов).
- Не требует подключения к интернету + использует локальные мощности (есть версия, созданная для Google Docs, но на больших объемах данных работает медленнее вашего компьютера, даже одноядерного, т.к. корпорация добра по привычке ограничивает процессорные мощности на 1-го пользователя.
- Представляет собой оптимизированный (насколько позволяет знание алгоритмов вычислений Excel) алгоритм для обработки больших ядер.
Файл является одним из серии файлов для специалистов по контекстной рекламе (планируются ещё интересные и очень полезные «роботы»). К слову сказать, разработка была создана «с нуля», и уже постфактум стало известно, что на рынке уже есть схожие макросы для табличных редакторов – например, публикация Devaka (макрос для OpenOffice) и разработка команды MFC-team, являющаяся адаптацией этого макроса под MS Excel. Впрочем, ни один из файлов не мог удовлетворить мои потребности как потребности специалиста по контекстной рекламе. У нашей разработки есть свои преимущества, о чём расскажу чуть ниже.
А пока — зачем это нужно?
Допустим, есть большое семантическое ядро. Каким образом оно было получено, нас не интересует. По сути это неструктурированный набор запросов, который мы хотели бы структурировать. Каким образом мы делаем это вручную?
- «Пробежавшись» по запросам глазами, пытаемся понять общую смысловую направленность, выделяем, какие категории запросов присутствуют в ядре.
- Определяем и выделяем слова-маркеры, которые позволят отнести запросы к той или иной категории. Самый примитивный вариант — «целевой-нецелевой», но можно выделять и направленность слов. Например, для компаний, работающих с e-commerce, популярными будут оптовые (опт, база, склад, оптовый…), информационные (как, где, отличие, сравнение, отзывы…), покупающие (магазин, купить, цена, стоимость…), арендные (прокат, напрокат, в прокат, аренда…), гео-маркеры, и т.д…
- Ищем каждый из запросов в исходном списке с помощью фильтров, помечаем эти запросы. Здесь всё зависит от фантазии – если у нас всего два варианта, то достаточно запросы просто отметить разными цветами. Если же вариантов много, чтобы не допустить путаницы, мы могли бы отметить напротив запросов в соседнем столбце в той же колонке название той самой категории, к которой принадлежит слово-маркер, содержащееся в запросе. А чтобы всё было ещё более наглядно, можно указывать в дополнительном столбце и само слово-маркер. К этому в итоге я и пришёл.
- После того, как всё разложено «по полочкам» таким образом – используем полученные списки в своих целях. Специалисты контекстной рекламы выставляют корректировки ставок в зависимости от категории запроса (например, чем «теплее» запрос, тем выше ставка), либо «минусуют» совсем нецелевые запросы.
Будучи искренне верящим в то, что лень — двигатель прогресса, и написавшим по этой причине не один макрос, я начал искать инструменты, которые позволили бы весь процесс максимально автоматизировать. Среди вариантов я не нашёл ни одного, полностью удовлетворяющего моим требованиям. И вот почему.
KeyСollector и СловоЁБ — многофункциональные программы, одна из задач которых – сбор семантического ядра. Первая платная, вторая является урезанной бесплатной версией. В них есть модуль «стоп-слова», позволяющий отметить фразы в таблице, содержащие данные стоп-слова.
Минусы данных программ:
- Невозможно использовать сразу несколько категорий, т.к. фразы будут просто отмечены в таблице. Поэтому анализ ядра на присутствие запросов определенной категории нужно проводить ровно столько раз, сколько у вас категорий.
- Если использовать поиск, не зависящий от словоформы, то могут быть ошибки сопоставления, например, «бельё» и «белый» считаются морфемами одного слова.
http://py7.ru/tools/group/ — инструменты появились в открытом доступе совсем недавно, но завоевали нешуточную популярность. Механика работы данного инструмента немного отличается от KeyCollector-а, но проблемы те же самые – ошибки со словоформами, невозможность анализировать несколько категорий одновременно.
Вышеупомянутые макросы Devaka и MFC. Здесь основной проблемой является то, что оба макроса используют алгоритм поиска по «маске», т.е. если слово-маркер является составляющей частью любого из слов, весь запрос относится к этой категории. В итоге, чем короче слово-маркер – тем больше ошибок, со словами Б и БУ невозможно работать априори, но верхний порог по символам даже в 6 символов не избавит вас от необходимости перепроверять всё сделанное. Например, слово «ванная» встречается в сотнях отглагольных прилагательных (лакированная, гофрированная…). Понятно, что во многих случаях о релевантности и речи не идёт.
