
«Горячая» и часто обсуждаемая сегодня тема оптимизации конверсии привела к безусловной популяризации А/Б-тестирования, как единственного объективного способа узнать правду о работоспособности тех или иных технологий/решений, связанных с увеличением экономической эффективности для онлайн-бизнеса.
За этой популярностью скрывается практически полное отсутствие культуры в организации, проведении и анализе результатов экспериментов. В Retail Rocket мы накопили большую экспертизу в оценке экономической эффективности от систем персонализации в электронной коммерции. За два года был отстроен идеальный процесс проведения A/Б-тестов, которым мы и хотим поделиться в рамках этой статьи.
Два слова о принципах A/Б-тестирования
В теории все невероятно просто:
- Выдвигаем гипотезу о том, что какое-то изменение (например, персонализация главной страницы) увеличит конверсию интернет-магазина.
- Создаем альтернативную версию сайта «Б» — копию исходной версии «А» с изменениями, от которых мы ждем роста эффективности сайта.
- Всех посетителей сайта случайным образом делим на две равные группы: одной группе показываем исходный вариант, второй — альтернативный.
- Одновременно измеряем конверсию для обеих версий сайта.
- Определяем статистически достоверно победивший вариант.
Прелесть этого подхода в том, что любую гипотезу можно проверить с помощью цифр. Нет необходимости спорить или опираться на мнение псевдоэкспертов. Запустили тест, замерили результат, перешли к следующему тесту.
Пример в цифрах
Для примера представим, что мы внесли на сайт какое-то изменение, запустили А/Б-тест и получили следующие данные:
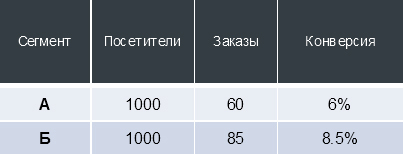
Конверсия — не статичная величина, в зависимости от количества “испытаний” и “успехов” (в случае интернет-магазина — посещений сайта и оформленных заказов соответственно) конверсия распределяется в определенном интервале с расчетной вероятностью.
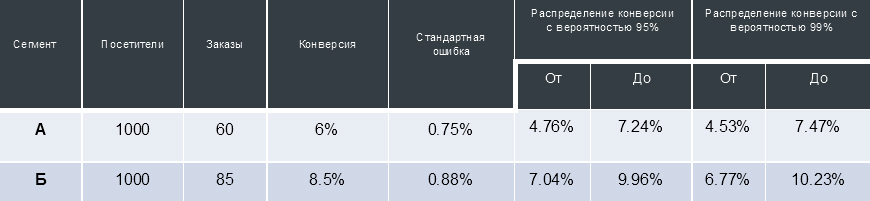
Для таблицы выше это означает, что если мы приведем еще 1000 пользователей на версию сайта “А” при неизменных внешних условиях, то с вероятностью 99% эти пользователи сделают от 45 до 75 заказов (то есть сконвертируются в покупателей с коэффициентом от 4.53% до 7.47%).
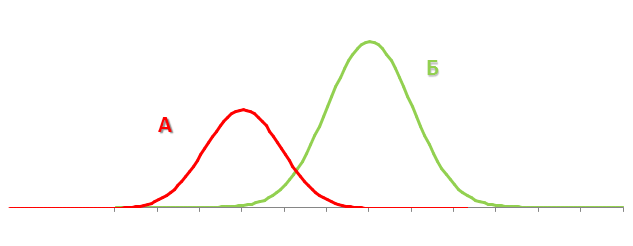
Сама по себе эта информация не слишком ценная, однако, при проведении А/Б-теста мы можем получить 2 интервала распределения конверсии. Сравнение пересечения так называемых “доверительных интервалов” конверсий, получаемых от двух сегментов пользователей, взаимодействующих с разными версиями сайта, позволяет принять решение и утверждать, что один из тестируемых вариантов сайта статистически достоверно превосходит другой. Графически это можно представить так:
Почему 99% ваших А/Б-тестов проводятся неверно?
Итак, с вышеописанной концепцией проведения экспериментов знакомо уже большинство, про неё рассказывают на отраслевых мероприятиях и пишут статьи. В Retail Rocket одновременно проходит 10-20 А/Б-тестов, за последние 3 года мы столкнулись с огромным количеством нюансов, которые часто остаются без внимания.
В этом есть огромный риск: если А/Б-тест проводится с ошибкой, то бизнес гарантированно принимает неверное решение и получает скрытые убытки. Более того, если вы ранее проводили A/Б-тесты, то скорее всего они были проведены некорректно.
Почему? Разберем самые частые ошибки, с которыми мы сталкивались в процессе проведения множества пост-тест анализов результатов проведенных экспериментов при внедрении Retail Rocket в интернет-магазины наших клиентов.
