
Настало время подробно рассказать, как работает наша реализация алгоритма распознавания номеров: что оказалось удачным решением, что работало весьма скверно. И просто отчитаться перед Хабра-пользователями — ведь вы с помощью Android приложения Recognitor помогли нам набрать приличного размера базу снимков номеров, снятых совершенно непредвзято, без объяснения как снимать, а как нет. А база снимков при разработке алгоритмов распознавания самое важное!
Что получилось с Android приложением Recognitor
Было очень приятно, что пользователи Хабра взялись качать приложение, пробовать его и отправлять нам номера.
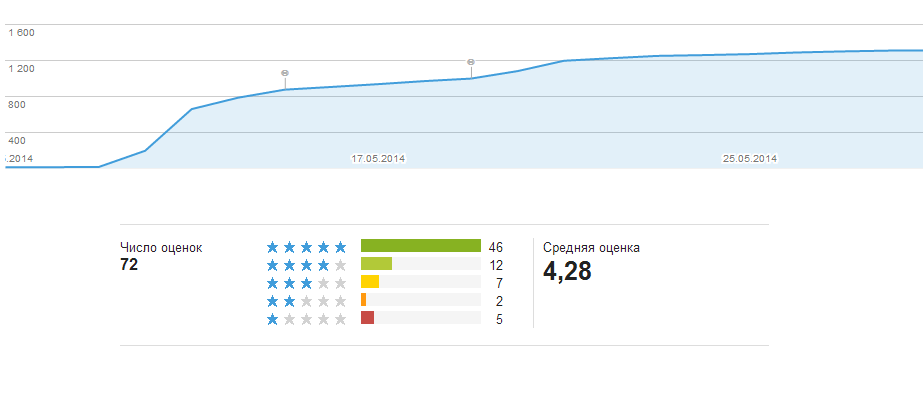
Скачиваний программы и оценки
С момента выкладывания приложения на сервер пришло 3800 снимков номеров от мобильного приложения.
А еще больше нас порадовала ссылка http://212.116.121.70:10000/uploadimage — нам за 2 дня отправили около 8 тысяч полноразмерных снимков автомобильных номеров (преимущественно вологодских)! Сервер почти лежал.
Теперь у нас на руках база в 12 000 снимков фотографий — впереди гигантская работа по отладке алгоритмов. Все самое интересное только начинается!
Напомню, что в приложении Android предварительно выделялся номер. В этой статье я не буду подробно останавливаться на этом этапе. В нашем случае — каскадный детектор Хаара. Этот детектор не всегда срабатывает, если номер в кадре сильно повернут. Анализ того, как работает нами обученный каскадный детектор, когда не работает, оставлю на следующие статьи. Это ведь действительно очень интересно. Кажется, что это черный ящик — вот обучили детектор и больше ничего не сделать. На самом деле это не так.
Но все-таки каскадный детектор — неплохой вариант в случае ограниченных вычислительных ресурсов. Если автомобильный номер грязный или рамка плохо видна, то Хаар тоже неплохо себя проявляет относительно других методов.
Распознавание номера
Здесь рассказ про распознавание текста в картинках такого вида:

Общие подходы про распознавании были описаны в первой статье.
Изначально мы ставили перед собой задачу распознавания грязных, частично стертых и здорово искаженных перспективой номеров.
Во-первых, это интересно, а во-вторых, казалось, что тогда чистые будут срабатывать вообще в 100% случаях. Обычно, конечно, так и происходит. Но тут не сложилось. Оказалось, что если по грязным номерам вероятность успеха была 88%, то по чистым, например, 90%. Хотя на деле вероятность распознавания от фотографии на мобильном приложении до успешного ответа, конечно, оказалось еще хуже указанной цифры. Чуть меньше 50% от приходящих изображений (чтобы люди не пытались фотографировать). Т.е. в среднем дважды нужно было сфотографировать номер, чтобы распознать его успешно. Хотя во многом такой низкий процент связан с тем, что многие пытались снимать номера с экрана монитора, а не в реальной обстановке.
Весь алгоритм строился для грязных номеров. Но вот оказалось, что сейчас летом в Москве 9 из 10 номеров идеально чистые. А значит лучше изменить стратегию и сделать два раздельных алгоритма. Если удалось быстро и надежно распознать чистый номер, то этот результат и отправим пользователю, а если не удалось, то тратим еще немного времени процессора и запускаем второй алгоритм для грязных номеров.
Простой алгоритм распознавания номеров, который стоило бы реализовать сразу
Как же распознать хороший и чистый номер? Это совсем не сложно.
Предъявим следующие требования к такому алгоритму:
1) некоторая устойчивость к поворотам (± 10 градусов)
2) устойчивость к незначительному изменению масштаба (20%)
3) отрезание каких-либо границ номера границей кадра или просто плохо выраженные границы не должны рушить все (это принципиально важно, т.к. в случае грязных номеров приходится опираться на границу номера; если номер чистый, то ничего лучше цифр/букв не характеризует номер).
Итак, в чистых и хорошо читаемых номерах все цифры и буквы отделимы друг от друга, а значит можно бинаризовать изображение и морфологическими методами либо выделить связанные области, либо воспользоваться известными функциями выделения контуров.
Бинаризуем кадр
Здесь стоит еще пройтись фильтром средних частот и нормализовать изображение.

На изображении приведен изначально малоконтрастный кадр для наглядности.
Затем бинаризовать по фиксированному порогу (можно порог фиксировать, т. к. изображение было нормализовано).
Гипотезы по повороту кадра
Предположим несколько возможных углов поворотов изображения. Например, +10, 0, -10 градусов:

В дальнейшем метод будет иметь небольшую устойчивость к углу поворота цифр и букв, поэтому выбран такой достаточно большой шаг по углу — 10 градусов.
С каждым кадром в дальнейшем будем работать независимо. Какая гипотеза по повороту даст лучший результат, та и победит.
А затем собрать все связанные области. Тут использовалась стандартная функция findContours из OpenCV. Если связанная область (контур) имеет высоту в пикселях от H1 до H2 а ширина и высота связана отношением от K1 до K2, то оставляем в кадре и отмечаем, что в этой области может быть знак. Почти наверняка на этом этапе останутся лишь цифры и буквы, остальной мусор из кадра уйдет. Возьмем ограничивающие контуры прямоугольники, приведем их к одному масштабу и дальше поработаем с каждой буквой/цифрой отдельно.
Вот какие ограничивающие прямоугольники контуров удовлетворили нашим требованиям:

Буквы/цифры
Качество снимка хорошее, все буквы и цифры отлично разделимы, иначе мы до этого шага не дошли бы.
Масштабируем все знаки к одному размеру, например, 20х30 пикселей. Вот они:

Кстати, OpenCV при выполнении Resize (при приведении к размеру 20х30) бинаризованное изображение превратит в градиентаное, за счет интерполяции. Придется повторить бинаризацию.
И теперь самый простой способ сравнить с известными изображениями знаков — использовать XOR (нормализованная дистанция Хэмминга). Например так:
Distance = 1.0 — |Sample XOR Image|/|Sample|
Если дистанция больше пороговой, то считаем, что мы нашли знак, меньше — выкидываем.
Буква-цифра-цифра-цифра-буква-буква
Да, мы ищем автомобильные знаки РФ именно в таком формате. Тут нужно учесть, что цифра 0 и буква «о» вообще не отличимы друг от друга, цифра 8 и буква «в». Выстроим все знаки слева направо и будем брать по 6 знаков.
Критерий раз — буква-цифра-цифра-цифра-буква-буква (не забываем про 0/о, 8/в)
Критерий два — отклонение нижней границы 6 знаков от линии
Суммарные очки за гипотезу — сумма дистанций Хэмминга всех 6 знаков. Чем больше, тем лучше.
Итак, если суммарные очки меньше порога, то считаем, что мы нашли 6 знаков номера (без региона). Если больше порога, то идем к алгоритму устойчивому к грязным номерам.
Тут еще стоит рассмотреть отдельно буквы «Н» и «М». Для этого нужно сделать отдельный классификатор, например, по гистограмме градиентов.
Регион
Следующие два или три знака над линей, проведенной по низу 6 уже найденных знаков, — регион. Если третья цифра существует, и ее похожесть больше пороговой, то регион состоит из трех цифр. Иначе из двух.
Однако, распознавание региона часто происходит не так гладко, как хотелось бы. Цифры в регионы меньше, могут удачно не разделиться. Поэтому регион лучше узнавать способом более устойчивым к грязи/шума/перекрытию, описанным далее.
Какие-то детали описания алгоритма не слишком подробно раскрыты. Отчасти из-за того, что сейчас сделан лишь макет этого алгоритма и предстоит еще протестировать и отладить его на тех тысячах изображений. Если номер хороший и чистый, то нужно за десятки миллисекунд распознать номер или ответить «не удалось» и перейти к более серьезному алгоритму.
Алгоритм устойчивый к грязным номерам
Понятно, что алгоритм, описанный выше совсем не работает, если знаки на номере слипаются из-за плохого качества изображения (грязи, плохого разрешения, неудачной тени или угла съемки).
Вот примеры номеров, когда первый алгоритм не смог ничего сделать:

А алгоритм, описанный далее, смог.
Но придется опираться на границы автомобильного номера, а потом уже внутри строго определенной области искать знаки с точно известной ориентацией и масштабом. И главное — никакой бинаризации!
Ищем нижнюю границу номера
Самый простой и самый надежный этап в этом алгоритме. Перебираем несколько гипотез по углу поворота и строим для каждой гипотезы по повороту гистограмму яркости пикселей вдоль горизонтальных линий для нижней половины изображения:

Выберем максимум градиента и так определим угол наклона и по какому уровню отрезать номер снизу. Не забудем улучшить контраст и получим вот такое изображение:

Вообще стоит использовать не только гистограмму яркости, но также и гистограмму дисперсии, гистограмму градиентов, чтобы увеличить надежность обрезки номера.
Ищем верхнюю границу номера
Тут уже не так очевидно, оказалось, если снимают с рук задний автомобильный номер, то верхняя граница может быть сильно изогнута и частично прикрывать знаки или в тени, как в данном случае:

Резкого перехода яркости в верхней части номера нет, а максимальный градиент и вовсе разрежет номер посередине.
Мы вышли из ситуации не очень тривиально: обучили на каждую цифру и каждую букву каскадный детектор Хаара, нашли все знаки на изображении, так определили верхнюю линию где резать:

Казалось бы, что тут и стоит остановиться — мы же нашли уже цифры и буквы! Но на деле, конечно, детектор Хаара может ошибаться, а у нас тут 7-8 знаков. Хороший пример цифры 4. Если верхняя граница номера сливается с цифрой 4, то совсем не сложно увидеть цифру 7. Что кстати и произошло в данном примере. Но с другой стороны, несмотря на ошибку в детектировании, верхняя граница найденных прямоугольников действительно совпадает с верхней границей автомобильного номера.
Найти боковые границы номера
Тоже ничего хитрого — абсолютно также, как и нижнюю. Единственное отличие, что часто яркость градиента первого или последнего знака в номере может превышать яркость градиента вертикальной границы номера, поэтому выбирается не максимум, а первый градиент, превышающий порог. Аналогично с нижней границей необходимо перебрать несколько гипотез по наклону, т. к. из-за перспективы перпендикулярность вертикальной и горизонтальной границы совсем не гарантирована.
Итак, вот хорошо обрезанный номер:

да! особенно приятно вставить кадр с отвратительным номером, который был успешно распознан.
Печалит лишь одно — к этому этапу от 5% до 15% номеров могут отрезаться неправильно. Например, так:

(кстати это кто-то нам отправил желтый номер такси, насколько я понял — формат не штатный)
Все это нужно было, чтобы все это делалось лишь для оптимизации вычислений, т. к. перебрать все возможные положение, масштабы и наклоны знаков при их поиске — очень затратно вычислительно.
Разделить строку на знаки
К сожалению, из-за перспективы и не стандартной ширины всех знаком, приходится как-то выделять символы в уже обрезанном номере. Тут снова выручит гистограмма по яркости, но уже вдоль оси X:
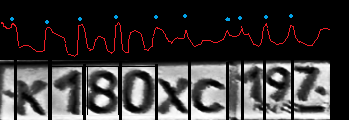
Единственное, что в дальнейшем стоит исследовать две гипотезы: символы начинаются сразу или один максимум гистограммы стоит пропустить. Это связано с тем, что на некоторых номерах отверстие под винт или головка винта автомобильного номера могут различаться, как отдельный знак, а могут быть и вовсе незаметны.
Распознавание символов
Изображение до сих пор не бинаризовано, будем использовать всю информацию, что есть.
Здесь печатные символы, значит подойдет взвешенная ковариация для сравнения изображений с примером:
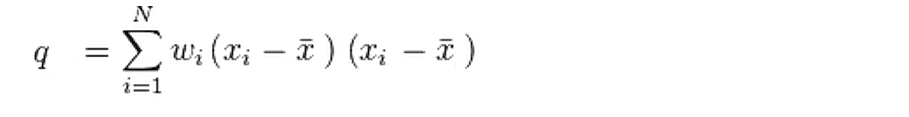
Образцы для сравнения и веса при ковариации:

Конечно, нельзя просто сравнить область, выделенную с помощью горизонтальной гистограммы, с образцами. Приходится делать несколько гипотез по смещению и по масштабу.
Количество гипотез по положению по оси X = 4
Количество гипотез по положению по оси Y = 4
Количество гипотез по масштабу = 3
Таким образом, для каждой области при сравнении с одним знаком необходимо рассчитать 4х4х3 ковариации.
Первым делом найдем 3 большие цифры. Это 3 х 10 х 4 х 4 х 3 = 1440 сравнений.
Затем слева одну букву и справа еще две. Букв для сравнения 12. Тогда количество сравнений 3x12x4x4x3 = 1728
Когда у нас есть 6 символов, то все справа от них — регион.

В регионе могут быть 2 цифры или 3 цифры — это нужно учесть. Разбивать регион гистограммным способом уже бессмысленно из-за того, что качество изображения может быть слишком низкое. Поэтому просто поочередно находим цифры слева направо. Начинаем с левого верхнего угла, необходимо несколько гипотез по оси X, оси Y и масштабу. Находим наилучшее совпадение. Смещаемся на заданную величину вправо, снова ищем. Третий символ будем искать слева от первого и справа от второго, если мера похожести третьего символа больше пороговой, то нам повезло — номер региона состоит из трех цифр.
Выводы
Практика применения алгоритма (второго описанного в статье) в очередной раз подтвердила прописную истину при решении задач распознавания: нужна действительно презентативная база при создании алгоритмов. Мы нацеливались на грязные и потертые номера, т.к. тестовая база снималась зимой. И действительно часто довольно плохие номера удавалось узнавать, но чистых номеров в обучающей выборке почти не было.
Вскрылась и другая сторона медали: мало что так раздражает пользователя, как ситуация, когда автоматическая система не решает совсем примитивную задачу. «Ну что тут может не читаться?!» А то, что автоматическая система не смогла узнать грязный или потертый номера, — это ожидаемо.
Откровенно говоря, это наш первый опыт разработки системы распознавания для массового потребителя. И о таких «мелочах», как о пользователях, стоит учиться думать. Сейчас к нам присоединился специалист, разработавший аналогичную «Recognitor» программу под iOs. В UI у пользователя появилась возможность увидеть, что сейчас отправляется на сервер, выбрать какой из выделенных Хааром номеров нужный, есть возможность выделить необходимую область в уже «застывшем» кадре. И пользоваться этим уже удобнее. Автоматическое распознавание становится не дурацкой функцией, без которой нельзя ничего сделать, а просто помощником.
Продумывать систему, в которой автоматическое распознавание изображения будет гармонично и удобно пользователю, — оказалось задачей ничуть не проще, чем создавать эти алгоритмы распознавания.
И, конечно, надеюсь, что статья будет полезна.
Первая статья цикла — общий обзор технологий
Вторая статья — Наш сервер
Третья статья — Протокол обращения к нашему серверу
Исходники клиентской части с первичным выделением номера
Собранная прога, распознающая номера