И вот именно поэтому…
… я и создал свой файл с
Теперь подробнее о разработке, комментарии на скриншоте:
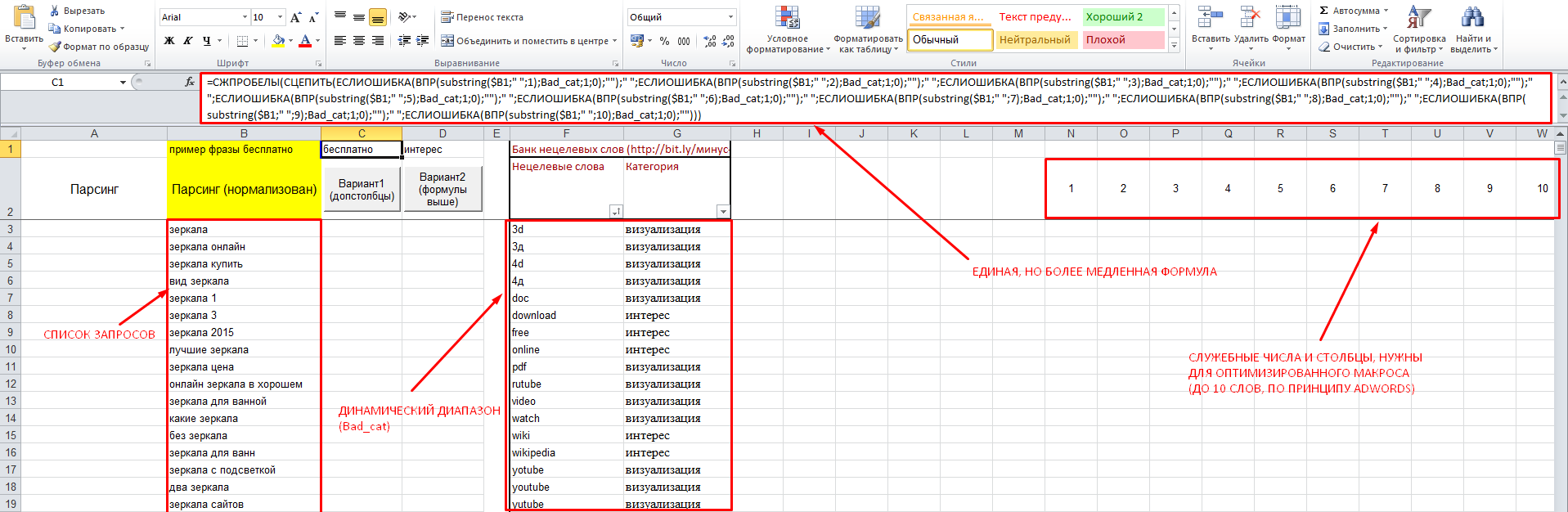
Ссылка на файл: робот-распознаватель
В файле 2 макроса, действующих по простому принципу – они:
- Делят запросы на слова (разделителем считается пробел). По принципу AdWords, только первые 10 слов.
- Сравнивают каждое из слов с «банком минус-слов», который представляет собой именованный динамический диапазон, т.е. в него можно добавлять слова вплоть до конца столбца, и макрос будет подстраиваться под каждый вариант, забирая тем больше процессорного времени, чем больше «банк», и наоборот.
- Если находят слово в банке – возвращают его, если не находят, возвращают «две кавычки» (пустой результат).
- Нехитрой формулой ВПР (вертикальный просмотр) возвращают категорию каждого из слов из соседнего столбца.
- Склеивают все полученные параметры вместе (через пробел) и выводят в соответствующие столбцы напротив.
Пример формулы, которая делает всё это в одной ячейке, сохранён в верхней строке, откуда её можно просто копировать вручную. Есть и макрос, который сделает это за вас, поместив новые данные в диапазон ровно напротив вашего списка ключей (в нём не должно быть пустых ячеек!). Однако такой вариант более ресурсозатратный, и заставит вас достаточно долго ждать, если количество ключевых слов и банк минус слов, допустим, более 5000. Поэтому создан второй макрос, делающий всё то же самое «пошагово» и отбрасывающий по пути ненужные вычисления.
Рекомендации:
- Для ускорения работы макроса рекомендуется «банк минус-слов» иметь в сортированном виде «А-Я» (по слову).
- Использовать нормализованные списки (как ключей, так и минус-слов) – это заметно ускорит расчеты в файле и вашу работу, т.к. сужает семантическое ядро.
- Но быть с ними внимательными (проверять итоговый список). Так, «Дели» (город) и «Делить» — для программ-нормализаторов условно — одно и то же слово. Похожие примеры — «чай» и «чаять» или «покрывала» и «покрыть»
- Не лениться составлять собственные списки минус-слов для разных тематик и делиться ими с коллегами.
- Файл можно использовать для каталогизации любых ядер по любым группам запросов, т.е. не обязательно использовать для минус-слов. Все зависит от задачи и фантазии.
Вот такая история. Берите файл, создавайте семантические ядра, используйте их в контекстной рекламе и SEO, делайте свой сайт лучше, делитесь опытом с другими.
P.S.: Пожелания и багрепорты приветствуются.
На текущий момент в файле используется линейный поиск ВПР. Позже выложу версию файла с бинарным поиском, прирост скорости вычислений на больших объемах будет колоссальный. Список минус-слов, указанный в файле, не является рекомендацией и может навредить вам и/или вашему клиенту, поэтому призываю проверять публичные списки (включая этот) на соответствие тематике вашего клиента, и дополнять его новыми словами. Формулы и макросы работают только в оригинальном файле, и не будут работать в других. Использование макросов в Excel не вредит вашему здоровью».
На этом и заканчивается история Дмитрия о создании полезного макроса. А мы напоминаем, что иногда самые сложные задачи имеют простые решения. MS Excel всегда был и остаётся главным помощником аналитиков, специалистов по контекстной рекламе и SEO-оптимизаторов. Его функции, формулы и макросы способны порождать интересные инструменты, облегчающие труд специалистов. Ну и, конечно, будет очень здорово, если некоторые из разработок будут выкладываться в открытый доступ и приносить реальную практическую пользу.