Доля аудитории в тесте
Пожалуй самая распространенная ошибка — при запуске тестирования не проверяется, что вся аудитория сайта участвует в нем. Довольно частый пример из жизни (скриншот из Google Analytics):
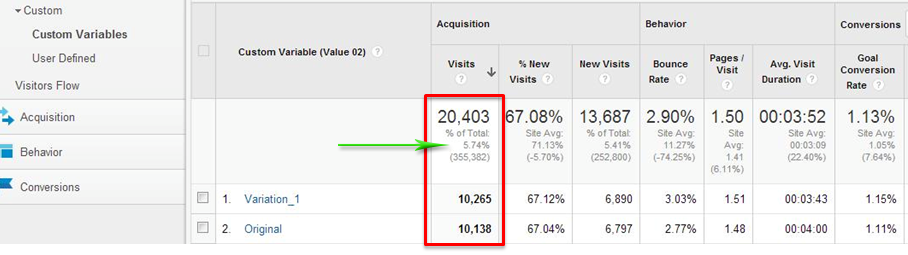
На скриншоте видно, что суммарно в тесте приняло участие чуть менее 6% аудитории. Крайне важно, чтобы вся аудитория сайта относилась к одному из сегментов теста, в противном случае невозможно оценить влияние изменения на бизнес в целом.
Равномерность распределения аудитории между тестируемыми вариациями
Недостаточно распределить всю аудиторию сайта по сегментам теста. Также важно проделать это равномерно по всем срезам. Рассмотрим на примере одного из наших клиентов:

Перед нами ситуация, при которой аудитория сайта делится неравномерно между сегментами теста. В данном случае в настройках инструмента для тестирования было выставлено деление трафика 50/50. Такая картина — явный признак того, что инструмент для распределения трафика работает не так, как ожидалось.
Кроме того, обратите внимание на последний столбец: видно, что во второй сегмент попадает больше повторной, а значит и более лояльной аудитории. Такие люди будут совершать больше заказов и исказят результаты тестирования. И это ещё один признак некорректной работы инструмента тестирования.
Чтобы исключить подобные ошибки через несколько дней после запуска тестирования всегда проверяйте равномерность деления трафика по всем доступным срезам (как минимум по городу, браузеру и платформе).
Фильтрация сотрудников интернет-магазина
Следующая распространенная проблема связана с сотрудниками интернет-магазинов, которые, попав в один из сегментов теста, оформляют заказы, поступившие по телефону. Тем самым сотрудники формируют дополнительные продажи в одном сегменте теста, в то время как звонящие находятся во всех. Безусловно, подобное аномальное поведение в конечном счете исказит итоговые результаты.
Операторов call-центра можно выявить с помощью отчета по сетям в Google Analytics:

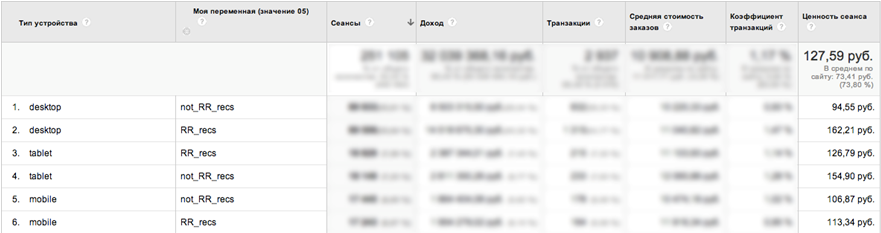
 На скриншоте пример из нашего опыта: посетитель 14 раз заходил на сайт из сети под названием «Торговый центр электроники на Пресне» и 35 раз оформил заказ — это явное поведение сотрудника магазина, который по какой-то причине оформлял заказы через корзину на сайте, а не через панель администратора магазина.
На скриншоте пример из нашего опыта: посетитель 14 раз заходил на сайт из сети под названием «Торговый центр электроники на Пресне» и 35 раз оформил заказ — это явное поведение сотрудника магазина, который по какой-то причине оформлял заказы через корзину на сайте, а не через панель администратора магазина.В любом случае, всегда можно выгрузить заказы из Google Analytics и присвоить им свойство “оформлен оператором” или “оформлен не оператором”. После чего построить сводную таблицу как на скриншоте, отражающую другую ситуацию, с которой мы сталкиваемся довольно часто: если взять выручку сегмента RR и Not RR (“сайт с Retail Rocket” и “без” соответственно), то “сайт с Retail Rocket” приносит меньше денег, чем “без”. Но если выделить заказы, оформленные операторами call-центра, то окажется, что Retail Rocket дает прирост выручки на 10%.
На какие показатели стоит обращать внимание при финальной оценке результатов?
В прошлом году проводился А/Б-тест, результаты которого оказались следующими:
- +8% к конверсии в сегменте “сайт с Retail Rocket”.
