
В прошлой статье мы подробно описали алгоритм распознавания номеров (ссылка), который заключается в получении текстового представления на заранее подготовленном изображении, содержащем рамку с номером + небольшие отступы для удобства распознавания. Мы лишь вскользь упомянули, что для выделения областей, где содержатся номера, использовался метод Виолы-Джонса. Данный метод уже описывался на хабре (ссылка, ссылка, ссылка, ссылка). Сегодня мы проиллюстрируем наглядно то, как он работает и коснёмся ранее необсужденных аспектов + в качестве бонуса будет показано, как подготовить вырезанные картинки с номерами на платформе iOS для последующего получения уже текстового представления номера.
Метод Виолы-Джонса
Обычно у каждого метода есть основа, то, без чего этот метод не мог бы существовать в принципе, а уже над этой основой строится вся остальная часть. В методе Виолы-Джонса эту основу составляют примитивы Хаара, представляющие собой разбивку заданной прямоугольной области на наборы разнотипных прямоугольных подобластей:
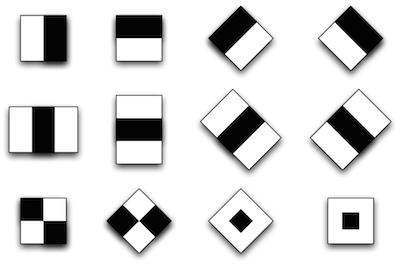
В оригинальной версии алгоритма Виолы-Джонса использовались только примитивы без поворотов, а для вычисления значения признака сумма яркостей пикселей одной подобласти вычиталась из суммы яркостей другой подобласти [1]. В развитии метода были предложены примитивы с наклоном на 45 градусов и несимметричных конфигураций. Также вместо вычисления обычной разности, было предложено приписывать каждой подобласти определенный вес и значения признака вычислять как взвешенную сумму пикселей разнотипных областей [2]:
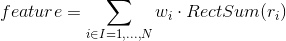
Почему в основу метода легли примитивы Хаара? Основной причиной являлась попытка уйти от пиксельного представления с сохранением скорости вычисления признака. Из значений пары пикселей сложно вынести какую-либо осмысленную информацию для классификации, в то время как из двух признаков Хаара строится, например, первый каскад системы по распознаванию лиц, который имеет вполне осмысленную интерпретацию [1]:

Сложность вычисления признака так же как и получения значения пикселя остается O(1): значение каждой подобласти можно вычислить скомбинировав 4 значения интегрального представления (Summed Area Table — SAT), которое в свою очередь можно построить заранее один раз для всего изображения за O(n), где n — число пикселей в изображении, используя формулу [2]:
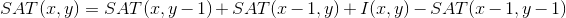
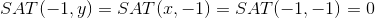
Это позволило создать быстрый алгоритм поиска объектов, который пользуется успехом уже больше десятилетия. Но вернемся к нашим признакам. Для определения принадлежности к классу в каждом каскаде, находиться сумма значений слабых классификаторов этого каскада. Каждый слабый классификатор выдает два значения в зависимости от того больше или меньше заданного порога значение признака, принадлежащего этому классификатору. В конце сумма значений слабых классификаторов сравнивается с порогом каскада и выносится решения найден объект или нет данным каскадом. Ну хватит теории, перейдем к практике!
Мы уже давали ссылку на XML нашего классификатора автомобильных номеров, который можно найти в мастере проекта opencv (ссылка). Посмотрим на его первый каскад:
<maxWeakCount>6</maxWeakCount>
<stageThreshold>-1.3110191822052002e+000</stageThreshold>
<weakClassifiers>
<_>
<internalNodes>
0 -1 193 1.0079263709485531e-002</internalNodes>
<leafValues>
-8.1339186429977417e-001 5.0277775526046753e-001</leafValues></_>
<_>
<internalNodes>
0 -1 94 -2.2060684859752655e-002</internalNodes>
<leafValues>
7.9418992996215820e-001 -5.0896102190017700e-001</leafValues></_>
<_>
<internalNodes>
0 -1 18 -4.8777908086776733e-002</internalNodes>
<leafValues>
7.1656656265258789e-001 -4.1640335321426392e-001</leafValues></_>
<_>
<internalNodes>
0 -1 35 1.0387318208813667e-002</internalNodes>
<leafValues>
3.7618312239646912e-001 -8.5504144430160522e-001</leafValues></_>
<_>
<internalNodes>
0 -1 191 -9.4083719886839390e-004</internalNodes>
<leafValues>
4.2658549547195435e-001 -5.7729166746139526e-001</leafValues></_>
<_>
<internalNodes>
0 -1 48 -8.2391249015927315e-003</internalNodes>
<leafValues>
8.2346975803375244e-001 -3.7503159046173096e-001</leafValues></_></weakClassifiers>
На первый взгляд кажется, что здесь куча непонятных цифр и странной информации, но на самом деле все просто: weakClassifiers — набор слабых классификаторов, на основе которых выносится решение о том, находится объект на изображении или нет, internalNodes и leafValues — это параметры конкретного слабого классификатора. Расшифровка internalNodes слева направо: первые два значения в нашем случае не используется, третье — номер признака в общей таблице признаков (она располагается дальше в XML файле под тегом features), четвертое — пороговое значение слабого классификатора. Так как у нас используется классификатор, основанный на одноуровневых решающих деревьях (decision stump), то если значение признака Хаара меньше порога слабого классификатора (четвертое значение в internalNodes), выбирается первое значение leafValues, если больше — второе. А теперь отрисуем реакцию некоторых классификаторов первого каскада:





По сути все эти признаки в какой-то степени являются самыми обыкновенными детекторами границ. На основе этого базиса строится решение о том распознал ли каскад объект на изображении или нет.
Второй по важности момент в методе Виола-Джонса — это использование каскадной модели или вырожденного дерева принятия решений: в каждом узле дерева с помощью каскада принимается решение может ли на изображении содержатся объект или нет. Если объект не содержится, то алгоритм заканчивает свою работу, если он может содержатся, то мы переходим к следующему узлу. Обучение построено таким образом, чтобы на начальных уровнях с наименьшими затратами отбрасывать большую часть окон, в которых не может содержаться объект. В случае распознавания лиц — первый уровень содержит всего 2 слабых классификатора, в случае распознавания автомобильных номеров — 6 (при учете, что последние содержат до 15ти). Ну и для наглядности как происходит распознавание номера по уровням:

Более насыщенный тон показывает вес окна относительно уровня. Отрисовка была сделана на основе модифицированного кода проекта opencv из ветки 2.4 (добавлена поуровневая статистика).
Реализация распознавания на платформе iOS



С добавлением opencv в проект обычно не возникает проблем, тем более что существует готовый фреймворк под iOS, поддерживающий все существующие архитектуры (в том числе и симулятор). Функция для нахождения объектов используется та же, что и в проекте под Android (ссылка):
detectMultiScale класса cv::CascadeClassifier, осталось только подготовить данные для подачи на вход. Допустим у нас имеется UIImage на котором нужно отыскать все номера. Для каскада нам нужно сделать несколько вещей: во-первых, ужать изображение до 800px по большей стороне (чем больше изображение, тем нужно рассмотреть больше масштабов, также от размера изображения зависит количество окон, которые нужно просмотреть при поиске), во-вторых, сделать из него черно-белый аналог (метод оперирует только с яркостью, по идее этот этап можно пропустить, opencv это умеет делать за нас, но сделаем это заодно, раз и так производим манипуляции с изображением), в-третьих, получить бинарные данные для передачи opencv. Все эти три вещи можно сделать за один мах, отрисовав в контекст нашу картинку с правильными параметрами, вот так:+ (unsigned char *)planar8RawDataFromImage:(UIImage *)image
size:(CGSize)size
{
const NSUInteger kBitsPerPixel = 8;
CGColorSpaceRef colorSpace = CGColorSpaceCreateDeviceGray();
NSUInteger elementsCount = (NSUInteger)size.width * (NSUInteger)size.height;
unsigned char *rawData = (unsigned char *)calloc(elementsCount, 1);
NSUInteger bytesPerRow = (NSUInteger)size.width;
CGContextRef context = CGBitmapContextCreate(rawData,
size.width,
size.height,
kBitsPerPixel,
bytesPerRow,
colorSpace,
kCGImageAlphaNone);
CGColorSpaceRelease(colorSpace);
UIGraphicsPushContext(context);
CGContextTranslateCTM(context, 0.0f, size.height);
CGContextScaleCTM(context, 1.0f, -1.0f);
[image drawInRect:CGRectMake(0.0f, 0.0f, size.width, size.height)];
UIGraphicsPopContext();
CGContextRelease(context);
return rawData;
}
Теперь можно смело создавать из этого буфера
cv::Mat и передавать в функцию по распознаванию. Далее, пересчитываем положение найденных объектов по отношению к оригинальному изображению и вырезаем:CGSize imageSize = image.size;
@autoreleasepool {
for (std::vector<cv::Rect>::iterator it = plates.begin(); it != plates.end(); it++) {
CGRect rectToCropFrom = CGRectMake(it->x * imageSize.width / imageSizeForCascade.width,
it->y * imageSize.height / imageSizeForCascade.height,
it->width * imageSize.width / imageSizeForCascade.width,
it->height * imageSize.height / imageSizeForCascade.height);
CGRect enlargedRect = [self enlargeRect:rectToCropFrom
ratio:{.width = 1.2f, .height = 1.3f}
constraints:{.left = 0.0f, .top = 0.0f, .right = imageSize.width, .bottom = imageSize.height}];
UIImage *croppedImage = [self cropImageFromImage:image withRect:enlargedRect];
[plateImages addObject:croppedImage];
}
}
При желании класс
RVPlateNumberExtractor можно переделать и использовать в любом другом проекте, где требуется распознавание любых других объектов, а не только номеров.Хотел на всякий случай отметить, что если захочется открыть сразу записанное изображение с диска через
imread, то на iOS могут возникнуть проблемы, т.к при фотографировании iOS записывает картинку всегда в одной ориентации и добавляет в EXIF информацию о повороте, а opencv EXIF не обрабатывает при чтении. Избавиться от этого можно опять же таки отрисовкой в контекст.Послесловие
Со всем исходным кодом нашего свежего приложения под iOS можно ознакомиться на GitHub: ссылка
Там можно найти много полезного, например, уже упомянутый класс
RVPlateNumberExtractor для вырезания номеров из полноценного изображения картинок с номерами, а также RVPlateNumber с очень простым интерфейсом, который Вы можете смело брать в свои проекты, если потребуется сервис по распознаванию номеров и вполне может быть Вы найдете там еще что-нибудь интересное для себя. Мы также не против, если кто-то захочет запилить новую функциональность в приложение или сделает красивый дизайн!Приложение в AppStore: ссылка
По запросам трудящихся мы также обновили андроид приложение: добавили выбор сохраненных номеров для отправки.
Список литературы
- P. Viola and M. Jones. Robust real-time face detection. IJCV 57(2), 2004
- Lienhart R., Kuranov E., Pisarevsky V.: Empirical analysis of detection cascades of boosted classifiers for rapid object detection. In: PRS 2003, pp. 297-304 (2003)