- Средний чек практически не изменился (+0.4% — на уровне погрешности).
- Рост по выручке +9% в сегменте “Сайт с Retail Rocket”.
После составления отчетов результатов мы получили такое письмо от клиента:
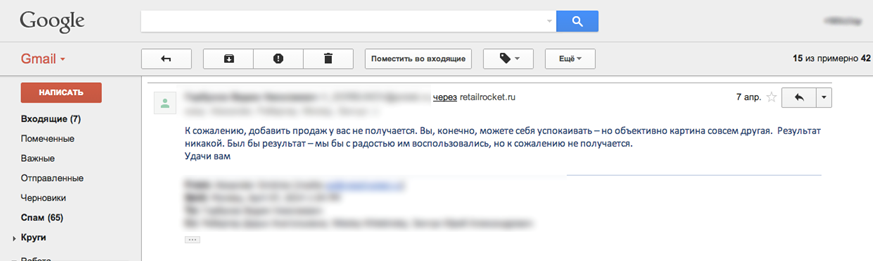
Менеджер интернет-магазина настаивал на том, что если средний чек не изменился, то эффекта от сервиса нет. При этом полностью игнорируется факт общего прироста выручки благодаря системе рекомендаций.
Так на какой показатель стоит ориентироваться? Конечно, для бизнеса самое важное — это деньги. Если в рамках A/Б-теста трафик делился между сегментами посетителей равномерно, то нужный показатель для сравнения — выручка (revenue) по каждому сегменту.
В жизни ни один инструмент для случайного деления трафика не дает абсолютно равных сегментов, всегда существует отличие в доли процента, поэтому необходимо нормировать выручку по количеству сессий и использовать метрику “выручка на посещение” (revenue per visit).
Это признанный в мире KPI, на который рекомендуем ориентироваться при проведении A/Б-тестов.
Важно помнить, что выручка от оформленных на сайте заказов и “исполненная” выручка (выручка от фактически оплаченных заказов) — это абсолютно разные вещи.
Вот пример А/Б-теста, в котором система Retail Rocket сравнивалась с другой рекомендательной системой:

Сегмент «не Retail Rocket» побеждает по всем параметрам. Однако, в рамках следующего этапа пост-тест анализа были исключены заказы call-центра, а также аннулированные заказы. Результаты:

Пост-тест анализ результатов — обязательный пункт при проведении A/Б-тестирования!
Срезы данных
Работа с разными срезами данных — крайне важная составляющая при пост-тест анализе.
Вот еще один кейс тестирования Retail Rocket на одном из крупнейших интернет-магазинов в России:

На первый взгляд мы получили отличный результат — прирост выручки +16.7%. Но если добавить в отчет дополнительный срез данных «Тип устройства» можно увидеть следующую картину:
- По Desktop-трафику рост выручки практически 72%!
- На планшетах в сегменте Retail Rocket просадка.
Как выяснилось после тестирования, на планшетах некорректно отображались блоки рекомендаций Retail Rocket.
Очень важно в рамках пост-тест анализа строить отчеты как минимум в разрезе города, браузера и платформы пользователя, чтобы не упустить подобные проблемы и максимизировать результаты.
Статистическая достоверность
Следующая тема, которую необходимо затронуть, — статистическая достоверность. Принимать решение о внедрении изменения на сайт можно только после достижения статистической достоверности превосходства.
Для подсчета статистической достоверности конверсии существует множество online-инструментов, например, htraffic.ru/calc/:

Но конверсия — это не единственный показатель, определяющий экономическую эффективность сайта. Проблема большинства А/Б-тестов сегодня — проверяется только статистическая достоверность конверсии, что является недостаточным.
Средний чек
Выручка интернет-магазина строится из конверсии (доли людей, которые покупают) и из среднего чека (размера покупки). Статистическую достоверность изменения среднего чека посчитать сложнее, но без этого никак, иначе неизбежны неверные выводы.
На скриншоте продемонстрирован очередной пример A/Б-теста Retail Rocket, при котором в один из сегментов попал заказ на сумму более миллиона рублей:
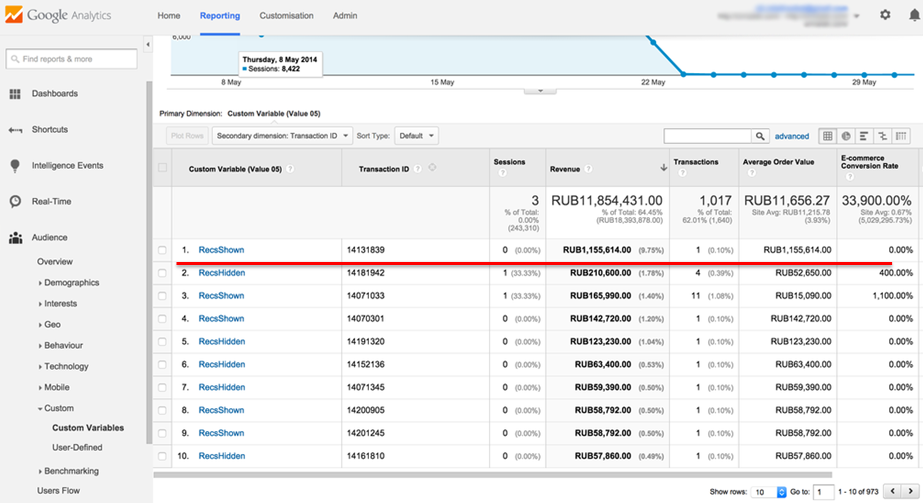
Этот заказ составляет почти 10% от всей выручки за период проведения теста. В таком случае, при достижении статистической достоверности по конверсии можно ли считать достоверными результаты по выручке? Конечно, нет.
Такие огромные заказы значительно искажают результаты, у нас есть два подхода к пост-тест анализу с точки зрения среднего чека:
- Сложный. «Байесовская статистика», о которой мы расскажем в следующих статьях. В Retail Rocket мы используем ее для оценки достоверности среднего чека внутренних тестов по оптимизации алгоритмов рекомендаций.
- Простой. Отсечение нескольких процентилей заказов сверху и снизу (как правило, 3-5%) списка, отсортированного по убыванию суммы заказа.
Время проведения теста
И напоследок, всегда обращайте внимание на то, когда вы запускаете тест и как долго он длится. Старайтесь не запускать тест за несколько дней до крупных гендерных праздников и в праздничные/выходные дни. Сезонность также прослеживается на уровне получения зарплат: как правило, это стимулирует продажи дорогих товаров, в частности, электроники.
Кроме того, существует доказанная зависимость между средним чеком в магазине и временем принятия решения до покупки. Проще говоря, чем дороже товары — тем дольше их выбирают. На скриншоте пример магазина, в котором 7% пользователей до покупки размышляют от 1 до 2 недель:
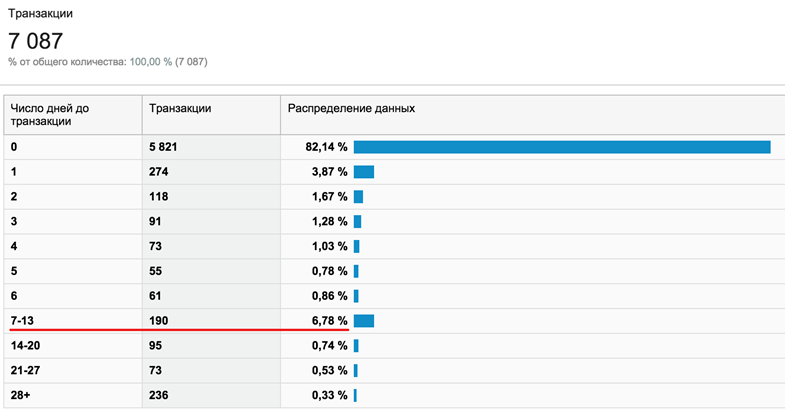
Если на таком магазине проводить А/Б-тест меньше недели, то в него не попадет около 10% аудитории и влияние изменения на сайте на бизнес однозначно оценить невозможно.
Вместо вывода. Как провести идеальный А/Б-тест?
Итак, для исключения всех описанных выше проблем и проведения правильного A/Б-теста нужно выполнить 3 шага:
1. Разделить трафик 50 / 50
Сложно: с помощью балансировщика трафика.
Просто: воспользоваться open source библиотекой Retail Rocket Segmentator, которую поддерживает команда Retail Rocket. За несколько лет тестов нам не удалось решить описанные выше проблемы в инструментах вроде Optimizely или Visual Website Optimizer.
Цель на первом шаге:
- Получить равномерное распределение аудитории по всем доступным срезам (браузеры, города, источники трафика и т.д.).
- 100% аудитории должно попасть в тест.
2. Провести А/А-тест
Не меняя ничего на сайте, передавать в Google Analytics (или другую систему веб-аналитики, которая вам нравится) разные идентификаторы сегментов пользователей (в случае с Google Analytics — Custom var / Custom dimension).
Цель на втором шаге: не получить победителя, т.е. в двух сегментах с одинаковыми версиями сайта не должно быть разницы по ключевым показателям.
3. Провести пост-тест анализ
- Исключить сотрудников компании.
- Отсечь экстремальные значения.
- Проверить значимость ценности конверсии, использовать данные по исполняемости и аннуляции заказов, т.е. учесть все кейсы, упомянутые выше.
Цель на последнем шаге: принять правильное решение.
Делитесь своими кейсами проведения A/Б-тестов в комментариях!
